基于深度学习的数据竞争检测方法
2022-09-06东春浩高鸿斌
张 杨 乔 柳 东春浩 高鸿斌
(河北科技大学信息科学与工程学院 石家庄 050018)
(zhangyang@hebust.edu.cn)
数据竞争[1]是指2个或多个线程同时访问1个内存位置并且至少有1个线程执行写操作.数据竞争是目前最常见的并发缺陷之一,它是一种典型的运行时故障,通常在特定的并发执行环境中发生,难以被检测,它的存在会给程序运行带来潜在的风险,严重时会导致程序无法正常运行甚至崩溃,造成无法估量的损失,因此迫切需要对数据竞争检测问题进行研究.
数据竞争检测一直是国内外并发缺陷研究领域的热点问题之一,很多学者对数据竞争检测问题进行了研究,所采用的方法包括基于动态程序分析的检测方法、基于静态程序分析的检测方法、动静结合的检测方法[2-4].基于动态程序分析的检测方法在程序运行过程中,通过监控程序执行路径和内存读写访问等方式检测数据竞争的发生,这种检测方式的优点在于误报率较低,缺点是数据竞争的漏报率较高,而且检测过程开销较大.已有的动态数据竞争检测工具有Said[5],RVPredict[6],SlimFast[7]等.与动态数据竞争检测方法不同,静态数据竞争检测在源代码或中间代码层次展开,通过分析程序中变量的读写访问,辅助以各种静态程序分析技术(如发生序分析、别名分析、逃逸分析等)进行数据竞争检测.这种检测方式的优点在于可以在程序运行之前排除相关问题,不仅开销较小,而且检测较为全面,漏报率较低;缺点在于仅在代码层面进行分析而没有真正运行程序,可能会导致很多误报,已有的静态检测工具包括RELAY[8],Elmas[9],SRD[10]等.此外,为了弥补以上2种方式各自的不足,有些研究人员也尝试将动态分析和静态分析2种检测方法结合起来,以此提高检测的整体效率,常用的动静结合的检测工具有RaceTracker[11]和AsampleLock[12]等.
近年来,随着机器学习和深度学习技术的发展和广泛应用,一些研究人员开始将相关技术应用于数据竞争检测.在国内,孙家泽等人[13-14]提出一种基于机器学习的数据竞争检测方法,该方法使用随机森林模型,收集指令级别数据,进行数据竞争检测,而且他们还基于Adaboost模型进行语句级并发程序数据竞争检测,该方法的准确率可达92%.在国外,Tehrani等人[15]通过提取文件级别的特征来构建数据竞争训练数据集,他们提出一种基于卷积神经网络(convolutional neural network, CNN)的数据竞争检测方法,实验表明该方法检测的准确率在83%~86%.
从目前的研究现状来看,一些研究人员从程序分析的角度开展数据竞争检测研究,另一些研究人员将程序作为语料库,使用机器学习和深度学习方法开展研究,虽然已有的检测方法取得了一定的成效,但仍存在3个方面的问题亟需进一步研究完善:
1) 目前已有工作所使用的学习模型主要依赖于深度学习中CNN模型和机器学习中随机森林模型,模型还有待于优化,准确率还有提升的空间.
2) 在构建数据集时,现有的基于深度学习的数据竞争检测工具[15]仅应用了3个不同的基准测试程序,所提取的数据集样本个数较少,在输入到深度学习模型时会导致检测精度下降.
3) 在特征抽取时,仅提取指令或文件等级别的某一方面的特征,无法充分反映数据竞争的真实情况.
针对目前研究存在的问题,本文提出一种基于深度学习的数据竞争检测方法DeleRace(deep-learning-based data race detection).该方法首先使用程序静态分析工具WALA[16]从多个实际应用程序中提取指令、方法和文件级别中多个代码特征,对其向量化并构造训练样本数据;然后通过ConRacer[17]工具对真实数据竞争进行判定进而标记样本数据,并采用SMOTE[18]增强算法使正负数据样本分布均衡化;最后构建CNN-LSTM[19]的深度神经网络,加以训练构建分类器,进而实现对数据竞争的检测.在实验中选取DaCapo[20],JGF[21],IBM Contest[22],PJBench[23]这4个基准测试程序套件中的26个基准程序进行数据竞争检测,结果表明DeleRace的准确率为96.79%,与目前已有的基于深度学习的检测方法DeepRace相比提升了4.65%.与RNN和LSTM相比,DeleRace采用的CNN-LSTM网络也具有较高的准确率.此外,我们将DeleRace与已有的动态数据竞争检测工具(Said和RVPredict)和静态数据竞争检测工具(SRD和ConRacer)进行比较,结果表明DeleRace可以检测出更多真实有效的数据竞争.
本文的主要贡献有3个方面:
1) 从26个不同领域的实际应用程序提取指令、方法和文件等多个级别的特征构建深度学习模型训练数据集和测试数据集.
2) 提出一种适合数据竞争检测的深度学习模型DeleRace,使用CNN的卷积核提取相关特征,借助LSTM提取时序特征,通过CNN和LSTM的结合提升检测精度.
3) 将DeleRace与现有的基于深度学习的数据竞争检测工具进行了对比,并与已有的基于程序分析的数据竞争检测工具进行比较,验证了DeleRace的有效性.
1 基于深度学习的数据竞争检测方法
本节首先给出DeleRace的检测框架,然后对框架中的每个部分进行详细介绍.
1.1 检测框架
为了对数据竞争进行检测,提出了一个基于深度学习的数据竞争检测框架DeleRace.首先,为了构建深度学习模型的训练数据集,DeleRace从DaCapo[20],JGF[21],IBM Contest[22],PJBench[23]四个基准测试程序套件中选取26个含有数据竞争的并发程序,然后使用静态程序分析工具提取数据竞争发生位置的上下文特征信息,构造训练和测试样本,并且在样本数据中对真实有效的数据竞争进行标记.为了使提取的文本特征样本更易于被深度学习模型所处理,DeleRace使用Keras[24]的嵌入层对训练样本中文本特征进行向量化.考虑到收集的并发程序中含有数据竞争正样本数可能较少,会导致正样本和负样本分布不均衡,我们使用数据增强算法增加正样本的数量,尽可能地保证正负样本均衡分布.最后,构建了一个CNN-LSTM深度神经网络模型,使用训练集对该模型进行训练,得到训练好的分类器,使用该分类器进行数据竞争检测.基于深度学习的数据竞争检测框架如图1所示:
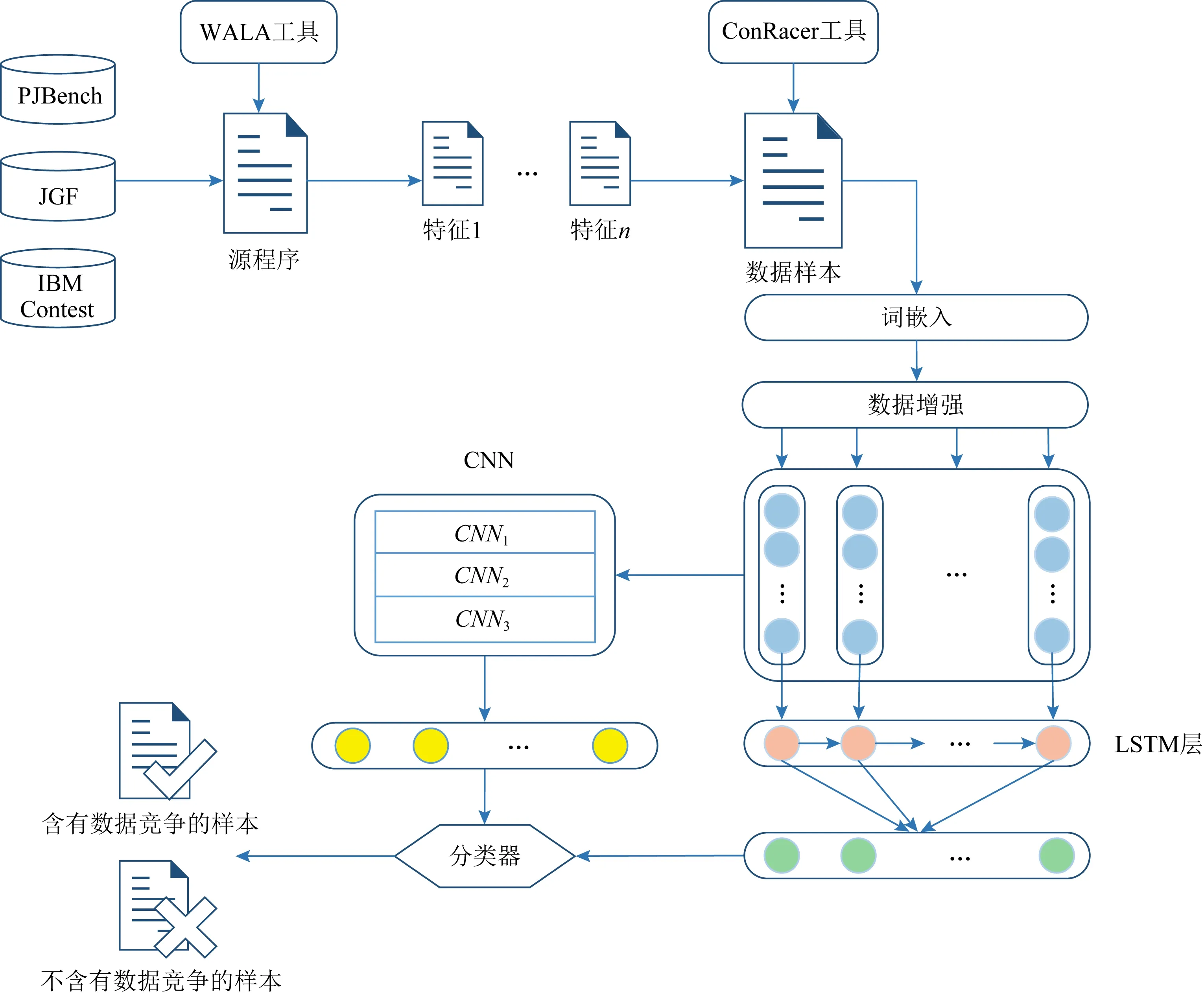
Fig. 1 The framework of DeleRace图1 DeleRace方法框架
1.2 选取实际应用程序
由于目前没有公开的专门用于数据竞争检测的数据集,为了训练深度神经网络进行数据竞争检测,我们首先构建数据竞争的训练数据集.
1.3 特征提取
已有的方法在提取数据竞争特征时相对单一,无法充分体现数据竞争的产生条件,例如文献[13-14]分别提取指令和语句级别的特征,而文献[15]仅提取了文件级别的特征.为了充分提取特征,我们在构建数据集样本时充分考虑了数据竞争产生的条件,依据这些条件提取多个级别的程序相关特征.
数据竞争的产生条件包括:1)2个或多个线程对同一个共享内存单元进行并发访问;2)至少有1个为写操作;3)各个操作之间没有被使用同一监视器对象的锁保护.基于这3个条件,我们从收集的基准程序中选取多个级别的特征来构建数据集样本,其中包括访问操作指令相关信息(如指令的Hash值、是否为写操作、是否被同步块包含、是否被同步方法包含)和数据竞争发生位置的相关信息(如包名、类名、方法名和变量名),其中前4个特征用于表明数据竞争的产生条件,后4个特征用于表明数据竞争发生的位置.
DeleRace借助程序静态分析工具WALA[16]进行特征提取,主要操作包括:
1) 通过方法makeNCFABuilder()构建程序的控制流图cg.
2) 遍历控制流图cg,收集所有节点cgNode下的访问操作,获取访问字段中的指令,判断该指令是否为写操作,判断是否被同步块或同步方法包含,并通过指令对应的内存地址来生成Hash值,将其作为变量访问的唯一标识.
3) 通过以上方法获得所有变量访问操作,将每个线程的访问操作存入集合V中,V定义为
V=〈isWrite,hashCode,isSyn,isSynBlock〉,
(1)
其中isWrite表示是否为写操作,hashCode表示变量访问操作指令的Hash值,isSyn表示是否被同步方法包含,isSynBlock表示是否被同步块包含.遍历每个线程集合中的所有访问操作,与不同线程的访问操作进行对比判断,获得所有可能存在竞争的访问操作对.
4) 通过获取包名、类名、方法名以及所有静态变量和实例变量表明每对访问操作发生数据竞争的位置,判断其访问变量是否相同.
这里对特征提取后的表现形式进行演示,如表1和表2所示.表1展示了IBM Contest[22]基准测试程序套件中的Account程序中部分数据的数值特征信息.其中,“读写访问”列中的“1”代表写操作,“0”代表读操作;“标签”列中“1”代表构成数据竞争,“0”代表不构成数据竞争;其他列中的“1”代表是,“0”代表否,每一条数据样本包括2个访问操作,每个访问操作包含读写访问、Hash值、同步方法、同步块等4条指令级别的特征.
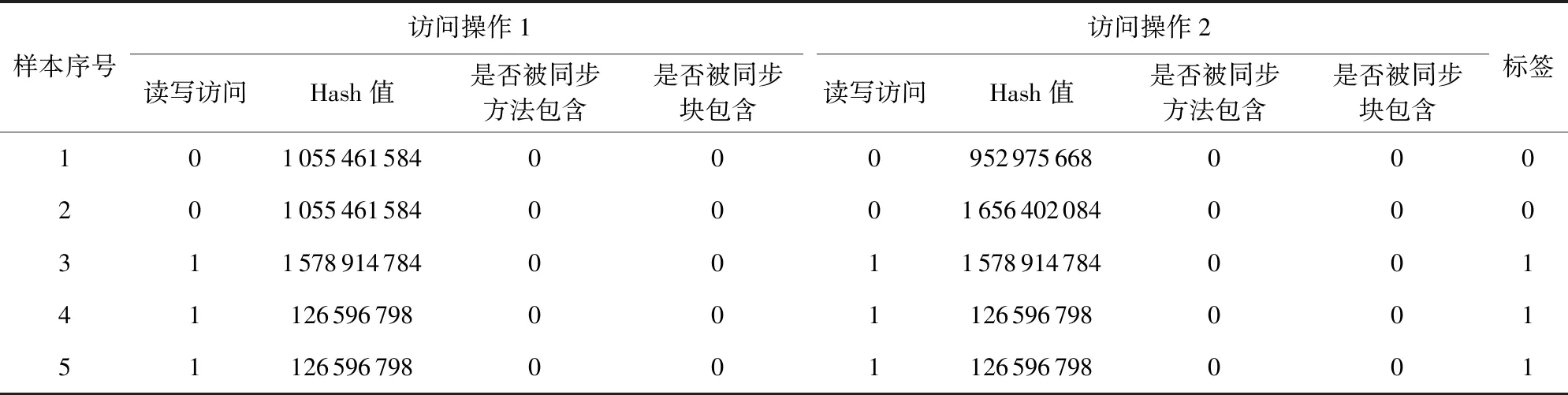
Table 1 Numerical Feature表1 数值特征信息

Table 2 Text Feature表2 文本特征信息
表2展示了IBM Contest[22]基准测试程序套件中的Account程序中部分数据的文本特征.“标签”列中“1”表示构成数据竞争,“0”表示不构成数据竞争,每一条数据样本包括2个访问操作,每个访问操作均包含包名、类名、方法名、变量名等文本特征,其中包名和类名为文件级别的特征,方法名和变量名为方法级别的特征.

Fig. 2 Text feature vectorization图2 文本特征向量化
我们借助ConRacer[17]工具对真实数据竞争进行判定,并对样本数据进行标记.之所以选择ConRacer工具,是因为ConRacer在对数据竞争的分析过程中考虑了方法调用的上下文信息,误报和漏报都相对较少.然而在实际应用中ConRacer也不是完美的,仍存在一些误报和漏报,为了确保数据集标记的准确性,我们对标记情况进行了手动验证,保证数据集的正确性.
1.4 文本特征向量化
深度学习模型在训练时一般采用数值向量数据作为输入,通常不会直接采用文本数据.为了使训练数据和测试数据易于被深度学习模型所使用,需要把提取的文本特征转化为数值向量.在文本特征向量化的过程中,由于指令级别的特征信息本身为整数(如表1所示),因此无需将其向量化;而对于方法和文件级别的特征,由于在特征抽取阶段获得的均为文本数据(如表2所示),因此需将其转化为数值向量.
DeleRace使用Keras[24]的嵌入层进行文本特征向量化,该层采用有监督的学习方式,基于已经标记好的信息进行学习并更新权重,其定义可表示为
f:Mi→Rn,
(2)
其中,Mi表示第i个文本特征的整数编码;Rn表示Mi对应的n维向量;f是一个参数化函数映射,表示将单词映射到n维向量.
图2以Account测试程序中某一文件级别的特征信息为例演示了文本特征向量化的过程,这里设置词向量维度n=8.首先将单词表中的单词进行词频统计并进行整数编码,将单词转换为数值向量时不区分大小写,因此单词Account与单词account的编码均为18,其他单词out,num编码分别为135,100;然后将每个单词的编码M经过嵌入层处理后映射为一个8维向量,此时得到文本向量化的表示是随机的,我们对嵌入层进行训练并更新权重;最后得到一个真正可以代表每个单词的数值向量,单词间通过各自对应的数值向量反映单词间相关性,通过计算均值使每一个单词仅用一个数值来表示.
1.5 数据均衡分布
DeleRace在样本数据的提取过程中,由于这些并发程序中数据竞争的数量很少,导致数据集中所提取的含有数据竞争的样本数远少于不含有数据竞争的样本数,这导致标签为正样本和负样本的数量极度不均衡,如果使用该数据集进行训练会严重影响深度学习模型的准确率.为了解决这个问题,通常采用欠采样(undersampling)和过采样(oversampling)2种方法.其中,欠采样方法会从多数样本中减少训练实例,该方法只会减少不含数据竞争的样本,虽可以保证数据均衡分布,但减少了样本数量;过采样方法通过分析少数样本来增加训练实例,有助于增加数据竞争的正样本数.此外,考虑到欠采样方法一方面可能会因为减掉的数据导致某些关键信息丢失,另一方面减少训练样本也很有可能导致模型精度下降,因此本文采用过采样方法来达到数据均衡分布的目的,既可以保证特征信息的完整,又有助于扩充训练样本从而提高模型精度.
在过采样过程中,DeleRace使用SMOTE算法[18]进行数据增强,它是一种合成少数类的过采样技术,其基本思想是对少数类样本进行分析,并根据少数类样本合成新样本,然后添加到数据集中,如图3所示.这里先选定一个正样本,找出这个正样本的K近邻(假设K=4),随机从K个近邻中选择一个样本,在正样本和被选出的近邻样本的连线上随机找一个点,这个点就是我们生成的新的正样本,一直重复这个过程,直到正样本和负样本数量均衡.通过SMOTE算法,将原有的12 836条训练样本扩充到25 438条,从而使正样本和负样本的数据样本数量达到了均衡.
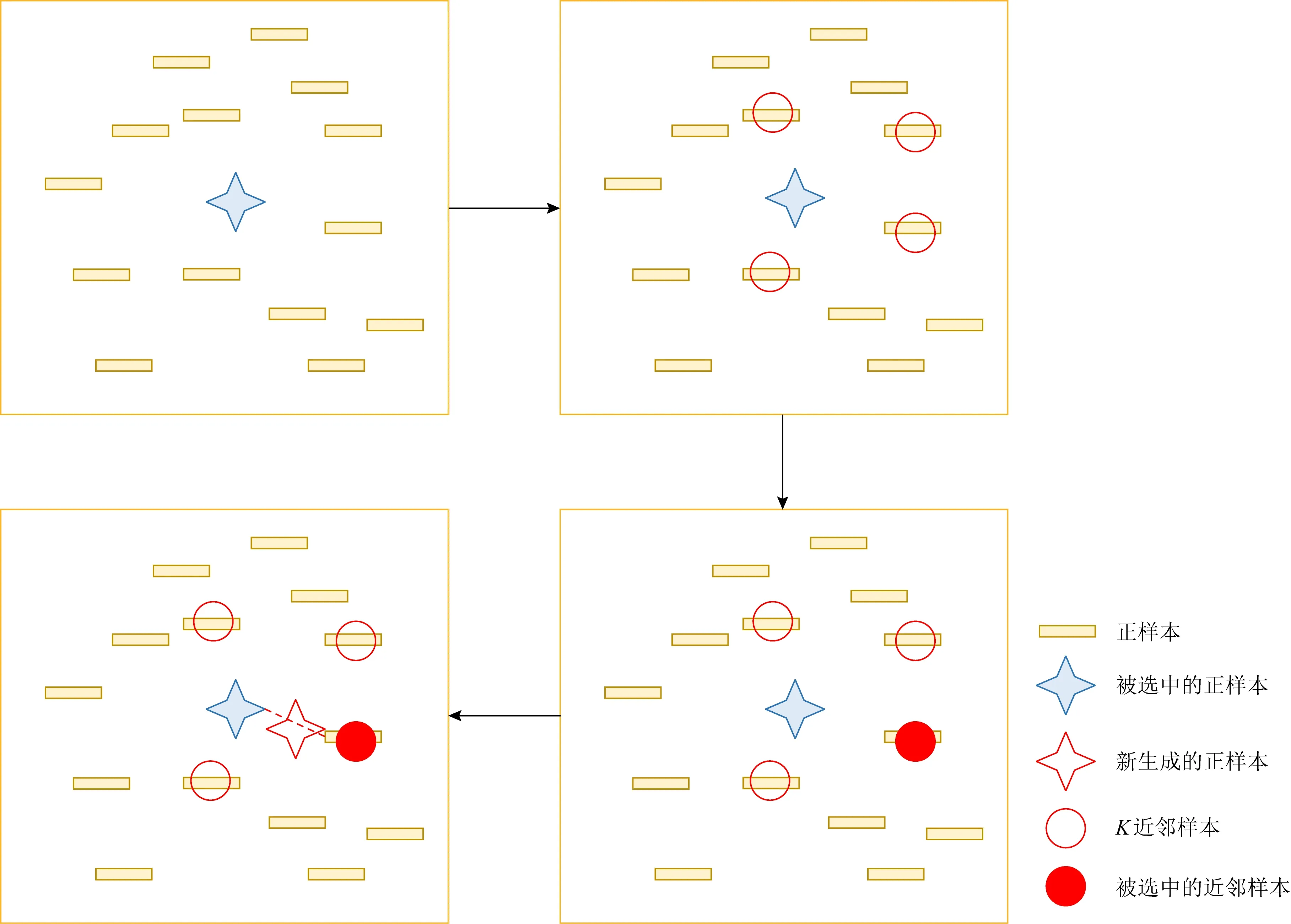
Fig. 3 SMOTE algorithm[18] 图3 SMOTE算法[18]
1.6 CNN-LSTM神经网络
本文采用CNN-LSTM的神经网络模型,该模型在Keras中实现.CNN并非只能处理图像,在NLP领域也能够很精准地处理分类任务,比如在情感分析[25]和观点分类[26]中都发挥了很好的作用.使用CNN进行文本分类最显著的优势是其无需人工手动地提取文本特征,可以自动获取基础特征并组合为高级特征,训练模型获得文本特征与目标分类之间的关系.我们借助CNN模型中卷积层的卷积核提取特征,然后使用最大池化层对上一层卷积层进行降维,既降低提取特征的数据维度,又保留了具有代表性的特征.
虽然CNN在处理文本分类问题上存在诸多益处,但由于卷积核的存在,导致CNN在处理时序信号数据时存在“长期依赖”问题.针对这一问题,我们选择了LSTM神经网络与CNN进行结合.LSTM是长短期记忆神经网络,可以有效解决“长期依赖”问题,不仅如此,LSTM既能解决RNN在训练时反向传播带来的“梯度消失”问题,又能够获得源代码中的语义关系.源程序中的包名、类名、方法名和变量名多以功能命名,因此不同层次中的语义信息与数据竞争息息相关.我们选取不同层次的文本特征,通过LSTM层,可以提取其中的语义关系[27],例如包含关系和上下文关系等,这有助于检测数据竞争,提高检测精度.
构建的CNN-LSTM神经网络架构如图4所示:

Fig. 4 CNN-LSTM deep neural network model图4 CNN-LSTM深度神经网络模型
训练网络时,首先将每对访问操作的特征信息输入到CNN-LSTM神经网络中,DeleRace的特征输入定义为
Input=〈Number_input,Text_input〉,
(3)
Number_input=〈numw,numh,numsm,numsb〉,
Text_input=〈textpa,textc,textm,textv〉,
其中,Input表示分类器的输入,Number_input表示数值信息的输入,numw,numh,numsm,numsb分别表示是否为写操作、Hash值、是否被同步方法包含和是否被同步块包含,Text_input表示文本信息的输入,此时输入的文本信息已经被向量化,textpa,textc,textm,textv分别为包名、类名、方法名和变量名.由于DeleRace的卷积和池化都采用了2维操作,因此用Reshape函数将数值向量的1维矩阵转化为2维,然后再将输入层的输出传入2维卷积层中进行自动学习,每个卷积层后都有一个最大池化层来降低特征维数,避免过拟合.函数Concatenate把CNN输出的卷积特征和和LSTM提取的时序特征融合到另一个全连接层进行二分类,并通过Dropout方法来防止过拟合,最终输出测试程序中含有数据竞争的个数.
2 实验结果与分析
本节首先对实验配置进行介绍;然后对DeleRace进行了实验评估,并对结果进行了分析;最后给出了DeleRace与传统的数据竞争检测工具的对比.
2.1 实验配置
硬件上,所有的实验都是在Dell Z820工作站上进行的,该工作站配备2个Intel Xeon处理器,主频为3.2 GHz,内存为8 GB.软件上,操作系统使用Windows 7 Professional,开发平台使用Jupyter NoteBook;使用Python3.6和Tensorflow1.9作为深度学习的运行支撑环境;程序分析工具使用WALA1.4.2,使用Eclipse 4.5.1作为WALA的运行平台,JDK版本为 1.8.0_31.
2.2 数据集描述
表3列出了构建DeleRace训练集的基准测试程序及其配置信息,这些基准程序主要来源于DaCapo[20],JGF[21],IBM Contest[22]基准测试程序套件.从表3中可以看出,DeleRace从16个训练程序中共提取了12 836个数据样本,由于数据集中正负样本分布不均衡,所以采用SMOTE算法对训练样本进行扩充,扩充后的训练样本数增长了近1倍,总数为25 438个.Lusearch是较大型的基准测试程序,其提取的训练样本数最多,达到了5 683个,经过SMOTE算法扩充后样本数增加到11 336个.对于Rax基准测试程序,最初只提取了23个训练样本,经过SMOTE扩充后训练样本增加到36个,是16个基准测试程序中所提训练样本最少的程序.对于其他基准测试程序,提取的训练样本数经过扩充后数量的范围在98~4 618.
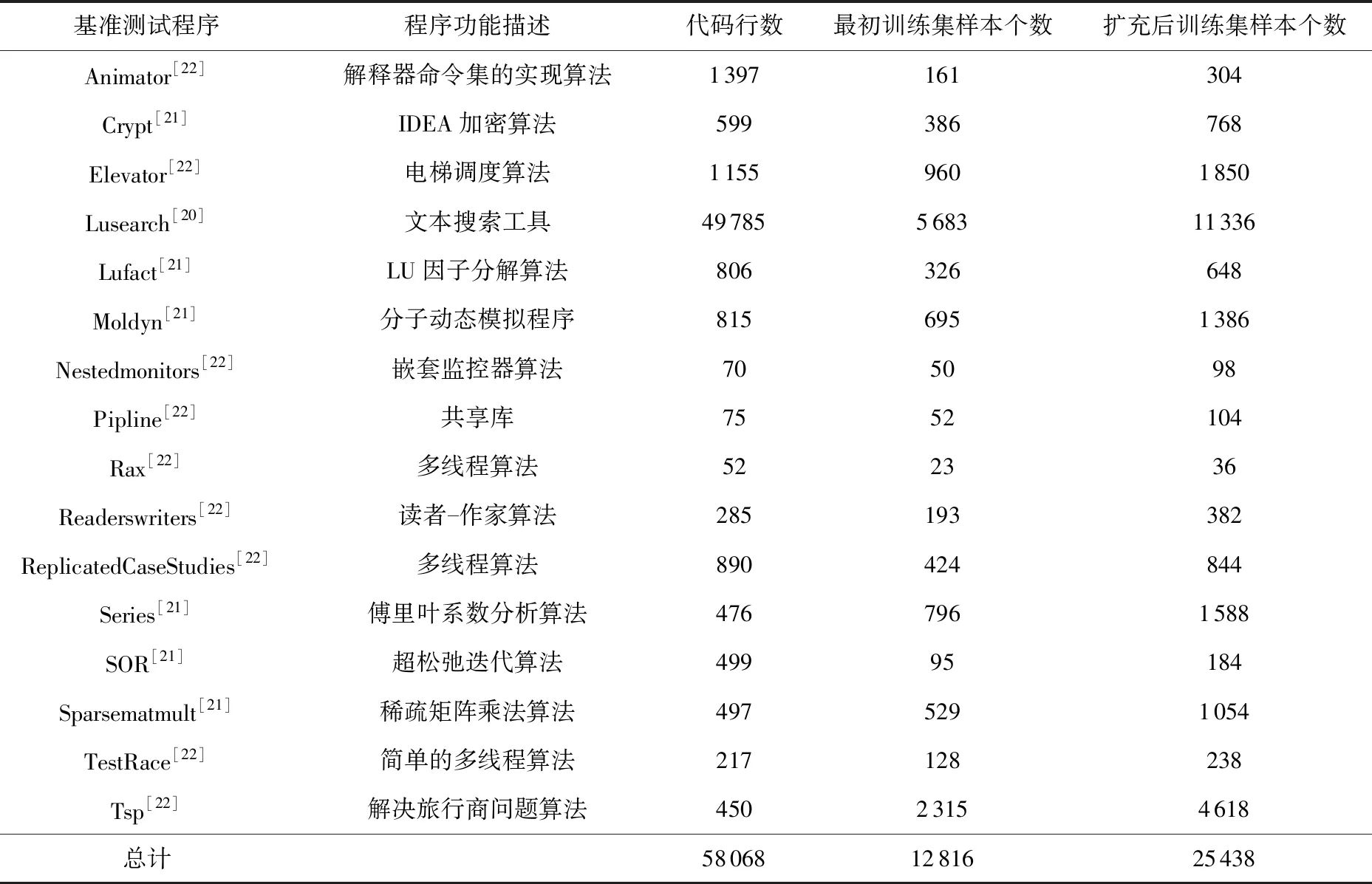
Table 3 Training Dataset表3 训练数据集
表4列出了构建DeleRace测试集的并发程序及其配置信息,这些测试程序主要来源于JGF[21],IBM Contest[22],PJBench[23]基准测试程序套件.在Account,AirlineTickets,Boundedbuffer等10个基准程序中提取数据样本作为DeleRace的测试集.表4中列出了这些测试程序及抽取的测试样本数,其中Boundedbuffer描述生产者-消费者算法,是所有测试程序中提取测试样本最多的程序,共提取599条测试样本;Critical是模拟双线程环境的测试程序,是所有基准程序中提取测试样本最少的程序,只有11条测试样本;其他测试程序的测试样本数在25~403.
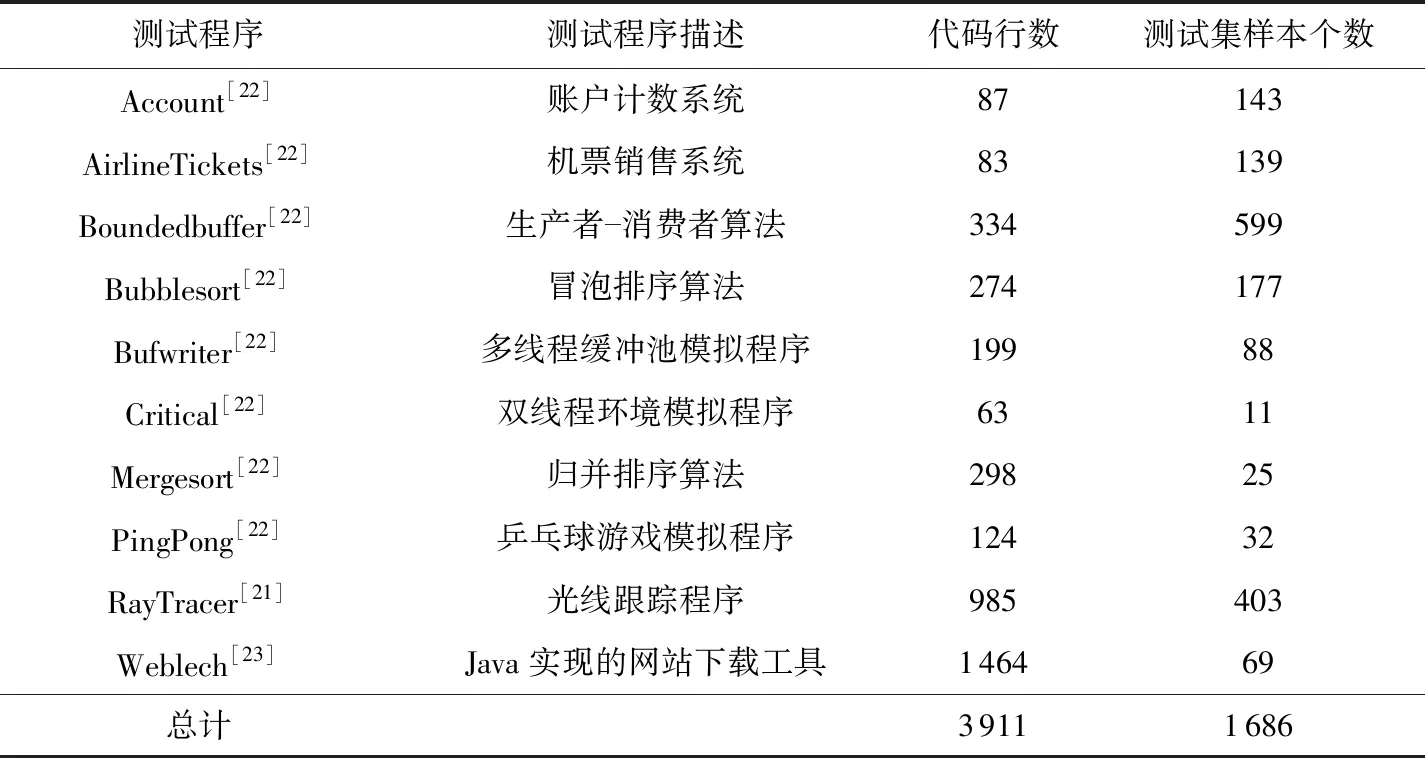
Table 4 Test Dataset表4 测试数据集
2.3 研究问题
在实验中,我们提出了6个研究问题(research question, RQ),通过回答这些问题对DeleRace方法进行评估.
RQ1:不同特征信息作为DeleRace输入信息对数据竞争检测结果有什么影响?如果只考虑几种特征输入信息,DeleRace的性能会如何?
RQ2:DeleRace是否能准确有效地检测出数据竞争?
RQ3:DeleRace是否优于现有的基于深度学习的数据竞争检测工具,与其他的深度神经网络相比,DeleRace的表现会如何?
RQ4:DeleRace是否优于传统的基于动态分析的数据竞争检测工具?
RQ5:DeleRace是否优于传统的基于静态分析的数据竞争检测工具?
RQ6:DeleRace在检测数据竞争时各部分时间性能表现如何?
RQ1关注的是不同特征信息对数据竞争检测结果的影响,通过比较部分特征信息和全部指令特征、方法特征和文件特征相结合的信息检测结果,以此来判断本文所提取的特征是否有效.
RQ2关注的是DeleRace在各个测试程序中准确率、精确率、召回率和F1值,以此来判断DeleRace是否可以准确测试出各个程序中是否含有数据竞争以及含有数据竞争的个数.
RQ3关注的是DeleRace与其他深度学习算法在检测数据竞争上的性能对比.我们选择现有的基于深度学习的数据竞争检测算法DeepRace[15]进行对比实验,并且与RNN和LSTM神经网络进行对比.
RQ4关注的是DeleRace与传统的基于动态程序分析工具在检测数据竞争上的性能对比.我们选择现有的基于动态分析的数据竞争检测算法Said和RVPredict进行对比实验.
RQ5关注的是DeleRace与传统的基于静态程序分析工具在检测数据竞争上的性能对比.我们选择现有的基于静态分析的数据竞争检测算法SRD和ConRacer进行对比实验.
RQ6关注的是DeleRace在检测数据竞争上的时间性能,针对测试数据集上10个开源程序,记录了DeleRace在整个检测数据竞争时的平均耗时情况.
2.4 模型评估指标
使用准确率、精确率、召回率、F1作为评价指标评估DeleRace的有效性.分类问题的混淆矩阵如表5所示,其中TP表示将正样本预测为正样本,FP表示将负样本预测为正样本,FN表示将正样本预测为负样本,TN表示将负样本预测为负样本.
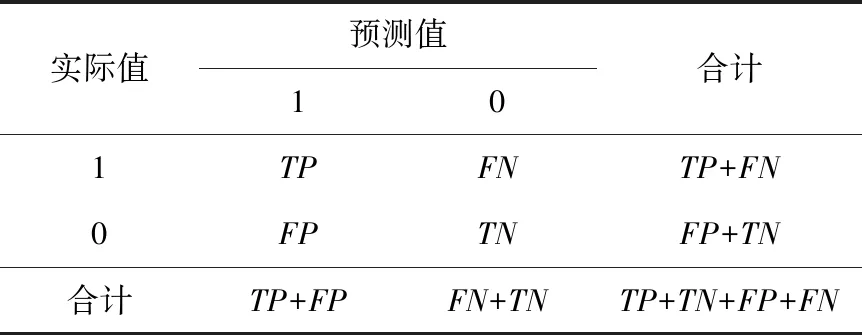
Table 5 Confusion Matrix of Binary Classification Problem表5 二分类问题的混淆矩阵
准确率(accuracy,ACC),表示预测正确的样本占测试集中所有样本的比例.
(4)
精确率(Precision),用于描述模型将正样本预测为正样本占测试集中实际预测为正样本的比例.
(5)
召回率(Recall),用于描述模型将正样本预测为正样本占测试集中实际预测正确的比例.
(6)
F1(F-Measure),用于描述精确率和召回率的加权调和平均.
(7)
精确率和召回率是相互影响的,通常情况下,精确率升高,召回率会随之下降,反之亦然.如果测试集中含有数据竞争的样本数量为0,则会得到值为1的召回率,但精确率却会很低,因此,F1用来权衡精确率和召回率之间的关系,其取值范围通常在[0,1]之间,F1值越大表示模型性能越好.
2.5 模型参数选择
为了回答RQ1,我们选择5个具有代表性的特征与本文所选择的8个特征进行对比,其对比结果如表6所示.首先研究特征提取的个数对于实验结果的影响情况,为此我们分别选择8个特征(见1.3节)和5个特征(包括访问指令的Hash值、是否含有读写操作、发生数据竞争的包名、类名以及方法名)的情况进行实验对比.实验结果如表6所示,其中 “DeleRace-5”代表在5个特征下深度学习模型的实验结果,“DeleRace-8”代表8个特征下深度学习模型的实验结果.从实验结果可以看出,在DeleRace-8情况下,无论是准确率、精确率、召回率还是F1都比DeleRace-5情况下要高,这表明选取8个特征进行实验比选取5个特征更能提高数据竞争的检测精度.这里我们没有对更多的特征个数进行实验,主要是因为这8个特征是依据数据竞争的产生条件提取出来的,已经可以充分表示数据竞争的相关特征.基于该实验结果,在对DeleRace模型进行训练时选择特征个数为8.
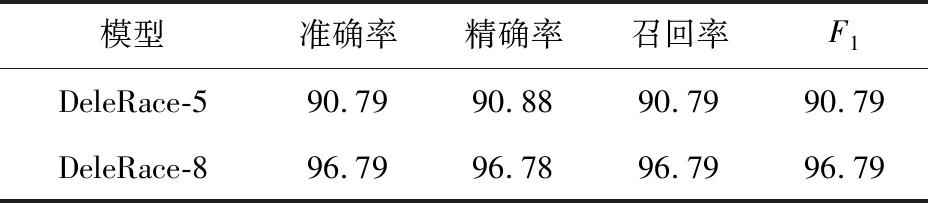
Table 6 Performance Comparison of Deep Neural Network Models with Different Feature Numbers表6 不同特征数量下深度神经网络模型的性能对比 %
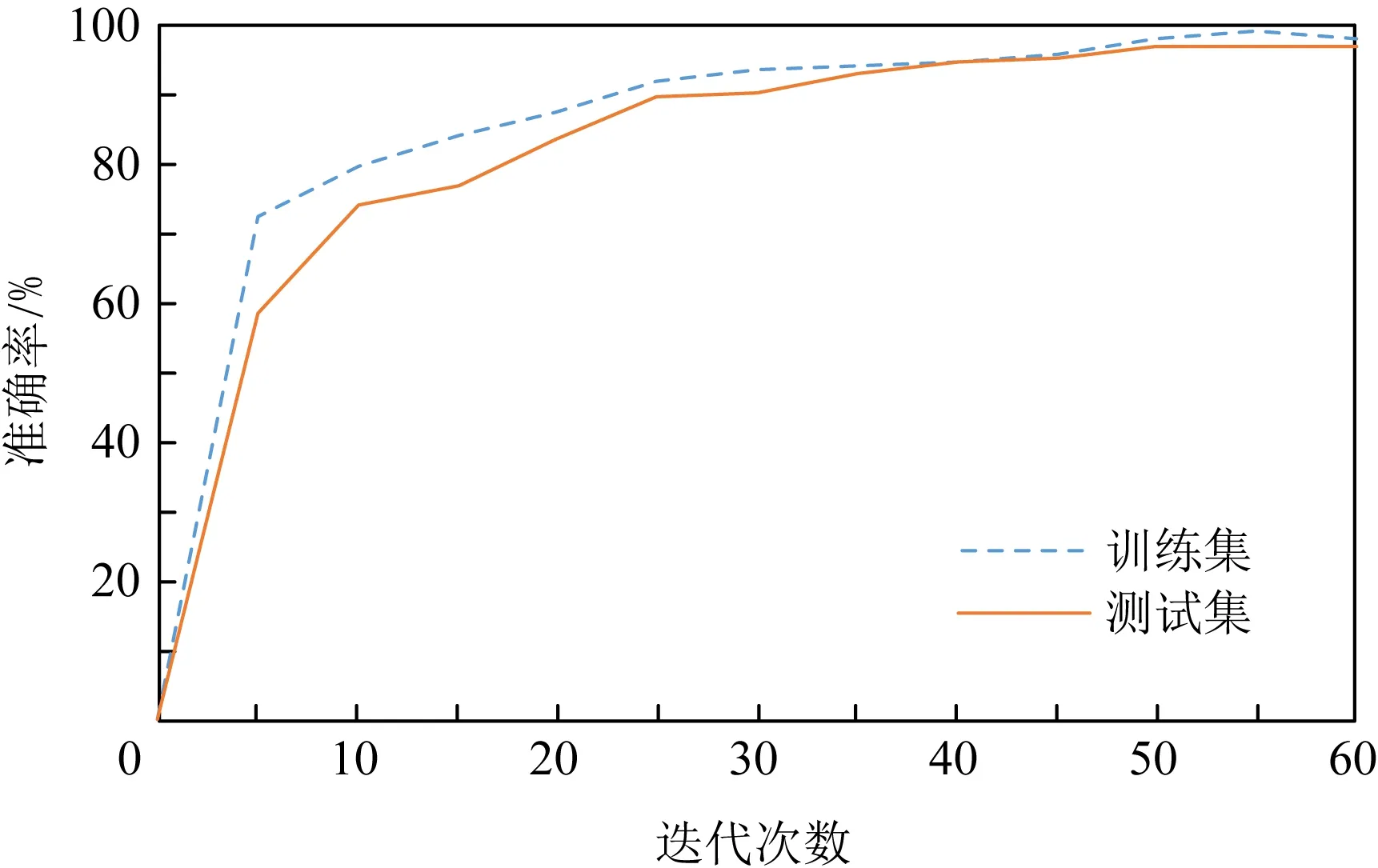
Fig. 5 The relationship between accuracy and iteration times for DeleRace图5 DeleRace准确率与迭代次数的关系
在不同特征数下DeleRace模型的训练过程中,我们还发现不仅特征提取的个数对分类精度有一定的影响,而且模型的迭代次数也会影响最终测试精度和训练时间开销.我们研究训练的迭代次数对于实验结果的影响情况,这主要基于2方面考虑:1)迭代次数过少可能会使检测精度降低;2)迭代次数过多虽然可以增加检测精度但会明显增加训练的时间开销.为了在检测精度和时间开销之间进行折中,我们通过实验确定相对合适的迭代次数,使其在提高模型检测精度的同时不会显著增加训练时间开销.图5给出了DeleRace随迭代次数的增加时训练和测试准确率的变化情况.从图5中可以看出,随着迭代次数的增加,准确率也会不断提高,当迭代次数增加到50时,准确率接近一个稳定值,即使迭代次数再增加准确率已不再有明显提升,因此在本实验中训练DeleRace模型的最佳迭代次数选择为50.
2.6 DeleRace检测结果
为了回答RQ2,我们选用表3中扩充后的25 438个数据样本作为DeleRace的训练集,选用表4中的10个基准测试程序所提取出的1 686个数据样本作为DeleRace的测试集,其检测结果如表7所示:
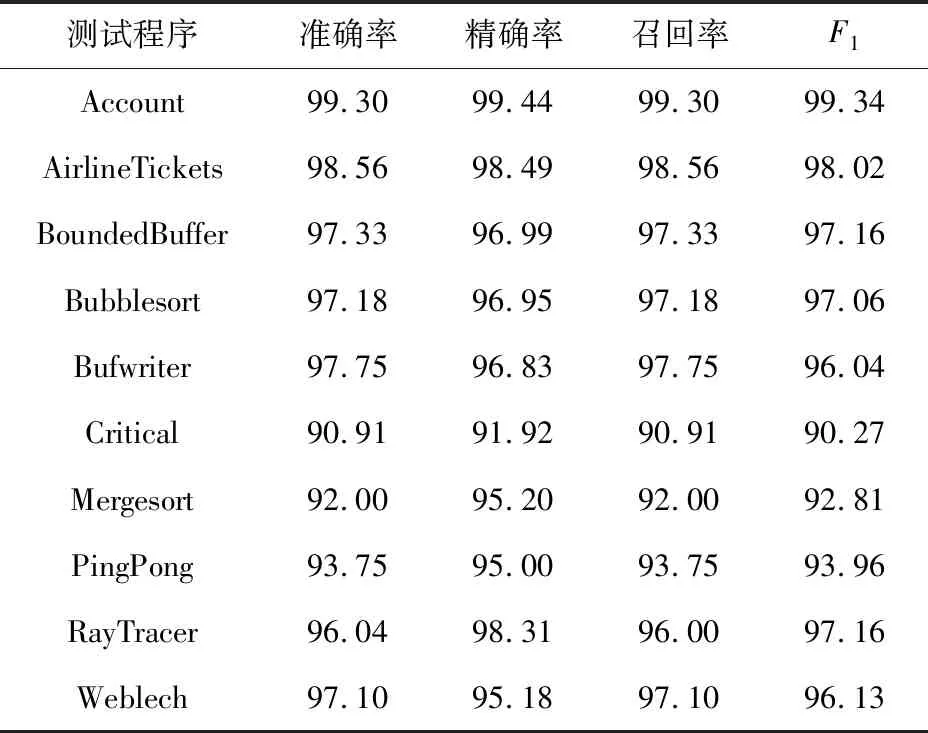
Table 7 Detection Results of DeleRace表7 DeleRace检测结果 %
由表7可知,整体上准确率范围在90.91%~99.30%,F1值在90.27%~99.34%.Account测试程序的准确率和F1值分别为99.30%和99.34%,其准确率、精确率、召回率和F1都是10个测试程序中最高的;而对于Critical基准测试程序,由于只提取了11个数据样本,其各个指标值都是10个基准测试中最低的,造成其性能较差的原因可能是因为含有的数据竞争数较少,进而提取的样本数也少,而深度学习模型的精度又与数据集大小有关,提供的数据集样本越多,效果越好,这可能导致Critical测试程序的检测精度偏低.
2.7 与其他深度神经网络方法对比
为了回答RQ3,我们将DeleRace与现有的基于深度学习的数据竞争检测工具DeepRace[15]进行对比,并与单独使用RNN或LSTM的神经网络性能进行比较,其实验对比结果如表8所示:

Table 8 Performance Comparison of Different Deep Neural Network Models表8 不同深度神经网络模型性能对比 %
DeepRace[15]是目前已有的基于深度学习的数据竞争检测工具,由于其数据集和模型均未开源,我们无法将其直接与本文方法DeleRace进行比较.为了进行比较,我们根据文献[15]中介绍的方法对其工作进行了复现.在比较时,DeleRace,RNN,LSTM,DeepRace都使用相同的训练集和测试集,遵循相同的过程和使用相同的工具来解析源代码和特征向量化,处理数据不平衡问题时也采用了相同的数据增强算法,在最大程度上保证了实验的公平性.与此同时,为了使我们的实验结果更为可靠,我们采用10倍交叉验证的方式来评估DeleRace,即将训练集和数据集混合为1份数据集,把整个数据集随机分成 10组,用其中9组作为训练集,另外1组作为测试集,重复这个过程,直到每组数据都作过测试集,我们取10次结果的平均值作为我们的最终结果.实验结果如表8所示.
从表8可以看出,DeleRace检测的准确率为96.79%,F1为96.79%,在4种方法中是最高的,准确率和F1分别比DeepRace高出约4.65%和4.67%,这表明本文方法DeleRace在检测数据竞争方面的性能优于DeepRace.此外,我们还将DeleRace与RNN和LSTM网络相比,在准确率方面,DeleRace比其他2种网络模型高出7%以上,DeleRace的F1值也比其他2种网络模型分别高出7.09%,8.23%.实验结果表明,无论是准确率还是F1,DeleRace均优于采用RNN神经网络、LSTM神经网络和DeepRace工具检测数据竞争的方法.
2.8 与动态数据竞争检测工具对比
为了回答RQ4,我们将DeleRace与现有的基于动态程序分析的的数据竞争检测工具Said[5]和RVPredict[6]进行对比,其实验对比结果如表9所示,其中R-races表示该程序实际的数据竞争数目.
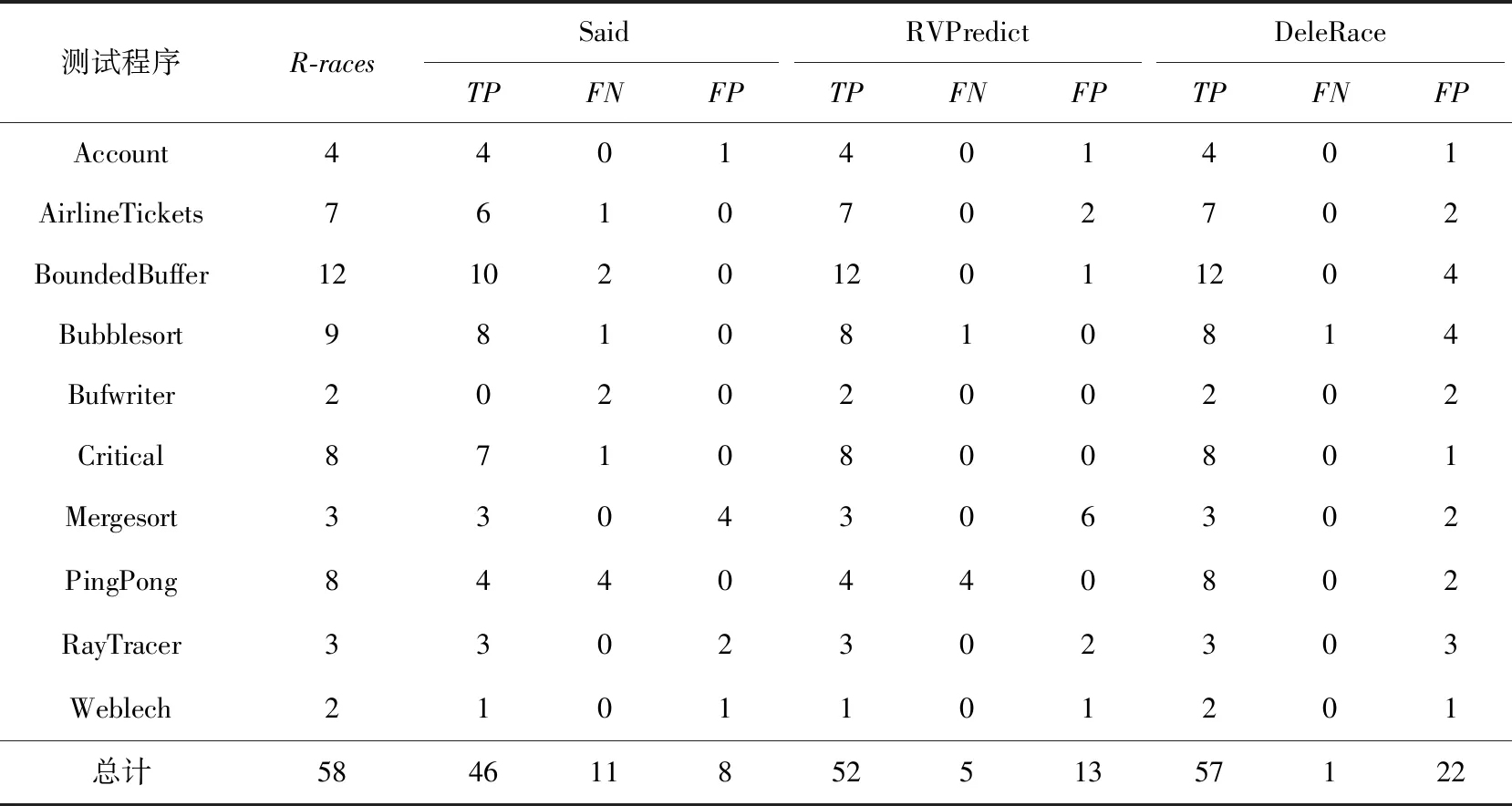
Table 9 Comparison of DeleRace and Dynamic Data Race Detection Tools表9 DeleRace与动态数据竞争检测工具的对比
从表9可以看出, Said检测到数据竞争总数为46个, RVPredict检测的总数为52个,而DeleRace检测到实际竞争的个数为57个,明显多于其他2种检测工具.对于测试程序AirlineTickets,BoundedBuffer,Bufwriter和Weblech,DeleRace检测到的实际竞争个数均多于Said检测到的数据竞争个数;对测试程序PingPong,DeleRace检测到的数据竞争个数比Said和RVPredict检测到的数据竞争个数多4个,并且使用DeleRace检测大部分程序的结果与实际竞争数#R-races是相同的, DeleRace最贴近真实竞争的个数.
在漏报方面,Said和RVPredict工具的漏报总数分别为11个和5个,而DeleRace的漏报总数为1个,相比较而言,DeleRace检测数据竞争时存在较少的漏报.在这些测试程序中,只有在检测Bubblesort测试程序时存在1个漏报,对于Said和RVPredict也同样存在1个漏报.漏报可能的原因是将某条标签为1的文本特征转化成数值向量时的单词相关性较低,从而导致其发生漏报.
尽管DeleRace检测的真实数据竞争个数较多且漏报较少,但在误报方面DeleRace与其他2个检测工具相比还存在一定的差距.总体来说,Said和RVPredict分别只有8个和13个误报,但是DeleRace的误报数却有22个.在这些程序中,误报较多的是BoundedBuffer和Bubblesort测试程序,造成误报的原因可能是在提取数据样本时标签为“0”的数据样本过多而标签为“1”的数据样本过少,造成了数据分布不均衡,尽管我们使用了SMOTE数据增强算法,使数据样本达到了平衡,但还是不可避免地造成了一些误报.DeleRace在误报方面的不足,将驱使我们进一步完善该方法.
2.9 与静态数据竞争检测工具对比
为了回答RQ5,我们将DeleRace与现有的基于静态程序分析的的数据竞争检测工具SRD[5]和ConRacer[17]进行对比,其实验对比结果如表10所示.
从表10可以看出,DeleRace检测到的数据竞争总数比SRD检测到的个数多17个,漏报个数比SRD少15个,在误报方面虽然与SRD相等,但总体而言,DeleRace的性能是优于静态数据竞争工具SRD的.
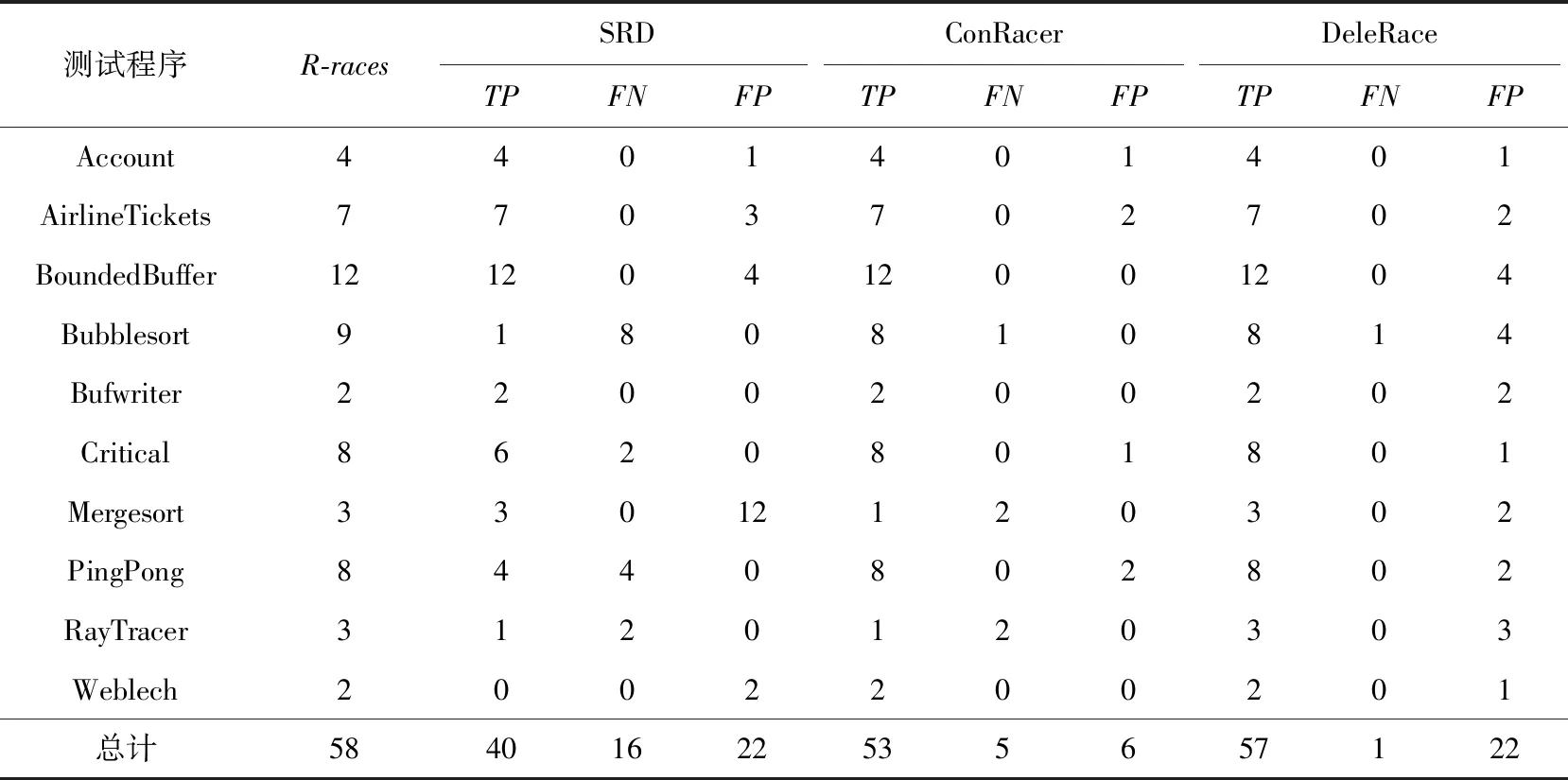
Table 10 Comparison of DeleRace and Static Data Race Detection Tools表10 DeleRace与静态数据竞争检测工具的对比
我们还将DeleRace与ConRacer进行了对比.对于检测到的实际竞争个数,DeleRace所检测到的个数为57个,而ConRacer是53个,本文方法DeleRace比ConRacer所检测到的个数多4个.漏报方面,本文方法DeleRace比ConRacer的漏报个数少4个.尽管DeleRace检测的真实数据竞争个数较多且漏报较少,但在误报方面DeleRace与ConRacer相比依旧存在一些差距,ConRacer的误报个数仅为6个,但本文方法DeleRace却为22个,造成误报较多的原因在2.8节已经进行了说明.我们计划在下一步的工作中进行改进.
虽然ConRacer工具检测到的实际竞争个数比本文方法DeleRace少,且漏报个数比DeleRace多,但与本文所提到的Said,RVPredict和SRD这3种基于程序分析的数据竞争检测方法相比,ConRacer不仅检测到的实际竞争个数最多,而且误报和漏报均最少,因此ConRacer依旧是较好的检测工具.针对判定时所出现的误报和漏报情况,我们对标记情况进行了手动验证,以保证数据集的正确性.
2.10 时间性能评估
对于回答RQ6,我们评估了DeleRace在检测数据竞争时的时间性能.表11记录了DeleRace检测数据竞争的整体耗时情况,总时长为3 657.14 s,其中耗时最久的步骤是深度神经网络模型的训练时间,共耗时3 492.42 s,占据整体检测时长的95%,主要原因是神经网络的时间复杂度和空间复杂度都会对模型的训练时间产生影响,如果复杂度过高,很容易导致模型在训练过程中消耗过多的时间,而DeleRace采用了3个卷积层和1个LSTM层处理数据,获得了不同的特征并加以合并,层数深且操作过程较为复杂,并且迭代次数过多也会使得训练时间过长,因此在训练模型过程中花费时间较多,耗时比例较高.
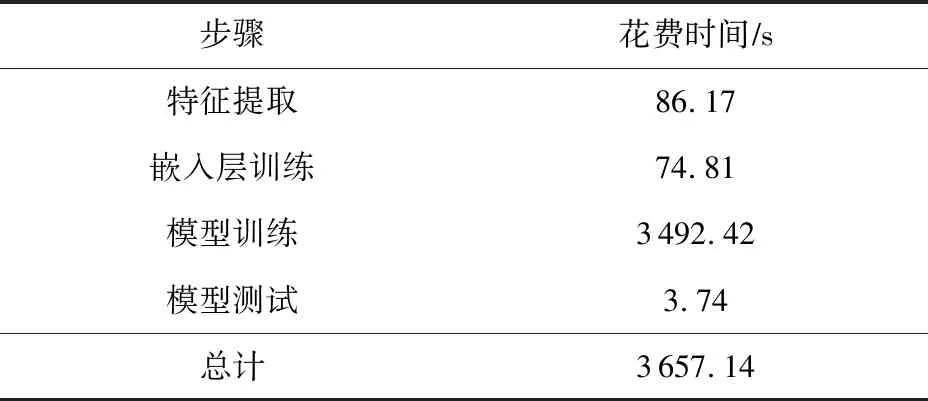
Table 11 The Time of Each Step in DeleRace表11 DeleRace完成各个步骤所花费的时间
2.11 有效性威胁
本节对实验过程中威胁有效性的4个因素进行了讨论.
1) 本文仅选择来自DaCapo,JGF,IBM Contest,PJBench这4个基准测试组件中的并发程序,从这些程序中提取的数据竞争数据集并不能代表所有程序,因为不同程序可能展现不同的数据样本.为了缓解这个有效性威胁,我们选择了26个测试程序,这些程序分别来自不同领域,尽可能保证数据集来源的多样性.
2) 我们在对训练数据集进行标记时采用了ConRacer工具,尽管该工具采用了上下文敏感的程序分析方法,可以有效地报告数据竞争,但该工具仍存在误报和漏报的情况.为了解决这一问题,我们对报告的数据竞争采用手动的方式检查数据竞争位置的代码,尽可能地排除误报和漏报,最大程度上保证了数据集的准确性.
3) 将文本特征转化为数值向量时,转化相似度的高低会影响最终结果的精度.本文采用Keras中的嵌入层进行文本向量化,通过对Keras的嵌入层进行训练并对其参数进行调节使其转化准确率可达98.7%,虽然没有达到100%的准确率,但通过该技术转化的数值向量已经在很大程度上接近数据竞争的文本特征,有效减少了文本向量化对最终结果的影响.
4) 在数据增强时我们选择的算法会对训练的最终效果有一定的影响.本文选择的SMOTE算法是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,容易使模型过拟合,而SMOTE算法采用KNN技术生成新样本[28-29],通过计算每个少数类样本的K个近邻,并从中随机挑选N个样本进行随机线性插值,最终构造新的少数类样本.因此使用SMOTE算法增加正样本个数,在扩充训练集时有效减小数据增强对模型训练的影响.
3 相关工作
数据竞争检测的相关研究仍是目前研究的热点内容之一,所采用的方法有很多,目前可分为基于程序分析的数据竞争检测方法以及基于机器学习和深度学习的数据竞争检测方法.基于程序分析的数据竞争检测方法通常又分为动态检测、静态检测和动静结合的检测方法.
动态检测通过运行源程序时插桩等方法获取并记录程序运行时状态.Said等人[5]提出了一种基于SMT解算器的符号分析方法,可以有效地分析线程调度,准确定位数据竞争.RVPredict[6]将数据竞争检测作为约束求解问题,利用可满足性模理论(satisfiability modulo theories, SMT)求解器查找数据竞争.SlimFast[7]通过减少数据冗余、内存使用和运行时间来检测数据竞争并提高检测效率.
静态方法是基于静态源代码分析,通过程序验证或符号执行的方式分析源码语义或者程序控制流.RELAY[8]是一种基于流敏感和过程间分析的静态数据竞争检测工具.Elmas[9]是基于模型检测理论提出的一种检测方法,通过对程序中锁操作路径进行分析并通过发生序关系过滤结果.SRD[10]采用程序切片技术静态判断访问事件之间的发生序关系并结合别名分析等静态分析技术检测数据竞争.
动静结合的检测方法是先静态找出所有可能的数据竞争,再利用动态分析检测程序.RaceTracker[11]采用动静结合的检测方法,首先使用当前的静态检测器来产生潜在的竞争,然后潜在竞争的代码位置进行插桩来识别数据竞争.AsampleLock[12]是基于优化的FastTrack[30]算法和锁模式的动态混合数据竞争检测算法,利用采样技术监控同一时刻同时运行的并发线程函数对,再通过预竞争检测获得真正的数据竞争的内存访问对.
有些研究人员开始使用机器学习和深度学习方法来检测数据竞争.Tehrani等人[15]提出基于深度学习的数据竞争检测工具DeepRace,首先通过变异分析生成特定的数据竞争类型,再通过为每个源文件生成AST构造数据集,最后将向量化的数值输入到CNN中进行训练,其检测准确率在83%~86%.孙家泽等人提出了AIRaceTest[13]和ADR[14]检测数据竞争工具,AIRaceTest是基于随机森林的数据竞争指令级的检测工具,首先基于HB关系和Lockset算法指令级检测数据竞争,并利用其分析结果训练数据竞争随机森林检测模型,模型精度为92%.ADR是基于Adaboost模型的数据竞争语句级检测工具,将插桩得到的指令内存信息进行语句级转化,提取出相关特征后构建Adaboost数据竞争检测模型.与AIRaceTest和DeepRace相比,DeleRace通过提取多个特征,模型性能更好,准确率也更高.
4 总 结
本文提出一种基于深度学习的数据竞争检测方法,该方法首先利用WALA工具从多个实际应用程序中提取指令、方法和文件等级别的多个特征,对其向量化并构造训练样本数据,通过ConRacer工具对真实数据竞争进行判定进而标记样本数据,采用SMOTE增强算法使数据样本均衡化,最后构建并训练CNN-LSTM深度神经网络实现对数据竞争的检测.在实验中选取10个基准测试程序验证了该方法的有效性,结果表明DeleRace的数据竞争检测准确率为96.79%,高于目前已有的基于深度学习的检测方法.此外,我们将DeleRace与已有的动态数据竞争检测工具(Said和RVPredict)和静态数据竞争检测工具(SRD和ConRacer)进行比较,验证了本文方法的有效性.
进一步的研究工作包括:1)针对本文方法误报较多的问题,将在未来的工作中通过扩大训练数据集、增加含有数据竞争的标签样本和采用更多软件分析等方法减少误报,并且选取更多的基准测试程序对模型进行训练,提高工具的普适性;2)本文使用CNN-LSTM的神经网络来对数据竞争进行检测,虽然准确率可达96.79%,但仍有可提升的空间,我们将继续尝试对深度学习模型进行优化,进一步提高检测精度.
作者贡献声明:张杨负责论文想法的提出、方法设计、实验指导、数据整理与分析、论文的写作与修改;乔柳负责实验设计与探究、深度学习模型实现、实验数据整理与分析、论文的写作与修改;东春浩负责深度学习模型实现、部分实验数据整理、论文的修改;高鸿斌指导实验和论文的修改.
