基于互学习的多词向量融合情感分类框架
2022-09-05曹柳文周艳艳邬昌兴黄兆华
曹柳文,周艳艳,邬昌兴,黄兆华
(1. 华东交通大学 软件学院,江西 南昌 330013;2. 江西卫生职业学院,江西 南昌 330052)
0 引言
情感分类旨在自动判断给定文本的情感倾向,是自然语言处理领域的热点问题之一。情感分类的结果有利于信息检索、产品推荐和智能客服等众多上层自然语言处理应用。依据情感分类对象粒度的不同,情感分类可以分为篇章级情感分类、句子级情感分类和方面级情感分类[1]。方面级情感分类(Aspect-level Sentiment Classification,ASC)旨在判断文本中特定方面的情感极性。例如,在句子“这款电脑的外观很时尚,但散热并不理想”中,关于“外观”和“散热”这两个方面的情感分别为“正向情感”和“负向情感”。方面级情感分类能够为上层应用提供更细粒度的情感信息,受到学术界和工业界越来越多的关注。
基于深度学习的方面级情感分类方法是目前主流的方法[2],取得了较好的识别性能。这类方法通常以词向量作为输入,基于注意力等机制[3]建模特定方面与其所在的上下文之间的关系,以学习与特定方面相关的特征用于情感分类。研究人员提出了大量用于建模特定方面与上下文之间关系的神经网络模型。例如,Zhang等[4]基于句子的依存树构建图神经网络,以有效地利用依存句法树中词之间的依赖关系。Xu等[5]基于结构化的注意力机制有效提取与特定方面相关的上下文信息。有些研究人员则探讨了作为输入的词向量对情感分类的影响。例如,Tang等[6]指出,在普通词向量中,具有相反情感倾向的词,如“good”和“bad”通常表示为相似的向量,这并不利于情感分类。因此,他们收集大量基于表情符号自然标注的评论来学习情感词向量,以代替普通词向量作为模型的输入,在Twitter数据集上获得了明显的性能提升。Cai和Wan[7]首先基于领域分类任务学习特定于领域的词向量,然后拼接普通词向量和领域词向量用于情感分类,在16个不同领域的数据集上取得了较好的分类效果。Xu等[8]拼接普通词向量和领域词向量作为CNN模型的输入,用于评论文本中的方面抽取任务,在多个数据集上取得了当时最好的效果。上述研究工作充分证明,联合使用多种词向量可以有效地提升情感分析的效果。
现有通过直接拼接[7-8]、门控机制或注意力机制[9]等融合多种词向量的方法可以在一定程度上提高模型的性能。然而,这些方法通常把多种含有不同信息的词向量融合在一起作为模型的输入,在一定程度上会造成词向量特性的丢失,因而不能充分发挥每种词向量的作用。
为了解决上述问题,本文提出一种基于互学习的多词向量融合情感分类框架,以充分利用普通词向量、领域词向量和情感词向量信息,从而提高方面级情感分类的性能。具体地,我们首先构建一个主模型,该模型以三种词向量的融合作为输入;然后,构建三个独立的辅助模型,分别以其中一种词向量作为输入,以充分利用普通词向量中含有的通用信息、领域词向量中含有的领域信息和情感词向量中含有的情感信息;最后,联合训练上述主模型和辅助模型,通过互学习的方式在它们之间传递知识,从而达到相互促进的效果。也就是说,辅助模型专注于利用对应词向量的特性,并在主模型的帮助下充分激发对应词向量的潜能(通过尽可能地模拟主模型的输出);主模型则通过吸收辅助模型学到的知识,以达到更好的识别性能。本文提出的框架可以与大多数现有融合多种词向量的方法(主模型中)一起使用,以进一步充分利用多种含有不同信息的词向量。值得说明的是,本文提出的框架虽然增加了模型训练的时间开销,但不会增加模型应用的时间开销(只需要主模型)。
在常用的方面级情感分类数据集上的实验结果表明,本文提出的基于互学习的多词向量融合情感分类框架的性能显著好于同类基准方法。
1 相关工作
本文工作主要与方面级情感分类、多词向量融合和知识蒸馏三个方面的研究工作相关,下面分别进行介绍。
近年来,研究人员提出了大量基于注意力机制[3]的深度学习模型,在方面级情感分类(ASC)上取得了较大的成功。例如,Tang等[10]和Wang等[11]把注意力机制和记忆网络相结合用于ASC。Wang等[12]和Ma等[13]基于LSTM计算词在上下文中的表示,然后利用注意力机制找出与给定方面关联度较高的词。He等[14]把句法信息融入注意力机制中,从而更有效地提取与给定方面相关的上下文。孙等[15]和杜等[16]分别把多头注意力机制和螺旋注意力机制用于ASC。Tang等[17]自动挖掘文本中的监督信息以学习更好的注意力机制。另一些研究人员提出基于交互的机制,代替注意力机制用于ASC,也取得了较好的效果。例如,Xue和Li[18]使用门控卷积神经网络直接建模给定方面与文本之间的关系。Li等[19]提出一种方面敏感的文本转换网络模型。Lei等[20]使用词级别的交互感知模块构建ASC模型。针对方面级情感分类标注数据比较少的问题,还有一些研究人员探索了如何利用外部知识或句子级/文档级情感标注数据的方法。例如,Ma等[21]通过扩展的LSTM集成外部知识库中与情感相关的知识用于ASC。He等[22]设计了一种信息传递机制,用于在多个情感分析相关任务之间共享信息,其中包括文档级的情感分类任务。Zhou等[23]提出了一种层次化的知识迁移机制,以利用大量的句子级/文档级的情感标注数据。与上述方法不同,本文研究如何充分有效地利用多种词向量信息,以提高方面级情感分类的性能,提出的框架可以较容易地与现有模型结合在一起使用。
大量研究工作证实,基于不同方法或不同语料训练得到的词向量含有的信息可以互补,融合多种词向量信息往往能实质性地提高模型的性能。例如,Yin和Schütze[24]基于拼接等方式融合多种预训练好的词向量得到词的元向量表示(Word Meta Embedding),用于词性标注等任务取得了较好的效果。Coates和Bollegala[25]发现算术平均多个词向量的效果也很好。Bao和Bollegala[26]基于自编码神经网络学习词的元向量表示。Kiela等[9]把上下文信息引入注意力机制或门控机制中,用于动态地计算每种词向量的权重,然后加权求和多种词向量用作模型的输入。与上述方法不同,本文提出一种基于互学习融合多种词向量的框架,主要优点是可以充分发挥每种词向量的优势。
知识蒸馏(Knowledge Distillation)广泛应用于自然语言处理和计算机视觉中,能实现多个模型之间的知识迁移。最初,Hinton等[27]通过知识蒸馏的方式把参数较多的教师模型中的知识迁移到参数较少的学生模型中,以达到模型压缩的目的。随后,Zhang等[28]突破“教师-学生”的模式,提出一种互学习方法,在多个模型之间通过知识的双向蒸馏,以达到相互促进的目的。最近,Xue等[29]把互学习与对抗学习相结合,用于跨领域的情感分类。Liao等[30]扩展互学习方法,在多个机器翻译模型的词级别层间和句子级别层间迁移知识。本文提出一种基于互学习的多词向量融合框架,在方面级情感分类上取得了较好的性能。
2 基于互学习的多词向量融合情感分类框架
如图1所示,基于互学习的多词向量融合情感分类框架包括一个主模型和三个辅助模型。主模型以普通词向量、领域词向量和情感词向量的融合作为输入,三个辅助模型则分别以三种词向量作为输入。基于互学习的方式,同时训练上述主模型和辅助模型,以达到相互促进的目的。框架的核心是双向的知识迁移: ①多个辅助模型到主模型的知识迁移,如图中实线所示; ②主模型到每个辅助模型的知识迁移,如图中虚线所示。原始的互学习方法[28]认为,同一任务的不同模型学到的知识是不同的,因此,可以基于它们输出的预测标签互相学习。从某种角度看,这也可认为是预测标签间的相互约束。不同的模型可以是结构不同的模型或初始化参数不同的模型等。本文分别使用三种不同的词向量及其融合作为输入,以进一步保证辅助模型和主模型学到不同的知识,从而提高互学习的效果。
该框架的优势包括以下四点: ①相对独立的辅助模型充分保留了每种词向量的特性; ②在互学习框架下,每个辅助模型尽可能地模仿主模型的输出,这可以进一步挖掘每种词向量的潜力; ③主模型通过吸收来自多个辅助模型的知识,可以取得更好的分类性能; ④适用性较强,不依赖于具体的方面级情感分类模型。
下面分别介绍主模型和辅助模型、双向知识迁移及联合训练算法。
2.1 主模型和辅助模型
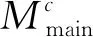
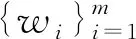
多词向量融合层首先把输入文本和方面中词的三种向量表示融合在一起,如式(1)所示。
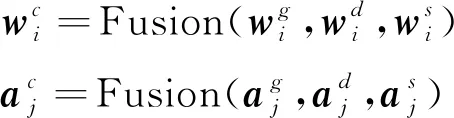
(1)
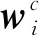
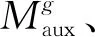
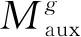
2.2 双向知识迁移
基于互学习的方式联合训练主模型和三个辅助模型,以达到相互促进的目的,其核心是主模型和辅助模型之间双向的知识迁移。
为了把辅助模型学到的知识迁移到主模型中,在训练时,要求主模型既拟合训练数据,又参考辅助模型输出的预测结果。为此,定义主模型的代价函数为J(θc)如式(4)所示。
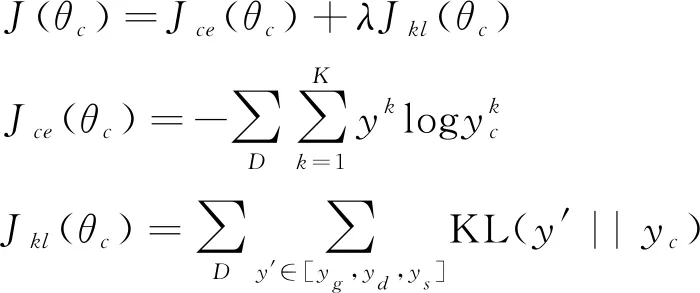
(4)

类似地,为了把主模型中的知识迁移到辅助模型中,在训练时,要求每个辅助模型在拟合训练数据的同时,尽可能地拟合主模型的预测结果。为此,分别定义三个辅助模型的代价函数为如式(5)所示。
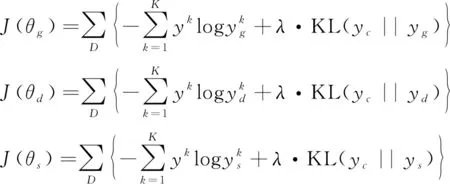
(5)
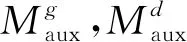
通过双向的知识迁移可以实现: ①主模型逐步吸收来自辅助模型的知识,以达到更好的分类性能; ②辅助模型不断挖掘每种词向量的潜力(通过尽可能地模仿主模型),分类性能也随之提高。也就是说,主模型和辅助模型可以相互促进。需要说明的是,三种不同词向量的信息有效地融合在整个主模型中,而不仅仅是主模型的Fusion层。
2.3 联合训练算法
算法1描述了基于互学习的多词向量融合情感分类框架的训练过程。主模型和三个辅助模型同时训练,分别基于各自的代价函数进行优化。需要说明的是,并不需要一个总的代价函数引导所有模型的训练。当有多个GPU设备可用时,可以并行训练,从而节省训练所需的时间。

算法1 联合训练算法输入: 训练数据集D,三种词向量,最大训练轮数N输出: 训练好的主模型1. 构建主模型和三个辅助模型2. 重复以下步骤: 3. 重复以下步骤: 4. 从训练数据集D中取出一批实例{(s,a,y)}5. 计算主模型的输出yc6. 分别计算辅助模型的输出yg、yd和ys7. 最小化主模型代价函数J(θc),更新参数θc8. 最小化辅助模型代价函数J(θg),更新参数θg9. 最小化辅助模型代价函数J(θd),更新参数θd10. 最小化辅助模型代价函数J(θs),更新参数θs11. 直到: 该轮训练结束12. 直到: 模型收敛或达到最大训练轮数N
3 方面级情感分类模型
理论上,任何可用于方面级情感分类的神经网络模型都可用作上一节提出框架中的主模型和辅助模型。


图2 TNet模型
为了验证所提框架的通用性,实验中还基于Zhang等[4]提出的ASGCN模型进行验证。ASGCN模型首先使用BiLSTM建模句子中词的上下文信息;然后,基于依存句法树和GCN(图卷积神经网络)[31]捕获方面中的词与句子中其他词之间长距离的依赖关系;最后,基于注意力机制得到与方面相关的句子表示用于情感分类。ASGCN模型的详细介绍可参见文献[4]。
4 实验

4.1 数据集
数据集Laptop、Restaurant和Twitter的统计情况如表1所示。Laptop和Restaurant数据集分别来源于SemEval ABSA挑战赛[32]提供的相应领域的评论;Twitter数据集来源于Dong等[33]收集的评论。随机选取训练集中10%的实例作为验证集,取验证集上效果最好的模型用于测试。
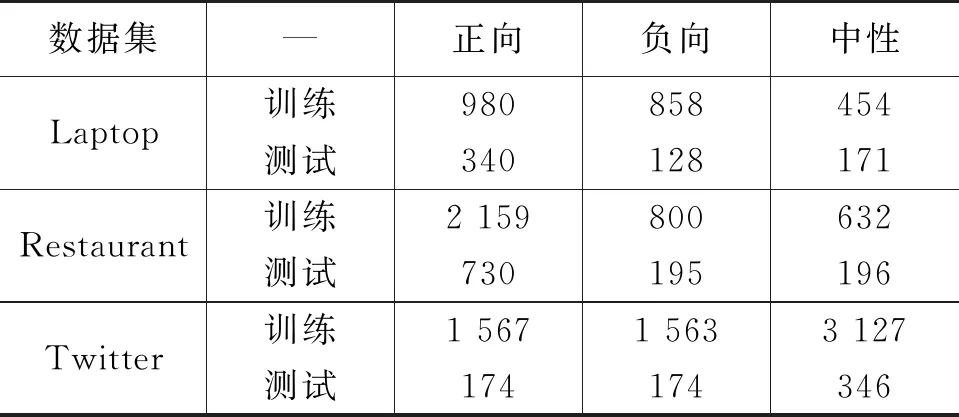
表1 实验数据统计情况
4.2 参数设置
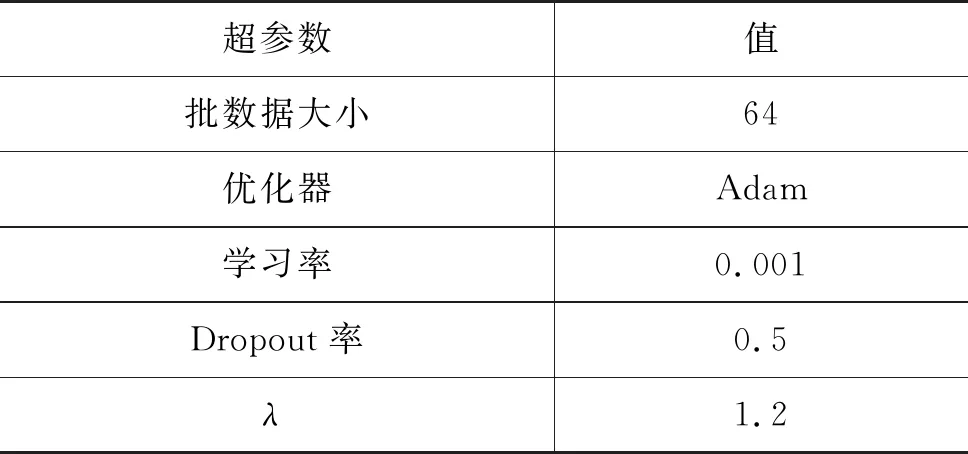
基于验证集上的最优性能选择模型中超参数的取值,如表2所示。TNet和ASGCN模型中涉及的超参数使用对应文献中建议的值。为了缓解过拟合问题,在输入的词向量上使用dropout技术[34]。

表2 超参数的值
续表
4.3 词向量
对于普通词向量,我们使用300维的GloVe词向量[35]。为了得到领域词向量和情感词向量,我们从亚马逊评论数据集[36]中抽取了约100万条与Laptop领域相关的评论,从Yelp Review Dataset(2)https://www.yelp.com/dataset/中抽取了约59万条Restaurant领域的评论,从Twitter Dataset(3)https://help.sentiment140.com/中抽取了约150万条Twitter领域的评论。这些评论都带有句子级的情感类别标记。使用fasttext[37]模型基于上述三个领域的语料分别训练相应的领域词向量,使用Wu等[38]提出的基于词向量平均的分类模型分别训练相应的情感词向量(4)文献[6]已经证实基于情感分类任务训练出来的词向量中含有丰富的情感信息。我们使用文献[39]中基于词向量平均的分类模型学习情感词向量的原因有: a)该模型非常简单; b)基于简单的模型执行情感分类任务更有利于把情感信息融入词向量中,而不是分类模型的其他参数中。。
使用余弦相似度计算词向量之间的相似性,并在表3中分别列出了三种词向量中与词fast(快)最接近的10个词。一般认为,词向量相近的两个词,其语义也相近。从中可以看出以下几点: ①普通词向量中,与词fast(快)相近的词中既包括情感极性相同的词,例如faster(更快)和quick(快);也包括与其情感极性相反的词,例如slow(慢)和slower(更慢)。这对情感分析模型来说是非常不利的。②Laptop领域词向量中,与词fast(快)相近的词具有较明显的领域特性,例如,amazingly(惊讶地)和keyboard response(键盘反应速度)。③Laptop情感词向量中,与词fast(快)相近的词基本上都是情感极性相同的词,而没有出现与其情感极性相反的词,这显然有利于情感分析模型。从以上分析可知,普通词向量、领域词向量和情感词向量中含有不同的信息,有效地融合这三种词向量可以潜在地提高情感分析模型的性能。
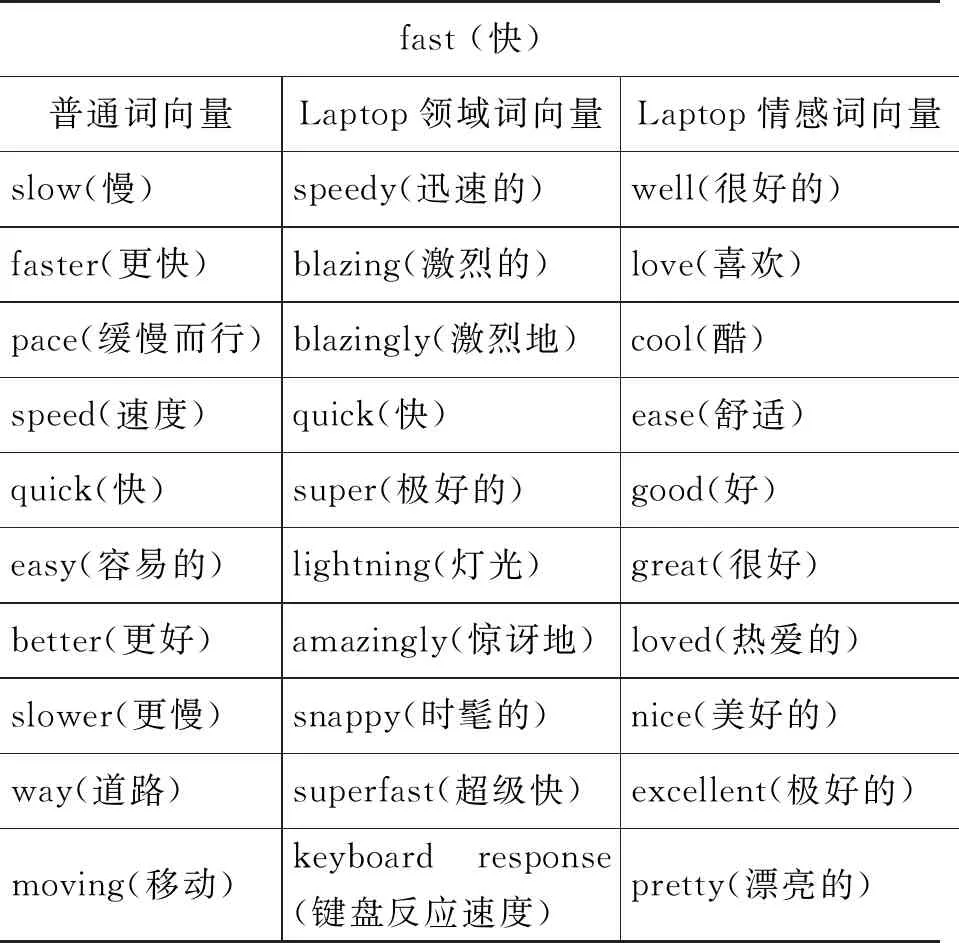
表3 三种词向量中与词fast(快)最接近的10个词
实验中使用预训练好的词向量作为输入,且不再进一步优化这些词向量。为了验证优化词向量是否可以进一步提高性能,我们尝试在训练的过程中更新词向量,但实验结果反而变差了。这一实验现象也与文献[8]中描述的一致。可能的原因有以下两点: ①更新词向量导致多个辅助模型的预测结果趋于一致,这对所提基于互学习的框架是不利的; ②如文献[8]所述,方面级情感分类数据集通常比较小,训练时只能更新很少一部分词向量(训练集中出现的词),而大部分未出现词的向量并没有更新,这对模型的泛化性能有较大的影响。
4.4 实验结果
为了验证所提框架在方面级情感分类任务上的有效性,我们首先以TNet模型为基础进行实验,并与以下基准方法进行对比:
TD-LSTM[39]: 使用两个LSTM分别建模特定方面左边和右边的上下文信息,拼接后用于情感分类。
MemNet[40]: 基于多跳(multi-hop)记忆网络模型,学习特定方面相关的句子表示用于分类。
RAM[41]: 采用多层注意力机制计算句子中与特定方面相关文本的语义表示用于分类。
IAN[42]: 利用两个LSTM分别学习特定方面和句子的语义表示,同时考虑了二者之间信息的交互。
HSCN[20]: 设计了三种神经网络模块用来模拟人类三阶段的阅读认知过程,以建模更深层次的语义表示。
PAHT[23]: 从多个角度建模位置信息,同时将句子级情感模型中的知识迁移到方面级情感分类模型中,以缓解训练语料的不足。
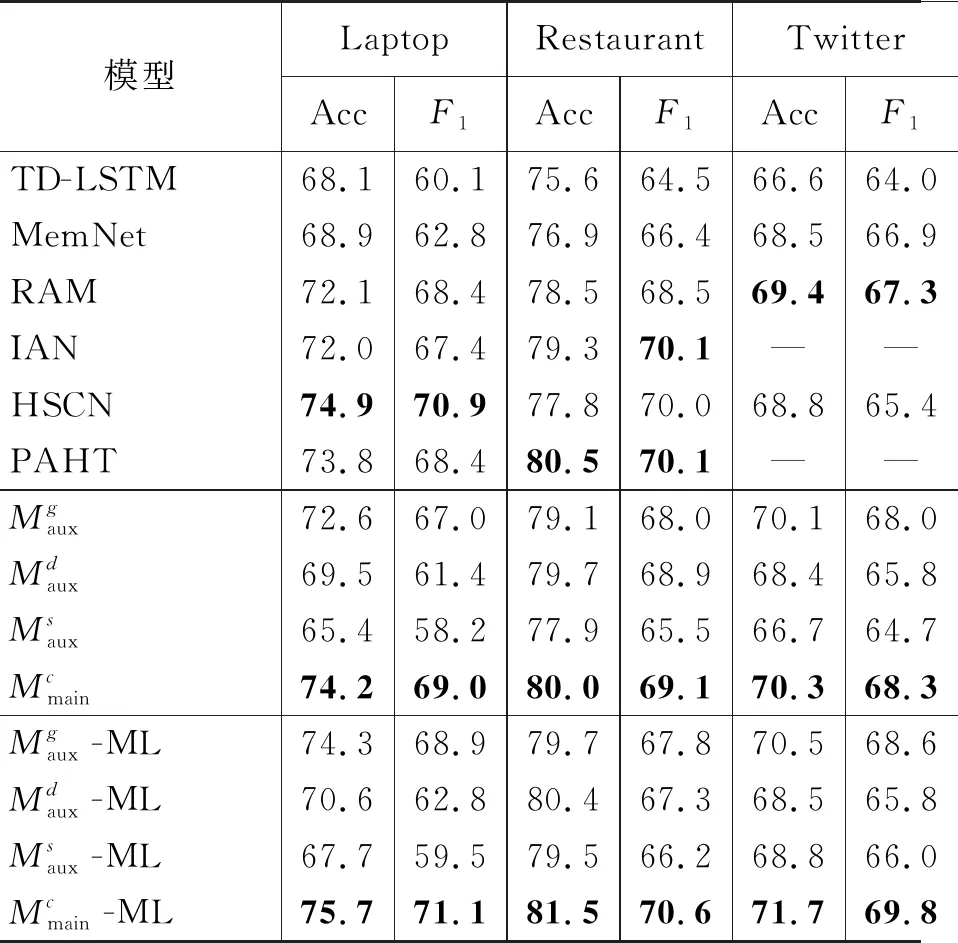
表4 与基准方法的性能对比
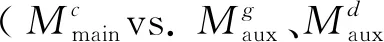
为了验证框架的通用性,我们以另一效果更好的方面级情感分类模型ASGCN为基础进行实验,结果如表5所示。

表5 基于ASGCN模型互学习的效果
从表5中的结果可以看出: ①在ASGCN模型的输入层直接融合3种词向量,效果有一定的提升但并不明显(行2 vs. 行1); ②所提基于互学习的框架能有效地融合多种词向量的信息,效果提升比较明显(行3 vs. 行2、行1)。
综合表4和5中的实验结果可知,本文所提基于互学习的框架能够有效地融合多种词向量的信息,且具有较强的通用性。
4.5 消融分析
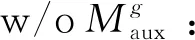
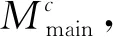
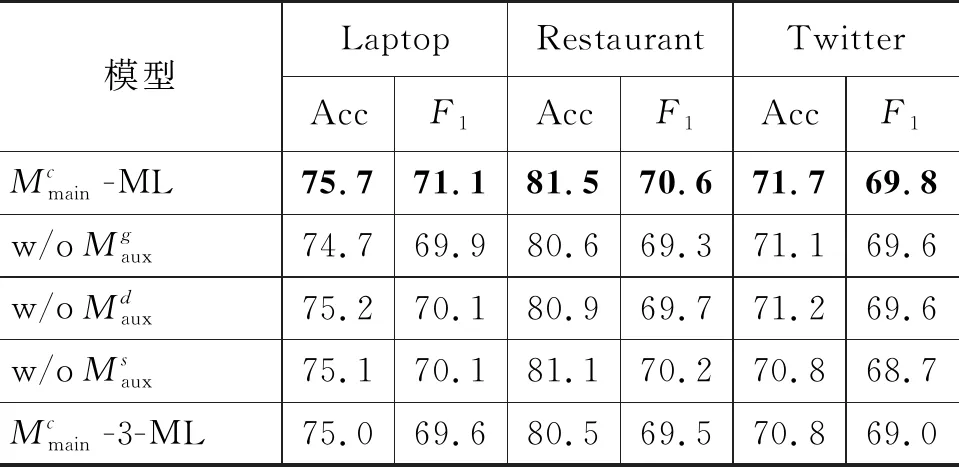
表6 消融实验
5 结束语
本文提出了一种基于互学习的多词向量融合情感分类框架,其目的是充分利用每一种词向量中的信息,以提高分类的性能。具体地,基于互学习的方式联合训练以多种词向量的融合为输入的主模型和多个以单一词向量为输入的辅助模型。实验结果表明,与基准方法相比,本文所提框架的性能有明显提高。未来工作中,我们将探索该框架在其他自然语言处理任务中的应用,如跨语言的相关任务。
