基于交叉注意力机制的多视图项目文本分类方法
2022-09-05方正云李丽敏李天骄
方正云,杨 政,李丽敏,李天骄
(1. 昆明理工大学 国土资源工程学院,云南 昆明 650093;2. 云南电网有限责任公司,云南 昆明 650051;3. 云南电网有限责任公司 电力科学研究院,云南 昆明 650217;4. 西安交通大学 数学与统计学院,陕西 西安 710049)
0 引言
文本分类[1](Text Categorization)是根据文本内容将文本划分为预先定义好的类别,可节省大量人力物力,在信息检索和信息存储上发挥着重要作用。通过从大量的科研项目文本获取重要的信息对项目进行分类,可以实现对科技项目的系统管理,加快自动化管理进程。对科研项目进行准确的分类,可以在科研项目审核的时候为推荐审核专家提供依据。
一般的文本分类方法首先对文本提取有效的特征表示,之后再利用提取得到的特征表示来进行匹配分类。传统的文本分类方法通过One-Hot编码或者TF-IDF模型[2]等方法将文本转为向量表示,然后通过一些机器学习的分类方法将向量进行分类,例如,朴素贝叶斯(Naive Bayes,NB)[3]、支持向量机(Support Vector Machine, SVM)[4]等。
随着文本向量化技术的进步和词向量模型Word2Vec[5]的推广应用,深度学习算法给文本分类带来了新的机遇和挑战。长短时记忆网络LSTM[6]通过链式连接的网络结构以及三个“门”对信息的控制,可以有效获取较长语句的特征。TextCNN模型[7]在文本分类任务中利用卷积神经网络的卷积核的局部感受野特性[8]在当时的文本分类任务中达到了较好的效果。但是,当文本的长度较长时,仅使用LTSM和TextCNN模型提取到的特征无法进行全文本的表示,尤其科研项目文本一般包括6个章节,每个章节都是一个长文本。因此针对结构化的科研项目文本,本文提出了基于交叉注意力机制的多视图项目文本分类模型(Multi-View Cross Attention Classification,MVCA)。根据电力科技项目的科研文本结构将其划分为项目摘要、项目研究内容、项目的目的和意义等视图,之后对每个视图使用BERT等预训练模型来提取对应的特征,最后使用交叉注意力机制将几个视图的特征融合,得到整个科研项目文本的特征,并基于此特征进行文本分类。
1 相关工作
1.1 文本分类方法
特征提取是文本分类最为关键的环节,常见的特征提取方法有TF-IDF、Word2Vec、BERT[9]等。通过TF-IDF模型得到的特征是由词频TF和逆向文件频率IDF构成的,词频(TF)是指给定的词语在该文件中出现的频率,逆向文件频率(IDF)是指一个词语的普遍重要性,最终TF和IDF相乘得到词语的TF-IDF特征。Word2Vec是使用机器学习的方式将语料库中的词转化为向量,以便后续在词向量的基础上进行各种计算。Word2Vec实现主要有两种方式: CBOW 和Skip-Gram。CBOW用上下文推导当前词,Skip-Gram通过具体的中心单词预测上下文。
深度学习的发展对词语特征提取的发展造成了很大的影响。Google在2018年提出了建立在Transformer[10]基础上的预训练模型BERT,其实质是采用无监督方法在海量语料库的基础上学习语义特征表示。由于其在自然语言处理任务中的良好表现,被认为是目前最为有效的语义特征提取方法。BERT性能优异的原因主要有两点: ①Transformer中编码器Encoder的网络结构中自注意力机制(Self Attention)、残差连接机制(Residual Block)[11]和层归一化(Layer Normalization)[12]的机制。②结合MLM(Masked Language Model)&NSP(Next Sentence Prediction)的学习任务在超大规模数据集上进行无监督的预训练。MLM针对Token级别的任务,对输入的单词序列,随机掩盖15%的单词,然后去预测被掩盖的单词。BERT同时对两个任务进行训练,以获得在Token层面和语句层面上都取得优异性能的模型。而在中文文本中上述MASK策略训练的是型补全字的能力,无法捕捉完整的句义信息,训练效率不高。BERT-WWM[13]在随机MASK时,最小的操作单位是语义完整的词,这样的策略可以增强模型对句意信息的解读能力。RoBERTa[14]在BERT-WWM的基础上使用了更多训练数据和动态的MASK机制来得到更好的结果。
文本分类方法在提取语义特征后还需要构造稳健的分类器。常用的分类方法包括朴素贝叶斯(Naive Bayes,NB)[3]、支持向量机(Support Vector Machine, SVM)[4]、人工神经网络(Artificial Neural Network,ANN)等。
1.2 多视图分类方法
在实际问题中,同一事物可以有不同视角的描述,这多种描述就构成事物的多个视图(Multi View)[15]。多视图数据在现实生活中广泛存在,如网页可以由内容信息和超链接两个视图所表示,同一语义对象可以用不同的语言来描述。在这复杂多样的多视图特征描述中,很难找到统一的方法高效去处理所有特征,如电视片段的视频数据和音频数据。多视图数据,由于是对同一对象的不同描述,所以其特征具有一致性,但视角不同,侧重点不同,会造成视图之间的差异性,从而导致信息之间的互补。多视图学习方法通过多视图数据的一致性和互补性融合多视图信息,往往比单视图学习更具有优势。
多视图学习一般可以分为特征视图融合和决策视图融合。特征视图融合是指首先将训练数据的多个视图提取到的特征融合为一个特征表示,之后再利用融合后的特征构建分类模型进行分类。子空间学习就是一种特征视图融合的方法,其通过挖掘不同视图之间的关联信息学习到一个多视图共享的子空间。
决策视图融合是对于分类结果的融合,它首先在各个视图数据上通过分类器得到每个视图的分类结果,之后将所有视图的分类融合,得到最后的分类结果[16]。Mitchell T和Blum A提出的协同训练算法[17](Co-training)就是一种决策视图融合算法。协同训练算法假设有两个视图: 视图A和视图B,在A、B视图上利用标记数据训练分类器Classifier A、Classifier B,然后分类器分别对无标签数据计算置信度,并且对预测置信度较高的数据进行标记,并将新标记的数据加入另外一方的标记数据集中,以便对方利用这些新标记的数据更新分类器,此过程往复进行,直到满足某个停止条件。协同训练算法正是基于数据在不同视图间的分布差异来发挥互补作用。
2 基于交叉注意力机制的多视图项目文本分类方法
本节先介绍注意力机制以及LSTM,然后以此为基础提出基于单个交叉注意力机制的两视图项目文本分类方法,以及基于双交叉注意力机制的多视图项目文本分类方法。
2.1 注意力机制
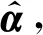
(1)
其中,qi、ki、vi为query、key、value向量,d为key向量的维数。
2.2 Long short-term memory(LSTM)
循环神经网络(Recurrent Neural Network, RNN)是一类用于处理序列数据的神经网络,其被广泛应用于机器翻译、语音识别、文本生成、人名识别等任务。时序性数据一般是不定长度的,且上下文相互关联。传统深度神经网络的输入维度是固定的,网络结构忽略了这种上下文关系。在RNN的网络结构中,每一个时刻的输出不仅依赖于当前的输入,还和以前的输入相关,即St=f(St-1,xt,θ)。由于RNN在训练的时候存在梯度消失等问题,导致模型难以学到远距离的依赖关系。为解决此问题,长短时记忆网络LSTM在RNN的基础上,增加了细胞状态Cell State,同时增加门结构控制信息的流动。遗忘门ft决定细胞状态丢弃的信息,输入门it决定细胞状态中加入的新信息,输出门ot决定细胞状态输出的信息。
由于本文在提取特征的时候使用RoBERTa将项目文本编码成多个有语义顺序的特征向量,分类时应该考虑到这种内在联系,所以本文采用LSTM处理文本的语义特征,主要目的在于减少信息的损失。
2.3 基于单交叉注意力机制的两视图项目文本分类方法
我们基于项目文本中的主要视图(main view)和辅助视图(side view),提出基于交叉注意力机制的两视图项目文本分类方法(Two View Attention, TVCA)。TVCA模型的结构如图1所示,由一个特征编码器(Encoder)、一个交叉注意力机制模块(Cross Attention Module)、一个残差模块(Residual Module)和一个分类器(Classifier)构成。特征编码器Encoder由RoBERTa构成,用以提取主要视图(main view)和辅助视图(side view)的文本字符串的语义特征,并用向量表示主要视图特征(main view feature)和辅助视图特征(side view feature)。Encoder在处理长文本的时候,将长文本以句号划分,对划分后的语句进行特征提取,所以主要视图特征和辅助视图特征的维数为nm×d和ns×d,其中nm和ns是主要视图和辅助视图中文本的语句数,d为预训练模型提取的特征的维数。

图1 基于单个交叉注意力机制的两视图项目文本分类方法TVCA结构
交叉注意力机制模块(Cross Attention Module)由放缩点积注意力构成,是TVCA的主要部分。这个模块将主要视图的特征(main view feature)作为放缩点积注意力中的查询(query)矩阵,将辅助视图的特征(side view feature)作为键值(key value)矩阵,通过放缩点积注意力得到交叉注意力特征,然后将交叉注意力特征与主要视图特征共同输入到残差模块得到交叉特征,残差模块由残差连接、层归一化(Layer Norm)和长短期记忆网络(LSTM)构成。交叉注意力机制模块和残差模块的整体结构如图2所示,计算如式(2)所示。
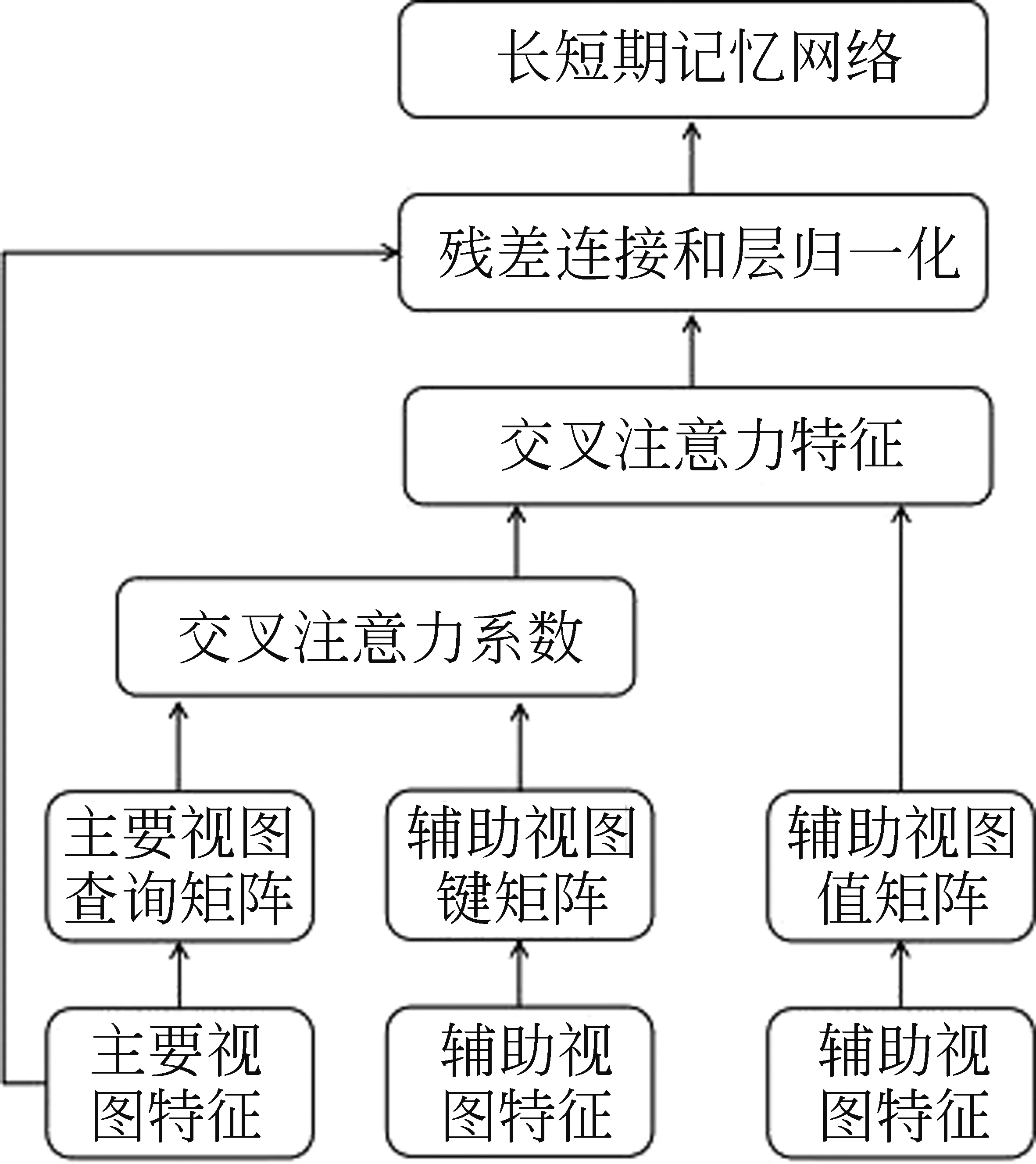
图2 残差模块与残差模块的整体结构
(2)
其中,WQ,WK,WV均为参数矩阵,dK是Q,K的列数,zm,zs,zc分别为主要视图特征,辅助视图特征,交叉特征,fc为交叉注意力机制模块网络。
分类器Classifier由两个全连接层组成,第一个全连接层使用ReLU激活函数,第二个全连接层根据分类问题确定激活函数。多分类问题使用Softmax激活函数,多标签分类问题使用Sigmoid激活函数。分类器Classifier的计算如式(3)所示。
(3)
其中,W1,W2是待学习的参数矩阵;b1,b2是偏置项,zc为交叉特征。
最终模型的损失函数如式(4)所示。
(4)
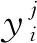
2.4 基于双交叉注意力机制的多视图项目文本分类方法
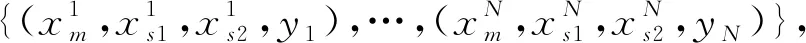
MVCA的网络结构如图3所示。MVCA模型由一个特征编码器(Encoder)、两个交叉注意力机制模块(Cross Attention Module)和一个分类器(Classifier)构成。MVCA的特征编码器、交叉注意力机制模块结构与TVCA的特征编码器、交叉注意力机制模块结构相同。不同的是,MVCA通过两个交叉注意力机制模块将主要视图特征,辅助视图1特征和辅助视图2特征融合为两个特征交叉特征1和交叉特征2。Classifier模块先将交叉特征1和交叉特征2进行加和,然后经过两个全连接层进行分类,其中第一个全连接层使用ReLU激活函数,第二个全连接层使用Sigmoid激活函数,计算如式(5)所示。
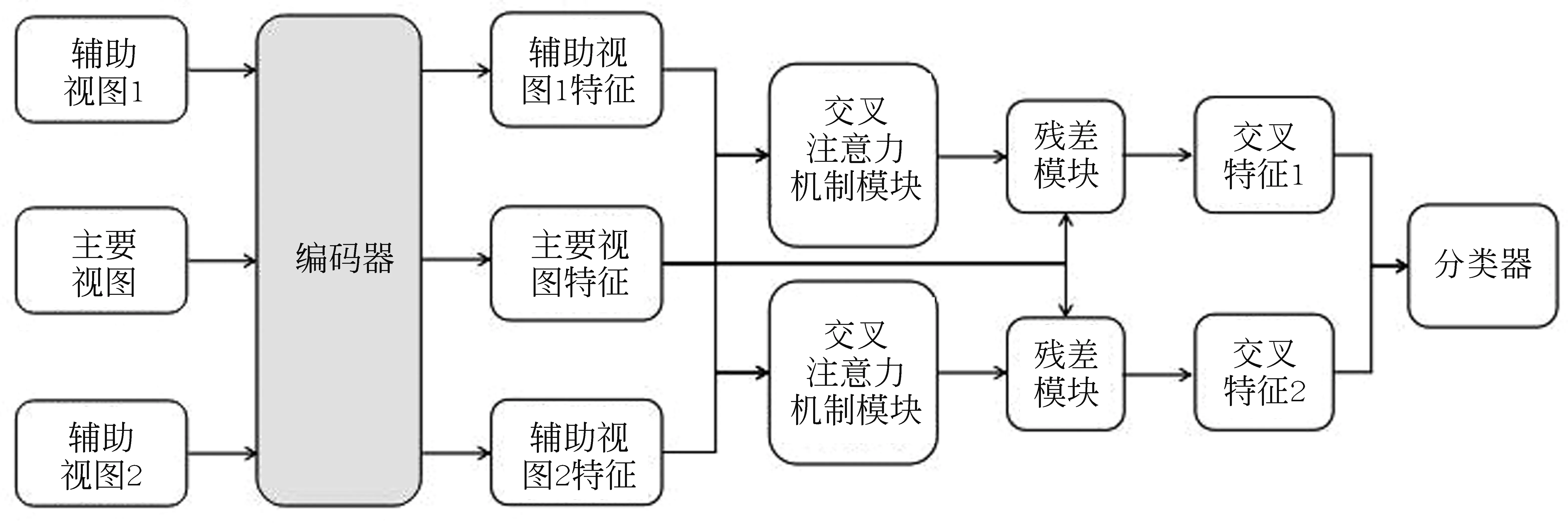
图3 基于双交叉注意力机制的多视图项目文本分类方法MVCA的网络结构
Classifier(zc1,zc2)=
Sigmoid(ReLU((zc1+zc2)W1+b1)W2+b2)
(5)
其中,W1,W2是待学习的参数矩阵;b1,b2是偏置项,zc1为交叉特征1,zc2为交叉特征2。
3 实验对比与分析
3.1 实验数据和设置
本文采用两组文本数据集验证所提出的基于交叉注意力机制的文本分类方法TVCA和MVCA。
Web of Science Meta-data: Mendeley Data提供的公开论文数据集Web of Science Meta-data[22]包含来自7个类别的46 985篇英文论文的部分信息,包括Label、Domain、Area、Keywords、Abstract等几部分组成。我们将摘要作为主要视图(main view),每个句子提取一个特征向量,将关键词作为辅助视图(side view),每个关键词提取一个语义特征向量,同时分别将语义特征向量数量设为8和6。我们将数据集分割为70%的训练集和30%的测试集,用以验证基于单交叉注意力机制的两视图文本分类方法TCVA的有效性。
南方电网电力科技项目文本: 该数据集包含2 082篇南方电网电力科技项目文本,其类型包括发电技术、配电技术、输电技术等共计12类,每类文本数量为100~200 篇。由于一个电力科技项目可以研究多项技术,电力科技项目文本的分类属于多标签分类问题。本文分别从项目摘要、目的和意义以及研究内容三个视角来刻画项目文本,将项目摘要作为主要视图(main view),其余两个章节作为辅助视图(side view1和side view2)。我们将数据集分割为70%的训练集和30%的测试集。本文基于RoBERTa对三个视图的每句话提取一个语义特征向量,分别将项目摘要、目的和意义以及研究内容语义特征数量设为10、20、30(超出设定数量的语句被裁剪,数量不够时补充为0向量)。
我们在网络训练中采用Adam优化器,其学习速率初始值设为5×10-4,并采用阶梯函数方式递减。所使用的分类器由两个全连接层组成,第一个全连接层使用ReLU激活函数,第二个全连接层使用Sigmoid激活函数。
3.2 评价指标
机器学习中的多标签分类问题一般使用精确率(Precision),召回率(Recall)和F1值进行评价。一个多标签分类问题可以看作是多个二分类问题的组合。二分类问题的精确率P(Precision)、召回率R(Recall)和F1值如式(6)所示。
(6)
其中,TP表示将实际类别为正的样本预测为正例样本的数量; FP表示将实际类别为负的样本预测为正例样本的数量;FN表示将实际类别为正的样本预测为负例样本的数量。
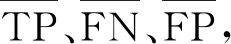
(7)
除微平均精确率(Micro Precision)、召回率(Micro Recall)和MicroF1值指标之外,我们还引入了汉明损失(Hamming-Loss)来对本文方法进行评价。汉明损失用来确认分类结果中错误分类的标签的比例。错误分类的标签包括实际类别为负的样本预测为正例样本和实际类别为正的样本预测为负例样本两类。计算如式(8)所示。
(8)
其中,N表示样本的数量,K表示分类中标签的数量,Yi,j表示第i个真实分类标签向量中第j个标签的值,Pi,j表示第i个预测分类标签向量中第j个标签的值,XOR是异或的表示,即XOR(0,0)=XOR(1,1)=0,XOR(1,0)=XOR(0,1)=1。
3.3 比较方法
本文分别与神经网络(NN)、预训练模型的微调Bert Fine Training (BFT)、长短时记忆网络(LSTM)、文本分类的卷积神经网络(TextCNN)、分层注意力网络(HAN)[24],使用对抗样本增强的长短时记忆网络(Adversarial LSTM, ALSTM)[25],使用自注意力机制的长短时记忆网络(Self Attention LSTM, SALSTM)[26]的方法进行比较。其中LSTM相当于TVCA和MVCA的消融实验,即在TVCA和MVCA中去掉交叉注意力机制的单角度方法。
神经网络(NN)方法对项目文本语义特征进行变换,没有考虑特征向量之间的时序关系;BFT方法处理文本语义特征时,由于其输入长度受到严格的限制(最长长度为512字符),会大概率造成信息提取的缺失;TextCNN方法使用Conv2d-ReLu-MaxPooled结构来处理项目文本语义特征,其只考虑相邻语句的上下文关系,没有考虑文本长距离的依赖关系;LSTM和HAN相对于TextCNN能捕捉到长距离依赖关系,更加符合客观情况;SALSTM方法首先通过自注意力机制捕捉上下文关系,而后采用LSTM方法压缩特征向量;尽管LSTM和HAN能比较好地处理文本上下文信息,但其无法很好地融合多个视图的信息,MVCA和TVCA在LSTM的基础上加入交叉注意力机制,能更加准确地提取文本语义特征。
3.4 实验结果
我们在论文数据集Web of Science Meta-data上,比较所提出的TVCA方法和其他方法,结果如表1所示。可以看出,在各个评价指标上,TVCA可以获得最佳(黑体)或者次佳(下划线)的实验结果。特别地,在加上了关键词的信息之后,TVCA通过交叉注意力机制大幅提高了仅使用摘要的LSTM方法,验证了TVCA融合两个视图进行分类的有效性。
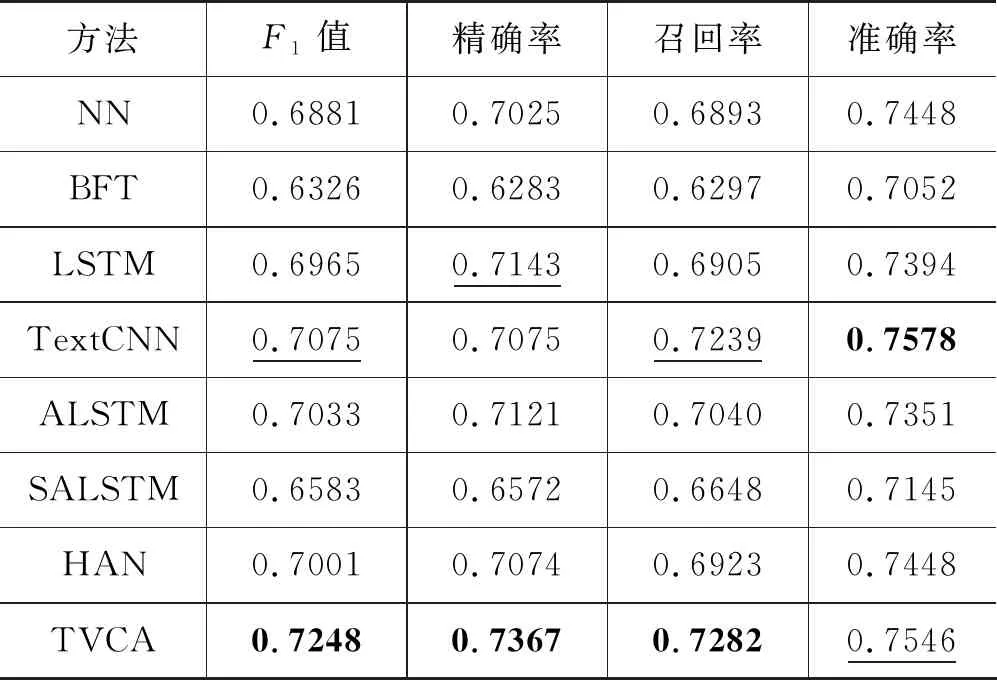
表1 Web of Science Meta-data分类实验结果
我们在南方电网科研项目文本数据上,比较使用项目摘要和项目研究内容两个视图的交叉注意力方法TVCA(项目摘要为主视图)和使用项目摘要、项目研究内容和目的与意义三个视图的交叉注意力方法MVCA(项目摘要为主视图),实验结果如表2所示。
从表2的实验结果可以看到,在综合评价指标F1上,LSTM方法优于BFT和TextCNN,原因在于BFT会造成信息缺失,NN和Text CNN没有充分考虑上下文信息。MVCA、TVCA方法不仅在F1指标上明显优于LSTM和HAN,而且精确率和召回率都有很大的提升,MVCA相对于LSTM,精确率提升4.9%,召回率提升了5.4%;TVCA相对于LSTM,精确率提升4.5%,召回率提升了4.3%。我们的多视图融合方法TVCA和MVCA,在汉明损失指标上都优于其它方法。实验结果表明,不同的视图通常包含不同的信息,多视图信息融合有助于提取到更丰富的语义特征。进一步可以看出,相较于两视图的TVCA,三视图的MVCA方法在微平均F1值,微平均精确率,微平均召回率以及汉明损失四项指标上都有所提升。这说明融合更多视图可以提取出更具有代表性的文本特征,更有助于项目文本分类。
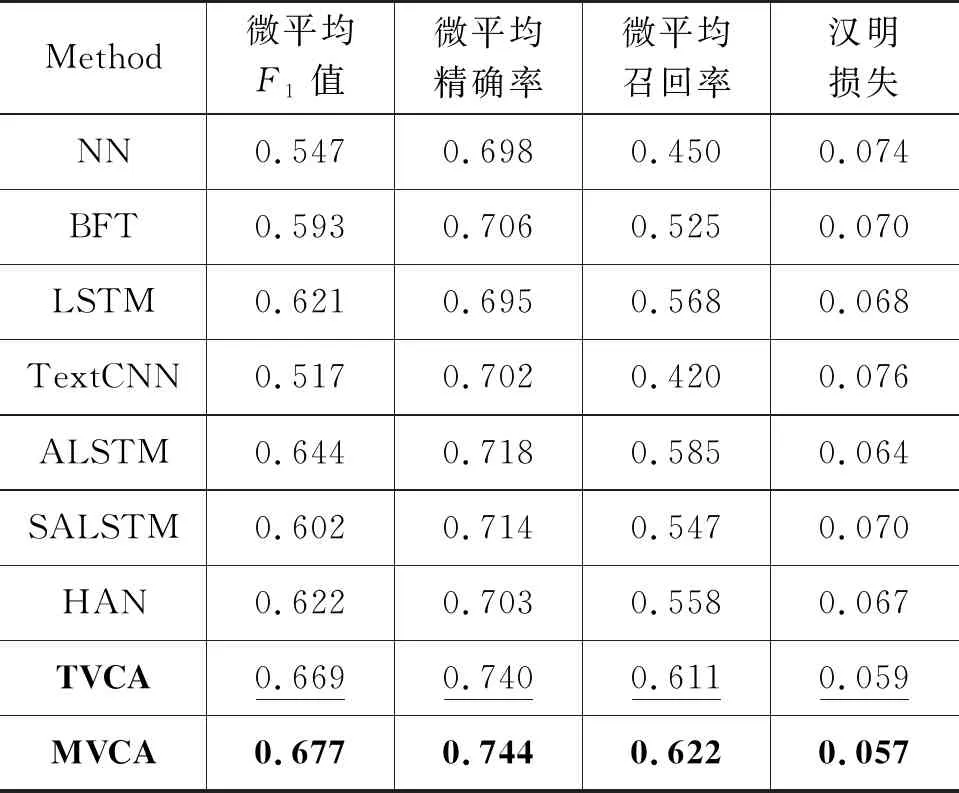
表2 南方电网科研项目文本多标签分类实验结果
为了进一步验证TVCA和MVCA的收敛速度,我们绘制了各方法在南方电网测试集上的微平均F1值随迭代步数的变化曲线,如图4所示。可以看出,TVCA和MVCA方法收敛最快,在50步以内可以达到稳定的测试精度。这说明不同视图之间互补信息的融合可以提高算法的学习效率,加快收敛速度。
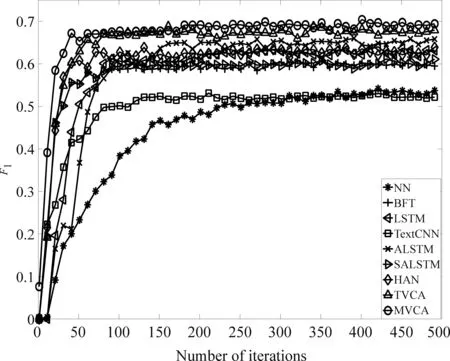
图4 各方法在测试集上Micro F1值变化曲线
4 结论
本文提出基于交叉注意力机制的多视图项目文本分类方法,其中包括单注意力机制的两视图方法TVCA和双注意力机制的多视图方法MVCA,融合项目文本中的主要部分和辅助部分信息。在南方电网科研项目文本分类上的实验表明,TVCA和MVCA不仅在分类效果上明显优于其他比较方法LSTM,TextCNN等,而且在收敛速度上也有明显优势。因此,TVCA和MVCA通过项目文本各组成部分之间的交叉注意力机制,融合不同视图上的互补信息,提取到更加丰富的语义特征,从而达到更精确的分类效果。
