热带气旋灾害预评估模型研究回顾
2022-08-31吴彩铭任福民朱婧
吴彩铭,任福民,朱婧
(1.中国气象科学研究院灾害天气国家重点实验室,北京 100081;2.厦门市海峡气象开放重点实验室,福建 厦门 361012)
引言
热带气旋是给人类造成损失最大的气象灾害之一[1],热带气旋引发的暴雨、大风、风暴潮以及由此产生的次生灾害对基础设施、财产、农业生产活动、人身安全等均会造成严重影响[2-4]。我国是全世界遭受热带气旋灾害最严重的国家之一,在2005—2016年间,热带气旋每年约影响中国大陆3 670万人,造成该区域约254人死亡和695亿元的直接经济损失[5-6],尤以给沿海发达地区造成的损失最为惨重[7-8]。与此同时,农作物受灾面积、死亡人口、倒塌房屋等数量的显著减少也说明增强防台经验、采取有效措施能够为减少灾害发生或减弱灾害强度提供可能性[9]。
过去,针对热带气旋灾害国内外开展了多方面的研究工作,包含热带气旋灾害基本特征[10-15]、灾害成因(即认为致灾因子危险性、承载体脆弱性及暴露度是导致灾害发生的决定性因素)[16-24]、灾害的防御[13,25-26]以及关于灾害危险性或危害评估[27]方面的模型。对于灾害预评估模型,黄崇福[28]认为灾害形成本身的复杂性以及人们对成灾机理认识的缺乏,使得从机理角度导出理论模型不易实现。因此就目前模型研究来看,总体上是以分析历史资料得到的统计模型为主,同时发展出一些侧重分析描述灾害形成机理进而实现灾前预评估的动力模型,以及两者兼顾的动力统计模型[29-32]。关于热带气旋灾害评估技术的研究回顾,主要涉及三个方面:一是灾害风险定量评估方法,即为判断某一地区不同程度灾害发生的可能性大小而建立的致灾因子强度和承载体脆弱性等灾害影响因子评估模型;二是灾情评估方法,通常指灾害形成后,对损失实况进行评价的模型;三是巨灾风险评估模型,即情景模拟大量热带气旋如何对承载体作用的具体过程,判断承载体损伤程度进而预估灾害损失[33-37]。虽然上述回顾涉及了灾情预评估相关内容,但专门系统性针对热带气旋灾前预评估模型研究的详细回顾总结仍然缺乏。
近年来,经济发展迅速,不断变化的人口模式和人口趋势等因素增加了热带气旋致损潜力[38-41]。沿海省份的人口爆炸和灾害多发地区城市的突然扩张导致风险明显加大[42-43]。显然,仅关注此类气象事件发生时间和强度的传统天气监测预报已经不能满足社会发展需求,越来越多的人开始关注其可能造成的影响以及灾害事件发生前需要采取哪些防范措施。因此,做好热带气旋灾害灾前预评估工作愈加迫切和重要。
对于热带气旋灾害的预评估,陈海燕等[44]认为其更侧重评估灾害的损失情况,即对一次热带气旋事件或一个地区有概率发生的热带气旋事件,评估其可能造成的人员伤亡和经济损失。本文立足于前人总结,从防灾减灾需求出发,围绕灾前预评估,就模型构建背后的物理意义,将国内外灾害预评估模型,包括新发展的及改进的、预评估过程中用到的风险评估模型以及巨灾风险评估模型中涉及热带气旋的灾害预评估过程,总体上概括为统计模型、动力模型和动力统计模型三类。以往,利用统计方法构建的预评估模型最丰富,根据每个模型所设计的方法和技术,将统计模型进一步划分为:(1)利用传统概率统计方法建立的回归模型,(2)用于多指标决策的层次分析方法,(3)应用不确定性理论构建的不确定性模型,(4)人工智能方向的机器学习模型。在此分类基础上,对每类模型进行回顾总结,并选取其中最具代表性的例子展开详细介绍,最后就模型目前研究现状、存在的问题以及未来模型发展进行总结和分析。
1 统计模型
统计模型在国内预评估模型研究中最为常见,基于历史资料建立灾情损失与致灾因子之间的数学关系(表1),进而实现对热带气旋灾害损失的预估。这种关系的搭建并不需要明确的灾害形成的物理机制,而是直接依赖于对历史资料的数学统计分析。根据数学统计方法的不同,统计模型可分成以下几种类型。

表1 热带气旋灾害预评估模型比较Table 1 Comparison between pre-assessment models for tropical cyclone disaster
1.1 回归模型
回归分析法即选取关联性较大的因变量(灾情状况)和自变量(影响因子)建立描述两者之间定量数学关系的回归方程,是一种统计方法。学者们从热带气旋自身、其引起风雨的特征、承载体脆弱性及暴露度等方面选取影响因子,研究其与灾害损失之间的关系,建立函数表达式。表达式形式包含多元回归方程[15,29,45-51]、回归方程组[52]和回归幂函数[53-57]。
这里以巩在武和胡丽[15]建立的多元回归模型为例进行介绍。该回归模型首先采用相关分析法,从致灾因子(包括登陆时中心气压、登陆时最大风速、日降雨量、过程降雨量)、承载体(包含人口密度等)和防灾减灾能力三方面25个影响因子中找到分别与各方面灾情如直接经济损失、倒塌房屋数、农作物受灾面积以及死亡人口等关联性大的影响因子,在此基础上建立关联关系的表达式(表达式以各影响因子乘以对应权重系数后相加形式体现),以便在未来通过获得自变量的值去定量预估每种灾情损失的值。
热带气旋灾害涉及多因素影响,而建立回归模型可以简化问题,即用回归分析得到的系数就可以计量各个影响因素对灾情的贡献大小。该模型在大样本情况下计算速度较快,分析结果更准确。但选用何种因子和该因子采用何种表达式只是一种推测,这影响了因子的多样性和某些因子的不可测性,使得回归分析建立的模型在某些情况下使用受到限制。
1.2 层次分析法
层次分析法(analytic hierarchy process,AHP)在灾害预评估过程中被用于综合指标的建立,准确地说它是一种风险评估手段,即将一个复杂的多指标决策问题作为一个系统,将目标分解为多个目标,进而分解为多指标的若干层次(具体体现为指标层、影响层和目标层),在每一层次中按已确定的准则对该元素进行相对重要性的判别,并辅之以一致性检验,根据确定好的权重建立最终综合性指标[22,58-59]。
下面以李春梅等[58]的层次分析方法为例进行介绍。该方法通过分析系统中各因素之间的关系,建立递阶层次结构(图1)。首先,选取包含致灾因子和承载体信息的17个单项评估分指标(指标层),进一步归为热带气旋特征参数、社会经济发展状况、气象条件三方面(影响层),文中具体用中心最低气压、地理综合参数、风综合参数、雨综合参数等4个亚指标表示。接着,对于同一层次的单个指标关于上一层次中亚指标的重要性进行比较,构造比较矩阵(判断矩阵),由判断矩阵计算被比较单个指标对于该亚指标的相对权重,并进行一致性检验,填充权重矩阵。实际上,判断矩阵是在专家咨询的基础上,引入合适的标度,通过指标间两两重要性的比较打分确定出来的。然后,在先计算各层次单排序值的基础上,计算同一层次所有因素对目标层相对重要性的总排序值,再从高层到最低层逐层加权求和计算,并对层次总排序进行一致性检验。最后,将4个亚指标的权重系数与对应指标值相乘再线性累加,得出表征热带气旋灾害对社会、经济的影响程度综合指标值(目标层)。

图1 热带气旋灾害层次分析法总体框架(引自李春梅等[58])Fig.1 Overall framework of AHP applied in assessing tropical cyclone disaster (Credit: LI et al.[58])
层次分析法往往作为预评估过程中的一个环节,用以确定影响因子权重,进而简化为一个综合指标,需要结合其他方法共同实现灾害损失的预估。该方法是一种定性与定量相结合的决策评价方法,能够将复杂系统分解,每个层次中的每个因素对结果的贡献程度都是量化的,清晰且明确。但评估过程中的确定权重环节,专家打分的形式使得该模型存在主观性,评估结果受到人为影响;另外,此模型还需要对判断矩阵作一致性检验,并需求出特征值与特征向量,计算量大。
1.3 不确定性理论模型
在现实社会中,传统精确性或随机性数学方法无法很好解决像热带气旋灾害形成机制这种复杂的不确定性问题,因此产生很多用于处理这类问题的理论——不确定性理论。基于不确定性理论,一些学者尝试建立了热带气旋灾害预评估模型。不确定性理论模型主要包括灰色关联方法[60-61]、模糊数学方法[62-64]、区间数模糊综合评判法[65-66]和可拓方法[67]等。
以灰色关联分析法为例进行详细介绍。该方法即根据序列间相似程度,判断各个影响因子与灾害损失之间的关联性大小,确定这些影响因子各自对灾害的贡献程度。由于参与比较的序列选取比较自由,可以是影响因子(单独的或综合的)或预评估结果(风险大小或者灾损),因此也可通过计算待评估序列与预先给出或通过历史资料获得的与各灾情等级对应的影响因子序列关联程度来进行最终灾情等级判别。如刘晓庆和陈仕鸿[61]选取过程最大降水量、24 h最大降水量、最大风速、最低气压、影响持续时间、影响范围(50 mm 以上过程降水和6 级以上大风影响的站点)、影响区域GDP、影响区域的人口、影响区域耕地面积、登陆时的天文大潮指数,通过计算这些序列与各台风造成的直接经济损失序列之间灰色绝对关联度、相对关联度(参与比较的序列由原始序列变换而来)、综合关联度(前两个关联度的加权和),进而判断出致灾的显著因子。
该类中各个模型考虑的“不确定性”存在差异,即:灰色关联分析法主要是解决信息缺乏引起不确定的问题;模糊数学方法则考虑到人们对于灾害成因认知上的不够成熟;有时,对于某些评价因素,难以得到一个准确的统计值,只能够作一个粗略的估计,也就是说这些评价因素取值本身都可能是一个区间,因而采用区间数模糊综合评判法;对于系统非静态的情况,提出了描述时变性特征的可拓方法等。这类模型似乎更贴合实际,在诸多不确定情况下,能够给出比较科学、合理的量化估计,一般以等级的形式体现。但与此同时,部分模型构建上仍然客观性不足,某些参数界定范围需人为确定;模型所依赖的数学理论基础也并不完善,应用存在局限。
1.4 机器学习模型
得益于计算机水平的迅猛发展,机器学习模型在处理复杂数据问题上有传统统计模型无法比拟的优越性。而作为机器学习的主流算法,神经网络和支持向量机[68-73]逐渐被用于灾害预评估模型的建立,并受到越来越多的青睐。它们是以统计学习理论为基础的新型机器学习算法,无需建立影响因子与灾情之间的具体表达式,用算法解析数据,从中学习,然后对热带气旋灾害进行预估,可以很好地处理灾情与致灾因子、承灾体暴露度及受灾体防御能力之间复杂的非线性关系。
如叶小岭等[70](图2)使用的神经网络模型,采用标准的BP网络结构(多层前馈的神经网络),即由输入层、隐含层和输出层三个神经元层次组成,其中隐含层和输出层具有计算和存储功能,负责计算整合上一层信息并存储。计算时,需要用到通过训练样本学习获得的用于连接输入层、隐藏层和输出层的权值。以此种自学习能力对关系复杂或具有不确定性的系统进行充分的逼近。这也就意味着,训练算法就是让权重的值调整到最佳,使得整个网络最终输出的值与真实值之间误差达到最小。此例子中,输入层从致灾因子、承灾体暴露度、受灾体防御能力和预警能力四方面选取了16个影响因子,直接经济损失、死亡人口、淹没农田和倒塌房屋数目作为输出变量。模型优化是使结果误差减小常用途径之一,这里具体为:首先以神经网络输出的误差为适应度,利用粒子群优化算法(particle swarm optimization,PSO)对网络初始权值、阈值迭代优化,微粒在搜索空间内不断更新位置、速度和权值、阈值,从而确定最优适应度时的参数,再将参数用于BP神经网络部分,最终优化神经网络输出结果。
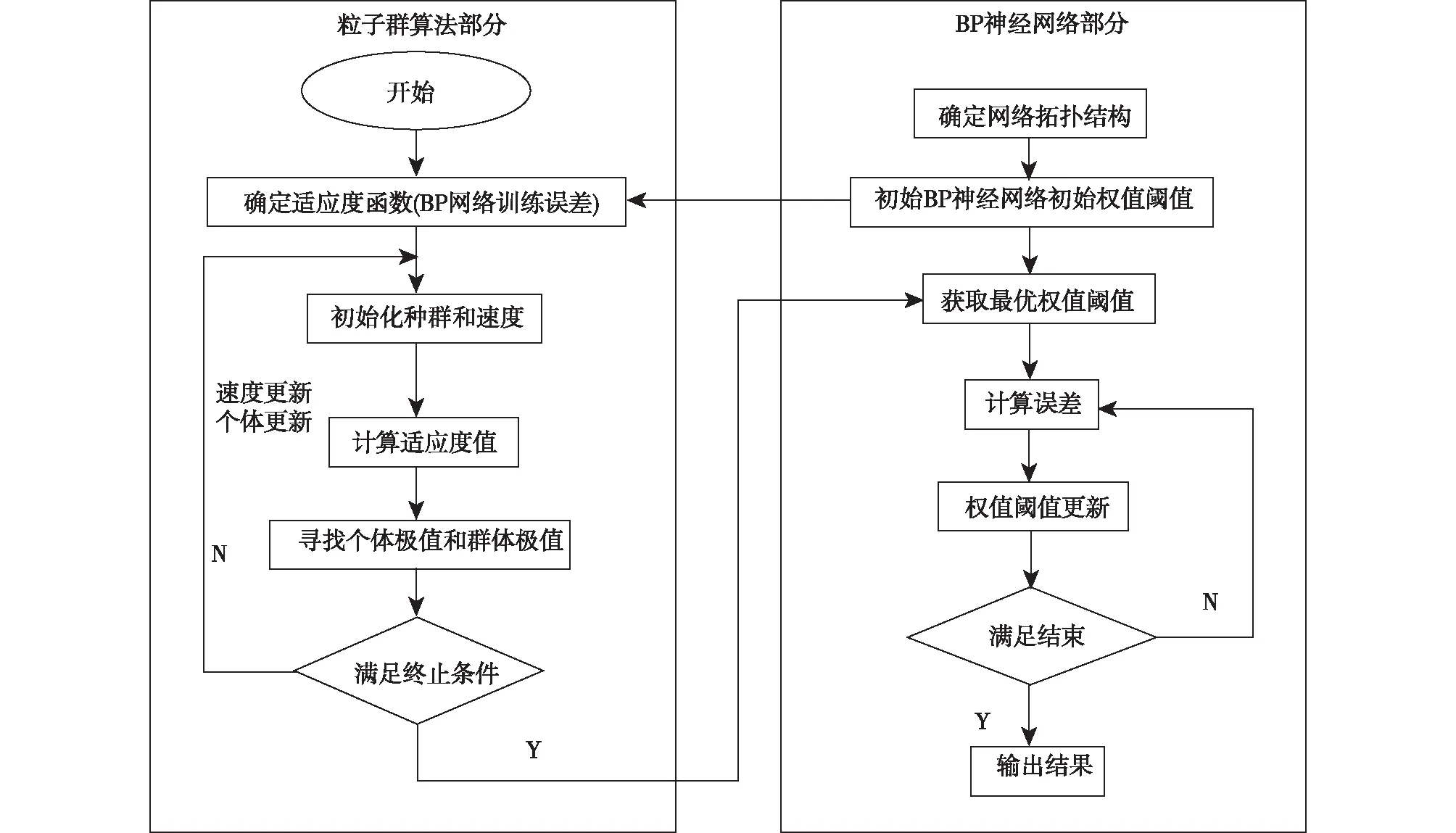
图2 PSO-BP神经网络模型流程图(引自叶小岭等[70])Fig.2 Flow chart of PSO-BP neural network model (Credit: YE et al.[70])
较传统统计方法而言,这类方法具有良好的非线性映射能力,而且一般不需要事先知道被建模对象的结构、参数等,只需要知道输入和输出的对象,就能够通过自身的学习功能进行训练,实现良好的数据拟合,得到符合要求的模型。但模型中仍存在像神经网络中隐藏层包含神经元的个数需人为确定、目标函数算法复杂等问题,需要不断完善发展。目前,越来越多的人致力于算法改进及参数优化等,并开始向多层次的深度学习迈进;同时,通过比较不同算法之间差异与模型适用范围,寻求一些合适的灾害预评估模型。
2 动力模型
动力模型,即侧重描述分析成灾机理而对灾害损失进行预估的模型。目前在国外开展较多,且多为应用于保险行业的巨灾模型,其开发主要源于灾难模型化开发商或研发单位,包含独立的灾难模型化公司(包括AIR、EQECAT、RMS)、基于世界一流大学的研究机构、再保险公司及其中介经纪公司和政府机构等[30,39,74]。模型首先利用仿真和现代信息技术生成热带气旋事件,包含其生成、路径、强度及风场分布等信息,接着可以估算出该模拟事件对承载体可能造成破坏的大小,根据承载体损伤程度来估算灾害损失,实现灾害预评估。这种层层递进的方式可以给出事件从发生到造成破坏、产生损失的详细过程,明晰致灾因子作用于建筑物的具体方式。这里选取HAZUS-MH飓风模型进行详细介绍。
HAZUS-MH飓风模型由VICKERY et al.[75]开发,根据工程力学原理,利用几类脆弱性指标和灾害参数估计飓风对建筑物及其内部可能造成的损害和损失[30]。模型由飓风灾害模型、地形模型、建筑物性能评判模型、物理损坏模型和建筑物损失模型五部分构成。每个模块的模型依次由登陆飓风的历史数据、风洞试验结果、飓风造成损害的现场观测和保险损失数据来进行验证,模块间衔接也有检验。此外,HAZUS-MH模型开发了快速运行损害和损失模块,用于估算每个建筑类别或居住类别的损失。HAZUS-MH模型开发总体流程(根据文献[75]修改)如图3所示。
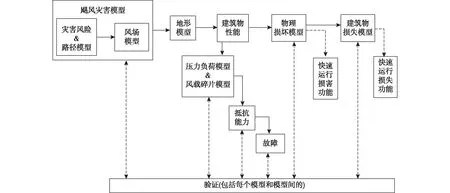
图3 HAZUS-MH模型流程图Fig.3 Overview of approach used to develop damage and loss functions for HAZUS-MH
具体而言,该模型先模拟生成飓风或热带风暴的整个路径和风场[76-77],其中,飓风灾害模型中模拟的完整飓风路径,包含不登陆与登陆两种情况。目前,飓风风场模型经扩展,可估计降雨率,进而估算从窗户及门破损处进入建筑物的水量,这也是评估建筑物损坏的一个组成部分。HAZUS-MH利用现有的土地利用和土地覆盖信息(这里用表面粗糙度表示)来构建地形模型;建筑构件性能部分由压力负荷模型和风载碎片模型两部分构成,采用基于工程上对建筑构件性能的分析方法,查看建筑物的承载和抵抗能力。物理损伤模型主要从建筑围护结构中构件的破坏程度来估算建筑的损伤程度。损失模型包含两大部分:第一部分是对建筑物损坏状态进行建模,分为外部和内部两部分(外部损失的计算结合了建筑物修复和更换的经验成本估计技术,是一个显式算法;内部损失估计基于经验模型,该模型可以将内部损坏的成本与建筑外部物理损坏关联起来计算,是一个隐式算法,此算法也用来估计由于门窗失效导致的围护结构破裂后进入建筑的水量);第二部分是根据修理该建筑物所需的时间,估计建筑物使用损失方面的费用。
HAZUS-MH模型是如今国际上比较典型的灾害损失评估系统,侧重分析致灾具体过程,综合考虑飓风自身及其引起风雨的特征、承载体脆弱性和暴露度情况,同时兼顾这些灾害影响因素之间的相互作用,能够明晰热带气旋事件如何生成、如何作用于承载体的具体过程,并据此评估承载体损伤程度,进一步估算灾害损失。但由于人们对飓风的认识及飓风对承载体的影响认识不全面,该类模型建立时对受影响环境的近似和简化程度以及社会资料的不完整或者不准确等,会使得模型在预评估灾害时产生不确定性。此外,模拟过程中台风模型、近地风场和水量参数的不确定性和差异,会导致最终估算结果具有较大的离散性。
3 动力统计模型
用于热带气旋灾害预评估的动力统计方法模型,从广义上考虑早先提出的动力统计结合思想[78],即将现有不够充分、成熟的对灾害形成机理的认识与积累的历史灾情信息进行综合提炼,在尊重历史事实、统计历史资料中蕴含的真实数理关系或规律的同时,兼顾分析描述事件形成、发展以及最终作用于承载体、造成灾害结果的具体物理机制,进而实现灾害损失预估。目前,应用该方法构建模型的研究处于起步阶段,较上述两类模型,其评估结果优势尚不明确,而如何将动力与统计方法结合应用到模型构建中也有待进一步研究。
这里以构建最多、最典型的相似台风模型进行介绍[32,79-80]。首先说明相似预报之所以归类于动力统计方法,主要出于两个方面考虑。一是依据若干条件(这些条件通常是直接影响灾害的因子,或者是对这些因子构成影响的其他条件如台风所处的大气环境、经过的下垫面等)筛选出来的历史相似台风,其灾害包含这些条件起到的动力热力作用;二是最新研究[81]提升了相似预报原理的认识,发展了动力统计相似集合预报(dynamical statistical analog ensemble forecast,DSAEF)理论,DSAEF理论不仅回答了为什么可以进行相似预报,同时还指出如何进行相似预报(即参考“准确模式”(1)“准确模式”是当前数值模式发展的终极目标——大气运动完全满足的模式。对应于起报时刻初值的预报量即为未来的实际观测,也就是准确模式的解,但其在起报时刻未知;而且,历史观测中还包含着大量类似的初值及其相应的预报量。预报思路,利用相似原理,挑选历史相似台风个例,采用集合的方式实现预报)。
关于相似台风的选取,这里具体以张国峰等[32]方法为例,即根据台风编号选取目标台风,并根据指定的半径对目标台风做缓冲区,接着根据目标台风年代、日期、强度(从动力分析中获得)及缓冲区进行属性与空间联合查询。对查询到的每个历史台风,筛选出外包矩形与目标台风外包矩形之间重叠度超过阈值的;进一步筛选出其路径长度和目标台风路径长度之差与各自路径长度比值都小于指定值的;对满足上述条件的历史台风,计算其路径与目标台风控制点之间的最短距离并取它们的平均值,记录历史台风的属性数据及其与目标台风的平均距离。对记录到的历史台风按距离排序,依次列出排序的台风供用户选择。可以看出,上述流程是通过不断加强台风路径相似条件来筛选相似台风的。其中,外包矩形重叠度反映台风影响范围的相似程度,路径长度差与各自路径长度的比值给出台风路径长度的相似程度,台风之间的平均距离决定台风路径的接近程度。
进一步利用筛选出的历史相似台风灾情,对目标台风灾情状况进行预判。具体以赖宝帮[81]提出的方法为例,即将几个相似台风灾情损失订正到与目标台风同一年份,按照相似度大小来赋予权重,将加权求和的结果作为目标台风的灾情,另外,损失订正的过程中可以结合抗灾能力对历史灾情作进一步的修正。
相似台风模型按照逐渐加强的条件筛选出与目标台风最为接近的历史台风,将历史台风的灾情信息按照一定方式处理,最终预估目标台风的灾情状况,其为动力、热力分析与相似统计办法结合的产物。该过程可以结合Arcmap等软件轻松实现,快速便捷。但相似判据的选择、参数临界取值以及满足筛选条件的历史台风样本量是否会影响最终结果等问题都有待于进一步考查。
4 小结与讨论
分类总结回顾了国内外现有与热带气旋灾害预评估相关的模型,并将各类别中的典型例子进行详细介绍。总体上模型的构建趋于复杂化、多元化与智能化,并且以应用统计方法为主,同时也有使用侧重描述分析灾害形成机理的动力方法,近年来,动力统计结合的方法开始被应用到模型研究中。具体而言,统计模型是直接利用历史资料,构建灾害的影响因子与灾情之间的统计关系,进一步实现灾前预评估。动力方法是应用计算机技术,模拟出若干个热带气旋事件,通过描述分析事件的发生发展及其对承载体的破坏过程,计算承载体受损程度,从而预估损失。该类模型更加侧重从分析灾害事件形成的动力机制来实现灾前预评估。动力统计模型目前主要指相似台风模型,在统计分析历史资料的同时,兼顾关注热带气旋灾害事件形成、发展以及产生结果等过程的物理机制,使得模型建立及结果更有意义。
上述热带气旋灾害预评估技术已逐步应用于业务。譬如,在国外,基于情景模拟方式建立了灾害风险评估系统(包含美国的自然灾害评估系统HAZUS[75]和佛罗里达公共飓风损失评估模型FPHM等)[74];在国内,国家气象中心和国家气候中心均开展了台风(预)评估业务[82-83],沿海省市气象局利用可拓方法[84]、典型相关分析、经验分析、层次分析[58]及历史相似等方法亦搭建了具有地方特色的台风灾害(预)评估系统[85-87]。但是,上述业务的应用特别是在国内,还普遍存在客观定量和精细化程度不高、基于不同方法的台风灾害(预)评估结果之间的可比性较差等问题。
基于以上研究回顾及预评估业务现状对未来研究发展方向给出一些意见或建议,具体为:
(1)影响因子问题。虽然已有模型不仅仅考虑到致灾因子,但对承载体信息及防灾减灾能力的认识一致性仍然较弱,如何制定合理的指标将其考虑进模型中或者如何用承载体信息和防灾减灾能力去修正仅考虑致灾因子模型所得到的预评估结果仍值得思考。
(2)历史资料问题。就目前一些灾害预评估模型而言,其构建过多地依赖于历史资料,因此,历史资料的好坏在相当程度上影响着模型效果。目前的灾情资料主要存在准确性不够、记录有缺失、记录指标缺乏统一标准以及分辨率较低的问题。那么,如何修正不合理的灾情资料;不同来源灾情资料如何比较使用;如何进行历史库重建,丰富样本容量或尝试应用信息扩散思想[88-89]以改善小样本数据带来的局限性等更好地将历史资料应用到模型中值得进一步研究,这对于未来提高预估结果的准确性非常重要。
(3)模型构建本身问题。各种模型不够成熟,仍需改进和发展。具体体现在模型所依赖的数学方法、理论不够完善,进一步导致模型在应用上存在局限;模型客观性不足,需要人为参与评判给出权重或界定范围;模型性能欠佳等。在未来,如何加强灰色理论、模糊数学等领域在灾害预评估上的理论应用研究;如何将客观性方法应用到预评估模型中;如何提升模型性能,包含参数优化和算法改进等方面;如何降低模型理想化程度以及减少数学统计方法的使用,逐步明晰灾害形成的物理机制、丰富模型物理意义等问题都有待于进一步研究。
(4)方法间相互融合。一方面,熵权法[90]的提出、客观确定层次分析法中的权值、自适应模糊神经推理与优化方法相结合预评估模型的产生[91]以及发展的动力与统计相结合的模型等均提供了一个新思路;然而未来将哪些方法结合,以何种形式结合有助于提升模型预评估能力值得进一步研究。另一方面,运用多种方法(涉及到方法选取与比较问题)对同一个热带气旋进行灾前预评估,综合分析评估结果,对于预评估最终效果的改善同样值得思考。
(5)目前热带气旋灾害预评估在业务应用上还没有形成统一的标准和技术规范,技术方法尚不成熟,评估的结果以半定量化“等级”形式体现,灾情资料的获取困难使得建立有效方法困难,先进手段获得高精度资料也尚未发挥作用。未来推广和应用各种先进技术,加强对灾害影响因子(包含致灾因子、承灾体、孕灾环境乃至防御能力建设)的综合研究,加强对现场和空间对地观测、空间技术、遥感、地理信息系统等的有效释用,将成为灾害预评估业务工作发展的主要方向。
