一种低延迟同态加密电路设计
2022-08-31徐鹏飞李桢旻王晓蕾杜高明
徐鹏飞, 李桢旻, 王晓蕾, 杜高明
(合肥工业大学 电子科学与应用物理学院,安徽 合肥 230601)
全同态加密的概念首次由文献[1]提出,然而构造全同态加密策略却是一个难题;文献[2]首次提出基于理想格的全同态加密策略(fully homomorphic encryption,FHE),在无需解密的情况下可以直接对明文进行任意计算,为云端安全计算以及隐私保护提供一种解决方法,但是由于性能过低无法应用到实践中。目前速度已经成为全同态加密策略应用的最主要限制因素,可以通过软件或者硬件实现方式来对全同态加密策略进行加速。然而相较于硬件加速,软件实现的效率对于实际应用来说还是太低了;文献[3]的研究中,有限层次全同态加密方案BGV中的矩阵-向量乘法器基于GPU实现也至少需要2 s;文献[4-7]采用硬件实现的方式来对加密方案进行加速;文献[8]首次提出GSW(Gentry-Sahai-Waters)全同态加密算法,加密后的密文是一个较大的矩阵,利用近似特征向量作为密钥的方式来构造加密策略。为了降低加密延迟,文献[8]采用硬件实现该加密算法,并通过FPGA开发板对其进行加速,将加密时间与CPU加密GSW算法时间进行对比,平均加速比可以达到36.29。
1 GSW全同态加密基本概念
1.1 基本原理
GSW同态加密方案可以根据不同的解密算法构造出如下2套解密方案:① 选择Dec作为解密算法,该解密算法仅能解密出0或1;② 解密算法是MPdec解密算法,使用该算法可以解密出u∈Zq。在GSW同态加密方案中,密文C是一个带有较小误差的N×N阶矩阵,私钥v是一个至少拥有一个较大系数的N阶向量,解密需要采用公式Cv=uv+e,其中e为一个较小的带错向量。为了能够从密文中正确解密出明文u,需要选取密文的第i行,即
x←〈Ci,v〉=uvi+ei
(1)
(2)
从原理上来看,GSW同态加密算法本质上是利用近似特征向量与特征值的关系,其中私钥v是密文C的近似特征向量,同时明文u也是密文C的特征值。
1.2 加解密步骤
(3)
同时令v=Powersof 2(s),函数Powersof 2是将向量s中的第i个数值si分别乘以2i,假设b是一个n维向量,那么Powersof 2满足:
Powersof 2(b)=(b1,2b1,…,2l-1b1,…,
bn,2bn,…,2l-1bn)
(4)
(3) 加密算法。随机生成矩阵R←{0,1}N×m,根据如下公式得到密文矩阵,即
(5)
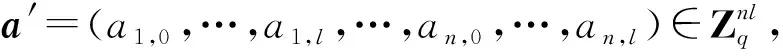
Flatten(a′)=BitDecomp(Bitdecomp-1(a′))
(6)
函数Bitdecomp-1满足:
(7)
(8)
(5) 根据解密公式D1v=uv得到明文u。
1.3 参数设置
根据选定的安全等级分别确定各类安全参数以及所需要的硬件内存,见表1、表2所列。

表1 GSW同态加密参数以及数据位宽
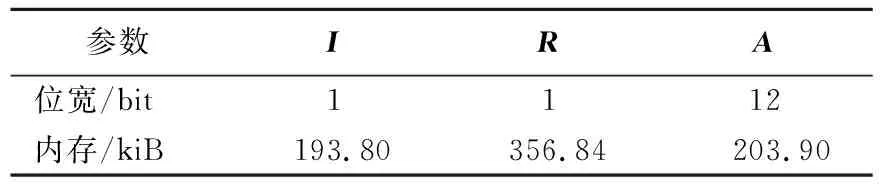
表2 矩阵的数据位宽及所需内存
2 硬件加速方法
本节将介绍基于FPGA的硬件设计方法,并结合改进的10×10脉动阵列和数据拼接及复用方法来降低系统功耗和减小访存次数,最终缩短加密所需时间。
2.1 脉动阵列的介绍
脉动阵列(systolic array,SA)的概念是一种应用于多处理器的体系结构,由多个相同的、结构简单的计算单元(processing element,PE)以网络的形式连接而成,具有并行性、规律性、局部通信的特征。脉动阵列可以是单维的也可以是二维或三维的。本文使用二维脉动阵列,二维脉动阵列有2个输入方向,暂且定为X和Y方向,并采用脉动阵列来对2个矩阵进行乘法运算。矩阵R从X方向输入到脉动阵列中,而矩阵A将从Y方向输入。由于矩阵R中的每个数据均为1 bit,而矩阵A的每个数据位宽为12 bit,本文将传统的脉动阵列PE乘法单元优化,如图1所示。

图1 普通PE与优化后PE结构对比
图1a所示为普通的脉动阵列PE计算单元,由一个加法器和乘法器以及2个寄存器R构成。图1b所示为优化后的PE计算单元,矩阵R的每个数据为1 bit,当输入值b为1时,乘法结果为a的输入;当输入值b为0时,乘法结果为0。因此本文用一个选择器来代替乘法器,随着脉动阵列维数的增加,减小的乘法器数量也会越大。图1中的寄存器R用来寄存输入值以及PE计算单元的乘累加结果。本文将普通PE计算单元和优化后的PE计算单元进行对比,经过Design Compiler综合后,采用SMIC 40 nm工艺,最终得到的结果见表3所列。从表3可以看出,通过这种优化方法可以大量减少DSP资源和功耗,单个PE计算单元功耗从83.27 μW降低到80.22 μW,下降了3.7%,单个PE计算单元面积从475.93 μm2降到474.96 μm2。
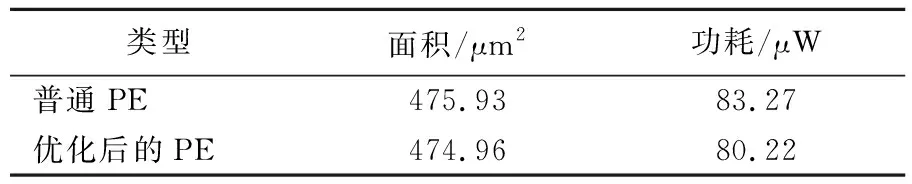
表3 2种PE资源对比
2.2 脉动阵列数据输入端控制单元
若要脉动阵列单元完成正确的乘法计算,则需要控制好脉动阵列2个输入端的数据格式,本文输入端控制单元的作用就是为脉动阵列组织好数据格式,由于脉动阵列的X轴和Y轴的数据均按照后一个数据输入相对于前一个数据输入延迟1个周期的规律,这也是由脉动阵列的特点决定的,这里采用移位寄存的方法,将输入的数据按照不同的通道寄存相应的周期数,从而保证数据输入的正确性。控制单元的结构如图2所示。
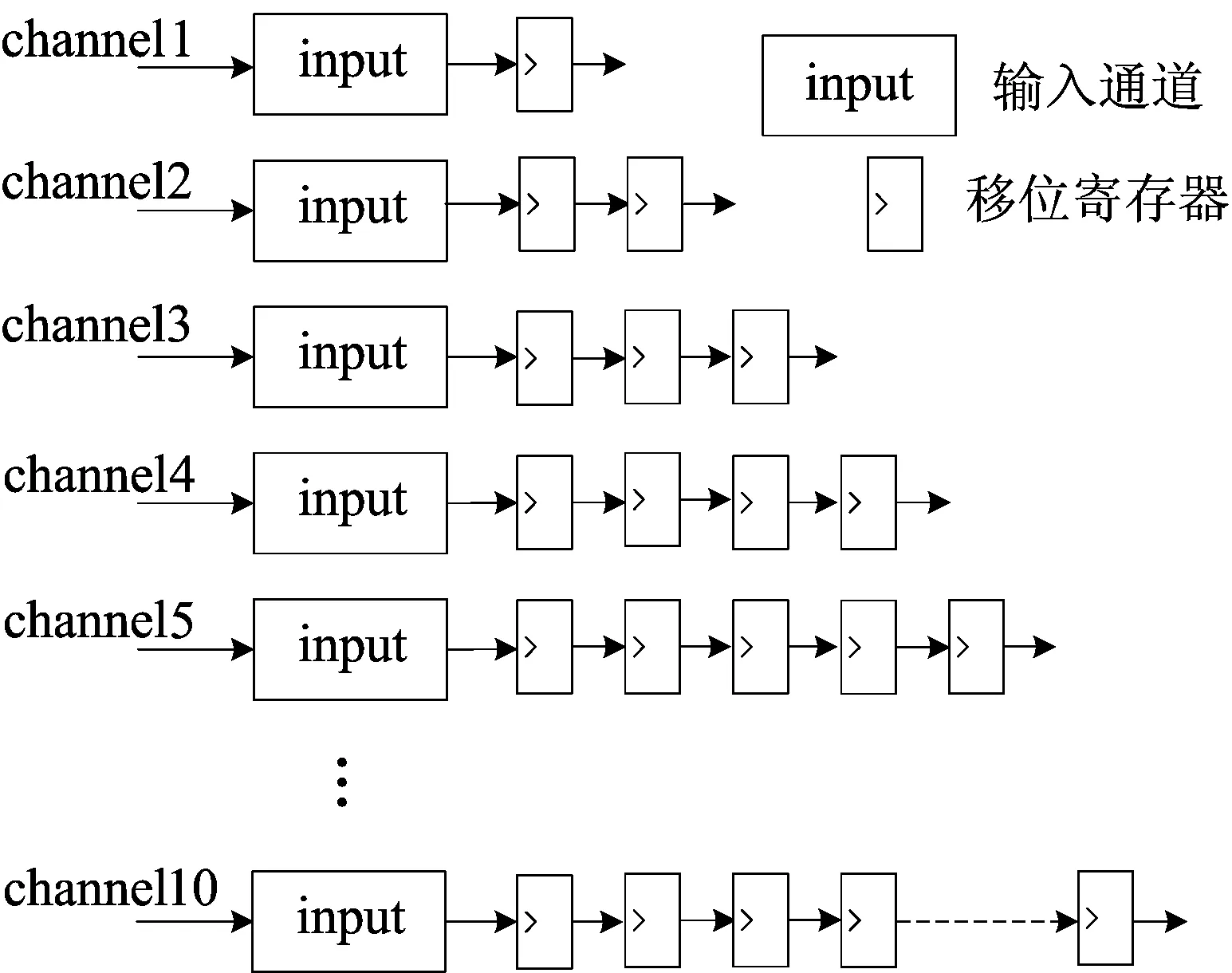
图2 输入端控制单元结构
本文将采用10×10二维脉动阵列,故X轴和Y轴各有1个数据控制单元,每个控制单元各有10个数据输入通道,数据输入端控制单元工作时要求每个周期10个数据同时进入到10个通道中。然而1个周期仅能从存储器Rom中读出1个数据,为了能够在1个周期中一次性读出10个数据,下面将介绍一种数据拼接方法。
2.3 数据拼接方法
因为读取存储器Rom时1个周期只能读出1个数据,然而为了与10×10脉动阵列的20个通道结合起来,本文提出一种数据拼接方法,将矩阵R每10行的10个数据拼成1个数从而得到1个10 bit数据,同时将矩阵A的每10列的10个数据拼接成1个数,即得到1个120 bit数据,从而将原来需要相乘的2个矩阵R(1 260×2 320)、A(2 320×9)转化为R(1 260×2 320)、A(2 320×9)。最后将矩阵R中的数据按行存储形式存到Rom-R中,矩阵A中的数据按照列存储方式存到Rom-A中。这样从存储器中一次读出1个数据相当于一次读出10个数据,存储器的访存次数是没有数据拼接情况访存次数的1/10,矩阵R和矩阵A的数据拼接示意图如图3所示。
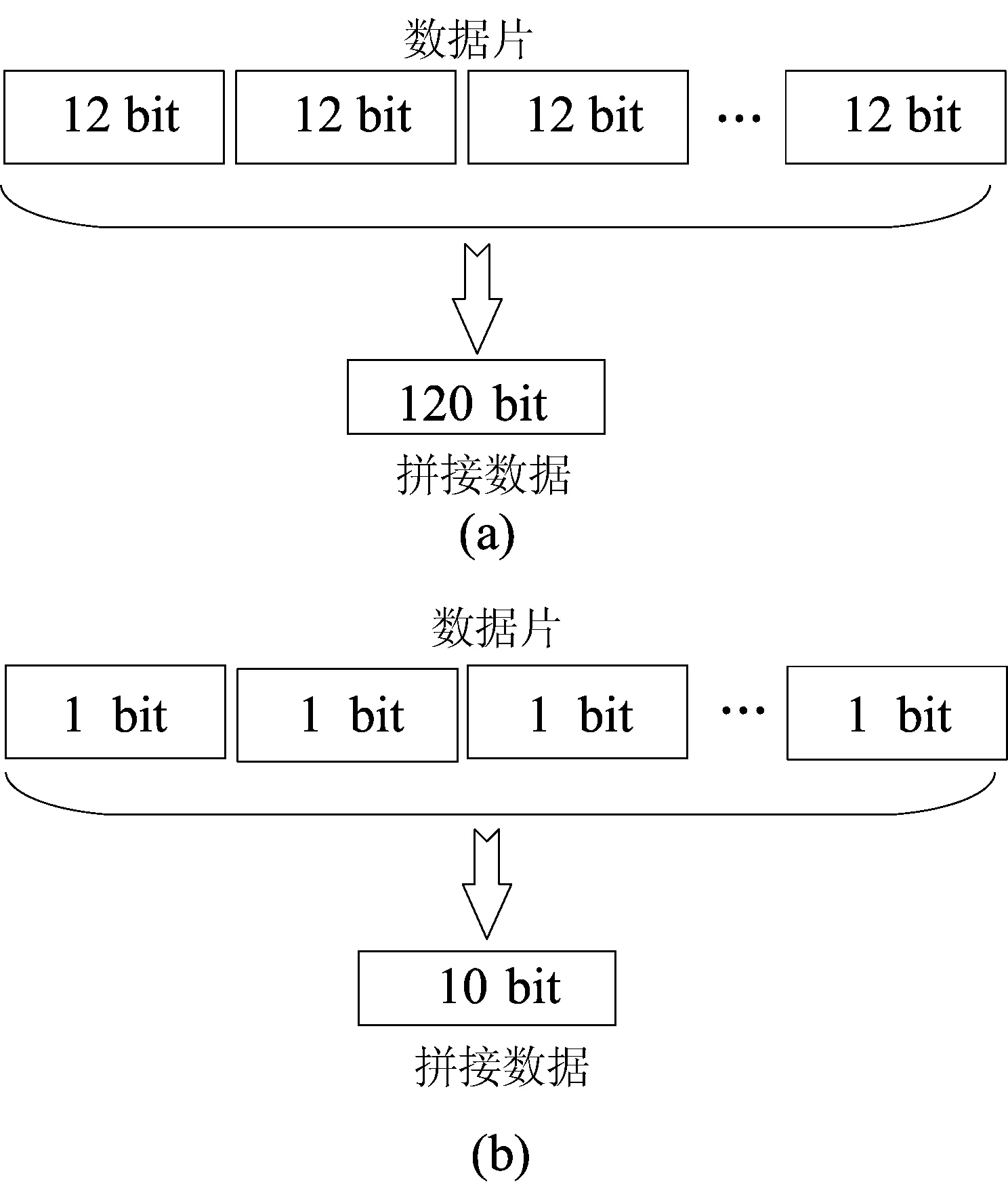
图3 矩阵A和矩阵R数据的拼接方式
2.4 脉动阵列数据存储方式
基于10×10脉动阵列对2个矩阵进行乘法操作,但是脉动阵列PE中计算值并不是同时计算出来的。每当计算出1组10×10矩阵值时,需要将这些PE值进行存储。其中一种方法是当所有PE值计算完1组数据后将所有数据进行存储;另一种方法是使用移位寄存器的形式,设立10组移位寄存器,根据脉动阵列自身的规律,每当PE计算出数值时,将数据按顺序移到相应的寄存器中,脉动阵列设计整体架构如图4所示。从图4可以看出,左上角的第1个PE将会计算出第1个数值,数据按照斜对角的形式依次计算出来,数据存储控制单元将按照脉动阵列的规律,将PE计算单元计算出来的结果依次存储到存储器中。
脉动阵列整体架构包含了矩阵R数据存储器和矩阵A数据存储器,这2个存储器用来存储矩阵R和A中的数据,另外还包括数据输入端控制单元,数据复用单元,脉动阵列PE计算单元,数据存储控制单元。
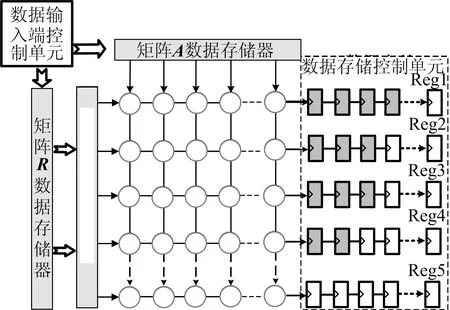
图4 脉动阵列设计整体架构
从图4可以看出,从矩阵R数据存储器中读出的数据将流入到数据复用单元,此处介绍数据复用单元的作用。图4中矩阵R数据存储器中的数据已经是拼接好后的数据,每当读出R的一行数据和A的一列数据后,经过脉动阵列单元计算后得到1组10×10数据。在整个计算过程中矩阵R的每一行数据要分别与矩阵A的每一列数据作运算,从而提出一种数据复用方法,即预先将矩阵R的每一行数值存储到数据复用单元中,此时只需读取A的每一列数据,当读完A的所有列数据后,将数据复用单元清空,并预读入R的下一行数据,以此往复,最终矩阵乘法运算总共访问的存储器次数从原来的5 216 400次降低到2 900 520次,次数减少了44.39%。数据存储控制单元的时序如图5所示。从图5可以看出,后面的寄存器相较于前面的寄存器延迟1个周期存入数据。
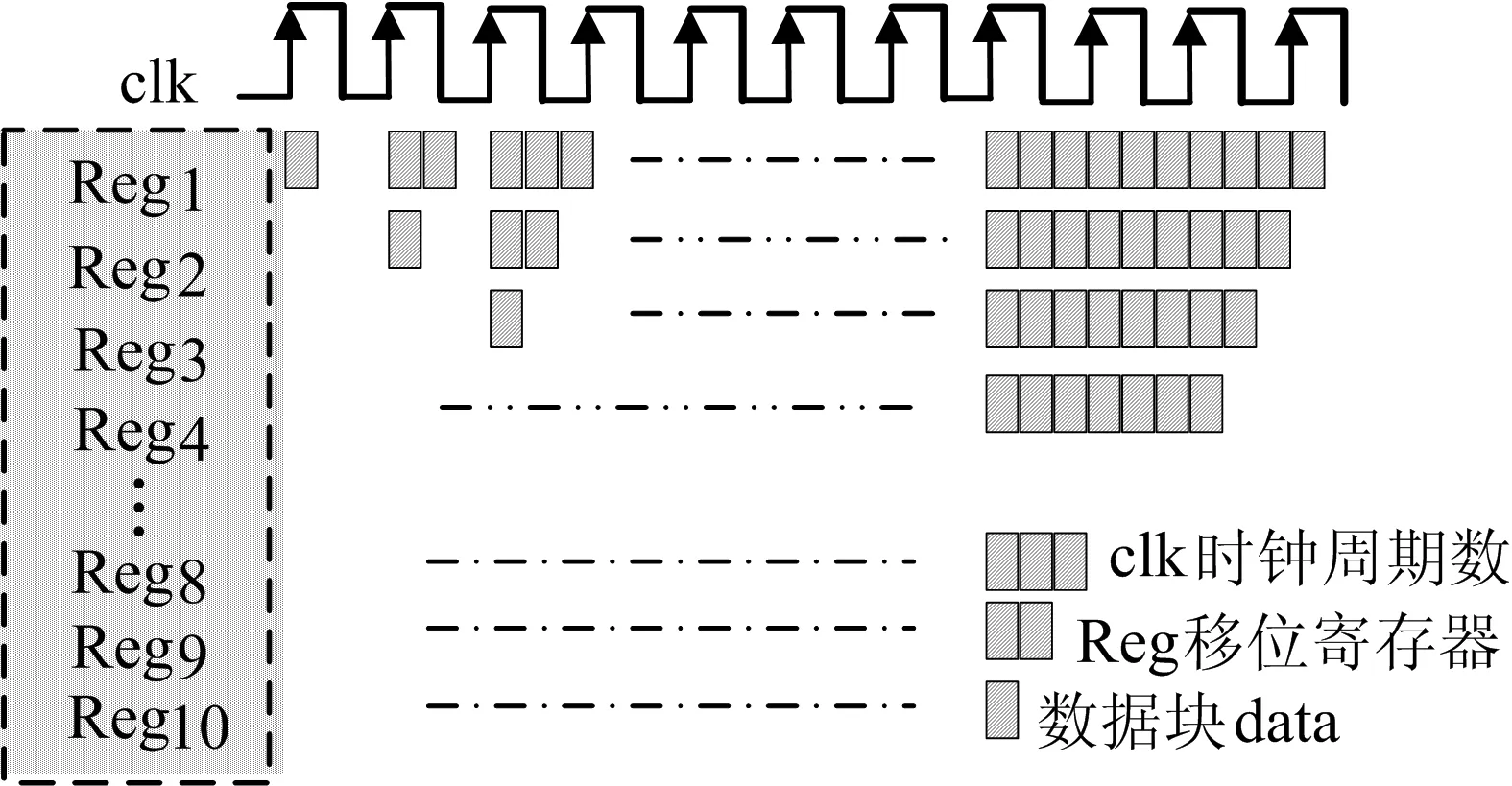
图5 数据存储单元时序图
3 硬件整体实现与实验分析
同态加密的整体硬件架构如图6所示,同态加密整体架构包括了主控制器、脉动阵列矩阵乘法单元、明文u与单位阵IN乘法单元、位展开单元以及加法模块,其中主控制器用状态机来实现,以协调整体硬件模块的功能,位展开单元实际上是完成BitDecomp函数,将输入的每个数据按14 bit二进制数进行展开,经位展开后的数据将与存储器中的数值一起进入到加法模块中进行相加操作,加法模块求和得到的结果将是最终需要得到的密文矩阵。
同时,将加密算法分别在CPU和FPGA软硬件中实现,其中处理器为Intel(R) Core(TM) i5-4570 CPU,而FPGA采用ZCU-102开发板,CPU与FPGA 2种平台分别对不同大小的明文数据进行加密所需时间对比,结果见表4所列。实验结果表明通过硬件加速后,可以大幅度缩短加密时间,相对于软件平台,平均加密时间得到了大幅度地缩短。最终,GSW加密算法的FPGA的综合结果见表5所列。从表5可以看出,LUT资源需要37.24 kiB,BRAM资源需要150 kiB,系统可达到的最高时钟频率为360.36 MHz。
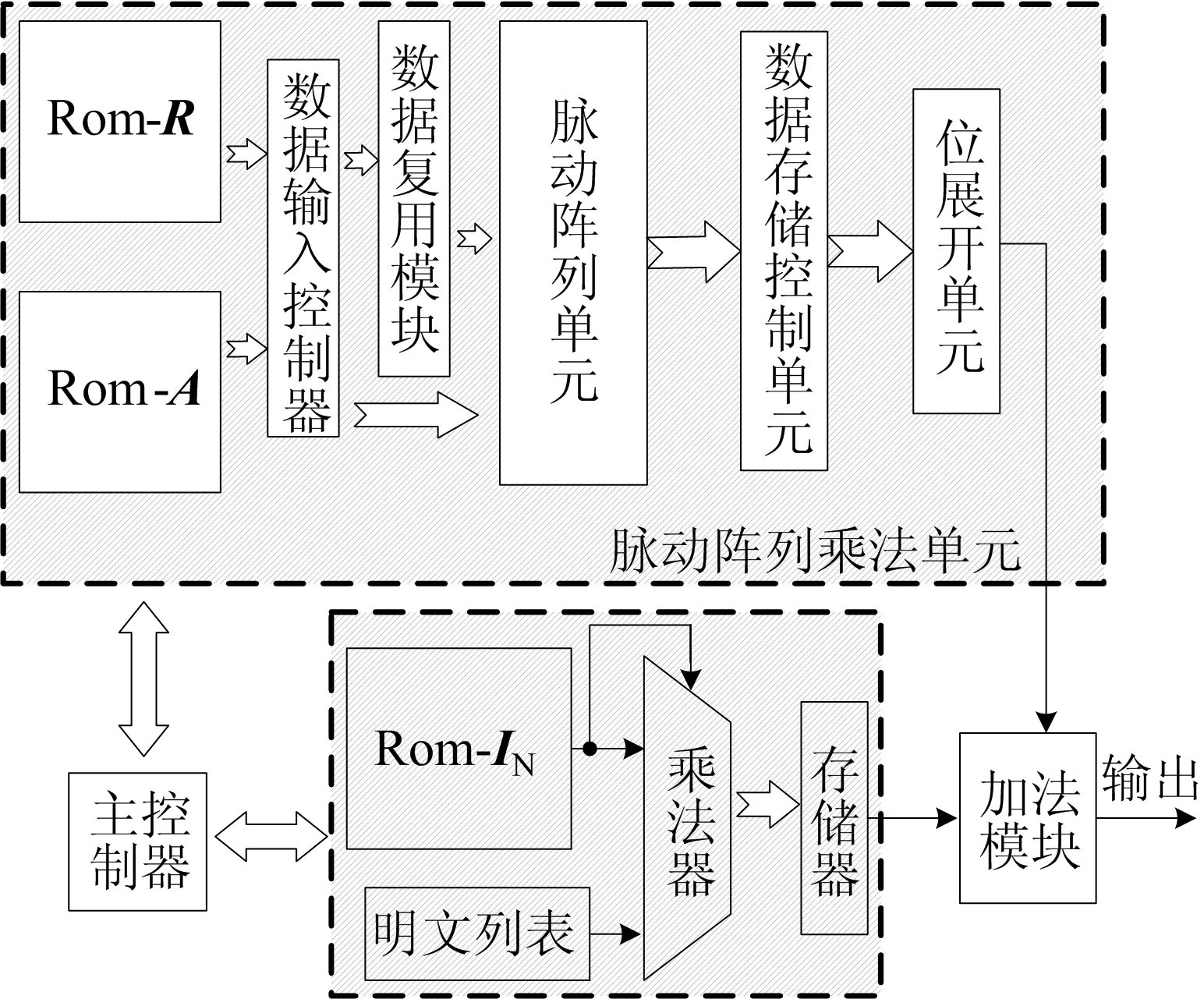
图6 同态加密整体硬件架构

表4 CPU实现与FPGA加密时间对比 单位:ms

表5 GSW加密算法FPGA综合结果
4 结 论
本文基于GSW加密算法提出高性能、低延迟的VLSI架构,基于改进的脉动阵列提出了一种数据拼接方法,同时设计了数据复用模块,降低了访问存储器的次数,从而降低了系统的动态功耗,实验结果表明,加密算法通过FPGA硬件加速后,加密时间得到了大幅度降低。
