基于大数据的突发事件网络舆情动态分类研究
2022-08-29王一帆邵开丽徐志文叶鸿鑫
王一帆,邵开丽,徐志文,叶鸿鑫
(黄河科技学院 工学部,河南 郑州 450000)
0 引 言
在大数据环境下,针对突发事件网络舆情的分析主要是对大量突发事件产生的网络信息数据进行采集、分析、筛选、储存,并甄别出有用的信息。大数据环境下的突发事件具有数据量大、形式多样、传播流动性强、真实性低等特点。按照传统数据统计的方法控制突发事件网络舆情已不符合当前需求,如何在大量且无序的网络舆情信息中筛选出有效信息并分类,避免“数据爆炸”,提高有关部门对突发事件的趋势判断能力,是当前环境下突发事件舆情分析面临的主要挑战。
为探究舆情引导重点与管理方案,庄文英、许英姿、任俊玲、王兴芬分析了舆情演化特征,将SEIR传染病模型与LDA文档主题生成模型相结合,采取LDA进行主题抽取,划分意见群体,构建拓展SEInR多意见竞争演化模型,并利用Python针对大宗商品领域突发事件“中行原油宝事件”进行数据采集、模型仿真与灵敏度检验,实现舆情演化与舆情防控分析,进而分析平台管控、媒体引导与监管干预对网络舆情演化的影响。对于使用单个预测模型会出现结果不准确的情况以及网民和媒体对于网络舆情的影响有直接关系等现象,刘定一、沈阳阳、詹天明、刘亚军、应毅提供了新的预测办法,该预测办法主要包括两部分,一是社交媒体热门看点分析,二是循环记忆神经中的长短期神经网络。实验证明了模型的精确性,说明此模型的预测精度较高,可以运用到实际生活中。基于数据分解的研究思路,程铁军、王曼、黄宝凤、冯兰萍利用自适应噪声完备集成经验模态分解、BP神经网络以及相空间重构理论构建基于CEEMDAN-BP的舆情预测方法,并根据突发事件的案例进行了实证研究。针对各种突发事件的网络舆情,许多专家都提供了自己的预测办法,并且将会随着科学技术的发展进步,提出更多、更好的分析预测方法来应对突发事件网络舆情。
随着科技的发展,社会舆情主要通过网络进行传播。截至2021年6月,中国网民规模达10.11亿,互联网普及率达71.6%。当突发事件发生后,网络平台成为舆情传播的主流媒体。例如,突发的新冠肺炎疫情,网络舆情会随时更新疫情最新进展、确诊人员情况和活动轨迹、药物供给情况、政府防控应对措施等,成为突发事件和应对方法的及时反馈,提高了政府公信力。因此,对于网络舆情进行准确识别和分类,为公众及时准确地了解突发事件提供了信息支持,为网络舆情管理部门提供了数据支持。
1 网络舆情动态分类总流程
网络舆情动态分类流程如图1所示。
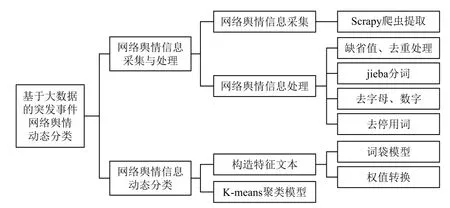
图1 网络舆情动态分类流程
2 网络舆情信息采集与处理
大数据或称海量数据,当前主流的数据处理工具无法对基数如此巨大的信息进行快速的处理分类。大量突发事件的网络舆情与大数据相似,其关键内容并非网络中发布的海量数据本身,而是基于大量数据研究分析得到的具有现实意义的结论,所以利用大数据分析突发事件的网络舆情更加便捷。
对于突发事件的网络舆情进行分类分析,需要对网络舆情进行深度挖掘,包括网络舆情采集、网络舆情处理等过程,如图2所示。

图2 网络舆情信息采集与处理流程
2.1 网络舆情采集
要实现网络舆情分类的前提是突发事件网络舆情采集。只有基于大量网络舆情信息的支持,聚类算法的结果才能够精准。此处运用了Scrapy爬虫框架,其具有可扩展、高性能、多线程、分布式爬虫等特点,可抓取微博、微信等媒体平台及官方网站中有关以下四类突发事件的网络舆情信息:
(1)自然灾害。主要包括水涝、干旱、台风、地震、沙尘暴、森林火灾、泥石流等。
(2)事故灾难。主要包括石油泄漏、车祸、道路坍塌、天然气井喷发、瓦斯爆炸等。
(3)公共卫生事件。主要包括非典、食物中毒、新冠肺炎、禽流感等。
(4)社会安全事件。主要包括持枪抢劫、毒气武器攻击、暴乱等。
2.1.1 Scrapy爬虫提取
Scrapy爬虫框架基于Python开发,能够高效的从网页中抓取有效数据。Scrapy框架结构如图3所示。

图3 Scrapy框架结构
2.1.2 网络舆情采集结果
Scrapy爬虫提取的部分突发事件网络舆情信息见表1所列,其中id表示网络舆情编号,detail表示网络舆情信息。

表1 Scrapy爬虫提取的部分网络舆情信息
2.2 网络舆情处理
对网络舆情的研究基于文本,通过Scrapy爬虫提取的结果并非都可以直接使用,往往会出现一些例如“。”、字母、数字之类的无用信息,所以必须对挖掘的网络信息进行处理。一般使用文本处理的方法,除缺失值处理、去重等一般方法外,还包括如下方法:
(1)jieba分词。中文的数据文本,词和词之间都存在紧密的联系,而此处使用的网络舆情文本基于词语,运用jieba分词方法对舆情信息进行处理,可以得到含有重要特征的关键词。如:将“2020年2月2日湖南发生高致病性禽流感”处理为“2020年 2月2日 湖南 发生 高 致病性 禽流感”。
(2)去字母、数字。从表1可以看出,采集的网络舆情信息含有数字、字母等文本内容,例如“2020年2月2日湖南发生高致病性禽流感”中含有数字,会影响之后网络舆情特征词的提取。这里去除数字为“年 月 日 湖南 发生 高 致病性 禽流感”。
(3)去停用词。通过以上步骤处理得到的结果,还不能很好地运用到模型中。其中“。”“、”“的”等标点符号和词,对舆情信息分类作用不大,故需将无用信息剔除,便于后续网络舆情特征文本词的提取。
经过缺失值处理、去重处理、jieba分词、去停用词等方法对网络舆情信息进行处理后,得到了清晰的文本。经过网络舆情处理部分网络舆情信息对比见表2所列。

表2 经过网络舆情处理部分网络舆情信息对比
3 基于大数据的突发事件网络舆情动态分类
基于大数据的突发事件网络舆情动态分类流程如图4所示。
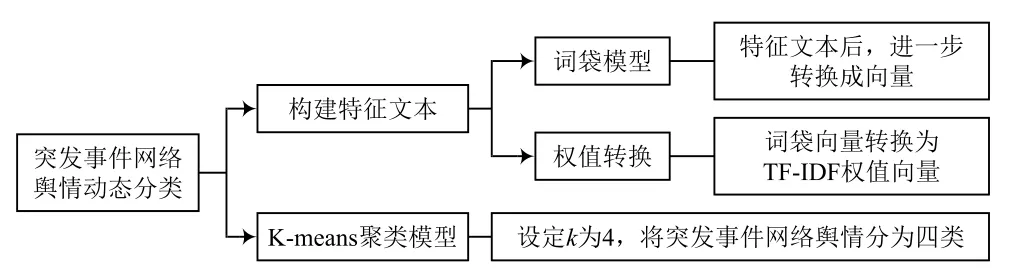
图4 基于大数据的突发事件网络舆情动态分类流程
3.1 构造特征文本
经过缺失值处理、去重处理、jieba分词、去停用词等方法对网络舆情信息进行处理后,得到的是仍然是文本,由于中文无法直接被计算机读取,无法将文本运用K-means聚类算法进行分析。因此,需要将网络舆情文本转化为特征向量,经过计算,如果网络舆情的特征向量相似度较高,代表网络舆情之间的相似度较高,可将其分为一类。
3.1.1 词袋模型
将通过上述步骤得到的网络舆情信息切分成特征文本后,进一步转换成向量,以便放入K-means聚类模型中。词袋模型构建:首先把提取的特征文本转化成此词条列表,然后针对每个特征集创建一个向量,词条重复的次数即为向量的值。
3.1.2 权值转换
采用TF-IDF统计方法判断网络舆情特征文本对于该网络舆情文本的权值。词频向量中的数字代表每条网络舆情对应的特征文本在总词条列表中出现的次数,使用TF-IDF算法可将其中出现次数多的,即词频向量中数字较大的特征文本做进一步提取,得到对应的网络舆情特征文本关键词。
经过权值转换后得到的矩阵,列代表全部特征文本词的集合,行代表网络舆情对应特征文本词的权值向量。矩阵即可代入之后的聚类算法中,实现网络舆情动态分类。
3.2 K-means聚类算法
经过权值转换得到的矩阵可用于聚类算法构建模型,此处使用K-means聚类算法。作为一种常用的划分聚类算法,K-means具有实现简单、能够处理大型数据等优点。对未分组的网络舆情进行分类,属于无监督学习。K-means算法以为参数,将一个或多个对象分成个簇,提高簇内部的相似度,同时降低簇之间的相似度。计算方法如下:
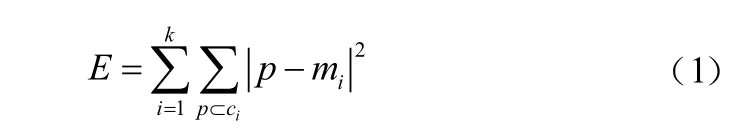
式中:代表所有网络舆情权值向量平方误差的总和;为每条网络舆情对应的点;m为某一簇的平均值。从图5可以看出:值越小,每簇分类的网络舆情之间的相似度越高。
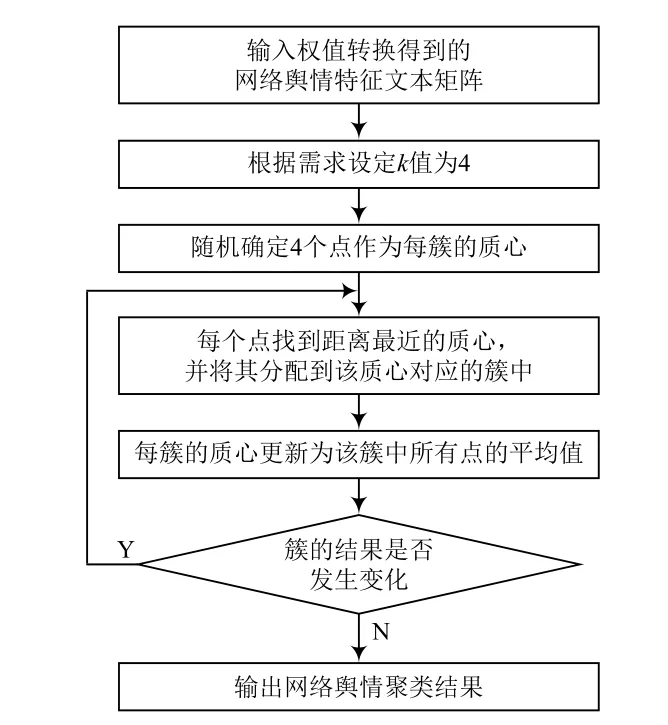
图5 K-means聚类算法工作流程
值得一提的是,一般聚类算法中距离度量使用的是欧氏距离,此处我们使用余弦相似度作为距离度量。余弦相似度与欧氏距离相比,更利于文本的相似度计算,因此使用余弦相似度计算网络舆情对应的特征文本词之间的相似度,便于对网络舆情进行分类。
通过TF-IDF算法得到每条网络舆情特征文本词权值向量之间夹角的余弦值,就可以评估网络舆情之间的相似度。为方便后续分析,需要把余弦值转换到0~1范围内,再做归一化处理。公式如下:
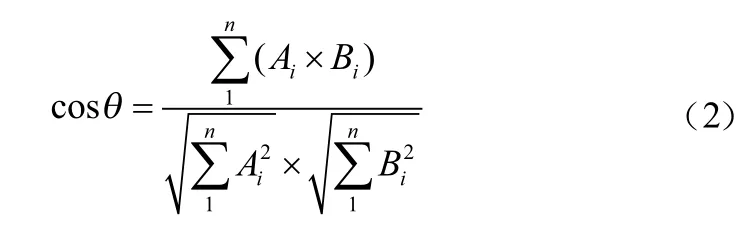
3.3 网络舆情动态分类结果
通过聚类算法我们得到4种分类结果,从左至右将得到的簇标号为1、2、3、4,得到的部分聚类算法分类结果见表3所列。

表3 聚类算法分类结果
将4种网络舆情分类与聚类算法结果结合,设定分类编号1、2、3、4分别对应自然灾害、事故灾难、公共卫生事件以及社会安全事件,4种舆情分类的部分结果见表4、表5、表6、表7所列。

表4 分类为自然灾害的部分网络舆情文本
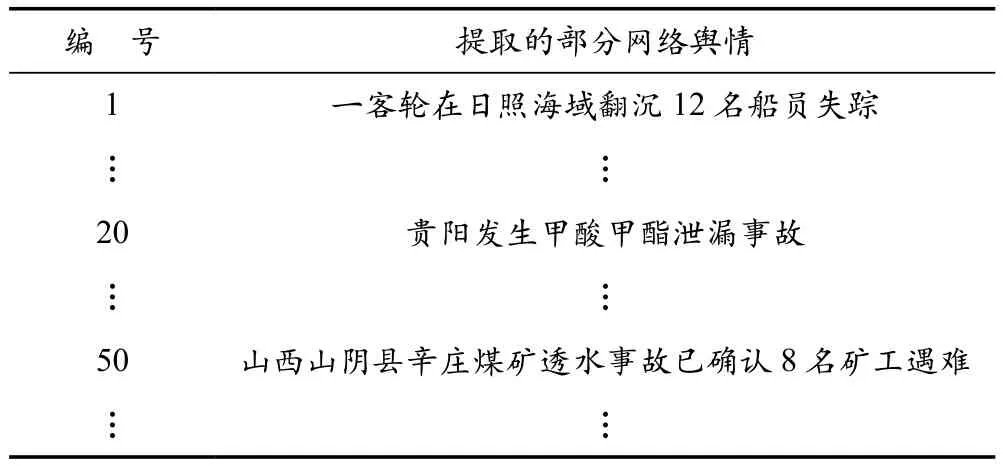
表5 分类为事故灾难的部分网络舆情文本

表6 分类为公共卫生事件的部分网络舆情文本
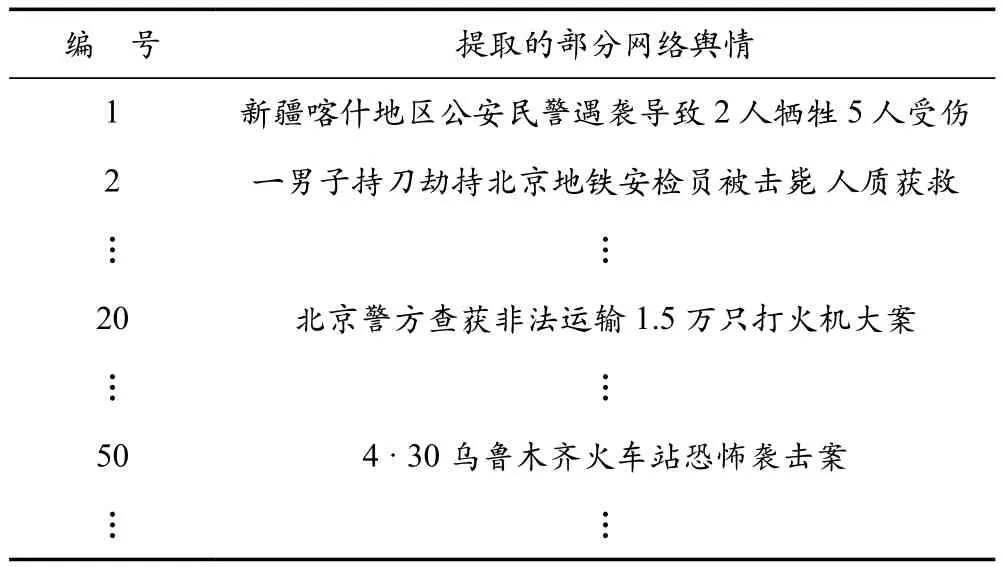
表7 分类为社会安全事件的部分网络舆情文本
将4个表中的数据与4种网络舆情分类对比,可以看出K-means聚类算法对网络舆情分类准确率较高,能够基本达到对大数据环境下突发事件网络舆情分类的目的。
4 结 语
本文通过研究基于大数据的突发事件网络舆情动态分类的背景、现状、意义,叙述了网络舆情动态分类的现实意义和重要性,使用网络爬虫方法进行网络舆情信息采集与处理,提取网络舆情关键特征文本,将其转化为权值向量,放入K-means聚类模型得到4种分类,可以直接观察对突发事件网络舆情分类的结果,实现研究目标。
