基于数据挖掘的城市人居环境河流水质变化监测模型设计
2022-08-26史利涛
史利涛
(漯河市生态环境局临颍分局,河南 漯河 462600)
引 言
城市居住环境中的河水是中水回用技术的主要应用对象,通过对城市居民生活用水进行集中处理,使水质达到一定标准,可回用于植被灌溉、路面清扫、厕所冲洗等,实现绿色生态发展战略下的节水要求[1]。因此刘冉等提出了一个基于辐射传输过程的水质遥感模型,根据入射光在水体中的辐射传输,确定污染物的悬浮状态,以定量分析的方式获取监测水样,为中水回用的河道水质,提供一个科学的监测技术[2]。李韶慧等对黔中水利枢纽的一期工程的核心水源工程进行评价,区分了各评价因子对水质贡献的差异性,提出了基于组合赋权贝叶斯模型的水质评价方法,对水质进行了较为精确的评价,达到了贵州省水功能区划的相应要求[3]。董巍等提出了基于最小二乘支持向量机的污水处理出水水质COD预测模型,实现污水处理中出水水质COD光谱信号重构,采用最小二乘支持向量机法建立水样吸光度和水质COD浓度预测模型,进而实现了污水处理中出水水质COD在线预测,稳定性较强[4]。
但是以往研究方法仅仅依靠单一的分类方法确认水质信息,训练与学习能力较差,直接影响模型监测精度,因此,此次研究将数据挖掘方法与监测模型相结合,优化水质变化监测模型。数据挖掘分为6个大步骤,以更加详细和精准的操作方式处理监测数据,为模型的监测工作提供数据划分原则,为今后的水质变化监测,提供更加科学的技术支持。
1 基于数据挖掘的城市人居环境河流水质变化监测模型
1.1 计算影响水质变化的参考指标
城市人居环境中,河流水质直接影响到绿化灌溉、车辆冲洗、道路冲洗等节水方案,同时,在城市污水处理中,二氧化氯主要是针对水体消毒的消毒剂,主要应用于饮用水、污水、食品加工车间环境、水产养殖、土壤改良等领域,功效是通过二氧化氯的强氧化性来杀灭水中的致病菌、病毒、芽孢、真菌、微生物等,达到净化水质的目的,因此在传统方法的基础上,本文所设计的水质变化监测模型选择氯作为影响水质变化的参考指标。
河道水流中的试剂氯,以总余氯、化合性余氯以及游离余氯的形式存在。考虑到河道中的有机物和无机物,会对余氯造成衰减反应,利用下列公式,描述河道中余氯的衰减过程:
Cl2+M=CBPs
(1)
公式中:CBPs表示含量为s的反应产物;Cl2表示河道水中的自由余氯;M表示能与自由余氯发生反应的有机物或无机物。设置三个参数的反应速率分别为vp、vc和vm,则通过下列方程组中的公式,描述不同物质的反应结果:

(2)
公式中:qp、qc以及qm分别表示CBPs、Cl2和M的实际浓度。若反应产物CBPs的浓度值小于物质M的浓度值时,将qm看做一个常数,则

(3)
公式中:vs表示余氯的衰减速率。河道是土体或建筑表面组成的空间,因此水中的余氯还会与河道接触,此时余氯与河道上的粘附物质发生反应,消耗了余氯。因此河道接触面的余氯反应速率为:
(4)
公式中:v1表示水流到河道表面的传输系数;lh表示高度为h的河道半径;qb表示河道表面的余氯浓度。则个面具上述计算结果,得到河道表面的余氯衰减速率,计算公式为:
(5)
公式中:f2表示Sherwood系数。联立公式(3)和公式(5),得到余氯在河流水中的衰减指标:
(6)
将上述指标作为模型监测水质变化的参照变量,然后进行下一阶段的优化设计[5]。
1.2 基于数据挖掘设置模型对水质变化的设别模式
数据挖掘方法中,聚类分析技术是一种先进的应用技术,可以根据目标变量或属性,计算具有距离差异的数据集合。因此利用数据挖掘技术,对水质监测矩阵进行数据分类。层次聚类分析法预先初始化相似矩阵和距离,然后对最小集合进行更新与合并,不断重复循环更新新的数据集合,达到设定的集合数目后结束迭代。将距离设置为d,则第a个监测区域和第b个监测区域之间的距离为:
(7)
公式中:uam和ubm分别表示第a个和第b个监测区域,指标m的实际监测值,该值就是公式(6)的计算结果[6]。而水质成分是水质变量观测结果的线性组合,因此归一化区域内所有水体的历史数据,得到水质成分分析结果:
(8)
公式中:Fab表示水体成分;βae表示衰减速率指标对于提取成分的影响程度;i、j分别表示水体主成分数目和监测样本数目;e表示水质指标的总变化次数。根据数据挖掘方法训练样本数据,得到实际可用的参数,找出水质数据之间的时空关联,利用模型的智能计算程序,监测水质变化情况,找出各时空间区域内,河道水质指标与其他参数之间的隐含关系,完成对某一特定区域内水质变化的识别[7]。监测模型设计的核心思想是以智能推理的方式合理解释重要的隐藏关系,并针对水质污染物、污染源等问题提出相应的管理措施,由此设置基于数据挖掘的水质变化识别模式,如图1所示,利用该模型实时监测河流水质变化特征。

图1 水质变化设别模式Fig.1 Water quality change model
将图1所示的识别模式,与监测模型之间建立有效连接,通过该模式控制模型的监测行为[8]。
1.3 构建具有时间性质的水质变化监测模型
时间序列是指随时间推移而发生变化的数据,由于监测模型与监测时间点存在相关性,因此构建一个具有时间性质的水质变化监测模型。根据统计特性,将时间序列划分为平稳和非平稳时间序列,当希望监测结果在未来保持不变时,此时需要模型具有处理平稳性监测数据的能力;当一些数据发生变化时,则需要模型具备处理非平稳性数据的能力。已知目标的未来走势与参考指标相关,因此根据移动平均法建立监测模型,计算公式为:
(9)

(10)
至此,在数据挖掘方法的辅助下,实现对城市人居环境河流水质变化监测模型的构建。
2 实验与分析
2.1 实验准备
将河南省某城市的人居环境河流作为实验测试对象,对该地区的河流水质变化进行监测。图2为该城市中,某一村镇的中水回用河道结构图。

图2 中水回用河道结构图Fig.2 Reclained water reuse chamel structure diagram
图2中,节点1表示村镇供水源,其他节点表示村镇人居环境用水节点,网状结构表示供水河道的走势。根据文中设计模型的一般过程,结合数据挖掘和时序性质基本特征,确定了自身输入层、输出层以及隐含层的神经元个数,分别为10、1和12,设置模型的学习速度为0.1,终止误差为0.0001,最大迭代次数为10000,初始权重范围为[-0.5,0.5],学习次数为7。根据上述参数的设置值,建立基于数据挖掘的城市人居环境河流水质变化监测模型,该模型在7次学习下,其损失函数的变化如图3所示。
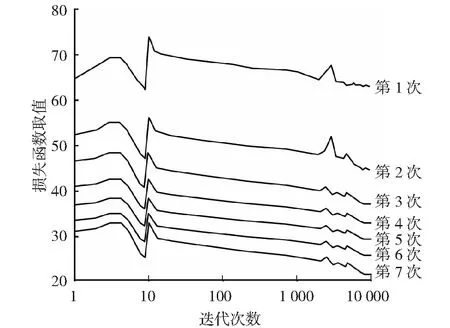
图3 模型损失函数的变化趋势Fig.3 Change trend of model loss function
根据图3中的数据可知,监测模型的损失函数为23.72,合计用时为3 386s。完成每一次学习任务后,根据样本误差剔除部分样本,再根据剩余的样本进行学习,整个建模过程中,学习的样本数量和被剔除的样本数量,如表1所示。

表1 建模过程中每次学习的样本数量Tab.1 Sample number of each learning in modeling process (个)
根据表1中的数据可知,随着学习次数的增加,被剔除的样本数量随之减少。当模型建立完毕时,共剔除了3 051个样本,最后用于建模的样本数为17 545。选择水质监测需要的仪器设备,搭建实验测试平台,将文中设计的监测模型作为实验组,将文献[2]方法作为对照组(和本文方法一直,均以定量分析的方式获取监测水样,减少数据采样过程中的不确定性),将两个模型与水质监测系统之间建立连接,比较不同监测模型对实验地区的水质监测结果。
2.2 模型误差检验
由于各学习样本的河道水质,是通过样本所在区域的中水回用资源均值栅格化得到的,并不是该测试河道的实际中水回用资源,因此不对单个学习样本误差进行分析,利用模型计算各个位置的河道水质,然后统计各个区域的水质均值,将该值与村镇报出的水质数据进行比较。利用两组模型监测12个区域中,6个月内的水质变化情况,模型的监测均值与公报值的绝对误差和相对误差,如表2所示。

表2 模型监测均值与公报值的误差对比Tab.2 Error comparison between the model monitoring mean value and the bulletin value
根据表2中的计算结果可知,文中模型计算下,有58.33%的绝对误差绝对值,小于20mm;所有绝对误差绝对值均小于30mm。而文献[2]方法应用下,有41.67%的绝对误差绝对值,小于20mm;有66.67%的绝对误差绝对值小于30mm。且文献[2]方法的水质监测误差,有4个区域的水质监测绝对误差绝对值,大于40mm。且这四个区域的相对误差也超过了25%。计算两个模型的相对误差绝对值均值,分别为7.13%和16.65%,文中模型的相对误差绝对值平均结果,比文献[2]方法低了9.52%。可见此次设计的水质监测模型,其监测误差更小,得到的水质变化监测结果,更加贴近河道水质的真实值。
2.3 水质变化监测效果测试
已知河南省有17个地级市1个直辖市,为了方便实验测试,将这些城市按照A1~A18的顺序进行编号。已知18个城市中,有6个城市的水质状态经过治理后,符合中水回用的标准;有2个城市的水质状态则出现了中度污染现象;其他城市的水质则一直符合中水回用标准。实验设置2个相同监测周期,分别利用2个模型,对河南省各个城市的河流水质变化进行监测,周期与监测过程一一对应,缩减实验时间。图4为第1个监测周期内,两个模型对城市人居环境河流水质变化的监测效果。

图4 第1个测试周期内模型对水质变化的监测效果Fig.4 Monitoring effect of the model on water quality changes in the first test period
根据已知的实验测试条件发现,文中设计的模型准确得到了6个城市的河流水质,不满足中水回用标准,同时也监测到了2个城市的河流水质出现了微弱变化。而文献[2]方法在监测过程中,还未发现明显的污染变化。图5是第2个监测周期内,两组模型得到的监测结果。
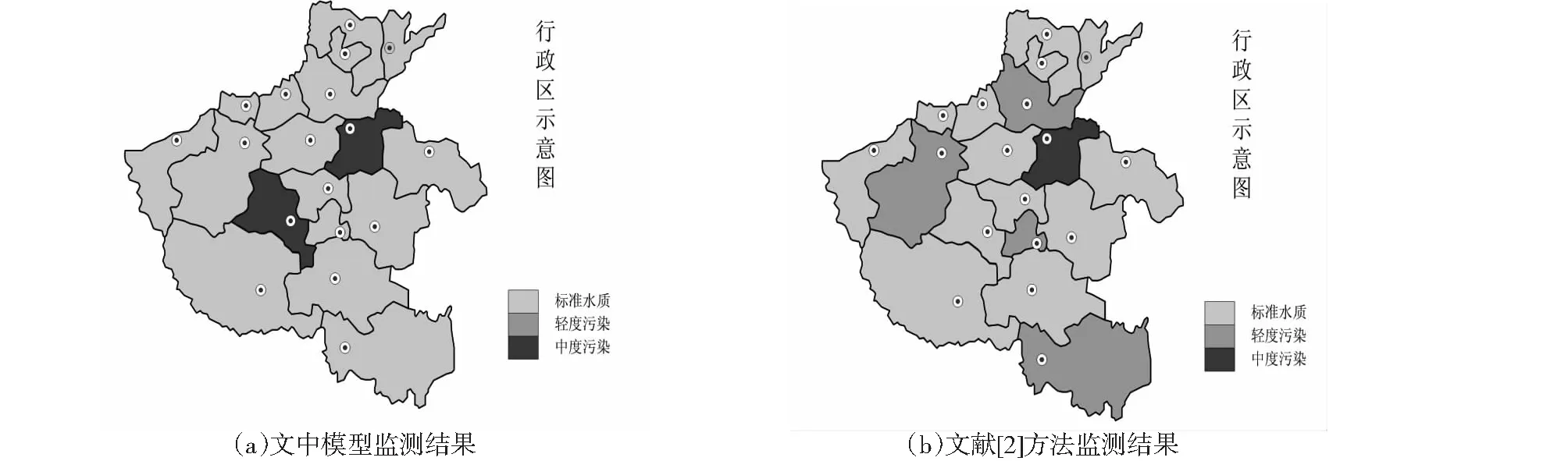
图5 第2个测试周期内模型对水质变化的监测效果Fig.5 Monitoring effect of the model on water quality changes in the second test period
根据图5所示的监测结果发现,此次设计的监测模型,得到的城市河流水质监测结果,与已知的实验测试条件完全一致。而文献[2]方法则只发现了4个城市的河流水质,开始接近中水回用标准值,且未发现1个城市的河流水质,朝着中度污染变化。比较两组模型的训练误差和泛化误差,结果如表3所示。
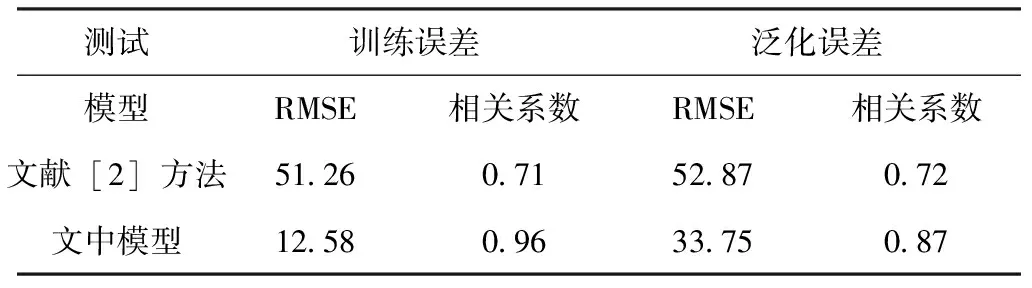
表3 模型误差统计Tab.3 Model error statistics (mm)
根据表3中的数据可知,此次设计的监测模型,其精度更高,因此在监测水质变化时,融入了数据挖掘技术,可以得到与实际数据一致的监测结果。
3 结 语
本研究在借鉴传统监测模型的基础上,针对分类方法单一,学习与训练能力较差的问题,结合数据挖掘算法与时间序列,建立具有时间性质的水质变化监测模型,帮助模型增强对数据的学习和训练能力,为城市水安全提供更完善的技术保障。
由于时间和实验样本的限制,仅对部分优化内容进行了详细描述,缺少其他影响水质变化因子的探讨与区域内水质变化样本的挖掘,因此,在以后的研究工作中,可以对其他部分进行说明,为模型的优化和使用提供更详细的数据。
