基于数据产权关系的市民卡数据归集比对系统的比对策略设计
2022-08-25由永桥
孙 辉, 任 颖, 由永桥
(1. 烟台市大数据中心, 山东 烟台 264000;2. 海军航空大学 航空基础学院, 山东 烟台 264000)
随着市民卡项目的不断推进,市民卡工程建设前期的数据信息会涉及到公安、人社、民政、教育、卫健、残联等多个部门,也包括各个社区填报的市民卡申领登记信息。由于各部门间业务系统的物理隔断,造成关联信息无法及时更新,存在差异。而社区报送的登记信息,在多个环节均存在由人为因素造成的有误信息[1]。因此,在市民卡发放前必须与信息产权部门进行比对确认,对部门与部门之间的历史数据进行比对、分析,实时交换、共享新增数据。本文主要目的是通过对采集的数据及共建部门的现有数据进行产权划分,明确数据的实际归属和数据的产权关系,从而建立一套数据更新机制,以便获取最权威、最真实的数据,为应用系统的建设提供可靠的数据基础。数据归集比对不仅仅是获取最权威的数据,更深层次的作用在于消除信息孤岛和信息烟囱,保证共享数据的准确性和及时性,对城市信息化建设过程中跨部门的数据归集、比对和数据共享具有重要意义。
1 数据分析
1.1 数据来源
1.1.1 个人采集数据
个人数据是市民基础数据库的重要组成,是市民卡数据比对的重要数据来源,因此采集的个人数据的数量和质量将直接关系到数据比对的成败、比对成本及市民卡的发放等环节[2]。根据申领登记表的要求,抽象出相关数据规格需求及数据项的产权归属情况。
1.1.2 共建部门数据
市民卡工程的前期建设数据信息可能会涉及到公安、人社、民政、教育、卫健、残联等多个部门,数据项的抽取和提供主要以市民卡工程建设的实际数据需求确定。
1.2 数据分类
1.2.1 自产权数据
自产权数据由该部门的相关专属业务决定,由该部门发布或审核的,具有绝对或相对的权威性的数据。如:身份证号、姓名、性别、出生日期等以公安局数据为准,是公安局的自产权数据;婚姻状况以民政局数据为准,是民政局的自产权数据[3]。
1.2.2 他产权数据
他产权数据是相对自产权数据而言的,是部门间在相互引用或业务关联过程中产生的数据,即涉及到的其他部门的自产权信息,但由于多种原因,在本部门中又不具有权威性的数据。由于各部门间业务系统的物理隔断[4],造成产权部门寄生在他部门的信息无法及时更新,寄主部门中的他产权数据无法时时与产权部门保持一致,存在差异[5]。数据来源分类及产权关系示意图如图1所示。
1.3 数据的完整性约束
1.3.1 个人采集数据
在各共建部门的业务系统中,由于历史遗留或其他人为因素,造成部分产权数据与事实不符存在差异的问题。而市民卡数据比对的目的之一就是通过数据采集和数据比对,将市民自己掌握的信息与业务部门的产权信息进行双向的核对,查漏补缺,纠正偏差,提高各业务部门数据的正确率[6]。
1.3.2 共建部门数据
共建部门数据一般包括自产权数据和他产权数据,而且均包含姓名和身份证号信息(除公安局信息外,其他部门的此2项信息均为他产权数据,可用于检索)和各部门的业务系统可作为索引项的产权数据(如人社数据的医保个人帐号等)[7]。因此,部门提供的数据必须保证姓名、身份证号及系统索引产权数据非空。

图1 跨部门数据来源及产权关系示意图Fig.1 Schematic illustration of cross sectoral data sources and property relations
2 比对策略分析
2.1 索引关键字分析
2.1.1 身份证号的分析
身份证在各个业务单位的个人基础信息中,都有相应的字段,如果身份证号能够唯一,并且公安部门能保证身份证号在以后也保持唯一,使用身份证号作为市民基础信息数据库的检索关键字是最好的选择,这样各家业务单位的业务系统将作比较小的改造,并有可能简化原来系统的复杂性,比对系统的设计也将会大大简化[8]。但是,考虑到身份号保持唯一在公安部门业务工作上的难度,身份证号不能够独立作为市民基础信息数据库的检索关键字[9]。
2.1.2 姓名的分析
姓名在各个业务单位的个人基础信息中,都有相应的字段,但是由于市民的姓名并没有相应的规则限制,市民重名现象很突出。因此不能单独使用姓名作为市民基础信息数据库的检索关键字。
2.1.3 姓名+身份证号的分析
姓名和身份证号在各个业务单位的个人基础信息中,都有相应的字段。据统计数据显示,随着我国身份证号的升位,及二代身份证的普及,出现姓名+身份证号同时标识多个市民的概率大大下降,姓名+身份证号标识多个市民的情况将不会存在[10]。因此,系统可以使用姓名+身份证号作为市民基础信息数据库的检索关键字。
2.1.4 市民卡号的分析
市民卡号是由市民卡系统统一生成和管理的,是唯一码,不存在一对多的关系,因此市民卡号具备作为市民基础信息数据库检索关键字的条件。但是根据市民卡的建设需求,市民卡号的产生时序在数据比对业务流程之后,而且在数据比对之前不可能对未经核实和比对的数据产生市民卡号[11]。市民卡号可以作为市民基础信息数据库的索引关键字。
2.2 比对策略分析
2.2.1 基本比对策略
基本的比对策略使用姓名+身份证号码作为采集数据和共建部门数据之间进行记录匹配的主要检索字段,如果找到记录,则进行下一步的数据比对;如果未找到唯一对应记录,则采用扩展比对策略[12]。
2.2.2 扩展比对策略
扩展比对是在基本比对失败的情况下进行的。扩展比对策略一般采取使用共建单位中其他可以作为检索字段的数据项,即业务单位的内码(如医保数据中的“医保个人帐号”等),进行2次检索比对,甚至3次、4次检索比对[13]。
3 数据比对分析
3.1 数据比对分类
3.1.1 自产权数据比对
共建部门自产权数据比对,即是用共建部门的自产权数据与个人采集数据中包含的对应数据项进行比对,并将有疑义数据项通过采取市民本人与产权部门进行核对的方式来更改和确认的比对过程。其目的主要是进行部门和市民之间的数据核准[14]。
3.1.2 他产权数据比对
共建部门他产权数据比对,即是用共建部门的他产权数据与相关的产权部门的自产权数据进行核准或更改的比对过程。其目的主要是实现部门间的数据共享。
3.2 数据比对流程
数据比对就是将个人采集数据和共建部门的数据,按照预定的策略,进行汇总、比对、整合,求同改异,最后形成一套内容最全面、信息最准确的数据,进入市民基础数据库[15]。
按照比对的功能需求,整个数据比对流程分为3个阶段,即标准检索数据生成阶段、共建部门自产权数据比对阶段和共建部门他产权数据比对阶段。
3.2.1 标准检索数据生成阶段
标准检索数据生成是数据比对工作进行的前提条件,也是一个比对检索依据,该过程以公安数据为比对的一个对象,将从市民采集的第一手资料和公安提交的数据进行姓名+身份证号的比对[16],形成正确的具有权威性的检索字段姓名+身份证号。
3.2.2 共建部门自产权数据比对阶段
共建部门自产权数据比对流程是对各个共建部门提交的数据中的产权数据与上一过程形成的标准检索数据进行比对,比对时用“标准检索数据生成阶段”中产生的具有权威性的姓名+身份证号作为检索条件,定位检索的记录。将各个共建部门的自产权数据进行核实,使其具有一定的权威性,为下一阶段建立比对基础。
3.2.3 共建部门他产权数据比对阶段
本阶段主要是将各个共建部门中比对成功表的他产权数据进行核实,确保各个共建部门的数据保持一定程度的一致性,实现跨部门的数据共享。比对过程中首先确定某一共建部门,然后以姓名+身份证号作为检索标准,定位一条记录,依次对该记录中的他产权数据项与产权部门进行遍历和比对,其他记录同理进行比对,直到该共建部门的所有他产权数据比对结束。其中比对一致的记录保持不变,比对不一致的记录以产权部门为依据更新本部门的比对成功表。
4 系统设计
4.1 总体结构
市民卡比对系统的建设主要包括:数据交换子系统、数据比对子系统和各业务部门接口子系统。系统的总体结构如图2所示。
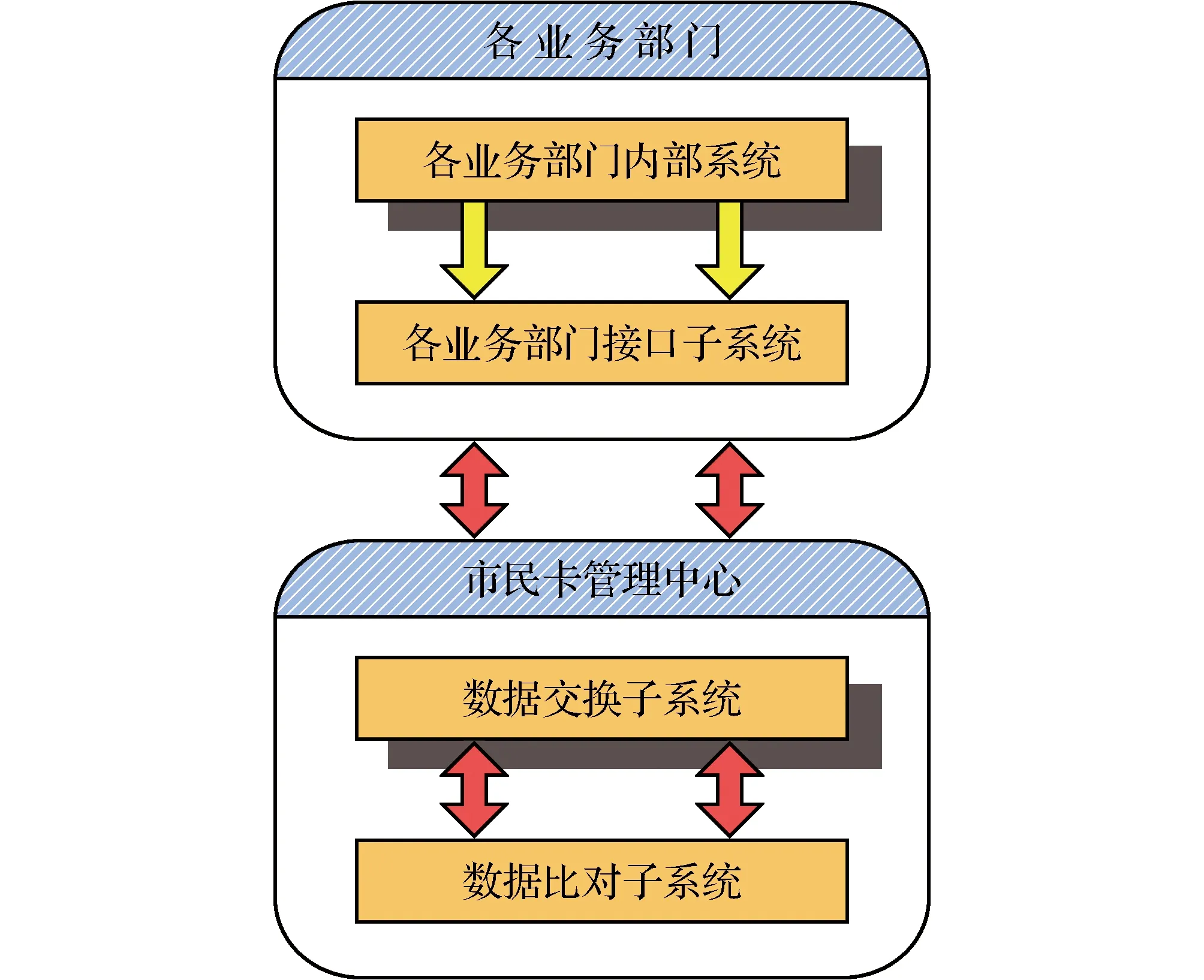
图2 系统总体结构Fig.2 System Overall Structure
4.1.1 各业务部门接口子系统
业务接口子系统采用统一的数据访问规范,直接与业务系统进行数据交换。通过安全可靠的数据抽取和访问形式,为各类应用系统提供信息共享和数据整合的手段,为应用系统实现“数据库无关”“操作系统无关”“网络环境无关”的数据交换和异构数据访问提供平台基础。
4.1.2 数据交换子系统
除了完成基本的数据分析、任务转发外,交换子系统还需要有丰富的配置管理和监控的功能,让使用者能够方便地使用和控制。通过监控与管理工具可以得知系统当前的运行状况和历史的运行状况;交换平台的管理工具对配置文件的修改将直接影响交换核心的运行。
4.1.3 数据比对子系统
由交换子系统获得的数据首先要对数据格式、代码等进行简单的转换,再根据预定义的数据清洗规则进行数据的过滤、清洗和语义转换,最后根据定义的比对策略进行数据比对。
4.2 网络结构
包括部门数据交换网络、市民卡管理中心网络和综合信息平台网络3个部分。部门数据交换网络采用放置在各部门的数据前置机与部门业务系统相连接,采用VPN等专网形式与市民卡管理中心网络连接。数据到达市民卡管理中心经过数据汇总后进行数据的清洗和比对,然后经过专网与综合信息平台进行数据的上传。最后以门户网站和信息亭等形式进行发布,如图3所示。
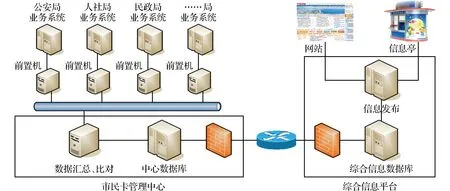
图3 系统网络结构Fig.3 System network structure
4.3 数据库建设
4.3.1 数据库规划
市民基础数据库是市民卡系统的重要部分。它集中存放与每一个市民相关的各个领域(包括公安、人社、民政、卫健等)的信息资料,并通过综合信息平台和分系统的服务窗口向社会、政府机构及个人提供及时准确的信息共享和访问。
4.3.2 数据库配置
对于服务器端,软件方面,数据库使用IBM UDB DB2(V11.1)服务器端,操作系统采用windows 10;硬件方面,由于涉及的数据处理量较大,集中处理峰值时的硬件要求较高,所以处理器使用4颗8核CPU,128G内存,根据数据量大小选择1T硬盘。
对于客户端,软件方面,数据库使用IBM UDB DB2(V11.1)运行时客户端,操作系统采用windows 10;硬件方面,处理器使用4核CPU,32G内存,500G硬盘。
4.4 比对功能设计
4.4.1 功能模块
比对功能主要包括前期的数据导入和预处理,数据的清洗格式转换,以及对数据字典、比对任务的设定,比对后,按照比对状态、比对的结果进行展示和结果统计。具体功能如图4所示。
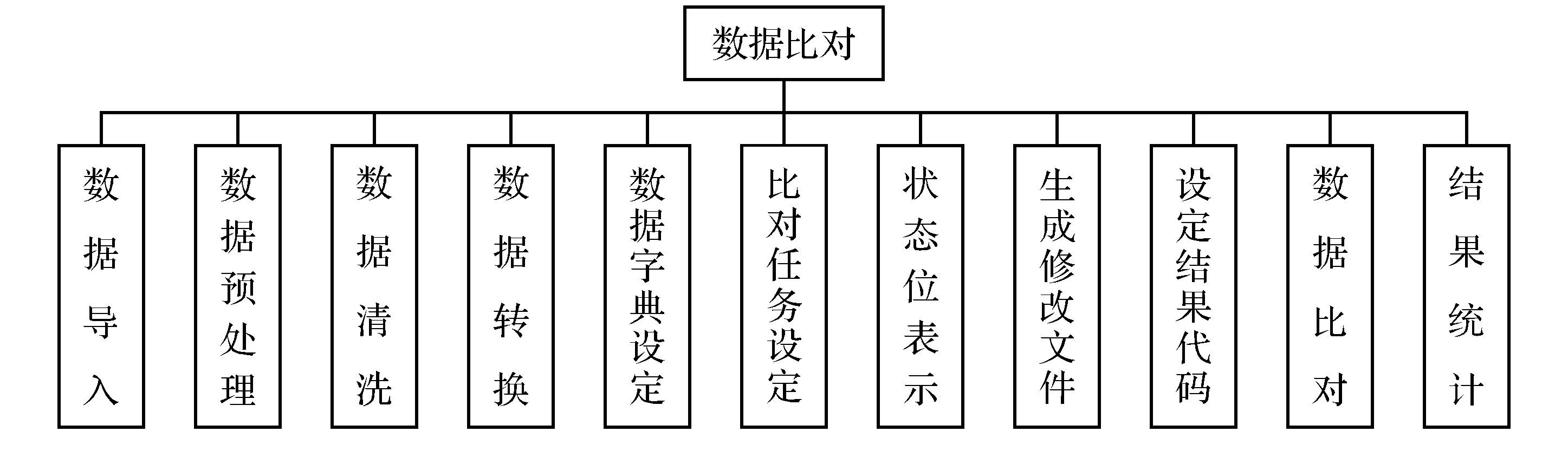
图4 比对功能模块Fig.4 Comparison function module
4.4.2 数据导入
将不同数据报文按照约定格式导入数据库。对于数据库数据文件、数据库备份文件等有针对性的数据文件,必须先通过人工转换为规定格式后再导入。
4.4.3 数据预处理
数据预处理主要包括:存在导致SQL语句出错的记录;按照约定建主键(在非关系型数据存储时很难对主键进行约束);按照约定提供相应的字段(在业务单位提供数据时有可能没有按照约定的字段提供);对非空字段的检查;设置问题数据过滤规则,清洗掉存在明显错误的数据;按照数据比对预定的数据格式进行相应的数据转换;对可能出现的虽然表述内容相同,但表示形式不统一的数据项,预设定转换规则,进行有针对性的转换。
4.4.4 数据字典设定
对数据库中的元数据(表、字段)进行说明性的描述,建设数据字典。
4.4.5 比对任务设定
比对过程设定,并保存比对设定任务。从数据库系统中提取相应的元数据对象描述信息(图5),确定比对源表和目标表,指定一个或多个组合比对关键字,设定数据映射关系(图6),确定比对数据范围,将设定信息以XML格式保存(图7),并确定为相应部门的比对任务,留以备用。
图5 获取数据库表、字段等元数据信息
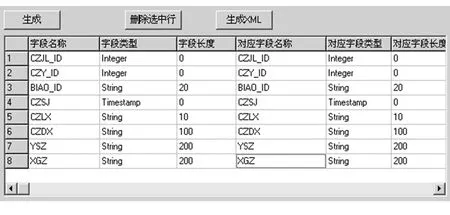
图6 设定比对数据的映射关系Fig.6 Set the mapping relationship of comparison data
4.4.6 比对过程的状态位表示
对每条数据进行过程状态的设定,在每步操作结束后,状态标志也相应地变化,而且状态标志有权数大小限制。对于低级状态标志的数据不可进行跨级别的数据比对,这样对有比对先后顺序的数据可以进行有效的顺序控制。
4.4.7 比对结果设定与统计
按照比对过程中可能出现的错误,预置结果代码,并按照代码进行比对结果统计。
5 结 语
大数据是未来智慧城市、城市大脑建设的基础,而面向政务服务的跨部门数据应用则是解决市民“一站办理”“一窗办好”“让数据多跑路,市民少跑腿”的关键。面对众多部门的多种业务领域的既有业务流程和专业数据,如何消除信息孤岛和信息烟囱,保证共享数据的准确性和及时性,都将是数据归集和数据共享工作面临的重要问题。针对此问题,借助对市民卡工程建设过程中出现的数据比对和跨部门的数据共享问题的深入研究和分析,提出了跨部门数据之间存在的产权关系,形成了模式化的比对流程,建立了基础的比对模型,为市民卡系统的数据建设奠定了基础并提出了理论依据。这对跨部门的数据归集和共享,及对其他城市信息化建设的数据处理起到了借鉴和参考作用。

图7 比对任务设定文件(XML)Fig.7 Comparison task setting file(XML)
