面向时变需求的多等级急诊患者入院控制
2022-08-25王子翔刘玉欣杨之涛
急诊部拥挤、病床资源紧张的现象在大型三甲医院经常出现,其原因十分复杂.首先,急诊不能采用预约机制,在一天的不同时段患者到达速率高度时变且不确定.同时,急诊患者的病情繁杂且有轻重缓急区别.进一步,每个患者占用医疗资源的时间具有不确定性,例如使用病床等医疗资源的时间不确定.这些复杂因素给急诊部服务管理和调度造成困难.
抢救室是急诊部的核心科室,而床位是抢救室最关键的资源,其使用的科学性与否直接影响对患者的救治是否及时、是否能做到对患者“应收尽收”的医疗原则.因此,急诊部需要在预诊时对患者病情进行分级,对病情严重的患者优先接收;对病情相对不紧急的患者根据资源占用情况选择性接收,即进行科学的入院控制.本文称前者为“危重患者”,后者为“非危重患者”.抢救室床位资源有限,如何通过合理的手段,对不同等级的患者加以控制,以提高患者健康回报和医院收益,是抢救室面临的重要问题.由于抢救室患者一般允许的等待时间很有限,所以当患者到达时需要实时决定是否接收.但是现实中做出科学实时的入院控制决策具有很大的难度,这是由于后续患者的到达、患者占用资源的时间都是高度不确定的,接收过多非危重患者导致床位不足,将可能影响后续危重患者的接收;接收过少则可能造成床位资源利用率不高,影响整体的医疗服务质量和收益.因此,抢救室需要科学的患者入院控制方法和策略,以提升整体运行和服务水平.
抢救室入院控制是医疗服务准入控制问题的典型场景之一.医疗服务准入控制是指针对待服务患者,对医疗资源(床位、检查设备等)进行动态分配调度,确定何种患者在什么时间可以获得医疗资源和服务,其主要研究方法包括Markov决策过程(MDP)、随机规划和近似动态规划等,其主要对象分为对非预约患者和预约患者的准入控制.首先,很多文献对非预约患者进行了服务准入控制研究.文献[1]针对突发事件后的入院控制问题,考虑时变的到达率和奖励函数,建立连续时间MDP模型,并通过状态离散化的方式进行求解.文献[3]考虑质子治疗场景下治疗组合的比例约束,通过聚合MDP模型,求解获得近似最优的患者入院策略.文献[5]为提高资源利用率和降低服务成本两方面的目标,提出了双目标随机优化模型,在不确定的需求和能力下取得资源利用率和服务成本之间的最优均衡.文献[4]针对不同紧急程度患者的入院控制问题,提出了一种配额策略,在获得需求信息之前决定最大日接纳量,并证明在特定条件下该策略等价于已知需求信息的最优策略.文献[8]考虑紧急患者和预约患者竞争的入院控制问题,证明了最优配额策略呈现单调性.文献[2]则研究患者到达及病情演变均不确定条件下的入院控制问题,建立资源动态分配的MDP模型,并通过粒子群算法进行求解.文献[9-11]进一步考虑了重症监护室场景,在拒绝新来患者和让患者提前出院之间取得平衡.
除了随机非预约到达患者,目前对预约患者的准入控制也有较广泛研究,主要包括对患者的预约调度和手术择期等研究.对于医疗检查资源的预约调度问题,文献[12]考虑爽约率和到达率不同的多类患者,利用分层算法框架求解.文献[7]针对择期手术决策问题,通过近似动态规划求解,仿真显示算法结果使得医疗系统运行效果得到改善.文献[13]针对择期患者入院控制问题,建立混合整数规划模型,求解多种资源、多个时间段和多类患者的准入控制问题.文献[14] 针对多台设备多类患者场景的检查资源预约调度问题建立MDP模型,求解使得收益最大化.
净压力决定裂缝的宽度,长度、高度,压裂施工中裂缝的净压力随地应力差的增加而增大,理想的裂缝高度是压裂目的层的厚度,实际上裂缝高度完全取决于压裂目的层的净压力与其上下隔层的应力差。一般认为,如果该压差大于5 MPa会对裂缝的垂向延伸起遮挡作用,净压力与隔层应力差小于5 MPa压窜顶板的风险加大,压窜顶板后裂缝沿着顶板水平延伸影响邻井产气量。
本文主要采用MDP方法进行患者准入研究.虽然如上所述的MDP方法已经在相关问题得到了运用,但本研究的抢救室准入控制问题和以上文献有显著区别,针对抢救室这个具体场景下的准入控制问题,本文的研究对象和基本假设都有别与已有研究.
(1) 传统基于MDP的患者准入研究假设提前设定了决策时刻或时间槽长度,如每隔10 min决策一次,两个决策时刻之间(10 min长度内)不做任何决策,以简化模型和求解.而本文突破以上设定,允许时段内发生多个事件且进行多次决策,即患者到达时立即根据系统状态做出相应的决策,更加符合抢救室的实际运行需要.
(2) 传统MDP患者准入控制模型设定系统只有在决策时刻才会发生状态变化.因此需要对系统的随机特征加以近似和限定,例如一般假设服务时间虽然是随机量,但是离散为时间槽的整数倍.本文的MDP模型中突破此约束,允许各个随机量具有连续随机性,更加符合实际的随机特点.
(3) 传统MDP模型由于设定了特定的决策时刻,为了获得好的效果必然要求决策时刻密集,且对每个决策时刻均求解出一个决策策略,因此最终得到很多决策策略.本文突破此模式,针对一个较长时段求解得到统一策略且不限制决策时间,如此更好满足了急诊抢救室运作管理的需要,提高了研究成果实施可行性.
1 问题与模型描述
若危重患者出院,转移后状态为′=(,, 2),转移概率为(+1);若非危重患者出院,′=(+1,-1, 2),转移概率为
这里的A和B是为了方便表示,分别指信标节点和普通接收节点.令A在t2n-1时刻的坐标为PA(t2n-1),B收到广播信号的时刻是T2n,相对于A的实际时刻是t2n,这里dAB(t2n-1-t2n)= ‖PA(t2n-1)-PB(t2n)‖.
(1) 急诊室床位总数为,每个床位可视为此服务系统中的“服务台”.
(5) 根据合作医院提供的数据统计拟合,设定两类患者的医疗服务时间,即其占用床位的时间,分别服从给定参数为和的指数分布.
(3) 两类患者到达速率的时变性质,参考现有文献[16],将一个较长决策期等分为个时段,每个时段长度为.例如合作医院的数据中=24,为1 h.

(2) 患者实际病情复杂多变,根据我国卫生部2011年发布的急诊病人病情分级指导原则,急诊患者可分为4个等级,其中需进入抢救室抢救的患者可分为两个严重等级,本文称为危重患者和非危重患者.
(6) 采用合作医院的基本收治规则,即当系统有床位空闲时,若危重患者到达,则必须本着“应收尽收”的原则加以接收,分配床位;若非危重患者到达,则可以接收,也可以拒绝接收.当床位已满时,就不再接收任何患者.
(7) 假设接收患者会产生确定的正收益,拒绝患者则会产生相应的负收益.接收一位危重患者和非危重患者的收益分别为和;拒绝一位危重患者和非危重患者的损失分别为和注意此处的收益并非仅指经济收益,而是考虑了患者救治难度、患者转院风险、医院经济收益以及社会责任等因素的综合性指标.
本研究寻找科学的策略集合,使得时变需求下患者的入院控制问题最优,即求解每个时段的患者入院控制策略,在每个时段内使用对应的最优策略,以实现一个较长时域内(例如24 h)总收益最大化.在一个时段内患者随机连续到达,患者每次到达需要实时决策,这造成本问题中一个时段内虽然策略是确定的,但是决策的时间点和次数不确定.同时,本文放弃了类似研究常用的“时间槽”概念,设定患者的到达是随机且速率时变的,每次到达实时决策,这样的设定更加符合实际情况,同时也更加具有挑战性.
以上决策问题可以通过有限期无折扣的MDP模型来描述.本文建立的MDP模型主要包括4个元素,即系统状态、决策集合、状态转移概率和收益评估.
◎没超过39℃可以不用退热药,自己在家观察、物理降温就可以了。超过39℃要就医,预防高热惊厥,一定要使用退热药。一般用布洛芬(美林)。对乙酰氨基酚(百服咛、泰诺林),别名扑热息痛,也是可以用的,WHO也是推荐使用,但中国乙肝高发,所以在中国建议1岁以下慎用。
1.1 系统状态
定义系统状态为=(,,),、分别为当前系统中危重患者和非危重患者数量;为系统当前事件性质,取值0,1,2分别表示“危重患者到达”“非危重患者到达”和“无患者到达”,其中“无患者到达”包括“患者出院”和“系统自转移”(系统自转移见下文13节定义)两类事件考虑到系统人数不超过,因此状态总数为

(1)
1.2 决策集合
考虑患者到达时的决策包括“接收”和“拒绝”.根据本文假设,在某些状态下,其对应决策集只有一个决策,如床位占满时,只能拒绝患者;有空床且危重患者到达时,只能接收.需要指出,无患者到达时,无需进行决策,即定义为 “空决策”,不产生收益或损失.综上,定义决策集为={0, 1, 2},其中0表示拒绝患者,1表示接收患者,2表示空决策若一个时段内各个状态对应的决策均确定,则称该时段策略确定,任意状态对应决策()可由该策略给出,即对任意有() =()
1.3 状态转移概率
相关MDP文献一般是将决策期划分为多个等长的时间槽,假设事件发生的时间间隔是离散随机,即为时间槽的整倍数,从而将模型简化为决策时刻和系统状态转移均只发生在每个时间槽端点.但由于本研究中患者到达时间和服务时间均为连续随机变量且需要实时决策,所以,使用均匀化方法将系统事件发生时间离散化.对于一个连续时间马尔科夫链,令表示其最大转移速率,则系统在时段内发生事件数量()服从参数为的泊松分布,例如,发生事件数量为的概率为

(2)
那么,若系统当前状态为,发生一次事件后转移到的概率为
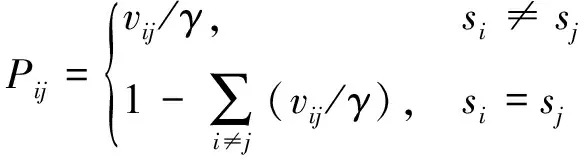
(3)
式中:为系统从状态到状态的转移速率当=时,表示状态不发生改变,即系统自转移.
针对本文研究的系统,其最大转移速率可定义为
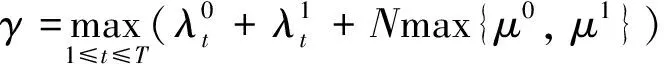
(4)
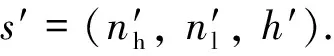
危重患者到达且接收,即=0,=1
本文则在对企业战略管理、企业总体经营战略、企业生命周期等相关理论进行总体简单概述的基础上,结合河南省许昌市胖东来商贸集团由创业期转向企业成长期以及企业成长后期这两次经营战略调整的经验教训,提出了企业的首要发展目标是成为一个长寿企业,而非把企业做大做强,即企业首先要致力于成为一个500年的企业,而非成为世界500强。文章在此观点上,进一步提出了企业实现长期可持续发展的一些对策和建议。
黏土砖必须在砌筑前1 d浇水湿润,一般以水浸入砖四边1.5 cm为宜,含水率为10%~15%。常温下施工不得干砖上墙,雨季不得使用含水率达饱和状态的砖砌墙。
该决策的条件为+<接收患者后,=(+1,, 2)接收后,可能发生的随机事件如下.
首先考虑单步收益,即在某一状态下做一次决策所能获得的收益.对于同类型患者,接收或拒绝的收益是确定而唯一的.若时段状态=(,,)采取的决策为,则一次决策后的单步收益可以记为

(2) 患者出院.
本文聚焦急诊抢救室床位资源,研究如何通过科学的手段,将有限的床位分配给不同等级的患者,即当患者到达抢救室时,按照何种策略决定是否接收该患者,以提高对患者的服务水平并提升医院的综合收益.针对急诊抢救室入院控制问题,本文根据合作医院的调研情况和实际数据做出以下几点假设.
(3) 自转移.
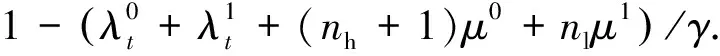
综上,该场景下状态转移概率可由下式表示:
(′|,)=
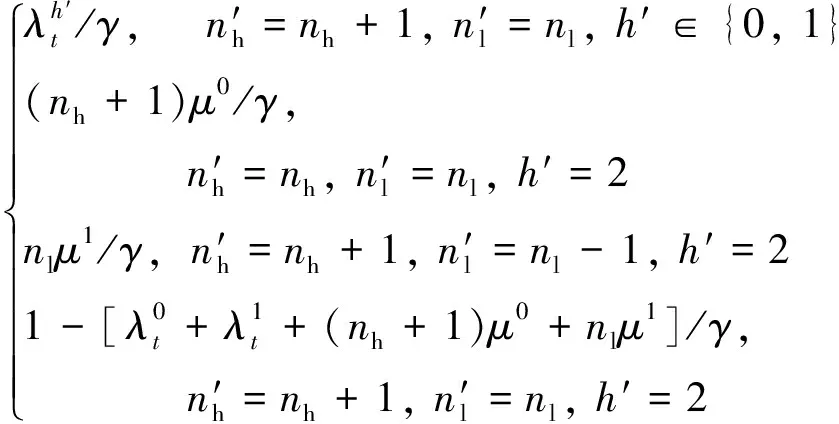
(5)
非危重患者到达且接收,即=1,=1
该决策的条件为+<接收患者后,=(,+1, 2)接收后,同上分析可得该条件下的状态转移概率为
(′|,)=
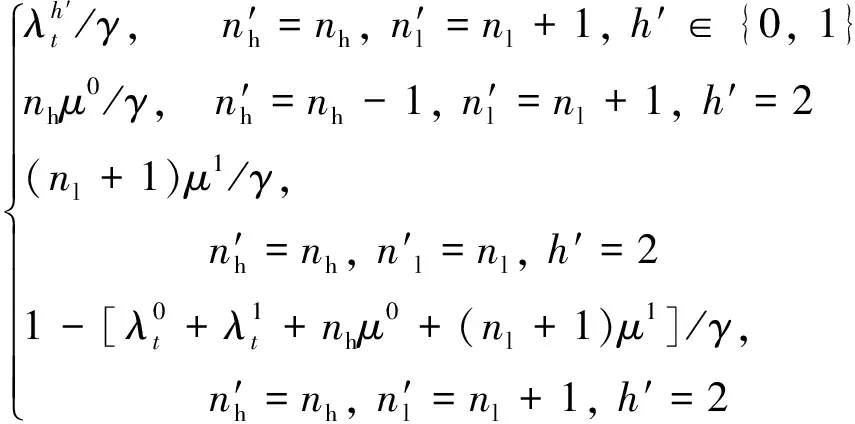
(6)
患者到达,决策为拒绝或无患者到达,即=0或= 2
对于危重患者到达,该决策的条件为+=;对非危重患者,决策条件为+≤;无患者到达时,采取空决策决策后状态均为=(,, 2)拒绝后,同上分析可得该条件下的状态转移概率为
(′|,)=

(7)
对其他未讨论情况,有(′|,)=0.
以上为发生一次事件时的单步状态转移,而当时段内策略确定,即每个状态对应的决策随之确定,场景1~4的单步状态转移可表示为二维状态转移矩阵;给定时段初状态分布(即处于各状态的概率)= [,1,2…,]后,若该时段发生事件数为,则时段末状态分布为(),而根据均匀化方法,发生事件数服从泊松分布,由此可利用函数(,)计算时段末的系统状态如下:

(8)
在系统状态+1中,状态对应的概率+1, 记为(|,),即时段状态转移概率,表示时段初系统状态分布为,采用策略,+1时段初处于状态的概率由于当事件数较大时,其发生概率e-()!接近于0,在数值实验中将其截断,给定事件数上限,从而只对∈[0,]求和即可,下文类似.
此处引入状态分布是必要的,一方面是均匀化方法的需要,另一方面,本文目标为求解每个时段的患者入院控制策略,即该时段每个状态的最优行动.经典的MDP仅需要分别确定每个状态的最优行动,不需要同时考虑其他状态.然而本文场景下,时段内决策次数不确定,在时段内可能转移到其他任何状态.如果分别从每个状态出发计算策略,则可能在不同的状态下得到不同的策略,这与本文要求冲突.因此,需要在时段开始设定状态的分布,利用分布计算并得到时段的唯一最优策略.
1.4 收益评估
经典MDP模型为每个决策时刻确定最优策略,不同决策时刻策略往往不同.本文是为每个时段确定最优策略,即本时段内每当患者到达抢救室,均采用此策略决策,最终实现决策期(个时段)内总的收益最大化.由于每个时段内的决策时刻和决策次数是不确定的,因此,本文在决策时所考虑的收益也区别于经典MDP,经典MDP考虑一次决策后获得的“单步收益”,而本文需要考虑一个时段内“多次决策的总收益”.本文通过均匀化方法进行收益评估.
(1) 患者到达.
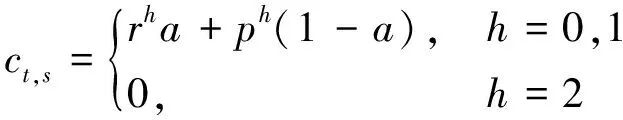
(9)
文献中一般是将决策期划分为多个固定长度的时间槽,假设事件的决策时刻均在时间槽端点,进而最大化逐点的收益之和.在本文研究的场景下,系统事件发生的时间间隔是连续随机的,不一定为时间槽的倍数,因此需要对收益评估做出调整.给定时段初状态分布,当该时段策略确定,单步状态转移矩阵确定,由式(9)可知,每个状态在决策后能够获得的单步收益也随之确定,记为向量= [,1,2…,]若时段内系统未发生转移,则收益为0;否则,系统发生第(>0)次转移后的收益可表示为()-1,则根据均匀化,时段内的总收益可通过函数(,)计算如下:
=(,)=

(10)
1.5 经典有限期MDP模型对比分析
以上构建的MDP模型与经典有限期MDP患者准入控制模型存在着显著区别.① 经典MDP模型存在确定的决策时刻,而本模型的决策时刻为患者随机的到达时刻,更加满足实时决策的需要;② 经典MDP考虑相邻决策时刻之间的单步状态转移,本模型考虑逐时段之间的状态转移,且是基于均匀化计算状态分布之间的转移;③ 经典MDP通过对每个决策时刻收益累加计算总收益,本模型则通过均匀化累加每个时段收益来计算总收益;④ 经典MDP 模型通过确定每个决策时刻的策略来最优化目标,而本模型通过确定每个时段的统一策略来优化系统.
2 算法设计
首先从经典有限期MDP的Bellman最优性方程引入本文计算方法:

(11)
式中:()为决策时刻状态的最优价值,即在时刻从状态出发,按最优策略决策,直到决策期结束时所能获得的总收益由式(11)可知,为了最大化状态价值,需要综合考虑当前单步收益(,)和未来期望收益,当前状态和未来状态通过状态转移概率(′|,)联系.
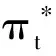

(12)

大学生旅游消费具有以下特征:①在价格上,给予学生足够的优惠,旅行社所负担的饮食住行等方面以中档为主,在降低成本的基础上注重学生的消费体验。②在学生专线的选取上符合学生的心理:路线短,时间短,名气大。③严格保证旅行的安全。
根据状态价值定义以及式(12),本文提出Bellman最优性方程如下式所示:
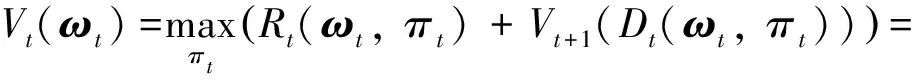
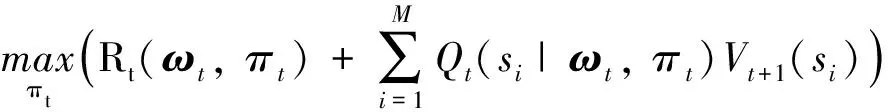
(13)
需要注意的是,经典Bellman方程式(11)中是分别对每个状态做出最优决策.但是本文Bellman方程式(13)考虑逐时段的递推关系,一个时段内可能会发生多次状态转移.根据式(10),要得到整个时段的总收益,须确定该时段完整的策略,因此不能分别求每个状态的最优决策,而是针对时段初状态分布,直接确定时段内最优策略.
为最大化决策期的总收益,本文基于Bellman最优性方程式(13)设计了双向迭代算法,确定每个时段的最优策略,即得到包含个策略的策略集合.由于该算法复杂度较高,无法应对大规模问题,所以进一步提出逐时段策略迭代算法.另外,为便于实际应用,设计了双向阈值迭代算法来求解最优阈值策略.
对各种地理水纹记号进行汇总、划分、归类后,引入视觉传达艺术的设计方法,并融入我国传统水文化中的创意元素,进行图形设计,填补地理水纹记号的空缺;然后依据我国水利信息化的要求,进行数字化处理;最后再对整理后的结果进行处理,向水利信息化靠拢,最终形成一套完整的系统。
1)从模拟施工过程的变形数据和现场监测数据相比较而言,模型变形规律还是比较接近于现场数据,拟合度较好,三维模拟可以为施工提供参考.
2.1 双向迭代算法
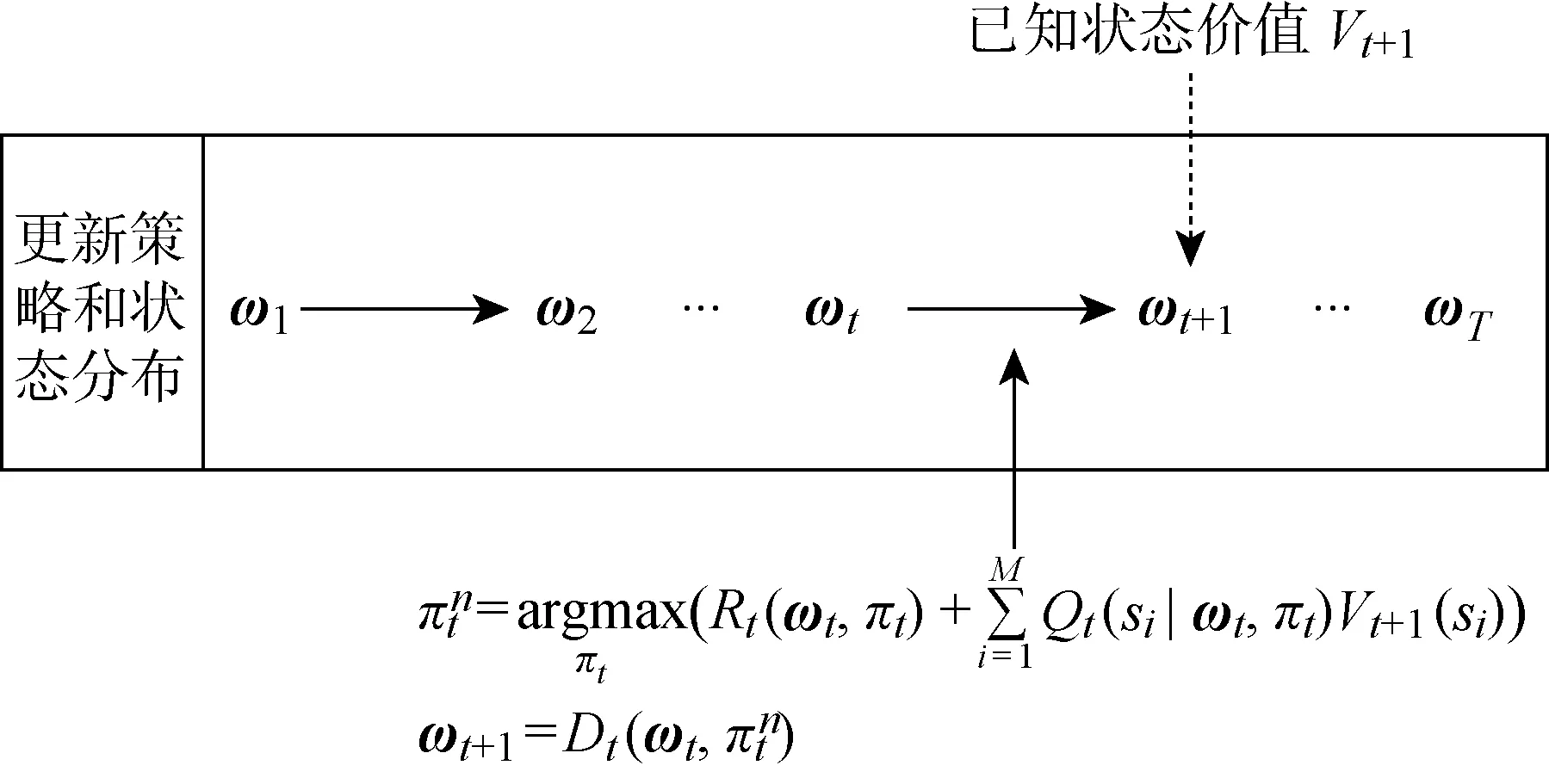
由式(8)可知,给定决策期初始状态分布,若各个时段策略确定,则之后各个时段初的状态分布(=2, 3, …,)均可确定;再由式(13)结合()定义,可从时段向时段1方向依次计算各时段各个状态的价值() (=,-1, …, 1)经典有限期MDP采用基于Bellman方程的逆向迭代求解,但基于本文的Bellman方程式(13)无法实现这样的求解过程,其原因在于未知上一时段初的状态分布,从而无法评估时段内的收益和时段状态转移概率(|,);同时,若采用正向求解,也会遇到未知下一时段初状态价值的困难.因此,本文设计双向迭代算法求解每个时段的最优策略,其中,正向寻优以时段1为起点,基于逆向寻优得到的各时段状态价值向后逐时段寻找最优策略,并更新各时段的状态分布,如图1所示;逆向寻优以时段为起点,基于正向寻优得到的各时段的状态分布向前逐时段寻找最优策略,并更新各时段的状态价值,如图2所示;这个完整的过程称为一轮双向迭代.当相邻迭代中正向寻优所得策略不变时,算法收敛.



(2)()=0,∀,
初始状态分布
各时段策略
(1)双向迭代()
《实用心电学杂志》是由江苏大学主办,中国医师协会、中国心电学会等单位协办的心电学专业期刊。双月刊,大16开,双月28日出版,每期10元,2019年全年60元。2013—2018年过刊任选两年现仅需100元,快递包邮。
双向迭代算法
(3) 迭代编号=0
亳文化悠久丰富,特色鲜明,风格独具,这正是其走向世界的立足之本。亳文化以什么样的路径走出去一直是亳州市政府、企业等关注的焦点,研究表明,亳文化“走出去”必须改变单一路径,突出文化个性,培育地域特色品牌,推动彰显亳文化的产品走出去。

(5)=+1
(6)=1 to
▷正向寻优
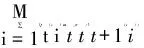

(9)
(10)=to 1
吴玉梅不得已,只得如实告诉他们:说杨力生和杨秋香是已谈过恋爱的。老两口一边仍然表示不同意,一边暗暗埋怨自己儿子眼光低下。
▷逆向寻优
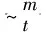
厂里正在落实公司精准培训工作要求,积极为青年人搭建成长锻炼的平台,通过导师带徒的方式,为每个人量身定制培养计划。俩人一拍即合,师徒关系就此结下。
由于会计信息化在一定程度上增强了财务风险概率。为此,企业要提高风险管理意识,全面地掌握住会计信息化特点,综合分析企业可能存在的潜在的风险,并且制定完善的风险管理机制。首先企业需知,信息系统具有很大的开放性,企业的信息数据会出现被不法分子所盗取或者更改,对此,企业需要建立专门的网络安全维护部门,安排专业的计算机人员,承担财务信息系统的运行工作,从而保障企业信息数据的安全,降低企业的财务风险与经营风险。
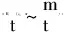

(13)
(14)
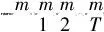
(16)

数值实验验证了该算法在小规模数据上的最优性,需要注意的是,在所有状态中,危重患者到达或无患者到达时,决策是确定的.只有当非危重患者到达时,可能的决策有两种,可得到每个时段内不同的策略共有2/3种,与状态总数呈指数关系.由于在算法1步骤7和11中直接遍历所有策略,显然该算法难以应用到大规模抢救室入院控制问题.
2.2 逐时段策略迭代算法
为求解大规模问题进一步提出“逐时段策略迭代算法”,求解近似最优策略.该算法从时段向时段1依次寻优,对每个时段,采取策略迭代算法,先随机选取一个策略,如先到先服务(FCFS)策略,再逐状态改进当前策略,直到相邻迭代所得策略不变,则该时段迭代过程结束,然后继续对前一个时段进行策略迭代,直到所有时段策略确定.数值实验显示,每个时段一般不超过4轮迭代策略即确定,而每轮迭代需评估的策略数仅为2/3,求解效率大幅提升.
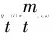
逐时段策略迭代算法
初始策略(如FCFS)
各时段策略
(1)逐时段策略迭代()
(2)+1()=0, ∀
(3)=to 1
(4) 迭代编号=0

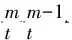


(8)=+1
(9)
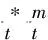


(12)

(14)
2.3 双向阈值迭代算法
考虑到抢救室入院控制实际应用时的便利性,本文设计阈值策略.阈值策略即为每个时段提供一个阈值,基于该阈值可确定该时段内的唯一策略.考虑两种阈值策略,空闲床位阈值策略和非危重患者阈值策略.
(1) 空闲床位阈值策略.
该策略基于系统中空闲床位的数量来决定是否接收非危重患者:当空闲床位数量大于某一阈值时,接收非危重患者;否则不接收非危重患者.
(2) 非危重患者阈值策略.
该策略基于系统中已有非危重患者的数量来决定是否接收非危重患者:当已有非危重患者的数量小于某一阈值时,接收非危重患者;否则不接收非危重患者.
阈值策略可采用上文双向迭代框架求解,本文称为双向阈值迭代算法.相比于双向迭代算法,只需将对策略的搜索调整为对阈值的遍历.双向迭代算法每个时段要遍历23个策略,而由于阈值范围有限([0,]),每个时段只需要遍历+1个策略,因此决策空间大大缩小,可应用于较大规模场景.
双向阈值迭代算法具体步骤如算法3所示.其中:为时段的阈值;(′|,)为给定阈值策略后,由状态分布转移到状态′的概率;(,)为从状态分布出发,根据阈值策略得到时段内的总期望收益;(,)为从状态分布出发,根据阈值策略得到+1时段初的状态分布+1
双向阈值迭代算法
初始状态分布
各时段阈值
(1)双向阈值迭代()
(2)()=0, ∀,
(3) 迭代编号=0
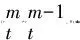
(5)=+1
(6)=1 to
▷正向寻优

(9)
(10)=to 1
▷逆向寻优



(13)
(14)

(16)
3 数值实验
使用上海某大型三甲医院急诊部的实际运行数据,首先利用处理后的小规模数据对双向迭代算法的最优性加以验证,再基于医院真实数据对比分析各个算法的实际性能,最后对床位数量进行灵敏度分析,为抢救室入院提供易于执行的控制策略和床位数量安排指导意见.为使用均匀化方法,截断了式(8)和(10)中无限事件数,设每个时段内最多发生事件数为=50,且通过实验验证了此设定可保证均匀化精度.数值实验采用的数据见网络材料 https:∥pan.baidu.com/s/1UaRkX-iXta2o4NBCgwthRw (提取码:jl48).
3.1 双向迭代算法最优性验证
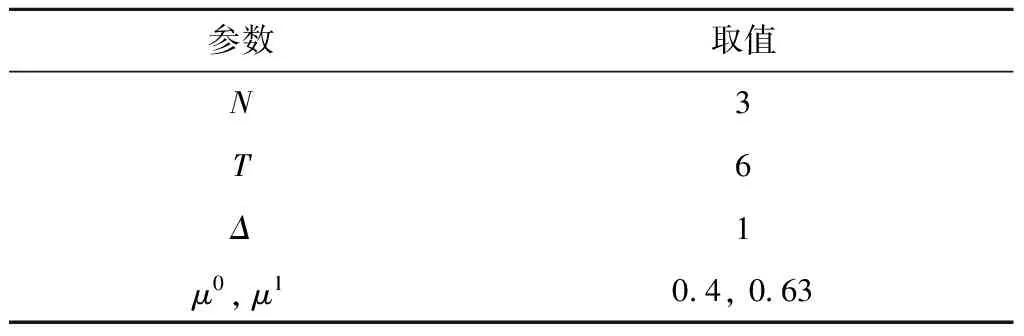
理论证明双向迭代算法最优性非常困难.但针对小规模问题可通过枚举法枚举出所有时段策略的组合,确定最优策略以及最大收益.因此,本文将双向迭代算法与枚举法在多组实验参数下的收益结果加以对比,进行最优性验证.由于医院原始数据规模较大,考虑缩短决策期和缩小状态空间来降低求解时间,使用医院采集数据中连续6 h且设置3个可用床位,在此基础上设置不同参数共计得到8个算例.算例中统一的参数设定如表1所示,算例间参数区别包括各时段到达率和单步收益(或损失),具体参数数值见网络材料SM-1节.求解结果如表2所示,由表2可见,双向迭代算法和枚举法的求解结果完全一致,数值结果支持双向迭代算法的最优性假设.

3.2 逐时段策略迭代和双向阈值迭代算法对比实验
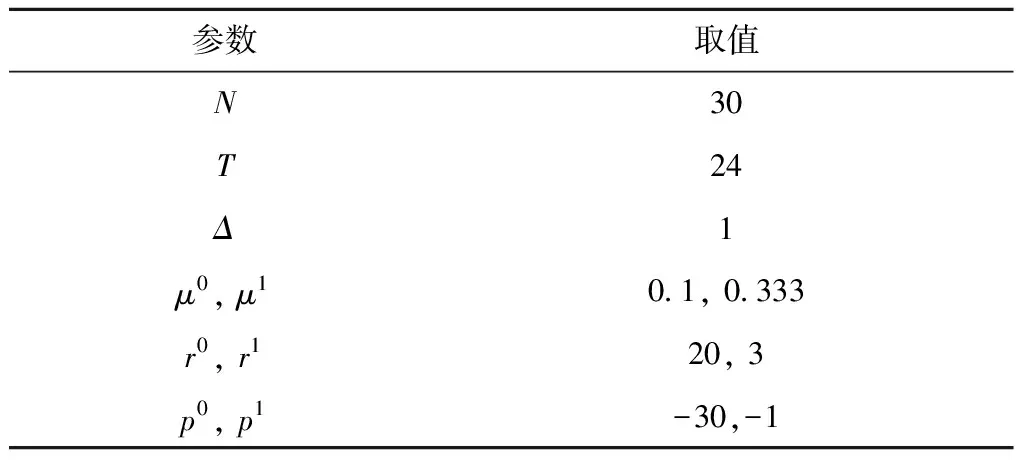
由于双向迭代算法复杂度很高,难以应对实际场景带来的大规模准入控制问题,利用逐时段策略迭代算法求解近似最优策略,并从易于实施的角度,采用双向阈值迭代算法求解两种阈值策略.本节以先到先服务策略为基准策略,记为K0,分别与近似最优策略(记为K1)以及两种阈值策略(记空闲床位阈值策略为K2,非危重患者阈值策略为K3)进行对比,每种策略均由仿真进行系统的性能评估,得到总收益和患者接收率指标.采用急诊部提供的实际运行数据,考虑长度为一天24 h的决策期,床位数目、服务速率等参数如表3所示(完整参数见网络材料SM-2节).
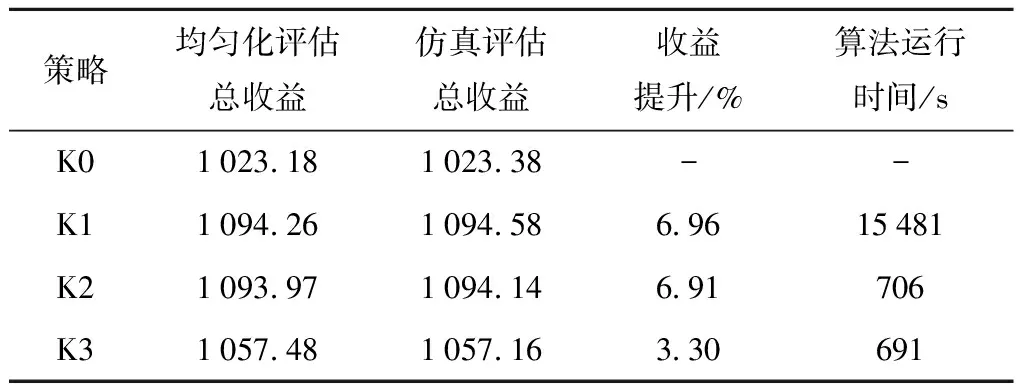
4种策略收益及效率的对比结果如表4所示,表中显示均匀化评估所得收益、仿真评估所得收益(仿真10d)、算法求得的策略相比K0的收益提升(“收益提升”列)以及算法运行时间(取算法运行5次的平均时间).由表4可知,在各个策略下,均匀化评估结果与仿真结果都十分接近,误差不超过0.03%,验证了均匀化方法的评估精度.不同的策略下收益表现有显著差异,K1取得了最高收益,相比K0提升6.96%;K2与K1表现非常接近,差距不足0.1%;K3相比K0提升了3.3%,表现不如K2策略.但从效率上看,K2和K3策略由于搜索空间较小,其求解效率远优于K1策略.综合来看,K2的求解结果和效率更具优越性.
除了总收益外,患者接收率也是抢救室关注的重点指标,尤其是危重患者的接收率.本文通过仿真统计3项患者接收率,分别为总接收率(即不区分患者类型的接收率,记为)、危重患者接收率(记为)和非危重患者接收率(记为).各时段平均接收率结果如表5所示,分时段接收率见网络材料SM-3节.相比于基准策略,本文优化后的3种策略表现有所差异,虽然均提高了平均危重患者接收率,但导致平均非危重患者接收率有不同程度的降低.K1和K2的平均危重患者接收率由95.6%提升到99.1%,提高了对危重患者的服务水平,且平均非危重患者接收率保持在84%以上.K3的平均危重患者接收率尽管也提高到98.1%,但平均非危重患者接收率降低较多不足80%.由此可见,即使在相同的参数下,采取不同的策略,对患者接收率仍有较大影响,本文提出的K1、K2策略在保证总体接收率合理的情况下,更大程度上提高了危重患者的接收率而具有优势.

由于抢救室重点关注危重患者,重点针对每个时段的危重接收率进行分析,如图3所示.基准策略K0在不同时段波动很大,整体接收率低,难以实现应收尽收原则.K1有19个时段的接收率在98%以上,K2也有17个时段的接收率在98%以上,验证了K2阈值策略的性能优势.且注意到K1和K2策略在24个时段中接收率波动较小,服务水平稳定.K3策略相比K0有所提升,但有13个时段的接收率在98%以下,难以达到医院要求.整体来看,本文求解所得3种策略相比基准策略都有较大提升,其中K3提升较少,而K1和K2提升显著,尤其是K2阈值策略,既有性能优势又易于实施,优势明显.

3.3 床位数量灵敏度分析
显然,床位数量越多,医院就可以接收更多的患者,达到更高的接收率.但是抢救室床位资源成本高昂,医护资源也有限,并不能无限扩增床位.因此本文对床位数量进行敏感度分析,讨论不同数量的床位对危重患者接收率及总收益的影响.
除床位数量外,本节采用参数均与3.2节相同.因K2策略结果与K1策略接近,且更具实际应用意义,本节采用K2策略进行分析,讨论在该策略下床位数量的影响.考虑∈[25, 35]的变化区间,总收益变化如表6所示.由表6可以看出,床位增加带来收益增加,但增长速度越来越慢,即增加床位的边际收益越来越少.

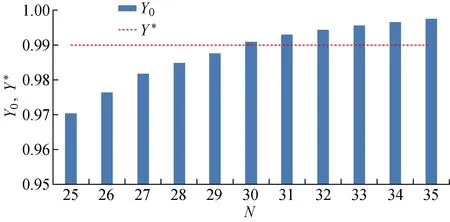
除了总收益外,抢救室还关注一天内危重患者的平均接收率随床位数量的变化.不同床位数量下接收率变化如图4所示.由图4可知,随着床位数量增长,平均危重接收率持续增长,但增长率逐渐放缓,直到增加到30张床位时,平均危重接收率达到抢救室目标值=0.99.基于在合作医院调研得到的床位成本,当床位数超过30时,增加的总收益低于床位增加成本.因此,在保证平均危重接收率达到目标危重接收率的条件下,较为合理的床位数量为30,此时既能满足危重患者服务水平的要求,又控制了总投入成本.
4 结语
针对急诊抢救室床位资源紧张的问题,提出根据患者病情严重及紧急程度选择性收治患者.建立了MDP模型,考虑到到达率的高度时变特性,使用均匀化方法逐时段进行离散化并求解每个时段内的最优策略.提出了求解最优策略的双向迭代算法和求解近似最优策略的逐时段策略迭代算法,实现了在较大规模数据和较长决策期场景下的应用.为了易于在实际场景中实施,进一步设计了双向阈值迭代算法,高效地为大规模实际场景求解得到简单且有效的阈值策略.数值实验验证了双向迭代算法在小规模数据上的最优性,验证了近似最优策略以及两种阈值策略的效果,所提出的阈值策略性能与近似最优策略接近且易于实施,可以为抢救室床位管理提供有效指导.本研究方法虽可以对时变且随机患者需求等复杂条件的准入问题进行决策,但也存在一些局限.首先受限于迭代算法复杂度较高,难以应用于大规模问题,拟进一步采用深度强化学习等方法来提高求解效率.另一方面可拓展考虑对允许加床等更复杂的场景进行准入决策研究.
