集合预报在南盘江流域中长期径流预报中的应用研究
2022-08-24林志友张立飞吴钊平杨璐璘
林志友,张立飞,吴 巧,吴钊平,杨璐璘
(天生桥二级水力发电有限公司,贵州兴义,562400)
0 引言
行业上通常将预见期在3~10 d的预报称为中期预报,预见期在15 d以上、一年以内的预报称为长期预报。中长期水文预报具有较长的预见期,能使人们在解决防洪与抗旱、蓄水与弃水及各部门用水之间的矛盾时及早采取措施进行统筹安排,以获取最大的效益。
随着社会经济的不断发展及电力市场化改革的深入,对中长期径流预报精度的要求越来越高。要求能提供预见期长、准确性高的中长期预报,为提高来水预测综合准确率、提高调度综合水平及防洪度汛提供技术保障。
南盘江是珠江主源,发源于云南省沾益县马雄山南麓,流域面积56 880 km2,年来水量2.17×1010m3。南盘江干流全长914 km,总落差1 840 m,目前已建梯级水电站共15个,除天生桥一级、天生桥二级和平班为大型水电站外,其余均为中小型水电站。天生桥一级水电站水库总库容为102.57亿m3,为红水河梯级龙头水库,对下游水电站具有较大补偿效益。
近几年来,南盘江流域内的各条河道相继建设了很多大大小小的水电站,拦蓄了河道水流,严重影响了径流预报的精度。须研究南盘江流域的中长期径流预报模型,建立一种适用于南盘江流域的集合预报模型,为南盘江流域水电站优化调度运行提供科学的决策依据。
1 中长期预报模型
目前,中长期预报方法主要有成因分析方法、统计学方法及新的数学方法。成因分析方法主要有天气方法与天文地球物理方法。统计学方法主要有时间序列分析法、门限回归模型、最近邻抽样回归模型等。目前应用较为广泛的统计学方法是门限回归模型,该模型通过门限因子的分区实现了预报对象的分区线性描述,从而体现了水文要素的非线性特性。新的数学方法包括人工神经网络、支持向量机模型等。本次南盘江流域中长期径流预报对象是天生桥一级水库,预报模型为集合预报模型。集合预报模型是利用神经网络模型、门限回归模型、最近邻抽样回归模型、支持向量机模型等不同模型的优点,采用最优加权法形成的预报模型。
1.1 人工神经网络模型
人工神经网络理论是模仿生物大脑结构和功能建立的。水文资源分析计算中,应用最多的是BP网络模型,一般三层(一个输入层、一个隐层和一个输出层)。BP网络模型可刻画水文水资源研究对象。
受天体因素、降雨天气系统和流域下垫面系统综合作用的影响,长期径流时间序列是非线性、强相关、高度复杂、多时间尺度变化的动力系统。模型的参数率定也是一个复杂的优化问题,本系统采用了自适应遗传算法进行模型的参数率定。
1.2 门限多元回归模型
门限多元回归模型是具有广泛意义的一种非线性时序模型,实质上是以分区间线性回归模型来描述研究对象在整个区间的非线性变化特性。
水文水资源系统为一非线性系统。多元线性回归模型中自变量与因变量线性关系的假定不符合客观规律,门限回归模型就是为近似解决非线性问题提出的。
1.3 支持向量机模型
支持向量机方法建立在统计学习理论的VC维理论和结构风险最小原理的基础上,根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折衷,以期获得最好的推广能力。支持向量机方法的主要优点有:(1)专门针对有限样本情况,其目标是得到现有信息下的最优解,而不仅仅是样本数趋于无穷大时的最优值;(2)算法最终将转化成为一个二次型寻优问题,从理论上说,得到的将是全局最优点,解决了在神经网络方法中无法避免的局部极值问题;(3)算法将实际问题通过非线性变换转换到高维的特征空间,在高维空间中构造线性判别函数来实现原空间中的非线性判别函数,其特殊性质能保证机器有较好的推广能力,同时算法复杂度与样本维数无关,解决了耦合模型输入变量维数增加的问题。
1.4 最近邻抽样回归模型
最近邻抽样回归(NNBR)模型是一类基于数据驱动、不需识别参数的非参数模型。其基本原理是:客观世界的发生存在一定的联系,未来的运动轨迹与历史具有相似性,即未来发展模式可以从已知的众多模式中去寻求。根据研究对象不同,将NNBR模型分为单因子NNBR模型和多因子NNBR模型两种。
1.5 集合预报模型
人们常在选择一个较优预测值的同时舍弃另外的预测值,这是很不明智的,因为舍弃的预测值一般都蕴含某些有用信息;另一方面,任何时间序列模型的参数都不可能得到准确的识别,不同模型组合往往能得到较好的预测值。集合预报(EF)模型作为一种新的预测方法或途径,特别是应用于中长期水文预报,具有发展前景。
集合预报的提出就是为了弥补单个预测模型的片面性,从集结尽可能多的有用消息出发,充分利用不同模型的优点,使预测模型具有对环境变化的适应能力。目前常用的集合预报方法可以分为两类:(1)权系数组合预测法。在集合预报中,权重的选取十分重要,合理的权重会大大提高预测精度。常用的权重选取方法有最优加权法、均方倒数法、离异系数法等。(2)模型组合预测法。以各单一模型的预测结果作为输入,或考虑进系统预测因子的输入,再构造预测模型进行预测,常用的方法有最小二乘法、人工神经网络法、小波变换法等。
权系数组合预测法的一般形式为:

式中,Y′为预测值;Y为实际值;m为预测数据的个数。该方法也称为均方倒数法,是利用各个模型预测结果均方误差的倒数归一化,作为各个模型的权重系数。
1.6 模型自适应挑选技术
模型的自适应挑选建立在模型精度评定结果的基础上,考虑到不同的来水特性在不同时段均存在一定的差异,可根据不同时段前期各模型的预报精度进行排序,精度排名越靠前,组合权重越大。
根据各模型精度评定结果计算各模型权重,计算公式如下:

式中,Pw为精度排序为w的模型权重;w为精度排序(精度最高的排名为1,依次类推);m为模型个数;wj为第j个模型的精度排序。
南盘江流域中长期来水预报采用模型自适应挑选技术计算各模型综合权重。模型自适应挑选技术通过分析预报对象不同预报时段前期各模型预报精度,对各模型预报精度进行排序。根据模型智能筛选排序,计算各模型综合辨识权重,根据权重得出集合预报结果。模型自适应挑选流程见图1。
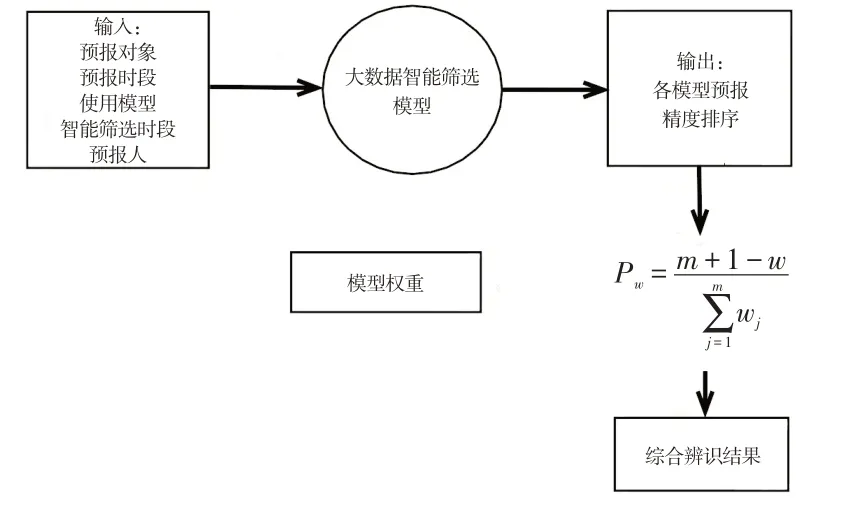
图1 模型自适应挑选流程Fig.1 Process of adaptive selection
2 中长期预报方案编制
本次预报方案制作过程中,结合南盘江流域来水过程及资料情况,把月预报和旬预报按自然月进行分期模拟。
2.1 预报因子选择
各时段影响预报流量的因子选择见表1。
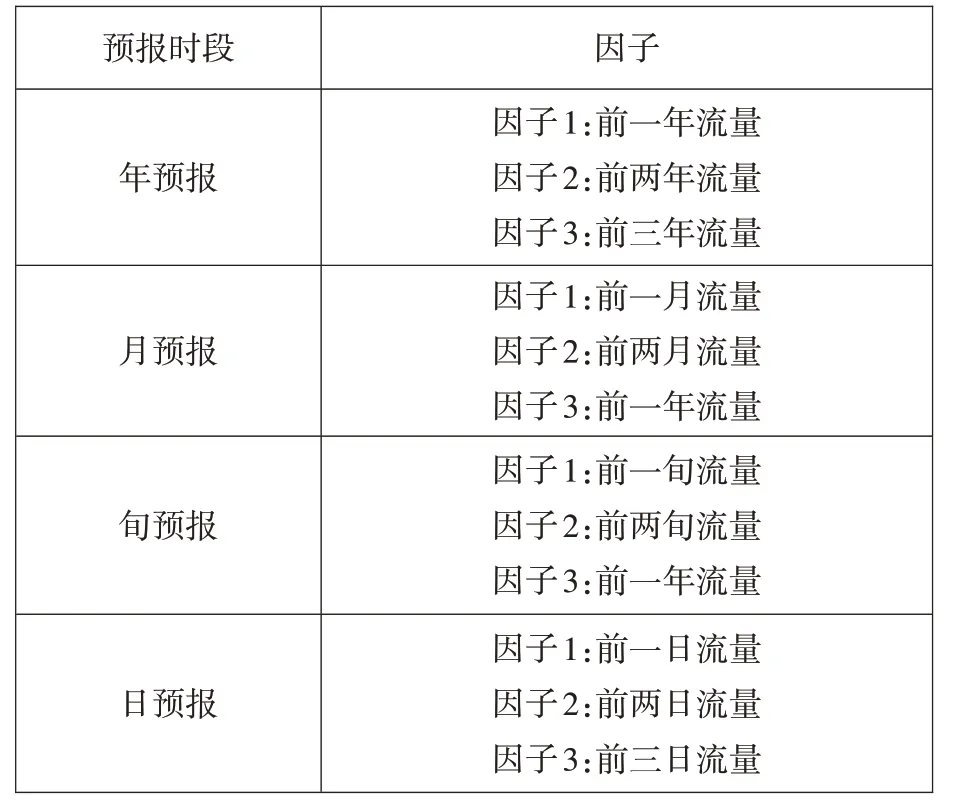
表1 预报因子Table 1 Forecast factors
本次中长期预报方案制作采用2015年前的数据率定模型参数,2015年后的数据用来检验。
2.2 预报方案编制
预报方案的编制流程见图2。

图2 预报方案编制流程Fig.2 The preparation of forecast plan
2.3 各模型模拟精度
根据样本对各模型参数进行率定,得到各模型对年、月预报径流的模拟精度,见表2。
本次中长期预报方案采用2015年后的数据来检验人工神经网络(BP)模型、门限回归模型、支持向量机模型、最近邻抽样回归(NNBR)模型、集合预报(EF)模型的预报精度,结果见表3。
由表2和表3可知,集合预报模型将另外四种模型进行组合后,避免了采用单个模型预报时出现的极端偏离情况,使预报更准确。采用集合预报模型时,中长期预报精度高达78%,接近甲等水平,满足指导实际生产应用的要求,因此南盘江流域中长期径流预报采用集合预报模型是可行的。
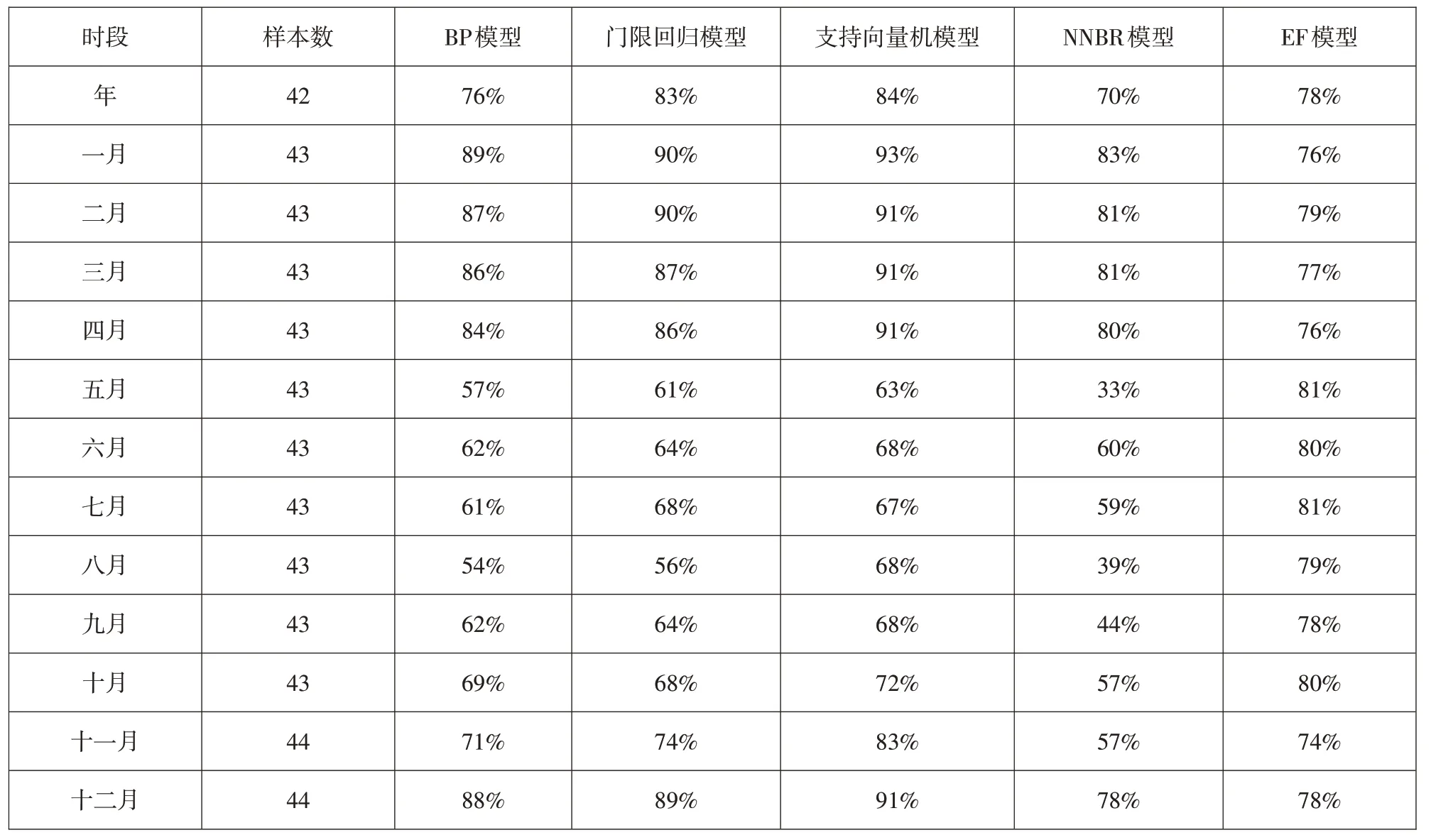
表2 各模型模拟精度Table 2 The simulation accuracy of each model
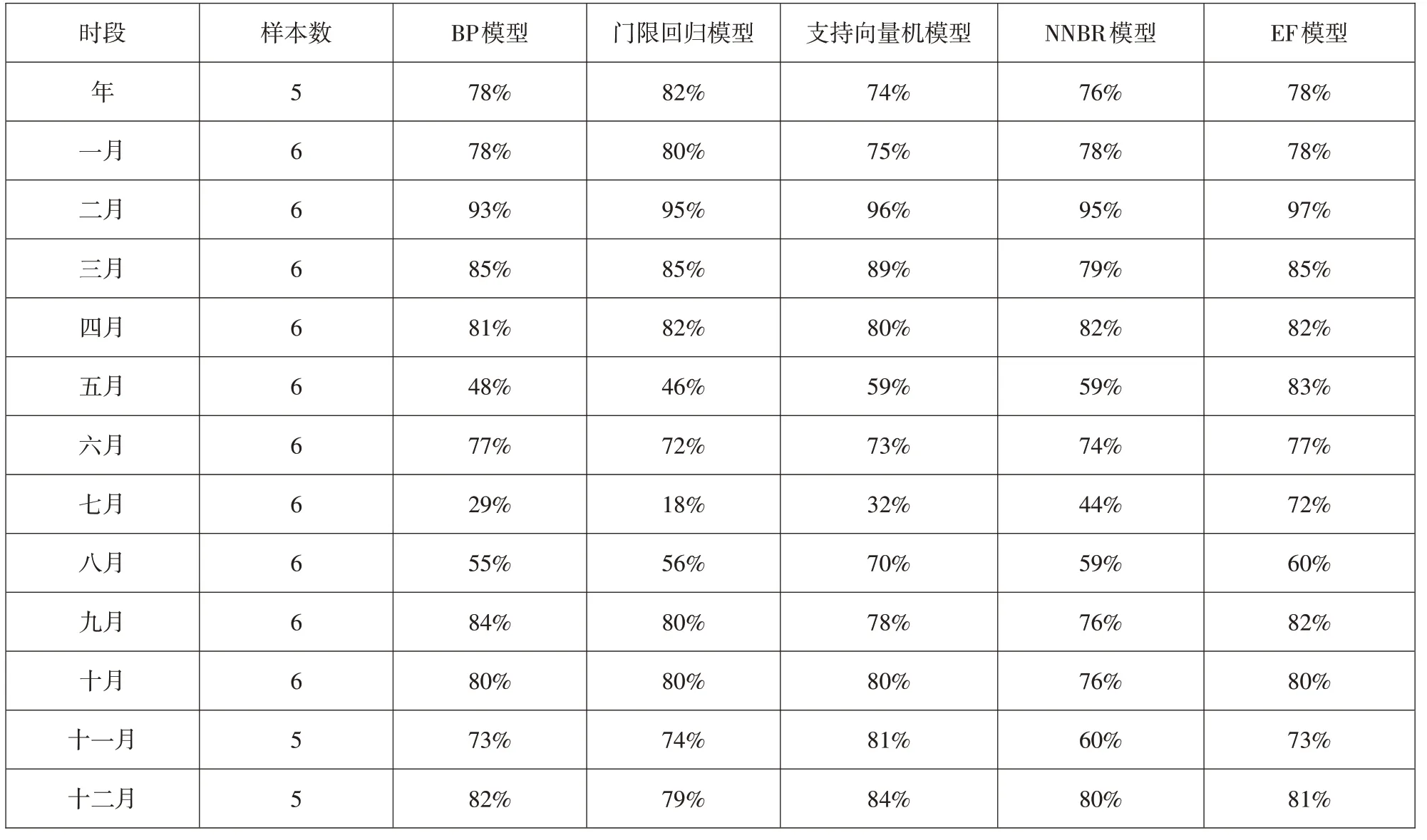
表3 各模型检验精度Table 3 The test accuracy of each model
3 结语
为了弥补单个预测模型的片面性,本次中长期预报方案制作以人工神经网络模型预测结果、多元门限回归模型预测结果、支持向量机模型预测结果和最近邻抽样预测结果作为输入,采用最优加权法进行权系数组合预测,建立了集合预报模型。该方法充分利用不同模型的优点,使预测模型具有对环境变化的适应能力。本次中长期预报方案可以为决策者实现水库的优化调度提供有利依据,保证南盘江流域中长期预报精度,以便更好地为水电站的优化调度服务。
本项目的研究成果为南盘江流域的中长期水文预报提供科学、有效的预测方法和技术支持,对提高南盘江流域水能资源的利用程度、降低电网调度运行的不确定性和电力供需平衡风险具有十分重要的意义。
由于长期径流的预测难度大,特别是在制定年度发电量计划时,需要制定高、中、低多个方案供决策者选用,故建议后期在预报软件开发时,进一步运用蒙特卡洛模拟方法,将不同来水量与概率相结合,为计算不同年度发电量目标的完成概率提供理论依据。
