改进决策树算法下高校财务管理与决策分析的仿真研究①
2022-08-24蔡晶
蔡 晶
(华侨大学财务处,福建 泉州 362000)
0 引 言
国内学者对高校财务管理决策系统的研究已取得了一定成果。文献[2]将K均值聚类算法引入到决策树的建立过程中,组建高校财务预警模型,在此基础上实现了高校财务管理决策。文献[3]利用该矩阵实现对高校财务的管理和决策,该算法能有效提升财务信息的分类效率,但是存在数据信息表意混淆,任意性较为突出的问题。文献[4]构建的高校财务模型预测精度较高,但存在预测时间较长的问题。基于此,提出了改进的决策树算法模型并引入到高校财务管理决策分析中。
1 决策树的基本思想
决策树结构实质是根据树状结构对目标数据记录进行统计分类,决策树每个叶节点表示某种条件下的特定数据记录集合,依据数据记录片段的取值构建树状结构的分支[5]。决策树的构建由多个节点和有向边组合而成。通常情况下节点可分为两种,一种是内部节点,一种是外部节点。内部节点由单个数据属性或是单个特征构成,可将其叶节点也考虑为某一类。决策树进行分类通常以根节点开始,其实就是对某种实例的单个特征进行测试,依据测试结果,将具体实例划分到具体的子节点上[5]。由此即可对具体实例进行有效分类,将不同类别的信息划分给叶结点的类中。
设定D表示事先设定的训练数据集:
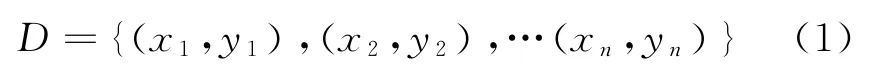
可将上述描述的决策树视为一个if-then规则的集合。由决策树的根状节点一步步连接叶节点的各条路径构造一条规则;所有路径的内部结点特征均有相应的规则约束,而决策树中叶结点的类别对应着规则的结论。决策树的每条路径均有相应的性质:即互斥但完备。
依据相关文献所描述的信息论可知,期望信息越小,相应的信息增益越大,对应的决策树模型精确度越高。决策树算法的在于:信息增益度量结果的属性选择即为最终的依据,并按照划分后信息增益最大的属性进行划分的,以下给出具体的实用概念。
设定D表示不同类别对训练样本集合的划分,D相应的熵可描述为:
民勤县地处甘肃省河西走廊东北部,石羊河流域下游,东、西、北三面被腾格里和巴丹吉林沙漠所包围,年降水量110 mm,无霜期157 d,属温带干旱气候,日照充足,昼夜温差大,为典型的旱作灌溉农业区。玉米是民勤县种植的主要农作物,年生产面积近0.67万hm2左右,产量12 750 kg/hm2。近年来,种植面积不断增大,重茬面积较大,品种严重退化,田间病菌虫害积累较多,严重影响着玉米产业的发展。2017年民勤县贤丰种业引进了玉米新品种科河699和大民3307,在红沙梁镇中沟村进行试验种植,鉴定新引进玉米品种的丰产性、稳产性、适应性、抗逆性及其他主要特征特性,为民勤县玉米新品种推广提供依据。
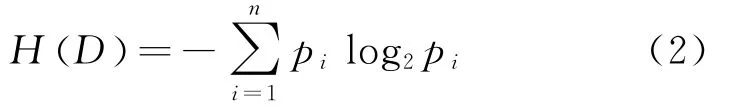
式中p i为第1个类别在整个训练样本集合中出现的概率,H D()是信息熵。设定将训练样本集合D根据属性A来划分,则采用A对D进行分类的期望信息可描述为:
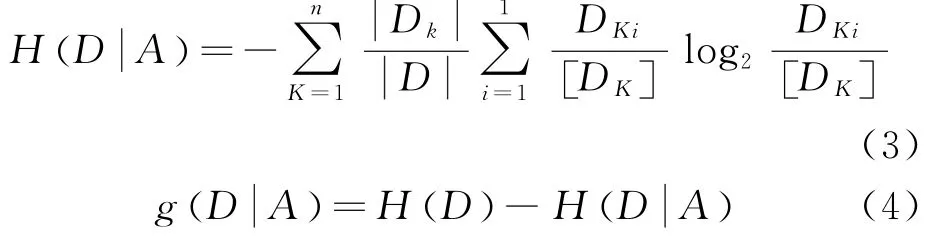
决策树算法实质是在每次分裂时,计算训练样本集合中各个属性的增益率,从中再选取增益率最大的那个属性进行分裂,分裂中设定当前决策树节点的数据记录数量小于一个给定阈值时则停止分裂的截止条件。
2 基于改进决策树算法的高校财务管理和决策优化分析
2.1 基于大数据的高校财务管理样本数据库建立
大数据对高校财务管理具有重要影响,有利于高校财务资源分配,强化财务预算管理。大数据在高校财务管理决策中最重要作用是预测,从当前高校财务管理实际来看,对财务数据的分析是根本,对财务数据的及时更新、均匀性良好的样本数据库是数据梳理的前提。但受到实际应用过程中众多因素的影响,传统的财务管理数据处理方式难以对基础数据进行快速抽取,导致高校财务数据分析不足。为解决上述问题,使用水库抽样算法来抽取样本数据,水库抽样算法能够有效解决传统财务时间处理局限,在不影响抽取精度的前提下,提供传统高校财务所无法提供的大数据样本形成能力。
进一步需要对原始数据库内的样本数据进行均衡抽取,产生样本投入到财务数据的分析中,所谓最大程度的均衡抽取就是保障每个数据类型被抽取的几率是等同的。
如果将f'er定义为原始财务样本数据,k代表均衡抽取的数目,在得到超出k的n个数目时候,利用公式(1)在已经扫描过的原始数据中均衡抽取k个数据:
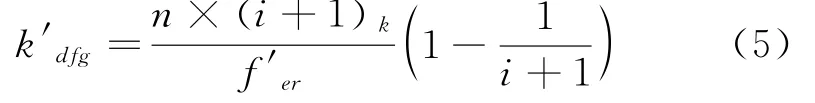
在式中,将(i+1)定义为接收数据的数量,定义为第i个数可以被抽取的概率。
在得到数据的数量为(i+1)的时候,可利用概率被代替,而是被第i数被选中的概率。两者的乘积为定义为第i个数被替换出数据组的概率。由此利用公式(6)将存储在均衡抽样数据组中的数据概率定义为时间发生概率的乘积:
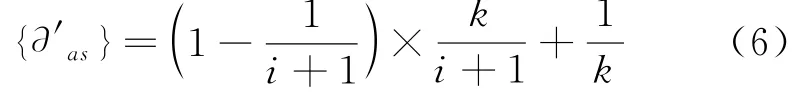
2.2 基于改进决策树算法的高校财务管理和决策分析
基于很多数据度量相似性的线性方算法都具有尺度不变性的最大特性。因此,在均衡的抽取数据信息样本的基础上,将MBDT算法引入到决策树的构建当中,设定度量阈值,对数据样本进行分类,给出决策树的逐层信息增益率,在此基础上构建高校财务管理决策的预警模型,完成对财务管理的优化分析。具体的步骤如下详述:
假设,可以将e定义为全部数据样本的训练集,∂″u是样本类别的数目,定义其分支准则,利用公式(7)表述:
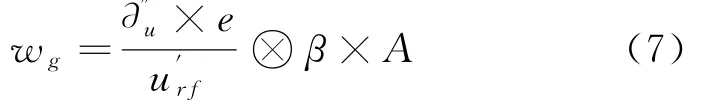
在式中,可以将β表述为交替的误分类阈值,A定义为一个属性的子集,将u'rf定义为没有类别的却含有不间断属性的集。
在一个由C∈T代表的集合中,将C定义为含有部分类别的财务数据信息样本。而b∈B代表相同属性的集合,假设X={x1,…x a}为C的样本在属性范围内的取值,如果该值为MBDT算法中的最小值,则将该样本纳入这个类型中,选取由b best∈B的属性集合为目标,使C的数据样本可以被精准分类。
假设t i样本被误分类到t j中的概率很大,并且其概率值要大于β,则视t i和t j为相同的类型,二者放到下层继续进行分类,利用公式(8)给出每层决策树的信息增益率:
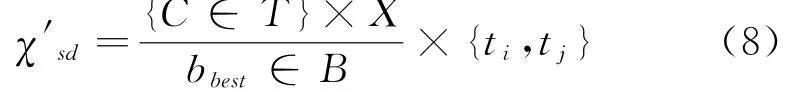
在进行决策树的构建过程中,其中一个重要的环节就是对数据信息划分,而其中信息增益率就是信息增益和其信息熵的比率。相互比较的是不同数据类型单位属性上的信息量。将信息增益定义为财务样本数据集划分最小单位子集的时候,对其变量进行取值的时候存在的误差。为了降低这种误差,采用下式对信息增益进行优化:
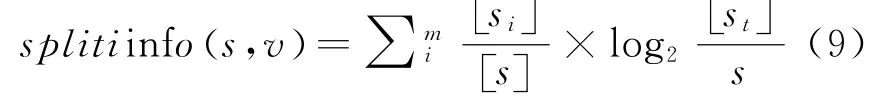
则利用公式(10)构建财务管理决策树:
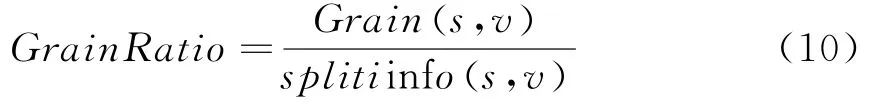
由此组建高校财务预警决策树模型:

在式中,d'gh为穷离散符号集。
3 实验与仿真
为了更好验证算法应用有效性,在Matlab7.1环境下搭建高校财务管理和决策的实验仿真平台。实验数据来源于某高校财务2011-2016年数据集。将其中40%样本数据作为测试集,其余作为训练集。
3.1 评价指标的设定
为验证算法对高校财务管理决策的性能,将实验分为两个部分,第一个部分将分类精度作为主观评价指标进行验证。将文献[6]算法作为对比算法,将拟合优度作为客观评价指标,定义不同算法进行财务管理和决策分析的优劣。
3.2 本文算法的分类精度对比
利用提出的改进决策树算法进行高校财务管理和决策分析实验。测试改进决策树算法进行高校财务管理和决策分析的分类精度,测试结果如图1所示。
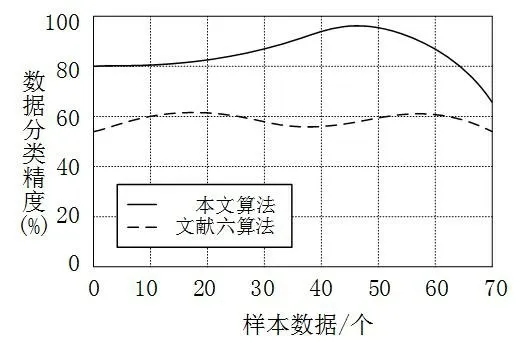
图1 本文算法数据分类精度
从图1看到,利用本文算法进行财务数据分类的精度较高,这是因为算法均衡抽取高校财务数据库中的原始样本数据,充分保证了高校管理决策系统对分类精度的需求。
3.3 不同算法的拟合优度对比
利用提出的改进决策树算法和文献[6]算法进行高校财务管理和决策分析实验。测试不同算法进行高校财务管理和决策分析的拟合优度,测试结果如图2所示。
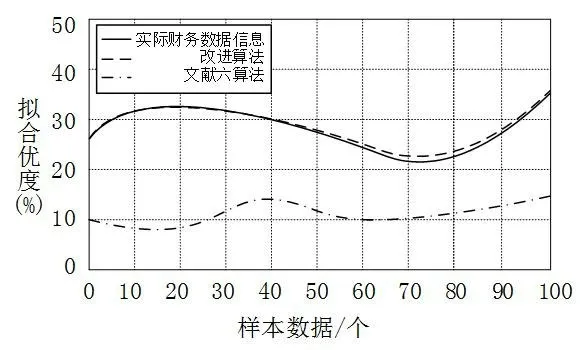
图2 不同算法的拟合优度对比
从图2看出,改名算法的拟合优度要高于文献[6]算法,是因为在利用算法构建高校财务管理决策系统时,将MBDT度量引入到决策树中,设定了分类阈值,细化了每层决策树的样本数据,由此构建了基于决策树财务预警模型,保证了算法进行高校财务管理决策分析的全面性。
4 结 语
很多高校管理者采用财务报表和历史经验对高校财务管理进行决策,无法满足社会信息化发展对高校财务管理提出的目标。为构建高质量的高校财务管理决策系统,提出了改进决策树方法的财务管理系统。实验仿真证明,提出的改进决策树算法具有较高的预测精度,在建设高校财务管理决策体系中具有重要的应用价值。
