基于深度学习模型的软件源代码归属研究①
2022-08-24任群
任 群
(亳州学院电子与信息工程系,安徽 亳州 236800)
0 引 言
自然语言文本的作者身份识别是一个众所周知的问题,已在文献中进行了广泛研究[1-2]。但是,只有很少的作品专门用于结构化代码中的作者身份识别,例如计算机程序的源代码[3]。源代码作者身份识别是通过基于程序员独特的样式特征将程序员与给定代码相关联的代码作者身份识别过程。然而,问题在于自然语言文本的作者身份识别是困难且不同的。这种根本的困难主要是由于编译器的语法规则所建立的书面代码表达式固有的不可读性。
代码作者身份识别依赖于根据程序员在结构化代码和命名变量中的偏好从程序员生成的源代码中提取功能。鉴于这些功能,代码作者身份识别的主要目的是根据提取的功能将程序员正确地分配给源代码。能够识别代码作者既是风险也是理想的功能。一方面,代码作者身份的标识给希望保持匿名的程序员带来了隐私风险,其中包括开放源代码项目的参与者,活动家以及在一边进行编程活动的程序员。因此,这又使代码作者的身份识别成为匿名问题。另一方面,代码作者身份的识别对于软件取证和安全分析人员非常有用,特别是对于识别恶意代码(例如,恶意软件)程序员而言;例如,此类程序员可能会将源代码留在受损的系统中进行编译,或者可能从反编译的二进制文件中提取程序员的功能。此外,源代码的作者身份识别有助于作者身份纠纷、版权侵权、和代码完整性调查。针对软件源代码归属问题,设计了一种基于深度学习的程序依赖关系图方法,目的是确定不同类型的源代码的真正作者。该方法可以用于任何编程语言且不遵循任何编程结构的方式设计特征提取。
1 软件源代码识别分类方法
1.1 程序依赖关系图
程序依赖关系图是源代码的图表示:编程表达式、变量、条件和方法调用可以用顶点表示,边表示图中顶点之间的程序和控件依赖性。程序依赖关系图G=(V,E,μ,δ)是一个四元组,其中,V是顶点集合,E是边集合,μ是定义顶点的类型函数,δ是定义边依赖类型的函数。
如果存在影响程序执行的变量var,则可以在v1和v2之间生成表示数据依赖的边。v1可以使用指针直接或间接传递给var,而v2可以使用指针执行var给定的值。因此,通过更改var值可以影响源代码的执行。
此外,控制依赖性显示了源代码的内部逻辑流。如果存在一个真值条件从v2控制执行v1,则可以生成从v1到v2的控制依赖边。
首先,从不同的程序代码中提取程序依赖关系图(数据和控制)特征。这些高质量的特征捕捉了数据变化和控制流功能,能表示不同语句之间的数据流动方式以及控件信息在不同语句之间的传递方式。这些重要特征可能会揭示不同程序代码的隐藏模式。
1.2 预处理和特征权重
接下来,使用了预处理技术将程序依赖关系图特征转换为没有噪声的小型实例。该过程将程序依赖关系图分解为词例,然后计算每个词例的频率。预处理步骤的第一步是数据清洗。数据清洗是指删除不需要的数据,例如特殊符号、数字、停用词和标点符号。在源代码特征分类中不需要此类噪音信息。然后,使用转换过程将源代码分解为有用的特征。词干提取、停用词和频率参数用于在转换阶段提取有价值的特征。词干提取用于将一组单词还原为其词根形式,频率参数信息指示不同源代码中每个元素的出现次数[4]。
为了获得更高的分类精度,需要将程序依赖关系图实例转换为加权特征。加权特征用于调整单个文档以及多个文档中每个特征的重要性。采用局部和全局加权技术来获得每个特征的权重。例如,假设比较三个分别用C++,Java和C#语言编写的源代码文档,其中局部权重提取自一个文档中的每个特征的重要性,而全局权重可以捕获所有文档中每个特征的重要性。这些特征有助于对每种编程风格的每个特征进行评分和排名。该过程为分类器提供了有用的信息,即哪些特征对于准确的预测更有价值。将TFIDF加权技术用于全局权重,将Log TF技术用于局部权重[5]。词频是每个词例的出现次数,其计算方式如式(1)所示:
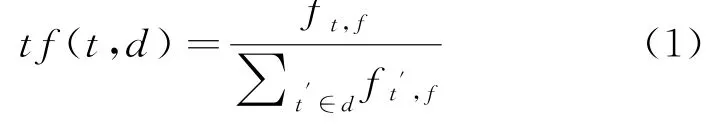
式(1)其中f(t,d)表示词频,d表示文档。而反向文档频率的计算方式如式(2)所示:
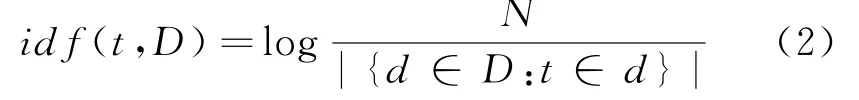
式(2)其中D表示包含词t的文档数量,N表示文档的总数量。TFIDF的定义如式(3)所示:
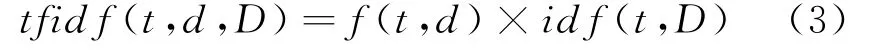
1.3 合成少数类过采样技术
对于类不平衡问题来说,与欠采样相比,过采样可以提供更好的准确性。合成少数类过采样技术(SMOTE)技术可以更好地解决类不平衡问题,该技术基于与原始少数类样本的相似性来合成新的少数类样本。
首先,SMOTE使用欧几里得距离计算每个少数类x i的k最近邻值。然后,在x i的一组近邻中随机选择一个最近邻x j。接下来,如公式(4)所示:
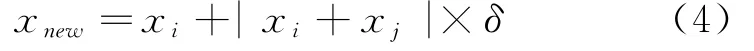
在训练特征时会遇到类不平衡的问题,这是由于数据集由不同数量的C++,Java和C#源代码构成。而且每个程序员所写的源代码可以具有不同行数的代码。当某一类别的样本数远多于另一个类别时,应用深度学习算法会造成效率低下,从而影响分类精度。使用SMOTE方法对少数类进行过采样,以解决类不平衡的问题。
1.4 深度学习模型
Tensor Flow是一个开源的深度学习框架,对于深度学习编程任务的各种应用而言非常重要。用户可以使用Tensor Flow库配置不同的深度神经网络,跟踪并共享每个操作的状态(带有突变详细信息)。队列功能用于异步计算相应的张量。队列功能的功能就像多线程处理一样。它可以并行运行这些操作以加快操作。设计了深入的程序依赖关系图DL方法,以识别每种类型的源代码的相应作者。可以使用高级Keras API训练深度学习模型。易于配置以扩展不同的模块并快速建立原型。具有局部和全局加权值的标准化数据集被输入到深度学习算法。Tensor Flow对标准化数据进行预处理以排队进入训练阶段,如图1所示。
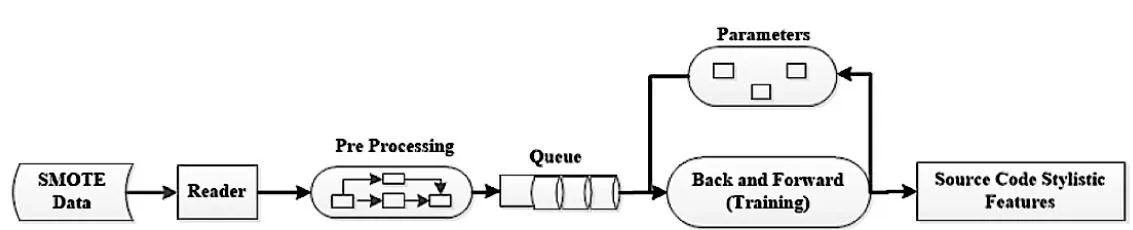
图1 Tensor Flow训练流程
配置了七个层来分别使用100,80,80,60,60,40个神经元来训练特征。第一层是输入层,然后中间五层是隐藏层,最后是输出层。ReLu(线性整流)激活函数用于输入层和隐藏层,softmax函数用于目标变量。Dropout层用于调整深度学习算法,以消除过拟合的问题。在第一层神经元有750个参数,在第2层有15100个参数,在第3层有50100个参数,在第4层有5049个参数。为了获得更高的准确性,深度学习算法通过微调配置进行了优化。softmax激活函数也称为归一化指数函数,该函数在输出层中用于处理多类问题。它采用K个实数的向量,然后转换为K个概率的归一化概率分布。Softmax能够将K个实数转换为K个范围在[0,1]内的数字,它通常用于多类神经网络中,以将非标准化输出转换为预测类的概率分布。标准softmax函数σ定义如公式(5):
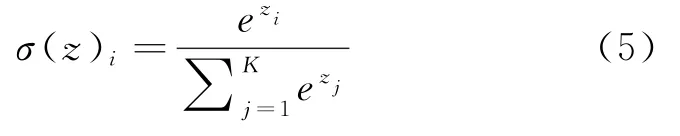
对输入向量为z的实例z i应用标准指数方法,通过除以所有这些指数的总和来归一化输出值。训练过程的主要目标是充分了解数据集结构,以便对看不见的数据进行准确的预测。ReLu激活函数用于输出变量,以便更好地理解和使用深度神经网络,其定义如公式(6):
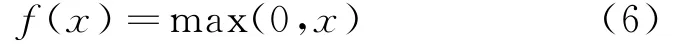
式(6)中x代表相应神经元的输入,这也称为渐变函数,其图形的行为类似于基于一元实数的渐变。现在它是深度神经网络最流行的激活函数。熵函数用于识别每个瞬间的损失,以积累深度学习功能。它以张量为输入,并以类似的轮廓标记张量为输出。
训练是深度学习算法的下一阶段,其中模型逐渐优化并学习给定的数据集。训练的主要目标是要学习足够的数据集结构。它使模型能够为看不见的语料库做出准确的预测。Adam优化器也被认为是随机下降梯度,可用于编译和优化深度学习模型。它采用迭代技术来更新网络权重。它为深度学习网络中的每个约束计算出不同的自适应学习率,如公式(7)-(10):
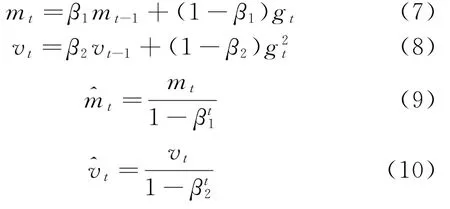
损失和准确性函数用于预测类别概率。分类损失函数的定义如公式(11):
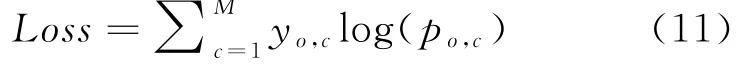
式(11)其中M是预测类别的数量,c是观察o的正确分类,p是在观察c中的观察o的预测概率。所提出的算法如算法1所示。

算法1基于深度学习的源代码归属分类算法1.for each a in folder do 2.for each q in a do 3. G=getPDG();4. end for 5.end for 6.for each g in G do 7. t=get Freq(q);8. tlocalw=get Local Weight();9. tGlobalw=getGlobalWeight();10. for each i in t do 11. w=tlocalw[i]+t Globalw[i];12. tw.add(t[i],w)l 13. end for 14. q.add(tw);15. dataset(q,a);16.end for 17.traindataset,testdataset=randomSplit(dataset,80,20);18.traindataset=SMOTE(traindataset);19.model=model_type=Sequential;20.layer_type=Dense,Dropout;21.activation_function=relu;22.epoches=20000 23.optimizer=adam 24.authorship_attribution(traindataset,testdataset)
2 实验评估
实验所采用的数据集是从GCJ收集的,该数据集包含了属于1000个程序员的三种不同编程语言(即C++,Java和C#)的源代码,数据集中三种编程语言的分布情况如图2所示,其中C++占53.96%,Java占32.37%,C#占13.67%。
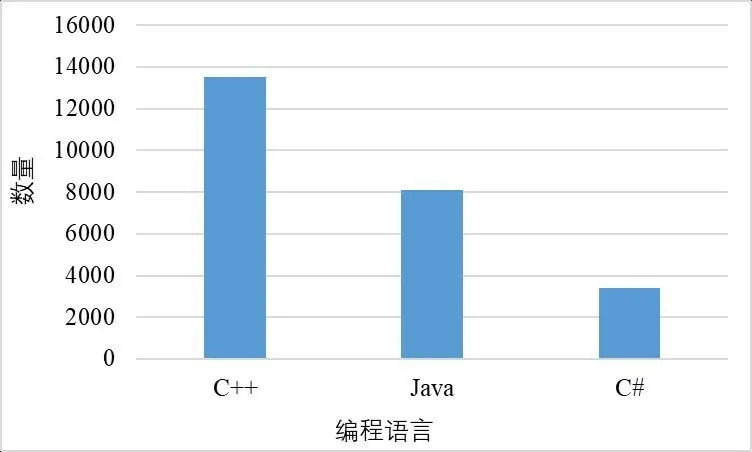
图2 数据集中编程语言的分布情况
从数据集中提取得到程序依赖关系图,部分程序依赖关系图如图3所示。
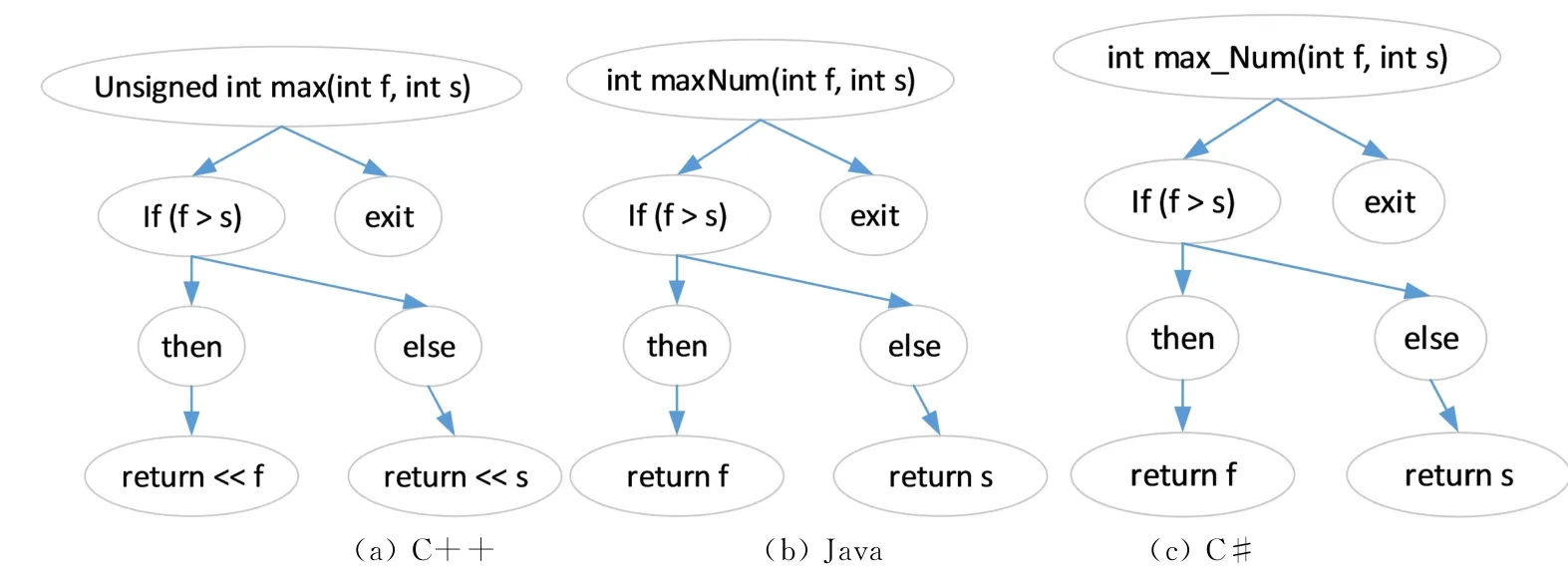
图3 数据集中的程序依赖关系图示例
由于数据集中存在严重的类不平衡,因此使用SMOTE技术来解决此问题。表1和2分别展示了使用SMOTE技术前和后的混淆矩阵。
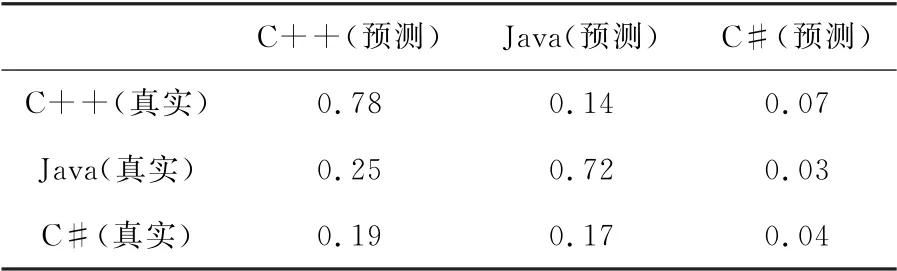
表1 没用应用SMOTE技术的混淆矩阵
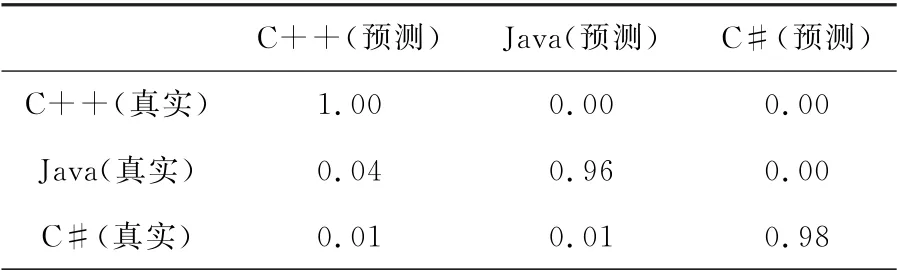
表2 应用SMOTE技术后的混淆矩阵
实验使用的评估指标有精度、召回率、F度量,其计算方式如式(12)所示:
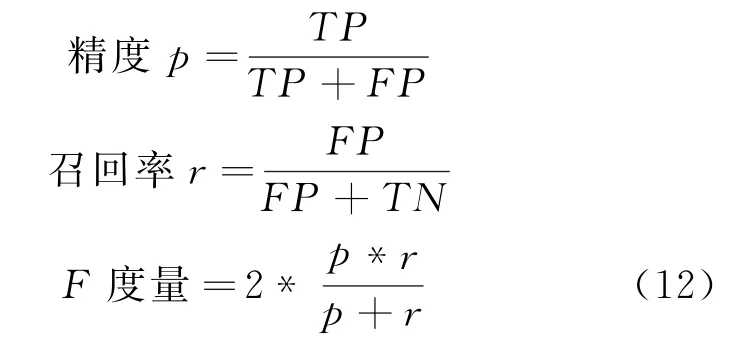
其中,TP,FP,TN分别是指被正确分类的正例、被错误分类的正例和被正确分类的反例的数量。实验结果如表3所示。由表3的结果可知,就这些指标而言,提出的方法均优于其他算法。
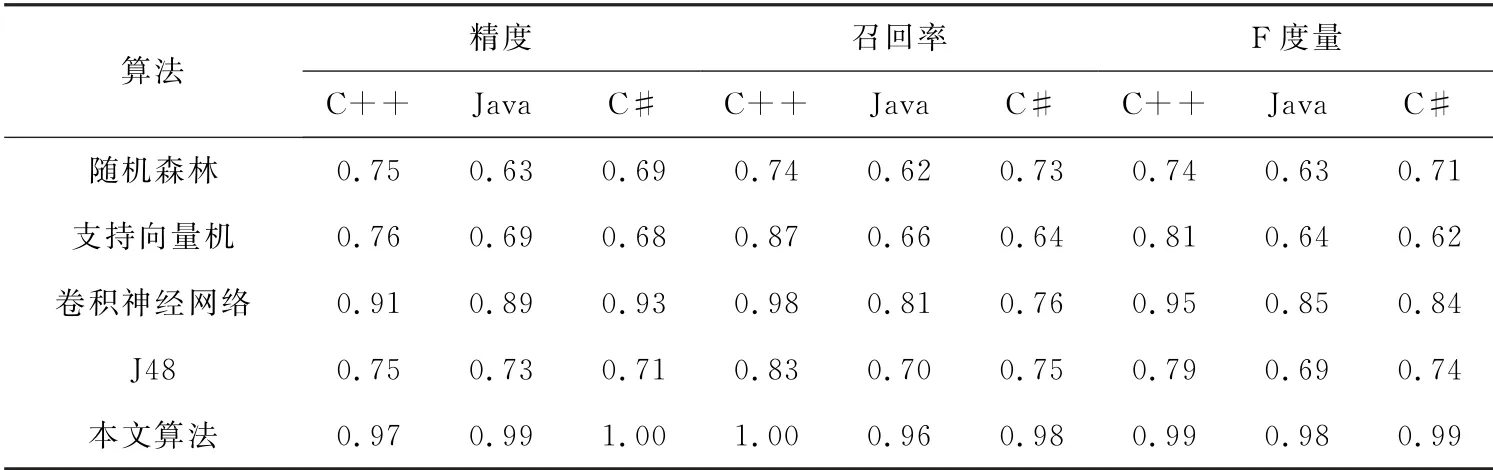
表3 实验结果对比
3 结 语
结合软件程序依赖关系图和和深度学习模型来以捕获编码样式以识别程序员,以预测不同类型的源代码的作者。将所提出的方法与其他现有方法进行了比较,考察分类精度、召回率和F度量三方面的性能。实验结果表明,所提出的方法在识别源代码的真正作者方面要优于其他方法。所提出的方法可以自动识别源代码的作者,并进行代码抄袭的检测。
