Incremental Learning Framework for Mining Big Data Stream
2022-08-24AlaaEisaNoraELRashidyMohammadDahmanAlshehriHazemElbakryandSamirAbdelrazek
Alaa Eisa,Nora EL-Rashidy,Mohammad Dahman Alshehri,Hazem M.El-bakry and Samir Abdelrazek
1Information Systems Department,Faculty of Computers and Information,Mansoura University,Mansoura,35516,Egypt
2Machine Learning and Information Retrieval Department,Faculty of Artificial Intelligence,Kafrelsheikh University,Kafr El-Sheikh,Egypt
3Department of Computer Science,College of Computers and Information Technology,Taif University,Taif,21944,Saudi Arabia
Abstract:At this current time,data stream classification plays a key role in big data analytics due to its enormous growth.Most of the existing classification methods used ensemble learning, which is trustworthy but these methods are not effective to face the issues of learning from imbalanced big data, it also supposes that all data are pre-classified.Another weakness of current methods is that it takes a long evaluation time when the target data stream contains a high number of features.The main objective of this research is to develop a new method for incremental learning based on the proposed ant lion fuzzy-generative adversarial network model.The proposed model is implemented in spark architecture.For each data stream,the class output is computed at slave nodes by training a generative adversarial network with the back propagation error based on fuzzy bound computation.This method overcomes the limitations of existing methods as it can classify data streams that are slightly or completely unlabeled data and providing high scalability and efficiency.The results show that the proposed model outperforms stateof-the-art performance in terms of accuracy (0.861) precision (0.9328) and minimal MSE(0.0416).
Keywords: Ant lion optimization(ALO);big data stream;generative adversarial network(GAN);incremental learning;renyi entropy
1 Introduction
In the advanced digital world, the data streams are generated by different sources, like sensors,social media networks,and internet of things(IoT)devices which are rapidly growing[1,2].These data streams are characterized based on the changes in data distribution and high velocity with respect to time.As such,several research works are concentrated more on the issues of data stream classification,especially in the non-stationary data.The main issue in the classification process is the utilization of various concept drifts during the changes of data distribution based on time in unforeseen ways[3–6].
The data stream is the manifestation of big data that is characterized by five dimensions (5 V),namely value,variety,veracity,velocity,and volume.Data stream mining is the methodology used to deal with the data analysis of a huge volume of data samples in an ordered sequence[7–13].Incremental learning follows the paradigm of machine learning methods.In this technique,the learning procedure can take place only when new examples appear and then adjusts to the one that is gained from previous examples.The ensemble learning model uses multiple base learners to integrate the predictions[14–19].
The large volume of data sequence leads to the need for data analysis techniques for special purposes,as it does not require recording the entire data stream in memory[20–23].A method adopted for analyzing data streams explores the incremental production of informative patterns.This pattern signifies a synthesized vision of data records that were analyzed in the past and it progressively analysis for the availability of new records.On-line and incremental learning methods are used for dealing with the rapid arrival of continuous data,unbounded streams,and time-varying data[24–26].Online environment is a non-stationary one that copes with the learning issues in big data conditions [27].Moreover, learning frames are constant to develop more effective feature expression and renewal models.The prediction model requires several parameters and this model can always be rebuilt[28,29].
The main contribution of this paper can be summarized as follow:
·The authors propose an incremental learning framework for big data stream using ant lion fuzzy-generative adversarial network model (ALF-GAN) that provide speed, high efficiency,good convergence,and eliminates local optima.
·The proposed model is carried out in spark architecture that provides high scalability[30], in which master node and slave nodes are considered[31].
·The authors use a tri-model for the feature extraction process,which includes token keyword set,semantic keyword set,and contextual keyword set.
·The authors use renyi entropy for features selection that decreases over-fitting,reduces training time,and improved accuracy.
·The proposed framework is compared to other state-of-the-art methods using standard criteria.
·The authors explore the limitations of the current literature on big data stream mining techniques.
The paper is organized as follows:Section 2 describes the review of various data classification methods.Section 3 shows materials, methods and elaborates the proposed ALF-GAN model,Section 4 presents the results and discussion,the paper concluded in Section 5.
2 Related Works
Most of the existing data stream classification methods used ensemble learning methods due to their flexibility in updating the classification scheme, like retraining, removing, and adding the constituent classifiers[32–35].Most of these methods are trustworthy than the single classifier schemes particularly in the non-stationary environments [5,36].The dynamic weighted majority (DWM)effectively maintains the ensemble of the classifier with the weighted majority vote model.The DWM dynamically generates and alters the classifiers with respect to concept drifts [37].In the case of a classifier that misclassifies the instance, the weight is reduced to a certain value that disregards the output of the ensemble.The classifier with a weight less than the threshold value is removed from the ensemble[38–40].
Gupta et al.[41] introduced a scale free-particle swarm optimization (SF-PSO) and multi-class support vector machine(MC-SVM)for data classification.Features selected to minimize time complexity and to enhance the accuracy of classification.The authors validated their approach using six different high dimensional datasets but they failed to use the benefit of particle’s learning mechanism.Lara-Benítez et al.[42]introduced an asynchronous dual-pipeline deep learning framework for data streaming(ADLStream).Training and testing process were simultaneously performed under different processes.The data stream was passed into both the layers in which quick prediction was concurrently offered and the deep learning model was updated.This method reduced processing time and obtained high accuracy.Unfortunately,this technique was not suitable if the label for each class instance was not immediately available.Casalino et al.[10] introduced a dynamic incremental semi-supervised fuzzy c-means for data stream classification (DISSFCM).The authors assumed that some of the labeled data that belongs to various classes were available in the form of chunks over time.The semisupervised model was used to process each chunk that effectively achieved cluster-based classification.The authors increased the quality of classification by partitioning the data into clusters.They failed to integrate small-sized clusters,as they may hamper the cluster quality in terms of interpretability and structure.Ghomeshi et al.[5]introduced an ensemble method for various concept drifts in the process of data stream classification based on particle swarm optimization (PSO) and replicator dynamics algorithm(RD).This method was based on three-layer architecture that generated classification types with varying size.Each of the classification selected some amount of features from number of features in target data stream.This method takes long evaluation time when target data stream contains high number of features.
Yu et al.[29] introduced a combination weight online sequence extreme learning machine(CWEOS-ELM)for data stream classification.This method was evaluated based on the correlation and changing test error.The original weight value was determined using the adaboost algorithm.It forecast the performance using adaptable weight and with various base learners.It doesn’t require any user intervention and the learning process was dynamic.This method was more effective but failed to predict for an increasing number of feature space.Gomes et al.[40]introduced an adaptive random forest(ARF)model for the classification of data streams.The authors generally increase the decision tree by training the original data in the re-sampled versions and thereby few features are randomly selected at each node.This method contains adaptive operators and a resampling model that cope with various concept drifts for various datasets.This method was accurate and used a feasible amount of resources.The authors failed to analyze the run-time performance by reducing the number of detectors.Dai et al.[43] introduced a distributed deep learning model for processing big data.They offered distributed training on the computed model of the data system.This method faced large overheads due to the adaptation layer among different schemes.Sleeman et al.[44] introduced an ensemblebased model for extracting the instance level characteristics by analyzing each class.It can learn the data from large-sized skewed datasets with different classes.The authors failed to solve the multi-class imbalanced issues in big data,like extreme class imbalance and class overlapping.Tab.1 summarizes the studies undertaken for review:

Table 1:Summary of the studies undertaken for a review
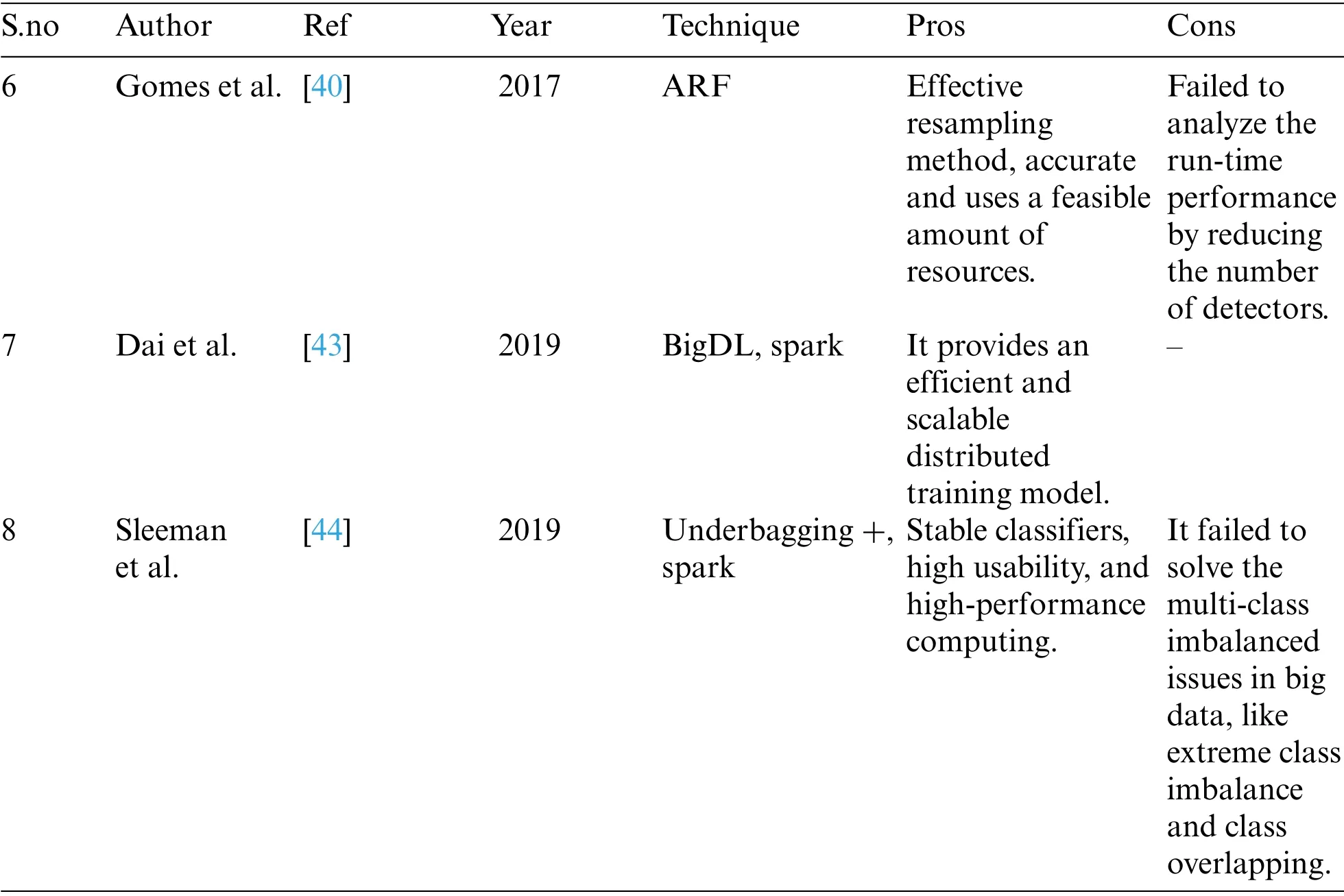
Table 1:Continued
Some of the issues faced by the existing data classification methods are explained as follows:
·The existing methods are not effective to face the issues of learning from imbalanced big data, as they are designed for small-sized datasets.Classification tasks can be more scalable by combining the data with high-performance computing architecture[44–47].
·In data stream classification, it is not pragmatic to suppose that all data are pre-classified.Therefore, there is a need to focus on classifying stream data that are slightly or completely unlabeled[48].
·The increasing rates of big data and the curse of its dimensionality produced difficult tasks in data classification[41,49].
·The adaptation to various concept drifts poses a great challenge for data steam classification when data distribution evolves with respect to time[50,51].
3 Methods and Materials
3.1 Soft Computing Techniques
Soft computing(SC)techniques are an assemblage of intelligent,adjustable,and flexible problemsolving methods[52].They are used in modeling complex real-world problems to achieve tractability,robustness, low solution cost.The singular characteristic of all SC techniques is their capacity for self-tuning, that is, they infer the power of generalization from approximating and learning from experimental data.SC techniques can be divided into five categories which are (machine learning,neural networks,evolutionary computation,fuzzy logic,and probabilistic reasoning)[53,54].For more reading about SC,Sharma,S,et al.provide a comprehensive review and analysis of supervised learning(SL)and SC techniques for stress diagnosis in humans.They explore the strengths and weaknesses of different SL(support vector machine,nearest neighbors,random forest,and bayesian classifier)and SC(deep learning,fuzzy logic,and nature-inspired)[55]
3.2 Spark Architecture Based Big Data Stream Approach
This section describes the big data streaming approach using the proposed ALF-GAN in spark architecture.Most of the classification process requires a complete dataset to be loaded in memory before starting the process[56].For online data classification,where the dataset size is extremely large,there is a need for scalability which is supported by spark architecture.The process of incremental learning is performed by considering the input data as big data.The proposed incremental learning process includes the phases,like pre-processing,feature extraction,feature selection,and incremental learning which are progressed in spark architecture.Let us considernthe number of input dataBto be passed to thennumber of slave nodes in order to perform pre-processing and feature extraction processes.From slave nodes, the extracted features are fed to the master node to achieve feature selection and the incremental learning process.Finally,the class output for each input of big data is computed at slave nodes.Fig.1 represents the schematic diagram of the proposed ALF-GAN model on spark architecture.

Figure 1:Schematic diagram of proposed ALF-GAN in spark architecture
3.3 Pre-Processing of Input Big Data
The input data considered to perform the learning process is defined as,

whereϖdenotes the database,nindicates the total number of data,andBirepresentsithinput big data.The data pre-processing phase involves the following steps:
1. Stop word removal:it reduced the text count and enables to increase the system’s performance.
2. Stemming:it is used to minimize variant word forms into a common representation termed as root.
3. Tokenization:it is the exploration of words in the sentence.The key role of tokenization is to identify meaningful words.The pre-processed data is represented asD.
3.4 Feature Extraction Using Tri-Model
The pre-processed dataDis passed to the feature extraction phase,where features are extracted using a tri-model.It is designed by considering the techniques, like token keyword set, semantic keyword set,and contextual keyword set[57,58].
Token keyword set:it represents the word with a definite meaning.A paragraph may contain up to six tokens in the keyword set.
Semantic keyword set:in this phase word dictionary with two semantic relations is built.It represented as,

where,drepresents keywords,bandcare the synonym and hyponym word.
Contextual keyword set:it identifies the related words by eliminating the word from irrelevant documents.It identifies the context terms and semantic meaning to form relevant context.Key terms are the initial indicators and the context terms are specified as validators to find whether the key terms are the indicators.Let us consider the training data asD,key term asDkt,and the context term asDct.
Identification of key term:let us consider the language model asMsuch that for each term,the keyword measure is computed as,

whereMrelis relevant document andMnon-relrepresents the non-relevant document in the language model.
Identification of context term:for each key term, the contextual terms are needed to compute separately.The key term instances for both the relevant and irrelevant documents are computed and the sliding windowWis applied to extract the key term aroundD.The relevant terms are denoted asarel,whereas the non-relevant terms are specified asanon-rel,respectively.For each unique term,a score is computed using the below equation,

whereMs(rel)denotes the language model for the set of relevant documents,Ms(non-rel)indicates the language model for the set of non-relevant documents.Thus, the features extracted using tri-model are represented asf,which is given as the input to the feature selection phase.
3.5 Feature Selection Using Renyi Entropy
After extracting the features from big data,feature selection becomes essential as it is complicated to mine and transform the huge volume of data into valuable insights [59].The unique and the important features are selected using renyi entropy measure.It is defined as the generalization of shannon entropy that depends on the parameterris given as,

The features selected using the entropy measure are represented asRwith the dimension of[U×V].
3.6 Incremental Learning Using Ant Lion Fuzzy-Generative Adversarial Network
Once,features are selected,the process of incremental learning is accomplished using the proposed ALF-GAN model.The significance of incremental learning is that while adding new samples,it does not require retraining all the samples, and hence it reduces the cost of training time and memory consumption.
The learning steps of the proposed ALF-GAN are presented in Fig.2.Initially, the input data is considered asStand the new chunk data is given asSt+1.Both the dataStandSt+1are used to be trained by GAN with the back propagation errorQtand the resulted output is declared as a predicted class.The error of new chunk dataQt+1is checked with the error of initial dataQt.IfQt+1is less thanQt,the GAN will be trained att,otherwise the fuzzy bound is computed based on range modification degree (RMD).After computing the fuzzy bound, the new training process is carried out using the proposed ALF-GAN to get a new GAN.
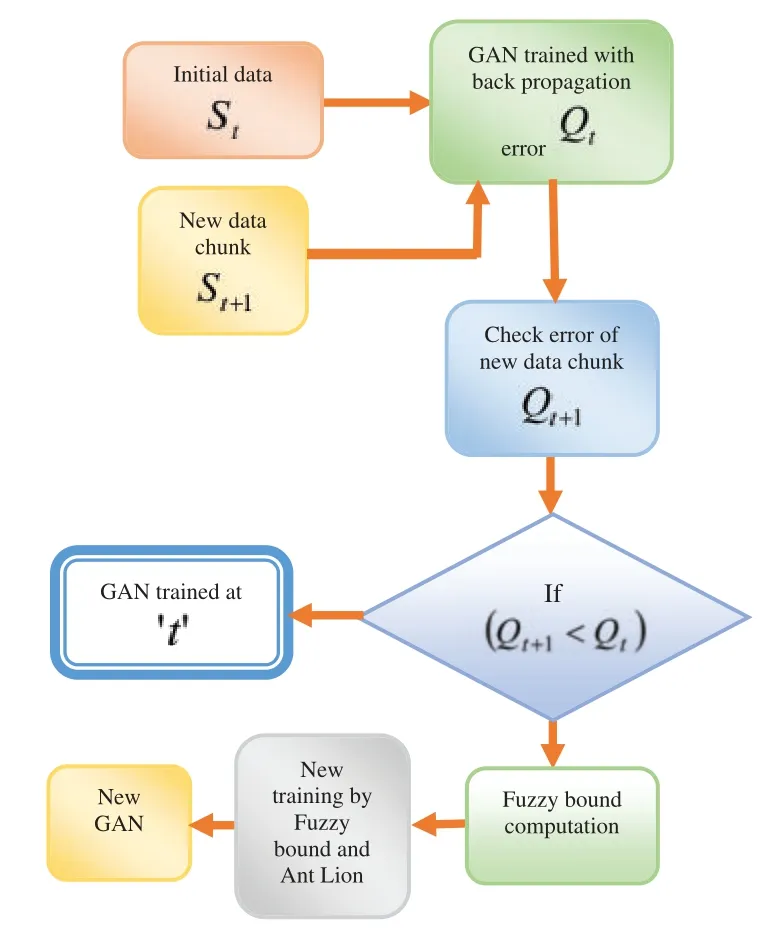
Figure 2:The proposed incremental learning model
3.6.1 Architecture of GAN
The architecture of GAN is represented in Fig.3.GAN[60]is an efficient network to learn the generative model from the unlabeled data.The benefit of using GAN is its ability to generate accurate and sharp distributions,and it does not require any form of functionality for training the generator network.GAN is composed of two models,namely the generatorHand the discriminatorCmodel,respectively.Let us consider the inputHas the random noiseA= {A1,A2,...,Ak}.Thus,the output obtained fromHis synthetic samplesH(A) = {H(A1),H(A2),...,H(Ak)}.The input passed toCisH(A)orR,which is the selected features obtained from the feature selection phase.The aim ofCis to find the real or fake samples.The loss function is represented as,
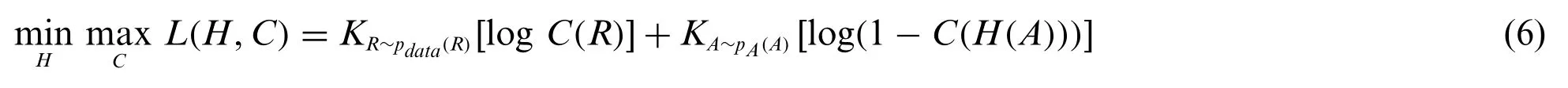
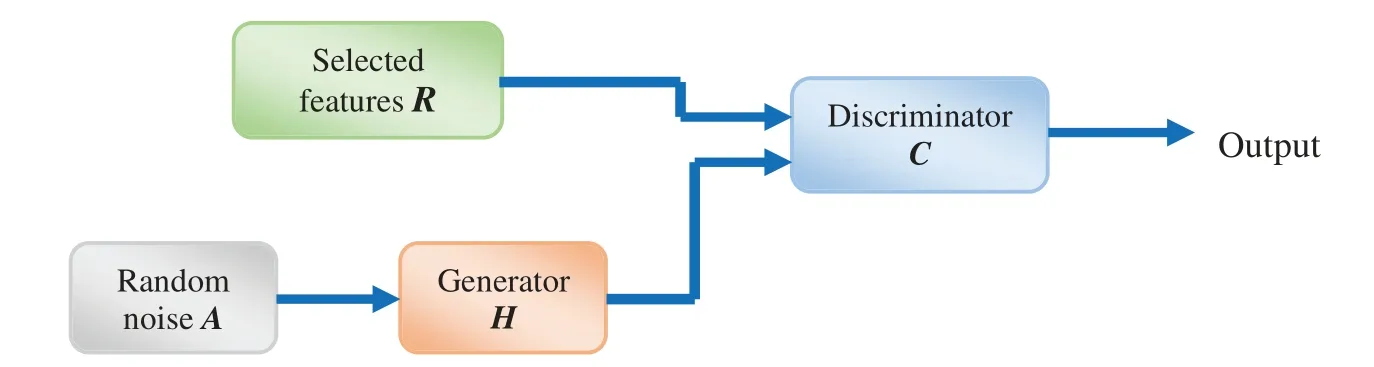
Figure 3:Architecture of generative adversarial network
3.6.2 Fuzzy Ant Lion Optimization Algorithm
The algorithmic steps of the proposed ALF-GAN are explained as follows:
i) Initialization:let us consider the weights are initialized randomly.
ii) Error estimation:after computing the loss function of GAN, the error valueQtis measured based on the ground truth value and the loss function of GAN using the below equation as,

iii) Fuzzy bound computation:when a new dataSt+1is applied to the network, the errorQt+1is computed.IfQt+1is greater thanQtFuzzy bounding model used to bound the weights based on RMD,which is given as,

where,XtandXt+1are the weight estimated attandt+1.The new bounding weight is computed as,

where,Edenotes fuzzy bound, andXtrepresents weight vector, which is to be updated using ALO.The fuzzy bound is computed using triangular membership functionβ,

where,ρdenotes fuzzy bound threshold andβdefines the triangular membership function with some parameters,a,g,h,andw.
iv)Update weights:ALO algorithm[61–63]is used to select the optimal weight.
v)Termination:steps are repeated until the best solution is obtained.Algorithm 1 represents
the pseudo-code of the proposed ALF-GAN.

Algorithm 1:Pseudocode of proposed incremental learning algorithm 1Input:R,Tj 2Output:Xt 3Initialize the weights 4Estimate error(Qt)for instance St from Eq.(7)5When a new instance St+1 add,estimate error(Qt+1)using Eq.(7)6While end criteria are not satisfied(Qt >Qt+1)7Updating weights using ALO and Fuzzy bound 8End while 9Return optimal weight 10 Terminate
3.7 Dataset
In this section the authors discuss the datasets used in the implementation process of the proposed framework:
· WebKB dataset[64]:this dataset is collected from Mark craven’s website.It consists of web pages and hyperlinks from different departments of computer science,namely the University of Texas,University of Wisconsin,University of Washington,and Cornell University.
· 20 Newsgroup dataset[65]:it is the popular dataset considered for the purpose of experiments that includes text applications, like text clustering and text classification.Newsgroup dataset includes 20,000 newsgroup documents that are equally partitioned into 20 various newsgroups.
· Reuter dataset[66]:the total number of instances available in the dataset is 21578 without any missing values.The task used for the association purpose is classification and the attributes are ordered based on their categories.The characteristic features of the dataset are text.
4 Results and Discussion
The experiments carried out with the proposed ALF-GAN and result acquired to prove the effectiveness of this model is presented in this section.
4.1 Experimental Setup
The proposed ALF-GAN is developed in the PYTHON tool using WebKB,20 Newsgroup,and Reuter datasets to conduct numerical experiments for evaluating the effectiveness of the ALF-GAN model.
4.2 Performance Metrics
The performance of the proposed ALF-GAN is analyzed by considering the metrics,like accuracy,MSE,and precision which are shown in Tab.2.

Table 2:Evaluation metrics
4.3 Comparative Methods
The competitive methods used for analyzing the performance of the proposed model are scalefree particle swarm optimization(SF-PSO)[41],asynchronous dual-pipeline deep learning framework for data streaming (ADLStream) [42], and dynamic incremental semi-supervised fuzzy c-means(DISSFCM)[10].
4.4 Comparative Analysis
The analysis made to show the effectiveness of the proposed framework by considering three different datasets is presented in this section.
4.4.1 Analysis Using 20 Newsgroup Dataset
Tab.3 and Fig.4 demonstrate and depict the analysis made using the proposed ALF-GAN based on the Newsgroup dataset.The analysis made with accuracy metric is shown in Fig.4a.By considering the chunk size as 2, accuracy measured by the conventional SF-PSO, ADLStream, and DISSFCM is 0.6389, 0.6683, and 0.6992, while the proposed ALF-GAN computed the accuracy of 0.7068,respectively.When the chunk size is considered as 3,the accuracy obtained by the existing SF-PSO,ADLStream,and DISSFCM is 0.7008,0.7114,and 0.7224,whereas the proposed ALF-GAN obtained higher accuracy of 0.72971, respectively.By considering the chunk size as 4, accuracy measured by the conventional SF-PSO, ADLStream, and DISSFCM is 0.7638, 0.7646, and 0.772758, while the proposed ALF-GAN computed the accuracy of 0.7774,respectively.When the chunk size is considered as 5,the accuracy of traditional SF-PSO,ADLStream,and DISSFCM is 0.8288,0.8290,and 0.8311,while the proposed ALF-GAN achieved the accuracy of 0.8413,respectively.

Table 3:Analysis using 20 newsgroup dataset
The analysis carried out with MSE metric is portrayed in Fig.4b.By considering the chunk size as 2, MSE measured by the conventional SF-PSO, ADLStream, and DISSFCM is 0.6652, 0.5861,and 0.2202, while the proposed ALF-GAN computed the MSE of 0.1463, respectively.The MSE measured by the conventional SF-PSO,ADLStream,and DISSFCM by considering the chunk size 3 is 0.3035,0.1700,and 0.1164,while the proposed ALF-GAN computed the MSE of 0.1145,respectively.By considering the chunk size as 4, MSE measured by the conventional SF-PSO, ADLStream, and DISSFCM is 0.1528,0.1390,and 0.0848,while the proposed ALF-GAN computed the MSE of 0.0703,respectively.When the chunk size is considered as 5, MSE measured by the conventional SF-PSO,ADLStream,and DISSFCM is 0.0724,0.0544,and 0.0479,while the proposed ALF-GAN computed the MSE of 0.0416,respectively.
The analysis made with the precision metric is depicted in Fig.4c.By considering the chunk size as 2,precision computed by the conventional SF-PSO,ADLStream,and DISSFCM is 0.76843,0.7865,and 0.8065,while the proposed ALF-GAN computed the precision of 0.8109,respectively.By considering the chunk size as 3,precision computed by the conventional SF-PSO,ADLStream,and DISSFCM is 0.8165,0.8229,and 0.8295,while the proposed ALF-GAN computed the precision of 0.83419,respectively.The precision obtained by the existing SF-PSO,ADLStream,and DISSFCM is 0.86312,0.8635,and 0.8682,while the proposed ALF-GAN has the precision of 0.88099 for chunk size 4.By considering the chunk size as 5,precision computed by the conventional SF-PSO,ADLStream,and DISSFCM is 0.9053,0.9055,and 0.9066,while the proposed ALF-GAN computed the precision of 0.91225,respectively.
4.4.2 Analysis Using Reuter Dataset
Tab.4 and Fig.5 demonstrate and depict the analysis made using the proposed ALF-GAN based on the Reuter dataset.The analysis made with accuracy metric is shown in Fig.5a.By considering the chunk size as 2, accuracy measured by the conventional SF-PSO, ADLStream, and DISSFCM is 0.6929, 0.6961, and 0.7067, while the proposed ALF-GAN computed the accuracy of 0.72193,respectively.The accuracy of existing SF-PSO, ADLStream, and DISSFCM is 0.7047, 0.7144, and 0.7291, while the proposed ALF-GAN measure the accuracy of 0.7426 for chunk size 3.When the chunk size is considered as 4, the accuracy of existing SF-PSO, ADLStream, and DISSFCM is 0.781107, 0.7817, and 0.7903, while the proposed ALF-GAN computed the accuracy of 0.7907,respectively.By considering the chunk size as 5, accuracy measured by the conventional SF-PSO,ADLStream,and DISSFCM is 0.8383,0.8471,and 0.8489,while the proposed ALF-GAN computed the accuracy of 0.8610,respectively.

Figure 4:Analysis of ALF-GAN using 20 Newsgroup dataset,a)accuracy,b)MSE,c)precision

Table 4:Analysis using reuter dataset

Table 4:Continued
The analysis carried out with MSE metric is portrayed in Fig.5b.When the chunk size is considered as 2,MSE measured by traditional SF-PSO,ADLStream,and DISSFCM is 0.609,0.4359,and 0.3585, whereas the proposed ALF-GAN measured the MSE of 0.356, respectively.The MSE measured by SF-PSO,ADLStream,and DISSFCM is 0.3384,0.2357,and 0.14539,while the proposed ALF-GAN computed the MSE of 0.1441, for chunk size 3.By considering the chunk size as 4,MSE measured by the conventional SF-PSO, ADLStream, and DISSFCM is 0.2247, 0.13548, and 0.09774,while the proposed ALF-GAN computed the MSE of 0.0611,respectively.When the chunk size is considered as 5,MSE obtained by the existing SF-PSO,ADLStream,and DISSFCM is 0.0907,0.07093,and 0.0668,whereas proposed ALF-GAN obtained the MSE of 0.0202,respectively.
The analysis made with the precision metric is depicted in Fig.5c.By considering the chunk size as 2,precision computed by the conventional SF-PSO,ADLStream,and DISSFCM is 0.8078,0.8097,and 0.8169, while the proposed ALF-GAN computed the precision of 0.82023, respectively.When the chunk size is considered as 3,precision computed by the conventional SF-PSO,ADLStream,and DISSFCM is 0.8214,0.8276,and 0.8365,while the proposed ALF-GAN computed the precision of 0.8449, respectively.The precision achieved by the existing SF-PSO, ADLStream, and DISSFCM is 0.87453, 0.8749, and 0.8799, while the proposed ALF-GAN achieved the precision of 0.8900 for chunk size 4.By considering the chunk size as 5, precision computed by the conventional SFPSO, ADLStream, and DISSFCM is 0.9111, 0.91603, and 0.91703, while the proposed ALF-GAN computed the precision of 0.9382,respectively.
4.4.3 Analysis Using WebKB Dataset
Tab.5 and Fig.6 demonstrate and depict the analysis made using the proposed ALF-GAN based on the WebKB dataset.The analysis made with accuracy metric is shown in Fig.6a.By considering the chunk size as 2,accuracy measured by the conventional SF-PSO,ADL Stream,and DISSFCM is 0.48139, 0.4948, and 0.6687, while the proposed ALF-GAN computed the accuracy of 0.7442,respectively.When the chunk size is considered as 3,accuracy measured by the conventional SF-PSO,ADLStream,and DISSFCM is 0.48039,0.5065,and 0.6917,while the proposed ALF-GAN computed the accuracy of 0.75150, respectively.The accuracy achieved by existing SF-PSO, ADLStream, and DISSFCM for chunk size 4 is 0.4832,0.49754,and 0.6293,while the proposed ALF-GAN computed the accuracy of 0.75038, respectively.By considering the chunk size as 5, accuracy measured by the conventional SF-PSO,ADLStream,and DISSFCM is 0.4857,0.5081,and 0.70018,while the proposed ALF-GAN computed the accuracy of 0.7625,respectively.
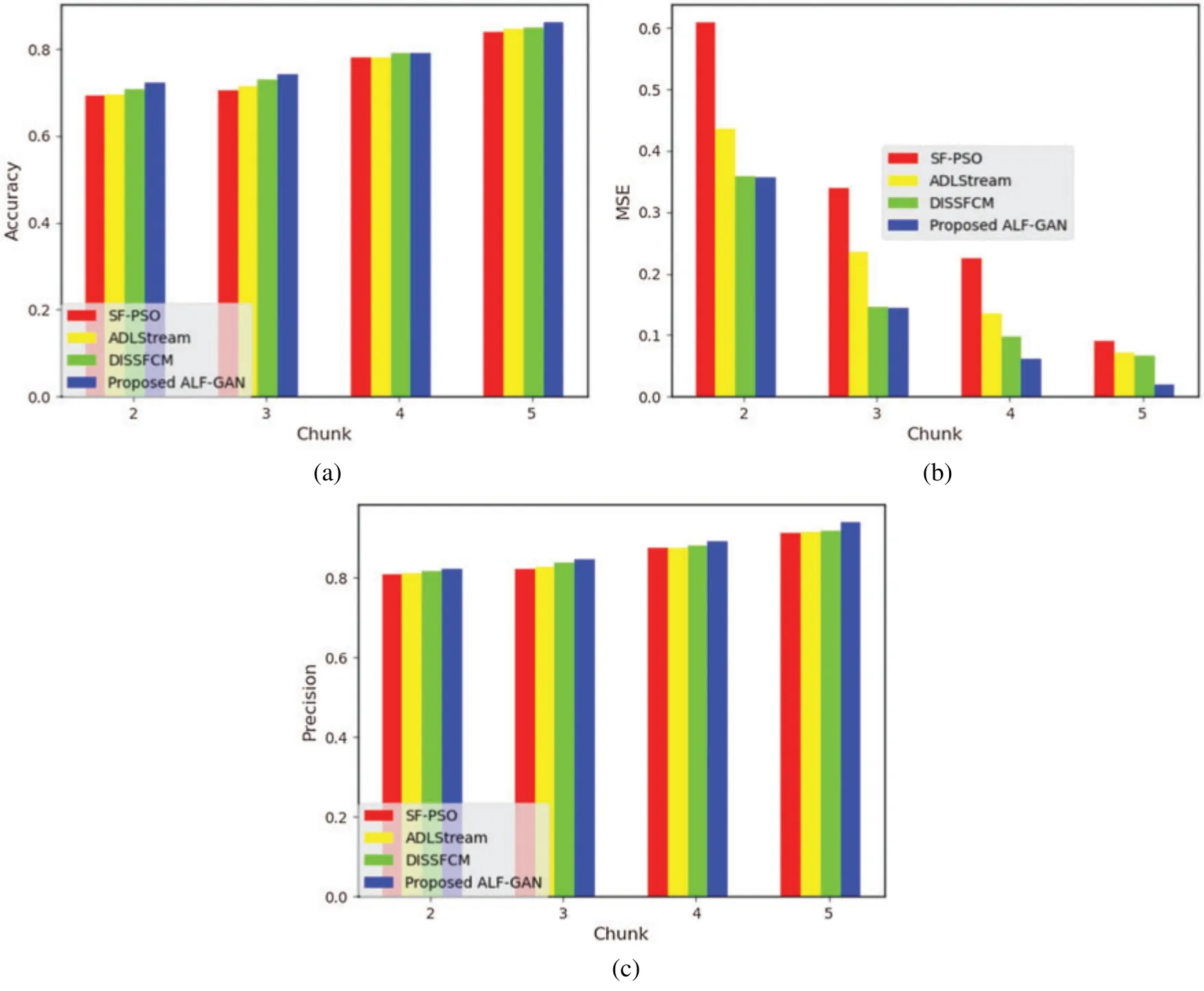
Figure 5:Analysis of ALF-GAN using Reuter dataset,a)accuracy,b)MSE,c)precision

Table 5:Analysis using WebKB dataset

Table 5:Continued

Figure 6:Analysis of ALF-GAN using WebKB dataset,a)accuracy,b)MSE,c)precision
The analysis carried out with MSE metric is portrayed in Fig.6b.By considering the chunk size as 2, MSE measured by the conventional SF-PSO, ADLStream, and DISSFCM is 0.3404, 0.23806,and 0.2086, while the proposed ALF-GAN computed the MSE of 0.2018, respectively.When the chunk size is considered as 3, MSE achieved by existing SF-PSO, ADLStream, and DISSFCM is 0.2531,0.2505,and 0.1422,whereas proposed ALF-GAN computed the MSE of 0.1146.The MSE of SF-PSO,ADLStream,and DISSFCM is 0.3158,0.2566,and 0.2211,while the proposed ALF-GAN computed the MSE of 0.1046 for chunk size 4.By considering the chunk size as 5, MSE measured by the conventional SF-PSO, ADLStream, and DISSFCM is 0.3108, 0.2361, and 0.1323, while the proposed ALF-GAN computed the MSE of 0.0835,respectively.
The analysis made with the precision metric is depicted in Fig.6c.By considering the chunk size as 2,precision computed by the conventional SF-PSO,ADLStream,and DISSFCM is 0.4832,0.4844,and 0.4914,while the proposed ALF-GAN computed the precision of 0.49754,respectively.When the chunk size is considered as 3,the precision measured by existing SF-PSO,ADLStream,and DISSFCM is 0.48139,0.4858,and 0.49488,whereas the proposed ALF-GAN computed the precision of 0.49775.By considering the chunk size as 4, precision computed by the conventional SF-PSO, ADLStream,and DISSFCM is 0.4857,0.4865,and 0.4946,while the proposed ALF-GAN computed the precision of 0.5081, respectively.The precision obtained by existing SF-PSO, ADLStream, and DISSFCM is 0.4803, 0.4828, and 0.5065, while the proposed ALF-GAN computed the precision of 0.51388 for chunk size 5.
These results show the higher performance of the proposed framework and prove that it provides higher accuracy and precision than comparative methods with lower MSE.
4.5 Comparative Discussion
Tab.6 portrays a comparative discussion of the proposed ALF-GAN model.From the below table,it is clearly showed that the proposed ALF-GAN model obtained better performance with the Reuter dataset for the metrics of accuracy,MSE,and precision.By considering the chunk size as 5,accuracy measured by the conventional SF-PSO,ADLStream,and DISSFCM is 0.8383,0.8471,and 0.8489,while the proposed ALF-GAN computed the accuracy of 0.8610,respectively.By considering the chunk size as 5, MSE measured by the conventional SF-PSO, ADLStream, and DISSFCM is 0.0907,0.07093,and 0.0668,while the proposed ALF-GAN computed the MSE of 0.0202,respectively.By considering the chunk size as 5,precision computed by the conventional SF-PSO,ADLStream,and DISSFCM is 0.91119,0.91603,and 0.91703,while the proposed ALF-GAN computed the precision of 0.9382,respectively.

Table 6:Comparative discussion
5 Conclusion
This paper provides a framework for big data stream classification in spark architecture using ALF-GAN.The proposed model achieved many merits such as scalability through using spark architecture.The incremental learning model provides high accuracy and has the ability to deal with the rapid arrival of continuous data.It uses GAN that can classify data streams that are slightly or completely unlabeled data.Renyi entropy is used to select features that decrease over-fitting,reduces training time,and improved accuracy.ALO algorithm provides speed,high efficiency, good convergence,and eliminate local optima The results showed that the proposed ALF-GAN obtained maximal accuracy which is 0.8610,precision is 0.9382,and minimal MSE value of 0.0416.The future work of research would be the enhancement of classification performance by considering some other optimization methods.
Funding Statement:Taif University Researchers Supporting Project Number(TURSP-2020/126),Taif University,Taif,Saudi Arabia.
Conflicts of Interest:The authors declare that there is no conflict of interest regarding the publication of the paper.
杂志排行

Computers Materials&Continua的其它文章
- Hybrid Renewable Energy Resources Management for Optimal Energy Operation in Nano-Grid
- HELP-WSN-A Novel Adaptive Multi-Tier Hybrid Intelligent Framework for QoS Aware WSN-IoT Networks
- Plant Disease Diagnosis and Image Classification Using Deep Learning
- Structure Preserving Algorithm for Fractional Order Mathematical Model of COVID-19
- Cost Estimate and Input Energy of Floor Systems in Low Seismic Regions
- Numerical Analysis of Laterally Loaded Long Piles in Cohesionless Soil