Effective Classification of Synovial Sarcoma Cancer Using Structure Features and Support Vectors
2022-08-24ArunachalamJanakiramanJunaidRashidJungeunKimSovanSamantaUsmanNaseemArunKumarSivaramanandBalasundaram
P.Arunachalam,N.Janakiraman,Junaid Rashid,Jungeun Kim,*,Sovan Samanta,Usman Naseem,Arun Kumar Sivaraman and A.Balasundaram
1Department of Electronics and Communication Engineering,K.L.N.College of Engineering,Pottapalayam,630612,Tamil Nadu,India
2Department of Computer Science and Engineering,Kongju National University,Cheonan 31080,Korea
3Department of Mathematics,Tamralipta Mahavidyalaya,Tamluk,721636,West Bengal
4School of Computer Science,University of Sydney,NSW 2006,Australia
5School of Computer Science and Engineering,Vellore Institute of Technology,Chennai,600127,India
6School of Computer Science and Engineering,Centre for Cyber Physical Systems,Vellore Institute of Technology,Chennai,600127,India
Abstract: In this research work,we proposed a medical image analysis framework with two separate releases whether or not Synovial Sarcoma (SS)is the cell structure for cancer.Within this framework the histopathology images are decomposed into a third-level sub-band using a two-dimensional Discrete Wavelet Transform.Subsequently,the structure features(SFs)such as Principal Components Analysis(PCA),Independent Components Analysis(ICA)and Linear Discriminant Analysis(LDA)were extracted from this subband image representation with the distribution of wavelet coefficients.These SFs are used as inputs of the Support Vector Machine(SVM)classifier.Also,classification of PCA+SVM,ICA+SVM,and LDA+SVM with Radial Basis Function (RBF) kernel the efficiency of the process is differentiated and compared with the best classification results.Furthermore,data collected on the internet from various histopathological centres via the Internet of Things (IoT) are stored and shared on blockchain technology across a wide range of image distribution across secure data IoT devices.Due to this,the minimum and maximum values of the kernel parameter are adjusted and updated periodically for the purpose of industrial application in device calibration.Consequently,these resolutions are presented with an excellent example of a technique for training and testing the cancer cell structure prognosis methods in spindle shaped cell (SSC) histopathological imaging databases.The performance characteristics of cross-validation are evaluated with the help of the receiver operating characteristics (ROC) curve,and significant differences in classification performance between the techniques are analyzed.The combination of LDA+SVM technique has been proven to be essential for intelligent SS cancer detection in the future,and it offers excellent classification accuracy,sensitivity,specificity.
Keywords: Principal components analysis;independent components analysis;linear discriminant analysis;support vector machine;blockchain technology;IoT application;industry application
1 Introduction
The medical industrial applications are one of the fastest growing industries in the world for diagnosing diseases with the help of IoT applications through blockchain techniques to protect patients from harmful chronic diseases.Recently,digital clinical histopathology images have proposed numerous cancer cell classification techniques for brain,breast,cervical,liver,lung,prostate and colon cancers[1].A synovial sarcoma(SS)is a mesenchymal tissue cell tumour that most frequently occur commonly in the limb of adolescents and young adults[2].The SS peak incidence is observed in the most common in children and adolescents younger than 20 years of age,the annual occurrence rate is 0.5 to 0.7 per million [3].SS has a variety of morphological patterns,but its chief forms are the monophasic and biphasic spindle cell patterns[4].These two types of spindle cells appear looking like an ovoid shape are called as spindle shaped cell(SSC),as shown in Fig.1[5,6].

Figure 1:The SS cancer images and their SSC(oval-shape)structure of the components
The digital histopathological examination is a crucial technique for diagnosis,but it is still not established in cancer cell structures often non-specific,it overcomes through wavelet transform(WT)has too often been helpful.The WT has transformed into sub-band image and it consists of the resolution scale wavelet coefficients and set of detail sub-band orientation.Hence,the sub-band image such as discrete wavelet transform(DWT)analysis are necessary to address the different behaviour of cell structure in order to describe it as an image[7].Moreover,the DWT is well suitable to calculate cell structure pixel intensity value of an image.WT is a very powerful mathematical tool similar to the signal processing technique compared to the Fourier Transform(FT)and is used in various medical imaging applications [8].Wavelet,which is used at different scales to decompose a signal,provides better resolution characteristics for WT in the 1D and 2D versions of the time scale plane [9].WT decomposes an image approximation,the detail coefficients of which operate first with 1D wavelets and finally with columns.The result is that the first level of 2D DWT is calculated as an image.The images here are decomposed by low and high pass filters to obtain approximate(LL or A1),horizontal(LH or H1),vertical (HL or V1) and diagonal (HH or D1) coefficients [10].Further,the first level approximation(A1) coefficients sub-band image is decomposed into three level wavelet coefficients,from this the structural features of the wavelet coefficients(Haar wavelet)are extracted and used to differentiate the cell structure by support vectors(SVs)[11].
Most of the studies on cancer classification have been achieved through the use of supervised or unsupervised pixel-wise classification of small rectangular image regions in terms of color and texture[12].Similarly,for data classification,decisions are made based on a set of features.Here,many structural or pattern authentication tasks are first used by the pathologist,and then the same features are used in the automated classification[13,14].However,it can also be a difficult task.Fortunately,pathologist does not have to use the features used in machines.Assessing to pathologists,sometimes difficult features are easily extracted and used in automated systems.
Thiran et al.[15]proposed a mathematical morphological technique.This technique first removes the noise behind the image and analyzes its size,shape and texture.Subsequently,the image is classified as cancer or normal based on the extracted values.Smith et al.[16]have proposed similarity measurement method for the classification of architecturally differentiated image sections is described prostate cancer.In this application,the Fourier transform and eigenvalue based method is recommended for the Gleason grading of histology slide images of prostate cancer.Khouzani et al.[7]have presented that the classification of image grade is proposed by two perspectives.First,the entropy and energy features are derived from the multiwavelet coefficients of the image.Then,to categorize each image to the appropriate quality,the simulated annealing algorithm and thek-nearest neighbor(k-NN)classifier select the most discriminating features.Second,wavelet packets and co-occurrence matrixes features are extracted.Then,they are compared to the multiwavelet method.The testing shows superiority of multiwavelet transformations compared to other methods.For multivariable,critically sampled pre-processing improves back-to-front pre-processing and is less sensitive to the noise of second-level decomposition.Most researchers do not use it in extraction because it is more sensitive to first-level noise.
Huang et al.[17]have extracted intensity and co-occurrence (CO) features such as intensity,morphology,and texture features from the separated nuclei in the images.It has been effectively differentiated varying degrees of malignancy and benignity by applying local and global characteristics.The SVM based decision map classifier with feature subset selection is used for each endpoint of the classifier compared to thek-NN and SVM model.The accuracy rate of the classification is increased by 1.67%with the SVM based decision graph classification.Doyal et al.[18]have presented a boosted Bayesian multiresolution(BBMR)system to identify regions of prostate cancer(CaP)in digital biopsy slides.They extracted image features such as first-order statistical,second-order co-occurrence,and Gabor filter features using the AdaBoost ensemble method.The BBMR approach has been found to have higher values of accuracy and area under the receiver operating characteristics (AUROC)curve than the other classifiers using the random forest feature ensemble strategy.Al-Kadi [19]has represented a multiresolution analysis technique based on wavelet packets and fractal dimensions(FD)for brain tumor meningioma classification.WT has applied the morphological process to blue color channel images.The wavelet sub-bands with high FD signatures are selected and used for classification in SVM,naive Bayesian and thek-NN classifier.The SVM classifier achieves better performance characteristics of the energy-texture signatures selection approach compared to the co-occurrence matrix signatures.
The parrot, finding she was not much alarmed, told her who he was, all that her mother had promised him and the help he had already received from a Fairy who had assured him that she would give him means to transport the Princess to her mother s arms
Ding et al.[20]have introduced three types of features for SVM classification,namely monofractal,multifractal,and Gabor features,which can be used to efficiently separate microbial cells from histological images and analyze their morphology.Their experiments show that the proposed automated image analysis framework is accurate and scalable to large data sets.Spanhol et al.[21]were introduced to estimate six different texture descriptors in different classifiers,and reported that the accuracy ranges rates of 80% to 85%,depending on different image magnification factors.There is no denying that texture descriptors provide a good representation of classification training.However,some researchers advise that the main weakness of current machine learning methods is the ability to learn representatives.Features extraction methods play an important role in the malignancy classification of histopathology image.Histopathological images of different cancer types have dramatically different color,morphology,size,and texture distributions.It is difficult to identify the common structures of malignancy diagnosis that can be used for the classification of colon and brain cancer.Therefore,features extraction [22]is very important in the high-level histopathology image task of classification.Kong et al.[23]used a similar multiresolution framework for grading neuroblastoma in the pathological image.They demonstrated that the subsets of features obtained by sequential floating forward selection are subject to dimension reduction.The tissue regions are hierarchically classified by usingk-NN,LDA+nearest mean(NM),LDA+k-NN,correlation LDA+NM,LDA+Bayesian and SVM with a linear kernel.Classification accuracy is achieved by the SVM classifier due to the selected optimal subset of features.
In this work,the application of blockchain technology based IoT devices to classify SS cancer through a combined study of SF and SVM methods leads to access to a wide range of secure histopathological imaging data for processing multiple histopathological imaging data within the cancer classification.Blockchain is an information base,or record that is shared across an organizational network.This record is encoded to such an extent that solitary approved parties can get to the information.Since the information is shared,the records can’t be altered.Rather than transferring our information on a brought together cloud,we appropriate across an organization over the world.Blockchain-based distributed storage consummately joins security and versatility with its interlinked blocks,hashing capacities,and decentralized design.It settles on the innovation an optimal decision for adding an additional layer of safety to the distributed storage.So,the security components intrinsic of blockchain can be supported utilizing the logical force of profound deep learning and Artificial Intelligence.
It was another long, winter afternoon with everyone stuck in the house and the four McDonald children were at it again -- bickering1, teasing, fighting over their toys. At times like these, Mother was almost ready to believe that her children didn’t love each other, though she knew that wasn’t really true. All brothers and sisters fight, of course, but lately her little lively bunch had been particularly horrible to each other, especially Eric and Kelly, who were just a year apart. They seemed determined2 to spend the whole winter making each other miserable3.
In the domain of sharing of SS image information,the capacity to safely and effectively measure monstrous measures of information can create a huge incentive for organizations and end-clients.Simultaneously,the IoT empowered gadgets across the Internet to send information to private blockchain organizations to make,alter safe records of shared SS image information.For instance,IBM Blockchain empowers our establishment accomplices to share and access IoT information without the requirement for focal control and the board.Each sharing can be confirmed to forestall questions and construct trust among all permissioned network individuals.SVs for SF stored on IoT devices are trained with a large number of distributed high-quality image data[24,25].
Spindle Shaped cells (SSC) are specialized cells that are longer than they are wide.They are found both in normal,healthy tissue and in tumors.The proposed approach used dimensionality reduction techniques to extract structure features(SFs)from third-level Haar wavelet sub-band images as follows:(1) Principal Component Analysis (PCA) gives second order statistical pixel variance,(2) Independent Components Analysis (ICA) gives higher order statistical to extract independent component pixel variance,and(3)Linear Discriminant Analysis(LDA)gives optimal transformation by minimizing the within-class and maximizing the between-class distance simultaneously(co-variance pixel value).Therefore,storing and sharing histopathological image data through a decentralized and secure IoT network can lead to in-depth learning from various histopathological image health care centres and medical industry[26].Moreover,this work used dimensionality reduction techniques to extract structure features(SFs)from third-level Haar wavelet sub-band images as follows:(1)Principal Component Analysis(PCA)gives second order statistical pixel variance,(2)Independent Components Analysis (ICA) gives higher order statistical to extract independent component pixel variance,and(3)Linear Discriminant Analysis(LDA)gives optimal transformation by minimizing the within-class and maximizing the between-class distance simultaneously(co-variance pixel value)[27,28].Therefore,these dimensionality reduction techniques are implemented before classifiers are trained.As a result,the complexity of Support Vector Machine (SVM) classifier is reduced,convergence velocity and performance of classifier has increased.Hence,SVM is used to find the optimal hyperplane to separate different class mapping input data into high dimensional feature space[29].Furthermore,this work chosen the Radial Basis Function(RBF)kernel[30]and their tuning parameters to train these extracted SFs,which can be easily tailored for any other kernel functions.Hence,it has the advantage of a fast training technique even with a large number of input data sets.Therefore,it is very widely used in pattern recognition problems[31]such as medical image analysis and bio-signal analysis.
7.Beautiful, pious girl:Her looks are very important and there is a tendency in stories to have beauty and goodness paired together. The description strengthens the blamelessness and goodness of the girl. In the 812 version, she simply lived though the three years in the fear of God and without sin (Zipes, Brothers, 176).Return to place in story.
Here,SVM classifies two different datasets by finding an optimal hyperplane with the largest margin distance between them,which is much stronger and more accurate than other machine learning techniques.Therefore,this work used an SVM trained model to automatically classify the SSC and non-SSC (cell structure) in the images.In most diagnostic situations,training datasets for unexpected rare malignancies structure are not included.Hence,the combination of discrimination model has been included such as PCA+SVM [32],ICA+SVM [33]and LDA+SVM.They are designed with RBF kernel function transformations.Furthermore,these SFs are most crucial techniques to extract features from histopathological images [34].This transforms existing features into the lower dimensional image feature space,and they are used to avoid redundancy and also reduce the higher dimensional image datasets.The accuracy of aforementioned different type classifiers has been assessed and cross-evaluated,and benefits and limitations of each method have been studied.The simulation results show that the SVM with RBF kernel by using SFs can always perform better.Moreover,among these three classification methods,the best significant performance has been achieved in LDA+SVM classifier.
22. Poisonous comb: The second temptation relates to Snow White s head and her hair. Combs were an attribute of Aphrodite, the Sirens and mermaids all symbols of female desirability. Hair is a symbol of fertility and virility, but the comb tames its wildness and its poison nearly kills her. IRReturn to place in story.
And outside the house was a large courtyard with horse and cow stables and a coach-house--all fine buildings; and a splendid garden with most beautiful flowers and fruit, and in a park quite a league long were deer and roe10 and hares, and everything one could wish for
2 Materials and Methods
2.1 Overall Process and Internal Operation of SSC Structure Classification
Histopathological Synovial Sarcoma(SS)cancer images have been downloaded from the online link http://www.pathologyoutlines.com/topic/softtissuesynovialsarc.html,for training the classifier model.The stained slide SS images are collected from the Kilpauk Medical College and Hospital,Government of Tamil Nadu,Chennai,India for the external validation purpose.The IoT network is used to store,share,and train a large number of histopathological imaging data based on the blockchain technology.Then it can be integrated the histopathological data into advanced medical industry applications.The multispectral colour images are stored individually in red,green,and blue components and the size of each image is 128×128 pixels,respectively.The total number of images is 5400,the number of samples per second in each image is 49,152,and eight iterations have been considered in each image for computation.In particular,for all applications in medical image classification methods,from the overall dataset,70%is used for training the classifier,15%forinternal validation,and 15%forexternal validation.The overall procedure and the implementation flow of SSC classification are represented as a block diagram in Fig.2.In the cancer classification perspective,a RBF kernel machine has been implemented to operate on all groups of features simultaneously and adaptively combine them.This framework has provided the new and efficient SFs characteristics without increasing the number of required classifiers.
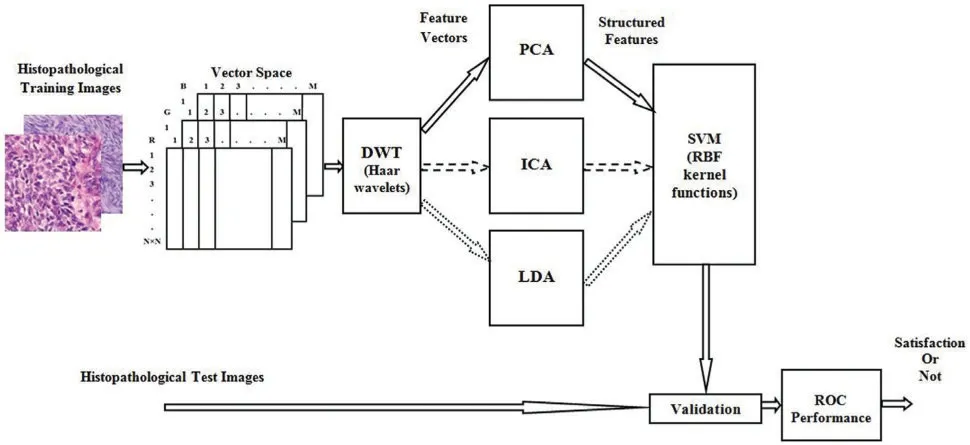
Figure 2:Block diagram of overall procedure and its internal operation of SSC structure classification
2.2 Fundamental of Wavelet Transform(WT)
An image is said to be stationary,then it does not change much over time.The Fourier transforms(FT)can be applied to the stationary images.But,the images have plenty of image pixel density value which contains stationary characteristics.Thus,it is not ideal to directly use the FT for such images;in such a situation sub-band techniques such as WT must be used.Wavelet analysis has been used for a variety of different probing functions[36].This idea leads to state the equation for continuous wavelet transform(CWT)and defined as

where,the variableuacts as to vary the time scale of the probing function ofΨ,andvacts as to translate the function acrossx(t).Ifu<1(but still positive)it contacts the function and if itu>1,the wavelet functionΨis stretched along the time axis.While the probing functionΨcould be any of a number of different functions,it at all times take on an oscillatory waveform,is called the wavelet.TheΨ*indicates the complex conjugation ofΨ,and the normalizing factor ofensures that the energy is the same for all values of the time scaleu.In furthermore,the Haar transformations would be preferred a transform that produces the minimum number of coefficients required to recover accurately in the original signal/image.The standard Haar waveletψ(t)is defined by
Now there came a time when it became necessary for the merchant to leave his home and to travel to a distant Tsardom. He bade farewell to his wife and her two daughters, kissed Vasilissa and gave her his blessing and departed, bidding them say a prayer each day for his safe return. Scarce was he out of sight of the village, however, when his wife sold his house, packed all his goods and moved with them to another dwelling14 far from the town, in a gloomy neighborhood on the edge of a wild forest. Here every day, while her two daughters were working indoors, the merchant s wife would send Vasilissa on one errand or other into the forest, either to find a branch of a certain rare bush or to bring her flowers or berries.

DWT controls this parsimonytranslation and scale,functions,variation to powers of 2 in general.Filter banks are best described as the basis for most medical image processing applications,such as DWT-based analysis.The advantages of a group of filters to separate an image into different spectral components is called sub-band image.This approach is called as multi-resolution decomposition of thex[n]image.Each phase of the system consists of two digital filters and two down-samplers by 2.In nature,the first one is the high pass filter,h[.]is the distinctive mother wavelet and the other mirror version is the low pass filterg[.].The down sampled releases the first high-pass and the low-pass filters provide detail and the approximation,respectively[37].
On the day before Christmas, snowflakes mingled11 with the howling wind. As the pastor unlocked the church doors, he noticed an older woman standing12 at the nearby bus stop. He knew the bus wouldn’t be there for at least half an hour, so he invited her inside to keep warm.
Appropriate wavelet and decomposition levels are most significant in the analysis of images using DWT.The number of decomposition levels is selected based on the dominant frequency components of an image.2D-DWT acting as a 1D wavelet,it alternates rows and 1D-DWT columns.2D-DWT works directly by placing an array transposition between two 1D-DWTs.Rows of arrays are initially managed only with one level of decomposition.It is basically divided into two equally vertical.The first half stores the average coefficients and the second vertical half save the detail coefficients.These steps are repeated with the column,resulting in four sub-band images within the array defined by the filter output as shown in Fig.3,and these images are three-level 2D-DWT decomposition of the image.Each pixel value represents digital equivalent image intensity,with pixels set in the image 2D matrix.This is unnecessary because the adjacent pixel values are highly correlated in the spatial domain here.So to compress the images,these redundancies in pixels should be removed.It converts DWT spatial domain pixels into frequency domain information,so they are represented by multiple sub-bands images[38].
In order to further reduce the dimensionality of the extracted structure feature vectors,the wavelet coefficient statistics value has been used to represent sub-band image distribution[39].The statistical features are listed here:(1) Mean values of coefficients in each sub-band,(2) Standard deviation of coefficients in each sub-band,(3)Ratio of absolute mean values of the adjacent sub-band.
2.3 Structure Features Extraction Methods
where,M-dimensional value vectorf (i)(x),i=1,2,...,Mis generated.

Figure 3:Levels of Haar wavelets sub-band images
2.3.3 Linear Discriminant Analysis(LDA)
2.3.1 Principal Component Analysis(PCA)
Principal Component Analysis,or PCA,is a dimensionality-decrease strategy that is frequently used to diminish the dimensionality of huge datasets,by changing a huge arrangement of factors into a more modest one that actually contains the majority of the data in the bigger set.PCA can be depicted as an“unsupervised”algorithm,since it“disregards”class names and its objective is to discover the bearings(the supposed head segments)that amplify the change in a dataset.Decreasing the quantity of factors in a dataset normally comes to the detriment of exactness,yet the stunt in dimensionality decrease is to exchange a little precision for straightforwardness.Since more modest informational collections are simpler to investigate and picture and make examining information a lot simpler and quicker for AI calculations without superfluous factors to measure.
In PCA,the mathematical representation of linear transformations of original image vector into projection feature vector[40]is given by

where,Yis them×Nfeature vector matrix,mis the dimension of the feature vector,and transformation matrixWis ann×m,whose columns are theeigenvectors(λ)corresponding to theeigenvalues (I)computed usingλI=SI.Here,the total scatter matrixSis defined as the average image of all samples.
The wretch80 not long after managed to approach me under another form, and one day, when I was in the garden, and asked for some refreshment81, he brought me--in the disguise of a slave--a draught82 which changed me at once to this horrid83 shape
Surely you do not doubt the existence of a future life? exclaimed the young wife. It seemed as if one of the first shadowspassed over her sunny thoughts.


More recently,some SVM based methods utilizing reduce the remodeling or reconstruction error [35]have been proposed for other types of cancers,but they are not yet applied to cancer cell SF classifies.The rest of this paper has organized as follows.The brief descriptions of the overall classification process,basic WT theories,SF extraction methods such as PCA,ICD and LDA,and SVM formulation with RBF kernel function are given in Section 2.The classification accuracy of experimental results is analysed and compared with existing works in Section 3.Further,the importance of structure based feature extractions,SVM classifiers and RBF kernel are discussed in Section 4,and the summary given in Section 5.
In this context,a classification using LDA feature extraction required less number of SVs than PCA feature exaction method.Moreover,the feature extraction classification process requires a lower number of SVs for the ICA than the PCA.The ICA measurements are described not only as unrelated to cell structural components but also as independent.Therefore,it is used for classification in terms of more valuable independent components than its related components.
The Independent Components Analysis(ICA)is statistical parameter feature extraction methods that transform a multivariate random signal into a signal having components that are mutually independent and it can be extracted from the mixed signal.The ICA rigorously defines as the statistical“latent variable”model[41,42].Letnlinear mixturesx1,x2,...,xnofnindependent components.

ICA models have now dropped time indext,wherexjis the each mixture.In addition,each independent componentskis a random variable that converts a real-time signal image.Here,the observed valuesxj(t),the mixture variables and the independent components are assumed to be zero mean.If it is not true,then observable variablexihas consistently been centred by subtracting the sample mean,and which is made the model zero mean.For our convenient to use vector matrix notation as an alternative of sums like in the Eq.(6).Letxbe the random vectors with elements is the mixturesx1,x2,...,xnand similarlysbe the random vector whose elements has been the mixturess1,s2,...,sn.LetAbe a matrix,whose components areaij.All vectors are understood to be column vectors;this vectorxTis a row vector.Eq.(7)is rewritten using this vector matrix notation.
There he gave her beautiful clothes, and food and drink, and because he loved her so much he married her, and the wedding was celebrated16 with great joy

Suppose,the required columns of matrixAand indicated byaj,then the model equation can thus be changed as

The correspondingwithin-classcovariance matrixandbetween-classcovariance matrixin the feature space are given as
The ICA starting point is very simple considering that componentsiare statistically independents and it must also have non-Gaussian distributions.The determination of matrixAand the calculation of its inverse matrixWare used to obtain the independent component.

LetW=A-1,but neitherAnor its inverse are known and the determination ofAby maximumlikelihood techniques.
Meantime the Fairy had prepared a chariot, to which she harnessed two powerful eagles; then placing the cage, with the parrot in it, she charged the bird to conduct it to the window of the Princess s dressing-room
The structure features(SFs)has been used to feature dimensionality for better optimized criterion related to dimensionality reduction techniques for other criteria.Lot of feature selection methods have been available to reduce dimensionality,extracting features,and removing noises before the cancer classification.First one is an input space feature selection,which reduces the dimensionality of the image by selecting a subset of features to conduct a hypothesis testing in a same space as the input image.Second one is the subspace feature selection or transform based selection,which reduces the image dimensionality by transforming images into a low dimensional subspace induced by linear or nonlinear transformation.The linear dimensionality reductions are commonly used method for image dimensionality reduction techniques in cancer classification.The popular linear dimensionality reduction techniques are,(1)Principal Component Analysis(PCA),(2)Independent Component Analysis (ICA),and (3) Linear Discrimination Analysis (LDA).The subspace feature selection methods have been mainly focused on this study.
Linear Discriminant Analysis or Normal Discriminant Analysis or Discriminant Function Analysis is a dimensionality decrease procedure which is ordinarily utilized for the managed characterization issues.It is utilized for displaying contrasts in gatherings,for example,isolating at least two classes.It is utilized to extend the highlights in higher dimensional space into a lower measurement space.For instance,we have two classes and we need to isolate them productively.Classes can have different highlights.Utilizing just a solitary component to order them may bring about some covering.Along these lines,we will continue expanding the quantity of highlights for legitimate arrangement.PCA can be portrayed as an“unsupervised”algorithm,since it“disregards”class marks and its objective is to discover the bearings(the alleged head segments)that augment the difference in a dataset.LDA is“managed”and processes the bearings(“linear discriminants”)that will address the tomahawks that expand the partition between different classes.
The main goal of the LDA is to discriminate the classes by projecting class samples frompdimensional space onto a finely orientated line.For aN-class problem,m=min(N-1;d)different orientated line will be involved in[43].For example,the analysis hasN-classes,X1,X2,...,XN.Let theithobservation vector from theXjbexji,wherej=1,2,...,Jandi=1,2,...,Kj.Jis the number of classes andKjis the number of observations from classj.The co-variance matrix is determined in two ways(1)within-class co-variance matrixCW,and(2)between-class co-variance matrixCB.


The projection of observable space into feature is accomplished through a linear transformation matrix T:

Eq.(8) is called the ICA model or generative model which describes how the observed data are generated by the process of mixing the components ofsi.The latent variables are independent component,which they can be indirectly observed.Also,let us consider the mixing matrix is to be unknown.The random vectorxis observing all and must evaluate the bothAandsusing it.


The linear discriminant is then defined as a linear function for which the objective functionJ(T)is given as

Here,the value ofJ(T)is the maximum and the solution of the Eq.(17) is the optimal transformation matrixTof theithcolumn,which is the common eigenvector corresponding to theithlargest eigenvalue of the matrix of.To obtain the discriminant profile,the LDA classification score(Lik)for a given classkis calculated by the Eq.(18)and it is considered equivalent to the class covariance matrices:
For me, volunteering was a personal journey into unexpected enrichment and inspiration. I helped small children revel29 in another realm of physical and spiritual being, a space only their horses could create for them. I saw these children empowered and renewed by their equine companions. I rediscovered my deep love for horses and drew lessons from their gentle ways. And last but not least, I learned that giving yields greater generosity30 than it asks.

where,Xiis a measurement vector unknown to a sample I;Xkis the mean measurement vector of class k;Σpooledis a pooled covariance matrix;andπkis the prior probability of classk[42].
2.4 The Constructing of Support Vector Machine(SVM)
Let us consider the case of two classesα1andα2,and the training dataset isX={x1,x2,...,xN}⊂PR.The Eq.(19)is formed as rules by the training data[44].

In appearance,SVM is binary classifier and it can evolution of image data points and assign them to one of the two classes.The input observation vectors are projected into higher dimensionalfeature space F.The functionf(x)takes the form

Withθ:PR→Fandv∈F,where(·)is denoted by the dot product.Often,all desirable data in these two classes meet the constraints in Eq.(21)
So they took a sad farewell of each other, and the Princess stuck the rag in front of her dress, mounted her horse, and set forth5 on the journey to her bridegroom s kingdom. After they had ridden for about an hour the Princess began to feel very thirsty,15 and said to her waiting- maid: Pray get down and fetch me some water in my golden cup out of yonder stream: I would like a drink. 16

Eq.(21) can be described as a hyperplane,where,vandbare described as the position of the corresponding region to coordinate the vector and centre of the hyperplane,respectively.
The optimization of this margin to its SVs can be converted into a constrained quadratic programming problem as seen in Eq.(21).This problem can be rewritten as optimization statements.

where,Eq.(22)is the primary objective function and Eq.(23)is the relative constraint of the objective function.Where,ξiis the slack variable,which indicates the misclassified of the corresponding margin hyperplane,andCis the parameter indicates the cost of the penalty.It is used to reduce the error if it is too large or to increase the size of the margin if it is too small.
The Eqs.(22)and(23)can be solved by creating aLagrangefunction.Hence,the positiveLagrangemultipliers are taken considerationωi;i=1,2,...,N,one for each constraint in both Eqs.(22)and(23).TheLagrangefunction[45]is defined by

The gradient ofLpmust be minimized with respect to bothvandbvalue,and they must vanish.The gradients are given by
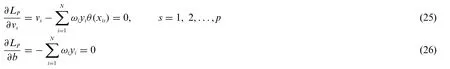
wherepis the dimension offeature space F,and by combining these conditions,the primary function,constraints of theLagrangemultipliers,and theKarush-Kuhn-Tucker(KKT)conditions are obtained.They are defined as in Eqs.(27)-(31).


Here,thev,bandωare variables to be solved from the KKT Eq.(26)and derived as

Therefore,

wherel(xi,x)=(θ(xi)·θ(xj))is the kernel function that uses the dot product atFin the feature-space;Also,substitute Eqs.(24)-(33),which leads to increase the dual functionLD.

Here,define the dual function which incorporates the constraints,and obtain the dual optimization problem.

Both primalLpand the dualLDconstraints are represented by the same objective function,but with different constructions.This optimization of the primal dual constraints is considered as a type of convex optimization problem and it can be rectified by using the grid-search algorithm.Finally,the SVM classifier classifies the input data vectorxby the classification criteria in Eq.(40).

Hematoxylin and eosin stain(H&E stain)is one of the chief tissue stains utilized in histology.It is the most broadly utilized stain in clinical conclusion and is regularly the best quality level.For instance,when a pathologist takes a gander at a biopsy of a presumed malignancy,the histological segment is probably going to be stained with H&E.It is the blend of two histological stains:hematoxylin and eosin.The hematoxylin stains cell cores a purplish blue,and eosin stains the extracellular lattice and cytoplasm pink,with different constructions,taking on various shades,tones,and mixes of these shadings.Thus a pathologist can undoubtedly separate between the atomic and cytoplasmic pieces of a cell,and furthermore,the general examples of shading from the stain show the overall format and dispersion of cells and gives an overall outline of a tissue test’s construction.Accordingly,design acknowledgment,both by master people themselves and by programming that guides those specialists(in computerized pathology),gives histologic data.
In this study,the SVM algorithm is analyzed using the RBF kernel,which can be easily formatted for any other kernel function.It also has tuning parameter to optimize performance [46-48]and defined as

where,l(xi,x)is the positive definite for a value in RBF kernel case,γ=is the tuning parameter which controls the width of the kernel function,andσis the standard division.
Support Vector Machine (SVM) is a supervised machine learning algorithm which can be used for both classification and regression challenges.It aims to minimize the number of misclassification and reconstruction errors.It is used in all the real-world applications,where the data are linearly inseparable.The SVMs implemented in this research were used as classifiers for the final stage in a multistage automatic target recognition phase.A single kernel SVM in this research may be used as an SVM with K-Means Clustering.Here,Support Vectors (SVs) are simply the co-ordinates of individual observation.We plot each data item as a point in n-dimensional space(where n is a number of features)with the value of each feature being the value of a particular coordinate.Then,we perform classification by finding the hyperplane that differentiates the two classes very well.
At this stage,the reconstruction error may be occurring in the distance between the original data point and its projection onto a lower-dimensional subspace.This reconstruction error is a function of the outputs and the weights.It may be calculated from a given vector,which is to compute the Euclidean distance between it and its representatives.In K-means,each vector is represented by its nearest center.Minimizing the reconstruction error means minimizing the contribution of ignoring eigenvalues which depend on the distribution of the data and how many components we are selecting.So the SVM based learning is to adapt the parameters which can minimize the average reconstruction error made by the network.
3 Experiment Results
A few examples are utilized as usefully focuses to oversee enormous component spaces through the SVM classifier to abstain from over-fitting cell structures by controlling the edge,and they are called support vectors(SVs).Through these SVs the proposed calculation can tackle the current issues.The arrangement won’t generally change if these preparation datasets are re-prepared.The preparation can guarantee that SVs can address every one of the attributes in the dataset.This is viewed as a significant property while investigating huge datasets with numerous uninformative designs.All in all,the quantity of SVs is more modest than the complete preparing dataset.In any case,this doesn’t change overall preparation information into SVs.In this experiment,the 64 SVs are utilized for dynamic interaction (Figs.4-6),showed a circle;the green circle ‘○’is utilized for SVs in the SSC structure class and the red circle ‘○’portrays SVs for non-SSC structure class.The class areas are isolated by a hyperplane.
Based on experimental results,Figs.4a,5a and 6b are shown the two-dimensional (2D) scatter plots of cell structures from the third level of the Haar wavelets(feature vectors).The acquisition of the third-level of the sub-band image detail approximation(A3)structured features have been extracted for the structure of the SSC (‘○’-red color circle) and non-SSC (‘○’-green color circle) of the two classes.Visually,it is difficult to separate data dispersion into two classes,so using a linear separable hyperplane can cause overlapping problems.This has an impact on errors in the classification process.In such case,a kernel function is required to convert the data into high dimensional space.Based on this,the cell structures of the two groups of histopathological image can be easily separated.
In this work,the RBF kernel SVM classifier with two corresponding tuning parameters such asβandγplays a key role in model performance.As a result,both of these parameters result an excessive fit for inappropriate selection.Therefore,the proposed methodology found the optimal tuning parameter values,which led to the classifier to accurately classify the data input.Furthermore,this methodology used 5-fold for cross-validation to implement the appropriate kernel tuning parameters forβandγ.Most importantly,all pairs (β,γ) for the RBF kernel are accessible,and the best of them is crossvalidation accuracy.The optimal tuning parameter pair values wereβ=2-1,γ=2-3and the classification error rate was 0.15.After selecting the value of the optimal kernel tuning parameters,the entire training data is re-trained in the construction of the final classifier.

Figure 4:PCA+SVM classifier model
The structure of the cell is classified and the performance results have been compared with SEs methods such as PCA,ICA,and LDA by SVM classifier with RBF kernel functions which shown in Figs.4b,5b and 6b.The dimensionality of the cell structures has been reduced by using the structural features.SVM with kernel classification model has been implanted using these structural feature datasets as inputs.In the classifier result,if the SSC structure is provided with output,it represents SS cancer,and if non-SSC structure is provided with output,it represents non-cancerous.

Figure 6:LDA+SVM classifier model
The training process examines the RBF kernel in three different ways:(1)PCA+SVM,(2)ICA+SVM,and(3)LDA+SVM.Using PCA,ICA,and LDA types of SFs methods,the cell structures’feature vectors are extracted from Haar wavelet sub-band image (A3) individually.The number of SVs is decreased and the classification test results have been analyzed by internal and external crossvalidations.Fig.6b explains the separation of cell structures when the distribution along with the LDA+SVM model indicates the mass of correlation co-efficient values of the two classes of data points which has been exactly distributed,towards the up-right and down-left side portions.But,one or two data points are occupied in the nearby SVs margin.Fig.5b explains the separation of cell structures when the distribution along with the ICA+SVM model indicates the mass of variance matrix value of two classes of data points.Then the maximum number of data points has been distributed,towards the up-right and down-left side portions.But,few numbers of data points are occupied in the nearby hyperplane.Fig.4b explains the characteristics of data classification separated based on its highest PC1 variance value.The separation of cell structures when the distribution along with the PCA+SVM model indicates the mass of PC1 variance value of the two classes of data points.Then the moderate number of data points has been distributed towards the up-right side and down-left side portions.When compared to ICA+SVM,more number of data points is occupied on the nearby hyperplane in both cell structures.Furthermore,the mass of data has been separated into two classes using SVM hyperplane and each of the groups.Here,the best boundary discrimination has been achieved by the RBF kernel function.The LDA+SVM have been achieved excellent performance of classification method and it has shown by the number of SVs,which has reduced than the ICA+SVM and PCA+SVM.
2.3.2 Independent Components Analysis(ICA)
However,the LDA+SVM feature extraction process takes longer duration in the training process than the ICA+SVM and the PCA+SVM feature extraction methods.Moreover,it has a transparent selecting scheme for the kernel function tuning parameters which are a pivotal to get better performance characteristics and overcome the problems of over-fitting with excellent classification process.
Before making any predictions about whether or not the histopathological images are affected by SSC structure,it is necessary to train the data by the characteristics associated with the test samples of the known class.Next,with the same datasets,the performance of the classification models is evaluated.The proposed work evaluated the classification performance by using the ROC curve.The relative tradeoffs between thesensitivityof theycoordinates and1-specificcityas thexcoordinate are shown in ROC curve.Fig.7 shows the ROC curve and useful for assigning the best cutoffs to the classification[49].These two parameters are mathematically expressed assensitivity=TP/(FN+TP)andspecificity=TN/(FP+TN).Tab.1 shows the test images with confusion matrix.The threshold for the best cutoff ranges between 0-to-1 is considered uniformly with 0.02 intervals,and it gives totally 50 samples per parameters.
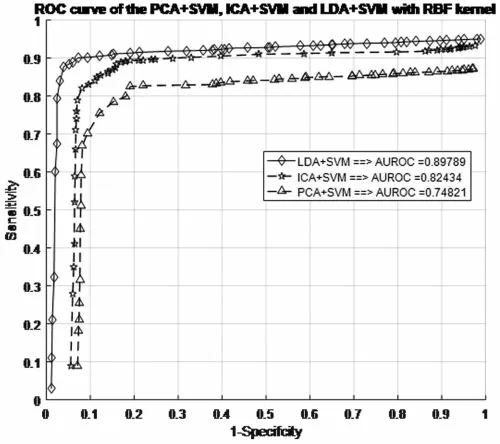
Figure 7:ROC curve for different SFs in the SVM+RBF classifiers with RBF kernel models

Table 1:Test image confusion matrix
The most common quantity index for describing accuracy is given by the area under the ROC curve(AUROC).AUROC is used as an analytical tool for evaluating and comparing classifiers,and also provides measurable quantities such as accuracy and approximate standard error rate[50].This curve is used to classify and regulate the performance regardless of class distribution.ROC curve measurement is classified into negative and positive classes in the result code for desirable properties and performance.Furthermore,AUROC can also be determined by the Eq.(42).Tab.1 summarizes the AUROC performance results and approximated standard error of the PCA+SVM,ICA+SVM and LDA+SVM classification models with different kernel functions.
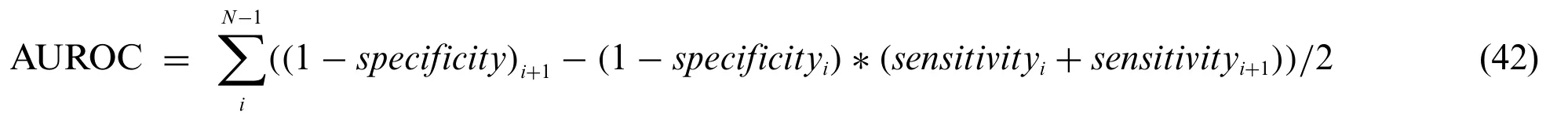
The AUROC grade system is generally categorized into four groups,which are excellent,good,worthless and not good.Their common range values are 0.9<AUROC<1.0,0.8<AUROC<0.9,0.7<AUROC<0.8 and 0.6<AUROC<0.7,respectively.Hence,Fig.7 shows the result of AUROC values for PCA+SVM,ICA+SVM and LDA+SVM with RBF kernel function,and they have the AUROC of 0.7482,0.8243,and 0.8979,respectively.Depending on these AUROC values,not good,worthless and good are described as PCA+SVM,ICA+SVM and LDA+SVM classification models,respectively.Whereas the LDA+SVM with RBF is a good model,and it is demonstrated that has been chosen to be applied in the proposed SSC structure classification,because this classifier model has greatest AUROC than the others.
The LDA+SVM with RBF model is compatible with taxonomic sources as it has the lowest approximate standard error in the creation of a hyperplane model which shows in the Tab.2.There is an attractive difference between two analyses.It means a ROC curve against the occurrence of the classification error and the other two classifiers.However,the ROC curve analysis is useful for performance evaluation in the current framework because it reflects the true state of classification problem rather than a measurement of classification error[51-53].

Table 2:Classifiers performance estimation by AUROC
4 Discussion
The present study reaffirms the existence of training databases based on evaluation of the classification models by using different types of SFs and RBF kernel functions.Blockchain technology allows SVM models to be trained with a large number of decentralized high-quality SS image data from IoT networks.The structural features of SVs are stored on IoT devices and periodically trained for SVM classification.The LDA structure feature and the SVM with RBF kernel were selected as a classification model.If the red circle resultant from thef(x)calculation value in the rule Eq.(35)of the RBF kernel is denoted by(‘○’),and it is classified as a SSC structure.Conversely,the diagnosis of SS cancer may assist pathologists in the progression and prognosis of chronic disease from the histopathological image.
SVM is based on cell structures with high dimensional spacing,which is usually much larger than the original structured feature space.The two classes are always separated by a hyperplane with a nonlinear map suitable for an acceptable high dimensional dataset.While the original structured feature brings enough information for better classification,the mapping of the high-dimensional structured feature space makes available in the best discriminating sources.Hence,the problem with training for SVM is that the nonlinear input is mapped to a higher dimensional space and selection of the classification function.The RBF kernel function is used for the training of SVM.The values of optimal RBF tuning parametersβandγhave been identified through grid-search technique.An SVM classifier with RBF kernel provides better experimental results based on the integrated training[54-56].However,other common optimal parameter searching methods are available such as deep learning algorithms,particle swarm optimization,and genetic algorithm[57].So,this is an interesting topic to explore further.
Tab.3 shows the overall performance comparison between SFs methods and RBF functions.The Gini index is a primary parameter that measures the superior performance between the classifiers.It is based on the area dominated by the ROC surfaces.The determination of Gini coefficient from the ROC curve is given by

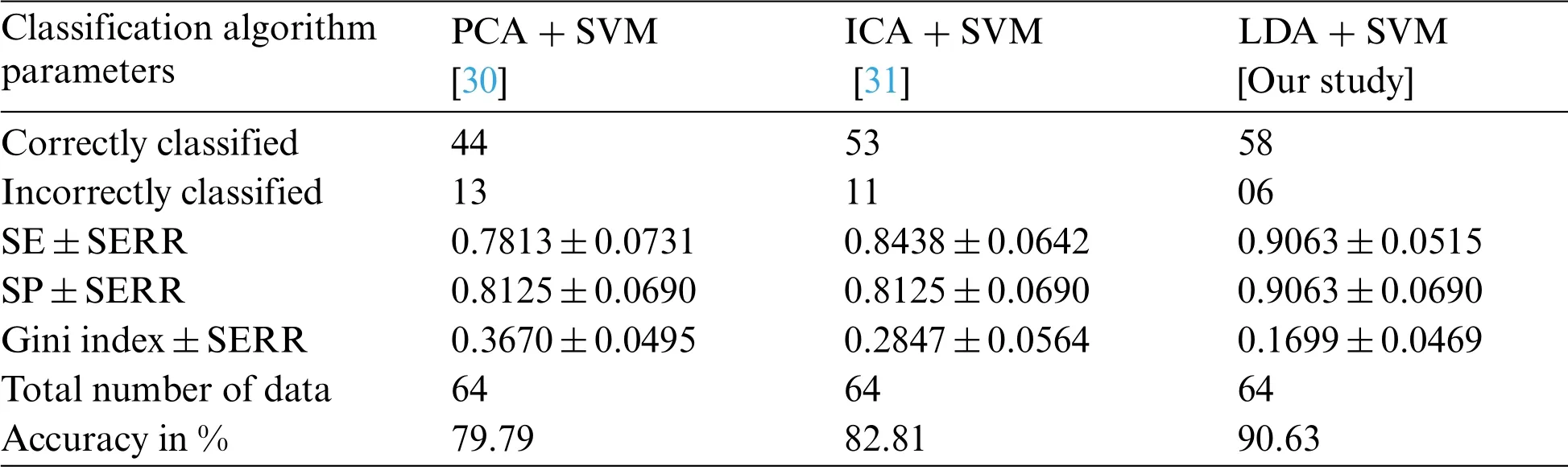
Table 3:Experimental results of PCA+SVM,ICA+SVM,and LDA+SVM models for RBF kernel
The proposed classification model has shown the robustness of classifying SS cancer effectively and accurately in LDA+SVM with RBF kernel function.The standard error(SERR)is specified in each parameter to understand the maximum and minimum variations in sensitivity (SE),specificity(SP) and Gini index.The LDA+SVM have obtained a higher classification rate than the other classifier models.
The success rate of the proposed classification methodology depends on the structural features and its selection process of a cell.The classification performance is improved by the transformation patterns of the SFs which reduces the with-class scatter,increases the between-class scatter,and significantly reduces the size of overlap between the classes.Statistically,PCA,ICA and LDA structural features are distinguished between normal image and SS cancer image due to the easy computation,simplicity,and rapid implementation.
5 Conclusion
Classification of cancer based on the malignant cell structure in histopathology images is a very difficult task.Hence,SVM classifiers used to classify the cell structure and assists to pathologists for diagnostic decision making.The conventional classification techniques of histopathology images using mutually exclusive time and frequency domain representations are not provided the proficient results.In this work,the histopathology images have been decomposed into sub-band using Haar DWT and then the SFs are extracted by obsessed their distribution.The extraction of SFs may be possible in three different ways:PCA,ICA,and LDA.These methods are used SVMs with RBF kernel functionality.The extraction results are compared with the observed cell structures and then cross-compared with their accuracy.The scalar performance measures like accuracy,specificity and sensitivity are derived from the confusion matrices.Results of the histopathological image classification by using SVMs are shown the nonlinear SFs datasets can provide the better performance characteristics of the classifier when reducing the number of SVs.Hence,the use of nonlinear SFs datasets and SVM with RBF kernel function may be served as a diagnostic tool in modern medicine.Besides,the interpretive performance of SVM can be improved by dimensionality reduction of PCA,ICA,and LDA.Likewise,blockchain technology may be used in the deep learning technique as a storage system and sharing of SS image data over a secure IoT network.This secured electronic health imaging data may be stored in the planetary file system with the latest support vector’s values.Therefore,recent support vectors and different structural features may be available for future works to achieve integrated blockchain technology based SS image data classification and pharmaceutical industry applications.
Acknowledgement:Our heartfelt thanks to Dr.S.Y.Jegannathan,M.D(Pathologist),DPH,Deputy Director of Medical Education,Directorate of Medical Education,Kilpauk,Chennai,Tamil Nadu,India,who provided valuable advice and oversight in guiding our work.
Funding Statement:This work was partly supported by the Technology development Program of MSS[No.S3033853]and by Basic Science Research Program through the National Research Foundation of Korea(NRF)funded by the Ministry of Education(No.2020R1I1A3069700).
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- EACR-LEACH:Energy-Aware Cluster-based Routing Protocol for WSN Based IoT
- Medical Image Analysis Using Deep Learning and Distribution Pattern Matching Algorithm
- Fuzzy MCDM Model for Selection of Infectious Waste Management Contractors
- An Efficient Scheme for Data Pattern Matching in IoT Networks
- Feedline Separation for Independent Control of Simultaneously Different Tx/Rx Radiation Patterns
- Deep-piRNA:Bi-Layered Prediction Model for PIWI-Interacting RNA Using Discriminative Features