基于对称非负矩阵分解的终端区扇区划分方法
2022-08-23张兆宁柯智舟
张兆宁, 柯智舟
(1.中国民航大学空中交通管理学院, 天津 300300; 2.中国民航大学安全科学与工程学院, 天津 300300)
近年来,随着航班数量的激增,终端区资源十分有限,一旦终端区扇区划分不合理,极易造成管制超工作负荷,进而影响飞行的安全性。因此,若要使得管制负荷处于合理的区间,有必要对终端区扇区划分方法进行研究,便于管制部门对扇区单元中航空器保障工作的整体把控。
许多国内外学者对扇区划分方法进行了研究。在国外,2012年,Kumar[1]为了对相邻扇区进行划分,运用ART1神经网络方法均衡了管制员工作负荷的目标需求。同年,Xue[2]基于利用遗传算法对Voronoi
图的扇区边界进行优化,多次迭代确定最终的扇区划分方案。2013年, Flener等[3]提出以管制负荷为约束条件,进行几何扇区优化的方法。2014年,Flener等[4]运用遗传算法对3D空域扇区进行划设优化。2015年,Sergeeva等[5]归纳总结扇区划分的分类标准和限制因素,提出了自动扇区划分的概念,对自动扇区划分做了调查研究。2019年,Granberg等[6]提出了一种谱聚类算法,利用 Voronoi剖分,结合整数编程,对航路和空域扇区进行了划分及优化。2020年,Oktal等[7]结合地理信息系统分析空域,构建空域的区域划分多目标整数规划数学模型,对土耳其空域进行了扇区边界的优化。
在国内,2009年,张明等[8]使用可变精度粗集理论,分析飞行数据,提出了不同航班数量下的动态扇区数目划分规则。2013年,王超等[9]提出顶点间联系程度模型,运用谱聚类算法实现扇区凸形有效分割。同年,尹文杰等[10]将终端区扇区划分当作整数规划问题,解得最优解来生成终端区扇区。2014年,罗军等[11]通过构建拓扑结构模型,并使用粒子群算法解决了扇区优化问题。2015年,王超等[12]以均衡扇区的飞行流量为目的,运用动态规划的方法,进行空域的划分。2017年,王莉莉等[13]基于复杂度因子影响程度来定义管制员工作负荷,利用生长算法对扇区进行划分优化。2019年,王兴隆等[14]把扇区移交点作为研究对象,以最小航班延误成本为目标,利用遗传算法进行延误成本的优化。2021年,张兆宁等[15]提出了一种基于态势的动态优化算法。同年,朱承元等[16]定义交通管制复杂度,利用反向传播(back propagation,BP)神经网络对管制员工作负荷进行预测。同年,高伟等[17]根据空域关键点之间的靠近程度,建立带权重的空域网络结构模型,利用谱聚类实现了扇区的划分。
可以看出,前人研究主要集中于利用几何模型以及启发式算法对扇区单元的划设方法研究,然而使用聚类方法的研究较少。现通过增加恶劣天气和航行情报因素,建立终端区划分模型。以新的组合特征参数生成的 “snake”扇区序列构建对称且非负的相似矩阵,实现聚类效果。为此,使用对称非负矩阵分解(symmetric nonnegative matrix factorization, SNMF)应用于终端区划分,以期实现特征提取和快速降维,提高时效性。
1 终端区划分模型
分析终端区网络加权图,利用节点和边集的权重计算管制员的工作负荷。在原管制负荷定义的基础上增加考虑恶劣天气和航行情报产生的负荷,建立以满足各扇区间管制负荷均衡为目标的终端区划分模型。
1.1 管制负荷和终端区描述
管制员工作负荷,即航空器运行过程对管制员造成了客观的任务需求,管制员为完成监视、冲突、协调等任务对身体和精神上产生的消耗。扇区的划分依据主要是对管制负荷进行量化,因此,定义第k扇区的管制负荷Wk为

(1)
假设终端区模型为二维平面进行划分研究,不考虑高度的因素。在空间二维平面上可以用二元组G(V,E)表示,其中V和E分别为节点和边的集合,以自然航路点为节点,航段为边。终端区网络图则分为有向图和无向图,无向图指的是两个节点之间只有相连接和不相链接的两种关系,即为至多存在一条边,而有向图则指的是两点之间有两个不同方向的连接线组成。采用无向图来进行终端区的描述,无向图中终端区结构的节点集合为V={V1,V2,…,VN},边集为E={E12,E13,…,Eij}。
在实际运行过程中,除了考虑终端区的物理结构,还需要对终端区的整体流量趋势进行分析,因此,终端区划分模型的构建还要考虑流量因素。以通过节点Vi的航空器架次记为权重wi,即图1中圆圈中的数字2、4、7、8、9、10、11、12,通过边Eij的航空器架次记为权重wij,即图1中连线上的数字1、2、3、4、5、6。则终端区网络加权图可以用权重来表示流量,以管制过程中的航空器架次为测度标准的表达,用F={wi,wij}表示。若无向图中具有此属性,则可用三元组G(V,E,F)来表示,图1所示为终端区网络加权图。
1.2 模型构建
从定义上看,管制负荷主要由监视负荷、冲突负荷和协调负荷三部分参数组成,终端区划分需要量化各扇区内管制负荷,建立以均衡扇区间管制员工作负荷为目标的模型。
管制员对扇区k的监视负荷和冲突负荷可用在处理该扇区内经过航路点的飞机总架次的监视和冲突任务所需的时间来表示,飞机总架次可用包含在扇区k内的节点权重wi来表示,即
(2)

(3)
式中:TM、TC分别为处理监视和解决冲突任务所需时间;xik为决策变量。
管制员对扇区k的协调负荷指的是进入和离开扇区k所需的时间,即航空器进入和离开扇区k的飞机总架次移交任务所需的时间,飞机总架次可用权重wij来表示,即
(4)
式(4)中:TO为处理协调任务所需时间;xik、xjk均为节点决策变量,可表示为

(5)
终端区内管制员在日常工作中除了监视航空器、防止航空器产生冲突和跨区飞行航空器的协调工作外。若因风向的改变,引起跑道换向;因日常设备维护,导致部分导航设备关闭;因某条跑道维修,改用单跑道运行等情况,是终端区管制员所特殊需要考虑的问题。且终端区内航空器的进近和离场过程中,天气因素的变化给管制员工作造成的困扰表现较为显著。
因此在原来的管制员工作负荷中还考虑了恶劣天气和航行情报两个因素对管制负荷的影响。则扇区k内的管制负荷的表达式可更新为

(6)
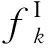
终端区的划分是以满足各扇区单元之间的管制负荷均衡为目标。基于此对扇区单元进行聚类划分,得到划分目标函数为
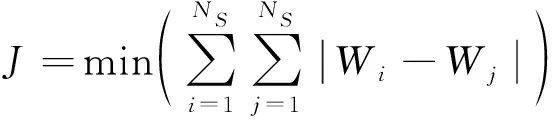
(7)
式(7)中:Wi为扇区i的管制负荷;扇区数目|S|=NS。
扇区单元最终划分个数的确定主要结合英国运筹与分析理事会提出的DORATASK[18]方法分析得出式(8),扇区单元集合为S={S1,S2,…,SNS},最终划分扇区数目为|S|=NS。
(8)
2 模型求解方法
针对模型目标中两两扇区间的管制负荷均衡问题,可以考虑将不同管制负荷之间的关系组合成新的特征参数并用于构建“snake”扇区序列,通过不同扇区单元在“snake”中的不同位置来判断两两扇区单元之间的相似度,构建相似度矩阵。使用对称非负矩阵分解对相似度矩阵进行求解,最终聚类划分的扇区满足目标函数的最优解。
2.1 层次聚类分析
扇区的划分过程中构建扇区序列需要对参数进行加权融合处理。利用专家打分法确定监视、冲突、协调负荷之间的权重大小,生成新的组合特征参数,计算公式为

(9)
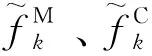
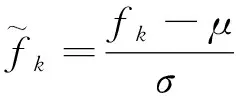
(10)
式(10)中:σ为方差。
在组合特征参数的基础上,参考文献[19]中“snake”的概念。首先,对所有扇区单元运用层次迭代聚类算法进行分析。同时,管制负荷具有相关性,如果终端区空域中的一块扇区在某一时刻发生了负荷过高情况,则会导致其相邻扇区在同一时刻很快也发生同类情况。参照此想法,为了方便在第二步骤完成相似矩阵相似度的计算,在第一步骤聚类过程中,使用层次迭代聚类算法找到各个扇区单元之间相邻且相似的高负荷情况的扇区。其中层次迭代聚类算法的顺序流程图如图2所示。
由图2可看出,终端区中每块特定的扇区模块,都会产生对应的一个扇区序列,由终端区中所有扇区组成,被称为“snake”,其中第一个元素的扇区即为该特定扇区。然而每一条“snake”扇区序列的产生都是由特定扇区开始的,逐一吸收当前已加入的扇区的相邻扇区,直到包含了整个终端区中所有的扇区模块。
在层次迭代聚类算法分析各个扇区单元时,为了得到扇区单元所对应的组合特征参数,“snake”扇区序列首先要识别自己相邻的所有扇区。同时,将相邻的扇区与已经聚类的扇区平均值进行比较。为了在增加扇区单元时,确保扇区与扇区单元之间的低方差和空间相邻性质,选择一个与该扇区最为相似的加入当前扇区系列中。扇区间方差的计算公式为
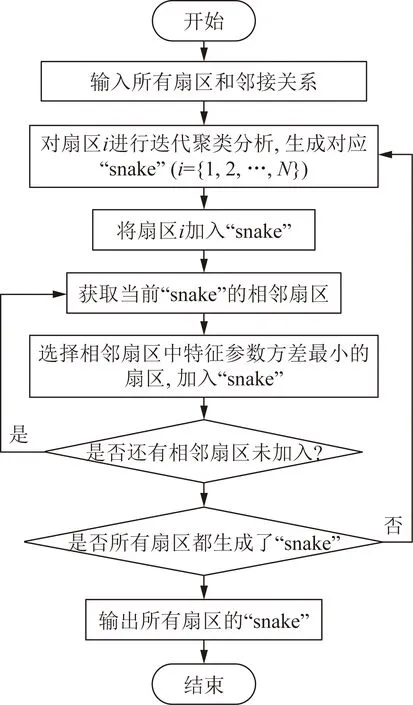
图2 层次迭代聚类算法Fig.2 Hierarchical iterative clustering algorithm
(11)

(12)

2.2 相似度矩阵计算
通过层次迭代聚类算法使得终端区内每个扇区单元模块都有相对应的扇区序列“snake”。在所有“snake”扇区序列的基础上,考虑两两扇区之间的负荷均衡性和空间相连性,在此基础上执行两两扇区单元之间的相似度计算。结果得到每个扇区有且仅有一个由该扇区为首具有相连性和均衡性的扇区序列“snake”区域。因此,通过对所有不同长度尺寸下的扇区序列“snake”中包含的相同元素的数量进行统计,即为两两扇区单元之间的相似度值,可以用两两扇区序列“snake”之间相似度值来表示。计算公式为

(13)
式(13)中:w(i,j)为相似度矩阵W中的元素;sik、sjk分别为扇区i和扇区j之间对应的“snake”的前k个扇区;N为终端区中具有扇区个数的数量;intersect(sik,sjk)为sik和sjk在长度尺寸k的前提下包含的相同扇区的数量,其中,长度尺寸k指的是截取“snake”前k个扇区。
相似度矩阵为两个不同扇区单元之间的相似度值组成的,是用来评判两个不同扇区单元之间的相似程度,即为不同的扇区单元所对应的扇区序列“snake”之间的相似程度,其中该扇区在当前扇区序列“snake”中位置越靠后,则与位于“snake”的起始扇区之间越不相似,极易使得两者之间的相似性不能完全表现出来。因此,为了可以更好地理解扇区序列“snake”中不同的扇区的位置顺序,该扇区应该具有不同权值的原因如图3所示。
图3(a)中,sg和sh两个扇区单元的扇区序列“snake”极为相似的原因,是因为{I,J,K,H}扇区单元从首次被累计计算进来后,每次统计相同扇区时,都会再次被统计一次,直到统计完成所有尺寸的扇区序列“snake”中相同扇区数目为止。因此,这些扇区会被统计很多次。比如,扇区I在sg和sh尺寸为3的时候被统计了一次,这时候尺寸为3的sg和sh有公共扇区数为1,即为{I},下一步统计尺寸增长到4时,sg和sh的公共扇区数同增长到了2,即为{I,J},加上之前计算得到的数据,得到统计的数值为3。以此类推,首先将之前统计得到的相同扇区的数目,叠加到当前的相似度值上,直到所有长度尺寸下的 “snake”中相同扇区被统计完时,扇区I被统计的次数为N-2次。
图3(b)中,扇区{a,b,e}被统计的次数较少,由于处于靠后的位置。因此,sa和sz两个扇区序列“snake”之间的相似程度不同。虽然扇区a出现在sa中第一位置,但是出现在sz中的倒数第二位,最后被统计到的总体次数为3。扇区之间都存在空间相连性,当扇区在不同的“snake”都处于靠前位置,则计算两个“snake”相似度的时候,该扇区被统计的次数偏多。所以,式(13)可以用式(14)来代替,即
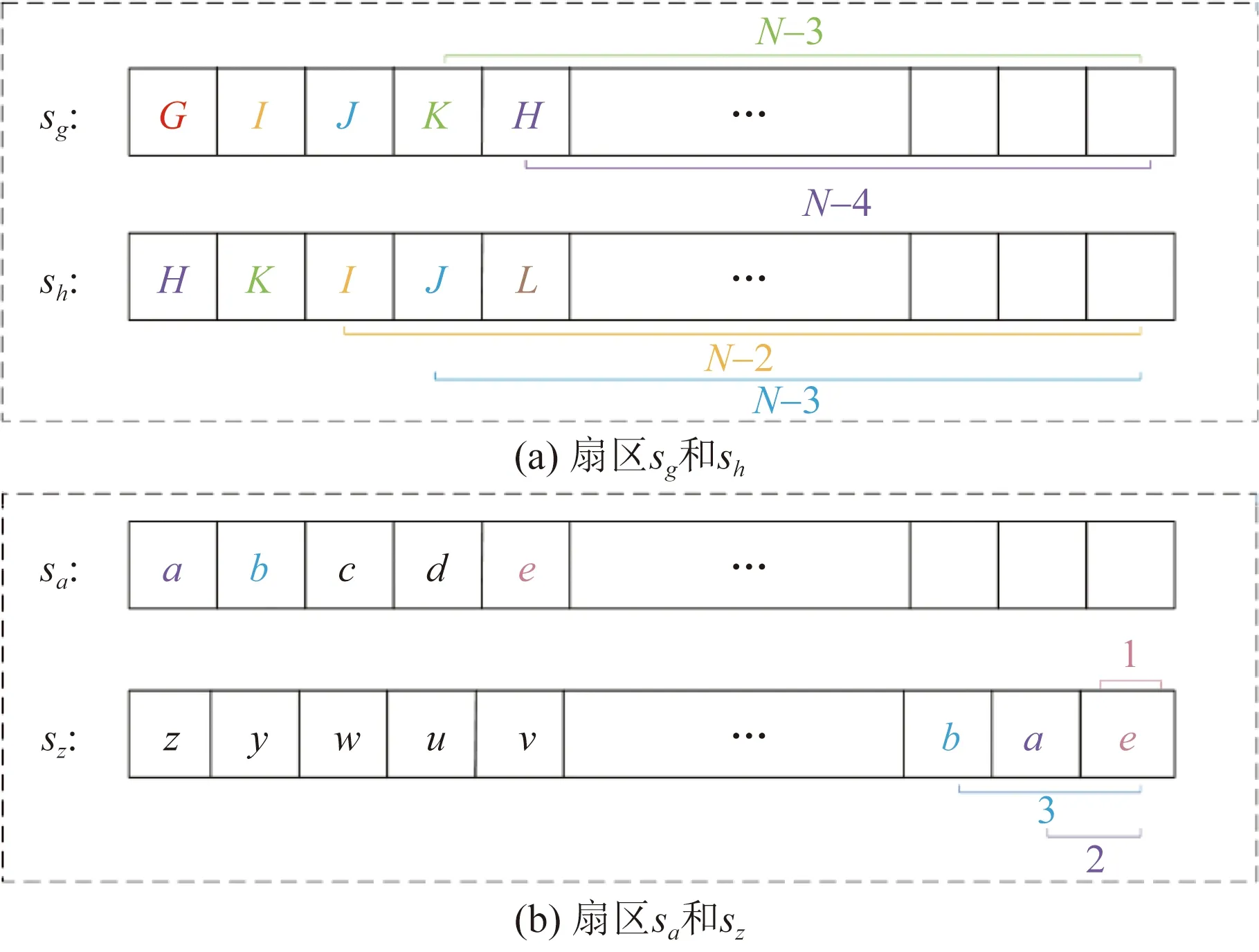
图3 相似度计算Fig.3 Similarity calculation
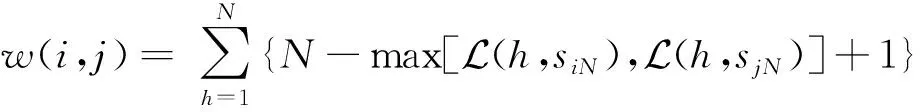
(14)
式(14)中:siN和sjN分别为扇区i和扇区j所对应的完整“snake”;L(h,siN)为扇区h在siN完整“snake”的位置。
扇区在“snake”中的位置越靠前,则越表示它与“snake”之间的相似度越高,若是对两条不同的扇区序列“snake”进行分析,其中所在位置都比较靠前,则可以间接表示两两之间的相似程度越高,同时也反映出扇区序列“snake” 对应的两个扇区之间的相似度也就越高。通过引入了权重系数Φ≥1,可以得到更加紧凑的扇区模块,权重因位置不同而具有不同的权值,使得位置对权重的影响更加明显。
(15)
式(15)中:Φ变大,则更加关注空间位置信息,使得到的扇区模块更加紧凑,从而可以简化下一步中对称非负矩阵分解的步骤。
2.3 对称非负矩阵分解
对称非负矩阵分解(SNMF)是一种图聚类的方法,用构建的相似矩阵可以将原始的数据转化为图形,然后分解矩阵得到最后划分结果。对称非负矩阵分解主要通过对维度的规范,从而降维解决未解(non-deterministic polynomial,NP)难题。在智慧交通领域中,设计区域聚类划分方法时常选用标准割图(normalized cut,NC)作为优化目标函数,目标函数为
(16)
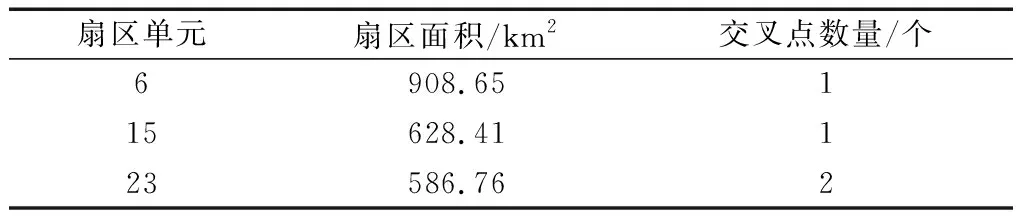
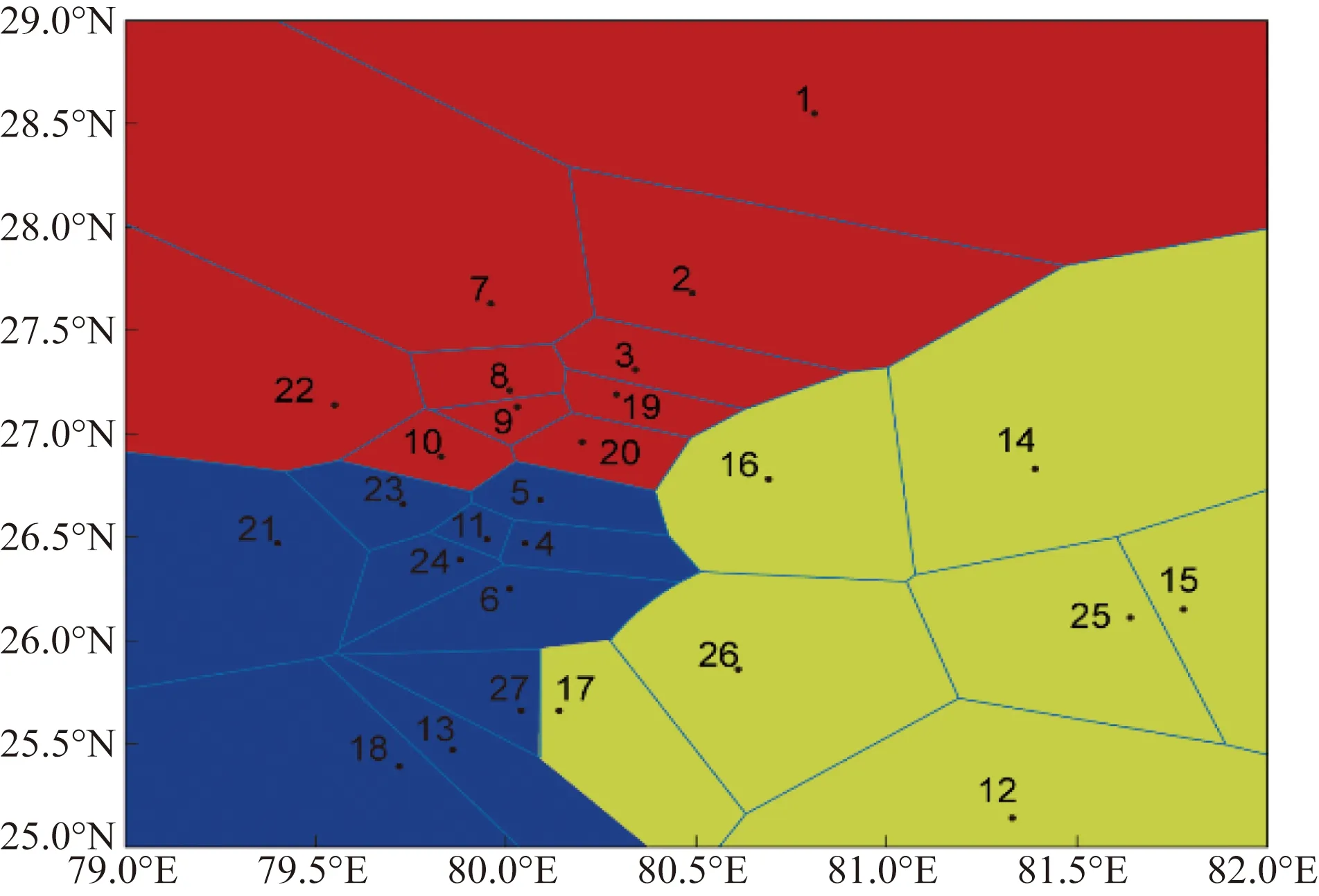
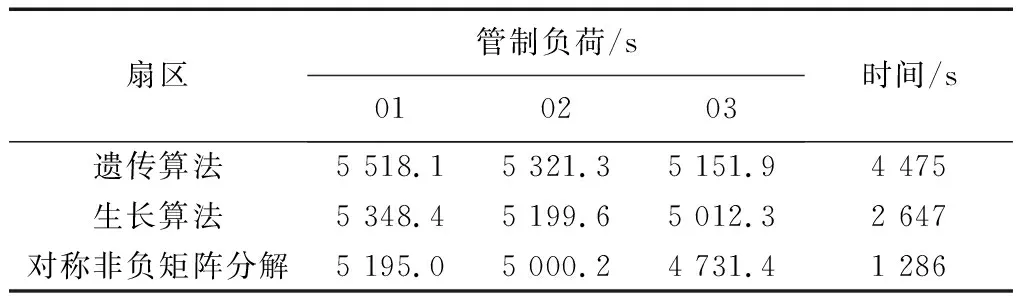
式(16)中:w∈RN×N为相似度矩阵;H∈RN×NS为聚类指示矩阵,其中每一行元素的最大值相对应的列名,则为该实例所属的类别,N和NS分别为扇区个数和预先估计的最后划分扇区个数,通常NS< 上述的目标函数的约束条件H≥0和HTH=I使得优化问题变成了NP难题,为了解决NP难题,SNMF可通过松弛约束变量进行近似求解,SNMF则松弛HTH=I保留H≥0,而约束条件中HTH=I的含义为每个对象有且只有一种类别,通过松弛该约束条件,使得每个对象可以属于多个划分结果,虽然这样得到的结果不符合聚类目的,但是,只保留H≥0的约束条件下,同样能使得最后的划分结果满足HTH≈I。松弛过后的目标函数则变为 (17) 使用公式计算两两扇区之间的相似度,构成相似矩阵w进行归一化处理作为新的相似度矩阵。归一化处理可以很好地限制了终端区扇区面积的大小,防止出现过大或者过小的扇区模块,计算公式为 (18) (19) 在进行对称非负矩阵分解聚类划分的过程中,确定最终划分扇区数量NS,利用随机初始化的方式生成H矩阵,得到满足最小化目标函数所对应的低阶近似矩阵。其中低阶近似矩阵H的每一行代表的都是每个扇区属于此区域的概率,概率最大的类别则为该扇区的归属区域。 以某终端区空域,选取该终端区某日10:00—12:00时间段内的航班数据为依据,研究对象为现实运行过程中的206架航班,43条航段,27个航路自然点及导航台, 11:16—11:46内有恶劣天气的真实数据为例。图4是基于该终端区的重要航路坐标点与终端区结构所绘制的原先终端区扇区单元Voronoi图,则该终端区初步可由26个扇区单元组成。 以本文模型结合终端区扇区结构数据来计算该终端区内每个扇区单元的管制员工作负荷如图5所示,并且表1给予了部分的扇区结构统计数据。 图4 原先终端区扇区单元Voronoi图Fig.4 Voronoi diagram of sector unit in the original terminal area 图5 各扇区单元管制员工作负荷Fig.5 Controller workload of each sector unit 表1 部分扇区结构数据统计Table 1 Part of the sector structure data statistics 对于新的组合特征参数中3种管制负荷关系之间权重的确定,从华东空管局、中南空管局、天津空管局以及民航院校,选取10名专家。均具有丰富的空域扇区划分研究经验和长年的一线管制经历。专家结合实际工作过程中的操作情况,以及科研调研过程中的数据分析对两两参数之间进行权重的确定。综合考虑多名专家的判断,多次反复沟通后对权重求平均值。最终确定α、β、γ分别为0.4、0.4、0.2,生成新的组合特征参数,对扇区进行聚类划分,进行终端区的划设。 根据本文方法,依据Voronoi生成的扇区单元之间进行聚类划分,在基本参数中,统计得到管制总负荷为14 789 s,确定最终扇区个数NS=3,然后进行求解。最终得到如图6所示可以满足扇区间管制负荷均衡效果的划分结果,01号扇区包含1~3、7~10、19、20、22扇区单元,02号扇区包含4~6、11、13、18、21、23、24、27扇区单元,03号扇区包含12、14~17、25、26扇区单元。聚类划分后该终端区所划分的3个扇区的管制员总工作负荷如表2所示。 终端区扇区初步划分结束后,为了避免扇区边界不符合扇区划分原则,产生凹形的扇区边界,将一个扇区边界光滑技术应用于扇区初步划分后的边界,如图7所示。 为了体现本文方法的优越性,比较遗传算法、生长算法对于扇区划分的收敛结果。SNMF划分方法对于图聚类相较于其他两种方法具有良好的收敛性和收敛速度,如表3所示。 图6 终端区扇区划分结果Fig.6 Sector division result of terminal area 表2 聚类后各扇区管制负荷和空域利用率结果Table 2 Control load and airspace utilization results of each sector after clustering 图7 光滑处理后的终端区扇区划分结果Fig.7 Sector division result of terminal area after smoothing 表3 不同方法的扇区划分结果对比结果Table 3 Comparison of sector division results of different methods 结果显示,对于该时段的扇区划分,以新的组合特征参数以及SNMF划分方法的结果中,扇区间管制负荷和空域利用率基本均衡,优于划分前的扇区单元,验证了组合特征参数的有效特征,体现出本文方法的时效性和合理性。 从终端区网络图出发,通过量化管制员负荷,建立扇区划分模型。利用新的组合特征参数构建“snake”扇区序列,计算两两“snake”序列之间的相似度量,构建相似度矩阵并进行归一化处理,下一步利用对称非负矩阵分解方法对相似度矩阵进行分解,得到满足扇区单元之间管制负荷均衡的聚类结果。从结果上来看,划分方法具有良好的效果,结合某终端区的现实数据,展现了模型和方法的有效性,适用于实际应用,为终端区扇区划分方法提供理论依据,使之更加合理。
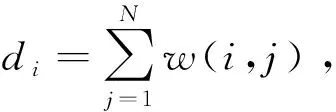
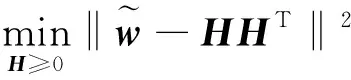
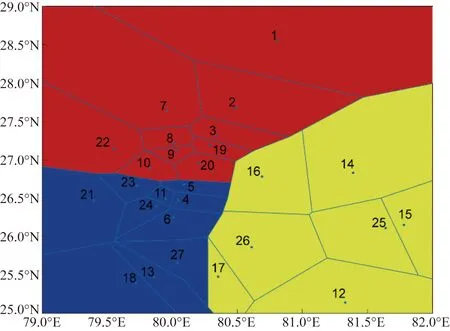
3 算例分析



4 结论
