融合知识图谱的多通道中医辨证模型
2022-08-23叶青张素华程春雷邹静彭琳
叶青, 张素华, 程春雷, 邹静, 彭琳
(江西中医药大学计算机学院, 南昌 330004)
中医辨证主要依赖临床专家依靠感官收集四诊信息,在中医理论指导下,利用四诊信息对证候归属进行判断[1]。辨证是中医认识疾病的基本原则,是中医对疾病的一种特殊的研究和处理方法,也是中医学区别于其他医学的重要特征[2]。
纵观整个中医辨证发展脉络,中医辨证的研究方法可归纳为知识工程、数理统计法、传统的机器学习方法和深度学习四大类[3]。知识工程主要是利用规则的方法进行辨证,但规则较多时则容易出现规则前后矛盾的现象[4]。知识图谱是以图的形式表现客观世界中的实体、概念及其之间关系的知识库。将知识图谱应用于医疗决策是目前的研究热点[5]。严冬等[6]收集了78例患者在北京中医药大学东直门医院脑病科就诊的病历资料,对其进行主成分分析与聚类分析。王伟杰等[7]采用前瞻、多中心的横断面观察性研究方法对302例类风湿关节炎患者病历数据进行逻辑回归分析。这类数理统计的方法在单一疾病的辨证效果尚好,但很难满足真实临床中多种疾病多个证候相兼的情况。许立辉等[8]采用基于关联规则优化的FP-Growth算法,构建了中医证候关联分析模型。刘丽蓉等[9]提出了基于反向传播(back propagation,BP)神经网络和支持向量机方法,探讨并构建了荨麻疹证候分类模型,达到较好的效果。传统的机器学习方法需要领域专家进行复杂的特征设计和提取,相对于其他研究领域,中医领域数据类型繁杂、结构多样并且缺乏统一的标准规范,如何保证数据集的质量面临着巨大的挑战。深度学习算法可从原始数据中自动提取特征,不需要研究者对领域知识有十分深入的了解[10]。张阳等[11]应用深度学习技术分析多囊卵巢综合征患者不同的中医辨证分型与生活方式,该研究数据量相对有限,结果可能有所偏差。许梦白等[12]收集关于不孕症的中医名医病案300例,采用统计学注意力神经网络模型构建不孕症中医辨证模型。然而,该研究所采用的数据仅为文献病案数据,样本量较小,模型在低质量数据中会产生偏移。
临床上的中医病历文本数据在中医四诊(望诊、闻诊、问诊、切诊)的观测角度不同,各方面的特征表达存在差异。例如,问诊部分的“睡眠欠佳经年”与现代医学语言相近;脉诊部分的“略细弦涩,右寸略浮,尺沉稍有力,左关略软”主要根据三部九候的方法对脉象要素进行描述;舌诊部分的“舌质正红,尖略红,苔薄白”主要观察舌质与舌苔的变化;望诊部分的“形体偏瘦”多用于描述面色、皮肤、身材。模型通过对四诊信息多通道的分开处理,训练更为合理。
与此同时,中医电子病历缺乏高质量语料,模型训练容易欠拟合。例如,脉诊与舌诊字段描述较全,但描述区分度较低;闻诊字段则空缺信息较多等。此外,针对一个特定病案,虽然中医病历文本数据中四诊观测角度不同,但各观测角度所得症状存在知识关联。例如,某病案的问诊部分的“睡眠欠佳经年”和望诊部分的“形体偏瘦”具有关联性。加入人工知识图谱,可对模型训练进行知识的增强。
通过上述分析,现提出融合知识图谱的多通道中医辨证模型。鉴于中医辨证结果存在多种证候相兼的情况,对中医电子病历证候字段进行处理,构造中医电子病历多标签分类数据集。人工构建小规模知识图谱,训练知识图谱嵌入向量。对模型中标签注意力部分改进为多通道结构,并将知识图谱嵌入向量嵌入模型中,从而提高症状识别效果。
1 融合知识图谱的多通道中医辨证模型
临床上的中医病历文本数据训练和测试的样本在脉诊、舌诊、望诊、闻诊和问诊的观测角度不同,各方面的特征表达有所差异。针对一个特定病案,虽然中医病历文本数据中观测角度不同,但是各观测角度所得症状存在关联。中医电子病历缺乏高质量语料,模型训练容易欠拟合。根据这些特点,提出融合知识图谱的多通道中医辨证模型。模型整体结构如图1所示,该模型包括以下4个模块。
(1)特征提取模块。通过多个双向长短期记忆网络(bi-directional long short-term memory,BiLSTM)初步提取上下文信息和浅层语义特征,得到可以特征互补的症状句子向量。
(2)知识图谱嵌入模块。人工构建小规模知识图谱,训练中医实体与关系的嵌入向量,得到更丰富的语义特征。
(3)模型融合与预测模块。将特征提取模块和知识图谱嵌入模块进行融合,进行算法的学习与预测。
(4)随机加权平均模块。使用随机加权平均算法[13]进行模型的集成与优化,提高模型的泛化能力。
1.1 特征提取模块
为了获取文本的序列信息,选取基于反馈机制的BiLSTM提取特征信息,hi为双向长短期记忆网络i时刻的输出向量,其表达式为
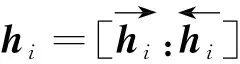
(1)
注意力权重αij的学习通过在原始的网络结构中增加一个前馈网络实现。这一前馈网络的注意力权重的值αij是输出隐藏向量hi和标签隐藏向量wj的点积,其表示形式为
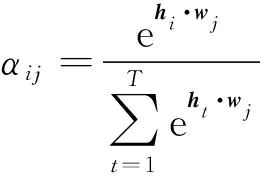
(2)
式(2)中:t为文本某个字符;T为文本长度。
标签注意力模块能够自动地学习权重αij来捕捉症状字符和证候字符的相关性,学习所得的注意力权重将会被用来构建某一个特征向量。在j标签时,注意力输出向量kj的表达式为
(3)
基于多通道的方法借鉴集成学习思想,它训练多个特征并整合,可获得比单个特征更好的性能[14]。鉴于中医电子病历丰富的四诊信息,文本将其应用于文本处理中,设置4个通道,对同样的输入
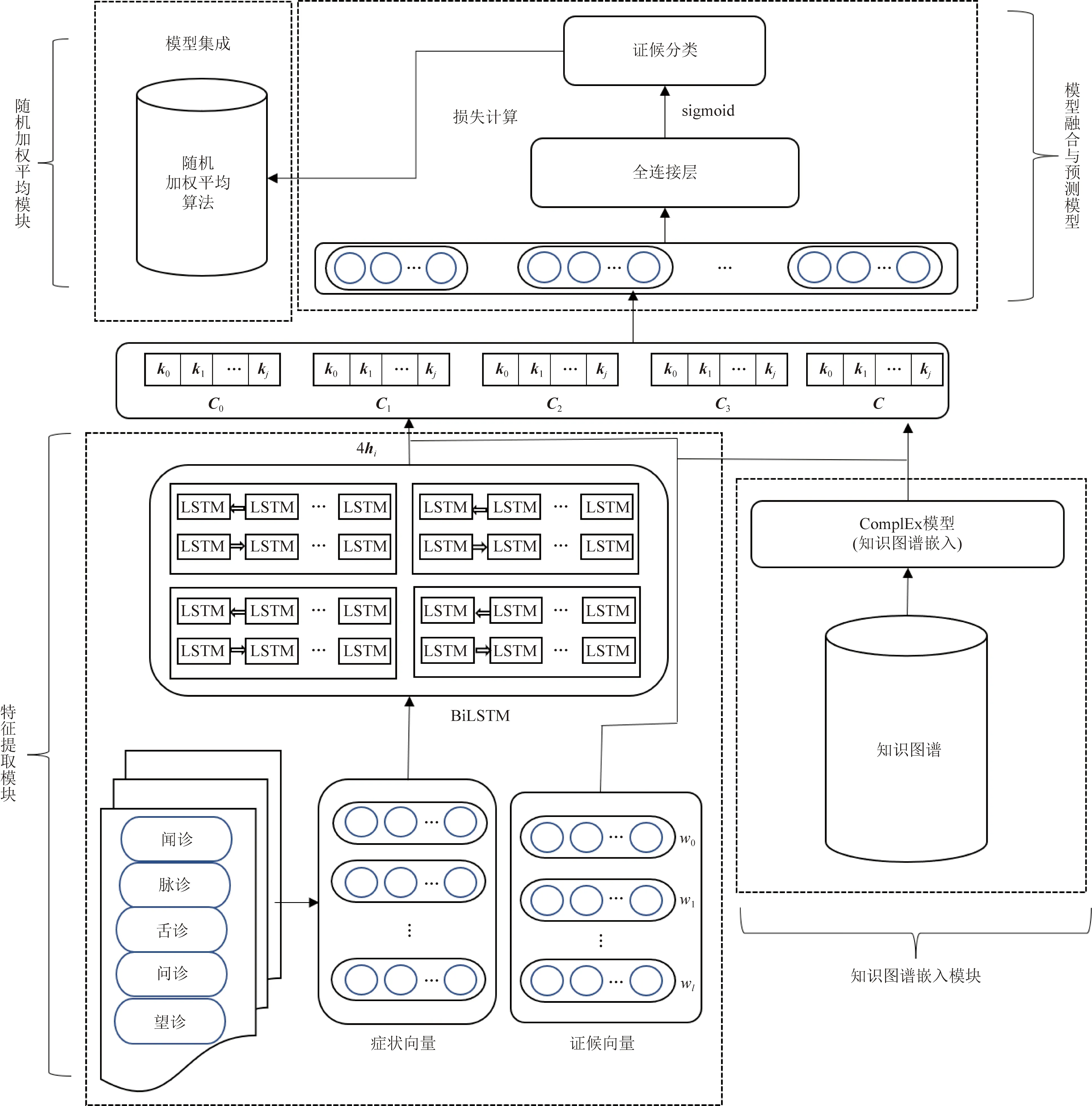
图1 融合知识图谱的多通道中医辨证模型结构示意图Fig.1 Structure diagram of multi-channel Chinese Medicine syndrome multi-label classification model based on knowledge graph
症状进行多种特征表示。如图1所示,假设标签数量为l,第i个通道中特征向量Ci表示为

(4)
式(4)中:k0为第0个标签的注意力输出向量;k1为第1个标签的注意力输出向量,以此类推。Ci∈Rl×m,i∈{0,1,2,3},m为标签向量维度。
1.2 知识图谱嵌入模块
1.2.1 知识图谱构建
为了学习症状之间的内在关联,构造了基于中医电子病历的知识图谱。实体抽取后得到八类实体:脉诊、舌诊、闻诊、望诊、查体、中医诊断、护理宜忌和证候结论;十五类关系:脉诊表现、舌诊表现、闻诊表现、望诊表现、查体表现、证候结论表现、护理宜忌表现、中医诊断表现、脉诊-证候结论、舌诊-证候结论、闻诊-证候结论、望诊-证候结论、查体-证候结论、证候结论-护理宜忌、证候结论-中医诊断。
按中医诊断的逻辑“辨证”,首先通过脉诊表现、舌诊表现、闻诊表现、望诊表现、查体表现、证候结论表现、护理宜忌表现、中医诊断表现来对图谱中8个类别的实体进行汇聚;然后在已有8类实体基础上结合关系:脉诊-证候结论、舌诊-证候结论、闻诊-证候结论、望诊-证候结论、查体-证候结论、证候结论-护理宜忌、证候结论-中医诊断,使用Neo4j构建图谱,总计构建八类实体共202 619个,15类关系,总计1 499 457个三元组。部分知识图谱展示如图2所示。
1.2.2 知识图谱嵌入
知识图谱嵌入是将知识图谱中的实体和关系进行向量表示,主要用于补全知识库的知识,但也可用于知识问答、推荐、语义检索、文本信息增强。
根据评分函数,嵌入技术大致分为两类:平移距离模型和语义匹配模型。对于中医领域,平移距离模型更关注中医关系的多样性。语义匹配模型更关注中医实体和关系的深层次交互信息。在语义匹配模型中,RESCAL模型[15]将知识图谱的三元组编码为张量,通过点积形式的评分函数来衡量实体和关系的语义相关性。为解决随着知识图谱的扩增而导致RESCAL模型计算效率较低的问题,DistMult模型[16]将Mr限制为对角矩阵,通过双线性对角模型学习实体和关系的向量表示。
用嵌入向量的点积作评分函数,可以处理关系的对称性、自反性和非自反性,通过恰当的损失函数还可以实现其传递性。然而,实数向量之间的点积计算具有交换性,DistMult模型不适用于处理三元组反对称的关系。ComplEx模型[17]在DistMult模型基础上引入复数向量的方法捕捉反对称关系,同时保留点积的效率优势,即空间和时间复杂性的线性。
选用更关注实体和关系深层次交互信息的ComplEx双线性模型。该模型中引入复数方法,可解决除对称、非对称外更复杂的对称类型,更能表达中医实体与关系的复杂性。定义事实的评分函数为
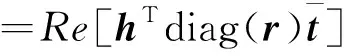
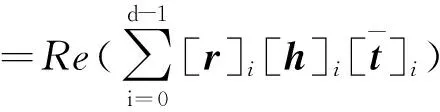
(5)
1.3 模型融合与预测模块
将多通道特征向量和知识图谱嵌入向量输入一个完全连接层和一个输出层中,利用sigmoid函数进行概率预测,标签j的概率为

(6)
式(6)中:z为输出向量;l为标签数量。模型使用二进制交叉熵作为损失函数,该损失函数与sigmoid非线性激活函数匹配。损失函数的计算公式为
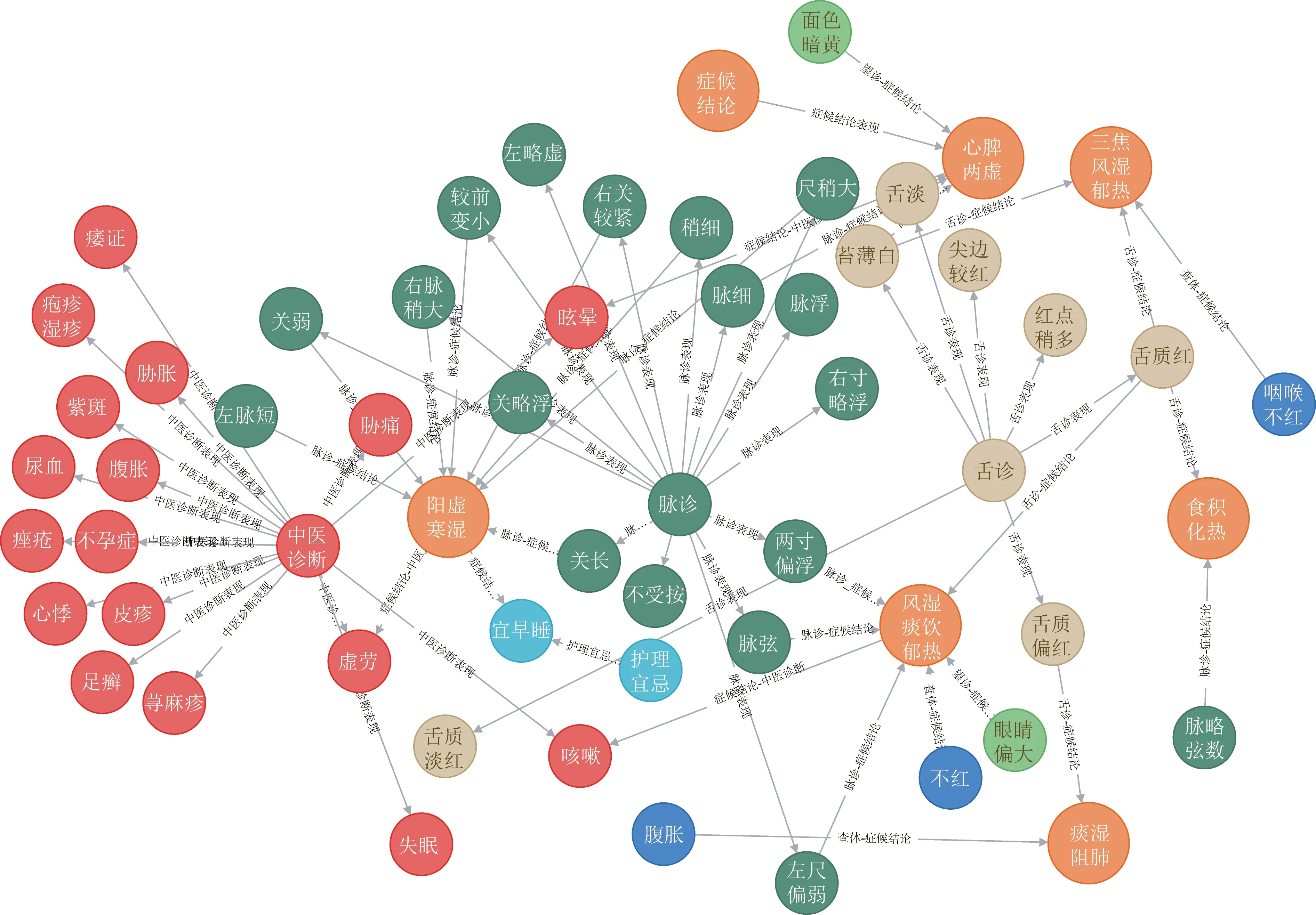
图2 中医电子病历部分知识图谱Fig.2 Part knowledge graph of Chinese Medicine electronic medical record

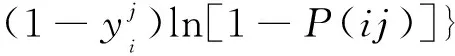
(7)
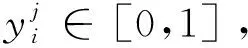
1.4 随机加权平均模块
随机加权平均算法(stochastic weight averaging,SWA)与模型集成方法接近,但其计算损失更小。随机加权平均算法的观点来自经验观察,即每个学习速率周期结束时的局部最小值都倾向于在损失平面上损失值低的区域边界处累积。通过平均化边界点的损失值,可得到具有更低损失值、泛化性和通用性更好的全局最优解。模型平均权重参数更新方程为
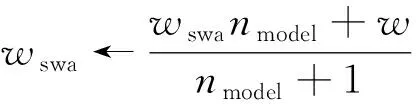
(8)
式(8)中:wswa为模型权重的平均值;w为模型初始化权重或模型经随机梯度更新后的权重;nmodel为模型数量;←表示赋值更新。
2 实验
2.1 实验环境
实验运行环境:算力为NVIDIA T4(6 核 CPU 30 GB 内存,50 GB 工作空间)、17.18 GB 显存;编程语言为python 3;深度学习框架为pytorch。
2.2 实验数据
实验数据来自江西中医药大学岐黄国医书院临床中医电子病历,诊断时间为2009年12月—2019年5月,共有131 651条。该临床中医电子病历字段包括:就诊编号、病历编号、诊次、挂号流水号、脉诊、舌诊、一般情况、望诊、闻诊等共72个字段。经与专家探讨与对电子病历统计分析,选取脉诊、舌诊、望诊、闻诊、主诉(问诊)等症状作为输入特征字段,选取证候(症候)结论作为标签。部分病历数据如图3所示。
各字段存在缺失值,剔除证候结论字段空缺数据,剩余107 958条。证候标签处理参考文献[18],证候标签处理例子如图4所示。将证候结论部分的数据字段以标点符号分割开,形成多个证候标签。若部分数据片段包含其他虚词或无意义词,用正则表达式的方法进行替换,处理过程主要依托python编程实现。最后,中医电子病历数据证候标签总数为3 559类,每条病历平均标签数为5.06条。
2.3 评价指标
参考文献[20],确定选用P@k(k处的精度,k=1,3,5)和N@k(k处的归一化折损累计增益,k=1,3,5)两个经典多标签分类指标作为评估指标。P@k表达式为

(9)
式(9)中:rank(l)为第l个最高预测标签的索引;yrank(l)为指示函数,判断实际类别和预测类别是否一致;P@k为模型预测的前k个概率最大的结果里面含有正确标注的标签的比例。N@k表达式如下。
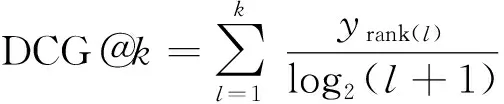
(10)

(11)
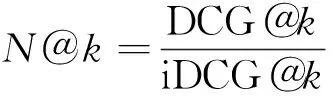
(12)
式中:log2(l+1)为对数衰减因子;‖y‖0为真实标签中的数量;N@k为归一化折损累计增益;DCG@k为折损累计增益,DCG@k令预测正确且排名靠后的证候比预测正确且排名靠前的证候取得更小的精度。N@k是用于排名的度量,N@k相比P@k考虑到位置的评价信息。
2.4 参数设置
实验超参数设置如表1所示。

表1 实验参数设置Table 1 Experimental parameter settings
2.5 实验结果与分析
2.5.1 模型对比实验
为了评估模型的性能,将本文模型与XML-CNN模型[19]、Attention XML模型[20](基线模型)、BERT模型[21]做对比实验。其中XML-CNN模型属于卷积神经网络结构,Attention XML模型属于循环神经网络结构,BERT模型属于Transformer结构。所有模型数据均以107 958条病历数据进行实验,训练集与测试集按8∶2比例进行划分,即数据量均分别为86 367条和21 591条,实验结果见表2。
从表2实验结果可以发现,XML-CNN模型由于较难捕捉到文本序列信息,对本文标签数量大的电子病历数据集表现不佳。Attention XML模型通过长
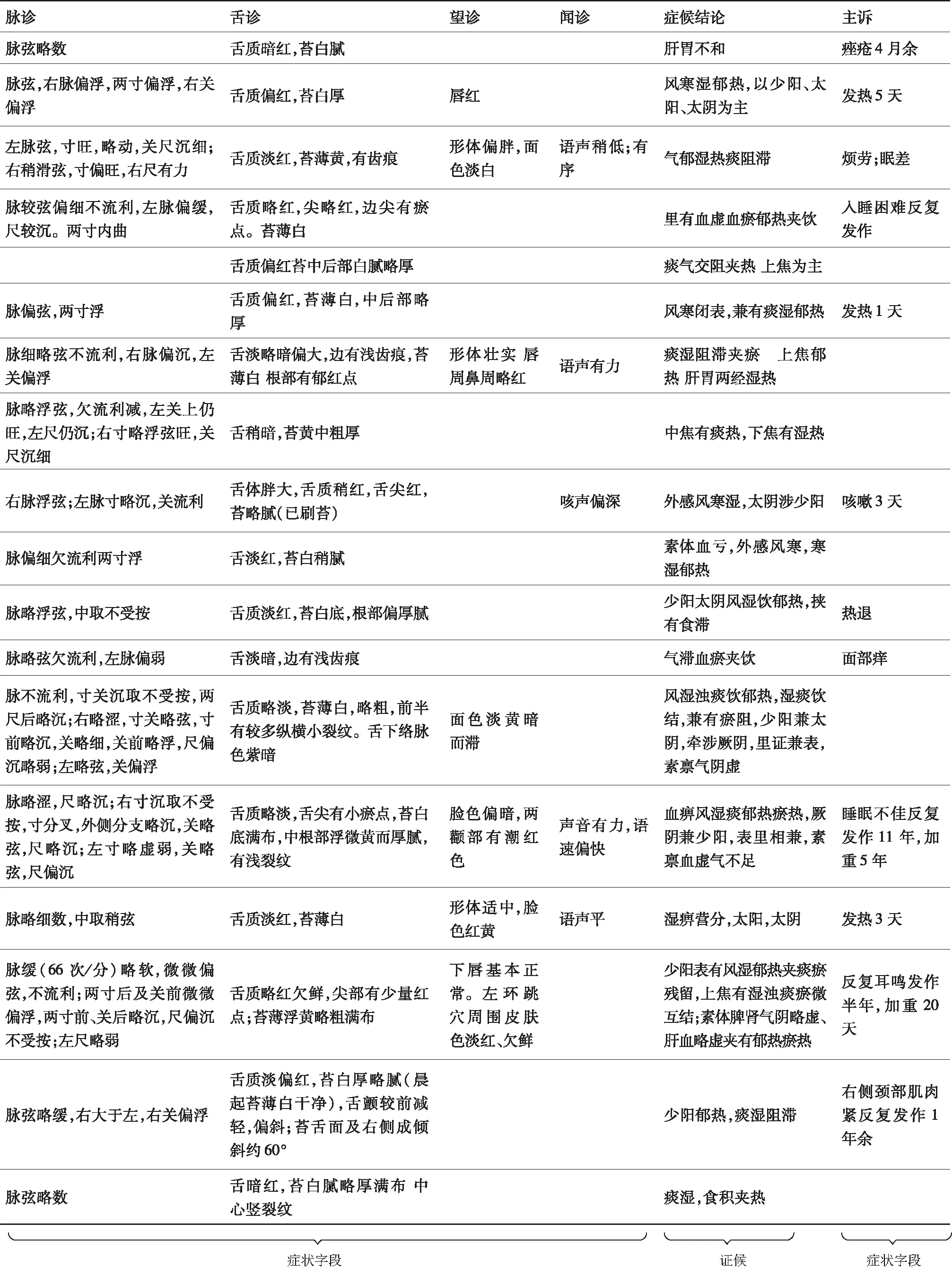
图3 部分病历数据Fig.3 Part of the medical record data

图4 证候标签处理过程示例Fig.4 Example of syndrome label processing process
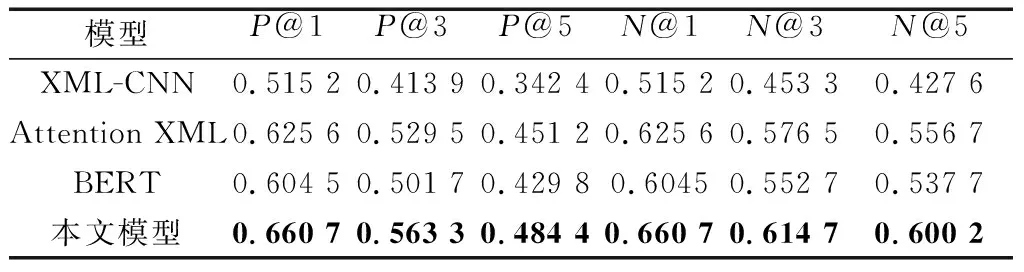
表2 不同模型实验对比结果Table 2 Comparison results of different model experiments
短期记忆网络获取文本序列信息,使用多标签注意力机制融入标签信息捕捉重要的症状特征,达到更好的多标签分类效果,P@1指标相比XML-CNN模型提高11.04%。BERT模型相比XML-CNN模型有更好的实验结果。但中医电子病历语料与通用语料存在一定差异,基于通用语料训练的BERT模型预测结果精确度略差于Attention XML模型。针对病历数据集中症状相互联系和不同观测角度的特征表达不同的问题,对模型中标签注意力部分改进为多通道结构,并将知识图谱嵌入向量嵌入模型中。本文模型在P@1指标上相比Attention XML模型提高3.51%,达到更好的实验效果。
2.5.2 数据量差异实验
为验证数据量大小对模型的影响,将本文模型和Attention XML模型(基线模型)进行数据量差异对比实验。实验结果如表3所示。
可以看出,相比Attention XML模型,本文模型除5.8%数据的P@5略微降低,其他指标均有所提高,证明本文模型的模型效果更好。
相比Attention XML模型,本文模型在P@1指标上在百分比为5.8%、34.7%、58%、100%,电子病历数据集上分别提高0.71%、1.06%、1.61%、3.51%。证实随着电子病历数据集百分比提高,本文模型提高的效果更显著。
2.5.3 模型结构分析
为验证模型结构的有效性,将本文模型拆解成4种结构模型:I(单通道模型);II(单通道及知识图谱嵌入模型);III(多通道模型);IV(多通道及知识图谱嵌入模型)。评估结果如图5所示,可以得到以下结论。
(1)由I和III结果可知,多通道标签注意力结构通过特征互补能更好地识别四诊特征,使模型达到更好的效果。
(2)由I和II结果可知,知识图谱嵌入结构可梳理症状间的关系,提高模型效果。
(3)由III和IV结果可知,知识图谱嵌入结构在N@1提升效果较大,在N@3和N@5则持平或略有下降,说明知识图谱嵌入结构使模型更趋向于预测出最优的结果。
2.5.4 通道可视化与辨证案例分析
将“口腔溃疡反复多年。弦缓略滑舌偏胖嫩而暗,苔平”这条症状输入预测模型中,并截取模型中多通道注意力层的症状字符权重,热力图如图6所示。由图6可知,第一个注意力通道更偏重于“苔平”,而第二、四个注意力通道更关注“口腔溃疡”。由此可见,多通道标签注意力可以获取更多特征,能更好地实现特征互补。
抽取5个病历特征描述输入预测模型中,预测结果展示如表4所示,粗体为预测正确结果。在第1个例子中,模型完全预测正确,其“血糖高”字眼有更强的区分性。在第2个例子中,模型得到“略有风寒”这个与“风寒引动”证候含义相近的证候结论,原因是知识图谱嵌入模型训练中医实体与关系,使得嵌入向量具有更丰富的语义特征,进而使预测模型得到含义相近的证候类型。在第3、4、5个例子中,预测结果均是部分预测正确,部分预测错误的预测结果,说明本文模型及其数据质量仍需要改进。总体而言,从标准证候与预测证候的结果对比可知,模型预测效果良好。
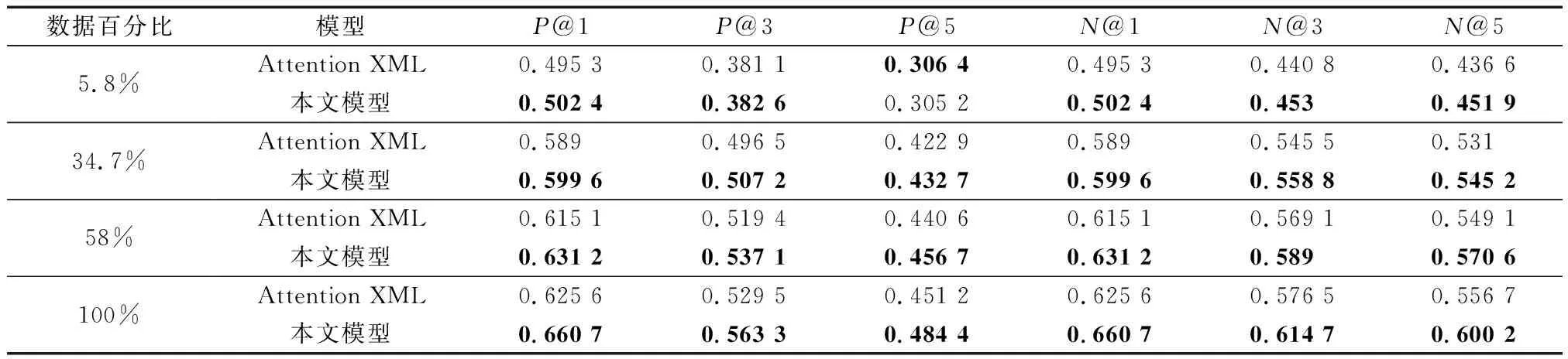
表3 数据量差异对比实验Table 3 Data volume difference comparison experiment

图5 结构评估结果对比Fig.5 Comparison of structural evaluation results

图6 多通道标签注意力结构的症状特征捕捉热力图Fig.6 Multi-channel tag attention structure symptom feature capture heat map

表4 辨证案例Table 4 Dialectical case
3 结论
针对中医电子病历高质量语料缺乏,以及病历样本在不同观测角度的特征表达差异和同一病历的症状存在关联的特点,构建了融合知识图谱的多通道中医辨证模型。实验显示,基于中医电子病历数据集,本文模型在P@1指标、P@3指标、P@5指标上相比基线模型分别提高3.51%、3.38%、3.32%。模型表明,引入涵盖专家经验的知识图谱既有知识对于中医药领域人工智能决策是一个不错思路。
在未来工作中,中医证候较难规范统一,导致任务处理标签巨大。如何基于病历病案现状,提升模型决策效率,实现更为可行的辅助诊断,仍需进一步分析研究。总体来说,中医辨证研究是中医学科的核心问题之一,值得更多的探索。
