针对在线教育情感分析的数据扩充研究*
2022-08-23黄伟强梁韬文杨海华
黄伟强,刘 海,梁韬文,杨海华
(1.华南师范大学 网络中心,广东 广州 510631;2.华南师范大学 计算机学院,广东 广州 510631)
0 引言
随着信息技术的飞速发展,在线教育逐渐兴起,越来越多的人在在线教育课程中留下了有价值的评论,通过对这些评论进行情感分析可以达到多方面的目的,如分析学生对课程的满意度、调查老师授课水平、挖掘课程质量等。
情感分析(Sentiment Analysis),又称为情感倾向性分析[1],目的是找出文本中情感的正负性,如正面或负面、积极或消极,并且把这种正负性数值化,以百分比或者正负值的方式表现出来。情感分析的研究方法大致可以分为两种:一是基于情感词典的情感分析[2],主要通过建立情感词典或领域词典及通过文本中带有极性的情感词进行计算来获取文本的极性,由于依赖于情感词典,存在覆盖率不足等缺点;二是基于机器学习的情感分析,包括监督学习、无监督学习和半监督学习三种方法,其中与监督学习和无监督学习相比,半监督学习通过少量标注数据和大量无标注数据进行识别,既不用对所有的数据进行标注,也不依赖先验经验,有较好的实用性,从而被许多学者应用在情感分析问题上,如陈珂等[3]利用基于分类器集成的self-training方法进行情感分析研究,使用少量标注样本和大量未标注样本来进行情感分析训练,准确率达86%。
数据扩充[4]是一种结合机器学习使用的方法,在训练样本不足的情况下,可使模型训练更好地拟合,通过与半监督的方法相结合,可达到标注少量数据以扩充至大量训练数据的效果。数据扩充方法目前已被用于图像、交通、医疗等领域[5-7],目前主流的数据扩充方法有图像翻转、随机噪声、标签传播等[8]。
情感分析目前已被应用于如电影评论、书籍评论、微博短评等多个领域,但在在线教育课程评论领域的应用还较缺乏,把情感分析应用在在线教育课程评论上存在着各种挑战,如评论数据的获取、评论数据的标注等。为了解决以上问题,本文借鉴半监督学习的方法,提出基于聚类分析的文本数据扩充方法:对少量关键数据进行标注,并通过聚类分析获得大量已标注数据。在目前主流在线教育平台爬取的569 970条课程评论中选取1 000条关键数据进行标注并使用本文数据扩充方法扩充至10万条标注数据,分别利用SVM[9]、RandomForest[10]、AdaBoost[11]、GradientBoost[12]和CNN模型对标注数据进行训练,实验表明,与目前主流的LabelSpreading算法相比,本文的数据扩充方法均有准确率上的优势。
1 课程评论情感分析的流程
在线课程评论情感分析的流程如图1所示。

图1 在线课程评论情感分析流程
(1)课程评论获取与向量化:利用爬虫爬取在线教育平台课程评论数据,把文本的课程评论数据分词及词向量转化后,再组合词向量得到向量化的课程评论数据;
(2)主观评论提取:手工对少量数据进行主客观标注后,经聚类分析把课程评论分为主观评论和客观评论两类,保留主观评论并移除客观评论;
(3)评论情感值计算与标注:手工对少量关键数据进行正负性标注后,利用聚类分析计算主观评论的情感值,利用情感值对数据进行标注,以达到扩充数据的目的;
(4)情感分析模型训练:分别利用CNN、SVM、RandomForest、AdaBoost、GradientBoost模型和前三步得到的大量标注数据进行课程评论情感分析模型训练,并对各模型的课程评论情感分析准确率进行对比。
2 课程评论获取与向量化
在课程评论获取操作中,通过爬取“中国大学MOOC”[13]、“网易云课堂”[14]和“砺儒云课堂”[15]共10 037门课程,获取共569 970条课程评论数据用于制作数据集。获取的课程评论大多为数据长度在10~40字数的中文短评,具体数据长度的数量分布如图2所示。

图2 不同长度数据的数量分布
在课程评论向量化操作中,首先对爬取的课程评论进行分词操作:基于Python环境下的中文分词组件“jieba”对数据集课程评论进行分词,为了支持含特殊字符的表情符的分词操作,对“jieba”组件中匹配关键字的正则表达式及相关代码进行了修改,使其能够识别组成表情符的空格及特殊字符,并通过增加自定义表情符字典的方式,使其对表情符的分词提供支持。
然后,对课程评论进行字典生成和向量生成:利用自然语言处理Python库“gensim”的内置模块“corpora”中的“Dictionary”方法,对分词后的文本进行字典生成,并利用“gensim”中内置的词转向量算法“Word2Vec”对分词后的文本进行词到向量的转换。由于字词的重要性随着其在文件中出现的次数成正比增加[16],为了增强文本向量表达的准确性,利用tf-idf向量[17]作为权值,对词向量进行加权平均后得到文本向量:

其中:⊕表示的是词向量的拼接操作,本文使用的是向量的加法;ri表示文本各词的向量;R表示文本向量;n表示该文本含有的词的数量;ti表示词的tf-idf权值。
课程评论向量化操作中使用的词向量维度为128维,词向量训练规模为268 GB的中文语料,滑动窗口设为20×120。
3 基于聚类的数据扩充方法
3.1 算法表示
基于以下两个假设,使用基于聚类分析[18-19]的方法计算各课程评论的情感值,以实现课程评论的正负性标注:
(1)在文本向量空间中距离相近的2个文本正负性质相近;
(2)在文本向量空间中2个文本距离越近,其正负性质越相近。
借鉴半监督训练的方法,通过标记少量的数据来对整个数据集进行情感值的计算,把标记的数据作为情感值计算的标杆,基于以上两个假设对整个数据集进行聚类操作。
使用第2节中向量化后的课程评论数据作为数据集T,设ti∈T,使用Mi来表示ti的情感值。Mi为正则表示评论ti偏向正面,Mi越大表示正面性越强;Mi为负则表示评论ti偏向负面,Mi越小表示负面性越强。在T中选取适量课程评论数据作为初始数据集Tj,对任意tj∈Tj,对tj手工标记mj:若该评论为正面评论则标记mj=1,若该文本为中性评论则标记mj=0,若该文本为负面评论则标记mj=-1。设正整数常量Minit(经本文实验,Minit=100为一个较合适的取值),用于对Mi进行初始化。对于每个ti,设置其Mi值:

设dij为评论ti与评论tj在向量空间的距离;设距离dfar,若dij≤dfar,则表示ti与tj的正负性质一样(经本文实验,dfar取除杂后向量空间中各评论数据平均距离的1/8为较合适的值);设距离dclose,若dij≤dclose, 则表示ti与tj非常接近 (经本文实验,取为较合适的值)。在每一轮聚类中对于新标记的课程评论数据集Tk(初始时Tk=Tj)中的每一条评论tk,按下式更新其附近课程评论集合Tl中每一条评论tl的Ml值:
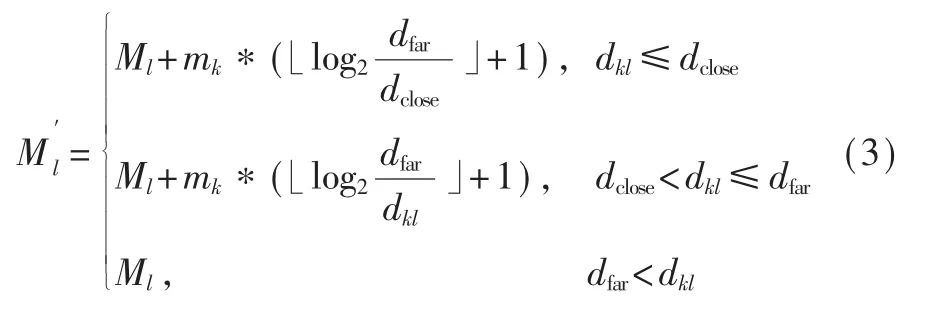
式(3)中表述了更新tl情感值的三种情况(见图3):

图3 三种更新情感值的情况


3.2 实际例子
设tk被手工标注为mk,t1、t2、t3、t4为tk附近的课程评论,对于算法中每一轮聚类过程及式(3)的更新过程,以下给出两个实际例子进行说明。


表1 实际例子1


表2 实际例子2
3.3 情感值计算实验结果
使用手工标注约800条课程评论数据进行正负性聚类用于课程评论的情感值计算,经主客观聚类后提取的主观课程评论数据通过PCA[20]降维操作可视化后的分布情况见图4。

图4 文本在正负性向量空间的分布情况
聚类后的部分评论及对应情感值Mi见表3。

表3 正负性分析部分结果
情感值计算的准确率使用基于古典概型[21]的方法推算得出:通过另外随机手工标注课程评论数据并剔除Mi=0的评论,直到最终剩下n条课程评论,在n条课程评论中统计标注与聚类结果相符(即另外标注结果与实验结果同为正面或同为负面)的数据量k,使用下式推算实验准确率:

其中,P(A)为标注与聚类结果相符的事件A发生的概率,即推算出的准确率。本文实验使用100条课程评论数据用作统计,即取n=100;统计出100条数据中标注与聚类结果相符的数据有86条,即k=86。基于上述计算,推算出准确率达86%。
在完成情感值计算的课程评论中,本文选取情感值最大的5万条正面评论及情感值最小的5万条负面评论共10万条课程评论用于下文情感分析实验。
4 基于聚类的主观数据提取
使用3.1节中算法对向量化的569 970条课程评论数据进行聚类分析及主客观性质计算,通过手工标注约1 000条课程评论数据进行主客观聚类,由文本在向量空间[22]通过PCA降维操作后的分布情况(图5)可知:主观评论数据及客观评论数据已经在几个地方分别聚集成团,但由于手工标注的课程评论数量有所不足,使得部分数据不能参与聚类,从而造成图中仍有部分中性数据。

图5 文本在主客观向量空间的分布情况
聚类后的部分评论及对应主客观性质Mi见表4。

表4 主客观分析部分结果
通过另外手工标注的100条课程评论数据中有81条标注与聚类结果相符(即另外标注结果与实验结果同为主观或同为客观),即n=100,k=81,由式(4)可推算准确率达81%。
剔除干扰评论数据、中性评论数据及客观评论数据后,本文最终筛选出23万主观课程评论用于情感值的计算及正负性标注。
5 情感预测分析
5.1 情感分析方法及参数设置
采用3.3节筛选出的10万条课程评论数据进行情感预测分析实验,随机取其中90%作为训练集,其余10%作为测试集,分别采用基于机器学习库“sklearn”的SVM模型、RandomForest模型、AdaBoost模型、GradientBoost模型和基于TensorFlow的卷积神经网络(CNN)模型进行情感预测分析。支持向量机(SVM)模型是一种在分类与回归中分析数据的学习模型,SVM模型把数据映射为空间中的点,使每一类数据被尽可能宽地间隔分开;随机森林(RandomForest)模型是一个包含多个决策树的分类模型,其通过平均多个深决策树以降低方差;AdaBoost模型是一种自适应的迭代模型,其在每一轮中加入一个新的弱分类器,以减少分类的错误率;梯度提升(GradientBoost)模型是一种用于回归和分类问题的机器学习模型,其以分阶段的方式构建模型,通过允许对任意可微分损失函数进行优化实现对一般提升方法的推广;CNN模型是一种前馈神经网络模型,它的人工神经元可以响应一部分覆盖范围内的周围单元,近年来在图像处理和语音处理上取得不少突破性进展,也有被应用于情感分析领域。
各模型参数设置见表5。

表5 模型训练参数设置
本文实验设备配置为Inter®CoreTMi7-9750H CPU和NVIDIA GeForce GTX 1650显卡,系统环境为64位Windows 10系统,Python版本3.6.8。
5.2 模型训练结果
对比sklearn的Label Spreading半监督学习算法,本文基于聚类分析的文本数据扩充算法在5个模型的情感分析准确率上均有明显优势,在SVM模型上准确率相差最大,在CNN模型上准确率相差最小。其中进行LabelSpreading实验时,kernel选择KNN,其他参数保持默认,使用标记为3.3节的手工标注,数据集为569 970条课程评论数据向量,最终随机筛选出10万条课程评论数据进行情感预测分析实验。
在5个机器学习模型的准确率对比上,CNN模型的准确率最高(使用基于聚类分析的文本数据扩充算法时准确率达96.5%,使用LabelSpreading算法时准确率达84.47%);在使用基于聚类分析的文本数据扩充算法时,各模型准确率均高于89%。详细对比见图6。

图6 本文方法与LabelSpreading在5种模型的准确率对比
准确率最高的CNN模型在训练时的loss和准确率随epoch的变化见图7:随着epoch的增加,loss逐渐减小,准确率逐渐提高,模型训练在约第70个epoch收敛;loss最低值为0.012 6;准确率最高值为97.01%,最终准确率为96.50%。
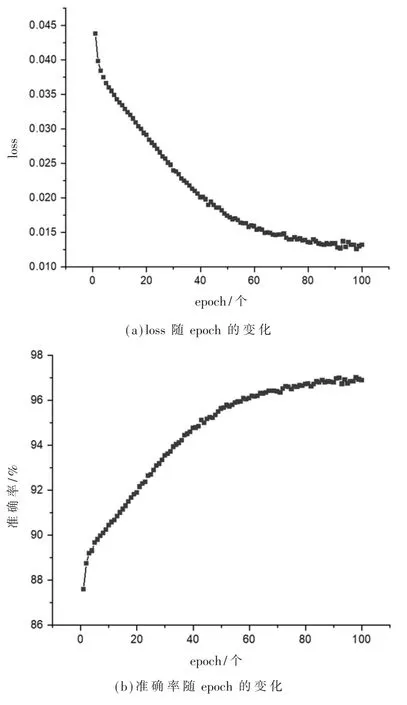
图7 loss及准确率随epoch变化图
6 结论
本文针对情感分析应用在在线教育领域上的数据标注问题,提出了基于聚类分析的数据扩充方法,手工标注少量关键数据以扩充至大量标注数据。利用该方法扩充的数据,在多个主流机器学习模型和CNN模型上进行情感预测分析训练,结果表明,经过扩充后的数据在各模型上的准确率均达89%以上,其中在CNN模型准确率达96.5%。使用本文方法扩充的数据在各模型上得到的准确率皆优于目前主流的LabelSpreading数据扩充算法的准确率。
