Fruits and Vegetables Freshness Categorization Using Deep Learning
2022-08-23LabibaGillaniFahadSyedFahadTahirUsamaRasheedHafsaSaqibMehdiHassanandHaniAlquhayz
Labiba Gillani Fahad,Syed Fahad Tahir,Usama Rasheed,Hafsa Saqib,Mehdi Hassan and Hani Alquhayz
1Department of Computer Science,National University of Computer and Emerging Sciences,Islamabad,44000,Pakistan
2Department of Computer Science,Air University,Islamabad,44000,Pakistan
3Department of Computer Science and Information,College of Science in Zulfi,Majmaah University,Al-Majmaah,11952,Kingdom of Saudi Arabia
Abstract: The nutritional value of perishable food items, such as fruits and vegetables,depends on their freshness levels.The existing approaches solve a binary class problem by classifying a known fruitvegetable class into fresh or rotten only.We propose an automated fruits and vegetables categorization approach that first recognizes the class of object in an image and then categorizes that fruit or vegetable into one of the three categories: purefresh, medium-fresh, and rotten.We gathered a dataset comprising of 60K images of 11 fruits and vegetables,each is further divided into three categories of freshness, using hand-held cameras.The recognition and categorization of fruits and vegetables are performed through two deep learning models:Visual Geometry Group (VGG-16) and You Only Look Once (YOLO),and their results are compared.VGG-16 classifies fruits and vegetables and categorizes their freshness,while YOLO also localizes them within the image.Furthermore, we have developed an android based application that takes the image of the fruit or vegetable as input and returns its class label and its freshness degree.A comprehensive experimental evaluation of proposed approach demonstrates that the proposed approach can achieve a high accuracy and F1score on gathered FruitVeg Freshness dataset.The dataset is publicly available for further evaluation by the research community.
Keywords:Fruits and vegetables classification;degree of freshness;deep learning;object detection model;VGG-16;YOLO-v5
1 Introduction
Appearance,such as color,texture,size,and shape,can be used to find the category of freshness of fruits and vegetables [1,2].The freshness can be categorized into pure-fresh, medium-fresh, and rotten.An automated system to identify these categories can be useful for individual consumers as well as for fresh items trading industry[3,4].However,high intra-class variations make it a challenging problem since the fruits in the same freshness category can have different appearances[5].Approaches exist that focus on the categorization of a single fruit or vegetable into pure-fresh or rotten only[6],while to the best of our knowledge, none of the approaches identifies the medium fresh category.Identification of medium-fresh category is useful in reducing the wastage of fruits and vegetables.However, differentiating the medium-fresh from the pure-fresh and rotten categories is the most challenging part because of the fine-grained differences between them.Moreover, by assuming that the class of the fruit or vegetable is already known,the existing approaches solve a binary problem of fresh or rotten,while the similarity among different fruit and vegetables does not remain a challenge[2,3,5,6].However, this interclass variation becomes significant if the class of fruit or vegetable is unknown.For example:a green banana and a cucumber can have similar shape,while a green lemon and a green orange can have same appearance[7].
Unlike the existing approaches solving a binary class problem of fresh and rotten category of a known fruitvegetable,the proposed approach performs two tasks:first it detects and assigns a label to the fruit or vegetable in an image;second,it categorizes the freshness of that fruit or vegetable as pure-fresh,medium-fresh,or rotten.In this regard,our contributions are three folds:
· We propose FruitVeg Freshness dataset of 60K images of 11 fruits and vegetables, each with three categories of freshness.
· For recognition of a fruit or vegetable and to categories its three freshness levels,we formulate a multi-class classification problem.
· We develop an android application for a real time demonstration of our system.
Our self-collected FruitVeg Freshness dataset contains 60K images of eleven fruits and vegetables,each of which is further categorized based on freshness.In the proposed approach,we first detect and localize the object such as fruit or vegetable in the image.Next,the category of freshness from the three is identified.Thus, we solve a multi-class problem with 33 classes by exploiting two Deep learning models VGG-16 and YOLO-v5 and compare their results.VGG-16 classifies fruits and vegetables and categorizes their freshness,while YOLO,in addition to the classification and categorization,also localizes the objects within the images.We achieve the accuracy of 82% and 84% on the proposed dataset,respectively.
The rest of the paper is organized as follows:In Section 2,related work on fruits and vegetables classification is discussed.In Section 3,we present the proposed FruitVeg Freshness dataset.Next,In Section 4,the proposed fruits and vegetables freshness approach identification approach is discussed.The experimental analysis is presented in Section 5.Finally,Section 6 draws conclusions.
2 Related Work
Fruit texture,color,and shape are three key visual features for assessing fruit quality[2].Different machine learning techniques including Support Vector Machines (SVM), Multi-Layer Perceptron(MLP) and K Nearest Neighbor (KNN) classifiers are used to identify the healthy apples from the defective ones.Among the three classification techniques,SVM shows better performance.In visual object recognition,deep learning is widely employed[8,9].YOLO is faster compared to the previous methods,achieving a real-time image processing speed of 20 frames per second[10].A classification approach using image saliency and Convolutional Neural Network (CNN) differentiate fruits and vegetables [11].The deep neural network, VGG, is used for recognition, demonstrating that CNN can reach a high accuracy as they go deep[12–14].In contrast to[11],a shallow network is used for feature extraction [15], with four convolutional and pooling layers followed by two fully connected layers.However,the background of the input image is simple,where all the fruit items are placed on a white background.Another quality grading approach exploits the visual characteristics to build a computer vision-based system for the classification of tomato as either defective or healthy[5].An autonomous approach to rank the olive fruit batches uses discrete wavelet transform and textural data[16].Another approach exploits deep learning for recognition of raspberry using a 9-layered CNN with 3 convolutional and pooling layers,one input and one output layer[3].
In a hybrid deep learning approach for fruit classification, first, hand crafted features are extracted.In the next step,it uses convolution autoencoder to pre-train the images and then applies an attention based DenseNet to process the images[17].A tomato disease detection and classification approach uses transfer learning[6,18].Multiple deep learning models are used to classify nine types of diseases in leaves including healthy tomato leaves.Among all, DenseNet Xception shows better performance.CNN is used to learn the inter-class variations between different types of fruits [19].Deep learning techniques are used to identify leaf stress issues on 33 types of crops related to fruits,vegetables, and other plants [20].Different machine and deep learning techniques including SVM,KNN,Naïve Bayes(NB)and CNN have been used in the recognition of insect pests for wheat,rice and soybean crops using publicly available datasets[21].Among all the techniques,CNN shows the best performance.Computer vision and Machine learning based systems have been previously applied to the field of vegetables and fruits classification[22],using texture and color features to identify and describe the damaged areas on fruits [23].Moreover, color co-occurrence has been used to classify diseased and normal leaves in citrus fruit [24,25].In [26], local damage to strawberries is detected using local key point detectors,such as Scale Invariant Feature Transform(SIFT)and Oriented Fast and Rotated BRIEF(ORB).Moreover,CNN is also used to identify the freshness of fresh-cut iceberg lettuce[27].
An automated approach based on computer vision and deep learning is presented in [28] to detect the different diseases of Guava Fruit.Local Binary Patterns (LBP) are used for feature extraction and Principal Component Analysis(PCA)is used for dimensionality reduction.Different machine learning approaches including SVM,KNN,bagged tree and RUSBoosted tree are used for classification.Among these, SVM shows better performance [28].An automated plant leaf disease detection approach is discussed in [29], where features are extracted using LBP, segmentation is performed to identify the Region of Interest(ROI),while one class SVM is used for the classification of leaf diseases.In a citrus fruit disease detection approach,ROI is identified using Delta E segmentation,color histogram and textural features are extracted and then SVM is used for classification [7].The Performance evaluation of five CNN based models including NasNet,Mobile,Xception,DenseNet,Inception ResNetv2 and Inception v3 with transfer learning and data augmentation techniques is discussed in[30]for classification of tomatoes.
An approach to identify the fresh and rotten fruits based on ensemble learning is discussed in[31],that combines two deep convolutional neural networks:Resnet-50 and Resnet-101.The approach first differentiates between the fresh and rotten fruits and then identifies the type of fruit.An automated fruit classification approach presented in[32]exploits deep learning and stacking ensemble methods to identify the fresh and rotten categories of banana and apples.Moreover, it is emphasized that a cost-effective solution based on Respberry Pi module, camera and touchscreen can also be used for the real time monitoring of fruits.Deep features extracted using CNN can be effective in detecting and analyzing the freshness of different varieties of food items [33].A fruit classification approach is presented in [34], where images obtained from the CMOS sensors and Kaggle fruit360 dataset[30] are used to train a CNN model to identify six categories of fruits including fresh and rotten apples,bananas,and oranges.Moreover,augmentations techniques of scaling,rotation,translation,Gaussian noise addition, brightness variation have also been applied to the obtained images [34].Hyperspectral imagery and machine learning techniques based on Artificial Neural Network(ANN)and Decision Tree (DT) have been applied to detect the penicillium fungi in citrus fruits [35].A performance comparison of three deep learning models including Alexnet,Googlenet and Inception V3 is performed for the identification of water stress conditions of three crops maize, okra and soyabean[36].Among the three models,Googlenet shows the best performance compared to the rest of the models.A fruit ripeness estimation technique first resizes the images to the same size and then perform segmentation to extract the image from the background[37].In the next step,color features are extracted,and an adaptive neuro-fuzzy inference system is used for identification of different stages of fruit ripeness.
Finally,we compare the existing datasets based on the number of classes,number of images,size of images, and freshness categories per class (Tab.1).Most of the datasets are fruit-and-vegetable classification datasets only.A few exist for freshness categorization;However,these datasets focus on binary categorization of fresh and rotten only.The medium-freshness category is ignored by all the datasets, Moreover, these datasets have images of only a single fruit or vegetable.It is important to collect a dataset that includes multiple fruits and vegetables and the three categories of pure-fresh,medium-fresh, and rotten for ranking of fruits and vegetables to be used for trade industry and for timely consumption of the fresh items.

Table 1: Existing datasets used in fruit classification,freshness categorization or disease detection

Table 1:Continued
3 FruitVeg Freshness Dataset
Fig.1 shows the sample images from the dataset.The similarity among the three categories of freshness is high within the same fruit/vegetable.In addition,different fruits and vegetables may appear similar because of the shape/color, while the same class may appear different in different instances,which makes it a challenging dataset.The FruitVeg Freshness dataset is publicly available for further use by the research community.
Tab.2 shows the details of the proposed FruitVeg Freshness dataset.The proposed dataset contains a total of 60059 images divided into 11 fruits and vegetables:six fruits(Apple,Banana,Guava,Orange,Lemon and Tomato)and five vegetables(Brinjal,Cucumber,Chili,Pepper and Potato).Each fruitvegetable is further categorized into three categories based on the freshness.Digital images of size 1088 × 1088 are captured using hand-held mobile cameras and are also gathered using the various sources from internet,such as some samples of pure-fresh category are obtained from Fruit365[30].RGB colored images are collected in both dark and bright lighting conditions with variable background complexities such as from plain white background to complex backgrounds with varying color patterns.Size of each image is 1088×1088.Images contain both single and multiple objects such as 30%of the dataset consists of single objects,while remaining has multiple objects ranging from 2 to 20.We annotate the whole dataset manually using the MakeSense tool online.
4 Proposed Methodology
Let N × 3 be the number of classes of fruit and vegetable, where N is the number of fruitsvegetables, and each fruitvegetable has three categories based on the freshness level.Fig.2 shows the block diagram of the proposed freshness recognition approach.The preprocessing step involves preparing the dataset for the training.It represents object cropping,resizing and annotation using the annotation tool ‘makesense.ai’.We exploit and compare two classification models for recognition and categorization of fruits and vegetables: VGG-16 and YOLO-v5.VGG-16 is a classification model,while YOLO-v5 performs localization and classification in an image.

Figure 1:Sample images from fruitveg freshness dataset separated in three categories
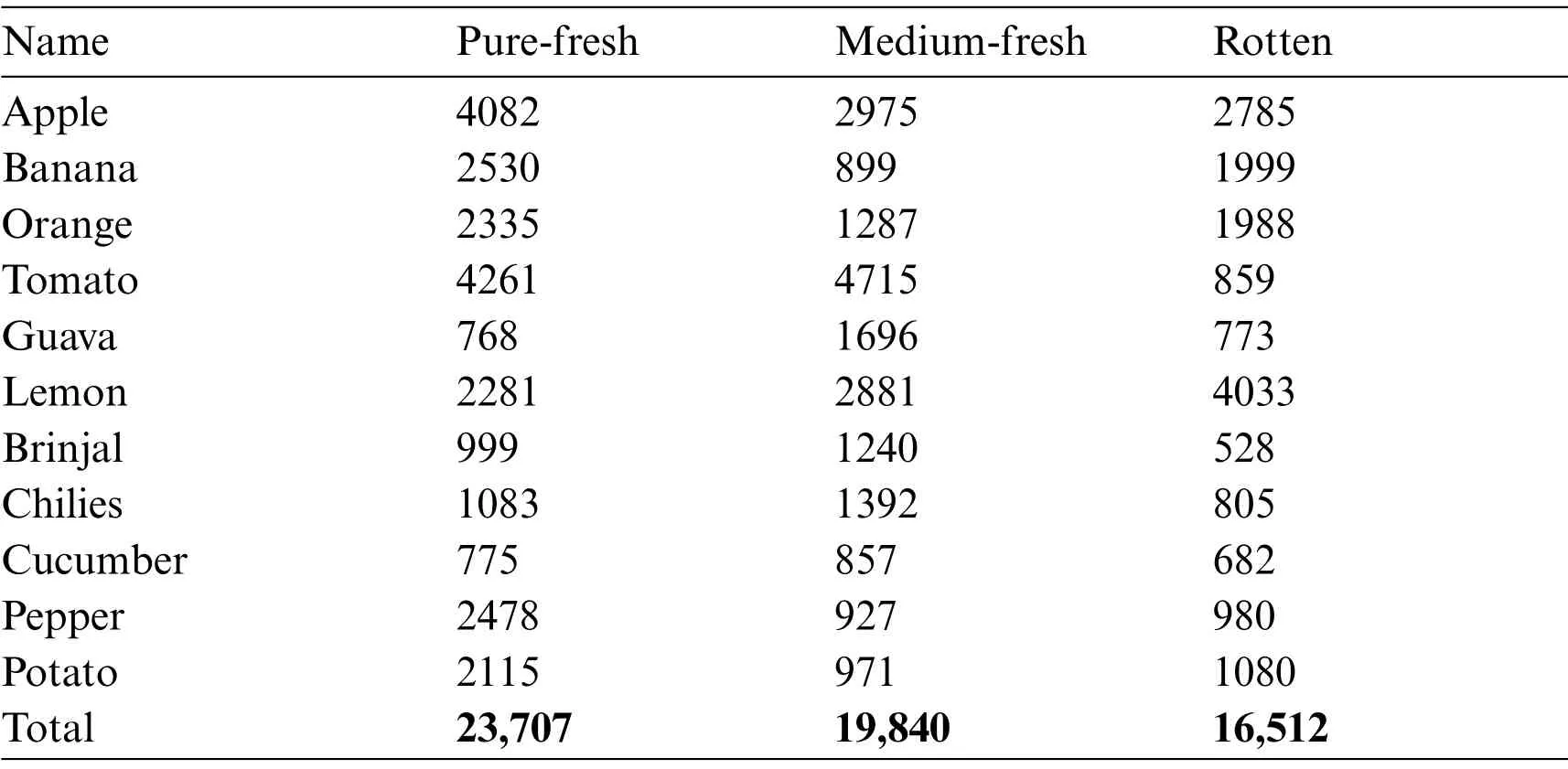
Table 2: Dataset containing 60059 images of 11 fruits and vegetables in 3 categories
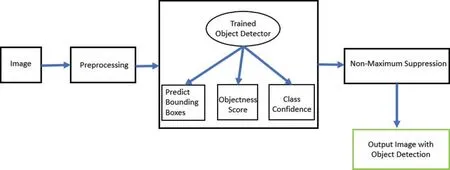
Figure 2:Block diagram of the proposed approach
4.1 VGG-16 Architecture
Fig.3 shows the architecture of VGG-16[39,40].We use softmax activation function in the output layer of model because there are multiple classes available i.e.,Pure-fresh,Medium-fresh and Rotten.In the case of softmax,the sum of probabilities of all classes in output is 1,given in Eq.(1).

Figure 3:VGG-16 CNN architecture

where v is the vector,nClasses=3(fresh,medium,rotten).We use the loss function Categorical Cross Entropy(CE)for multi class classification given in Eq.(2).

wheref(v)iis the softmax output of ithposition in vector,tiis target value,nClasses=3(Pure-fresh,Medium-fresh,Rotten).
4.2 YOLO-v5 for Detection and Classification
YOLO is an object detection algorithm based on regression [10].YOLO can simultaneously predict location and classes of many objects present in an image.We use YOLO-v5 as it is fast and accurate as compared to other object detection models.YOLO-v5[38,41]is a family of four models(small, medium, large, and extra-large).They differ in number of layers and number of weights in the network.We use medium version of YOLO-v5 (Fig.4), which provides good performance with acceptable computational complexity.

Figure 4:YOLO-v5 architecture
For training,we provide the annotation file containing location of each object in the image along with its label and image.YOLO predicts the class and bounding box specifying object location.Each bounding box can be described using four descriptors:(i)Center of the box(bx,by),(ii)Width(bw),(iii) Height (bh), and (iv) class ID.Along with the bounding box, it also predicts the probability of presence of an object in the bounding box.YOLO-v5 uses Leaky ReLU activation function in hidden layers along with the sigmoid activation function in the final output layer.Another important parameter of the algorithm is its loss function, YOLO simultaneously learns about all the four parameters it predicts as discussed before.YOLO-v5 uses Binary Cross-Entropy with Logits loss function from PyTorch for calculating object score and class probability while the loss function for predicting bounding box is given in Eq.(3).
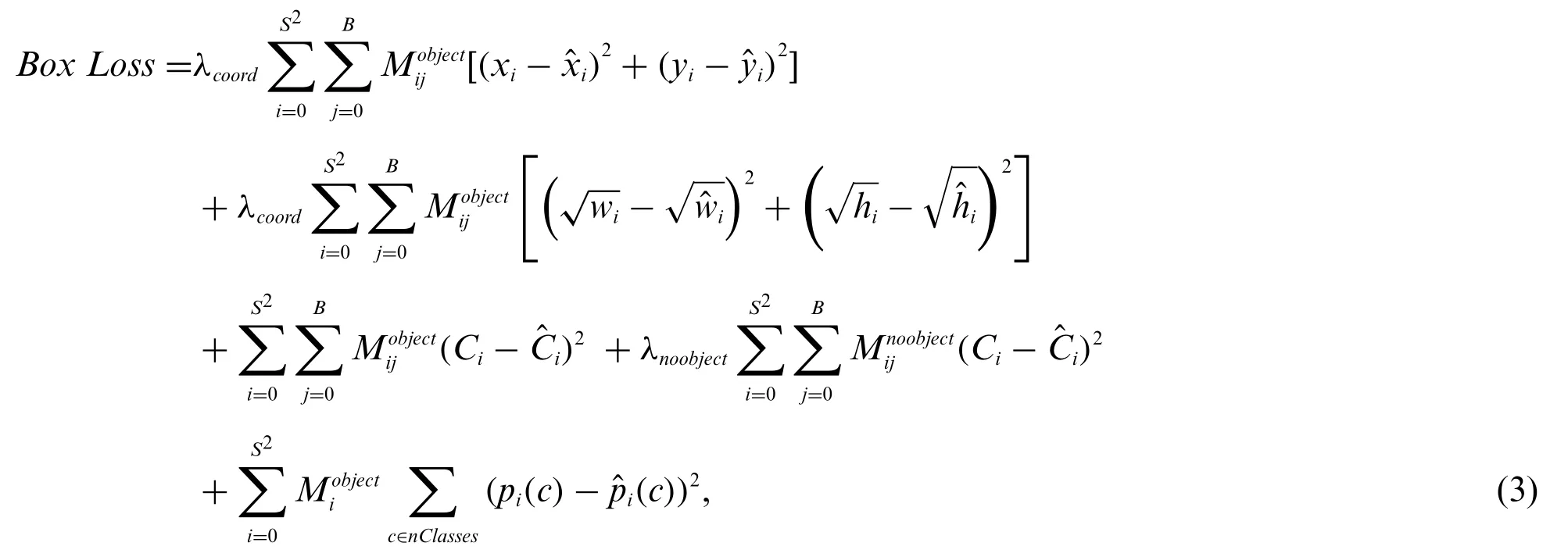
where S is number of cells in the image,B is the number of Bounding boxes predicted in each grid cell,and c represents the class prediction for each grid cell.pi(c)represents the confidence probability.For any boxjof celli,xijand yijrepresent the coordinates of the center of the anchor box,hijgives height,wijgives width of the box and Cijgives the confidence score.Finally,λcoordandλnoobjectare the weights to decide the importance of localizationvs.recognition in the training.
Eq.(3)has five terms summed up to measure the loss.The 1stterm penalizes the poor localization of centre of the cells.The 2ndterm penalizes those bounding boxes having inaccurate width and height.The presence of square root indicates that errors in smaller bounding boxes are more penalized than the errors in larger bounding boxes.The 3rdterm attempts to equalize confidence score to Intersectionover-Union(IoU)between the prediction and object when there is only a single object.The 4thterm minimizes confidence score close to zero when there is no object in the cell.Finally,5thterm represents classification loss.We train the model to detect if a cell contains an object and penalize the model if it predicts an object that does not exist in the cell.We achieve this by using two binary masks(and).is 1 if there is an object in the cell and 0 for other cells,whileis 0 for non-object cells and 0 otherwise.
YOLO splits the image into cells,typically into a 19×19 grid.Each cell then predicts K number of bounding boxes.During the forward propagation,YOLO determines the probability of a certain class for each cell given as:

wherepcis the probability that there is an object of certain class ‘c’.The class with the maximum probability is assigned to that grid cell.Similar process is performed for all grid cells present in the image.After predicting the class probabilities,the next step is non-max suppression,it helps the algorithm to get rid of the unnecessary anchor boxes.YOLO finds the Intersection over Union(IoU)for all the bounding boxes with respect to the one with the highest-class probability given in Eq.(5)as:

An object is in a specific cell if the center co-ordinates of the anchor box lie in that cell.Therefore,the center co-ordinates are always calculated relative to the cell,whereas the height and the width are calculated relative to the whole image size.It then rejects any bounding box whose value of IoU is less than a threshold.The above process is repeated to find the bounding box with the next highest-class probabilities until we locate all the objects in the image in separate bounding boxes.
5 Evaluation and Discussion
We evaluate the proposed approach on the challenging Fruit Freshness dataset containing 11 different fruits and vegetables and three categories of freshness for each class.For evaluation of the proposed approach,we split each Fruit and vegetable in the dataset into train and test sets in the ratio 70:30, respectively.Further we develop the Android based application, which gives real time output from the system.
5.1 Production Environment(Android Application and Sockets Based Server in Python)
We have developed an android based mobile application that connects the mobile devices with our trained models loaded on a server for the real time predictions.Following are the functionalities of the application:
· Capture Image using camera/load image from gallery or URL
· Connect to server using socket
· Send image to server
· Receive prediction from server
· Display the prediction
Fig.5 shows the Architecture diagrams of the system.The input to the application is an image and the output is an image containing bounding boxes drawn around objects,label(classes and freshness category),and confidence score.

Figure 5:Functionality diagram of the android application
5.2 VGG-16
VGG-16 is trained for 50 epochs with a batch size of 32.The technique of early stopping is applied where if the loss is not reduced consecutively for 4 epochs,then training is stopped to avoid the overfitting of the model(Fig.6).In classification of 33 classes,VGG-16 achieves an average test accuracy of 82.2%.

Figure 6:VGG-16(a)Training loss;and(b)Accuracy graphs
5.3 YOLO-v5
We train YOLO-v5 to locate and classify fruit and vegetable, and to categorize their freshness.For training of YOLO-v5,we use Google Colab,since it provides virtual machines with state-of-theart GPUs such as Tesla T4 and Tesla K80 with 16 GB of cache and 16 GB of RAM, for a 12-h session per day.Moreover 20 GB of Secondary storage is required for storing and loading of data.The network is trained for 200 epochs with a batch size of 8 on our FruitVeg Freshness dataset.Fig.7 shows the performance of the model on training and validation data.First three columns represent the Bounding-box loss, Object loss, and classification loss in (top row) training and (bottom row)validation data.We can see that the precision and recall are also improved in the validation data with the number of epochs in the training.Since YOLO also provides the location of the object in the form of a bounding box, which can be validated using IoU.The last two graphs in the bottom row show validation results of the mean average precision(maP)with 0.5 threshold as well as with varying thresholds ranging from 0.5 to 0.95 for IoU.It can be seen that the validation results become stable till the 200 epochs.
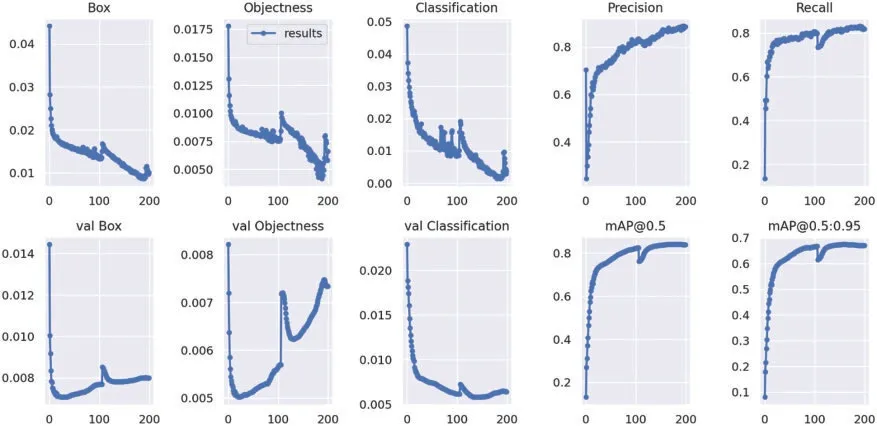
Figure 7:YOLO-v5:(top row)training,and(bottom row)validation graphs
Fig.8 shows the confusion matrix for classification of 33 classes using YOLO-v5 on test data.Predicted classes are on vertical axis,while ground truth is along horizontal axis.It can be observed that most of the classes are correctly classified by YOLO.However, the error is due to detection of background as an object or an object if detected as background.In addition, some fruits because of their inter-class similarity results in classification confusion.For example, Apple categories are confused with Guava.Also,in a few cases,it is observed that the freshness categories within the same class are also confused because of high intra-class similarities.
Tab.3 shows the detailed detection and classification results of each fruit and vegetable in FruitVeg Freshness dataset, where P is the Precision, R is the Recall.Also mAP at 0.5 IoU threshold and by varying threshold from 0.5 to 0.95.In addition, we measure the F1 score across all classes, which is considered a better measure compared to the accuracy.The variations in the appearance and structure of the three categories (pure-fresh, medium-fresh, and rotten) of each fruit and vegetable result in adding more complexity to the problem.Overall F1 score achieved by the system is 85%.However,individual classes range between 70%and 99%of F1score.Banana has the least F1 scores because of the less Recall.The reason of low recall is the high number of false negatives, i.e., Many of banana classes (pure-fresh, medium-fresh, and rotten) are classified as chilies or cucumber because of high inter-class similarities.It can be observed from the results that the deep learning model YOLO5 is able to learn these fine-grained differences those are even difficult to recognize visually in correct classification of fruits of vegetables into the defined categories.

Figure 8:Confusion matrix for YOLO-v5 graphs.The color intensity indicates the probability of each element in a cell

Table 3:Continued
6 Conclusion
We proposed a new dataset with three categories of freshness for 11 fruits and vegetables.We proposed the fruitsvegetables classification and freshness categorizing approach by exploiting two deep learning models i.e., VGG-16 CNN and YOLO-v5.Moreover,an android based application is also developed for the real time classificationcategorization of fruits and vegetables from the input image.We achieved mean Average Precision of 84%.These types of automated systems are quite useful in reducing the wastages of fruits and vegetables by early and in time consumption.VGG-16 is easy to setup,however,lacks in classification accuracy.While YOLO-v5 also localizes the object in addition to classification,however its performance is always a tradeoff between speed and accuracy.In the future,we would exploit newer and more efficient models,while increasing the size of dataset by incorporating more classes of fruits and vegetables.
Acknowledgment:The authors would like to thank the Deanship of Scientific Research at Majmaah University for supporting this work under Project Number No.R-2021-264.
Funding Statement:The authors received no specific funding for this study.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- Building a Trust Model for Secure Data Sharing(TM-SDS)in Edge Computing Using HMAC Techniques
- Adaptive Runtime Monitoring of Service Level Agreement Violations in Cloud Computing
- Automated Deep Learning Empowered Breast Cancer Diagnosis Using Biomedical Mammogram Images
- SSABA:Search Step Adjustment Based Algorithm
- SVM and KNN Based CNN Architectures for Plant Classification
- Adaptive Fuzzy Logic Controller for Harmonics Mitigation Using Particle Swarm Optimization