注意力与多尺度融合的图像阴影去除算法
2022-08-19曲海成刘万军
曲海成,佟 畅,刘万军
辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105
图像中阴影区域的存在,是一件普遍的现象。但对于计算机的视觉系统来说,对阴影区域的区分却是一件困难的事情,如图像分割时,阴影会导致分割区域判别不准确,造成图像分割的误差;目标跟踪时,阴影影响跟踪框的圈定,造成目标的丢失;智能监控系统中,阴影会干扰监控物的数量判断、形状、活动范围等。因此,对图像中阴影进行去除是十分必要的。
目前阴影去除算法可分为基于物理模型的方法、基于图像自身特征的方法、基于机器学习和深度学习等方法。基于物理模型的方法进行阴影去除,通过对阴影区域的环境特征进行模型构建来实现,主要依靠环境特征,但环境特征所受的影响因素太多且实时变化,不好确定,如太阳偏射角等。Yu[1]、Huang[2]和Finlayson[3]等人从物理模型出发,进行阴影去除,利用光源与障碍物的关系进行建模,具有一定的可行性,但建模过程的计算量大,所需的计算参数精确度欠缺。基于图像自身特征的方法,通过图像自身的特征进行阴影去除,如材质、亮度等。但同一幅图像中,不可能存在完全一样的材质、亮度等特征,因此此种方法存在固有的误差。如Guo等人[4]提出区域匹配算法,通过寻找与阴影区域相同材质的无阴影区域进行恢复,但对场景复杂图片的阴影去除效果不好。Lin 等人[5]通过多尺度和形态学方法进行阴影去除,有效缩减了漏检率,但对光谱与阴影相近且形状面积差异不大的地物,阴影去除出现困难。Fan 等人[6]利用图片的纹理特征,设置纹理置信区间,能够有效地去除复杂的投射阴影,但半影部分有少量残留。Jiao[7]和Zhang等人[8]构建阴影去除模型,具有便捷、高效的特点,但需对图片特定区域进行处理。Wu等人[9]提出生成器结构及多尺度图像分解法,使复杂背景图像的细节更加丰富、清晰,但只对特定数据有效,具有局限性。基于机器学习与深度学习的方法,主要利用大规模的数据进行模型网络参数的调整,实现阴影的去除,但也存在阴影误检和暗区域阴影去除不完全的问题。如Sepideh[10]和Zhang[11]等人使用机器学习的方法,提高了阴影检测与去除的时效性,但监测效果有待提高。Hu[12]与Fan[13]等人利用深度网络模型实现阴影去除,但面对复杂照明变化任务阴影去除效果还有待提高。Hu等人[14]提出方向感知与上下文分析的阴影检测网络,通过聚集的空间上下文特征建立方向感知注意力机制,恢复阴影图像,但仍存在可能将黑色的物体误检为阴影,或者漏掉一些不太明显的阴影区域的问题。
无论是基于物理模型的方法、基于图像自身特征的方法,还是基于机器学习和深度学习的方法,普遍存在两个问题:一是存在阴影去除算法普适性较差的问题,只针对特定类型的图像阴影去除效果好,非指定类型图像阴影去除效果差;二是面对复杂的纹理或与阴影区域相似的暗区域的情况,图像阴影去除效果不明显。为了解决上述问题,本文基于生成对抗网络的思想,利用注意力机制与多尺度特征融合的特点,提出了注意力与多尺度融合的图像阴影去除算法。该算法提升了不同类型图片阴影去除的准确率,解决了复杂的纹理或与阴影区域相似的暗区域阴影去除困难的问题。
本文主要工作总结如下:
(1)在生成网络的注意力形成阶段,运用空洞卷积层构造的残差网络进行特征提取,增加网络的感受野,提取的特征信息精确性更高,使编码阶段的输入特征信息具有更本质的全局特征,增强暗区域或纹理复杂区域的图像阴影去除效果。
(2)在编码过程中,引入多尺度的概念,把不同尺度的特征进行融合,兼顾全局语义信息与局部特征,进一步增加了对(1)中注意力机制的关注度,提高编码器的质量,使生成的图像更具有骗过判别器的潜质,使网络面对不同的场景,阴影去除依然可以具有较高的精确性。
(3)在判别网络中,引入多重注意力机制,通过多个串联的注意力机制进行引导,增加判别网络对感兴趣区域的关注度,减少关键特征信息的损失,提高判别网络的鉴别能力,调整了判别网络的步伐,使整个网络对不同类别以及暗区域或纹理复杂区域的阴影去除,起到了积极的促进作用。
1 算法基础
1.1 生成对抗网络
生成对抗网络(generative adversarial network,GAN)是深度学习领域一项伟大的创新,该网络基于博弈的思想进行设计[15]。该网络由生成器网络与判别器网络两部分共同构成,其核心思想是通过两个子网各自的最优变化,达到全局的最优效果。生成器网络的核心作用是通过一系列的网络结构生成可以骗过判别器网络的数据。判别器网络的核心作用是通过网络设计可以不被生成器网络生成的数据所骗过。生成器网络与判别器网络二者互相制约,共同成长,形成表现良好的网络结构[16]。生成器网络与判别器网络共同训练的过程如图1所示。

图1 生成器与判别器对抗图Fig.1 Antagonism graph between generator and discriminator
生成对抗网络训练过程中,只受限于判别器网络的鉴别能力,因此生成器网络具有最大限度的“想象”空间,这也是本文选用GAN 作为图像阴影去除的主框架的原因。
1.2 注意力机制
注意力机制核心思想是让计算机可以拥有自己的感兴趣区域,根据不同的应用场景的需求,对目标数据进行加权变换。注意力机制让计算机系统可以更多地关注自己感兴趣区域,防止关键特征的丢失。
注意力在不同的应用场景下或不同的表达方式下可分为多种不同类型。本文注意力机制属于软注意力机制,即形成的二维注意力图的对应权值在0~1 之间,越重要的特征分配的权值越大。注意力机制贯穿了本文的整个算法,在判别网络中,为防止重点特征的分散,采取乘法注意力机制,引导网络进行判断;在编码阶段,因需要长期存储提取图像的关键特征,选取LSTM(long short-term memory)作为编码阶段注意力的核心单元。LSTM是一种特殊的RNN类型,可以学习长期依赖信息,其由遗忘门、输入门和输出门组成,可表示为:

其中,ci表示整体的某一部分,et表示对应ci在t时刻的注意力得分。
注意力机制在本文中的具体应用如图2所示。图2为带干扰的阴影图像(下水井盖与阴影区域在光谱特性上有相似之处,去除阴影过程中具有干扰性)及对应的三幅热力图。其中图2(a)为包含井盖与阴影区域的图像,阴影区域在整幅图像的左边,是由人举挡板造成的。图2(b)为第一次的注意力热力图,图2(c)为第三次的注意力热力图,图2(d)为第六次的注意力热力图。

图2 生成注意力图示例Fig.2 Example of generating attention map
注意力热力图中,红色区域表示图2(a)中的阴影区域,蓝色部分为图2(a)中非阴影区域,浅蓝色为图2(a)中地面颜色稍微深一些的部分。在图2(b)到图2(d)的过程中,浅蓝色部分的区域逐渐与图2(a)中较深色地砖部分的位置对应。热力图对图2(a)的理解在逐步增加,即对图像色调变化捕捉敏感,对细节关注更为精细。在图2(d)中红色区域与图2(a)中的阴影区域位置对应,可知该注意力机制对阴影区域位置的关注比较精准,注意力的引用有利于提高图片编码的质量。
1.3 多尺度特征融合
多尺度即对信号的不同粒度进行采样,通常在不同的尺度下可以观察到不同的特征,从而完成不同的任务。通过少量卷积层,得到的特征分辨率高,包含更多位置、细节信息,但其所包含的语义信息少,噪声多[17]。而通过大量的卷积层,得到的特征分辨率却偏低,对细节的感知能力差。多尺度特征融合的提出就是为了能够提取更为全面的信息,兼顾全局语义信息与局部细节信息[18]。为了兼顾图片阴影区域的位置信息与细节特征,在编码阶段运用多尺度特征融合进行特征的抽取。
不同的尺度具有不同的感受野。图3为3个不同尺度下的图像对比图,直观地反映不同尺度的作用,其中图4(a)为640×680,(b)为64×48,(c)为8×6。

图3 不同尺度对比图Fig.3 Comparison of different scales
特征融合的两个经典方法是concat 和add。concat是直接将两个特征进行连接[19]。两个输入特征x和y的维数若为p和q,输出特征z的维数为p+q。add将这两个特征向量组合成复向量,具体形式见公式(3),其中i 是虚数单位,本文算法融合时使用add 的方式进行不同层次的特征融合,在不改变通道数的情况下,增加特征信息量。

本文多尺度特征融合采用串行的跳层连接结构实现。串行的跳层连接结构对图像的边界信息敏感[20]。在编码器编码的过程中,引入对反卷积层的邻接卷积进行串行的跳层连接,有助于加强编码器编码过程中对阴影边界的关注,提高了无阴影图像生成的质量。
1.4 损失函数
该算法是基于生成对抗网络(GAN)的框架下进行的,而在生成对抗网络中,需要优化目标函数,来达到纳什平衡[21]。GAN 网络的目标函数V(D,G)优化过程表示为:
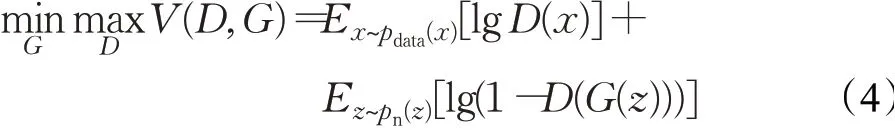
式中,G代表生成网络,D代表判别网络,pdata(x)代表真实分布,pn(z)代表噪声分布。G(z)表示输入的噪声z映射成数据(生成图片)。D(x)表示x来自于真实数据分布pdata(x)的概率。
在本文中,因注意力机制应用形式的不同,有许多不同的连接方式,但每部分注意力机制的损失计算方式是相同的。注意力机制的损失函数La表示为:

损失的计算是通过比较每次生成的注意力图(At)与对应图片阴影掩膜(M)(不提供阴影掩膜的数据集,用数据库中的阴影图像与非阴影图像做差得出)之间的均方误差(MSE)进行的。超参数的选择参考文献[20-21],N取6,θ取0.8。
在生成器网络,编码阶段的损失函数Le表示为:
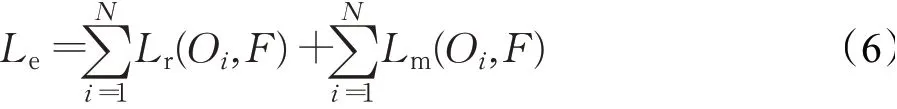
编码阶段损失(Le)由图片的真实损失(Lr)和模型损失(Lm)两部分构成,其中Oi为编码生成的图片,F为真实图片。
图片的真实损失(Lr)通过计算编码阶段生成的无阴影图片(Oi)与数据库中真实的无阴影图片(F)之间的均方误差(MSE)而得到,参数β的取值参考文献[22],分别取0.6,0.8,1.0,对应编码阶段的三个不同的尺度,i对应着编码生成的无阴影图像的次数,每生成一次就需要计算一次。图片的真实损失(Lr)表示为:

模型损失(Lm)为通过VGG 网络编码生成的图片(Oi)与真实图片(F)的损失的均方误差,表示为:

2 注意力与多尺度融合的图像阴影去除算法
2.1 算法框架
为了解决图像阴影去除算法中存在普适性差、复杂地物及暗区域阴影去除困难等问题,提出了注意力机制与多尺度特征融合相结合的图像阴影去除算法。该算法运用细节信息提取更精细的VGG-E作为该网络的预训练模型。整体思想基于GAN 网络架构,分成生成器网络与判别器网络部分。其中生成器网络包括注意力编码和注意力判别网络,是为了生成无阴影的图像。判别器网络是为了判断生成器网络生成的无阴影图像的质量。
生成器网络部分,对提取的特征进行多尺度的注意力编码,提高生成器网络生成无阴影图像的质量,加速网络的收敛。在判别器网络,运用注意力机制,平衡生成器网络与判别器网络的步调,加速网络的收敛,实现良好的图像阴影去除的效果。该算法整体框架如图4所示。
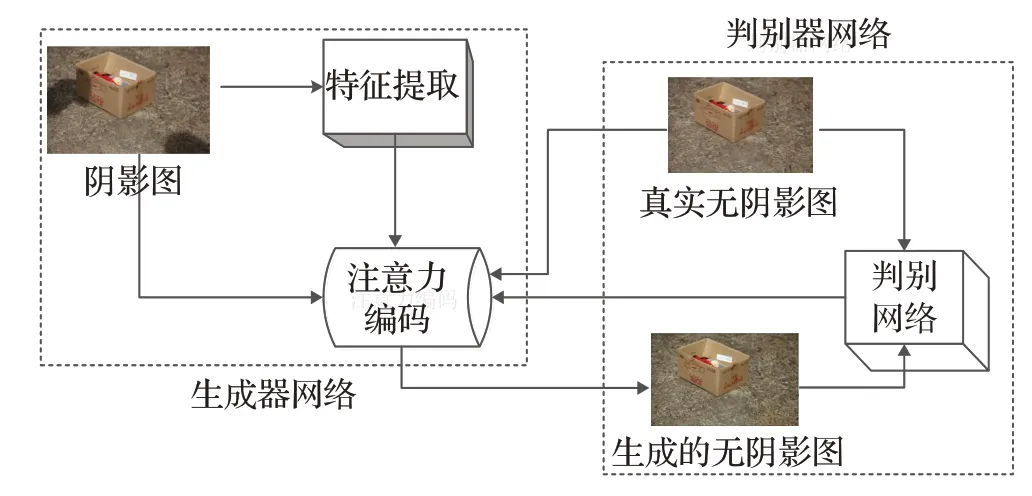
图4 注意力与多尺度融合算法整体框架图Fig.4 Overall framework of attention and multi-scale fusion algorithm
2.2 CDD残差块
CDD残差块模块的提出是为了解决暗区域及纹理复杂地物阴影区域细节信息与轮廓边界不能很好地兼顾的问题。
该模块的设计运用了普通卷积与空洞卷积组合的方式,结合了残差网络的设计思想。空洞卷积的应用具有更大的感受野,包含更多的上下文信息(细节信息),但空洞卷积的使用也会造成特征信息连续性的欠缺,因此,设计不同的学习率以避免这一问题。图5 中,第一层为普通卷积,相当于学习率为1的空洞卷积。第二层的空洞卷积的学习率设为2,第三层的空洞卷积的学习率设为3。
为了避免高层语义信息提取时梯度消失的问题,借助了残差网络的思想,对上述网络进行设计。CDD 残差块的设计如图5所示。

图5 CCD残差块设计Fig.5 Design of CCD residual block
2.3 多尺度编码器
编码器的输入由阴影图片与阴影图片的注意力图共同构成。这是一个逐层递进的过程,每次形成的注意力图重新与阴影图片进行下一次的特征提取,形成下一次的注意力图,其具体结构如图6所示。
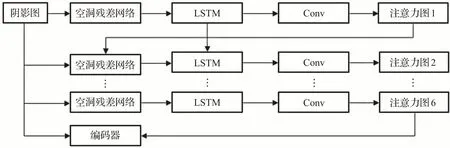
图6 生成器注意力网络Fig.6 Generator attention network
为了使网络面对不同场景的图像,阴影去除依然可以具有较高的精确性,在编码器中运用多尺度融合的思想,高层语言特征与底层细节信息的结合,使网络面对不同类型的图像,都具有较好的表现。该算法分别结合3种不同的尺度进行特征融合,兼顾全局与局部的特征,提高注意力编码器生成图像的精确度。选取融合的层次为Conv_8、Conv_9、Conv_10,它们为反卷积进行还原图像的临接卷积层,分别代表特征图尺寸为1、1/2、1/4时的特征。该实验编码阶段共由10个卷积层、4个空洞卷积层、2 个反卷积层以及3 个跳跃连接层组成。其中编码阶段的输入为带阴影的图像与注意力图,每层之间的激活函数为LRelu,输出结果为不带阴影的图片。Conv代表卷积层,Dia_conv代表空洞卷积层,Deconv代表反卷积层,且每个反卷积层包含一个avg_pool层。编码器内部卷积层的连接如图7所示。
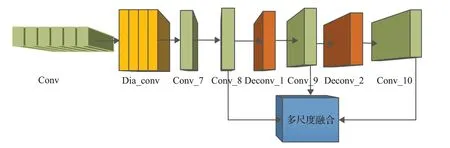
图7 编码器特征融合示意图Fig.7 Encoder feature fusion diagram
2.4 注意力判别网络
注意力模型(attention)关注图像的结构特征,可以灵活地感知到全局与局部的联系,提升网络的感知能力,提高输出的质量,且不需要监督[23]。注意力在判别网络中的应用,加强了判别网络对生成器网络的约束性,调整了判别网络的步伐,使整个网络对不同类别以及暗区域或纹理复杂区域的阴影去除,起到了积极的促进作用。
判别网络设计过程中,在每两层之间,加入乘法注意力机制,目的是通过注意力机制过滤掉一些无关特征,防止重点内容被分散,为后部分语义特征的提取提供基础。乘法注意力机制是在加法注意力机制要求编码与解码的隐藏层长度必须相同条件下的改进,具有更高的灵活性。判别网络设计如图8所示。
图8中3层的注意力图分别为第2、4、6层卷积特征的一个加强,为防止多次卷积后特征分散,不利于后三层语义信息的提取。后三层stride取4,每层特征变为原有的1/4,便于提取最本质、最抽象的特征信息。

图8 判别器设计图Fig.8 Discriminator design
3 实验及结果分析
3.1 实验环境及数据集
实验环境为ubuntu16.10 系统,GPU 加速卡型号为GeForce GTX 1080Ti。
数据集选取ISTD[24]和SRD[25]。ISTD数据集共1 870对阴影与非阴影数据对,其中训练集1 330 对,测试集540 对。SRD 数据集共3 088 对阴影与非阴影数据对,其中训练集2 680对,测试集408对。
3.2 评价指标
实验的评价主要从视觉效果和当前主流的衡量指标(SSIM、PSNR 和RMSE)两方面进行评价。SSIM 结构相似性基于图像亮度、对比度和结构进行评价,可表示为:
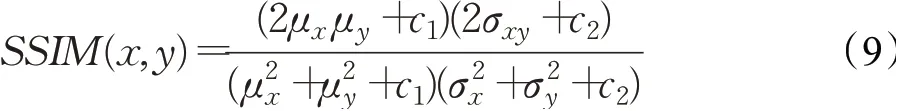
式(9)的值越接近1,两图片相似性越强。其中x、y代表要比较的两张图片,μx为x的均值,μy为y的均值,为x的方差为y的方差,σxy为x和y的协方差,c1=(k1l)2,c2=(k2l)2为两个常数,l为像素范围,本次实验k1为0.01,k2为0.03。
PSNR 为峰值信噪比,单位是dB,数值越大表示效果越好。基于对应像素点间的误差,即基于误差敏感的图像质量评价。不考虑人眼的视觉特性,会出现评价结果与人的主观感觉不一致的情况,可表示为:
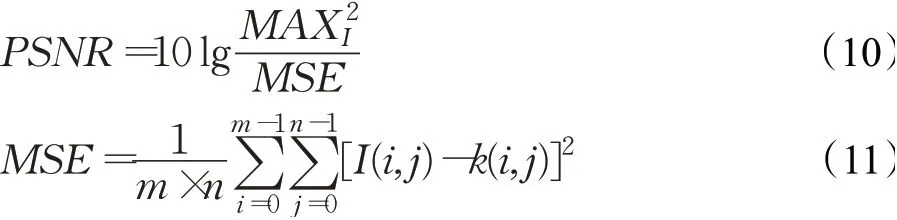
其中,m、n为图像的长与宽,I为真实图像,k为生成图像。
均方根误差(RMSE)是一个中间的评价指标,很多评价指标都是基于均方根误差进行的,是均方误差(MSE)的开根号数,均方根误差计算阴影图与非阴影图像素级的误差,可表示为:

3.3 实验结果与分析
生成器网络与判别网络具有不同的结构,因此生成器网络与判别器网络进行了不同的学习率设置。其中生成器网络学习率为0.002[26],判别器网络学习率为0.001[26],且每进行10 000次训练,学习率缩小10%。
实验在ISTD 数据集与SRD 数据集上选取不同场景且地物相对复杂或具有与阴影区域相近的暗区域的图像进行测试,经过100 000次训练的网络,实验最佳结果SSIM可达到0.978,PSNR为32.23 dB,RMSE为6.23。现随机选取6幅测试图片的值进行展示,不同数据集效果对比见表1。

表1 不同数据集效果对比表Table 1 Effect comparison of different datasets
该算法分别在ISTD 和SRD 选取不同场景且地物相对复杂或具有与阴影区域相近的暗区域的3 幅图片进行展示,可见该算法对不同场景下图像的阴影去除具有很好的表现,对相对复杂地物、暗区域的阴影去除效果也表现良好。不同数据集实验效果如图9所示。图9共6 组图片,前3 组为ISTD 数据集的测试图片,后3 组为SRD 数据集的测试图片,其中图9(a)为带阴影的图片,图9(b)为实验结果图片,图9(c)为数据集中给出的真实无阴影图片。

图9 不同数据集实验效果图Fig.9 Experimental renderings of different datasets
为了验证多尺度融合、注意力机制、CDD残差块对该算法的影响,设计了逐步改进实验。实验1为去除多尺度算法的实验,实验2为去除CDD 残差块的实验,实验3 为去除注意力机制的实验,实验4 为所有模块综合的实验。逐步改进实验的实验效果见表2。图像为随机选取的一幅图像,逐步改进实验视觉效果如图10所示。
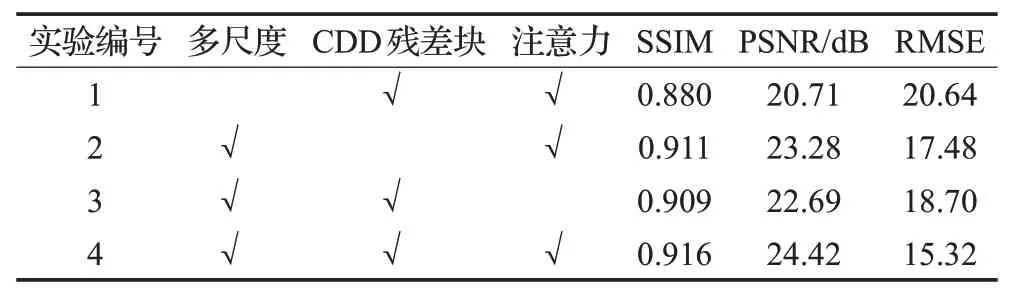
表2 逐步改进实验效果比较Table 2 Effect comparison of gradually improving experiment

图10 逐步改进实验视觉效果图Fig.10 Visual effect of gradually improving experiment
图10(a)为带阴影的原图片,图10(b)为实验1的测试效果图,图10(c)为实验2 的测试效果图,图10(d)为实验3 的测试效果图,图10(e)为实验4 的测试效果图,图10(f)为SRD数据集中给出的无阴影的真实图像。
综合表2与图10的实验结果,多尺度特征融合可以明显提高图像阴影去除的质量,无论从视觉角度还是测量指标上,都有显著提升,CDD残差块与注意力机制也在一定程度上,改善了该算法的阴影去除能力。因此,进一步把三者结合,进行实验验证,发现在视觉效果与图像测试指标上,都比其他组单独实验效果要好,证明了三者结合为该算法阴影去除能力最强的组合。
为了证明算法的有效性,用该算法与参考文献[9,14,24]进行对比,视觉效果如图11所示。其中图11(a)为原始带阴影图像,图11(b)为数据集中对应无阴影图片,图11(c)为文献[9]的结果,图11(d)为文献[14]的结果,图11(e)为文献[24]的结果,图11(f)为本文算法。图像测试指标对比见表3所示。

图11 算法视觉效果对比图Fig.11 Visual effect comparison of algorithms
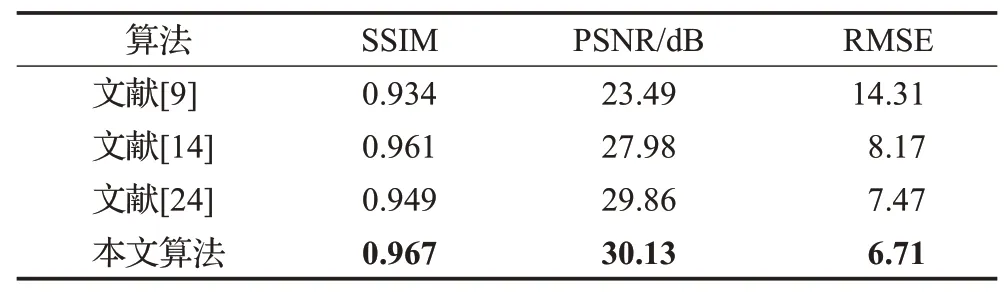
表3 算法测量指标对比Table 3 Comparison of algorithm measurement indexes
4 结论
本文针对图像阴影去除算法中复杂地物或与阴影区域纹理相似的暗区域阴影去除不完全的问题,提出注意力与多尺度融合的图像阴影去除算法。该算法的无阴影图像是由生成器在注意力与多尺度融合的引导下,由判别器监督而生成的最接近真实的无阴影图像。利用新型的空洞残差块(CDD)进行特征提取,在增大感受野的同时减少了计算量,加强了特征感知的强度。多尺度的特征融合,兼顾了全局语义与局部特征,增强了编码器生成图像的质量。注意力机制的引入,调整了判别网络的步伐,加强了网络对全局与部分的把控。该算法无论从定量指标还是视觉感受,都达到了较为理想的阴影去除效果。
该算法也可以迁移到其他同类型的监督学习的应用中,比如去雨、去马赛克等。当然该算法也存在一些不足之处,生成的图像与原图可能会存在一些细微误差,特别是灰色背景的图片,且对具有红色信息的图像,阴影去除效果较差。
