结合BERT 词嵌入和双向循环卷积神经网络的新闻文本分类研究
2022-08-19李文杰舒宇杰赵旖旎通讯作者
任 鹏,李文杰,舒宇杰,孙 航,赵旖旎(通讯作者)
(1 西南交通大学希望学院 四川 成都 610500)
(2 四川大学外语语言训练中心 四川 成都 610065)
0 引言
在信息高速发展的今天,随着各种社交媒体的大量涌现,大量繁复的信息资料产生。在这些信息和社交媒体中充斥着不同种类的新闻,由于网络用户的数量过于庞大,导致新闻传播速度过快,一旦有突发社会事件产生,舆情扩散速度会非常迅速,如果事件是负面的,就会造成巨大的社会舆情,带来负面影响。这些舆情主要以新闻文本为载体,在网络中大肆传播。因此,对新闻文本的分类工作显得尤为重要,是相关部门监督信息传播的基础。高效且精准的新闻文本分类识别可以让监督部门及时关注某事件的发展趋势,一旦某新闻的报道频率出现异常,会提醒监督部门及时处理热点事件,避免事件发酵造成社会负面影响。
目前,文本分类是自然语言处理的热门方向[1],实用性较强。常用的文本分类方法大致可以分为3 类[2]:基于规则的分类系统、基于机器学习的分类系统和基于深度学习的分类系统。基于规则的分类系统表达上等同于决策树,精度高,但是测试集小,泛化能力不够。基于机器学习的分类系统相比基于规则的分类系统,泛化能力更强,但是机器学习需要人工特征,并且训练结果会因为训练集的原因而导致偏差。伴随着人工智能时代的到来,深度学习已经在OPENCV、ASR、NLP 有着广泛应用。深度学习不需要进行人工特征训练,可以使用更大的训练集,但是对模型的解释性较差。考虑到是对新闻文本进行精确分类,对模型的解释性没有太大要求。汉语是世界是使用最广泛的语言,但是有关汉语的文本分类却很少,一方面汉语比英文复杂,另一方面有关中文的语料库太少,这些都是制约中文文本分类发展的主要原因。因此本文爬取网络开源的新闻标题文本,并将BERT、TEXTRCNN、BILSTM-CRF 组合来实现新闻标题文本的多元化分类,该模型可以在各个领域起到重要作用。首先,由于传统新闻文本分类算法使用RNN 进行分类,对于大量且多元化的新闻文本来说,准确率并不高,融合BERT、TEXTRCNN、BILSTM-CRF 模型能够提高分类的准确率;其次,该模型对情报部门进行新闻文本的收集与判断提高效率;最后,针对大规模的中文文本分类任务提供一种更优的模型,推进中文文本分类方法研究的发展。
1 结合BERT词嵌入和双向循环卷积神经网络的新闻文本分类模型研究应用
1.1 用于文本分类的BERT
词嵌入是一种特殊的分布式词表示,它是利用神经网络构建的。BERT 词嵌入算法是2018 年由Google 发布,BERT[3]是基于transformer 架构,但与同样是使用transformer 架构的GPT 而言,BERT 使用了多层双向变换器,这能使其执行对所有层联合调节左右语境来处理未标记的文本。与传统嵌入方法相比,BERT 算法计算复杂度大大降低,精度得到提高。BERT 模型示意图见图1。本文利用BERT 模型作为句子编码器,将新闻文本标题使用one-hot 表达后输入到经过任务微调处理的BERT 模型进行编码,其中输入BERT 中的编码向量是WordPiece 嵌入、位置嵌入和分割嵌入这3 种特征的单位和[4]。由于新闻文本标题词与词之间蕴含意思丰富,故运用大量语料训练的BERT 模型更能表示出词嵌入的信息。
1.2 TEXTRCNN 模型
词嵌入技术与深度学习网络的快速发展,也为各种NLP 任务带来了新的发展空间。在词嵌入的帮助下,一些方法被提出来读取文本特征,其中RecursiveNN 与RecurrentNN[5]备受关注。但是由于前者在读取长句子或文件的不足以及后者在读取时,后面的词比前面的词更占优势,导致降低模型效果。为了解决以上模型的局限性,本文采用TEXTRCNN 模型以解决新闻文本分类问题。该模型采用双向递归结构,与传统的神经网络相比,会引进更少的噪音,并且在读取特征时,可以最大程度地捕获上下文的信息。其中TEXTRCNN 模型使用双向RNN 层来替代原来的卷积层,这样会使整个模型效率提高,从而有利于对新闻文本标题的分类。该模型的神经网络结构见图2。
1.3 BILSTM-CRF 模型
1.3.1 LSTM 模型
长短时记忆网络(LSTM)[6]是专门设计用来避免长期依赖问题的特殊的RNN。LSTM 的关键在于单元状态,LSTM是通过门的结构来对单元状态信息进行增删操作。一个LSTM 具有遗忘门、输入门和输出门,用以控制和保护单元状态。模型的结构见图3。
其中3 个门通过Sigmoid 激活函数连接,值域被控制在[0,1]的区间内。候选存储单元由tanh 激活函数连接,区间控制在[-1,1]内。该模型的计算步骤如下。
其中,分别代表遗忘门、输入门、当前输入单元状态、当前时刻单元状态、输出门和最终的输出结果。
BILSTM[7]是一个优化的LSTM 模型,它结合了正向LSTM 和反向LSTM 来获取信息。因此,BILSTM 可以向前和向后处理和整合数据。BILSTM 模型结构见图4。前进层和后退层连接到输出层,输出层包含6 个共享权重。
在前向层中,从时间l 到时间t 进行前向计算,获得并且保存每个前向隐藏层的输出。在后向层中,通过从时间t 到时间L 的反向计算,同样获得且保存每个时间段的后向隐藏层的输出。最后,将前向层和后向层在每个时间段的输出结果相结合,得到最终输出。
1.3.3 BILSTM-CRF 模型
BILSTM-CRF[8]模型是在BILSTM 顶层上使用CRF 层进行序列标注。模型结构见图5。
首先给定一个句子,通过嵌入层,句子被表示为一个向量序列。然后,向量序列被输入到BILSTM 层中。在BILSTM 层中,对于每一个词t,序列从左到右,前向LSTM 计算出向量为,而后向LSTM 计算相同序列的反向表示,那么这个词的表示方法为。然后在BILSTM 上的Tanh 层用来预测每个单词对应各个标签的分数,作为BILSTM 的输出结果。
将BILSTM 输出结果输入到CRF[9]层,CRF 层将会添加到所有可能的标签序列中,并输出一个序列中分数最高的作为最终的输出结果。此外,CRF 层可以在训练中增强序列的合法约束,降低非法序列的概率。
为了更好提高新闻文本分类的准确率,本文采用BILSTM-CRF 模型能够使得大量且多元化的新闻文本标题的分类效果更好,提升分类的准确性。
目前,经性传播已成为我国艾滋病传播的主要方式,而家庭内配偶间经性传播已成为艾滋病进一步蔓延的重要因素之一,我国2011年估计的78万艾滋病患者中经异性传播占46.5%,其中约1/4为配偶间性传播[1]。因此,了解配偶间人类免疫缺陷病毒(human immunodeficiency virus,HIV)传播状况及其相关影响因素,采取相应措施降低配偶间HIV传播尤为重要,现将相关研究进展综述如下。
2 实验
2.1 实验数据集及评估指标
本文所使用的数据集是通过小组自行制作的爬虫脚本从各大开源新闻网站之中爬取获得,数量总共10 万条左右,获得的数据集在分类整理之后,分为8 个类别,分别为经济、军事、教育、科学、社会、时政、体育、娱乐。并且我们将这10 万条汇总数据分为3 个数据集,分别为训练集、测试集以及对最终模型进行效果检测的验证集,3 个数据集的比例是6 ∶2 ∶2,训练集拥有6 万条数据,测试集和验证集分别有两万条数据。数据集的划分见表1。
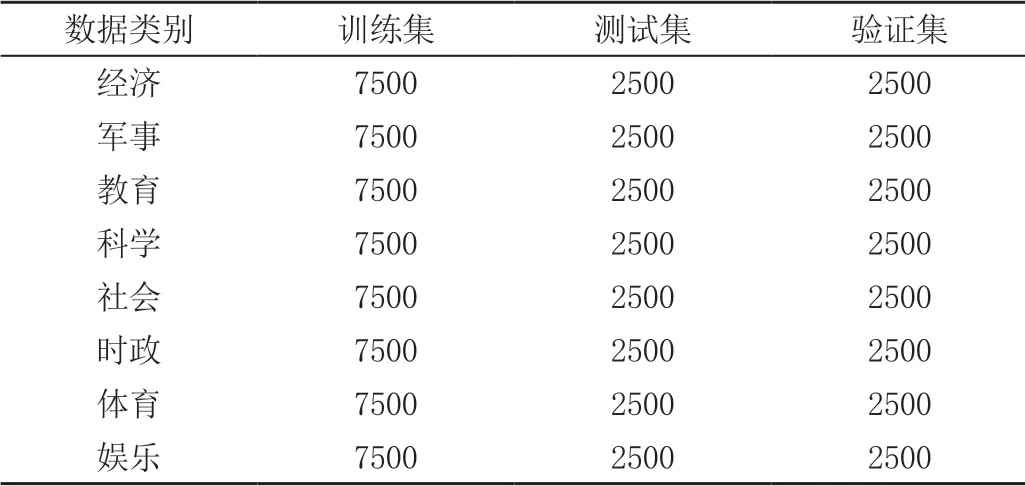
表1 数据集的划分
本文采用准确率、召回率和F1 得分3 项作为此次的评估指标。准确率会显示特征提取之后的效果,并且在后面F1 得分计算之中也会应用。准确率的公式如下:
召回率和准确率一样,在计算F1得分的时候需要使用。召回率的公式如下:
F1 得分能够对模型分类准确性提供一个数字化的结果,以便于人们对于模型分类的准确性有一个把握,以下是F1 得分的公式:
2.2 实验环境和模型参数设置
本文实验基于PyTorch 框架上,用到的软件是pycharm 专业版,使用的GPU 是云服务器RTX3090。本文对整个模型的参数设置见表2。

表2 参数设置
2.3 实验结果分析
为了检测Bert-BRNNText 的效果和运行情况,本文引入了几个经典的文本分类模型,即TextCNN、TextRNN、DPCNN 和FastText 4 个模型。同时,我们也引入了仅仅使用RNN 的Bert 词嵌入模型。随后将已经分类完成的数据集导入到5 个模型之中进行对比训练,以此测试本文模型效果。
首先将训练集分别导入到6 个模型之中,随后将测试集分3 次引入到已经完成训练的6 个模型之中。第1 次引入的结果见表3。
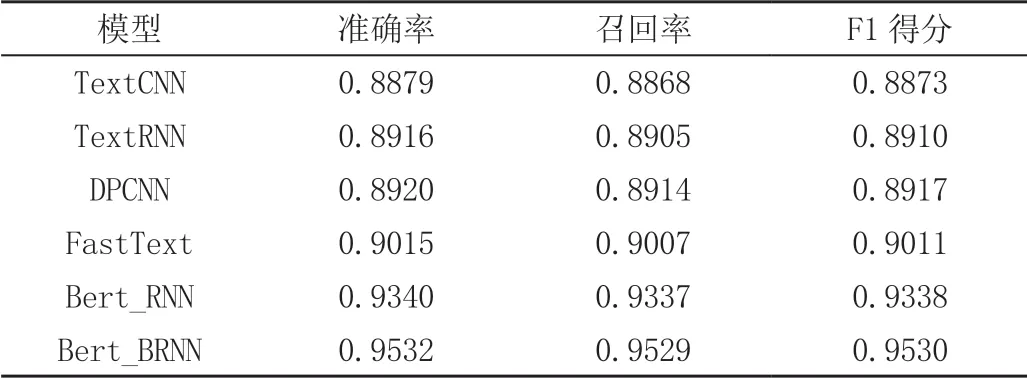
表3 第1 次测试结果
从第1 次的结果能够清晰地看出,相比于传统的分类模型,加入了Bert 词嵌入的RNN 模型,无论是在准确率上还是召回率上都更高,而在最终的F1 得分上更是达到了0.93,比TextCNN 模型高出了0.4 左右,而对比其他模型也有不小的差距。故Bert 词嵌入对于文本分类有重要影响,而本文所设计的模型运用的双向循环卷积则进一步提升了文本分类的效果。为了验证双向循环卷积模型的高效性,再次进行了两次测试。表4、表5 是后两次测试结果。

表4 第2 次测试结果

表5 第3 次测试结果
3 次测试结果之中,本文所使用模型的准确率和召回率以及F1 得分都达到了0.95 以上,相比于只使用RNN 的词嵌入模型来说,双向循环卷积模型能够有效提高文本分类的效率以及精准度。
为了检测BRNN 的分类效率,这里对比了Bert_RNN 以及Bert_CNN 的收敛速度。收敛速度见表6。

表6 收敛时间对比
由表6 可知,双向循环卷积模型的收敛时间和正常的Bert 词嵌入模型并没有太大的差距,但相比于正常的模型来说,双循环卷积模型大大提升了精准度,由此看出双向循环卷积模型的优势。
3 结语
本文使用了TextCNN、TextRNN、FastText 等方法对我们所获取的新闻文本进行分类训练,得到了不同的实验数据。其中,利用BERT 词嵌入和双向循环卷积神经网络的文本分类方法得到的模型为最优模型。模型使用BERT 词嵌入将词转化为变量来表示,TextRCNN 获取上下文本特征,BILSTM-CRF 在基础的BILSTM 模型上添加了CRF 层,使得在捕捉上下文关系时更加准确。实验结果表明,结合BERT 词嵌入和双向循环卷积神经网络模型具有较高的效率和准确率,其准确率可以达到0.9551,验证了模型的有效性。该模型有效解决了在处理大量且多元化的中文文本分类问题中准确率不佳的问题。在实际应用中,能够为有关部门实现准确识别新闻类别并维护网络新闻环境提供理论依据。
