基于孪生网络的行星齿轮箱故障诊断方法
2022-08-18钱心筠王友仁赵亚磊
钱心筠,王友仁,赵亚磊
(南京航空航天大学 自动化学院,江苏 南京 211106)
0 引言
行星齿轮箱作为一种传动效率高、承载能力强的机械装置,被广泛用于新能源发电、军事、航空航天等涉及国计民生的领域。由于行星齿轮箱长期工作在变转速重载的恶劣环境下,太阳轮、行星轮等关键部件极易发生故障,易引发传动系统的失效。由于行星齿轮箱本身受到一定维护加之部分故障发展较慢,因而无法收集到足够的故障样本用于故障诊断[1]。
随着机器学习尤其是深度学习理论的发展,在训练样本有限的情况下行星齿轮箱的故障诊断已成为当前的研究热点。针对这类问题,在小样本学习领域一般可从数据、算法等角度进行处理,目前,算法层面上主要是通过提取故障敏感特征,并对故障分类上选用支持向量机(support vector machine, SVM)这类有小样本分类能力算法进行改进来解决此类问题,这类方法所提取特征质量密切相关,需要大量专家知识[2]。因而,最为常用的方法仍然是在数据层面对训练数据集进行增强,效果比较好的是通过生成对抗网络(generative adversarial nets,GAN)实现样本扩充。文献[3]将堆栈自动编码器作为GAN的判别器,生成了与原始分布相似的样本,实现了在故障样本量较小情况下的故障诊断。文献[4]通过有限元仿真生成的轴承仿真样本来弥补故障样本缺失的不足,将仿真样本和真实样本送入GAN实现样本扩充。文献[5]利用条件变分自动编码器获取了原始故障样本分布,通过生成器为解码网络生成大量故障样本,实现了行星齿轮箱故障的有效诊断。然而这类基于GAN的样本增强方法往往只学习到了对象在分布上的特点,当面对某些类别的样本量极少时,所训练出的模型并不能达到令人满意的效果[6]。
BROMLEY J等提出的孪生网络(siamese networks)[7]目前已广泛应用于人像识别、指纹识别、目标追踪等模式识别领域。孪生网络通过两个结构相同的网络对特征进行提取,而后基于距离度量给出分类准则。该网络通过训练集样本组成样本对的方式,增加了对单个样本的利用次数,实现了在有限的训练样本中获取到多类别样本间的共同特征,为在样本量有限情况下的故障诊断提供了一种新的思路。
本文选用一种基于孪生卷积神经网络(Siamese convolution neural networks, Siamese-CNN)的行星齿轮箱故障诊断方法,以应对故障训练样本有限的问题。该方法利用CNN自动提取行星齿轮箱振动信号特征,将特征输入至孪生网络架构,基于样本间的距离度量来优化网络参数。测试阶段通过将测试样本和训练集中部分样本组成样本对输入至Siamese-CNN网络中进行故障诊断,最后以行星齿轮箱实验平台的数据为例验证了该方法的有效性。
1 孪生卷积神经网络理论
1.1 孪生网络概述
孪生网络的基本结构如图1所示,网络1和网络2是两个相同的神经网络,用于将输入样本对映射到同一个高维空间,通过特征向量距离的相似度量,输出一个在[0,1]之间的数作为该样本对样本间的相似度。通过这种基于距离度量学习的方式,可以极大地减少网络参数的训练负担。对于一个样本量M的训练集而言,可以组成M(M-1)/2个不同的训练样本对,这样增加了样本的利用率,又借此减少对训练样本量的依赖。在测试时,一条网络的输入是训练集的样本,用于提供先验知识;另一条支路则是测试集样本。通过训练好的网络获取样本间的相似度,确定测试样本状态。

图1 孪生网络基本结构
1.2 孪生网络训练与测试策略
图2(a)所示为孪生网络训练过程,输入网络的是一对对相同或者不同类别的样本数据,输出则是经相似度量后这个样本对样本间相似的概率,通过得到的相似概率与实际的差距来调整模型参数。
测试策略上借鉴元学习理论[8],从训练集中选取每类N个样本作为支持集,如图2(c)所示,采用N-shotK-way测试准则,确定测试样本的分类。

图2 孪生网络训练与测试策略

S={(x1,y1),…,(xk,yk)}
(1)

(2)
对于N-shotK-way测试过程,则是进行了N次one-shotK-way的测试过程,支持集Sn是N个形如式(1)的集合组成。将每一类别所得到的N个相似度求和,选取各个类别求和所得的最大值作为当前测试样本的最终类别,其表示式如(3)所示。
(3)
1.3 孪生卷积神经网络训练机制
1) 相似度量
孪生卷积神经网络是指图1中的网络1、网络2均为卷积神经网络,在这里选用包含5个卷积层、5个最大值池化交替组成的卷积网络结构。该网络使用L1距离度量CNN网络,其表达式如(4)所示。
(4)
式中f(·)是所使用的卷积神经网络。最后,如式(5)所示,通过全连接操作生成最终的相似度,
P(x1,x2)=sigm{FC[df(x1,x2)]}
(5)
式中FC为全连接层,这里采用Dropout进行全连接降维,增强了模型泛化性;sigm是sigmoid激活函数,用于生成两个向量之间的最终相似度。当值越接近则代表两者越相似。
2) 损失函数
采用交叉熵损失函数,对于一个训练样本对而言,令t表示两个样本是否属于同一类。当t=1表示输入样本对的两个样本属于同类,t=0代表两个样本不属于同一类,同时引入带自适应系数λ的L2权重衰减系数项λ|W|2来防止模型过拟合,得到如式(6)所示的误差控制函数。
L(x1,x2,t)=tlog(P(x1,x2))+
(1-t)log(1-P(x1,x2))+λ|W|2
(6)
3) 优化
孪生网络使用mini-batch与Adam相结合的优化训练机制,计算每个参数单独的自适应学习率,网络参数更新遵循以下规则:
(7)
式中:w(T)是在第T个epoch的参数;L(T)是如式(6)所示的损失函数;ρ1、ρ2分别是Adam优化算法的一阶矩、二阶矩遗忘因子;s和v代表移动平均线。
4) 训练

2 行星齿轮箱故障诊断算法
本文采用一种基于孪生卷积神经网络的行星齿轮箱故障诊断方法,该方法通过卷积神经网络提取行星齿轮箱多方向振动信号特征,利用孪生网络的度量学习能力,实现了在故障训练样本有限的情况下的故障特征分类。
基于Siamese-CNN的故障诊断算法流程如图3所示,具体实施步骤如下:

图3 行星齿轮箱故障诊断流程图
1)获取行星齿轮箱多方向的振动信号,划分训练集和测试集,并将训练集两两一组形成样本对,输入Siamese-CNN网络中。
2)训练Siamese-CNN。首先通过卷积神经网络提取样本对的故障特征,经历L1距离度量、全连接生成相似度,根据全连接生成的相似度、样本对实际情况构建的误差损失函数反向优化CNN模型参数。反复训练直至完成所设定的迭代次数。
3)将测试样本与支持集样本形成的样本对,输入训练好的Siamese-CNN中进行行星齿轮箱故障诊断,分析诊断结果。
3 实验结果与分析
3.1 行星齿轮箱故障诊断实例
1)实验平台及数据简介
采用的行星齿轮箱故障模拟实验平台如图4所示。实验平台主要由变速驱动电机、平行齿轮箱、行星齿轮箱与磁粉制动器组成。在本实验中分别在行星轮和太阳轮上设置了裂纹、磨损、断齿这3类故障,6种故障模式。实验采集了共121种工况下的数据:11种转速600~1 500r/min,11种负载0~22.5N·m。振动加速度采样率为20 480Hz,采样时间为51.2s。

图4 行星齿轮箱实验平台
2)样本数据集
实验选取工况为900r/min、0N·m;1 050r/min、9N·m,1 200r/min、13.5N·m这3种工况下的三通道时域数据,将3路信号作为整体,选取每种工况下6s数据,前3s用于训练,剩余用于测试。其中,在训练样本的构建上使用时域信号滑窗的方式划分样本,步长为80,滑窗长度为2 048,以减少因信号截断对诊断造成的影响。在测试样本的构建上,则以2 048为长度截取测试样本。最终获取到每种模式2 100个训练集样本、90个测试样本,具体信息如表1所示。
实验中,分别从表1所示的样本集中随机抽取每种模式9、12、20、30、40、70、150个样本组成训练集,用于模拟故障训练样本量不足的情况,测试集则总样本量为630。
3.2 故障诊断结果分析
本文所使用算法均在Python环境下使用Google研发的Tensorflow框架实现,神经网络通过keras搭建,程序在搭载有Intel Core i5-8500处理器16G内存的计算机上运行,操作系统为Windows 10。
本实验将SVM、分类器为Softmax的CNN与Siamese-CNN方法进行比较。其中,SVM方法在核函数上采取高斯核函数,分别输入与上文所述样本集(SVM1)以及该样本集经人工提取特征后所得样本(SVM2)。CNN方法的特征提取架构与Siamese-CNN相同,两种深度学习架构学习率设置为0.001,优化方法采用Adam算法。每种模型训练5次,取其平均值作为诊断准确率(图5)。

图5 不同诊断模型在不同训练样本量下比较
由图5可知,任何一种方法的故障诊断准确率都随样本量的增大而增大。然而,SVM这类传统方法在样本量较小的情况下表现不佳。当训练集样本总量为63时,使用两种类型数据训练的SVM方法仅能达到不足30%的故障诊断准确率,远小于深度学习方法。直接使用所截取的原始时域数据训练的SVM所得模型较经特征提取后所得模型而言,故障准确率随样本增加上升缓慢。
相比而言,基于CNN的诊断方法有着较高的诊断准确率。为了更好理解基于孪生网络的故障诊断方法在样本量有限的情况下的效果,绘制出在训练集总样本量为140情况下的CNN、Siamese-CNN中one-shot测试方法提取的特征TSNE可视化散点图以及网络分类结果(图6、图7)。从图6中可以看到,相比传统CNN方法,Siamese-CNN所提取的特征更加充分,尤其在行星轮断齿与太阳轮磨损间的故障特征上更加明显。从图7分类结果上看,使用Siamese-CNN方法在行星轮断齿、太阳轮磨损故障相比传统CNN方法更容易诊断,分类精度明显高于CNN方法。
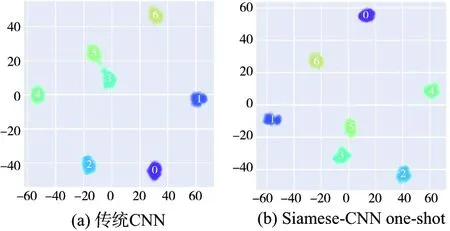
图6 故障特征可视化

图7 分类结果混淆矩阵
根据上述分析可知,孪生卷积神经网络能在一定程度上减轻对样本的依赖,在样本量有限的情况下取得较高的诊断准确率以及分类精度。
4 结语
本文采用了一种基于孪生卷积神经网络的故障诊断方法,通过实验得出以下结论:
1)基于孪生卷积神经网络的故障诊断方法通过CNN自动提取敏感故障特征,而后基于度量学习方法确定样本分类,在一定程度上减少了对样本的依赖。
2)基于孪生卷积神经网络的故障诊断方法,故障诊断准确率明显优于SVM这类传统解决方法。
3)相比传统CNN方法,基于孪生卷积神经网络区分度好,在每一种模式上的分类精度都更高。
