基于改进YOLOv3的机场停机坪目标检测方法
2022-08-18袁国武
王 阳, 袁国武, 瞿 睿, 周 浩, 郑 东
(云南大学 信息学院 云南 昆明 650504)
0 引言
云南拥有丰富的旅游资源,并且是从国内中转东南亚国家的航空中心,其航空业地位非常重要[1]。安全是民航业永恒的主题,因此云南机场集团围绕旅客安全、空防安全、安保等重点环节建立统一的安全监控平台。机场停机坪的全天候监控是机场安全中的一个重要环节。目前,传统的方式是通过人工进行监控,这种方法不仅造成了人力的浪费,还存在疏忽遗漏的风险。随着计算能力的提高和相关数据集的丰富,深度学习在图像分类、语义分割、目标检测等任务上取得了很大的成功,但是将其应用于机场停机坪监控的研究尚未见报道。
深度学习在2012年之后逐渐流行起来,文献[2]在R-CNN算法的基础提出了Faster R-CNN算法,成为两阶段目标检测算法中的经典。为了提升物体检测速度,YOLO和SSD等目标检测算法相继被提出,成为一阶段目标检测算法中的经典。文献[3]在YOLO算法的基础上提出了YOLOv3算法,将检测模型转变为一个一体化的网络,直接将图片数据输入其中,一次性输出检测物体的类别和概率。国内外很多学者对该检测算法进行了改进,例如将其应用于农业领域中害虫的检测[4],推进了农业智能化的发展。文献[5]也基于该算法对医学图像进行辅助检测,提高了医疗诊断的智能化水平,有效提升了YOLOv3算法在复杂条件下针对特定场景的检测精度和速度。由于在实际的检测任务中存在较多的复杂场景,因此需要根据不同的检测任务对算法进行改进。
将原始的YOLOv3算法直接应用于机场停机坪目标检测,主要存在以下问题:首先,由于机场监控摄像机离停机坪较远,停机坪内活动的人在监控场景中较小,识别率低,且存在大量漏检的情况;其次,原始算法采用的特征提取网络较复杂,对原始特征图没有进行充分利用,存在特征图冗余现象,导致模型参数量过大,前向推理速度慢,无法满足在嵌入式设备上运行的要求;最后,原始算法采用IOU评价指标,影响了训练效率和检测精度。针对以上问题,本文提出了改进YOLOv3的机场停机坪目标检测方法,在减少模型参数量的同时,提升了模型在复杂环境下的检测效果。
1 YOLOv3改进算法
1.1 特征提取网络优化
原始YOLOv3的特征提取网络是Darknet53,其特征提取模块使用的是传统卷积,存在较多冗余特征图,导致了参数量和计算量的增大。本文将Darknet53修改为华为公司提出的一种新型特征提取网络GhostNet[6],GhostNet可以使用更少的参数来提取更多的有效特征,从而优化分类和回归结果。实验结果表明,将原始YOLOv3的特征提取网络修改为GhostNet网络后,检测精度和速度均有所提高。和传统卷积相比,GhostNet特征提取分为以下两个步骤。
第1步:使用正常的卷积得到通道数较少的特征图,具体操作为
Y′=X×f′,
(1)
其中:Y′∈Rh′*w′*m为原始卷积输出;f′∈Rc*k*k*m为卷积核。采用原始卷积时,特征图输出为n维,这里通过正常卷积只产生m维的特征图,剩余特征图通过线性变换产生,可以减少大量因卷积而产生的参数。
第2步:利用简单的线性操作,通过线性组合产生更多的特征图,与原始卷积产生的特征图拼接到一起,具体操作为
yij=Φi,j(y′i),∀i=1,…,m,j=1,…,s,
(2)
其中:yij是通过线性变换得到的特征图;Φi,j为线性变换函数。
改进后的特征提取网络如图1所示,利用GhostNet搭建了轻量级的检测神经网络,减少了参数量,使得检测模型在嵌入式设备中也能进行实时检测。本文将GhostNet结构作为YOLO模型的特征提取网络,提出了一种Ghost-YOLO网络模型,Ghost模块示意图如图2所示。

图1 改进后的特征提取网络

图2 Ghost 模块示意图
1.2 IOU损失函数优化
IOU是目标检测中常用的性能指标,当其值为0时,会导致梯度消失,在训练中会出现发散问题,影响训练效果。针对上述问题,采用DIOU指标[7]替换IOU指标,
(3)
其中:b和bgt分别指预测框和真实框之间的中心点;ρ为两个中心点之间的欧氏距离;c为预测框和真实框的最小闭包区域的对角线距离。
DIOU可以最小化两个目标框之间的距离。在非极大值抑制计算中,需要考虑重叠区域及中心点的距离和长宽比,以解决预测框与真实框不重叠时梯度消失的问题。
1.3 增加注意力机制模块
注意力机制本质上是一种模拟人的行为的仿生机制[8],将注意力集中到重要目标上,在自然语言处理、语音信号识别等领域都取得了较好的效果。为了更好地关注特征提取网络提取的特征图不同通道之间的关系,进而学习到不同特征的重要程度,本文将通道注意力机制(SE)和特征提取网络进行融合,以提升小目标的检测效果。特征提取网络的注意力模块如图3所示。
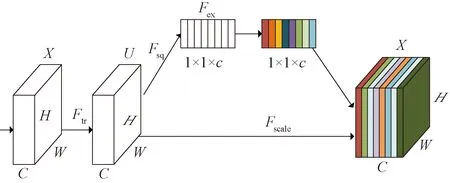
图3 特征提取网络的注意力模块
图3展示了加入YOLOv3中的注意力机制模块。其中,Ftr表示传统卷积操作,X为Ftr的输入,U为Ftr的输出,这些结构在原始的YOLOv3中是存在的,即普通的卷积操作,有
(4)
注意力模块是U后面的结构。首先,对U进行一次全局平均池化,对应图中的Fsq操作,将特征图进行压缩,选取每个特征图最重要的特征,公式为
(5)
然后,将输出得到的1×1×c的特征数据经过两级全连接,对应图中的Fex操作,最后用Sigmoid函数归一化到0~1范围,把这个值作为重要因子Sc,与特征图的各个通道相乘,得到的特征图Xc作为下一级数据输入,公式为
Xc=Fscale(Uc,Sc)=Sc*Uc。
(6)
1.4 基于反卷积放大和特征融合的目标检测方法
本文提出一种基于自底向上特征融合和反卷积特征放大的方法来提升小目标的检测效果,通过GhostNet提取到四个尺度的特征层(13,13,1 024),(26,26,512),(52,52,256),(104,104,128),分别将其标记为大尺度特征层(large feature layer, LFL)、中尺度特征层(medium feature layer, MFL)、小尺度特征层(small feature layer, SFL)、极小尺度特征层(tiny feature layer, TFL)。
将不同网络层的特征图进行了输出,如图4所示。浅层网络的特征图,图像分辨率高,边缘和纹理信息丰富,易于对小目标进行检测,但是缺少语义信息;深层网络的特征图,语义信息丰富,但是图像分辨率较低。因此,将浅层特征和深层特征进行融合,能够丰富特征信息,提高小目标的检测能力。

图4 不同网络层的特征图
1.4.1自底向上特征融合方法 轻量级的特征融合方法对提升图像特征具有重要作用[9],本文提出了一种自底向上特征融合的方式。注意力机制和自底向上特征融合示意图如图5所示,在融合之前通过1×1卷积对特征层进行降维,减少参数量。之后,对特征图采用双线性差值进行上采样操作。

图5 注意力机制和自底向上特征融合示意图
自底向上特征融合方法的具体步骤如下。
1)将各个层次的特征图进行3×3卷积操作,卷积操作特征图的输入与输出关系为
(7)
将式(7)中各个参数分别设置为F=3,P=1,S=1,保证输入与输出特征图尺寸保持不变。
2)在卷积之后各个通道的特征图中加入注意力模块,对无用的特征信息进行抑制,提升检测精度。
3)将LFL1层通过1×1卷积减少通道数,并通过上采样操作与MFL1层进行融合。为了满足嵌入式设备对实时性的要求,采用将特征图逐位相加的方法进行融合。
1.4.2反卷积特征放大 通过反卷积特征融合能够有效提升小目标的检测能力,文献[10]基于反卷积特征放大的思想进行图像识别的研究,其选择中间特征层进行反卷积操作,并未融合拥有丰富语义信息的底层特征,在小目标识别中有一定的局限性。将SFL1进行反卷积放大操作,与TFL特征层进行融合,其次将LFL2层进行上采样操作,与经过反卷积放大操作得到的特征图SFL3进行拼接,用于对小目标的预测。本文提出了一种通过自底向上融合的特征图与深层和浅层特征图进行融合拼接的方法,反卷积特征放大示意图如图6所示,图中虚线部分为反卷积特征融合放大模块。
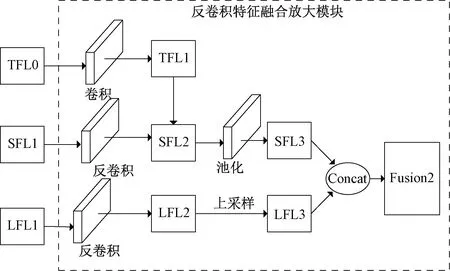
图6 反卷积特征放大示意图
反卷积特征放大的具体步骤如下。
1)选取通过自底向上融合得到的SFL1层作为进行反卷积放大的特征层。TFL0位于网络的表层,特征图尺寸较大,在与SFL2层特征进行融合前需要通过下采样减少特征图的尺寸。采用步长为2的空洞卷积进行下采样操作,减少特征图信息的损失,得到特征图TFL1,空洞卷积的输入与输出特征图大小的对应关系为
(8)
其中:d为膨胀系数;S为步长;K为原来卷积核的大小;I1为输入特征图大小;O1为输出特征图大小。
2)通过反卷积操作扩大SFL1特征图的分辨率,反卷积操作的输入与输出对应关系为
O=S(I-1)-2P+K,
(9)
其中:S为步长;P为扩充值;K为卷积核的大小;I为输入;O为输出。SFL1的特征图尺寸为52×52,设置卷积步长S=2,填充值P=1,卷积核尺寸K=4,采用特征映射的方式将TFL1层特征图与反卷积放大后的特征图进行融合,得到特征图SFL2。
3)将SFL2层进行下采样和1×1卷积操作,固定特征图的尺寸和通道数量。
4)将LFL1进行反卷积和上采样操作得到特征图LFL3,固定特征图的尺寸和通道数量。
5)将SFL3层与LFL3层进行特征融合,得到新的融合层Fusion2。
2 实验结果及分析
2.1 数据集与评价指标
采用云南机场集团提供的机场监控视频数据集,其中正样本数为7 000,负样本数为3 000,按照2∶8的比例划分测试集和训练集。当训练完成后,在测试集进行测试,得到模型的精度信息。评价指标包括召回率、精确率和FPS等。
召回率为被检测到目标个数与样本集中所有目标数的比值,即
(10)
精确率为目标检测过程中正确检测的目标个数占所检测目标数的比值,即
(11)
FPS定义为每秒能够被检测到图片的帧数,其值越高,表示算法的实时性越好。
2.2 训练参数设置
训练阶段将动量项设置为0.9,采用小批量随机梯度下降进行优化,一个batch设置为64张图片,训练完一个batch进行一次参数更新;网络学习率衡量的是网络学习训练样本的速率,在40 000次迭代后逐渐减小学习率,使其慢慢收敛到稳定。
2.3 实验结果分析
为了证明本文方法的有效性,选择较复杂条件下的监控视频进行实验。将YOLOv3算法和改进后的检测算法进行对比实验,结果如图7和图8所示,图中worker和noworker分别代表工作人员和非法闯入人员。图7(a)和图8(a)为原始算法的识别效果图,图7(b)和图8(b)为改进算法的识别效果图。
图7展示了在光线昏暗情况下的识别效果。可以看出,在光线昏暗条件下,原始算法对远处的小目标识别效果很差,仅对近处相对较大的2个目标做出了识别,而对远处的小目标无法进行检测,原始算法难以对进入停机坪的人员的合法性进行有效识别;改进算法可以在光线较暗的情况下对小目标进行准确识别,对大部分目标的识别准确度约为90%。

图7 在光线昏暗情况下的检测效果对比
图8展示了在人员密集情况下的识别效果。可以看出,在人员密集并且存在较多小目标的情况下,原始算法检测效果不佳,仅对1个目标做出了识别。通过改进后的算法进行目标识别,可以对所有的小目标进行准确识别。视频中穿着橘色外套人员与穿着橘色反光背心人员存在较多的相似性,而改进算法由于添加了注意力机制并且进行了特征融合,极大提升了小目标的检测能力,改进后的算法能将穿橘色外套人员也定义为非法人员,并且对其进行了实时跟踪。

图8 在人员密集情况下的检测效果对比
改进前后模型在数据集中的损失值变化曲线如图9所示。将epoch设置为150,通过图9可以发现,当epoch的值在100左右时,模型的损失值趋于稳定。图9中上方曲线代表算法改进前损失值变换情况,下方曲线为改进算法的损失值变化情况,可以发现,改进算法的初始损失值更小,收敛速度明显加快,一定程度上解决了模型发散的问题。
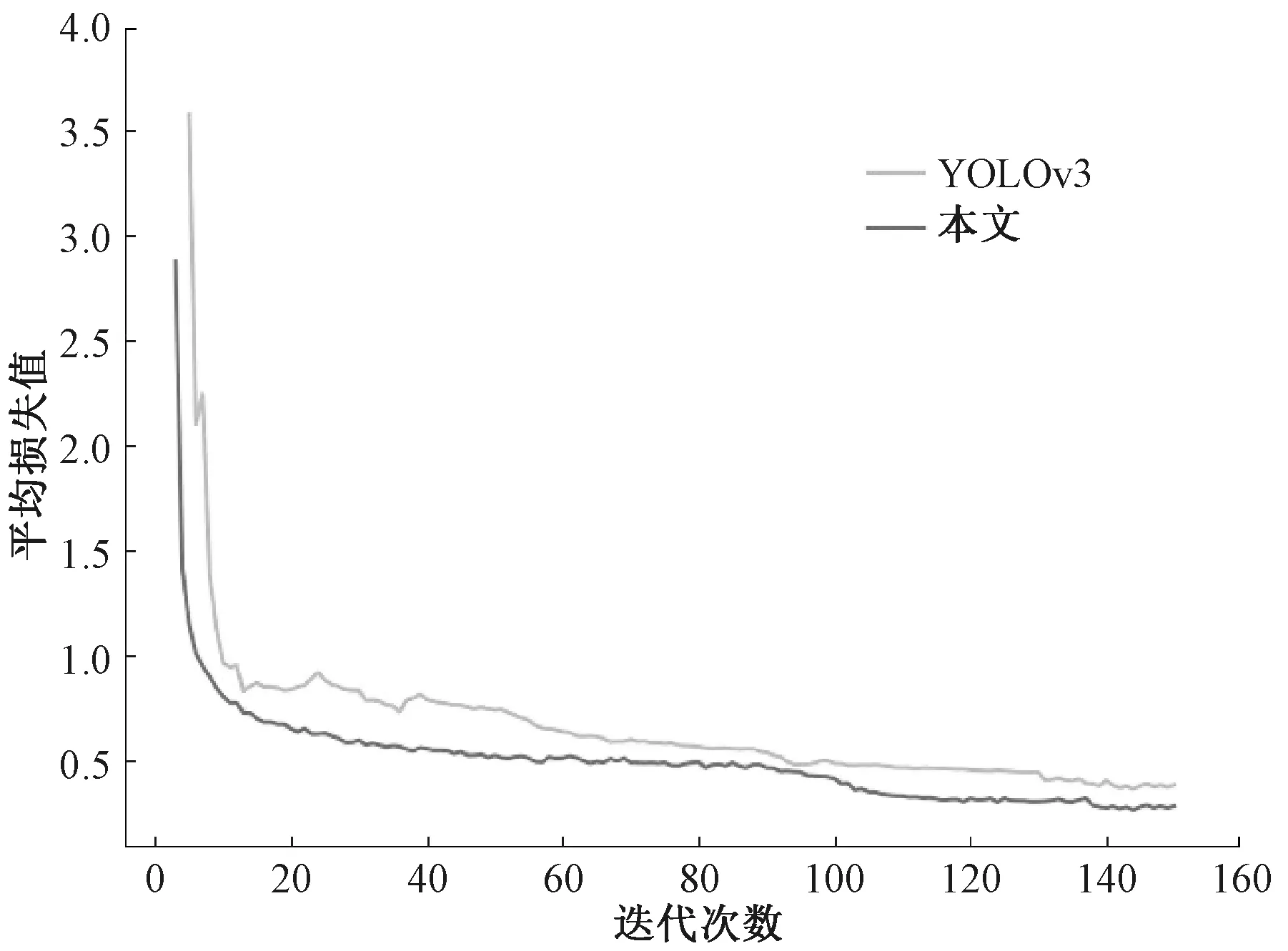
图9 改进前后模型在数据集中的损失值变化曲线
本文对原始算法提取特征的骨干网进行了优化,表1列出了算法改进前后检测速度指标对比结果。由表1可知,改进后模型的权重文件仅为原始算法的1/3左右,检测速度提升到2.5倍以上。
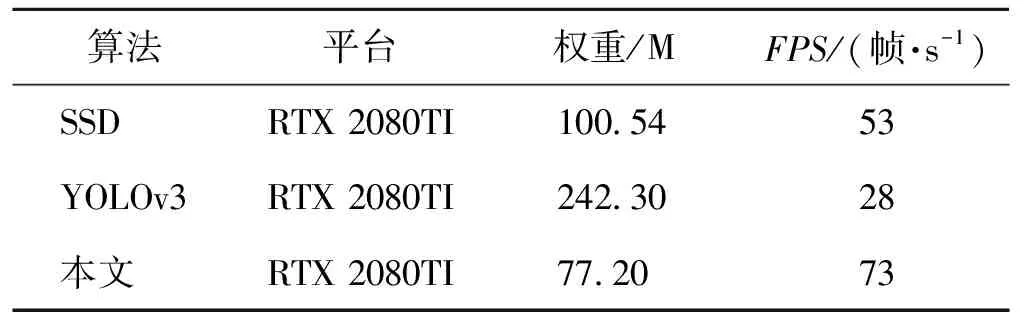
表1 算法改进前后检测速度指标对比
在特征提取网络和检测网络中添加了注意力机制和特征融合等方法,改进了损失函数。平均精度均值(mAP)是目标检测中衡量识别精度的指标,改进前后模型在数据集中的mAP变化曲线如图10所示。可以看出,上方星号曲线为改进后模型的mAP值,明显优于原始算法,提升了约14%。

图10 改进前后模型在数据集中的mAP变化曲线
表2列出了算法改进前后检测精度指标对比结果。由表2可知,改进后的算法性能优于同为一阶段检测模型的SSD算法,改进算法在提升模型前向推理速度的同时也提升了模型的检测精度。

表2 算法改进前后检测精度指标对比
此外,本文对改进算法进行了消融实验,为了验证不同改进算法对YOLOv3模型的影响,进行了4组对比实验,得到以下结论。① 对YOLOv3的特征提取网络进行优化,将GhostNet网络作为提取特征的骨干网,可以发现,改进后的算法略微损失了检测精度,但将检测速度提升了约2.8倍;② 为了提升模型的检测精度,将注意力机制应用于特征提取和检测网络中,模型的mAP值提升了约6%,而检测速度仅降低了2帧/s;③ 本文采用自底向上与反卷积
特征放大融合的方式,进一步提升了模型在复杂环境下对小目标的检测精度,mAP值相比之前的改进又提升了约9%;④ 采用DIOU指标替换IOU指标,优化了模型的参数,将mAP值又提升了1%。
3 小结
本文针对云南机场集团智能化检测任务的需求,提出基于YOLOv3的改进检测算法,优化了特征提取网络,在不降低检测精度的同时提升了检测速度;采用特征融合、添加注意力机制和反卷积特征放大的方式提升了小目标的检测能力。实验结果表明,改进算法能够提升模型在嵌入式设备中的检测速度和精度,为云南机场集团智能化建设提供有效的解决方案。
