基于纹理恢复的低剂量CT去噪算法
2022-08-17赵雪梅
赵雪梅
(北方工业大学信息学院,北京,100009)
关键字:图像去噪;低剂量CT;深度学习;纹理恢复
0 引言
近年来,随着医学CT的广泛使用,X射线辐射对患者健康的潜在危害引起了公众的关注。因此,降低CT辐射剂量已成为重要的研究课题。但X射线通量的降低会导致CT图像噪声和伪影的增加,进而影响医生诊断的准确性[1]。目前已经提出了许多算法来改善低剂量CT(LDCT)的图像质量。通常,这些算法可以分为三类:投影域去噪、迭代重建和图像域去噪。
投影域去噪和迭代重建都需要对投影数据进行建模,但作为CT扫描仪的中间数据,投影数据一般不易获得。图像域去噪方法直接对CT图像进行处理,不需要任何原始数据。因此,研究学者们在图像域进行了大量的研究[2]。最近,深度学习为低剂量CT去噪提供了新的思路。目前已经提出了几种用于CT去噪的方法,例如Chen等人设计了具有残差学习的编解码网络(RED-CNN)[3],去噪效果显著。但由于使用MSE损失,产生了过度平滑的问题。本文提出一种自注意力残差编解码网络,相比RED-CNN,能够更好地恢复出CT图像的纹理特征。
1 自注意力残差编解码网络(SRED-Net)
此前Yang等人引入VGG构建感知损失来解决过度平滑的问题[4],但VGG最初是针对自然图集的分类问题进行训练的[5],使用VGG损失会在CT重建过程中引入无关的特征[6]。因此,参考VGG19设计了特征提取网络,用来构建特征损失,并在编码网络引入自注意力机制,网络记作SRED-Net。
1.1 网络结构
原始的RED-CNN网络主要由卷积层,反卷积层和ReLU构成。在对应的卷积层与反卷积层之间加入短连接来学习残差。从输入到输出之间分别有5个卷积层和反卷积层,连续的卷积层、反卷积层可以看作编码、解码的过程。网络中所有卷积层与反卷积层的卷积核大小为5,每层的滤波器数量为96。

图1 SRED-Net 结构图
改进后的SRED-Net编码部分由5个编码块和2个自注意力模块组成,编码块滤波器数量分别为64、64、128、128、256;解码部分由5个解码块组成,滤波器数量分别为256、128、128、64、64。编码块由卷积层与ReLU激活层组成,解码块由反卷积层与ReLU激活层组成。卷积核大小设为3,步长为1,padding为1。
1.2 自注意力模块
自注意力模块如图2所示。自注意力机制[7]减少了对外部信息的依赖,擅长捕捉数据或特征的内部相关性。相比于自然图像,CT图像包含的信息较少,因此,采用自注意力机制可以更好地提取其内部相关信息。
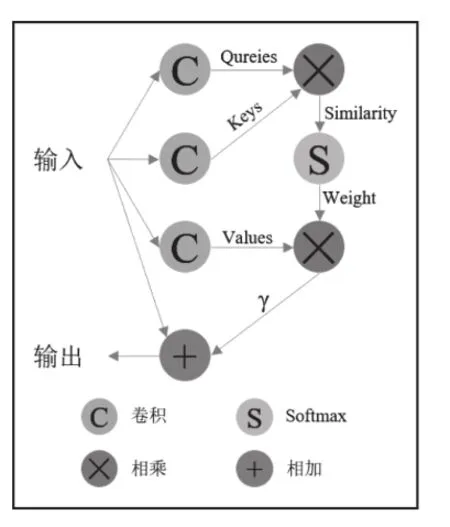
图2 自注意力模块结构图
1.3 特征提取网络
特征提取网络结构如图3所示。使用网络的第3层卷积后的输出作为边缘特征,用于构建边界损失。边界损失可以表达为:

图3 特征提取网络结构图

使用网络的第8层卷积后的输出作为纹理特征,用于构建纹理损失。纹理损失可以表达为:

其中,FE3(·)表示提取边缘特征,FE8(·)表示提取纹理特征,x代表输入LDCT的patch,y代表对应的NDCT的patch,w、h、d分别表示 patch的宽,高和深度,表示求二范数。
MSE损失表达为:

将MSE损失与边界和纹理损失相结合,完整的损失函数可以表达为:

记作BTL。其中,λ1、λ2是两个可训练的参数,用来权衡边界损失和纹理损失。
2 实验结果与分析
使用CPU版本为Intel(R) Core(TM)i5-8250U的计算机进行仿真,GPU版本为NVIDIA GTX1080的计算机能够加速计算。网络使用Python语言编写,利用Pytorch框架来实现。
2.1 训练
在训练期间,数据集采用AAPM低剂量CT挑战赛提供的CT数据[8],其中包括来自10位患者的常规剂量CT和相应LDCT数据,将患者L506的数据作为测试集,其余作为训练集。CT尺寸为512×512。使用Adam优化所有网络。通过patch的方法来增大数据集,patch size设置为64。batchsize设置为16。控制SRED的MSE损失、特征损失之间权衡的加权参数λ1、λ2通过训练来学习。
2.2 消融实验
通过RED-MSE和SRED-MSE的对比,验证自注意力机制的有效性;通过RED-MSE与RED-BTL的对比,验证特征提取网络的有效性。
(1)视觉效果分析
图4展示了不同神经网络对CT去噪的视觉效果。通过比较可以看出,与不使用自注意力机制的RED-MSE相比, SREDMSE保留了更多的纹理信息。使用MSE损失会使得组织纹理过于平滑,边界也较为模糊;使用BTL损失保留了更多的纹理细节,与NDCT更加相近。

图4 去噪效果对比图
(2)客观指标分析
表1展示了测试集上三个客观指标的均值,包括峰值信噪比(PSNR)、结构相似度(SSIM)和均方根误差(RMSE)。网络,在PSNR,SSIM,RMSE三项指标上均高于不使用自注意力机制的方法,验证了自注意力机制的有效性。使用BTL的RED-BTL和SRED-BTL,三项指标均高于不使用BTL的方法,验证了特征损失的有效性。并且,同时使用自注意力机制与BTL的SRED-BTL方法,获得了最优的指标结果,PSNR提升了1.21dB,SSIM提升了0.0112,具有一定的纹理保留效果。
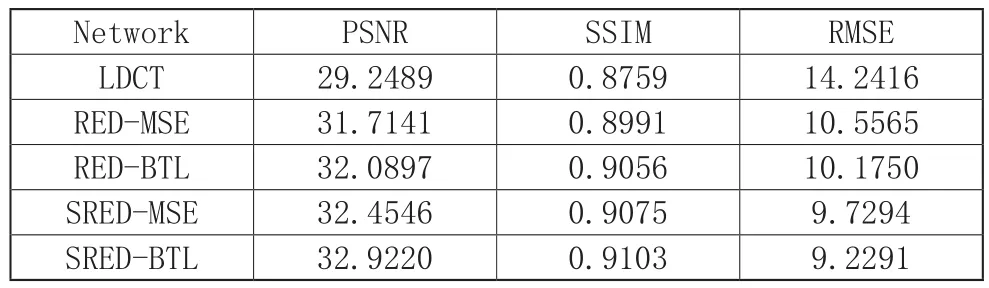
表1 测试集客观评价指标
3 总结
针对目前深度学习方法在低剂量CT去噪领域存在的纹理缺失和组织平滑问题,本文提出了一种自注意力残差编解码网络,主要有以下两点改进:(1)引入自注意力机制;(2)设计特征提取网络,构建边界和纹理损失。改进后的网络PSNR提升了约1.21dB,SSIM提升了约0.0112。
