大数据技术支撑下的移民搬迁信息化架构设计和应用实现
2022-08-17郭朝阳
王 凯 张 帆 郭朝阳
(自然资源部陕西基础地理信息中心, 陕西 西安 710054)
0 引言
移民搬迁是精准脱贫的主要方式之一,是一项集政策性、专业性、群众性于一体的系统工程,是影响国家安定和发展的一个重要因素[1-2]。移民搬迁工作具有数据体量大、信息碎片化、对象关系复杂等特点,数据管理、应用、分析和挖掘的难度非常大,这就需要思考如何用更便捷、更准确地获取、整合、管理数据,实现数据利用的最大化[3]。大数据时代的到来为解决海量数据的管理和应用提供了新的思路[4]。应用大数据技术,开展移民扶贫搬迁数据的汇集、处理、对比分析与综合评估,并通过大数据技术开展预警、决策和分析,能够为移民搬迁工作提供决策参考[5]。
本文在深入分析大数据相关技术的基础上,结合移民搬迁信息管理平台的实际业务需求,从海量数据管理、数据融合分析、数据可视化展示等方面开展了关键技术研究,提出了移民搬迁大数据平台的架构设计,为移民扶贫搬迁空间数据的存储、管理、分析和可视化服务提供了解决方案。
1 问题和需求分析
1.1 海量数据管理问题
移民搬迁工作是一项巨大的系统工程,从涉及对象的层级上看,有省级、地市、县区、乡镇、社区级搬迁对象等多级对象;从涉及业务的时间过程跨度上看,既有移民搬迁总体规划、逐年计划、规划地解决方案设计、评估、执行,又有搬迁前规划、搬迁建设监管和搬迁后管理;从数据类型看,有结构化的常规数据、地理信息系统(geographic information system,GIS)空间数据,还有非结构化的文档数据、视频及图像数据。如何采用大数据存储、架构和管理技术,对这些海量的数据进行有效管理,为移民搬迁工作管理提供强大的支撑,是移民搬迁信息化工作的需要考虑的基础性工作。
1.2 数据融合和分析问题
数据的价值在于利用,移民搬迁既包括移民搬迁对象信息、搬迁安置信息、项目信息,又包括了人口、社会经济、扶贫政策与产业、地理环境等各类数据,如何做到搬迁工作的科学化、信息化、精准化,实现搬迁对象精准、资源整合精准、项目安排精准、资金使用精准、措施到位精准、成效巩固精准,需要基于大数据技术,实现分布式环境下多源、异构数据的清洗、比对、统计、分析和挖掘,在海量的搬迁数据中将有价值的信息分类、汇总及分析,充分挖掘各类数据的价值,助力移民搬迁工作的精准和科学开展。
1.3 数据多维可视化展示问题
大数据时代的背景下,在繁杂多元的数据中找到精准的规律和结论,并创造价值是数据应用的基本路径。传统的数据展示方式往往是通过表格和数字,展示效果不够直观,无法让人快速获取需要的信息,无法满足辅助决策应用需求。大数据可视化技术为数据的直观展示提供了解决之道,比起使用文本或数字描述,大数据可视化技术将大量的数据和结果以更直观、美观的方式展示出来,让信息易于掌握并具有意义。特别是随着大数据可视化应用的发展,地理信息数据可视化也受到了越来越多的重视,地理信息数据的可视化,不仅可以再现和表达时空信息,更重要的是分析对象的时空格局、挖掘其演化规律,并且可以通过这些模式规律对动态变化进行模拟和预测[6-8]。
2 关键技术及体系架构
结合移民搬迁信息管理应用需求,引入大数据管理、处理和可视化技术,开展相关关键技术研究,形成移民搬迁大数据平台的架构设计,满足移民搬迁管理对科学管理、准确分析、辅助决策的要求。
2.1 关键技术研究
2.1.1分布式数据采集技术
移民搬迁涉及多源、异构的各类数据,为了实现数据的有效管理和分析,需要将分布式的各类数据进行有效汇集,形成符合一定标准的数据成果,并存储到目标环境中,实现统一的数据管理视图。
在采集架构上,数据采集基于分布式架构,分为Master、Worker角色,Master会根据采集任务量动态启动、关闭Worker;在采集方式上,采用Sqoop、Logstash、DataX等多源数据采集框架,实现不同来源、不同类型的数据源采集,使用消息队列传输采集的数据,使用Zookeeper保障任务稳定性、高可用性;在采集策略上,对于数据中有时间戳信息的数据进行增量采集,无时间戳信息则进行全量采集。其中,在全量数据采集时,对数据行进行MD5加密,并通过MD5值进行对比检测数据新增、修改、删除情况。数据采集的架构设计如图1所示。

图1 数据采集架构
数据采集涉及的相关技术如下:
(1)多源数据采集技术。多源数据采集框架实现分布式、多源、异构数据的汇集,主流的数据采集框架有Flume、Sqoop、LogStash等,其中,Flume主要用于采集文件,socket数据包等数据源,主要应用于海量日志信息的收集;LogStash和Sqoop主要用于传统的数据库(如Mysql、Postgresql)与分布式文件系统(如HDFS)之间的数据信息采集和传递,相比而言,LogStash在开发生态、扩展性上、易用性上更具有优势。
(2)消息队列技术。消息队列即消息中间件,是分布式系统中重要的组件,主要解决应用解耦、异步消息、流量削锋等问题。目前主流的消息队列有Kafka、ActiveMQ、RabbitMQ等。利用消息队列技术,可以将下层的数据采集框架与上层的消息处理解耦,数据采集框架负责数据采集,并定时写入到消息队列中,消息队列负责数据的接收、存储和提供。
2.1.2差异化数据存储管理
通过数据汇集来的数据类型多样,有结构化的业务数据、GIS空间数据,还有非结构化的文档数据、视频及图像数据,需要面向数据存储和应用特点,采用差异化的存储策略,实现多源异构数据的优化存储[9]。依据数据结构、数据量、数据特点和应用需求,在传统空间数据库、共享文件系统基础上,综合利用空间数据库、非关系数据库、分布式文件系统等各类管理模式,采用块存储、文件存储、对象存储等多样化的存储架构,进行多源异构数据综合存储,构建面向用户一致透明操作的综合数据库,实现来源不同、格式各异、应用各具特点的数据的高效存储和有效管理[10]。数据存储结构设计如图2所示。
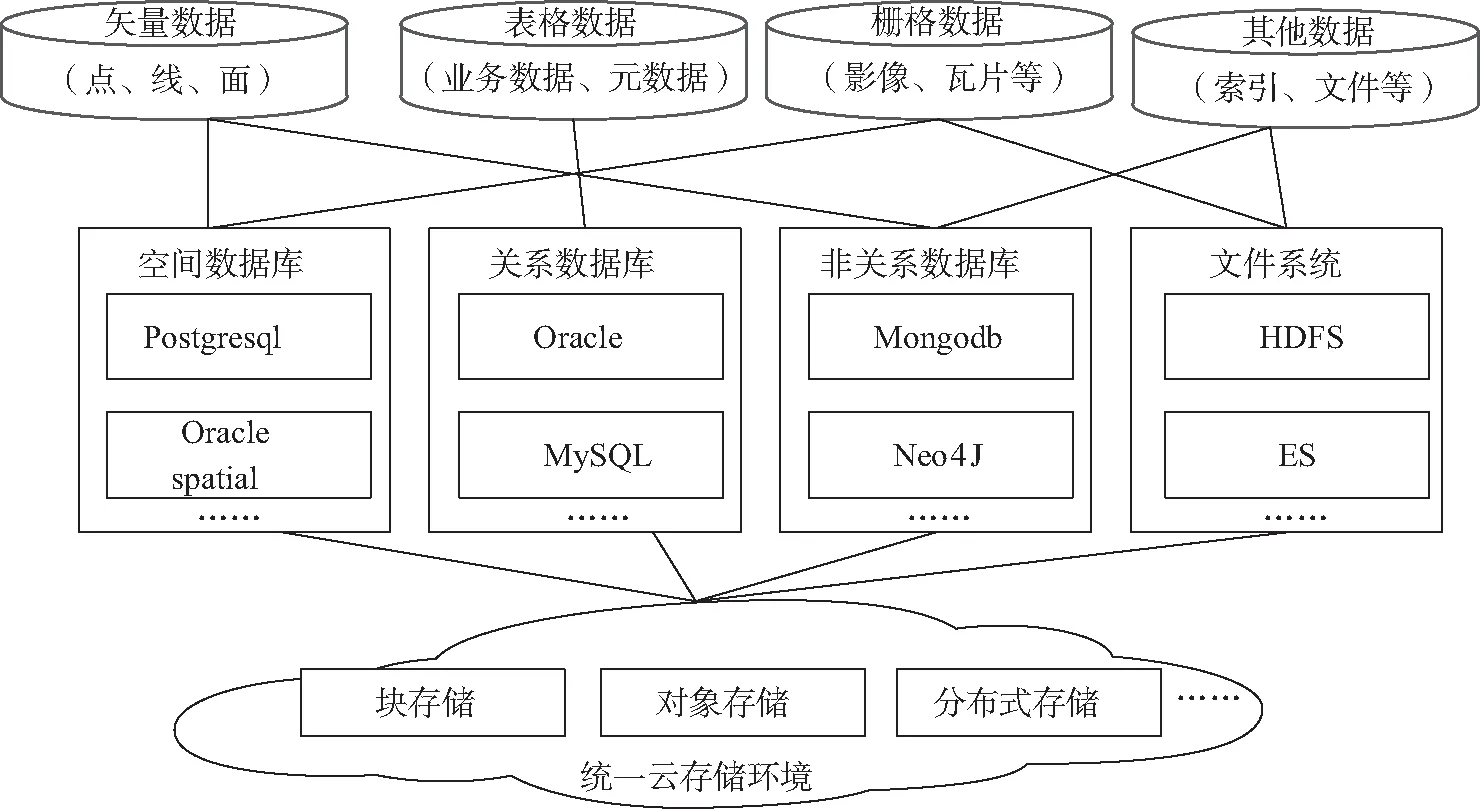
图2 数据存储架构
2.1.3数据清洗和融合技术
在大数据存储环境的基础上,借助于大数据计算引擎,开展移民搬迁数据治理,通过对不同数据之间的动态格式转换和对数据的清洗、分析、维护等一系列操作[11],形成统一的,可以对内服务、对外输出数据的信息服务。数据清洗和融合的技术流程图如图3所示。

图3 数据清洗融合架构
涉及的关键技术如下:
(1)数据清洗技术。数据清洗是按照一定的清洗规则,对数据进行规范化处理[12]。常见的数据清洗规则包括数据格式清洗、数据逻辑错误清洗,其中数据格式清洗是对数据格式(如时间、日期、全半角、货币单位等)、非法字符(如空格、全角/半角等)等进行统一处理;数据逻辑清洗是对数据重复、数据不合理值、数据相互矛盾等进行处理。数据清洗采用基于规则的清洗模式,将业务规则的抽象出来,支持自定义的数据规则扩展,并实现可插拔式的规则嵌入和清除。数据清洗基于Drools规则引擎框架,Drools规则引擎通过调用规则文件来判断记录是否是脏数据,并根据规则定义对数据进行处理。
(2)数据融合技术。数据融合是面向数据应用的关键。一方面,数据融合通过梳理各类数据之间的血缘关系,实现不同数据源、数据表、数据要素、字段、编码规则之间的映射和关联;另一方面,以数据流向、数据血缘关系和应用需求为依托,通过交互式操作,可灵活构建数据服务模型,提供自定义的模型化数据服务,实现基于数据模型直接建设数据应用。
2.1.4数据可视化表达技术
结合视觉传达,新媒体设计,图表化设计等方法,针对移民搬迁业务应用和辅助决策应用需求,基于主流的地图引擎和可视化渲染引擎,提供二维、三维地图、智能驾驶舱、高级图表等多样化的地图可视化表达,实现集宏观微观于一体、动态静态于一体、地图表格于一体的多样化数据表达[13-14]。可视化表达的技术架构如图4所示。
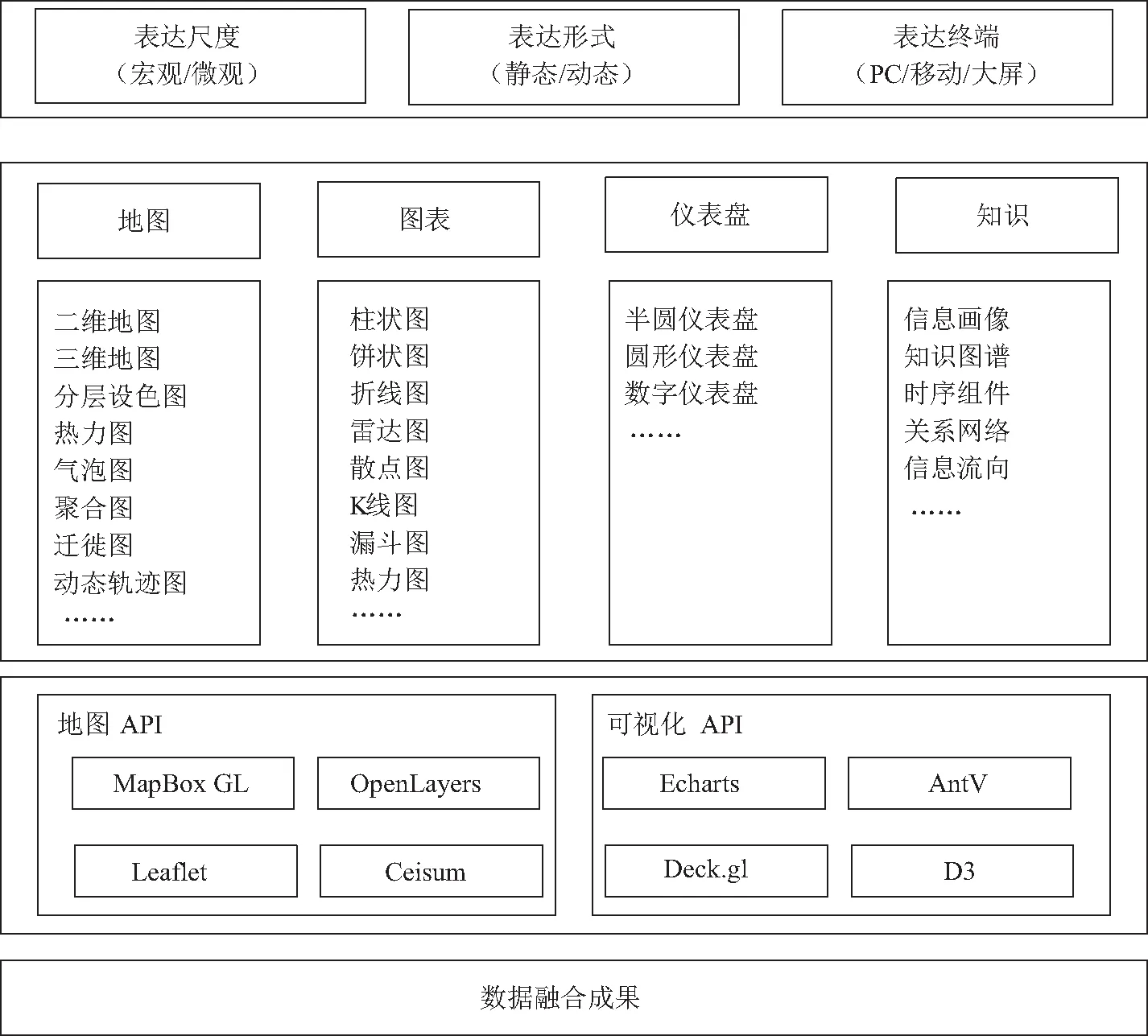
图4 数据可视化表达架构
数据可视化表示涉及的相关技术如下:
(1)地图API。地图应用程序接口(application programming interface,API)为数据可视化提供二维、三维地图呈现、渲染和应用的框架,包括各种商业和开源的地图API,其中,二维地图框架主要包括Leaflet、MapboxGL、ArcGIS、OpenLayers等,三维地图框架主要以Cesium、Threejs为代表。
(2)可视化API。可视化API为数据可视化提供形式多样、交互灵活、动静结合的可视化图形和图表应用框架,常见的可视化API包括ECharts、AntV、Deck等。通过将可视化API与地图API集成,构建以二维、三维地图为基底,以丰富多样的图表为承载的开放、跨终端时空数据可视化框架。
2.2 技术架构
基于上述关键技术研究,本文提出了大数据技术体系下移民搬迁数据汇聚、处理、应用的架构设计,该架构采用基于服务的设计理念,采用基础支撑层、数据源层、数据治理层、服务层、可视化表达层等多层架构进行实现,具体如图5所示。
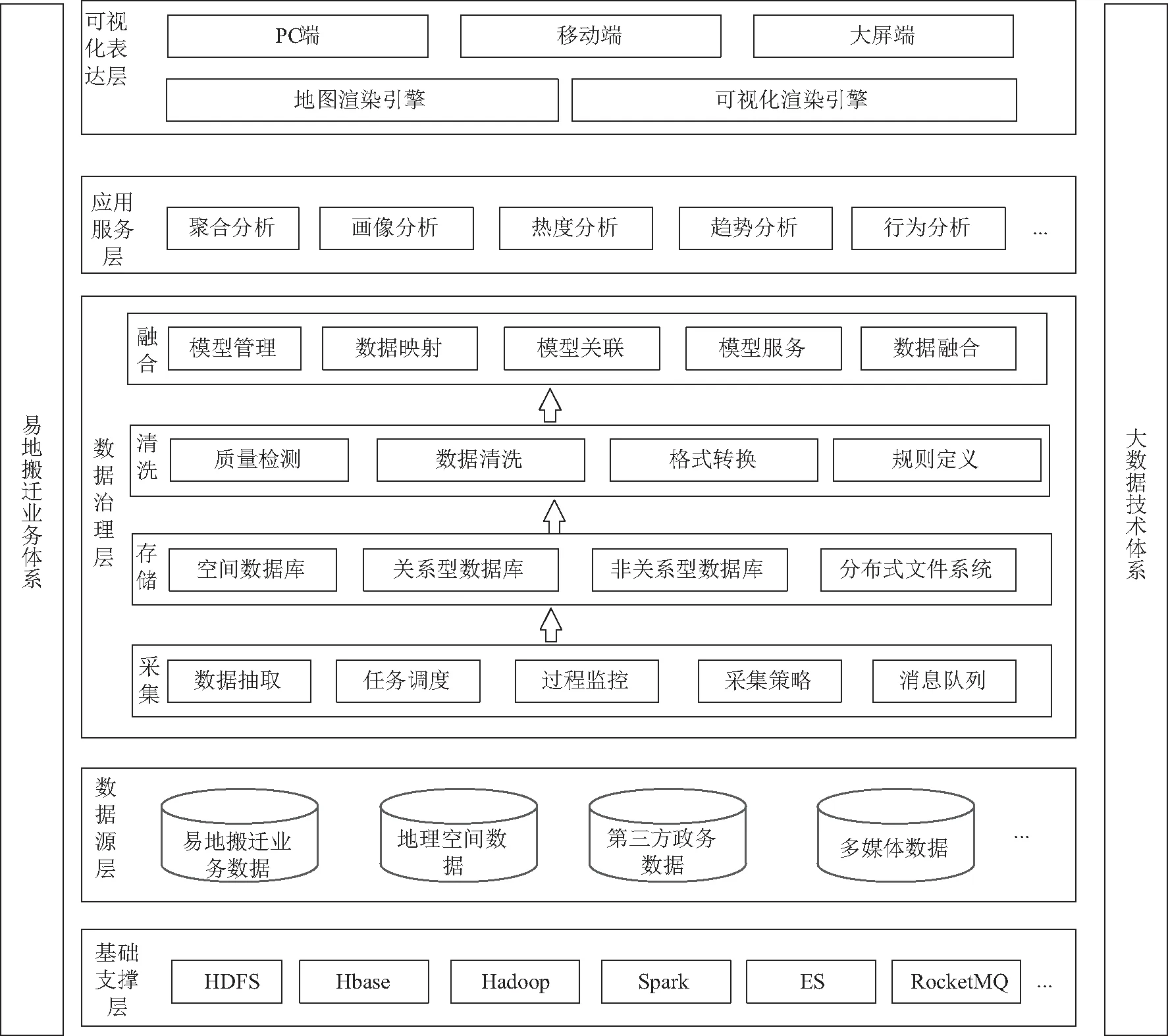
图5 平台总体架构
基础支撑层:基于大数据相关技术生态体系构建,包括HDFS分布式文件系统、HBase分布式数据库以及MapReduce、Spark等并行计算处理系统,为移民搬迁大数据的有效管理和高效运算提供计算环境。
数据源:提供多源、异构的移民搬迁数据,包括搬迁业务数据、地理空间数据、人口经济等第三方政务数据,以及图片、文档等数据。
数据治理层:由数据采集、数据存储、数据清洗、数据融合四层模块,采用基于规则和模型的数据治理策略,实现多源、异构、分布式数据的汇集、存储、管理和融合服务。
应用服务层:以数据融合的成果为基础,针对移民搬迁业务需求,提供聚合分析、画像分析、行为分析等各类数据应用和分析服务。
可视化表达层:结合视觉传达,新媒体设计,图表化设计等方法,采用地图引擎和可视化渲染引擎,提供开放的、可柔性定制的、跨终端时空数据展示框架,支持电脑端、移动端、大屏端等各类展示应用需求。
3 应用实践
以上文所述的系统框架和关键技术为基础,针对陕西省移民搬迁信息化管理要求,研发了陕西省移民搬迁信息管理平台。平台涉及全省100多万户约500万人的搬迁,用户群体包括省级、地市、县区、乡镇、社区各级用户,数据类型包括业务数据、空间数据、档案数据等多源数据。平台采用基于服务的设计理念,在Hadoop大数据框架的支撑下,综合应用基于LogStash和Kafaka的数据采集技术、基于Drools数据清理和Neo4j数据融合技术,完成了多源、异构、海量数据的高效存储和管理,构建了基于MapBox和Echarts的地图可视化框架,实现了海量搬迁数据的汇集、存储、清洗、融合和可视化分析。
通过平台建设,为移民搬迁业务指导、政策决定提供科学、准确的分析手段,确保了移民搬迁“搬得出,稳得住,能致富”,为实现“精准搬迁、精细管理”奠定了坚实的基础。平台的功能结构如图6所示。

图6 平台功能模块
4 结束语
本文结合移民搬迁信息化工作中数据体量大、信息碎片化、对象关系复杂等突出特点和管理需求,从海量数据管理、数据挖掘分析、数据可视化展示等方面进行了关键技术研究,在此基础上,提出了大数据环境下移民搬迁信息化平台架构并予以实现,为移民搬迁工作精准、科学管理提供了技术支撑,也为后续类似信息化业务平台建设提供了解决思路。
