基于CEEMDANSE和DBN南网发电侧燃料量预测研究
2022-08-16卢伟辉赵玉柱刘兴辉张中林
卢伟辉,赵玉柱,李 鹏,刘兴辉,张中林
(1. 中国南方电网有限责任公司调度控制中心, 广东 广州 510623;2. 南京华盾电力信息安全测评有限公司, 江苏 南京 210013;3. 南京工程学院能源与动力工程学院, 江苏 南京 211167)
当前,我国正将碳达峰、碳中和气候承诺纳入经济社会发展和生态文明建设整体布局.一方面,建设以新能源为主体的新型电力系统;另一方面,保障我国电力安全依然离不开煤电.截至2020年底,我国煤电装机容量达到1.08×109kW,占全部装机容量的49.1%,发电量占全网的70%.火电企业的安全稳定运行对于电网的安全稳定至关重要,而燃料问题是火电的核心问题.由于受到国际煤价、气候、经济发展、交通运输和市场博弈等多种复杂因素的影响,燃料供应存在一定的随机性和不确定性,且随着风电和光伏等新能源的比重逐渐增加,火电深度调峰带来了燃料消耗量的不确定性增加.南方电网(简称南网)范围内,水电比重较大,水电呈现出明显的季节性,新能源和水电的负荷有着明显的气候季节性分布规律.电网的安全取决于用电侧负荷和发电侧负荷平衡,目前电网对用电负荷实时预测已经研究非常充分,基本能准确预测到短期和长期用电负荷的变化[1-4].发电侧机组容量较大,负荷调度一般不存在问题,但是在尖端负荷和极端天气条件下,发电侧机组出力受限,特别是煤电燃料量问题影响煤电的出力,易造成电网大规模限电和停电事故.煤电企业的燃料量状况是电网发电侧负荷调度需要重点考虑的因素.
燃料是火电企业的重要问题,煤电企业均建有燃料信息化管理系统[5-6],对燃料实现了较好的管控.在南网范围内,信息化系统是信息孤岛,对全网的煤电燃料量没有统一管理和预测分析.文献[7]利用互联网+技术构建南网燃料管理系统,将南网范围内火电燃料统一管理和分析,并对燃料量进行一定预测,防止发生燃料事故.在碳中和背景下,由于水电、风电、光伏和分布式能源的充分发展,燃煤电站作为后备能源参与深度调峰,给煤电燃料量带来了更多不确定性.燃料库存量太高造成煤电资金压力过大,给经营带来困难;库存量太小,给电网安全运行带来威胁.确保一个合适的、安全的燃料库存量,依赖于对电网负荷及燃料用量的预测.为提高发电侧燃料预测精度,本文提出一种基于自适应噪声的完全集合经验模态分解-样本熵(CEEMDAN- SE)和深度信念网络(DBN)的发电侧燃料组合预测模型.该模型可提高南网发电侧燃料库存预测精度,降低煤电燃料库存成本,提高燃料安全性、电网安全性.
1 南网发电侧燃料综合管理平台
如图1所示,南网综合燃料管理系统主要由采集终端、服务器、采集网络和防火墙等构成.建立一个综合数据网络,煤电燃煤燃料库存信息通过该网络上传到主服务器.服务器的建设采用分区和分层方式,主服务器布置在安全三区,DMZ服务器布置在隔离区,服务区之间设置防火墙隔离.DMZ服务器作为主服务器安全备份,可供内部客户和外部客户访问,内部客户端可以直接访问,移动终端外围智能终端互联网用户需设置防火墙.

图1 燃料管理系统网络和硬件结构
综合管理平台采集南网区域内煤电燃煤库存信息,及时掌握南网区域内煤电燃煤库存情况,实现煤电燃料库存统一管理,便于电力调度的科学性和合理性,确保电网安全.基于煤电燃煤库大数据,开发先进预测控制方法可以对煤电燃煤燃料库存进行预测,指导煤电企业合理安排燃料采购,降低运行成本,提高经济效益.
2 南网煤电燃料量预测模型
2.1 预测模型选择
随着智能化技术和大数据的不断应用,人工智能方法逐渐取代传统预测方法广泛应用在预测领域.人工智能预测方法主要包括神经网络(ANN)、支持向量机(SVM)和专家系统[8].
BP神经网络在处理非线性问题上应用广泛, BP神经网络在初始化时,初始化参数存在一定的随机性,造成预测结果局部最优,难以达到整体最优.BP神经网络属于浅层神经网络,不能对样本数据进行充分提取,最后预测结果精度不高.DBN是一种由多层受限波尔兹曼机(RBM)堆叠成的深层网络,解决了BP神经网络浅层问题,精度更高,广泛应用于各种过程预测,通过无监督算法逐层预训练网络得到较好的初始参数,能对原始数据特征进行充分提取,获得较好的预测结果[9-10].
通过分析,南网范围内煤电燃料量信息是一种非平稳的时间序列,单一预测模型进行直接预测一般难以获得较好结果,DBN属于单一预测模型,将原始数据分解,利用DBN构建预测模型,再建立组合预测模型,可获得更高的预测精度.原始数据分解有多种方法,常用的有小波分解和经验模态分解(EMD)[11-12].小波分解需要预设基函数,EMD可以不用基函数,但是分解过程中易出现模态混叠现象.
CEEMDAN方法在EMD基础上添加自适应高斯白噪声,分解过程更加完整、模型重构误差低,解决了EMD模态混叠问题,分解效率高,能完全消除噪声[13].样本熵(SE)用于表示时间序列中新信息或新模式发生率的非线性动力学参数,不依赖数据长度,与时间序列具有更好的一致性.对于一个时间序列,熵值大小反映时间序列复杂度,样本熵越大,序列越复杂;反之,样本熵越小,序列越简单[14].
本文基于CEEMDAN-SE和DBN构建南网区域内煤电燃料预测模型的流程如图2所示.利用南网发电侧燃料综合管理系统采集的煤电燃料原始库存数据,采用CEEMDAN方法将原始数据分解为若干个本征模态函数(IMF),每个IMF代表不同的振荡成分.为了降低IMF复杂度和计算量、提高计算效率,利用样本熵计算每个IMF的复杂度并重组.对每个重组分量分别建立各自的DBN预测模型,最终的预测模型由各重组分量的预测模型叠加而成,与单一预测模型相比,建立的最终预测模型具有较高的精度.
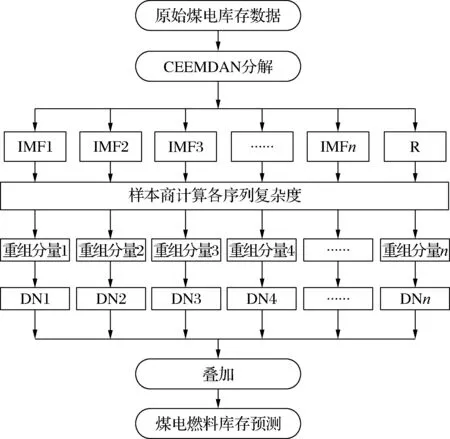
图2 基于CEEMDAN-SE和DBN煤电燃料量预测模型
2.2 CEEMDAN算法
为了克服EMD模态混叠现象,CEEMDAN在模态分量分解过程中添加自适应白噪声以及计算独特信号残差.CEEMDAN方法通过计算唯一余量信号得到各个模态分量,分解过程完整、重构误差低,重建后的信号几乎与原始信号相同,具体过程为:
1) 构建煤电燃料库存原始序列曲线X(t)+ε0ni(t),其中,ε0为高斯白噪声幅值常数,ni(t)为第i次加入的满足标准正态分布的高斯白噪声;
2) 采用EMD方法对原始曲线进行N次重复分解,通过均值计算得到第一个模态分量:
(1)
计算得到第一个余量信号:
(2)
3) 构建序列r1(t)+ε1E1(ni(t)),其中,E1为EMD运算符;
4) 继续对构建序列进行N次EMD重复分解,得到第二个模态分量:

(3)
计算得到第二个余量信号:
(4)
5) 重复步骤3)和4),当余量信号满足终止分解条件,得到第k个模态分量:
(5)
分解最终残差信号为:
(6)
通过以上方法,煤电燃料库存原始信号可以分解为:
(7)
2.3 样本熵计算方法
时间序列为X{x(1),x(2),…,x(n)}(n=1,2,…,N).样本熵计算过程为:
1) 将原始序列按顺序重构一组m维向量:
Xm(i)={x(i),x(i+1),…,x(i+m-1)}
(8)
2) 定义向量Xm(i)和Xm(j)中对应元素相差最大值的绝对值为其距离:
d[Xm(i),Xm(j)]=max[|x(i+k)-x(j+k)|]
(9)
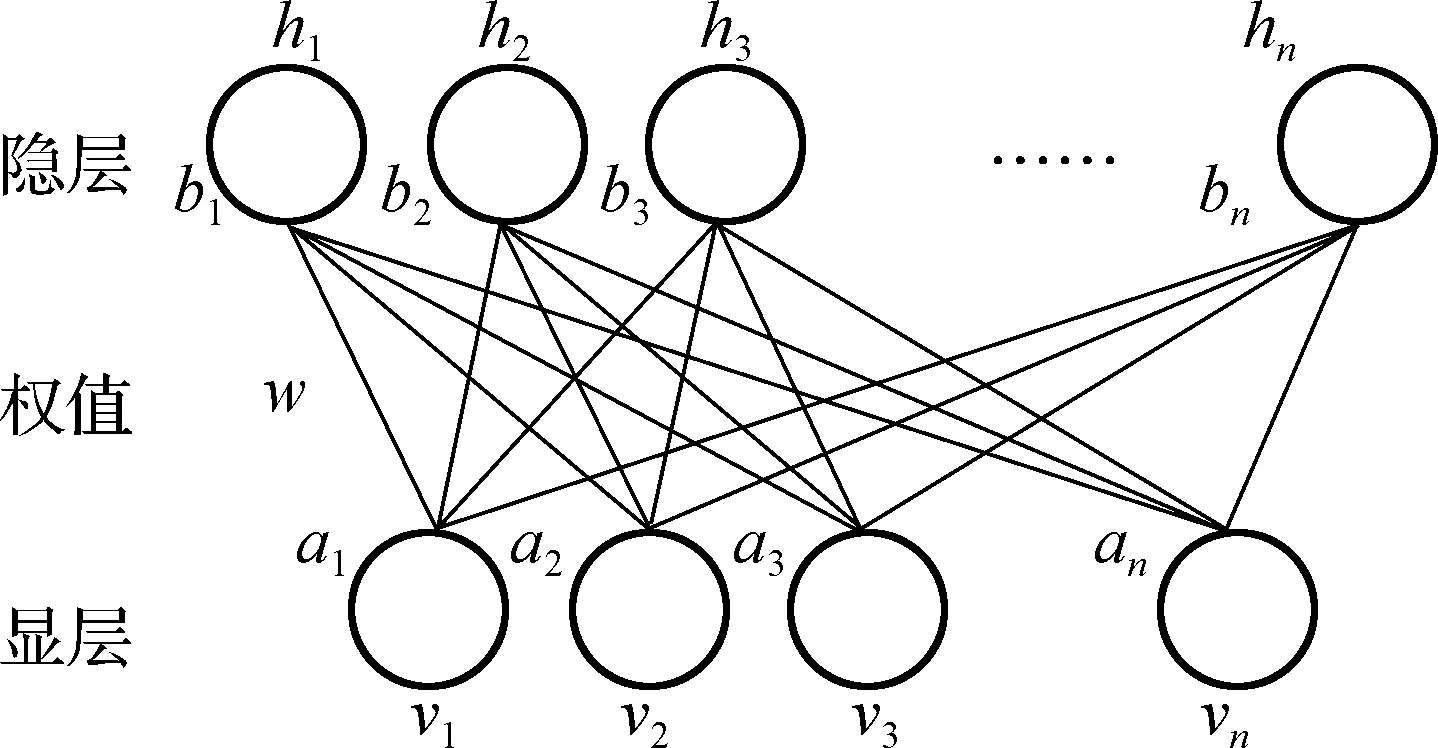
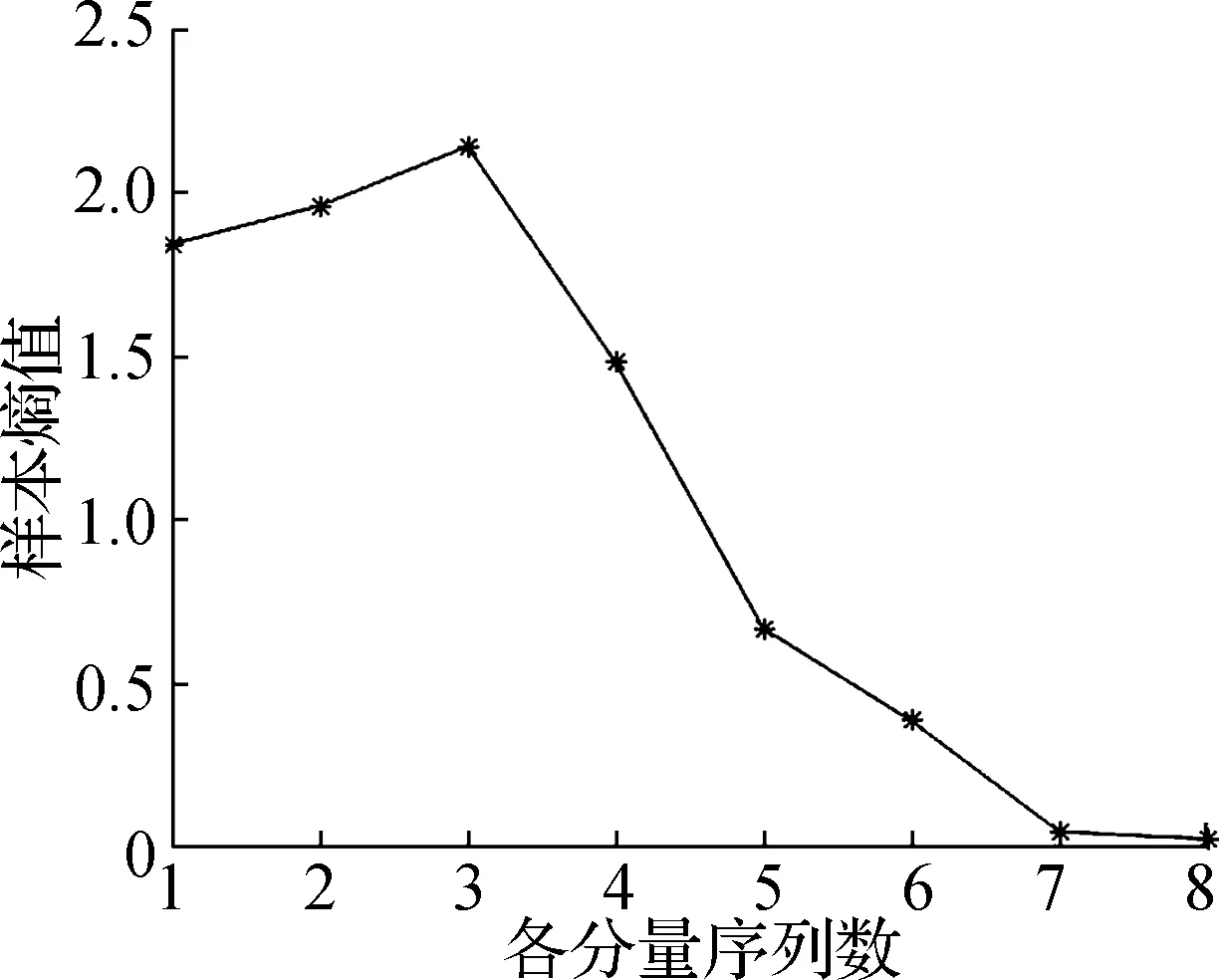
3) 设定一个阈值r,计算d[Xm(i),Xm(j)] (10) 4) 重复以上步骤,可计算得到理论样本熵值: (11) 对于有限的N,计算SE近似值: (12) DBN本质上是一种概率型深层网络,把无监督学习和有监督学习结合,主要由RBM堆叠构成.对DBN的训练主要分为无监督训练和微调两个步骤;对RBM预训练一般采用无监督贪婪逐层算法得到网络初值; 然后利用BP 网络有监督地对网络参数进行反向微调. RBM作为DBN的重要组成部分,由一层显层和一层隐层组成,结构如图3所示. 图3 RBM结构示意图 在RBM中能量函数定义为: For impedance matching, the equivalent input impedance of port 2 should be satisfied as follows, (13) 式中 :wij为隐层和显层间的连接权值;vi为显层;ai为显层偏置;hi为隐层;bi为隐层偏置. 显层概率分布函数为: (14) 为了学习RBM权重参数w、显层偏置参数a、隐层偏置参数b集合θ={w,a,b}的值,需要把方程式给出的似然函数最大化,似然函数形式定义为: L=lnP(v) (15) 采用带有一步Gibbs采样的对比发散(contrastive divergence,CD)算法来获取释然函数梯度: (16) 采用式(16),利用CD算法训练RBM. 以南网2019年全年的燃煤库存数据为样本,数据集包含同期电网负荷、新能源负荷、水电负荷和同期气象数据等.选取2019年南网全年每天燃煤库存数据作为训练集,辅助数据为同期新能源负荷、水电负荷和气象数据等. 发电侧原始燃料库存量序列属于随机非平稳序列,针对这一特性,基于CEEMDAN对库存训练集数据进行分解,即对365个连续数据点进行分解,添加白噪声组数NR=100,标准差Nstd=0.2,库存信号序列通过CEEMDAN算法被分解为7个特征互异的模态分量和1个残差信号,分解结果如图4所示. 模态分量的数量决定预测模型的规模,为了降低整体计算规模和模型复杂度,本文采用样本熵对每个IMF分量复杂度进行评估,计算过程中嵌入维数取m=2,相似容限取r=0.25,得到各IMF熵值曲线如图5所示. 根据图5,将复杂程度接近的分量进行重组,其中IMF1、IMF2、IMF3重组为分量F1,IMF6、IMF7重组为分量F4,结果如图6所示. 将图6所示的每一个重组分量建立DBN模型,然后将模型进行重组,利用重组后的模型对南网2020年发电侧燃料量进行预测,预测结果如图7所示. 由图7可见,综合考虑南网电网侧负荷构成和气象条件等因素,利用DBN模型预测的南网2020年发电侧燃料量具有一定的精度,能够较好地反映情况:在夏季水电负荷较高,煤电燃料库存偏高;在冬季水电负荷较低,煤电燃料库存偏低;光伏和风电等新能源对煤电燃料库存有影响. 图4 库存信号CEEMDAN模态分量分解 图5 模态分量和余量样本熵 图6 模态分量重组 图7 DBN模型燃料量预测值和实际值 本文构建了南网发电侧燃料库存统一信息管理平台,避免了发电侧和电网侧煤电库存的信息孤岛问题,为电力调度提供参考依据,提高了电网安全稳定性.利用管理平台采集的南网煤电燃料库存信息,将CEEMDAN算法引入到发电侧燃煤库存预测问题中,进行原始燃料库存数据的模态分量分解,采用样本熵对各模态分量进行复杂度分析,以此对各分量进行重组,降低了模型整体复杂度;对各重组序列进行周期性和影响因素分析,采用DBN作为后续预测模型;预测结果证明所提出的CEEMDAN-SE和DBN组合预测模型在南网发电侧煤量库存预测领域具有一定优势,有效地提高了煤电库存预测精度,对于确保电力生产和电网安全具有一定的研究意义.2.4 DBN预测模型
3 南网发电侧燃料量预测算例
3.1 数据预处理
3.2 基于样本熵模态分量重组
3.3 基于DBN模型燃料预测模型



4 结语
