股票评论信息能够预测股票市场的下行风险吗?
2022-08-16鲁万波郑天照
鲁万波,张 萌,郑天照
(1.西南财经大学 a.管理与工程学院,b.统计学院,四川 成都 611130;2.度小满科技(北京)有限公司 风险管理部,北京 100089)
一、引 言
随着现代社会信息化的发展,信息传递的方式发生了巨大的变化,以前多是通过报纸、广播以及电视等获取信息,但如今获取与传递信息的方式主要依赖于互联网。很多金融网站也专门为股市投资者提供了交流互动的股吧平台,产生的海量评论所包含的信息在一定程度上反映着投资者的心理和行为。
行为金融理论认为非理性股市投资者的心理和行为会对股票市场的价格走势产生影响,而且目前学术界已经有很多学者研究股评等文本信息对股票市场的影响。然而还没有学者研究股评信息对于股票市场下行风险的影响,股票下行风险发生的概率虽然很小,但产生的后果非常严重,于是本文探索性进行了股票评论信息与股票市场下行风险影响和预测能力的实证分析,一定程度上弥补了该领域研究的不足。
本文的主要贡献体现在三个方面:第一,利用文本情感分析技术充分挖掘了东方财富网股吧评论数据,探索性进行了股评信息与股票市场下行风险影响和预测能力的实证分析;第二,选择基于情感词典的无监督学习的文本分类方法,并且构建特定金融领域的情感词典,提高了基于情感词典的文本分类方法在股评上的文本分类准确度;第三,从反映投资者关注度的角度、反映投资者对于股市走向情感预期的角度以及从反映投资者情感预期传播程度的角度构建了较为完善的投资者情绪指标体系。
二、文献综述
近年来,越来越多的学者通过挖掘股评等文本的情感倾向,研究投资者情绪对股票市场的影响。挖掘股评等文本的情感倾向涉及文本情感分析技术,目前在互联网数据呈爆炸性增长的背景下,文本情感分析技术已经得到了蓬勃发展。
文本情感分类的算法主要有两种,第一种是基于情感词典的分类算法,在进行文本分类时,根据词典设计一定规则组合来完成对句子情感极性的判断。Ohana和Tierney提出将SentiWordNet词典应用于电影评论的情感分类,通过对正负情感词得分计数来确定情感倾向[1]。Qiu等根据语法和共现模式提取了语料库的意见词汇,并基于此对产品评论信息进行情感分类[2]。明均仁研究并设计了一种融合语义关联挖掘的文本情感分析算法,实现语义层面的情感分析与用户情感知识挖掘[3]。在领域情感词典构建方面,钟敏娟等构建了音乐领域情感词典[4]。唐晓波和兰玉婷构建了手机评论的领域情感词典以及微博表情符号词典[5]。郁圣卫等构建了电商领域的情感词典[6]。姚加权等通过词典重组和深度学习算法构建了适用于正式文本与非正式文本的金融领域中文情绪词典,并基于词典构建了上市公司的年报语调和社交媒体情绪指标[7]。第二种是基于机器学习的分类算法,即通过对已经标注好的训练文本进行分类学习,使其能够应用于新文本分类预测的一种有监督学习算法。Pang等首次将SVM和贝叶斯分类应用到情感分析中[8]。Zhang等提出了一种门控循环神经网络,能够考虑上下文之间的交互关系,从而使得文本分类效果得到显著提升[9]。王刚等通过对经典情感分析数据集进行试验,提出了一种比其他半监督学习方法效果都好的改进方法[10]。
在投资者情绪对于股票市场影响研究方面,Corredor等研究发现投资者情感对股票市场影响显著[11]。Porshnev等提取股评情感利用神经网络与遗传算法对道琼斯工业指数进行了预测[12]。陈晓红等考察了投资者情绪与股票市场指数的相关性及预测能力,结果表明情绪指数对股票价格有预测作用[13]。张宁等研究发现基于文本挖掘构建的BSI指标与上证综指的价格和收益显著相关[14]。赵明清和武圣强结合百度指数构建了基于微博情感分析的股市加权预测模型,结果表明微博情感综合倾向与股票价格变化情形几乎一致且预测准确率较高[15]。程萧潇通过VAR模型探讨新闻热度、新闻情感和社交媒体热度对股指收益率的效应及影响机制,研究新闻情感和社交媒体热度对股指收益率产生显著影响,而新闻热度却对股指收益率不产生显著影响[16]。欧阳资生和李虹宣系统性梳理了国内外学者从理论和实证分析等方面对网络舆情对金融市场影响的研究[17]。黄创霞等使用情感分析技术,提出了一种改进的个体投资者情绪度量的情感倾向点互信息算法,运用格兰杰因果检验方法研究了个体投资者情绪与市场收益率和成交量的互动关系[18]。姜富伟等研究发现媒体文本情绪可以更准确地衡量中国股市投资者情绪的变化,对中国股票回报有显著的样本内和样本外预测能力[19]。
股票市场下行风险是指股价未来会发生下跌,并且下跌的程度会超出分析师或者投资者预期的风险。史永东和杨瑞杰选取2007—2016年中国A股上市公司股票为样本,研究了不同信息对股价下行风险的影响,构造股价下行风险度量指标——收益率分布的负偏度系数和收益率上升、下降阶段的波动率之比考察了过度自信和损失厌恶两种不同的投资者行为是否会影响信息与股价下行风险之间的关系[20]。Yamai和Yoshiba对风险测度指标VaR和ES的优缺点进行了全面的比较[21-24]。VaR和ES虽然各有优缺点,但是VaR测度被广泛使用且其回测方法较为成熟,而ES的回测方法并不成熟且不被公认。对于VaR的度量,Ergün和Jun研究发现基于GARCH和极值理论(EVT)的模型能够更好地预测标普500指数的VaR[25]。吕永健和王鹏基于包括GAST在内的多种分布建立原油市场下行风险预测模型,得出GAST分布计算的VaR测度最精确的结论[26]。
综上所述,越来越多的机器学习算法被应用到文本情感分类的领域中,但是考虑到该方法需要大量已经标注好的数据,所以本文选择了使用基于情感词典的无监督文本分类方法。虽然已经有很多学者研究股票评论的情感倾向和股票市场之间的关系,但是鲜有学者研究股票评论与股票市场下行风险之间的影响关系以及股票评论对股票市场下行风险的预测能力,同时鉴于VaR测度的回测方法较为成熟,本文以VaR来测度股市下行风险。和以往研究相比,本文利用文本情感分析技术充分挖掘东方财富网股吧评论数据,使用基于情感词典的无监督学习的文本分类方法构建了特定金融领域的情感词典和相应的投资者情绪指标,并探索性地研究了股市评论对股票市场下行风险的影响关系以及预测能力,具有较高的应用价值。
三、基于股评信息的投资者情绪指标构建
本文选取东方财富网股吧平台上证指数吧的评论数据,时间范围是2018年7月2日至2020年6月30日,共抓取917 911条数据,获取的评论信息包含每条评论的时间、内容以及阅读量,例如,发布时间:2020-03-09,评论内容:买了就跌,阅读量:201。上证指数吧较为活跃,平均每天有近2 000条评论,能够在一定程度上反映投资者的情感信息。
目前也已经有较多的学者使用东方财富网的股吧评论数据来研究其与股市的影响关系。部慧等基于东方财富网股吧评论提出融合股评看涨看跌预期和投资者关注程度的投资者情绪度量指标,探讨投资者情绪对中国股票市场的影响[27]。尹海员和吴兴颖挖掘东方财富网股吧评论,构建了投资者日度情绪指标并探讨其对股票流动性的影响[28]。
(一)金融领域词典构建
通用基础情感词典在对特定领域文本进行情感分类时存在不足,于是在通用情感词典的基础上构建了金融领域的情感词典。所构建的词典组成结构如图1所示。

图1 词典的组成结构
1.N-GRAM算法构造新词词典
文本分词效果对于自然语言处理非常重要,本文使用Python的jieba库进行分词,但是在处理特定领域文本时,因词库无法识别部分未登录词,便会对后续产生持续影响。本文采用N-GRAM算法进行新词发现,首先将字符组合分为1-k元组,同时考虑字符组合左右邻字丰富程度和内部凝聚度,构造了一个统计量来衡量一个字符组合成词的可能性大小:
score=AMI+L(W)
(1)
其中:
(2)
Entropy(w)=-∑wn∈WNeighborP(wn|w)log2P(wn|w)
(3)
(4)
LE、RE为候选词左右信息熵,W表示字符组合,sigma是一个非常小的非0正数,Entropy(w)为信息熵计算公式,WNeighbor为字符组合左/右邻字的集合,c1,c2,…,cn表示字符组合包含的所有单个字符。
根据该统计量来判断股评语料库中最有可能成词的字符组合,过滤jieba库分词词典包含的候选词,再通过人工判断,生成特定领域的新词分词词典,最终得到1 402个新词。
2.基础情感词典构建
本文将知网Hownet情感词典、台湾大学NTUSD简体中文情感词典和清华大学李军褒贬义词典进行合并去重,从而得到综合后的基础情感词典,包含27 169个词,其中积极情感词11 879个,消极情感词15 290个。
3.扩展基础情感词典
本文使用PMI算法对情感词典扩展来构建领域情感词典,该方法认为如果一个词语和带有情感倾向的词语相关性越大,那么该词语就越有可能带有相同的情感极性,这里用点互信息来代表词语之间的相关性。
点互信息(PMI)的计算公式如下:
(5)
其中,word1和word2表示两个词汇,P(word1&word2)表示两个词汇在股票评论文本中同时出现的概率,P(word1)表示word1在股票评论文本中出现的概率,P(word2)表示word2在股票评论文本中出现的概率。
为了提高词语极性判断的可靠性,需要选择一组积极情感种子词汇(Pwords)和一组消极情感种子词汇(Nwords)作为基准词,然后把积极情感种子词汇和消极情感种子词汇与词语之间的点间互信息之和进行作差,最后利用这个差值来衡量词语的情感倾向。计算公式如下:
SO-PMI(word)=∑Pword∈PwordsPMI(word,Pword)-∑Nword∈NwordsPMI(word,Nword)
(6)
其中,word为待判断词性的词汇,Pword是积极情感词,Nword是消极情感词。
最终扩展的情感词包含股票领域的情感词以及基础情感词典中没有涵盖的情感词共有1 058个,其中新增积极情感词有429个,新增消极情感词有629个。
4.辅助情感词典的构建
本文所使用的停用词词典是对哈尔滨工业大学停用词表、百度停用词表和四川大学机器智能实验室停用词库合并去重得到的,共有2 130个。在知网程度副词词典的基础上,本文又添加了一些自行整理的程度副词从而构建了程度副词词典,根据词语的程度分为6个级别,分别是最、很、较、稍、欠和超,个数分别为69、42、36、13、29和33。所使用的否定词典是本文自行整理的否定词,共87个。
(二)文本情感分类规则制定
一条股评包含多个分句,股评的情感应该由这些分句共同决定。股评文本情感倾向值计算的思路是:首先对股票评论文本分句,分别对每一个分句计算情感倾向值;然后将分句情感倾向分数进行简单平均,如果分数大于0说明股评的情感倾向是积极的,分数等于0说明股评的情感倾向是中性的,分数小于0说明股评的情感倾向是消极的。
对于分句的情感倾向计算,首先,依次搜索分句中的情感词,记录是积极情感词还是消极情感词,如果是积极情感词则对该词打分为1,如果是消极情感词则对该词打分为-1;其次,搜索当前情感词和前一个情感词之间的程度副词和否定词,计算并且判断否定词个数是奇数还是偶数,如果是奇数,当前情感词的分数乘以-1,反之不变化,如果存在程度副词,则根据程度副词的级别对情感词得分进行加权;最后,将该分句所出现的所有情感词的分数进行求和并作为该分句的情感倾向分数。
(三)情感指标构建
股评信息主要反映投资者对股票市场的关注度和对股票市场的情感倾向,因此本文构建了关注度指标、情感倾向指标以及关注度和情感倾向相结合的指标。
关注度指标反映的是投资者对于股票市场的参与热情,具体指标为每日每条评论的平均阅读量。
投资者的情感倾向指标反映的是投资者对于股票后续涨跌的预期,具体指标分别是每日正向评论比例、每日负向评论比例、每日中性评论比例以及投资者一致性指数,其中投资者一致性指数的计算公式是:
(7)
其中,xi是第i天的投资者分歧指数,Npi是第i天积极情感倾向评论的个数,Nni是第i天消极情感倾向评论的个数。
关注度和情感倾向相结合的指标反映了投资者情感预期传播程度,具体指标分别是每日正向评论阅读量的比例、每日中性评论阅读量的比例、每日负向评论阅读量的比例。
四、基于投资者情绪的股票市场下行风险分析与预测
(一)股票市场下行风险的测度
1.股票交易数据的选取与处理
本文选择上证指数来综合反映股市的价格变动,并且从CSMAR数据库下载了2018年7月2日至2020年6月30日的交易数据,数据量为485个。
上证指数的日收益率的计算公式如下:
(8)
其中,P_closet表示第t日的收盘价,P_opent表示第t日的开盘价。
2.建立ARMA-GARCH模型
对上证指数收益率建立ARMA-GARCH模型,通过选取不同的阶数反复建模,综合考虑AIC、BIC和SIC原则,最终确定的模型是ARMA(4,5)-GARCH(1,1)模型。其中,mu是ARMA模型的常数项,ar1~ar4是AR模型的变量,ma1~ma5是MA模型的变量,omega、alpha和beta1是GARCH模型的变量,r为ARMA-GARCH模型的标准化残差。
根据表1可知,本文构建的ARMA-GARCH模型除omega以外的参数都是显著的,标准化残差序列及其平方进行Ljung-Box检验,在阶数分别为10、15和20时,得到的P值均远大于显著性水平0.05,则可以认为模型的标准化残差序列及其平方均无自相关,说明本文构建的均值方程以及方差方程是充分的。
拟合的ARMA(4,5)-GARCH(1,1)模型为:
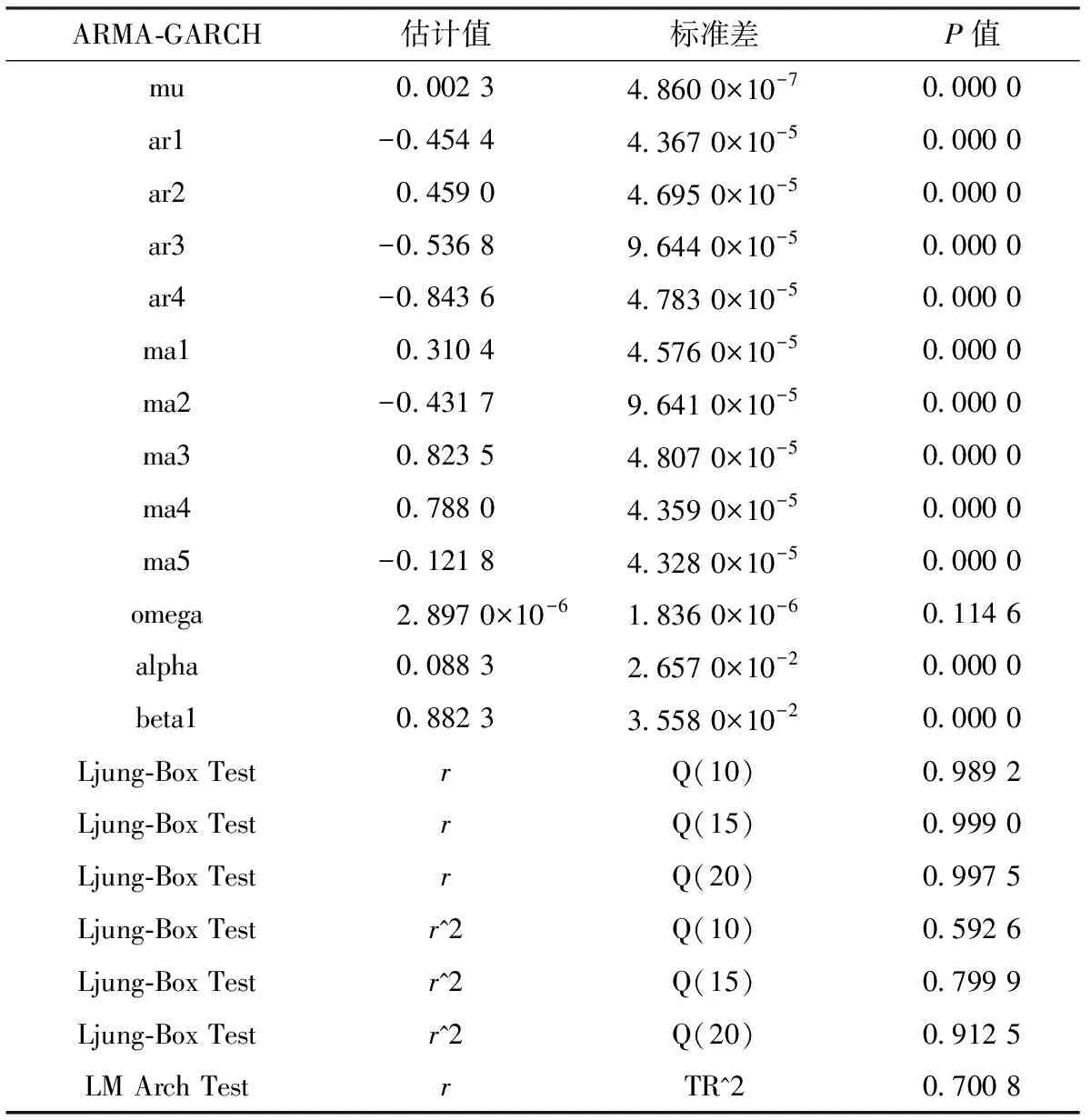
表1 上证指数收益率ARMA(4,5)-GARCH(1,1)模型估计及诊断结果
rt=0.002 3-0.454 4rt-1+0.459 0rt-2-0.536 8rt-3-0.843 6rt-4+0.314 0at-1-0.431 7at-2+
0.823 5at-3+0.788 0at-4-0.121 8at-5
(9)
at=σtεt
(10)
(11)
其中,假设εt服从标准正态分布。
3.VaR的计算与回测检验
根据上证指数收益率拟合的均值方程和方差方程,把均值方程和方差方程t时刻的拟合值,分别作为t时刻收益率假定分布的均值和标准差,然后利用VaR的计算公式,分别计算出在99%、95%、90%的显著性水平下上证指数收益率各个时刻VaR。

表2 样本内数据回测检验结果
下面对拟合出来的VaR进行Kupiec检验,结果见表2。由表2可知,拟合出来的VaR在99%、95%和90%的置信水平下,检验统计量的P值都大于显著性水平5%,则应该认为建立的模型是有效的。
(二)投资者情绪对股票市场下行风险的影响分析
1.平稳性检验
表3是本文所构建的投资者情绪指标体系。
本文在使用VAR模型检验变量之间的相互影响关系之前,需要检验每一个投资者情绪指标和股票市场下行风险(本章节以95%置信水平的VaR为例)的平稳性,各变量的ADF平稳性检验结果如表4。根据表4结果可知,在5%的显著性水平下,投资者情绪指标体系和95%置信水平下的VaR都是平稳的时间序列,说明可以对这些变量进行格兰杰因果检验。

表3 投资者情绪指标体系

表4 变量的平稳性检验结果
2.格兰杰因果检验
本文分别构建了每一个投资者情绪指标与上证综合指数95%置信水平VaR的VAR模型来研究其与上证指数95%置信水平VaR的影响关系。VAR模型滞后阶数的选择综合考虑了AIC、HQ、SC、FPE这4项评判标准,然后确定大小适中的滞后阶数,这样既可以体现模型的动态特征也不会导致模型的自由度过小。为了确定变量之间的因果关系,对构建的每一个模型进行了格兰杰因果检验,表5是格兰杰因果检验的结果。
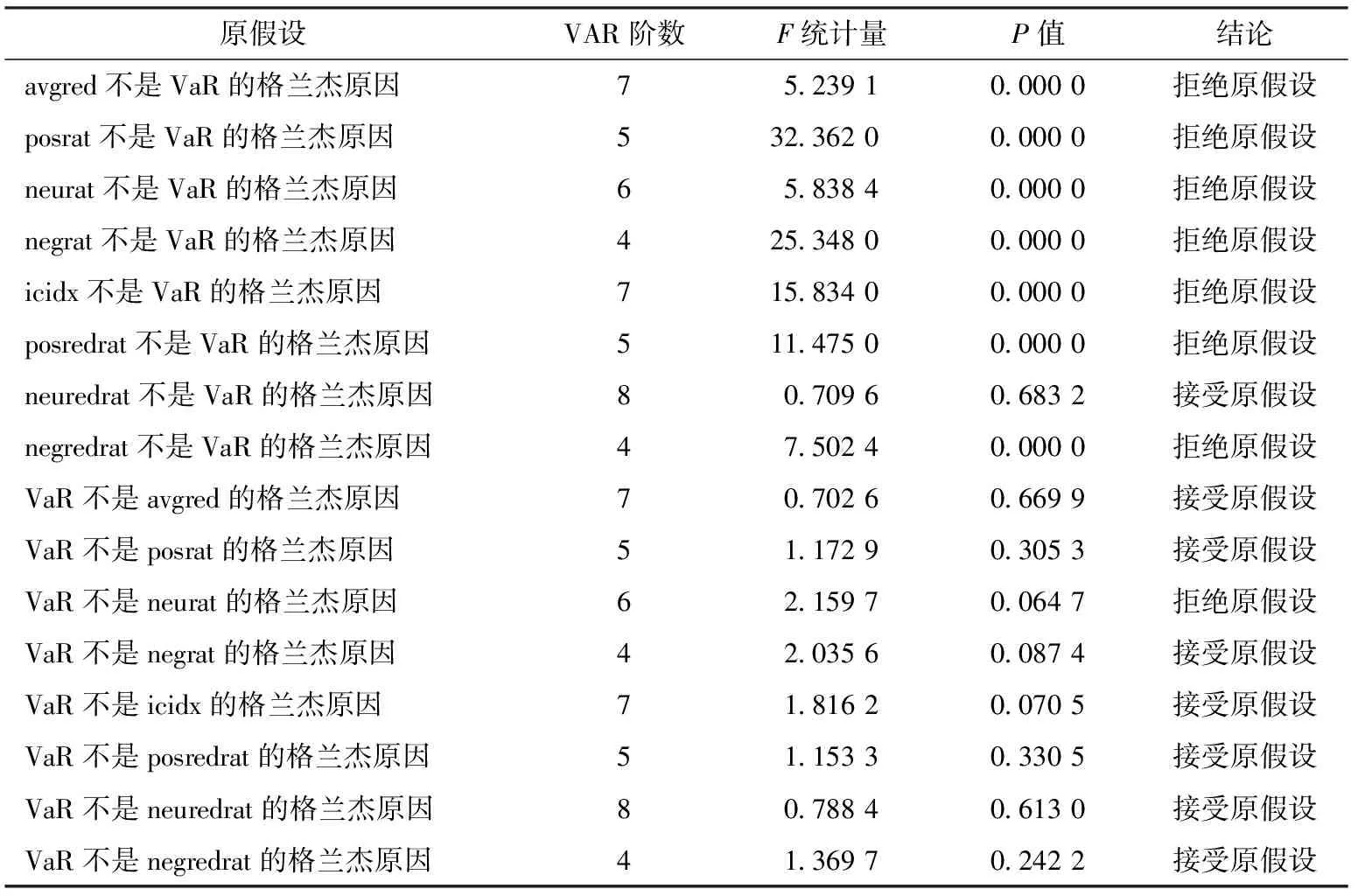
表5 投资者情绪特征对VaR的格兰杰因果关系检验结果
根据表5可知,在5%的显著性水平下,除了neuredrat(每日中性评论阅读量的比例)以外的所有投资者情绪指标都是上证指数VaR的格兰杰原因,但是反之均不成立。
3.VAR模型诊断
根据格兰杰因果检验的结果可知,除了neuredrat(每日中性评论阅读量的比例)以外的所有投资者情绪指标和股票市场的下行风险之间存在单向因果关系,接下来对每一个VAR模型进行了回归方程的显著性检验,并且对模型进行了系统平稳性检验。模型回归结果如表6、7和8所示。
根据回归方程显著性检验结果可知,本文所构建的VAR模型涉及的回归方程的显著性检验P值都小于0.01,说明在1%的显著性水平下,回归方程是显著的。

表6 VAR模型的估计及检验结果一
模型系统稳定性检验的结果见图2,该图形的横轴是时间,纵轴是残差累计和,如果残差累计和超出图中的两条临界线,说明系统是不稳定的。根据上述检验结果可知,模型都是系统稳定的。
对于投资者情绪指标对股票市场下行风险的影响关系,avgred(每日每条评论的平均阅读量)反映的是投资者对于股市的关注程度,关注程度增高,很有可能导致市场波动加剧,从而会导致下行风险增加,posrat(每日正向评论比例)和negrat(每日负性评论比例)代表了广大投资者对于股市行情的涨跌预期,posrat和negrat的增多可能会加剧股市行情的变化,从而导致下行风险的增加,neurat(每日中性评论比例)反映的是广大投资者对于股票市场行情的看平预期,icidx(投资者一致性指数)反映的是广大投资者对于股市行情涨跌预期的平衡程度,neurat和icidx的增加反映到市场上可能会导致股票市场行情的波动更小,从而导致下行风险的下降,posredrat(每日正向评论阅读量的比例)和negredrat(每日负向评论阅读量的比例)反映的是投资者看涨看跌预期的情感传播程度,由于情绪的传染性可能会出现posredrat和negredrat的增加导致股市行情的波动增加及股市的下行风险增加。

表7 VAR模型的估计及检验结果二
4.脉冲响应分析
图3是所建立的每一个模型的脉冲响应函数图,可以看出avgred(每日每条评论的平均阅读量)的冲击对于VaR的影响整体是正向的,这种影响在第一期的时候影响最大,后续波动几期之后开始逐渐收敛;posrat(每日正向评论比例)的冲击对VaR的影响整体上是正向的;neurat(每日中性评论比例)的冲击对于VaR的影响是负向的,这种影响在第2期的时候影响达到最大,持续7期左右,影响开始逐渐消失;negrat(每日负向评论比例)的冲击对于VaR的影响是正向的,这种影响在第4期达到最大,之后随着时间的推移影响逐渐减小,最终收敛为0;icidx(投资者一致性指数)的冲击对于VaR的影响整体上是负向的;posredrat(每日正向评论阅读量的比例)的冲击对于VaR的影响整体上是正向的,这种影响在第2期达到最大,之后持续几期之后逐渐收敛为0;negredrat(每日负向评论阅读量的比例)的冲击对于VaR的影响是正向的,这种影响在第3期达到最大,之后逐渐减弱,最终收敛为0。总体来看投资者情绪指标对于股票市场下行风险的影响具有滞后效应,持续时间大概在两周左右,并且脉冲响应图反映的影响关系符合预期。

表8 VAR模型的估计及检验结果三
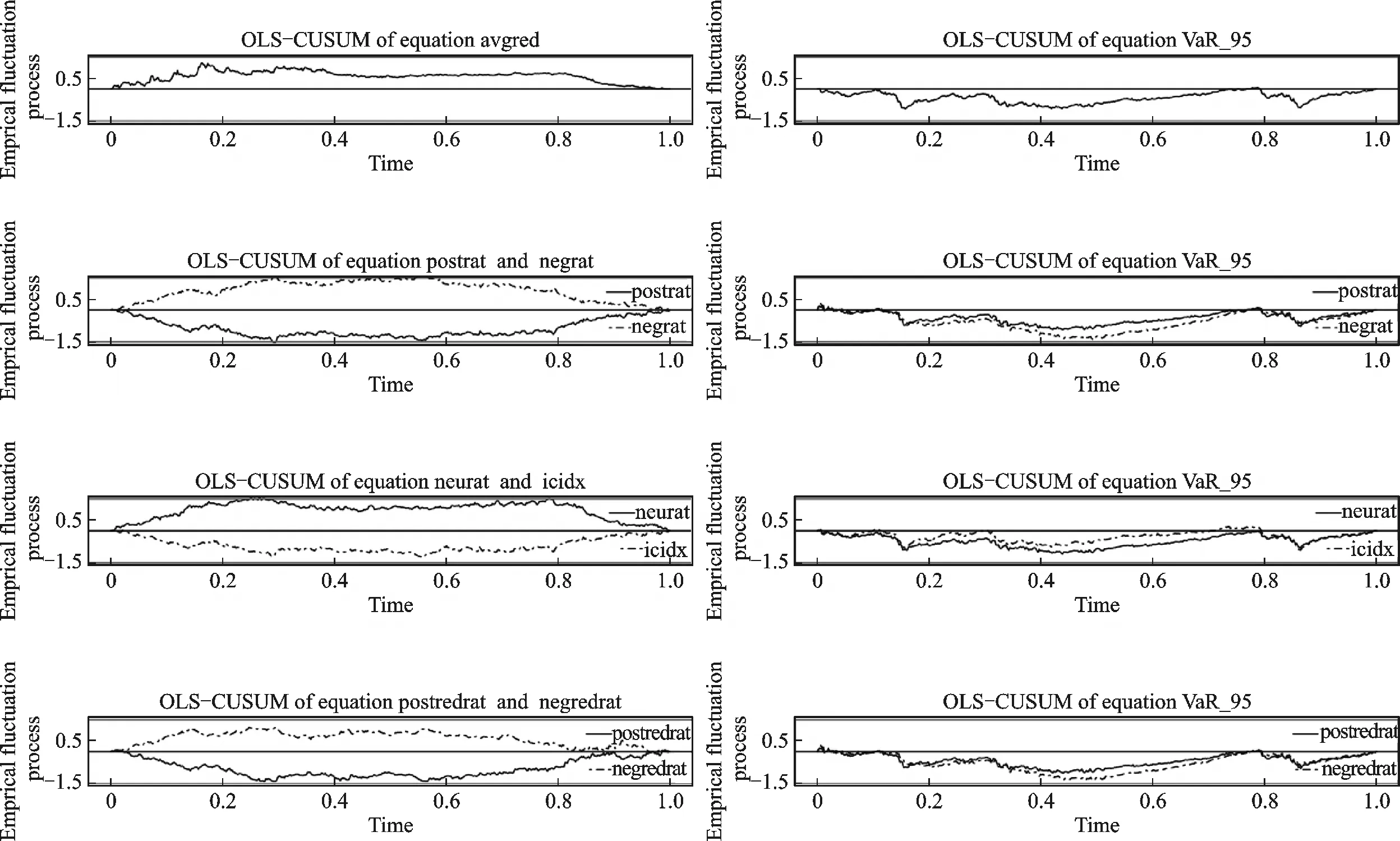
图2 系统稳定性检验

图3 脉冲响应图
(三)基于投资者情绪预测下行风险
上述研究结果表明,本文基于东方财富网构建的情绪指标对于股票市场的下行风险是有影响的,接下来进一步研究投资者情绪指标对股票市场下行风险的预测能力。
1.预测的实证分析
因为VaR的真实数值是不可知的,但是能够获得VaR的拟合值,所以利用机器学习模型基于投资者情绪指标对样本期内拟合的VaR进行训练,预测样本期外的VaR,并使用VaR的评估指标来评估模型预测效果。
比较不同模型VaR的预测效果,分位数损失(QL)是最常见的选择之一[29]。给定置信水平为1-α的分位数损失定义为:
QLt+1(α)=(α-dt(α))(yt-VaRt(α))
(12)
其中,dt(α)=1(yt-VaRt(α)),VaRt(α)表示置信水平为1-α的样本期外第t期的VaR预测值。
对于A、B两个模型之间的比较,如果QLA/QLB<1,则模型A优于模型B,反之亦然。
为了评估投资者情绪指标对于股票市场下行风险VaR的预测能力,本文需要将上证指数收益率数据划分为样本期内数据和样本期外数据,为了更好地体现样本期外预测效果的差异,本文选择的样本期外数据约占总数据的1/4,划分的样本内数据的时间范围为2018年7月2日至2019年12月26日共365个数据,样本期外数据的时间范围为2019年12月27日至2020年6月30日共120个数据。
由于VaR不是真实发生的,只有拟合值,所以在研究投资者情绪对上证指数VaR的预测能力时,不能直接使用全样本数据拟合的VaR作为因变量,并对其划分样本期内和样本期外数据,然后利用投资者情绪、收益率以及VaR的滞后项去预测VaR。如此设计,预测时便利用了未来数据的信息,即VaR的滞后项也是由全样本数据拟合得到的,会导致结果不够严谨。
因此,本文使用固定窗口为365来滚动拟合VaR,每次获得365个VaR拟合值,接着训练一个机器学习模型,并且去预测下一个时刻的VaR,这样可以依次获得120组长度为365的VaR拟合值,同时可以依次获得120个VaR预测值。最后比较实验组和对照组的预测效果,就可以判断投资者情绪指标对于VaR的预测能力。
本文使用了LightGBM模型,对95%置信水平下的VaR进行预测,具体步骤如下:
第一步:实验组和对照组的设定
实验组的模型输入特征包括除neuredrat以外的所有投资者情绪指标的滞后项(1~3阶)以及上证指数收益率和下行风险的滞后项(1~3阶),对照组的模型输入特征只使用收益率和下行风险的滞后项(1~3阶),目的是通过比较两组的预测效果来验证投资者情绪对于下行风险VaR的预测能力。
第二步:进行特征选择和模型参数的设定
在滚动拟合并且利用机器学习模型进行预测时,由于模型的预测值没有可供参考的真实值,所以没有办法进行特征筛选和模型参数调整,于是本文先对全样本拟合出来的VaR划分训练数据集和测试数据集,从而训练LightGBM模型并选择模型最优参数以及进行特征筛选。最终,对照组选择的特征是收益率和下行风险的滞后项(1~3阶)共6个特征,实验组选择的特征是特征重要程度前15个特征,包括收益率和下行风险的滞后项(1~3阶)这6个特征以及投资者情绪的9个特征。
第三步:滚动窗口拟合VaR
使用ARMA-GARCH模型对上证指数的收益率进行滚动窗口拟合,由于样本外的数据设置的是120个,所以共进行了120次的拟合,每一次模型拟合相应地计算出拟合的VaR值,共获得长度为365的VaR拟合值120组。
第四步:机器学习模型预测
基于前一步拟合出来的每一组VaR的值,构建实验组和对照组的输入特征,对每一组数据训练一个LightGBM模型,并且对下一个时刻的VaR进行预测。最终训练了120个LightGBM模型,并且分别获得了实验组和对照组样本外的120个VaR预测值。
第五步:实验组和对照组的效果比较
对于获得的120个VaR预测值,使用分位数损失的比例来评估两个模型的优劣,从而判断投资者情绪对于VaR的预测能力。

表9 VaR预测效果检验和比较
检验结果表明,实验组和对照组检验统计量的P值都大于0.05,说明在5%显著水平下,VaR的预测是有效的。实验组的分位数损失和对照组的分位数损失的比值小于1,说明实验组对于VaR的预测效果更好一些,也即是说明投资者情绪对于VaR是有预测能力的,为了进一步验证结论的稳健性,下面进行了稳健性分析。
2.稳健性分析
从三个角度来验证预测效果的稳健性,第一个角度是使用LightGBM模型对不同置信水平下的VaR进行预测,置信水平的选择分别是99%、95%和90%;第二个角度是使用不同的模型进行预测,本文除了使用LightGBM模型外,又使用了Random Forest模型进行预测;第三个角度是在使用ARMA-GARCH模型对上证指数收益率进行滚动建模时,又引入了扩展窗口滚动拟合,即以递归的方式用新的观测值来增加采样周期,例如第一次拟合的数据范围是1-d,第二次拟合的数据范围是1-d+1。预测出来的VaR的检验和比较结果如表10所示:
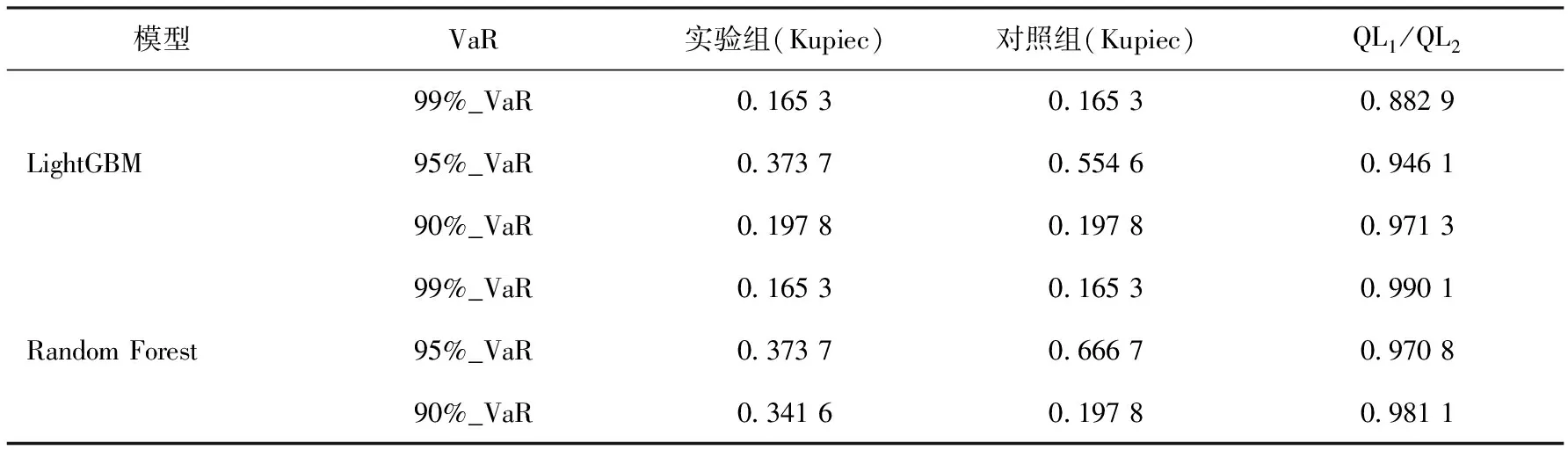
表10 基于滚动窗口拟合值的预测效果检验和比较
上述检验和比较结果表明,基于滚动窗口拟合值和基于扩展窗口拟合值的预测结论一样的,在使用LightGBM模型和Random Forest模型进行预测时,无论是实验组和对照组Kupiec检验的P值都大于0.05,说明在5%的显著性水平下,都不能够拒绝原假设,应该认为预测模型都是有效的,然后可以看出分位数损失的比值都小于1,说明实验组的预测效果好于对照组的效果。这也说明投资者情感指标对于上证指数的VaR是有预测能力的,且预测能力是稳健的。

表11 基于扩展窗口拟合值的预测效果检验和比较
五、结 论
本文选取2018年7月到2020年6月上证指数股评数据作为原始文本数据,采用基于情感词典的方法来挖掘股评的情感倾向信息,并且构建了较为完善的投资者情绪指标,利用VAR模型研究投资者情绪指标对于上证指数下行风险的影响,并且使用机器学习模型实证考察了投资者情绪指标对于上证指数下行风险的预测能力。研究发现:第一,基于情感词典的文本分类方法,不仅将现有的各种较权威的词典进行合并去重,而且还对新词词典和领域词典进行了扩展,构建了更加完善合理的金融领域词典,实现了比只使用通用词典进行文本情感分类更好的分类效果。第二,脉冲响应的结果表明,投资者情绪指标在短期内对股票市场下行风险有持续性的作用,其中每日每条评论的平均阅读量、每日正向评论比例、每日负向评论比例、每日正向评论阅读量的比例以及每日负向评论阅读量的比例的冲击整体上对于下行风险的影响是正向的,每日中性评论比例和投资者一致性指数的冲击整体上对于下行风险的影响是负向的。第三,股票评论信息对于股票市场的下行风险具有一定的预测能力。通过使用LightGBM模型和Random Forest模型对股票市场的下行风险进行预测,结果表明,相对于只使用下行风险和收益率的滞后数据,加入投资者情绪指标在样本期外能更好地预测股票市场的下行风险。本文的研究结论支持了金融监管机构通过加强网络舆论的监管来维持中国金融市场的稳定发展,从而能够在一定程度上防范金融市场异常波动以及金融危机的发生。
