基于区域互补注意力和多维注意力的轻量级图像超分辨率网络
2022-08-15周登文王婉君高丹丹
周登文 王婉君 马 钰 高丹丹
单图像超分辨率 (Single Image Super-Resolu- tion, SISR)[1]是一个基本的低级计算机视觉问题,旨在由一个给定的低分辨率 (Low-Resolution, LR)图像生成对应的高分辨率 (High-Resolution, HR)图像.SISR在医学成像[2]、物体识别[3]、视频监控[4]和遥感成像[5]等领域都具有广泛应用.SISR是一个病态的逆问题,因为许多HR图像可退化为相同的LR图像,重建的超分辨率(Super-Resolution, SR)图像往往会出现模糊、纹理细节丢失和失真等问题.
早期SISR的研究[6-7]主要是基于插值的方法,如双线性插值和双三次插值.基于插值的方法现仍广泛使用,其优势是简单、计算复杂度很低,但是不能恢复LR图像中丢失的图像细节.基于稀疏字典学习的方法[8-10]改进基于插值的方法,旨在通过训练图像,学习LR图像和HR图像之间的映射函数.但是基于稀疏字典学习的方法往往优化困难,同时具有较高的推理复杂度.卷积神经网络(Convolu-tional Neural Networks, CNN)[11-16]直接端到端地学习LR图像和HR图像之间的映射函数,已主导当前SISR技术的研究.但是基于CNN的SISR方法严重依赖于网络规模,即网络中参数量、深度(层数)和宽度(通道数)等.
为了提升SISR的性能,往往需要规模更大的网络.Lim等[17]提出EDSR(Enhanced Deep SR Network),有65个卷积层,参数量为43 M.Zhang等[18]提出RCAN(Very Deep Residual Channel Attention Net-works),卷积层数超过800,参数量为16 M.
EDSR和RCAN虽然在性能上有显著提升,但是需要较高的计算和存储能力,难以在资源受限的设备(如手机)上应用.设计轻量级SISR网络(计算和存储需求较低)是当前SISR方法研究的热点,但面临在CNN复杂度和性能之间如何建立更好平衡的挑战.
设计轻量级SISR网络的一个选择是使用递归结构[19-24],卷积层(或块)之间参数共享,在增加网络深度时参数量不变,但依旧会增加计算量.特征蒸馏网络是一个更有效的轻量级网络架构设计方案[25-26].Hui等[25]提出IMDN(Lightweight Information Multi-distillation Network),构造IMDB(Information Multi-distillation Blocks),包含蒸馏和选择性融合2部分.IMDN采用通道分裂和分层的特征蒸馏,IMDB根据特征的重要性进行融合.Liu等[26]提出RFDN(Residual Feature Distillation Network),改进IMDB的通道分裂和特征蒸馏,更轻量、有效,获得AIM 2020[27]高效SR挑战赛第1名.学者们也提出其它的轻量级SR网络架构[28-31].Li等[28]提出LAPAR(Linearly-Assembled Pixel-Adaptive Regression Net-work),将LR图像到HR图像的映射学习转换为多个预定义滤波器库字典上的线性系数回归任务.Zhao等[29]使用自校准卷积作为基本的网络构件,提出PAN(Pixel Attention Networks).Chen等[30]提出A2N (Attention in Attention Network),由非注意力分支与耦合注意力分支构成,并为2个分支生成动态注意力权重.李金新等[31]提出基于多层次特征的轻量级单图像超分辨率网络.Li等[32]提出MSRN(Multi-scale Residual Network),基本构件是MSRB(Multi-scale Residual Block),可提取与融合不同尺度的特征.MSRB是有效的,但是不够轻量.
基于上述情况,本文提出基于区域互补注意力和多维注意力的轻量级图像超分辨率网络(Lightweight Image Super-Resolution Network Based on Regional Complementary Attention and Multi-dimen-sional Attention, RCA-MDA).首先提出通道重组聚合卷积单元(Channel Shuffle Aggregation Convolution Unit, CSAConv)和多交互残差块(Multiple Interactive Residual Block, MIRB),CSAConv使MIRB较轻量,可有效融合多尺度特征.为了提高特征利用率和表达能力,提出区域互补注意力块(Region Comple-mentary Attention Block, RCAB)和多上下文信息融合块(Multi-context Information Fusion Block, MI-FB),可使图像不同区域的信息得到互补,有效提取和融合局部与非局部的多尺度特征.同时设计多维注意力块(Multi-dimensional Attention Block, MD-AB),可同时逐像素地关注特征通道维和空间维的相关性,更有效利用特征信息.实验表明本文网络性能较优,并将当前轻量级超分辨率网络的复杂度和性能平衡提升到一个较高水平.
1 基于区域互补注意力和多维注意力的轻量级图像超分辨率网络
本文提出基于区域互补注意力和多维注意力的轻量级图像超分辨率网络(RCA-MDA),网络架构如图1所示.
RCA-MDA主要包括4部分:浅层特征提取块(Shallow Feature Extraction Block, SFEB)、非线性特征映射块(Non-linear Feature Mapping Block, NFMB)、全局特征融合块(Global Feature Fusion Block, GFFB)和上采样块(Upsampler).SFEB仅包括1个3×3卷积层和1个渗漏修正线性单元(Leaky Rectified Linear Unit, LReLU)[33].Upsampler使用亚像素卷积[34].NFMB级联N(本文中N=3)个多上下文信息融合块(MIFB).GFFB主要由多尺度的通道重组聚合卷积单元(CSAConv)和多维注意力块(MDAB)组成.
给定输入的LR图像ILR,首先输入到SFEB,得到浅层特征:
F0=LReLU(C3×3(ILR)),
其中,C3×3(·)表示3×3的卷积函数,LReLU(·)表示LReLU激活函数.
F0再输入到NFMB中N个级联的MIFB块,提取多层深度上下文特征:
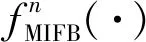
Ffusion=fGFFB(F1,F2,…,FN),
其中fGFFB(·)表示全局特征融合的函数.Ffusion和ILR同时输入Upsampler块,获得目标SR图像:
ISR=fup(Ffusion)+fup(C3×3(ILR)),
其中,fup(·)表示亚像素卷积上采样[35],C3×3(·)表示3×3的卷积函数,ISR表示输入的SR图像.
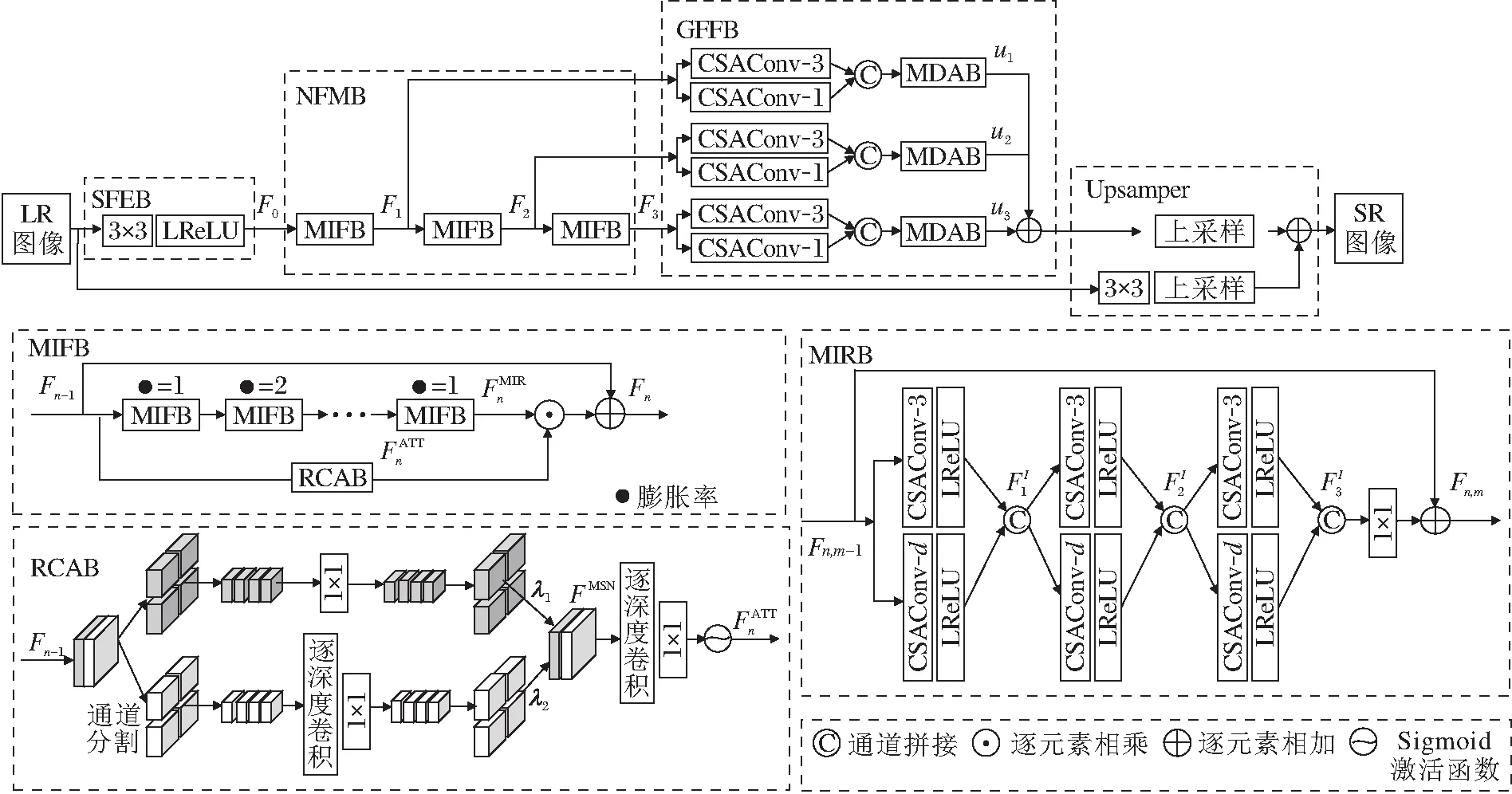
图1 RCA-MDA网络架构
1.1 通道重组聚合卷积单元
Zhang等[36]为移动设备设计计算效率较高的CNN架构,称为ShuffleNet,基本构件是ShuffleNet单元,结构如图2(a)所示.由于引入逐点的分组卷积,大幅降低计算代价,但ShuffleNet是为物体分类和检测等高级视觉任务设计的,包含批规范化(Batch Normalization, BN)层[37].BN层对低级视觉任务——图像超分辨率是有害的[17].CSAConv结构如图2(b)所示,去掉ShuffleNet单元中的BN层,也去掉ShuffleNet单元中的残差连接和修正的线性单元(Rectified Linear Unit, ReLU)[38].另外,考虑到分组卷积,不同组的通道之间无交互,会降低特征的表达能力,因此使用1×1卷积代替Shuffle-
Net单元中最后的逐点分组卷积(Group Convolution, GConv).CSAConv是一个结构更简单、适用于SISR的基本网络构件.实验表明:相比使用逐点的分组卷积,使用1×1卷积时,模型复杂度和性能之间具有更好的平衡.
CSAConv作为基本的计算单元,替代常规的卷积,可显著减少参数量和计算量.假定输出通道数均为C,特征图大小为H×W,核大小为k×k的卷积的参数量为k2C2,计算量为k2C2HW.对于核大小为k×k的CSAConv,假定分组卷积的组数为g,参数量为
计算量为
在本文的设置中,C=48,k=3,g=3,若设H=W=64,常规卷积的参数量和计算量都大约是CSAConv的6倍.CSAConv-1表示去掉图2(b)中逐深度卷积(Depthwise Convolution, DWConv).CSAConv-3表示CSAConv中的DWConv,使用核大小为3×3的标准卷积.CSAConv-d表示CSAConv中的DWConv,使用核大小为3×3、扩张率为d的扩张卷积.
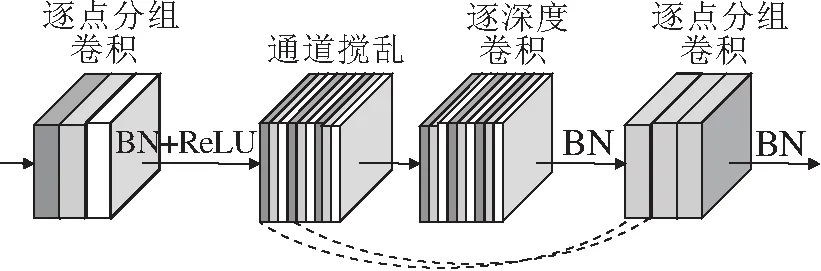
(a)ShuffleNet单元[36]
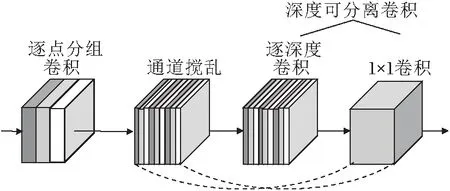
(b)CSAConv
1.2 多上下文信息融合块
如图1所示,MIFB主要包括3条分支,从上到下分别为:分支1、分支2、分支3.分支1只是一个简单的残差连接.分支2包含M(本文中,M=6)个级联的MIRB.分支3为1个RCAB.
MIRB中的扩张卷积有不同的扩张率.例如,6个级联的MIRB中的扩张率分别为1、2、3、3、2、1,以捕获不同尺度的上下文特征.RCAB使图像不同区域的信息互相补充,在不同大小的感受野范围融合互补信息.基于MIRB和RCAB,MIFB可充分融合多尺度、局部和非局部的多上下文特征信息,有效利用LR图像的自相似性.第n个MIFB支路2的输出特征可表示为
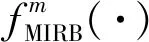
其中fRCAB(·)表示RCAB函数.第n个MIFB的输出特征可表示为
其中⊙表示逐元素相乘.
1.2.1 多交互残差块
Li等[32]提出MSRB,使用3×3和5×5的卷积核,捕获多尺度特征信息,并进行跨尺度的交互.不过MSRB每个支路只有2个卷积层.实验显示: 增加卷积层数和跨尺度交互次数,可更充分地利用特征信息,提高特征的表达能力.另外,MSRB使用的3×3和5×5的卷积,不够轻量、灵活.本文提出的MIRB与MSRB结构类似,参见图1.重要改进如下:1)把MSRB中的3×3卷积替换为CSAConv-3,5×5的卷积替换为CSAConv-d,可大幅减少参数量和计算量;2)进行更多次数的多尺度特征交互,改进性能(为了平衡性能与参数量和计算量,文中进行3次多尺度特征交互).值得注意的是,MIRB比MSRB更灵活,通过调整CSAConv-d中DWConv的扩张率,可较容易获得更多不同尺度的特征信息.假定第n个MIFB块中第m个MIRB的第1次多尺度特征交互的输出为(忽略LReLU非线性激活)
(1)
其中,fCUS3×3(·)表示MIRB上支路的第1个CSAConv-
3函数,fCUD3×3(·)表示MIRB下支路的第1个CSAConv-d函数,[·]表示特征通道拼接,Fn,m-1表示第n个MIFB中第m-1个MIRB的输出,即第n个MIFB中第m个MIRB的输入.
其中C1×1(·)表示1×1的卷积函数.
1.2.2 区域互补注意力块
Zhang等[39]提出分割拼接块(Cutting-Splicing Block, CSB),首先把特征图分割成n×n的单元,然后把它们在通道维进行拼接,再利用3×3的卷积提取局部和非局部的空间信息.受Zhang等[39]的启发,为了使网络学习到图像本身的自相似性,本文提出更轻量的RCAB,使图像不同区域的特征信息可互相补充.
RCAB的结构如图1所示.输入特征在通道维划分成相等的两部分,在2个支路上进行如下处理.
1)在特征空间维度分别分割成大小相等的4块,并在通道维进行拼接.
2)对拼接后的特征:一个支路使用1×1卷积,学习4个像素点位置和通道的依赖性;另一个支路使用3×3的逐深度卷积和1×1逐点卷积(即深度可分离卷积),学习4个非局部区域间特征的依赖性,即令图像不同区域的特征信息互相补充.
3)2个支路的特征自适应地拼接,还原成输入时的形状,自适应参数随网络模型端到端地学习.
4)通过一个3×3逐深度卷积和一个1×1逐点卷积,进一步融合特征,并使用Sigmoid函数,获得注意力权重.
RCAB包含两条支路,假定RCAB使用单分支,输入通道数为C,卷积核大小为k×k,仅用1×1卷积进行区域间信息融合,参数量为C2+k2C+C2.双分支RCAB如图1所示,参数量为
若C=48,k=3,参数量大约减少30%.
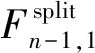
其中,fCUT(·)表示特征空间维分割和特征通道拼接函数,fICUT(·)表示fCUT(·)的逆函数,DWC3×3(·)表示3×3的逐深度卷积函数,λ1、λ2表示可学习的参数,FRC表示两个支路的输出特征.
第n个MIFB的注意力块RCAB的权重可计算为
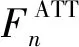
1.3 全局特征融合块
非线性特征映射块(NFMB)中每个MIFB块的输出特征输入到GFFB块进行分层的全局特征信息融合.GFFB有N个主支路(对应N个层的特征),每个主支路处理一个层的特征(即对应MIFB块的输出),如图1所示.每个MIFB块的输出分别通过一个主支路中CSAConv-1和CSAConv-3,然后进行通道拼接,再输入MDAB.N个主分支的输出分别乘以一个可学习的自适应参数,再求和,作为GFFB块的输出.这个过程可表示为
其中,fCUS1×1(·)表示CSAConv-1函数,fCUS3×3(·)表示CSAConv-3函数,[·]表示特征通道拼接,fMDAB(·)表示MDAB块函数,μn表示可学习的参数,Fn表示第n个MIFB的输出,Ffusion表示GFFB的输出.
当前,在SISR中,常见的注意力机制是通道注意力[40]和空间注意力[41].假定特征图的大小为C×H×W(C为特征的通道数,H、W为特征的高、宽),通道注意力计算1个一维向量(C×1×1),建模通道之间的依赖关系.空间注意力计算1个二维的矩阵(1×H×W),建模空间位置之间的依赖关系.
Zhang等[39]提出一阶三元组注意力,类似于通道注意力,它在特征的通道、行和列三个方向建模跨维度之间的依赖关系.Zhao等[29]提出像素注意力(Pixel Attention, PA),使用1×1的卷积和Sigmoid函数,计算一个三维逐像素的矩阵(C×H×W).MDAB结构如图3所示,与PA类似,也是计算一个三维逐像素的矩阵(C×H×W).但是它们有如下区别:1)1×1的卷积替换为CSAConv-3,Sigmoid函数替换为Softmax函数.2)为了更好地建模特征通道维和空间维的依赖关系,分别在通道维和空间维学习特征像素之间的依赖关系.MDAB包含1个CSA-Conv和2个1×1卷积,假定输入通道数为48,MDAB的参数量仅约为8.1 K.
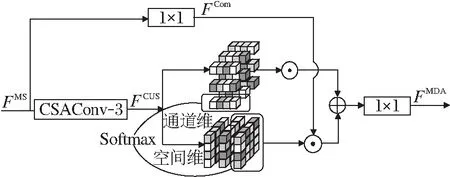
图3 MDAB结构图
假定MDAB的输入特征为FMS,分别经过一个1×1卷积和CSAConv-3.CSAConv的输出分别在通道维和空间维执行Softmax函数,获得2个像素级的注意力权重.1×1卷积的输出被这2个注意力权重加权,并求和,再通过一个1×1卷积进行信息融合.
FMS通过1×1卷积后的输出特征为
FCom=C1×1(FMS).
FMS通过CSAConv-3后的输出特征可表示为
FCUS=fCUS3×3(FMS),
其中fCUS3×3(·)表示CSAConv-3函数.MDAB块的输出特征可表示为
FMDA=FCom⊙τ1(FCUS)+FCom⊙τ2(FCUS),
其中,⊙表示逐元素相乘,τ1(·)表示在通道维上执行Softmax函数,τ2(·)表示在空间维上执行Softmax函数.
MDAB实现简单,也可方便地组合到其它SR模型中.
2 实验及结果分析
2.1 实验设置
本文采用DIV2K数据集[42]作为训练和验证数据集.第1幅~第800幅图像用于训练,第821幅图像~第830幅图像用于验证,标记为DIV2K_val10.原HR训练图像进行双三次下采样,获得配对的LR图像.类似其它方法,对输入图像随机地进行90°、180°、270°旋转和水平翻转,增强训练图像.测试数据是5个标准的测试数据集: Set5[43]、Set14[9]、B100[44]、Urban100[45]和Manga109[46].
在YCbCr空间[35]的亮度(Y)通道上,计算峰值信噪比(Peak Signal to Noise Ratio, PSNR)和结构相似性指数(Structural Similarity Index, SSIM)[47].
本文也给出各方法的参数量和计算量.计算量即GFLOPs(Giga Floating-Point Operations Per Se-
cond)[36],指乘法和加法运算的次数.在模型训练中,每批次随机选取16个64×64的图像块.使用Adam(Adaptive Moment Estimation)优化器[48],
β1=0.9,β2=0.999 ,ε=10-8.
2倍SR模型训练1 000个迭代周期,初始学习率设置为2.5×10-3,每200个迭代周期衰减一半.2倍SR模型作为3倍SR和4倍SR的预训练模型,3倍SR和4倍SR模型同样训练1 000个迭代周期.所有训练过程均使用L1损失函数.使用Pytorch[49]框架和一个NVIDIA 2080Ti GPU实现模型,并进行模型的训练和测试.
在RCA-MDA架构中,级联3个MIFB块,每个MIFB块的输入通道数和输出通道数均为48.每个MIFB块级联6个MIRB块,每个MIRB块中扩张卷积的扩张率分别为1,2,3,3,2,1.每个MIRB块中CSAConv的输入通道数为48,输出通道数为24,分组卷积的组数为3.每个RCAB块中可学习参数的初始值设置为
λ1=0.5,λ2=0.5.
GFFB块中可学习参数的初始值设置为
μ1=0.3,μ2=0.3,μ3=0.4.
2.2 各模块性能分析
2.2.1 多上下文信息融合块
当NFMB中分别级联2、3和4个MIFB块时,在DIV2K_val10验证集上,3倍SR的PSNR和参数量对比如表1所示.由表可看出,MIFB块个数更多,即网络深度更深,PSNR性能更优.MIFB个数由2增加到3时,参数量增加141 K,PSNR增加0.142 dB.MIFB个数由3增加到4时,参数量减少139 K,但是PSNR仅减少0.009 dB.因此当MIRB个数为3时,性能和参数量之间达到较好平衡.

表1 MIFB块个数不同时,3倍SR的PSNR和参数量对比
2.2.2 多交互残差块
为了探究MIRB中扩张卷积使用不同扩张率对网络性能的影响,进行5组对比实验.在6个MIRB中,一个支路的卷积核均为3×3,另一个支路扩张卷积的扩张率分别设置如下:1)均为1;2)均为2;3)均为3;4)1,2,3,1,2,3;5)1,2,3,3,2,1.这个设置是经验性的,情形1)~情形3)使用相同大小卷积核,分别为3×3、5×5和7×7.情形4)逐渐增大卷积核.情形5)逐渐增大卷积核,再逐渐减少卷积核,这个设置也与 Zhang等[39]设置相同.在 DIV2K_val10验证集上,3倍SR的 PSNR值如下:情形1)时,PSNR为29.536 dB;情形2)时,PSNR为29.640 dB;情形3)时,PSNR为29.410 dB;情形4)时,PSNR为29.345 dB;情形5)时,PSNR为29.676 dB.由此可看出:情形4)结果最坏,情形5)结果最优.情形5)可更充分地融合3×3到7×7不同尺度的上下文特征信息.
分组卷积可减少参数量和计算量.MIRB块中CSAConv最后的1×1卷积可替换为1×1的分组卷积.在DIV2K_val10验证集上,1×1的分组卷积组数为3.3倍SR时,使用1×1分组卷积,参数量为334 K,PSNR为29.605 dB.CSAConv最后使用1×1卷积时,参数量为425 K,PSNR为29.676 dB.相比分组卷积,1×1卷积时,参数量增长91 K,但PSNR增长0.071 dB,说明使用1×1卷积时,模型在参数量和性能间取得较好平衡.
为了探索MIRB块中多尺度特征间交互次数对性能的影响,进行3组对比实验,交互次数分别设为 2,3,4.在DIV2K_val10验证集上,3倍SR的PSNR和参数量对比如表2所示.由表可看出,交互次数越多,PSNR性能越优.交互次数由2增加到3时,参数量增加92 K,PSNR提高0.112 dB;交互次数由3增加到4时,参数量增加91 K,PSNR仅提高0.029 dB.因此交互次数为3是一个合理的折衷.

表2 MIRB块中多尺度特征间交互次数不同时,3倍SR的PSNR和参数量对比
2.2.3 区域互补注意力块
为了验证RCAB的有效性,在MIFB中,进行包含和不包含RCAB的2组对比实验.在DIV2K_val10验证集上,MIFB中使用RCAB时3倍SR的PSNR为29.631 dB,不使用RCAB时3倍SR的PSNR为29.676 dB.可以看出,使用RCAB块时,PSNR提升0.047 dB.
2.2.4 多维注意力块
为了验证MDAB的有效性,进行6组对比实验.对于GFFB块:
1)去掉MDAB块,模型称为MDAB_0.
2)MDAB块替换为SE通道注意力块[40],模型称为MDAB_1.
3)MDAB块替换为Woo等[41]提出的空间注意力块,模型称为MDAB_2.
4)MDAB替换为Woo等[41]提出的通道和空间注意力块CBAM(Convolutional Block Attention Mo-dule),模型称为MDAB_3.
5)MDAB块替换为PA[29],模型称为MDAB_4.
6)使用本文的MDAB,模型称为MDAB_5(即RCA-MDA).
在DIV2K_val10验证集上,3倍SR的PSNR和参数量对比如表3所示.由表可看出,使用MDAB-5效果最优.
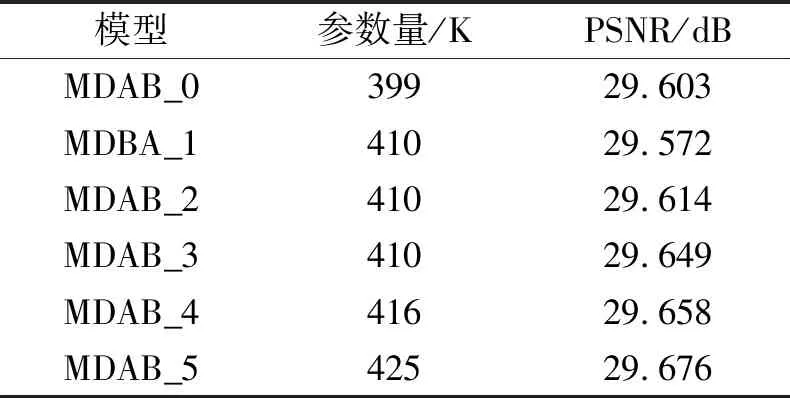
表3 GFFB中注意力块不同时,3倍SR的PSNR和参数量对比
2.3 实验结果对比
为了验证RCA-MDA性能,首先对比较大模型MSRN[29]与RCA-MDA的性能,结果如表4所示.
同时,选择如下13个代表网络进行客观定量对比和主观视觉效果对比:SRCNN(Image SR Using Deep Convolutional Networks)[11]、DRCN(Deeply-Recursive Convolutional Network)[19]、MemNet(Very Deep Persistent Memory Network)[21]、IMDN[25]、RFD-N[26]、LAPAR[28]、CARN(Cascading Residual Net-work)[50]、IDN(Information Distillation Network)[51]、FSRCNN(Fast SR CNN)[52]、VDSR (Accurate Image SR Using Very Deep Convolutional Networks)[53]、LapSRN (Laplacian Pyramid SR Network)[54]、 AWS-RN(Adaptive Weighted Learning SR Network)[55]、SMSR(Sparse Mask SR)[56].在5个标准测试数据集上,当放大倍数为2,3,4时,各网络的PSNR和SSIM值对比如表5~表7所示,表中黑体数字表示最优值,斜体数字表示次优值.
从表4~表7可看出,除早期网络(SRCNN、FSRCNN和LapSRN)计算量小于RCA-MDA外,其它方法的计算量都大于RCA-MDA.以放大倍数为4为例,在所有测试数据集上,RCA-MDA的PSNR值和SSIM值几乎是最好的.除MSRN以外,其它网络的PSNR值和SSIM值结果来自作者的原论文.MSRN的结果源自作者在https://github.com/MIVRC-/MSRN-PyTorch上提交的结果.
对于轻量级模型,除了参数量以外,推理时间也是一个重要指标,在Urban100测试集上,各网络4倍SR的推理时间如下:CARN为0.18 s,AWSRN为0.05 s,IMDN为0.08 s,LAPAR为0.13 s,RFDN为0.11 s,RCA-MDA为0.08 s.
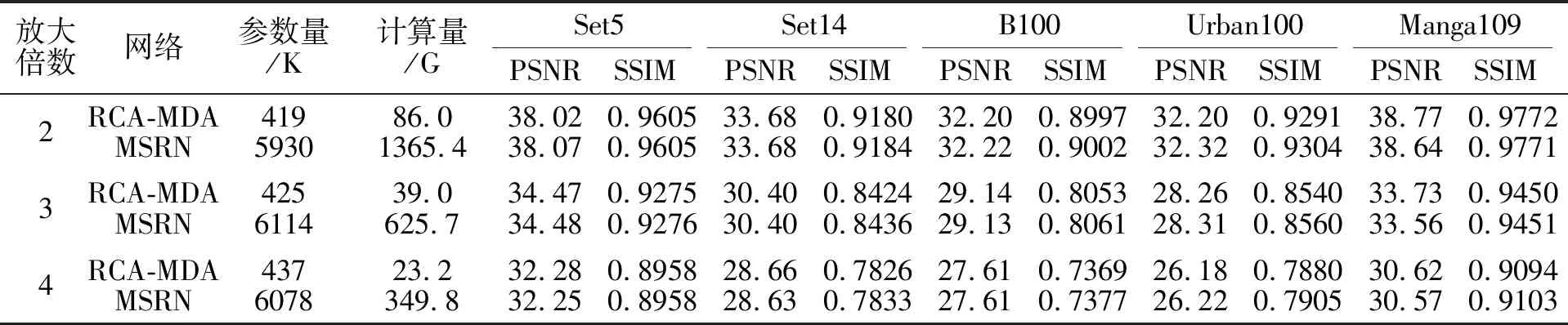
表4 MSRN和RCA-MDA的性能对比
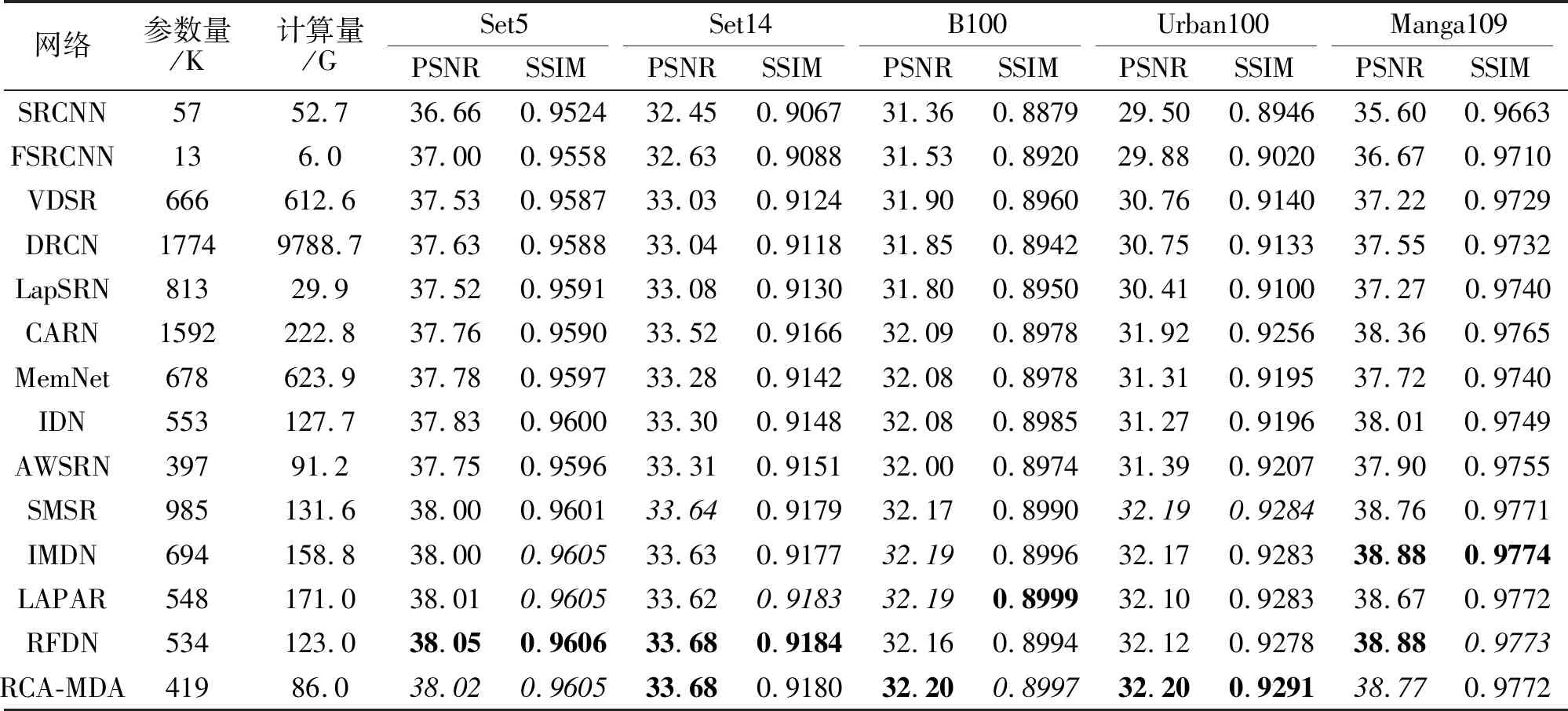
表5 放大倍数为2时各网络的指标值对比
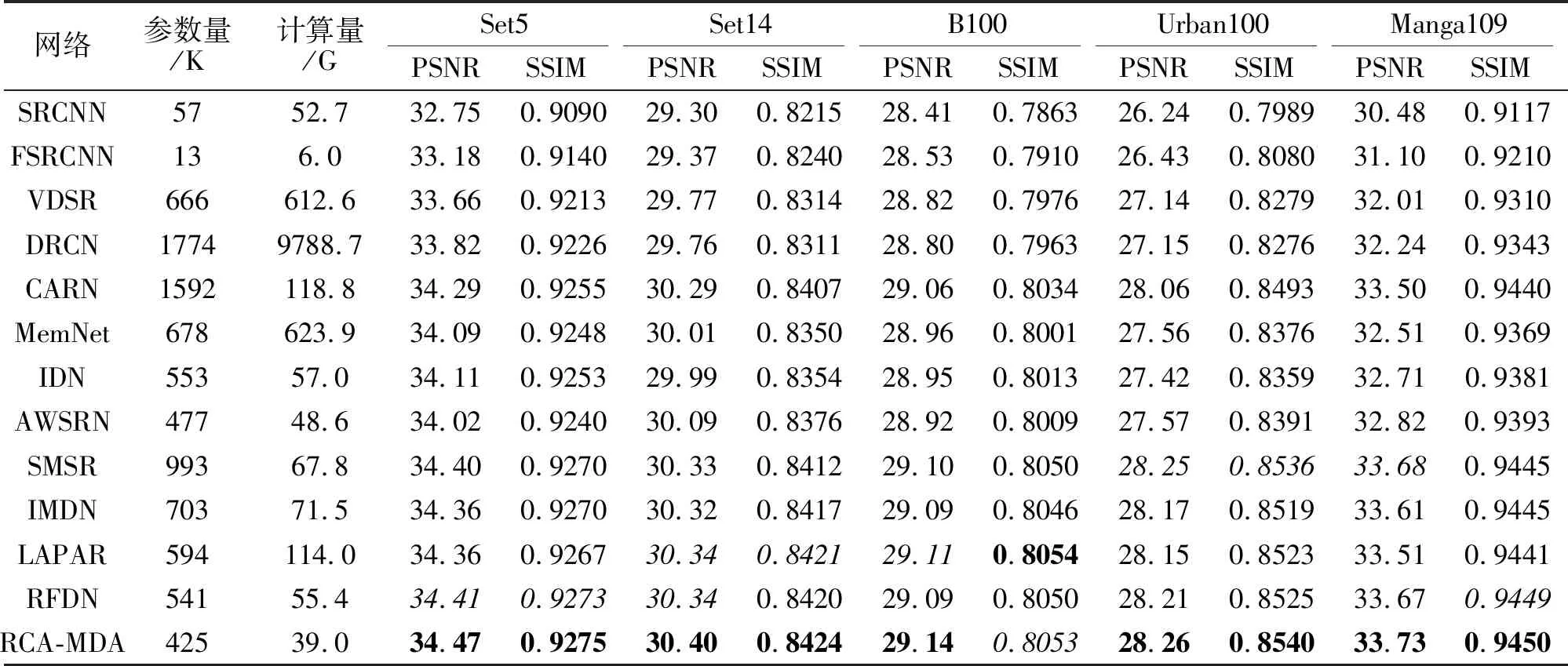
表6 放大倍数为3时各网络的指标值对比
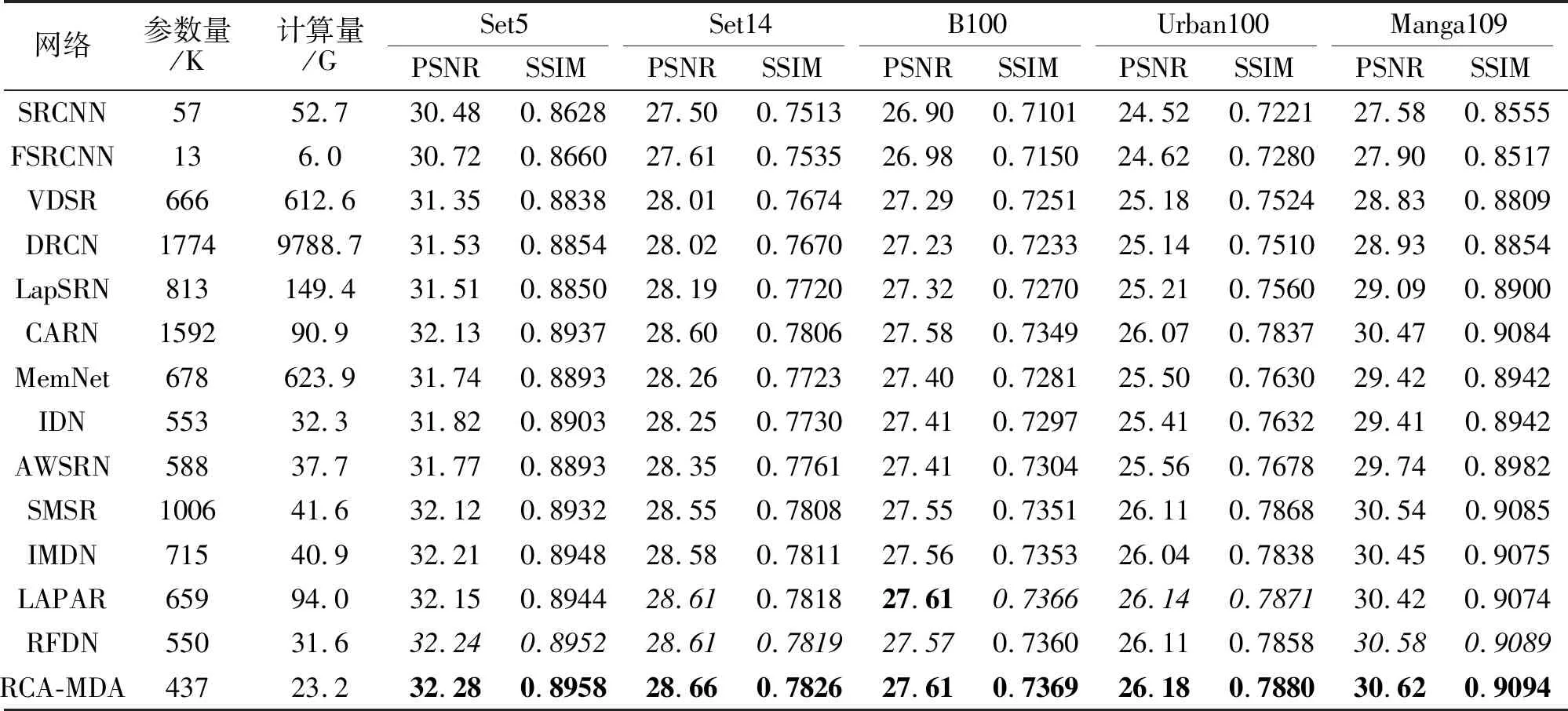
表7 放大倍数为4时各网络的指标值对比
图4和图5分别是各网络在放大倍数为2和4时重建的SR图像结果,图中Bicubic表示LR图像经过双三次上采样得到的SR结果.由图4和图5可见,RCA-MDA的结果最优.以Set14数据集上bar-bara图像为例,其它网络的结果或过度模糊,或失真严重,或恢复的条纹方向错误,RCA-MDA的结果接近于原HR图像.再以Urban100数据集上img004图像为例,其它网络也大都过度模糊或失真,RCA-MDA的结果最优.Urban100数据集上img096、img005图像的结果也是类似的.
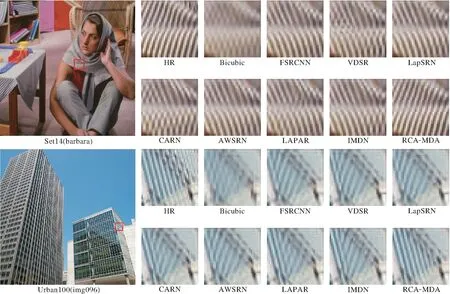
图4 2倍SR时各网络视觉效果对比

图5 4倍SR时各网络视觉效果对比
3 结 束 语
本文提出基于区域互补注意力和多维注意力的轻量级图像超分辨率网络(RCA-MDA),引入轻量级的卷积单元(CSAConv),基于CSAConv构造多交互残差块(MIRB),相比MSRN[32]的多尺度残差块,MIRB可大幅减少模型参数量,同时保持SR性能.同时提出区域互补注意力块(RCAB),组合RCAB和MIRB的多上下文信息融合块(MIFB).MIFB可有效融合局部、非局部和多尺度特征信息,使不同图像不同区域间的信息得到互补.本文也提出多维注意力块(MDAB),可逐像素建模特征通道维和空间维之间的依赖关系.MDAB进一步融合MIFB块输出的多层次特征信息.RCA-MDA网络架构轻量、有效.实验表明,RCA-MDA性能较优,把轻量级SISR模型复杂度和性能平衡提升到一个较高水平.本文对网络模型进行轻量化的方法和注意力机制也可应用到其它计算机视觉任务当中,其普适性和对不同网络性能的影响值得进一步研究.
