在线社交网络信息传播建模及转发预测研究
2022-08-15傅熙雯
傅熙雯
(云南大学,云南 昆明 650091)
随着科学技术的不断发展,在线社交平台不断增多,如微博、微信等,其不仅具有传统媒体的“时空偏向”特征,同时还可实现信息传播主体多元化、内容碎片化,为人们提供多样化选择,满足人们的个性化需求。
为促进复杂网络以及系统科学领域不断发展,需对在线社交网络信息传播机制进行深入探究,提升互联网治理水平。因此,亟需对在线社交网络信息传播进行建模分析,并进行转发预测。
1 分类预测模型
机器学习模型种类较多,常见的机器学习模型主要包括决策树、支持向量机和朴素贝叶斯等,不同模型均有一定的应用优势和弊端,本次在线分析社交网络信息传播建模中采用随机森林模型。
对随机森林本质进行分析发现,其属于决策树组合,是一种集成了bagging和具有随机性特征分裂方法的组合分类器,对于输入数量无需进行预处理,在建模前无需进行特征选择,在模型运行中,通过对变量的重要性进行选择,分析不同输入变量对模型的重要程度。
另外,在实际应用随机森林模型时,泛化误差率较低,数据集中可包含异常值和噪声,即使数据确实,依然保持较高的预测准确性,可有效提升预测结果准确性,并且能够平衡误差,预测性能较好。除此以外,在模型中,各个决策树均相互独立,能够避免过拟合问题产生[1]。
2 预测结果评估方法
在数据分析过程中,需应用多种度量指标,在本次建模分析中采用召回率(recall)和精确度(precision),可准确反映出稀类分类实际情况。
2.1 召回率和精确度
对于两分类问题,可用混淆矩阵表示,{+,-}指正负类的标签集合,“+”代表正类,“-”代表负类。根据给定分类模型,即可准确计算测试机,共包含4种分类。
f++(TP)为真正类,样本预测类别为正,真实类别为正;f+-(TP)为假负类,样本预测类别为负,真实类别为正;f-+(TP)为假正类,样本预测类别为正,真实类别为负;f--(TP)为真负类,样本预测类别为负,真实类别为负。
根据混淆矩阵,即可对召回率(R)以及精确度(P)进行计算:
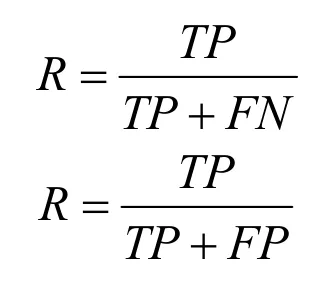
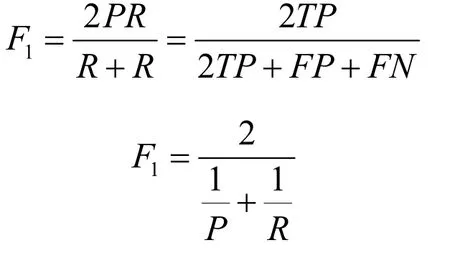
在模型分类效果评估中,还可采用F1度量这一指标,F1为召回率和精确度的平均值,如果R和P均最大,则F1即可最大化,三者之间的关系如下:
2.2 受试者工作特征曲线
受试者工作特征曲线即ROC曲线,在模型评估完成后,对于评估所得结果,可绘制成曲线,即可对不同分类模型的差异进行对比分析。在曲线二维平面中,横轴和纵轴分别为假正率及真正率,长度均为1。在ROC曲线评估模型的实际应用中,可采用以下2种分析方式:对ROC曲线的偏向进行观察,如果ROC曲线偏向左上角,则模型分类性能较好;对ROC曲线下面积(AUC)进行观察,如果AUC较大,则模型分类效果较好[2]。
ROC曲线绘制流程如图1所示,其中a为样本,如果阈值为C,则a为正类;如果阈值小于等于C,则a为正类。
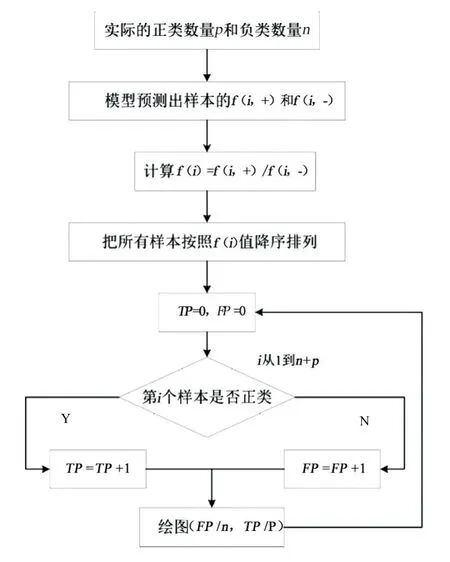
图1 ROC绘制流程
3 转发预测模型设计
在本次在线分析社交网络信息传播建模中,采用随机森林模型,对于模型参数可采用用户特征关键词权重,据此创建兴趣加权随机森林模型(WRF)。在无加权RF模型中,对于各个用户的特征变量,可采用一个权重参数,其能够对权重进行调节,充分展现出各个用户特征变量的差异。对兴趣差异进行分析发现,主要体现在兴趣数量和兴趣程度2个方面。各个用户输入变量的特征加权值计算方式如下:
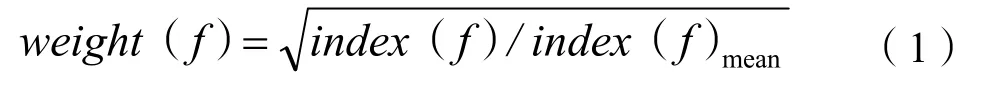
式(1)中:weight(f)为特征f的最终权重;index(f)为该特征某用户的兴趣权重;index(f)mean为该特征权重值的平均值。
在本次研究中,计算模型的关键步骤如下:①清洗数据集,数据集主要分布在多个文本中,因此,通过对数据集进行合并和去重处理,即可有效清洗数据集;②在数据集清洗完成后,可利用转发属性以及非转发属性,将数据集分为2种类型,再对各个数据集上各项指标的累积度分布情况进行计算,然后绘制CDF曲线;③创建转发行为预测指标体系,并根据式(1)对各个应用户的兴趣加权参数进行计算,然后再对各个特征进行加权计算;④将原始特征变量以及特征变量输入随机森林模型中,对R、P以及F1进行计算,然后在此基础上绘制ROC曲线,对各个指标在模型中的重要性进行对比分析;⑤以多种用户属性作为基础,并进行分类预测,对各个属性分类效果进行比较[3]。
4 在线社交网络信息转发预测结果分析
4.1 模型预测分析
在模型分析前,在获得原始数据后,需对所有数据进行清洗,在此过程中,可利用Python编程语言中的Numpy以及Pandas工具包,对数据进行拆分、合并处理,同时还可对缺失值进行有效处理。在数据清洗完成后,即可利用R语言界面友好的“rattle”数据挖掘工具包对模型进行计算分析。
在随机森林模型计算中,决策树数量的影响较大,在随机森林模型计算分析中,一般默认决策树数量,但是在具体的计算过程中,为了对模型进行优化处理,要求合理定义最佳参数。随机森林模型计算误差和决策树之间的关系如图2所示,分析图2发现,OBB指模型的泛化误差,“0”指否定结论的误判率,“1”指肯定结论的误判率。比如选择微博平台作为研究对象,在用户转发行为预测分析中,可对多个模型进行对比。
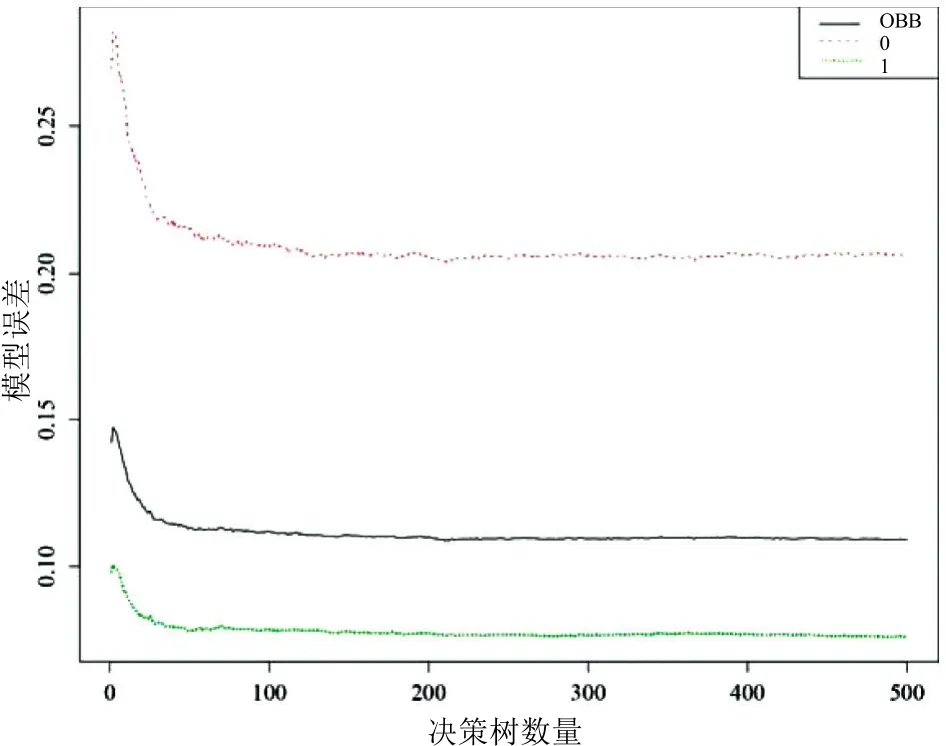
图2 决策树数量与模型误差关系
在预测分析中,可利用改进后的随机森林模型(WRF)与经典森林模型RF和Logistic回归模型相比,各项性能指标均比较好,精度更高,同时召回率指标和F1分值也有所提升。由此可见,在对用户兴趣加权进行调整后,通过利用WRF,可对用户转发微博信息的行为进行准确预测。
为了能够对不同模型中用户转发行为预测性能进行对比,需对ROC曲线进行绘制和分析,并对ROC曲线下方面积(AUC)进行计算,据此对各个模型的性能进行对比。当AUC在1.0~0.5之间时,如果AUC接近1,则模型分类效果较好,如果AUC在0.9以上,则分类准确性较高;当AUC在0.7~0.9之间时,分类准确性较高;当AUC在0.5~0.7之间时,准确性较低;如果AUC为1,则模型最完美;当AUC为0.5时,模型效果最差[4]。
确定模型指标重要性程度,可选择2个度量标准,即精度平均减少值(Mean Decrease Accuracy)和节点不纯度平均减少值(Mean Decrease Gini),如果2个值较大,则指标重要性也较高。在2种度量标准下,各个指标的排名差异较大,其中,转发性以及转发活跃度对于WRF分类效果的影响最大,而用户分类关键词数量以及性别对于模型分类的重要性最小。
4.2 不同用户属性的转发预测性能
在对模型分类预测性能进行评估后,即可确定不同指标的重要程度,为了能够对用户转发行为进行预测,可选择3个属性进行分析,包括特征属性、行为属性及兴趣属性。
3类用户属性预测结果差异较大,其中,行为属性预测结果准确性较高,而用户兴趣属性预测结果准确性较低。另外,在3类指标中,特征属性的召回率较高,兴趣属性预测召回率和特征属性预测召回率相近,行为属性召回率最低。
通过对F1分值进行对比发现,行为属性效果最好,兴趣属性得分最低。数据集具有不平衡特征,因此,在对模型分类能力进行分析时,需对精确度指标以及召回率指标进行分析,通过对F1度量结果进行对比分析发现,用户行为属性分类效果最好,由此可见,用户的转发行为、评论等会对转发行为产生较大影响,另外,不同用户粉丝属性以及关注人属性等会对用户信息转发行为产生较大影响,用户兴趣处于不断变化中,对于用户信息转发行为的影响比较小。
在绘制ROC曲线后,通过对ROC曲线进行分析,可发现用户行为属性的分类效果较好,对用户转发预测的影响较大。用户3类属性的ROC曲线如图3所示,行为属性ROC曲线最靠近左上角,因此,AUC值最大,由此可见,行为属性对于用户转发行为的影响较大,其次为用户特征属性,最后为用户兴趣属性。
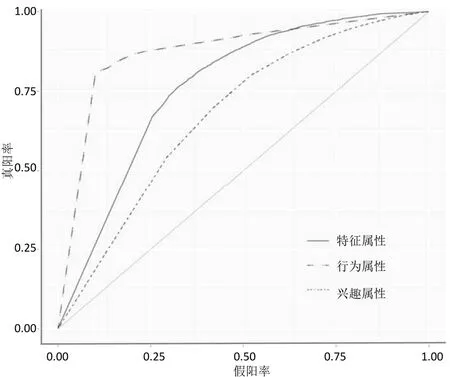
图3 3类属性的ROC曲线
5 总结
综上所述,本文主要对在线社交网络信息传播建模方法以及用户转发行为预测方式进行了详细探究。在在线社交网络平台运行中,在信息传播方面,用户行为驱动为十分重要的内在影响机制。在本次研究中,创建用户兴趣加权的随机森林模型,在用户转发行为预测中选择3个属性,分别为特征属性、行为属性和兴趣属性,通过将随机森林模型(WRF)与传统森林模型以及Logistic回归模型进行对比发现,WRF模型的分类性能比较好。另外,在WRF模型的基础上,对各项属性评分以及ROC曲线进行对比,确定行为属性预测效果较好,能够反映出用户行为习惯对在线社交网络平台运营中信息传播的影响。
