基于Transformer动态场景信息生成对抗网络的行人轨迹预测方法
2022-08-13邱文涛张艳宁
裴 炤,邱文涛,王 淼,马 苗,张艳宁
(1.陕西师范大学现代教学技术教育部重点实验室,陕西西安 710119;2.陕西师范大学计算机科学学院,陕西西安 710119;3.上海交通大学航空航天学院,上海 200240;4.空天地海一体化大数据应用技术国家工程实验室,陕西西安 710129;5.西北工业大学计算机学院,陕西西安 710129)
1 引言
基于深度学习的行人轨迹预测[1]是近年来人工智能和计算机视觉领域的热点研究问题,应用在视频安防监控、目标跟踪等方面.行人轨迹预测是根据目标行人的历史轨迹以及行为特征综合分析后,推测出目标行人在未来的位置坐标[2].在行人密集的公共场所,监测场所内行人的活动轨迹,并分析人群的运动、检测异常的行人轨迹,对犯罪预防、防恐防暴等公共安全领域有着积极的作用[3,4].在目标跟踪[5,6]领域,在跟踪过程中因目标行人被短暂遮挡而导致跟踪失败时,可以使用行人轨迹预测技术预测目标行人的未来轨迹,实现对目标行人的继续跟踪.
行人间的社交关系与所处的场景都会影响行人对未来路径的规划.例如当目标行人前方有结伴而行的路人时,根据社交惯例,其不会从路人之间径直穿越,而是选择绕行.在道路上遇到不同障碍物时会选择不同的策略改变其行进方向,其可以分为静态障碍物和动态障碍物两类:当目标行人遇见静态障碍物,如道路旁停放的汽车、树木以及建筑物,这时行人会选择绕行,而当其遇见动态障碍物,如行驶的汽车,行人首先会预估汽车的行进速度及其对自身前进路径的影响,进而会选择减速慢行或者驻足等候汽车通过.
行人轨迹预测本质上是基于时间序列的预测问题,该问题更关注近距离范围内的邻居行人及环境对目标行人的影响,较远距离的邻居行人及环境对目标行人的影响相对较弱,LSTM 在处理长距离依赖的时序问题上有较好的效果,但在短距离预测方面稍显不足,此外,静态场景信息对行人路径规划的影响体现在当前短时间内,而动态场景信息会影响行人对未来长远的路径规划.
因此,有效利用物理环境以及行人间的社交关系对解决行人轨迹问题至关重要,为解决上述问题,本文提出一种基于Transformer 动态场景信息生成对抗网络的行人轨迹预测方法,该方法首先构造动态场景信息提取模块,提取动态场景信息特征,同时利用Transformer在解决短距离依赖的时序问题上的优势,以此构造基于Transformer 的生成对抗网络对行人轨迹进行特征提取,同时利用池化模块将动态场景信息和行人社会交互信息进行特征融合,增强模型对物理场景信息以及社交信息的学习,进而提高模型预测的精准率.
主要贡献如下:
1.首先为了解决LSTM 在短距离依赖的时序预测问题上的不足,本文使用在短距离依赖的时序预测问题表现更好的Transformer 网络取代LSTM,Transformer网络的自注意力机制使网络在提取目标行人的社会交互信息特征与历史轨迹特征时更加关注近距离的邻居行人.
2.其次通过构造动态场景信息提取模块,使用卷积神经网络[7]提取动态场景信息特征,并利用池化模块将动态场景信息特征、历史轨迹特征、行人社会交互信息进行特征融合.池化模块利用社交边界模型对其交互信息进行池化操作,选取对行人轨迹产生最大影响的特征信息,将其与动态场景信息特征进行特征融合后反馈至解码器进行预测,从而实现将动态场景信息和行人社会交互信息结合,提升模型合理预测的精度.
3.最后构建基于Transformer 的生成对抗网络,生成器以池化层和随机高斯噪声为输入,将生成的符合日常生活规范的行人轨迹信息持续输入到鉴别器网络,生成器和鉴别器进行博弈,不断优化双方网络参数,最终使生成器可以生成高质量的行人轨迹信息扩充训练集,从而提高模型预测的准确率.
在ETH[8]和UCY[9]数据集上的实验结果和相关实验分析表明,本文提出的行人轨迹预测方法相较于以往基于传统循环神经网络模型的行人轨迹预测算法具有更高的准确率,验证了本文提出的行人轨迹预测方法的有效性.
2 相关工作
传统的行人轨迹预测研究[10~14]通常使用相对复杂的数学统计模型如:本领域的开创工作是Helbing[10]提出的基于社会力的线性模型Social Force,它将行人和障碍物对目标的影响简单抽象为引力与斥力,行人与目标相互靠近称之为引力,反之行人与目标相互排斥从而避免碰撞称之为斥力,以此进行建模.Kitani[11]等人使用基于隐含马尔科夫模型和逆最优控制的方式通过对行人的动作理解进行强化学习建模,从而更好地学习静态环境对行人轨迹的影响.但此类模型需要对场景进行语义标注,模型对复杂场景的泛化能力较低,在面对动态场景无法取得很好的预测效果.
此后基于数据驱动的深度学习模型[15~22]成为行人轨迹预测的主要方法,如基于循环神经网络模型(Recurrent Neural Network,RNN)以及长短期记忆网络模型(Long Short-Term Memory,LSTM)的方法[23~26]逐渐用在解决此类时间序列问题上,此类模型相较于社会力等数学统计类的模型可以处理复杂的场景,且预测准确率有较大提升,逐步成为行人轨迹预测的主流模型.现阶段基于LSTM 的社交网络模型有SRLSTM[25]、Social-LSTM[18]等模型,此类模型引入了行人社交机制,利用行人之间的欧式距离和LSTM 的隐藏特征信息进行社会化建模,通过社会池化层对其进行池化后根据隐藏状态信息进行预测.Pei[1]提出了一种在行人密集场景下的基于Social-affinity LSTM 的行人轨迹预测方法,其根据邻居行人的相对位置构造了一种社会亲和力图用于记录邻居行人的社交影响权重,Social-affinity LSTM 根据目标行人的个人轨迹特征和邻居行人的影响进行轨迹预测.上述方法的缺点在于并未考虑行人的轨迹是多模态的,在许多情况下对于行人而言可供选择的路径是多样的,并非单一路径.
生成对抗网络(Generative Adversarial Network,GAN)的出现为多模态的行人轨迹预测提供了技术途径.Gupta[27]等人提出了一种基于生成对抗网络(Social-GAN,SGAN)的行人轨迹预测方法,其通过LSTM 构造生成对抗网络,利用生成对抗网络的生成器网络和鉴别器网络不断博弈,从而强迫网络不断优化模型参数、生成符合社会规范的轨迹,以此扩充数据集,提高预测精度,但它未利用任何场景信息,仅利用行人之间的社会交互信息,未考虑场景对行人的影响,因此可能会出现违背生活常识的预测轨迹.
此后Sadeghian[28]等人将场景信息与注意力机制[29,30]结合,同时利用生成对抗网络生成多模态的轨迹.Vineet[31]等将图注意力(Graph ATtention network,GAT)网络和生成对抗网络相结合,其利用图注意力网络对静态场景中所有行人之间的社会交互进行建模,通过生成对抗网络构造预测轨迹与目标行人的行为特征之间的可逆映射来生成符合社会规范的轨迹.上述方法仅考虑当前时刻静态场景对行人的影响,未考虑动态场景的影响.
3 问题定义
行人轨迹预测问题可以看作是在固定场景中根据给定n个目标行人的历史轨迹以及状态特征,预测目标行人的未来轨迹坐标的问题,其本质上是基于时间序列的预测问题.在本文中,给定目标行人的轨迹X=(X1,X2,…,Xn),其 中Xi=为 场景中所有目标行人的个数为目标行人i在t时刻的坐标,tobs为观测的时序时长.将行人的真实轨迹表示如下:
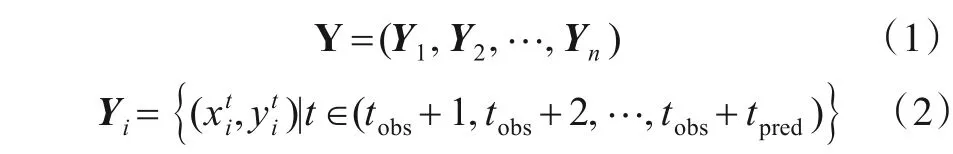
其中tpred为预测的时序长度,相似的,本文方法预测的行人轨迹表示如下:
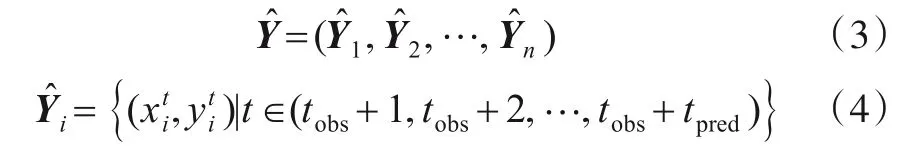
4 基于Transformer 动态场景信息生成对抗网络的行人轨迹预测方法
本文提出的基于Transformer 动态场景信息生成对抗网络的行人轨迹预测方法总体网络结构如图1所示,模型整体由动态场景信息提取模块、生成器网络、池化模块、鉴别器网络和损失函数组成,其中动态场景信息提取模块由卷积神经网络构成,生成器网络包含编码器和解码器,池化模块包含行人社会交互计算模块,鉴别器网络包含解码器、全连接层和多层感知机.由于本文中的生成对抗网络与Transformer 都由编码器与解码器组成,作为区分,本文将生成对抗网络中的生成器网络与鉴别器网络中的编码器分别表示为G-Encoder、DEncoder,将生成器的解码器表示为G-Decoder,将Transformer的编码器与解码器表示为T-Encoder、T-Decoder.
本模型的预测过程如图1所示,首先由场景提取模块进行动态场景信息特征提取,G-Encoder 将场景内所有行人的轨迹作为Transformer 的输入,学习行人的历史轨迹特征.池化模块根据G-Encoder传入的行人轨迹特征信息计算出目标行人的社会交互信息,之后将社会交互信息与动态场景信息进行特征融合获得行人状态信息.G-Decoder 将行人状态信息加入随机高斯噪声进行解码后生成相应的预测路径.生成器网络产生的预测路径与真实的行人数据作为鉴别器的输入,DEncoder 将路径信息进行编码之后由多层感知机对其进行分类鉴别.损失函数模块负责计算行人轨迹预测模型的误差,并将误差进行反向传播,从而增强生成器网络生成轨迹的能力.生成器网络和鉴别器网络会持续进行对抗训练,鉴别器网络对真假轨迹信息的鉴别能力也在对抗过程中不断提高,整个网络的参数也不断优化,最终生成器网络将产生可以媲美真实轨迹的高质量轨迹序列信息,模型的预测能也随之提升.

图1 基于Transformer动态场景信息生成对抗网络的行人轨迹预测方法总体网络结构
4.1 动态场景信息提取模块
行人当前时刻所处的静态场景会影响行人短时间内的行进方向,而动态场景会对其未来长远的路径规划产生重要影响,因此将动态场景信息引入行人轨迹预测方法显得尤为必要.为了获取行人所处的场景并加以利用,本文设计了动态场景提取模块,如图2所示.

图2 动态场景提取模块的工作流程
本模块由两个关键部分组成,一个是场景关键帧提取模块,用于在视频中获取行人所处的场景.场景提取模块首先将目标行人的编号视为键,将其出现的时刻视为值,由此构造哈希表.在哈希表中检索出目标行人出现的起止时间,根据起止时间获得视频对应的场景关键帧Pt,将当前时刻到tobs时刻的帧集合设为场景集合另是卷积神经网络模块,其首先对中的场景关键帧进行特征提取,对其进行最大池化计算得到动态场景信息张量动态场景信息提取模块工作的相关过程如下所示:
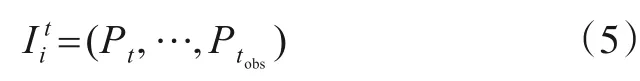
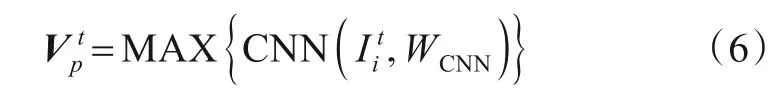
在本文中使用的卷积神经网络CNN(·)为ResNet,其网络初始化参数为使用ImageNet 预训练之后得到的参数,MAX(·)代表最大池化运算.
4.2 生成器网络
在处理时序问题上通常采用以长短期记忆网络(LSTM)为代表的循环神经网络(RNN),最近研究[32]表明LSTM 在解决长距离依赖的问题上表现较好,但在解决短距离依赖的问题上Transformer 网络表现较好,因此本文选择使用Transformer 网络与LSTM 共同构造生成对抗网络.与一般的生成对抗网络相似,本文方法也由生成器网络和鉴别器网络组成,在本文中生成器网络用于学习行人真实轨迹的数据分布、生成预测轨迹序列,其中G-Encoder 编码器由Transformer 网络构成,G-Decoder解码器由LSTM构成.
4.2.1 G-Encoder编码器
本文将所有行人的轨迹看作是二维坐标序列,GEncoder 编码器首先使用多层感知机将每个行人的轨迹序列由二维坐标序列转换为时空位置张量将其作为Transformer 网络的输入,Transformer 网络将学习并得到每位行人时空位置特征信息具体过程如下:
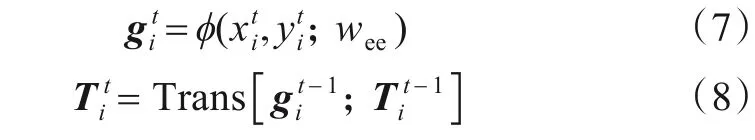
其中,φ(·)为含有非线性激活函数ReLU 嵌入层(Embedding Layer)网络,wee为嵌入层网络的权重参数.式(8)中Τrans(·)为G-Encoder编码器中的Transformer网络.
4.2.2 G-Decoder解码器

其中,wde为G-Decoder 解码器中LSTM 网络的权重参数,wdfc为全连接网络权重参数,wdp1与wdp2为多层感知机MLP(·)的不同权重参数.
4.3 池化模块
本文方法分别使用动态场景信息池化模块和行人社会交互信息池化模块来处理动态场景信息和行人社会交互信息.
4.3.1 动态场景信息池化模块


其中∅是含有ReLU 非线性激活函数的多层感知器,weh是∅的权重参数.X it,ngb行人i的所有邻居行人在t=tobs时的轨迹坐标张量.γ为多层感知机,Wep为其权重参数.
4.3.2 行人社会交互信息池化模块
社交信息池化社交信息池化模块首先确定影响行人的社交边界.例如,当目标行人行走时,离其最近的人对其规划路径时的决策影响最大,为此本文设计了社交边界模型来衡量行人间的社会交互影响,利用邻里之间的相对距离和行人的当前坐标去构造边界模型,得到社交边界特征张量,将其与动态场景信息张量、轨迹特征张量进行特征融合后得到行人状态信息特征具体过程如下:
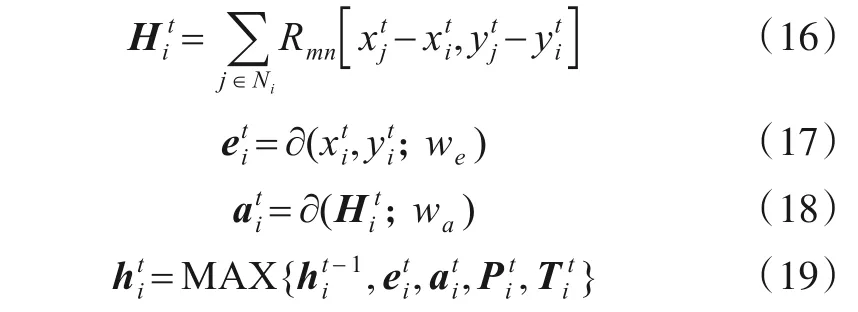
其中,式(16)中Rmn(·)为指示函数,用于检查坐标(x,y)是否在m•n表示的方格内部(在则返回1,否则返回0),Ni表示第i个行人社会边界区域内的所有邻居集合表示第i个人在t-1 时刻的状态特征信息,∂(·)是含有ReLU非线性激活函数的映射函数,we和wa是映射函数∂(·)的权重系数.
4.4 鉴别器网络

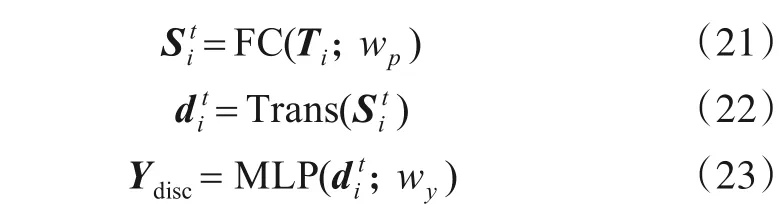
其中,wp为全连接层FC 的权重参数,wy为多层感知机MLP的权重参数.
4.5 损失函数
本文采用的损失函数由LGAN(G,D)和LL2(G)两部分组成,其中LGAN(G,D)是生成对抗网络的损失函数,LL2(G)是L2 坐标偏移的损失函数,其本质是基于最大似然定理的概率分布函数,用于计算真实坐标位移与预测得到的K个位移G(z)之间的最小差值以便提升预测轨迹的质量.通过对各个损失函数进行反向传播,不断地优化生成对抗网络各层的权重参数.其表达式如下:
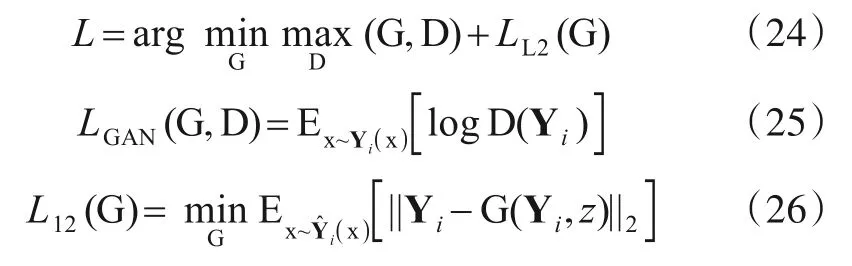
其中,γ为超参数,用于平衡LGAN(G,D)与LL2(G),E 为期望.
5 实验与分析
本文实验环境为Ubuntu 16.04,GPU为NVIDIATITAN XP,CPU为Inte(lR)Core(TM)i7-7700K CPU@4.20 GHz×8,使用的深度学习框架为PyTorch 1.7.0.
本文实验首先在ETH和UCY两个公共数据集上评估我们提出的方法的可行性,这两个数据集包含真实的行人轨迹和社会活动,包括对物理障碍物的躲避、行人之间行走.其中ETH 数据集包含ETH 和Hotel 两个场景,UCY数据集包含Zara1、Zara2和Univ三个场景.
5.1 实验数设置及评价指标
在本文实验中Transformer 网络的参数如下:TEncoder 的层数为6,head 个数为6,T-Decoder 的层数为8,head 个数为8.G-Encoder 中嵌入层单元数为64,隐藏层单元数为64,多层感知机单元数为1 024,G-Decoder的嵌入层单元数为64,隐藏层单元数为128,多层感知机单元数为1 024,瓶颈层单元数为1 024,使用ReLU作为激活函数,生成器网络的学习率设置为0.001.鉴别器中编码器的嵌入层单元数设置为64,隐藏层单元个数设置为64,多层感知机单元数为1 024,学习率设置为0.001.池化模块中的嵌入层单元数为64,隐藏层单元数为64,多层感知机单元数为1 024,使用ReLU 作为激活函数.场景提取模块使用在ImageNet 数据集上预训练的ResNet 模型,整个网络中噪声为8 个维度的高斯噪声,训练时的数据的批次大小为32,epochs 大小设置为500,训练迭代次数设置为15 000 次,观察轨迹的长度设置为8步,预测轨迹长度为12步.
与之前的研究方法[3,4]类似,在此本文选用ADE(平均偏移误差)和FDE(最终偏移误差)作为评价指标来刻画预测轨迹的准确性.ADE 是通过计算每个时刻的预测轨迹与真实轨迹的平均欧氏距离来评估预测序列的准确性.FDE 是通过计算最终时刻的预测轨迹位置与真实轨迹位置的平均欧氏距离来评估预测序列的准确性.
5.2 实验结果与分析
本文将文中方法和LSTM、Social-LSTM、Social-GAN、Sophie、Social-BiGAT 在ETH 和UCY 数据集上进行对比实验.
5.2.1 定量分析
本文将文中方法和LSTM、Social-LSTM、Social-GAN、Sophie、Social-BiGAT 在ETH 和UCY 数据集上进行对比实验.各种轨迹预测方法的ADE 和FDE 的对比结果如表1 所示.其中ADE 和FDE 的数值表示预测轨迹与真实轨迹误差,数值越小表示预测误差越小、准确率越高,各种场景下的最优结果已在表中标记.从表1中可以看出,本文方法的ADE 和FDE 表现在ETH 和UCY 两大数据集中的多个场景取得了较好的效果.本文方法的行人社会交互信息池化模块将来自于Transformer 的自注意力机制提取的社交特征与社交边界特征进行融合,从而更准确的刻画行人之间的社交影响.不同于上述模型仅考虑了社交因素而忽略了动态场景信息对目标行人的影响,本文方法中同时引入了动态场景信息池化模块,将其与行人社会交互信息池化模块相结合后产生社会交互约束,在对轨迹进行预测时会迫使模型生成符合日常生活规范的轨迹,使得模型对真实场景的拟合效果更好,模型的预测能力也随之提升.因此本文方法在大多数场景下的ADE 和FDE 优于LSTM、Social-LSTM、Social-GAN、Sophie、Social-BiGAT 等模型.

表1 不同模型的ADE和FDE结果对比
5.2.2 消融实验
为了进一步验证本文提出方法的有效性,本小节中使用定量分析方法进行验证.首先,本文选择Social GAN 作为基线方法,测试其在各个数据集场景中的实验结果.在此基础上,保持相同的试验参数设置,本文分别设计为其加入动态场景信息提取模块、Transformer网络以及两者结合方法的试验,具体对比结果如表2所示.
表2 表明:在单独使用动态场景信息提取模块或Transformer 网络的情况下,本文方法在大多数场景中的ADE 和FDE 优于基线方法,在使用两者结合的方法时,本文方法在全部场景中的ADE 和FDE 均优于基线方法.
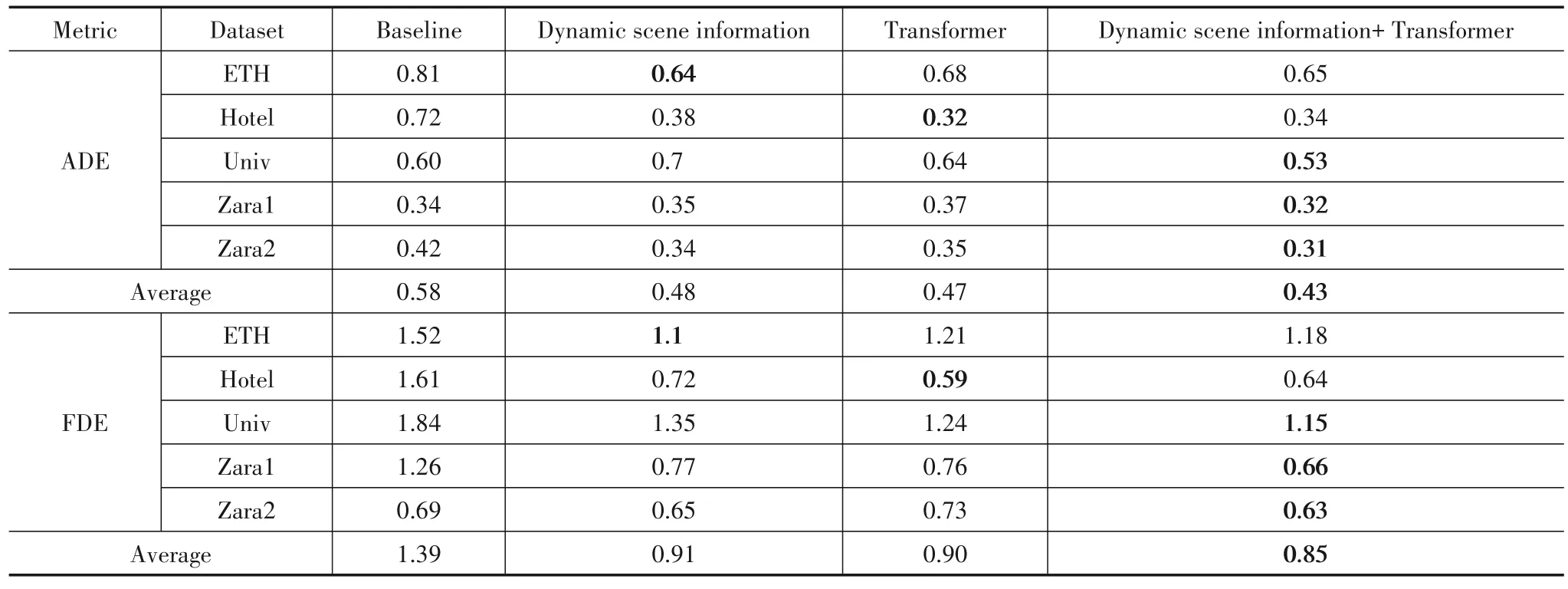
表2 消融实验结果对比
在ETH 数据集中,受数据集中场景的制约,行人行进路线基本固定,故动态场景信息对行人的路径规划有一定影响,本文方法相较于基线方法ADE 提高了19.75%,FDE 提高了22.37%,但略低于单独使用动态场景信息的方法,推测是因为Transformer 网络自注意力机制中的位置编码器,使得本文方法更关注行人自身的轨迹,从而弱化了动态场景信息的影响权重.
Hotel数据集中场景较为复杂,对行人的路径规划影响较大,因此本文方法相较于基线方法ADE 提高了52.78%,FDE提高了60.25%,和ETH 数据集中的情况相反,单独使用Transformer方法的准确率略高于本文方法,推测和ETH数据集中情况相似,动态场景信息对模型的影响权重略大,使得模型侧重于学习动态场景信息.
Univ 数据集中行人较为密集,障碍物处于道路边缘,因此对目标行人影响最大的是周围行人,得益于Transformer 网络的自注意力机制,本文方法相较于基线方法ADE提高了11.67%,FDE提高了37.5%.
Zara1 与Zara2 数据集场景相同,场景中的车辆、建筑物会影响行人对未来路径的规划,本文方法相较于基线方法ADE 分别提高了5.88%、26.19%,FDE 分别提高了47.62%、8.7%.
5.2.3 定性分析
图3 展示了各模型在ETH 和UCY 数据集中各个场景中的轨迹预测可视化对比图.其中图3(a)为ETH 数据集场景下的轨迹预测对比图,该场景两侧是积雪与围墙,场景前方有路障球.从图3(a)中可以看出,仅有本文方法预测的轨迹接近真实轨迹,LSTM、Social-GAN模型预测得到的轨迹与真实轨迹偏差较大.
图3(b)为Hotel 数据集场景下的预测对比图,该场景是位于车站的一个旅馆前,行人的轨迹主要是进出车站或者直行经过旅馆,场景中行人轨迹比较复杂.从图3(b)第一张图像中可以看出行人真实轨迹是直行,但Social-GAN、LSTM 预测行人将会转向.图3(b)第二张图像中可以看出目标行人的真实意图是直行路过,本文方法预测得到行人的轨迹与真实轨迹十分贴合,但Social-GAN 预测行人将会转向进入车站,LSTM 预测的行人行进方向基本正确,但与真实轨迹相差太大.图3(b)第三张图像场景内行人行进方向与图3(b)第一张图像刚好相反,目标行人的真实轨迹是转向,Social-GAN、LSTM 均对行人未来的行进方向判断失误,只有本文方法预测得到的轨迹与真实轨迹最相符.
图3(c)为Univ 数据集场景下的预测对比图,该场景是大学校园的一个交叉路口,该场景中人群密度大,可以看作是典型的拥挤社交场景.人群密度大带来的问题就是行人轨迹无序,社交信息对目标行人的路径规划产生决定性的影响,这体现在目标行人随时会调整前进方向,同时还会因为与其他行人交谈而产生中途长时间逗留的现象.从图3(c)中可以看出,本文方法在该拥挤社交场景中的预测表现显著优于其他的模型,这得益于本文使用的Transformer 网络的自注意力机制与其位置编码器在处理时序问题上的优异表现.

图3 各模型在不同场景的预测轨迹可视化对
图4(a)为Zara1 数据集场景下的预测对比图,图4(b)为Zara2 数据集场景下的预测对比图.两个场景均为商场前的道路,行人的运动轨迹主要为进出商场或者路过.从图4(a)中可以看出在行人稀疏时,各个模型的预测结果大致相似,本文方法预测的轨迹与真实轨迹几乎重合,在各个模型中表现最优.图4(a)中第一张图像展示了行人转向时各种模型的轨迹预测对比图,从图中可以看出LSTM、Social-GAN 模型均未预测到目标的转向,另外从图4(b)中第二张图片可以看出其他模型的预测轨迹会与汽车障碍物发生接触,这显然违背了生活常识,而本文方法预测得到的轨迹明显优于其他模型,这是因为本文方法引入的动态场景信息可以综合考虑到目标旁边的汽车障碍物,从而选择绕过汽车调整行进方向.

图4 各模型在zara1和zara2场景的预测轨迹可视化对比
5.2.4 预测时效分析
表3 中LSTM 模型最为简单,预测的精准度也最低,其预测所耗费的时间为2.7 ms.Social-LSTM 在LSTM 的基础上加入了社会池化模块,计算量大幅增加导致时间开销增加,其预测所耗费的时间为4.2 ms.Social-GAN与本文方法都基于生成对抗网络,需要进行大量前向传播以及通过优化鉴别器进行反向传播更新生成器参数,其中Social-GAN 预测所耗费的时间为29.4 ms,本文方法引入的动态场景信息提取模块会进行多次卷积、池化,所以耗时比Social-GAN 稍长,其预测所耗费时间为34.3 ms.对比结果如表3 所示,虽相对于其它对比方法预测耗时略长,但本文方法在34.3 ms仍然能够预测未来120帧的轨迹,完全满足视频处理实时性的要求(该数据集视频帧率为25 FPS).考虑到本文方法预测精度在对比方法中最高,因此该方法综合表现优异.

表3 各模型预测时效分析
5.2.5 合理性分析
为了进一步验证本文方法的预测结果是否符合日常规范,如图5 所示,本小节分别展示了本文方法在面对静态遮挡物和场景中移动目标时的预测结果(包含场景ETH、Hotel、Univ 和Zara1).为了将可视化的结果更好的展示,在此对每组目标生成10 次轨迹预测结果(多模态轨迹预测).其中(a)、(b)、(c)展示了本文方法面对静态障碍物时的预测结果,(d)展示了本文方法在面对动态障碍物时的预测结果.
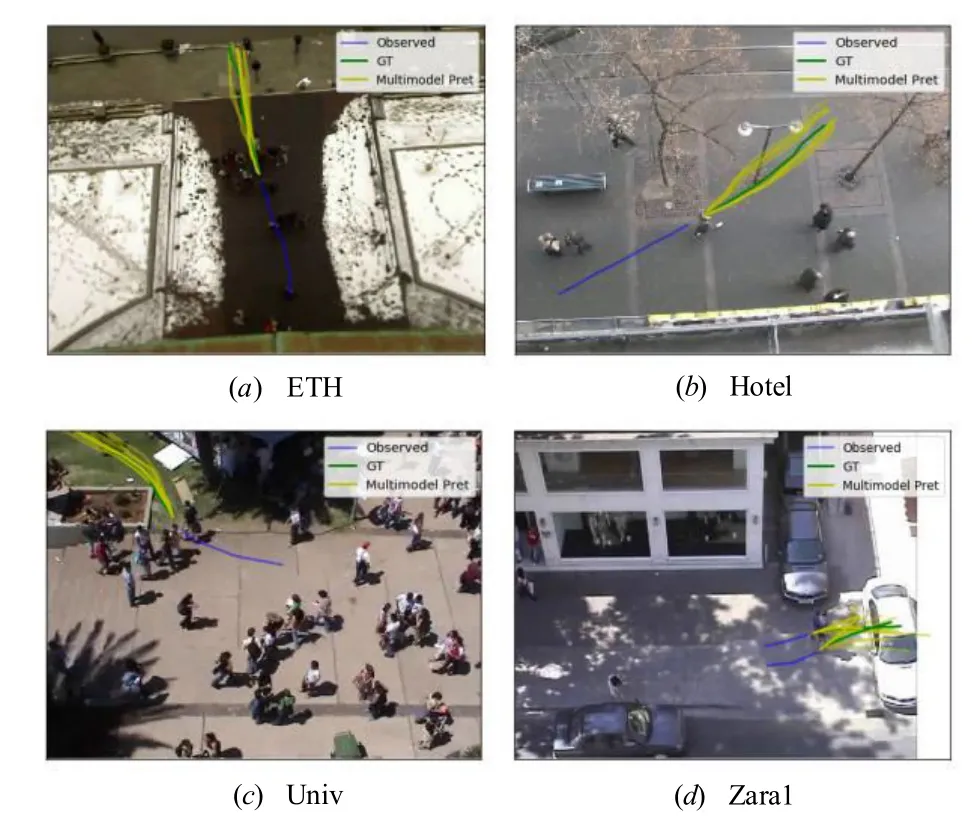
图5 不同场景的多模态轨迹可视化预测结果
从图5(a)中可以看出本文方法在面对路障球进行预测时,其预测的轨迹分布在路障球的左右两侧,从而避开路障球.图5(b)中展示了本文方法预测的轨迹会绕过路灯.图5(c)中展示了本文方法预测的轨迹分布在花坛旁边的空地上.在日常生活中,行人在避让车辆时会让车辆先行通过,本文方法在图5(d)Zara1 场景中生成的轨迹均未与行进中的汽车车头部分接触(图中轨迹与车的其他部分也并未接触,在第4帧之后汽车已经驶离场景).以上场景的预测轨迹符合日常规范,也证明本文方法提出的动态场景信息提取模块是合理有效的,所预测的结果是符合日常规范的.
6 结论
针对目前行人轨迹预测方法对物理环境以及行人间的社交关系利用不充分问题,本文提出了一种基于Transformer 动态场景信息生成对抗网络的行人轨迹预测方法.与其他行人轨迹预测方法相比,本文方法在ETH 和UCY 数据集的多数场景中ADE 和FDE 的表现优于其他方法,在复杂场景中可以较为准确的预测目标行人的轨迹,证明本文方法提出的动态场景信息提取模块与引入的Transformer 网络对模型的预测效果有显著提升作用.但是在拥挤场景中,本文方法的预测效果距离预期还有提升空间.在接下来的工作中,将引入图注意力神经网络对行人之间的社会交互建模,以此提高本文方法在各场景中的预测精度与预测效率.
