Glioma Segmentation-Oriented Multi-Modal MR Image Fusion With Adversarial Learning
2022-08-13YuLiuYuShiFuhaoMuJuanChengandXunChenSenior
Yu Liu,, Yu Shi, Fuhao Mu, Juan Cheng, and Xun Chen, Senior
Dear Editor,
In recent years, multi-modal medical image fusion has received widespread attention in the image processing community. However,existing works on medical image fusion methods are mostly devoted to pursuing high performance on visual perception and objective fusion metrics, while ignoring the specific purpose in clinical applications. In this letter, we propose a glioma segmentationoriented multi-modal magnetic resonance (MR) image fusion method using an adversarial learning framework, which adopts a segmentation network as the discriminator to achieve more meaningful fusion results from the perspective of the segmentation task. Experimental results demonstrate the advantage of the proposed method over some state-of-the-art medical image fusion methods.
Multi-modal medical image fusion aims to combine the complementary information contained in the source images of different modalities by generating a composite fused image, which is expected to be more informative for human or machine perception.During the past few decades, a variety of medical image fusion methods have been proposed. Most existing methods are developed under a popular three-phase image fusion framework, namely,decomposition, fusion and reconstruction [1]. According to the decomposition approach adopted, conventional multi-modal image fusion methods can be divided into several categories including multi-scale decomposition (MSD)-based methods [2]–[4], sparse representation (SR)-based methods [5]–[7], hybrid transform-based methods [8], [9], spatial domain methods [10], [11], etc. Recently,deep learning (DL) has emerged as a hotspot in the field of image fusion [12], [13] and some DL-based medical image fusion methods have been introduced in the literature, such as the general image fusion framework via the convolutional neural network (IFCNN)[14], the enhanced medical image fusion (EMFusion) method [15],the dual-discriminator conditional generative adversarial network(DDcGAN)-based method [16], and the unified and unsupervised image fusion (U2Fusion) method [17].
Although the study on medical image fusion has achieved considerable progress in recent years, it is worth noting that current works suffer from a common drawback, namely, there is a severe lack of clinical problem-oriented study. The primary target of most existing medical image fusion methods is to achieve fused images with pleasing visual quality and high performance on objective fusion metrics that are used in a broader range of image fusion tasks(i.e., not limited to medical image fusion). However, they ignore the specific purpose of the corresponding images in clinical applications,which limits the practical value of image fusion methods to a great extent.
As the most common primary brain malignancy, glioma has always been a serious health hazard to human. In clinical practice, the automatic segmentation of gliomas from multi-modal MR images is of great significance to the diagnosis and treatment of this disease. In this letter, we present a glioma segmentation-oriented multi-modal MR image fusion method with adversarial learning. By introducing a segmentation network as the discriminator to guide the fusion model,the fused images obtained are more meaningful in terms of the segmentation task. The fused modality can strengthen the association of different pathological information of tumors captured by multiple source modalities by integrating them into a composite image, which is helpful to the segmentation task as well as physician observation.
Methodology:
Overall framework: In the glioma segmentation task, the contrastenhanced T1-weighted (T1c) and the fluid attenuated inversion recovery (Flair) are two frequently used magnetic resonance imaging(MRI) modalities. The former one can well characterize the tumor core areas, while the latter one can effectively capture the edema areas that surround the tumor core. Therefore, we mainly concentrate on the fusion of T1c and Flair modalities in this work. Motivated by the recent progress in generative adversarial network (GAN)-based image fusion such as the FusionGAN [18] and DDcGAN [16], we propose an adversarial learning framework for multi-modal MR image fusion. Unlike all the existing GAN-based fusion methods that adopt a classification network as the discriminator model, a semantic segmentation network is used as the discriminator in our fusion framework to distinguish the fused image from the source images,aiming to assist the fusion network (i.e., the generator) to extract sufficient pathological information that is related to tumor segmentation from the source images.
Fig. 1 shows the overall framework of the proposed multi-modal MR image fusion method. The source images IT1cand IFlairare concatenated and fed to a fusion network to generate the fused image If. Two segmentation network-based discriminators are adopted to further improve the capability of the generator in preserving tumor pathological information. The discriminatorDT1caims to distinguish Iffrom IT1cvia the segmentation results on the tumor core area,while the discriminatorDFlairaims to distinguish Iffrom IFlairvia the segmentation results on the whole tumor area. The generator is encouraged to output a fused image with rich pathological information about the tumor area to fool the discriminators. By this means, the proposed framework builds an adversarial mechanism that is mainly concerned with the tumor regions, instead of the entire images considered in previous GAN-based fusion methods. During the training phase, the fused image gradually absorbs the information of the tumor area contained in the source images via alternating training of the generator and two discriminators. The training procedure is summarized in Algorithm 1. In each iteration, the two discriminators are both trainedktimes sequentially and then the generator is trained. Once the generated fused image cannot be distinguished by the discriminators, we obtain the generator as the trained fusion network, which can generate expected fused image that contains sufficient pathological information about the tumor area.accuracy using the fused images obtained by different fusion methods. It can be seen that the fused images of the proposed method achieve much higher segmentation accuracy than those of the other four comparison methods. This observation is in accord with results shown in Fig. 4, which further verifies the significance of the proposed fusion method.
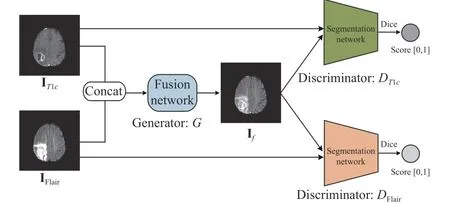
Fig. 1. The overall framework of the proposed fusion method.

Fig. 2. The architecture of our generator network. Conv(nk): Convolutional layer with k filters, BN: Batch normalization, ReLU and Tanh: Activation layers;GAP: Global average pooling, fc: Fully connected layer.

Algorithm 1 Training Procedure of the Proposed Method 1: Initialize the parameters of discriminator and and generator G, k is set to 2.2: for number of training iterations do DT1c DT1c DFlair 3: # Train the discriminator :4: for k steps do{I1f,...,Imf}5: Select m fused images from generator G.I1T1c,...,ImT1c}6: Select m T1c images .DT1c LDT1c 7: Update discriminator parameters by AdamOptimizer to minimize in (7).8: end for DFlair 9: # Train the discriminator :10: for k steps do{I1f,...,Imf}11: Select m fused images from generator G.I1Flair,...,ImFlair}12: Select m Flair images .DFlair LDFlair 13: Update discriminator parameters by AdamOptimizer to minimize in (7).14: end for 15: # Train the generator G:{I1T1c,...,ImT1c}{I1Flair,...,ImFlair}16: Select m T1c images and m Flair images from the dataset.LG 17: Update generator parameters by AdamOptimizer to minimize in (1).18: end for



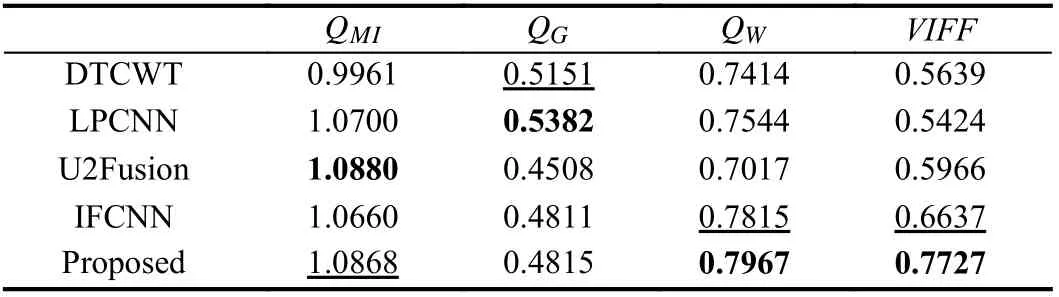
Table 1.Objective Assessment Results of Different Fusion Methods
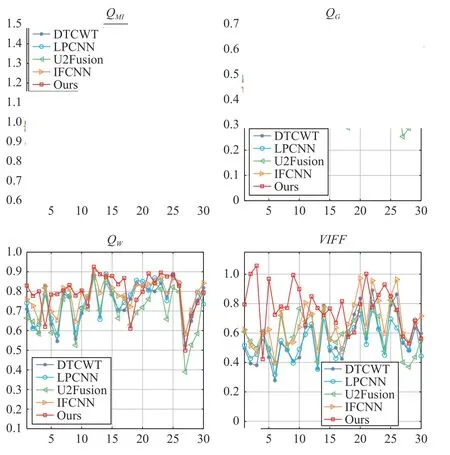
Fig. 3. A more detailed sample-wise comparison on the objective performance of different fusion methods.

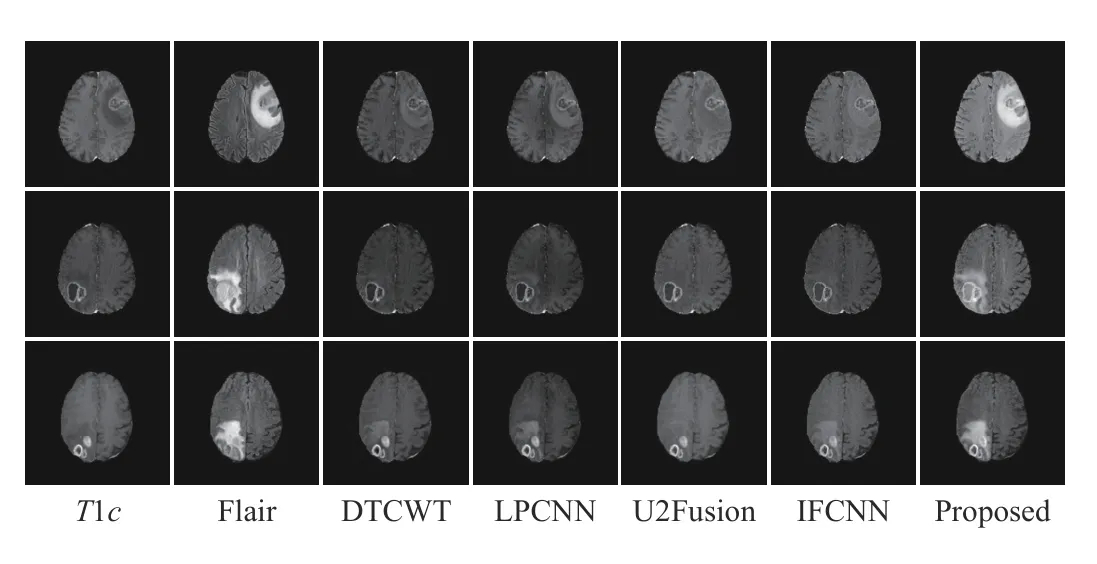
Fig. 4. Three sets of T1c and Flair image fusion results obtained by different methods.
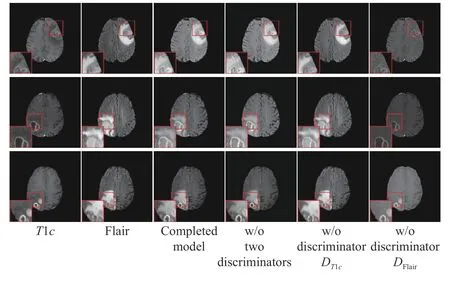
Fig. 5. Three sets of T1c and Flair image fusion results in the ablation study.

Table 2.The Segmentation Accuracy Using the Fused Images Obtained by Different Fusion Methods
Conclusions: This letter presents a glioma-oriented multi-modal MR image fusion method. The proposed method is based on an adversarial learning framework, in which the segmentation network is introduced as the discriminators to guide the fusion network to achieve more meaningful results from the viewpoint of tumor segmentation. Experimental results demonstrate the advantage of the proposed method in terms of objective evaluation, visual quality and significance to segmentation. This work is expected to provide some new thoughts to the future study of medical image fusion.
Acknowledgments: This work was supported by the National Natural Science Foundation of China (62176081, 61922075, 6217 1176); the Fundamental Research Funds for the Central Universities(JZ2020HGPA0111, JZ2021HGPA0061); and the USTC Research Funds of the Double First-Class Initiative (KY2100000123).
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Consensus Control of Multi-Agent Systems Using Fault-Estimation-in-the-Loop:Dynamic Event-Triggered Case
- A PD-Type State-Dependent Riccati Equation With Iterative Learning Augmentation for Mechanical Systems
- Finite-Time Stabilization of Linear Systems With Input Constraints by Event-Triggered Control
- Exploring the Effectiveness of Gesture Interaction in Driver Assistance Systems via Virtual Reality
- Domain Adaptive Semantic Segmentation via Entropy-Ranking and Uncertain Learning-Based Self-Training
- Position Encoding Based Convolutional Neural Networks for Machine Remaining Useful Life Prediction