基于深度强化学习的机械臂控制快速训练方法
2022-08-12赵寅甫冯正勇
赵寅甫,冯正勇
(西华师范大学电子信息工程学院,四川南充 637009)
0 概述
机械臂作为机器人领域中使用最广的一种机械装置,被应用在各个行业,如从工业生产中的仓库管理、汽车制造,到农业生产中的码垛和瓜果产品的采摘分拣。在工业生产中,许多工厂都是使用示教法对机械臂进行控制的,即事先通过手动拖拽或是使用示教器调整的方式,在移动机械臂到达每一个目标位置时保存各个目标的位置信息,然后使机械臂按照目标点的顺序移动。然而,如果在新的应用中目标位置产生变化,则需要重新示教,因此,这种采用示教的方法不仅耗费人力,灵活性也有所欠缺。除了示教法,应用最为普遍的传统控制方法通过运动规划理论对机械臂进行控制。目前的运动规划理论包括正运动学和逆运动学,正运动学的作用是根据机械臂的各轴转动角度计算得到机械臂末端的位置,而逆运动学则根据机械臂末端的目标位置计算得到各轴所需的转动角度。为了实现更灵活的机械臂应用,越来越多的研究人员开始将人工智能的数据驱动方法应用在机械臂的控制中。本文也将引入数据驱动的深度强化学习算法来解决机械臂的智能控制问题。
强化学习是人工智能的一个分支,其通过与环境的交互得到训练数据,利用数据的训练得到控制模型,进而实现智能决策。当前,为了提升模型的表征能力,研究者将深度神经网络引入到强化学习中,将两者优势互补,提出了可在复杂环境中感知并决策的深度强化学习算法。深度强化学习算法能够在高维度和连续状态空间下有效工作,其研究已经在围棋对弈、Atari 游戏等领域取得了较大进展。对于同属连续状态空间的机械臂控制问题,深度强化学习算法也可以很好地加以解决,但存在训练时间消耗巨大的问题。本文提出针对机械臂控制模型先2D 后3D 的训练方法,在保证应用效果的情况下缩短训练时间。
1 深度强化学习算法
1.1 算法介绍
深度强化学习算法作为一种端到端的学习算法,具有很强的通用性,研究者已经利用深度强化学习算法解决了很多智能决策问题:文献[1]提出深度强化学习算法DQN,使智能体学会了玩Atari 游戏,并打破了人类保持的记录;文献[2]同样在Atari 游戏中使用深度强化学习实现了多智能体之间的对战与合作;文献[3]利用深度强化学习优化了仿人机器人的行走稳定性;文献[4]通过策略搜索的方式完成了飞行器的自主飞行;文献[5]在OpenAI Gym 环境下,使用深度强化学习算法完成了对不同结构的双足、四足机器人的仿真训练,并比较了不同算法在训练效果上的差异;文献[6]将深度强化学习加入到目标检测算法中,加快了目标外框的检测速度;文献[7]在超参数的优化中使用强化学习算法,并提出了状态向量、奖励函数和动作的定义方法。
在深度强化学习算法中有以下5 大要素:智能体(Agent),环境(Environment),动作(Action),状态(State),奖励(Reward)。如图1 所示,智能体实时地和环境进行交互,智能体观测到状态(状态由状态向量表征,即描述当前状态的物理量个数和取值)后根据策略输出动作(机械臂各个关节电机的旋转角度),而动作会作用于环境进而影响状态。此外,环境还会根据动作和状态给智能体一个奖励(由奖励函数表征,描述是否达到了目标的一个反馈量化值),而智能体则根据动作状态和奖励更新自身选择动作的策略[8]。通过在环境中的不断尝试,获得最大的奖励值,学习到从状态到动作的映射,这种映射就是策略,以参数化的深度神经网络表示。

图1 强化学习算法流程Fig.1 Procedure of reinforcement learning algorithm
本文中使用的深度强化学习算法是深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法[9],该算法流程如图2 所示。DDPG 算法使用确定性策略梯度(Deterministic Policy Gradient,DPG)算法[10]中的策略网络,采用Actor-Critic 框架[11],并结合深度Q 网络(Deep Q-Network,DQN)[1]中的经验回放以及目标网络(Target_Net)和评估网络(Eval_Net)分开的技巧,在针对连续动作空间的环境中取得了不错的效果。在DDPG 算法架构中包含4 个神经网络,分别是Actor 的目标网络和评估网络以及Critic 的目标网络和评估网络,且2 个Actor 网络的结构完全相同,2 个Critic 网络的结构完全相同。

图2 DDPG 算法流程Fig.2 Procedure of DDPG algorithm
DDPG 算法描述如下:
算法1DDPG
输入Actor 评估网络,参数为θ;Actor 目标网络,参数为θ′;Critic 评估网络,参数为ω;Actor 目标网络,参数为ω′;衰减因子γ;软更新权重系数τ;批量梯度下降的样本数m;目标网络参数更新步数C;最大迭代次数T
输出最优的Actor 评估网络参数θ,最优的Critic 评估网络参数ω
1)随机初始化θ、ω,令θ′=θ,ω′=ω,并清空经验回放集合D。
2)从1 到T(训练总回合)进行迭代。
(1)初始化最初状态s。
(2)Actor 评估网络基于状态s得到动作a=πθ(s)+N。
(3)执行动作a,得到新的状态s′和奖励r,判断是否为终止状态done。
(4)将{s,a,r,s′,done}保存在经验回放集合D中。

(7)使用J(θ)=作为损失函数,通过神经网络的反向传播来更新Actor评估网络的参数θ。
(8)若T%C=1,则通过θ′←τθ+(1-τ)θ′,ω′←τω+(1-τ)ω′更新Actor 目标网络和Critic 目标网络的参数θ′和ω′。
(9)若s′为终止状态,则本轮迭代结束,否则s=s′,并回到步骤(2)。
1.2 状态向量设计与奖励函数
在深度强化学习中,状态向量、奖励函数是决定算法性能的重要组成部分。一个好的状态向量,能够全面地表征当前所处环境的特征,加快模型训练速度。一个适合的奖励函数,能够准确地表征模型任务目标,加快模型收敛速度。在将深度强化学习算法应用于真实问题时,如何设置状态向量和奖励函数是算法成功的关键,因此,需要使用不同的设置方式进行训练,对两者的收敛性和稳定性进行比较分析,寻找最优的设置方式。
对于状态向量的设置方式,往往根据具体问题的物理量通过经验设置。对于奖励函数的设置方式:文献[12]分析了不同奖励方式对强化学习模型最终效果的影响;文献[13]针对传统Q 算法对于机器人奖励函数的定义较为宽泛,导致机器人学习效率不高的问题,提出一种回报详细分类Q(RDC-Q)学习算法,算法的收敛速度相对传统回报Q算法有明显提高。文献[14-16]都是基于内在启发的思路对环境的感知和外部奖励信号进行处理,转化成自己的内在奖励。
1.3 机械臂的算法应用
关于针对机械臂的深度强化学习算法训练,已有许多研究者进行了不同的研究和尝试:文献[17]使用DDPG 算法以机械臂各个关节角度作为状态向量,针对奖励函数设置问题,提出包含单步奖励、回合稀疏奖励和方向奖励的复合奖励函数,并加入优先经验回放的概念,提升了算法的训练速度;文献[18]在OpenAI Gym 的FetchPickAndPlace-v1 环境中,专门针对机械臂控制进行了奖励函数的设计,通过不同奖励函数训练,得到了机械臂通过不同的轨迹到达目标位置的策略;文献[19]采用人工免疫原理对RBF 网络训练数据集的泛化能力在线调整隐层结构,生成RBF 网络隐层,当网络结构确定时,采用递推最小二乘法确定网络连接权值,由此对神经网络的网络结构和连接权进行自适应调整和学习,大幅提高了机械臂逆运动学求解精度。文献[20]提出了基于增广示教的机械臂轨迹规划方法,在经验回放中提前加入少量的示教信息,有效地降低了训练初期的难度,获得了更优秀的性能,并在Gazebo仿真平台下的Kent6 V2 机械臂上得到了验证。在训练耗时方面:文献[21]在Unity 中搭建了包括机械臂和目标物品的3D 模型,直接在3D 模型中通过DDPG 算法控制机械臂到达目标下方,并将其托举起,整个训练过程平均消耗33 h,相较于传统调试方法效率提升近61%。
本文提出先简化模型(2D 模型)再复杂模型(3D模型)的训练方法,使寻找合理的状态向量设置和奖励函数形式的训练时长大幅缩短,由此构建能控制3D 机械臂到达目标位置的深度强化学习算法模型,提升算法效率。
2 模型训练
本文通过深度强化学习算法进行训练得到机械臂的控制模型(一个深度神经网络),其动作是机械臂各转动轴的转动角度,而对于状态向量和奖励函数形式的选取,则根据经验使用不同的设置方式进行训练。
深度强化学习算法的训练过程是异常耗时的,通过对训练模型采取不同的状态向量和奖励函数形式来寻找合理的设置方式,会使得训练时长成倍增长。为缩减训练时间,本文先在不具备物理属性的2D 机械臂仿真模型上进行训练,这一过程主要目的是找到合理的状态向量和奖励函数设置方式,然后基于此设置方式,迁移到具备物理属性的3D 仿真环境中进行训练,3D 仿真环境中的机械臂和现实世界的真实机械臂在物理属性上已经非常接近。本文采用的真实机械臂是越疆科技的Dobot Magician,其在3D 仿真环境Gazebo中的模型与真是机械臂物理属性一致。
2.1 2D 机械臂训练仿真分析
本文所使用的2D 机械臂仿真效果如图3 所示[22](彩色效果见《计算机工程》官网HTML 版)。该2D 机械臂环境以图中左下角为坐标原点,长宽均为400;图中蓝色方块为目标区域,中心点坐标为(100,100),长宽均为40;两连杆为一个二轴机械臂,a 点为固定关节,在整个环境的正中心,坐标为(200,200),b 点和c 点均为自由关节,c 点为机械臂末端,连杆ab 和连杆bc 的长度均为200,用l代替,两者与水平正方向的夹角分别记为θ、α,活动范围均为[0,2π]。根据θ、α和l可以得到中端b 和末端c 的坐标分别为(200+l×cosθ,200+l×sinθ)、(200+l×cosθ+l×cosα,200+l×sinθ+l×sinα)。本文根据目标位置坐标点、自身状态等环境信息,使用不同的状态向量和奖励函数设置方式进行训练,输出θ、α的改变量,从而控制末端c到达目标区域(蓝色方块)。收集每回合的总奖励值和总步数,对比不同设置方式的收敛速度和稳定性,找到合理的状态向量和奖励函数设置方式。

图3 2D 机械臂仿真效果示意图Fig.3 Schematic diagram of 2D manipulator simulation effect
2.1.1 状态向量设置
一个好的状态向量能够完整地展示整个学习的环境特征,这样深度强化学习模型就能够依据这些状态从中学到有价值的策略。好的状态向量在加速模型的收敛速度以及提高模型稳定性上起到了至关重要的作用。
经过分析,最终得到如表1 所示的6 种针对2D机械臂的状态向量设置方法,其中各个参数的具体含义见表2。

表1 2D 机械臂状态向量设置方式Table 1 2D manipulator status vector setting patterns

表2 2D 机械臂状态向量中各参数含义Table 2 Definition of each parameter in 2D manipulator state vector
本文将以上状态设置方法应用在深度强化学习算法中,进行500 回合每回合最大200 步的训练,得到结果如图4~图9 所示。可以看出:使用标准化后的末端和中端坐标以及末端和中端与目标之间的直线距离和x、y两轴距离作为状态的效果最好,收敛速度快,且收敛后稳定其原因如下:

图4 使用2D 机械臂状态向量设置方式1 的训练结果Fig.4 Training results while using 2D manipulator status vector setting pattern 1

图5 使用2D 机械臂状态向量设置方式2 的训练结果Fig.5 Training results while using 2D manipulator status vector setting pattern 2
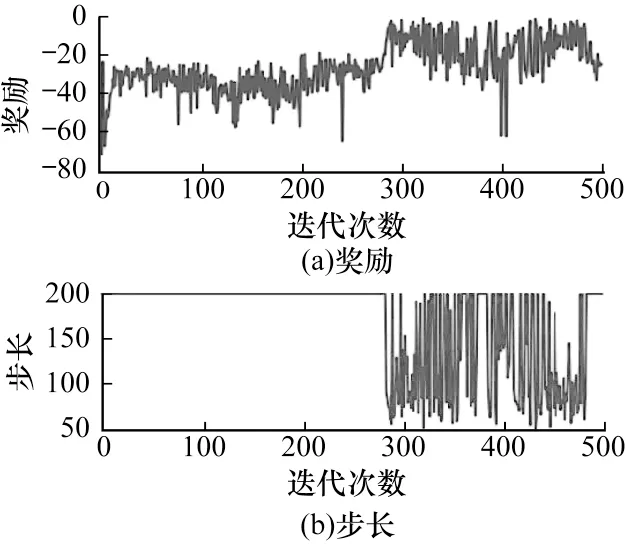
图6 使用2D 机械臂状态向量设置方式3 的训练结果Fig.6 Training results while using 2D manipulator status vector setting pattern 3

图7 使用2D 机械臂状态向量设置方式4 的训练结果Fig.7 Training results while using 2D manipulator status vector setting pattern 4

图8 使用2D 机械臂状态向量设置方式5 的训练结果Fig.8 Training results while using 2D manipulator status vector setting pattern 5

图9 使用2D 机械臂状态向量设置方式6 的训练结果Fig.9 Training results while using 2D manipulator status vector setting pattern 6
1)状态向量中不仅包含了末端坐标,而且还包含了末端与目标的位置关系和中端与目标的位置关系,这样的状态向量能够更详细地描述机械臂整体与目标之间相对位置信息,也使算法模型能够更全面地了解和学习环境。
2)使用标准化或归一化对神经网络训练的输入量进行预处理能够消除奇异样本对训练的影响,加快网络模型的收敛速度。
综合考虑以上因素,本文最终选择表1 中第6 种设置方式作为针对2D 机械臂的最优状态向量。
2.1.2 奖励函数设置
在强化学习领域,奖励函数的设计对于算法收敛速度和稳定性方面也起到关键作用。一个好的奖励函数能够清晰地告诉强化学习算法任务目标是什么,强化学习算法就能够依据奖励函数快速学习。
本文分别选用如表3 中的4 种奖励函数设置方式,各参数的具体含义见表4。选用以上4 种奖励函数设置方式进行500 回合每回合最大200 步的训练,得到结果如图10~图13 所示。

图10 使用2 维机械臂奖励函数设置方式1 的训练结果Fig.10 Training results while using 2D manipulator reward function setting pattern 1

图11 使用2 维机械臂奖励函数设置方式2 的训练结果Fig.11 Training results while using 2D manipulator reward function setting pattern 2

图12 使用2 维机械臂奖励函数设置方式3 的训练结果Fig.12 Training results while using 2D manipulator reward function setting pattern 3

图13 使用2 维机械臂奖励函数设置方式4 的训练结果Fig.13 Training results while using 2D manipulator reward function setting pattern 4

表3 2 维机械臂奖励函数设置方式Table 3 2D manipulator reward function setting patterns

表4 2 维机械臂奖励函数中各参数含义Table 4 Definition of each parameter in 2D manipulator reward function
可以看出:使用执行动作前后距离差作为奖励并没有使强化学习算法很好地了解到任务目的,每回合步数和每回合奖励均未收敛;当单纯地使用末端与目标之间直线距离的负值时,收敛后的稳定性最好;而使用末端与目标之间x、y两轴距离和的负值作为奖励时,收敛速度最快,但是收敛后的稳定性不足;在使用负的距离奖励加上到达目标奖励时,虽然每回合奖励的收敛速度快,但是在收敛后会出现“甩手”的现象(每回合步数大,但是奖励值小,机械臂末端在目标区域边缘晃动)。最终,本文选择使用结果最为稳定的末端与目标之间直线距离的负值作为针对2D 机械臂的最优奖励函数。
2.2 3D 机械臂训练仿真分析
Dobot Magician 机械臂结构如图14 所示,由图中可知,该机械臂主要由底座、大臂、小臂和末端执行器4 个部分组成,连接处有4 个旋转关节Joint1~Joint4,其中,Joint1~Joint3 用于控制末端位置,而Joint4 则用于控制末端执行器的角度。图15 为在Gazebo 仿真环境下的3D 机械臂,是通过越疆公司给出的Urdf模型导出的,其中并没有包含末端执行器,其余机械结构和实物一致。图16 为实物机械臂的图片。

图14 Dobot Magician 结构Fig.14 Structure of Dobot Magician

图15 Gazebo 中 的Dobot Magician 模型Fig.15 Dobot Magician model in Gazebo

图16 实物Dobot Magician 机械臂Fig.16 Real Dobot Magician
根据2.1 节中仿真训练确定的2D 机械臂环境下的最优状态向量和奖励函数,本文将其迁移到3D 环境中,加入了z轴的信息,并对3D 机械臂进行标定,使用机械臂的第三轴Joint3 作为中端mid,末端执行器作为末端end,得到状态向量如下:

使用末端与目标之间的距离的负值作为奖励:

各参数的具体含义见表5。

表5 3 维机械臂各参数含义Table 5 Definition of each parameter in 3D manipulator
在对奖励函数和状态向量设置完成后,使用固定的目标位置,在Gazebo 仿真环境下进行训练,每次500 回合,每回合最大200 步,最终得到的训练结果如图17~图18 所示。可以看出:本文使用的奖励函数和状态向量设置在3D 机械臂环境下,针对固定目标位置的训练效果好,收敛速度快,且收敛后稳定,并没有出现“甩手”的情况。

图17 固定目标位置的训练结果1Fig.17 Training result 1 for fixed target positions

图18 固定目标位置的训练结果2Fig.18 Training result 2 for fixtarget positions
在完成对固定目标位置的训练后,为了能够在真实场景下应用,对目标位置在每回合开始前进行随机的初始化,使用相同的奖励函数和状态向量设置进行训练,每次3 000 回合,每回合最大200 步,最终得到的训练结果如图19~图20 所示。可以看出:每回合的总步数和总奖励在1 000 回合左右收敛,且收敛后的稳定性良好。

图19 随机目标位置的训练结果1Fig.19 Training result 1 for random target positions

图20 随机目标位置的训练结果2Fig.20 Training result 2 for random target positions
以上结果充分说明了本文所使用的奖励函数和状态向量能够很好地描述机械臂所处的环境与任务目标,同时加快强化学习模型的收敛速度,提高收敛后的稳定性。
本文采用2D 机械臂仿真完成状态向量和奖励函数的设置方式选择,并成功迁移到3D 机械臂的训练上。在总耗时方面,包括2D 机械臂仿真中状态向量和奖励函数的探索以及3D 机械臂针对随机目标的训练,平均共消耗约16 h。与文献[21]中直接在3D 机械臂上训练方式相比,训练时间提升了近52%。最终,训练得到的控制模型部署在真实机械臂上,其控制效果达到了应用要求,具体可见https://www.bilibili.com/video/BV12v41117jQ 视频。
3 结束语
在机器人应用领域,一个可以快速控制机械臂到达目标位置完成抓取和摆放的机械臂控制器,能够在很大程度上提高生产效率。本文使用基于数据驱动的深度强化学习算法DDPG 代替传统运动学求解方法,针对2D 机械臂进行训练仿真找到合理的状态向量和奖励函数设置方式,并将其迁移到3D 机械臂的仿真环境中进行训练,最终得到能够快速控制真实机械臂的控制模型。在训练中考虑到强化学习算法训练时间冗长,本文提出先2D 后3D 的训练方式,训练时间相较于直接3D 训练缩短近52%。后续将构建存在障碍物的机械臂操作环境,通过深度强化学习算法训练得到控制模型,进一步提升机械臂操控的智能化水平。
