基于雾天条件下交通道路上的目标检测
2022-08-12管尧朱凯
管 尧 朱 凯
(江苏理工学院,江苏 常州 213000)
1 引言
雾是一种常见的自然天气现象,由于雾霾的存在,增加了图像上的噪音,尤其在交通道路上采集到的图像会因为对比度和饱和度低、视觉效果差的原因,给人们的生活以及各种计算机视觉系统任务的有效性带来严重的影响,如道路上的目标检测、目标追踪和识别系统。
雾天环境下的道路目标检测被分划为两个流程,首先经过去雾处理再进行目标检测。当下,雾天图像的去雾处理主要分为两大类。一类是基于传统的大气退化模型,利用神经网络对模型中的参数进行估算;另一类是利用输入的有雾图像直接输出得到去雾后的图像,即图像增强的方式;其中何凯明等[1]提出基于暗通道先验知识统计的去雾算法,该方法对雾气浓度值估计过高,导致色彩失真;Cai 等[2]提出DehazeNet,利用卷积网络对大气退化模型中的透射率进行估计从而恢复无雾图像。该方法提出了一种新的非线性激活函数,提高了恢复图像的质量,但是在雾气情况较重的场景下,由于透射率估计不准确会出现去雾效果不明显的状况。因此,当下的去雾算法大多是依赖大气散射模型的原理,依次对透射率和大气光值进行估值计算,最终得到去雾后的图片。所以,本文选用基于该理论的去雾算法:AOD-Net 算法[3],它可通过网络训练和学习,能够对雾天的图像特征信息进行有效的提取和增强,并且,无需对传输矩阵和大气光的值进行估算,而是通过轻量级的卷积神经网络直接生成清晰图像,其数据处理的误差更小,模型更小。
目前图像处理在车辆检测识别中也已经发展成熟,在利用深度学习进行目标检测的算法领域,主要分为两大类:两阶段[4-6]和单阶段[7,8]。“两阶段”是先经过对图片生成候选区域,然后将其分类成不同的目标类别,代表模型有R-CNN、Faster R-CNN[9];“单阶段”则将目标检测任务视为一个端到端的回归问题,直接进行预测识别,代表模型有YOLO(You Only Look Once)[10]算法系列和SSD(Single Shot Multibox Detector)[11]算法。
以上算法主要存在以下三个问题:①去雾网络对不同浓度雾的处理性不好,去雾效果不明显。②去雾模型复杂,耗时多,去雾后的图像应用到检测网络中准确率不高。③在雾天图像道路上行人和车辆检测,存在雾天检测数据集不充足。针对以上问题,本文将AOD-Net的去雾网络与YOLOv5的检测网络进行改进结合,其中YOLOv5 在输入端采用了Mosaic 数据增强的方式,通过对数据集进行随机裁剪,打乱布局,随意缩放的方式,达到丰富数据集的效果,并且,YOLOv5 的网络训练框架相对简洁,因此YOLOv5 的检测精度和检测速度更高。同时采用RTTS 的道路雾天数据集,在使用数据增强的前提下,扩充数据集,保证数据集充足,方便提高对雾天环境下车辆识别的检测性能且使得模型更加轻量易于嵌套,其流程图如图1所示。

图1 算法流程图
2 去雾处理
大气中存在雾霾、灰尘等介质时,光的传播会因为这些颗粒的散射导致图片信息不足,细节无法辨识,在很大程度上影响了图片的实用性。图像去雾的目的就是为了消除雾霾环境对图像质量的影响,增加图像的能见度。其中,雾天图片能见度较低以及对比度下降的原因,是由于大气中悬浮的颗粒对光的吸收和散热造成。由McCartney[12]提出的大气散射模型,该模型证明,接收到的光经过传播散射而衰减分为入射光和大气光。其中,传播距离越长,入射光越弱,大气光越强。探测器接收到的大气光成分主要是太阳直射光、大气散射光和地面反射光组成。因此,得到的雾天图片退化模型如式(1)所示:
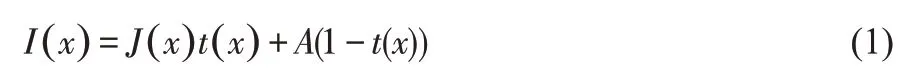
式(1)中:I(x)是指图像的亮度;J(x)是去雾恢复之后的图像;A是全球大气光成分,环境光;t(x)是透射率,取值在[0,1]之间。
当大气均匀时,透射率可以表示为:

式(2)中:β是大气散射的系数,d(x) 为光线传输的距离。该式表达了透射率会随着光线传输距离的增大而呈现出指数型的衰减。
为了使输出J(x)与真实图像之间的重建误差最小,采用自适应的深度模型,其参数将随着输入雾天的图像进行变换;t(x)和A集成到新变量K(x)中,如式(3)所示:

式(3)中:b为恒定偏差,值默认为1。
AOD-Net 算法由两个模块组成:一是K 值估计模块,用于从输入I(x)中估计K(x),二是利用K(x)的清晰图像生成模块,K(x)作为其输入自适应参数来估计J(x),其算法模型如图2所示。
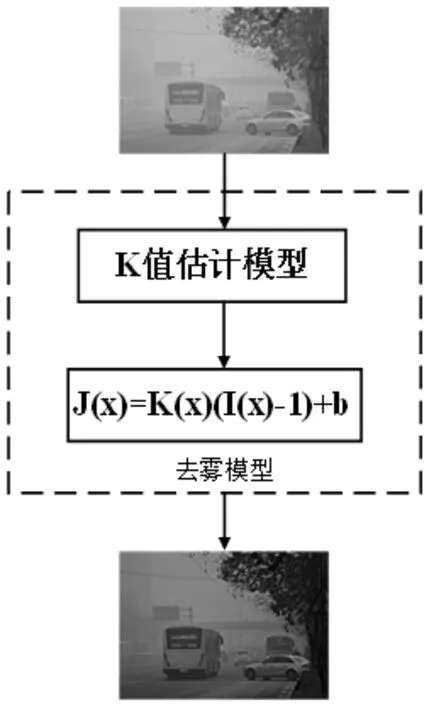
图2 AOD-Net模型
在K值估算模块中,卷积层融合不同大小的滤波器,以捕捉不同尺度的特征。第一层是输入层,每个卷积层只使用3 个卷积核。为了结合从不同卷积层提取的特征,在卷积层之间增加了Concat连接层。Concat1 将Conv1 和Conv2 提取的特征连接在一起;Concat2 连接从Conv2 和Conv3 提取的特征,依次类推。Concat层不仅可以结合各种特征实现从低级特征到高级特征的转换,还可以弥补卷积过程中的信息损失[13]。其模型如图3所示。

图3 K值估算模块
3 目标检测网络
本文采用YOLOv5 算法作为雾天交通道路上的车辆和行人目标检测网络,它是一种单阶段目标检测算法,该算法在之前的基础上添加新的改进之处,使得无论在速度还是精度上都得到了极大的提升,具体包括:输入端的Mosaic数据增强、自适应锚框计算、自适应图片缩放操作;基准端的Focus 结构与CSP 结构;Neck 端的SPP 与FPN+PAN 结构;输出端的损失函数GIOU_Loss[14]以及预测框筛选的DIOU_nms[15]。
3.1 输入端
该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。其中Mosaic数据增强方法,采用了4张图片按照随机缩放、随机裁剪和随机排布的方式进行拼接而成,将几张图片组合成一张,不仅大大丰富了数据集,而且直接计算4张图片数据,减少了GPU的训练负荷,降低了模型的内存需求,提升了网络的训练速度,具体的效果如图4所示。

图4 Mosaic数据增强
其中YOLO算法会根据不同的数据集,预测对应尺寸的锚框(Anchor Box)。在网络训练阶段,模型会对比初始锚框(Anchor Box),根据对比的尺寸差距输出对应的预测框,比较两者与真实背景(Ground Truth)框之间的区别,然后执行逆更新操作,以此更新整个网络的参数,因此设定初始锚框也是比较重要的一环。其中图片的自适应缩放,通常需要执行图片缩放操作,即将原始的输入图片缩放到一个固定的尺寸,再将其送入检测网络中。YOLO 系列算法中常用的尺寸包括416*416,608*608等尺寸。在最初的缩放方法中,由于图片的尺寸不同,经过缩放填充之后,图片两端的黑边大小不相同,相反如果填充过多,则会出现信息冗余的情况,加重算法处理的负担。为了进一步提升YOLOv5算法的推理速度,该算法提出一种方法能够自适应的裁剪图片至合适的尺寸送入网络。
3.2 YOLOv5的主干网络(Backbone and Neck)
主干网络通常包含了许多性能优异的分类器种的网络,其中Backbone 模块用来提取一些通用的特征表示。YOLOv5 中不仅使用了CSPDarknet53 结构,而且使用了Focus结构作为基准网络。该结构的主要思想是通过切片(slice)操作来对输入图片进行裁剪(图5)。原始输入图片大小为608*608*3,经过Slice与Concat操作之后输出一个304*304*12的特征映射;接着经过一个通道个数为32的卷积层,最终输出一个304*304*32大小的特征图。其结构如图6所示。
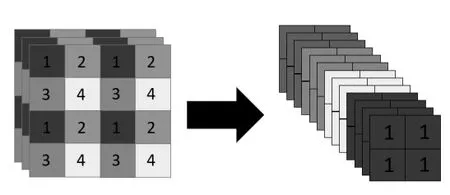
图5 切片操作

图6 Focus结构
Neck模块位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。YOLOv5用到了SPP模块、FPN+PAN模块,SPP模块采用1×1,5×5,9×9,13×13 的最大池化方式,利用Concat 拼接扩充维度的张量,进行多尺度特征融合,SPP 模块图如图7 所示。主干网络Backbone和Neck 中设计了两种不同的CSP 结构:CSP1_X 和CSP2_X,都借鉴了CSPNet 的网络结构,主要优点是在网络模型轻量化的同时保证准确性,同时降低了对计算机设备的要求。CSP1_X 模块由CBL 模块及卷积层Concat 而成,CSP2_X 模块由卷积层和多个残差结构Concat 组成,用于构建深层网络,进一步加强了网络特征融合的能力其模块分别如图8、图9所示。
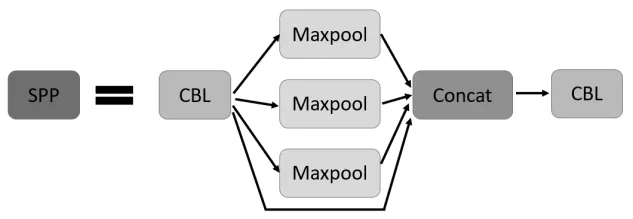
图7 SPP模块

图8 CSP1_X模块图

图9 CSP2_X模块图
3.3 输出端
该端用来完成目标检测结果的输出。其中IoU(Intersection over Union)表示两个方框所在区域的交并比,用于测量真实和预测之间的相关度,相关度越高,该值越高。其计算公式如式(4)。图10 展示了Ground-Truth 和predicted 的结果,绿线代表人工标记的结果,红线代表算法预测出的结果,IoU 利用这两个结果计算算法的精确性,以此来提高车辆检测率。


图10 IoU损失函数算法
YOLOv5中采用由IoU衍生出的GIoU_Loss做预测范围的损失函数。其损失函数公式如式(5),用C和A∪B比值的绝对值除以绝对值C得到闭合区域中不属于两个框的区域比重,最后计算IoU与比重的差,得到GIoU的值。

式(5)中A、B、C的含义如图11所示。
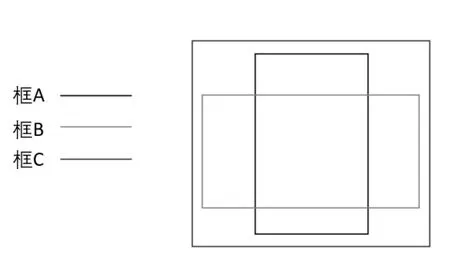
图11 GIoU损失函数算法
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要经过非极大值抑制处理(Non-Maximum Suppression,NMS)[16]。算法可能对同一个对象做出多次检测,NMS可去除冗余的检测框,保留最好的一个。如图12所示。

图12 NMS算法
在YOLOv5中所用到的Weighted NMS[17]的方式,在进行矩形框剔除的过程中,并未将那些与当前矩形框IOU大于阈值且类别相同的框直接剔除,而是根据网络预测的置信度进行加权,得到新的矩形框,把该矩形框作为最终预测的矩形框,再将冗余的检测框剔除。
4 实验结果分析
4.1 实验环境
本次程序设计平台为Python,并同时安装了cuda10.1 和cudnn7.6 用于完成模型的训练与测试。具体实验配置如表1所示。

表1 实验环境
4.2 去雾结果分析
本次实验将NYU2 数据集[18]划分为训练集24443 张图片,验证集2813张图片。以此训练去雾网络,其中初始学习率为1e-4,权重衰减值设为1e-4,一次训练所抓取的数据样本数量为8,迭代次数为10。利用训练得到的模型进行不同雾气浓度下的对比实验,如图13~15 所示,其中图左为原始图片,图右为去雾处理后的图片。最后对真实的雾天数据集RTTS[19]进行去雾处理,应用于目标检测阶段。

图13 轻度雾气下的处理结果

图14 中度雾气下的处理结果

图15 重度雾气下的处理结果
目前常用的去雾算法评价指标有,均方根误差(Root Mean Square Error,RMSE)、峰值信噪比(Peak Signal To Noise Ratio,PSNR)、结构相似度(Structural SIMilarity,SSIM)。其中PSNR 为基于误差敏感的图像质量评价,用于评价两幅图像相比质量的好坏,即失真情况,其公式如式(6)~(7)所示。SSIM 用均值作为亮度(Luminance)的估计,标准差作为对比度(Contrast)的估计,协方差作为结构(Structure)相似程度的度量,其公式如式(8)~(11)所示。RMSE反映的是空间细节信息的评价指标,其公式如式(12)所示。
在图像处理算法中,对一张H×W的图片,MSE 指处理后图像像素值与原始像素值之差平方和的均值,其公式如式(6)所示。

对于一张未失真的图片X 和一张失真的图片Y,SSIM分别从亮度、对比度、结构三方面度量图像的相似性,其公式如下:

式中:C1=(K1L)2,C2=(K2L)2为两个常数,避免除零,L为像素的范围,K1=0.01,K2=0.03 为默认值;一般取C3=C2/2 ;uX、uY为图像X和Y的均值;σX、σY分别为图像X和Y的方 差;σXσY表示图像X和Y的协方差;C1、C2、C3为常数项。

PNSR 和SSIM 值越大,RMSE 值越小,表示图像失真越小;此次分别利用传统的DCP[20]去雾方法得到的数据集和基于色彩增强的MSRCR[21]去雾方法得到的数据集,与经过AOD-Net去雾网络训练得到的数据集与进行对比,得到处理过后的指标,其对比如表2所示。

表2 本文数据集去雾效果的客观评价
分析表2 可知,经过不同的去雾处理后,经AOD-Net 网络去雾后的数据集相比于其他的去雾方法的PNSR值提高了2.16、0.5;SSIM 值提高了0.0398、0.01;RMSE 值降低了16.7、8.2。综上,处理后的数据集,得到了更详细的透射图像,图片信息更加丰富,为车辆检测提供了更好的图像。
4.3 目标检测结果与分析
本次将RTTS数据集划分为训练集3889张图片,验证集433 张图片进行模型训练。该数据集包含的种类以及数据集中检测的目标数如表3 所示,同时本文算法采用Mosaic数据增强,使数据集目标分布更加均衡,并且这种重新组合图像的方式增强数据集的丰富性,使得神经网络训练的鲁棒性更好。

表3 RTTS数据集的相关数据
本次实验部分实验参数学习率为0.0001,权重衰减系数为0.0005,batch_size为8,训练批次为260,采用Adam梯度优化使得模型总损失快速收敛,本次共训练了4个模型,模型1为YOLOv5s,模型2 为AOD+YOLOv5s,模型3 为DCP+YOLOv5s,模型4 为MSRCR+YOLO5s,以此来比对出本文算法的提升效果,具体训练过程参数如图16所示。

图16 不同模型的过程参数
在目标检测领域中,平均精度值(Mean Average Precision,mAP),作为当下衡量网络模型训练的重要参数,其中包含着模型的精确率P、召回率R。其公式如式(13)~(14)所示:

式(13)~(14)中:TP表示实际预测的正样本的个数;FP表示实际预测中假的正样本的个数;FN 为实际预测中假的负样本的个数。

此外,算法检测速度也是衡量算法性能好坏的重要指标。FPS是用来评估目标检测的速度,即每秒内可以处理的图片数量或者处理一张图片所需时间来评估检测速度,时间越短,速度越快。其公式如式(16)所示:

式(16)中:Frame为帧数,second为秒数。
本节使用控制变量法用于验证当前构造的去雾检测算法是较优的结构,并且选取了几张图片进行模型之间的比较。如图17所示,17(a)模型1为YOLOv5s算法下的效果图,17(b)模型2 为AOD+YOLOv5s 算法下的效果图,17(c)模型3为DCP+YOLOv5s算法下的效果图,17(d)模型4为MSRCR+YOLOv5s算法下的效果图。

图17 (a) 模型1

图17 (b) 模型2

图17 (c) 模型3

图17 (d) 模型4
由图17(a)~17(d)知,在雾天条件下的目标检测中,模型2对目标的检测效果明显优于其他3个模型。对交通道路上的目标的定位精度高于其他模型,且检测到的目标可靠度更高。
最终训练结果的具体参数如表4所示,在所选的数据集上模型2的MAP@0.5值相比于其他模型分别提高了1.31%、1.08%、0.73%,模型2 召回率相比于模型1、模型3、模型4 分别提高了3.4%、2.58%、1.78%。模型2 的检测速度FPS 达到了25.0,优于其他3个模型。

表4 不同算法模型间的性能对比
5 结语
本文结合去雾算法与目标检测算法,一方面,适用于不同雾气浓度下的交通环境,去雾效果明显,另一方面,改善了雾天车辆识别精度低、速度慢的问题。实验可见,该方法在真实雾天交通道路上的车辆检测的mAP 值可达81.73%,FPS可达到25.0。并且,相比于其他算法,该目标检测精度更高,泛化能力更好,算法模型更加轻量化,便于嵌套使用;下一步将继续增加数据集的图片数量和不同的雾天场景,从而为未来自动驾驶雾天环境下的车辆和行人检测奠定基础。
