基于多光谱遥感的典型绿洲棉田春季土壤盐分反演及验证
2022-08-08刘旭辉白云岗柴仲平张江辉丁邦新
刘旭辉, 白云岗, 柴仲平, 张江辉, 丁邦新,3, 江 柱
(1.新疆农业大学资源与环境学院,新疆 乌鲁木齐 830052;2.新疆水利水电科学研究院,新疆 乌鲁木齐 830049;3.西北农林科技大学水利与建筑工程学院,陕西 杨凌 712100)
目前,土壤盐渍化已经成为全球性生态环境问题,严重制约着干旱区灌溉农业的可持续发展[1-2]。新疆作为我国重要的农垦区,盐渍土面积约占耕地总面积的1/3,盐渍化问题尤为严重[3]。因此,亟需快速准确获取土壤含盐量变化的监测方法,以支持灌区灌溉制度制定、土壤盐渍化防治、盐碱地综合利用、土地管理等工作[4]。传统的实地采样调查方法不仅耗费大量的人力、物力,而且研究尺度较小,获取的多为点状信息[5-6]。遥感技术能够大面积快速获取同一地区不同时间点的地物信息,有助于开展长时间序列的土壤盐渍化研究工作,加之宏观、综合、及时、动态、低成本等特点,被广泛应用于土壤盐渍化的实时监测和土壤盐分的定量估算等[7]。
随着遥感技术的愈加成熟,学者们开始深入探索提高建模精度的各类方法,其中,光谱参量的构建和建模方法的选取有助于提高遥感反演精度[8]。许多学者采用敏感波段组合、特征光谱指数构建和光谱数学变换等方法创建模型输入变量[9-10]。周晓红等[10]以艾比湖湿地自然保护区为试验区,基于Landsat 8 OLI 多光谱遥感影像,构建了多种植被指数和盐分指数,在众多光谱指数中,增强型植被指数与土壤盐分的相关性最高,传统型植被指数次之,盐分指数最低;张晓光等[11]对光谱数据分别进行了对数、倒数、一阶微分、二阶微分等数学变换,以增强光谱与盐分之间的相关性,进而达到了提升模型反演精度的效果;Zhang 等[12]基于MODIS 卫星影像构建了光谱指数,反演了黄河三角洲地区的土壤含盐量;Alexakis 等[13]针对希腊克里特岛土壤盐渍化问题,基于WV2 和Landsat 8 OLI 计算盐分指数,结果表明,光谱指数S5对土壤盐分最为敏感,可为该地区地表土壤含盐量的监测提供新方案。以上研究表明,筛选敏感光谱变量可以有效提升模型反演效果[8]。除了自变量的优化,建模方法也经历了一段发展历程,从传统的线性回归发展到具有非线性拟合能力的机器学习算法。研究发现,当模型输入变量个数较多、且与土壤盐分的相关性较低时,机器学习的优势得到了更加充分的体现[14]。通过对比不同模型的建模和验证效果,确定了最适合本研究区土壤盐分的建模方法和反演模型,进而提升了土壤盐分遥感反演精度。冯雪力等[15]对比了传统回归方法和机器学习算法的建模精度,发现BP神经网络(Back propagation neural network, BPNN)模型预测效果最优,其稳定性和预测精度均优于经验回归模型;刘恩等[16]基于Landsat 8 OLI 多光谱影像,分别采用多元线性回归和BP神经网络算法构建了土壤盐分反演模型,发现影像光谱反射率和土壤含盐量之间不是单纯的线性关系,因而多元回归模型的预测效果具有很大的波动性,而BPNN 具有极强的非线性拟合能力,因而机器学习模型反演精度更高;张智韬等[17]以内蒙古河套灌区为研究区域,采用多种方法进行建模,发现支持向量机(Support vector machine,SVM)模型精度最高,分位数回归次之,偏最小二乘回归(Partial least squares regression,PLSR)最低。以上研究都说明了机器学习算法在土壤盐分遥感反演过程中的优越性。
土壤盐渍化相关研究虽然取得了一系列较为理想的成果,但现有的遥感反演研究多是基于某一特定时期的遥感影像展开,仅能反映当地该时期的土壤盐渍化状况,模型的推广性不强。而且,盐渍化程度受时空变化影响,不同位置的土壤含盐量存在差异性。因此,探讨某一地区不同年份的土壤盐渍化状况极为重要[18-19]。鉴于此,本文以新疆兵团农二师31 团为研究区域,基于2019、2021 年的Landsat 8 OLI卫星遥感影像和相应时期地表土壤含盐量,利用多元逐步回归(Multiple stepwise regression,MSR)、PLSR、极限学习机(Extreme learning machine,ELM)、SVM 和BPNN 构建土壤盐分遥感反演模型,实现棉田土壤盐分的定量反演,以期为当地土壤表层含盐量的实时监测提供参考。
1 材料与方法
1.1 研究区概况
新疆生产建设兵团农二师31 团位于天山南麓塔里木盆地东北边缘,塔里木河与孔雀河两河下游的冲积平原上,地处巴音郭楞蒙古自治州尉犁县境内,西南临塔克拉玛干沙漠,东北与库姆塔格沙漠接壤,地理坐标为85°24′~88°30′E,39°30′~42°20′N。灌区土壤类型主要为盐土、碱土和风沙土。团场深处欧亚内陆腹地,属北温带大陆性荒漠干旱气候,降水量年际变化大,多年平均降水量53.3~62.7 mm,多年平均蒸发量2273~2788 mm。现有灌溉面积7.5×103hm2,灌溉方式以膜下滴灌为主,灌溉用水来自塔里木河与恰拉水库。生育期灌溉量2700~3450 m3·hm-2,自每年5月开始;冬灌量约为3600 m3·hm-2,自每年11月开始,使用大水漫灌。地下水位保持在1~3 m之间,地下水矿化度2~7 g·L-1;塔里木河与水库矿化度0.47~1.53 g·L-1;灌溉排水矿化度10.58~18.36 g·L-1。
1.2 野外数据采集与处理
野外采样选择在棉花播种前(2019 年3 月20—28日、2021年4月7—12日)进行,该时段为裸土期,受植被影响较小。实地勘察后,按照从水库引水处沿干渠走向布设采样点,同时考虑交通条件、分布位置、土壤类型等因素。2019年和2021年最终采集的样点个数分别为53个和33个(图1)。
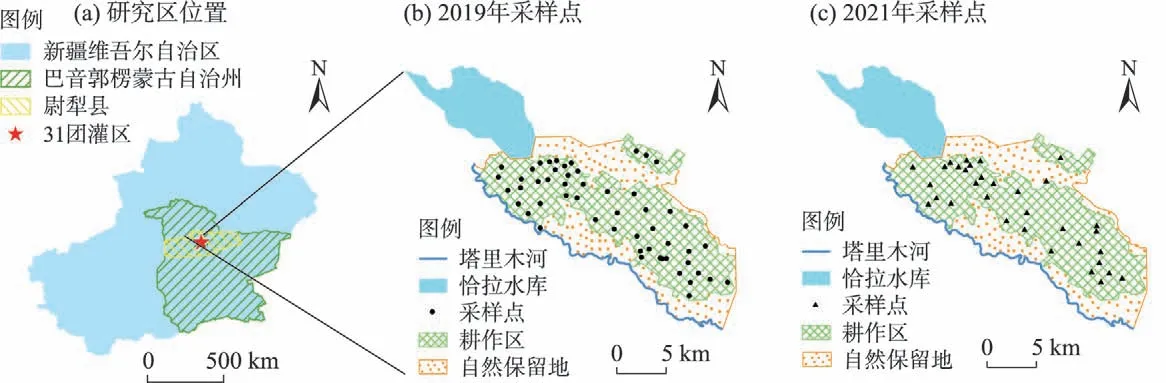
图1 研究区位置及土壤样点分布示意图Fig.1 Sketch maps of the study area location and soil sample distribution
1.2.1 表层土壤含盐量测定考虑到土壤水盐的变异性较强,从预设点向外辐射约10 m的范围内再选取2个点,利用3点取样法采集地表0~20 cm深度的土壤,使用四分法将3处土壤混合,作为该编号位置上的一个样品,随即将样品装入已编号的自封袋中,手持GPS 仪测定每个样点的经纬度,拍照记录各样点处的盐渍化程度、作物类型、植被覆盖度等信息。将土样带回实验室后,挑出杂物,风干,研磨,过2 mm孔径筛,称取18 g土样,在锥形瓶中按土水质量比为1:5 配置土壤溶液,用玻璃棒搅拌均匀后固定在振荡器上震荡10 min,使盐分充分溶解,静置后使用电导率仪测定土壤悬浊液的电导率值(EC,μS·cm-1),根据经验公式:y=0.0051x-0.5241(决定系数R2=0.9534)计算土壤总盐(g·kg-1)[20]。
1.2.2 表层土壤光谱曲线采集与处理选择晴朗、无云、无风的日子,在12:00—16:00之间进行光谱测定。使用美国PP Systems公司生产的UniSpec-SC光谱分析仪(波段范围310~1130 nm)测定土壤光谱反射率。样点观测前需要进行标准白板扫描和暗扫描操作,光谱采集时,探头设置在垂直距离地面50 cm 处,从而缩小仪器视场角,以减小地面背景及周围其他地物对土壤光谱的影响。对不同盐渍化等级的土壤测定多条光谱曲线,每个等级测定10 次,取平均值后作为每个盐渍化等级土壤的实测高光谱数据。土壤光谱采集完毕后,使用Multispec 5.1.5软件对数据进行处理,得到310~1130 nm 波段范围的土壤光谱反射率,在Origin 2018软件中绘制土壤实测高光谱反射率曲线。
1.3 遥感影像数据的获取与处理
多光谱数据采用Landsat 8 OLI 卫星遥感影像,数据来源于美国地质调查局(United States Geological Survey, USGS)官 网(https://earthexplorer.usgs.gov/),行列号143/031,空间分辨率30 m,重访周期16 d。根据与采样时间相近且云量较小的原则,本文选取2019 年3 月22 日和2021年3 月20 日的影像作为本次试验的多光谱数据源。使用ENVI 5.3 软件对影像数据进行辐射定标、大气校正和裁剪等预处理操作,实现遥感数据由数字量化值到辐射亮度值再到地表反射率的逐步转换,再通过ArcGIS 10.2提取各采样点对应的影像多光谱反射率,在Excel 2016中计算各类型光谱指数。
1.4 光谱参量构建
本文选取了7 个波段和12 个盐分指数作为土壤盐分反演模型的备选输入变量,光谱参量及计算公式如表1 所示,包括海岸波段(b1)、蓝波段(b2)、绿波段(b3)、红波段(b4)、近红外波段(b5)、短波红外1 波段(b6)、短波红外2 波段(b7)、盐分指数[归一化盐分指数(NDSI)、SI-T、SI1、SI2、SI3、SI4、S1、S2、S3、S4、S5、S6]。

表1 光谱参量及相关计算公式Tab.1 Spectral parameters and related formulas
1.5 遥感反演模型构建
考虑到土壤盐分受水分的影响,不同时期的灌溉、气温和降水等因素会影响土壤水分和盐分含量,2 期土壤含盐量分布的变异性存在差异。剔除异常值后,将2019年和2021年春季样本数据混合,按照土壤含盐量由小到大的顺序排列分组,根据建模集与验证集2:1 的比例进行等间隔取样[14],最终确定了建模集样本51 个,验证集样本26 个。对建模集影像的波段、盐分指数与土壤含盐量进行皮尔逊相关性分析(Pearson correlation coefficient,PCC),通过分析进行特征光谱参量筛选,将筛出的特征光谱参量分为波段组、光谱指数组和全变量组,并作为输入变量组参与建模,建模方法选用MSR、PLSR、ELM、SVM 和BPNN,共计15 个土壤盐分反演模型。建模方法如下:
(1)多元逐步回归(MSR)
MSR在多元线性回归的基础上进行改进,它能进一步优化公式,确定各个自变量对于因变量预测值的比重,剔除不重要的变量[15,21],是土壤盐分遥感反演最常用的回归方法之一[22]。本研究的MSR 建模与分析基于IBM SPSS Statistics 25完成。
(2)偏最小二乘回归(PLSR)
PLSR 是一种多因变量对多自变量的回归建模方法,能够在一定程度上消除参量之间的多重共线性,通过不断地迭代,最终模型将包含原有的所有自变量[15,23]。本文采用The Unscrambler X 10.4软件进行建模与分析。
(3)极限学习机(ELM)
ELM是一种单隐层前馈型神经网络,具有泛化能力强、人工干预小、学习速度快等优势[24],其特点是输入层与隐含层之间的连接权值和隐含层神经元的阈值随机生成[25]。本研究基于MATLAB 2018平台进行ELM 模型构建,通过反复试验,最终确定了波段组的神经网络模型结构(输入层神经元个数-隐含层神经元个数-输出层神经元个数)为4-11-1,光谱指数组的结构为7-11-1,全变量组为11-7-1。
(4)支持向量机(SVM)
SVM的原理是建立一个最优分类超平面,使其分类间隔最大化[26]。在进行非线性问题的求解时具有泛化能力强、全局最优、结构化风险最小等优势[27]。本文采用LIBSVM 工具箱在MATLAB 2018软件中建立SVM模型,通过测试确定了最适于本实验数据的svmtrain函数参数,SVM类型设置为e-SVR回归,核函数选用高斯径向基核函数(RBF)。惩罚参数(c)和核函数参数(g)根据样本数据进行测试,最终确定了波段组c为900,g为0.25;光谱指数组c为367,g为0.14;全变量组c为4,g为0.09。
(5)BP神经网络(BPNN)
BP神经网络(多层前馈式误差反向传播神经网络)是一种监督学习模型,它通过对代表性样本进行学习训练,从而掌握研究对象的本质特性,具有很强的自组织和自适应能力,能够模拟任意的非线性输入输出关系[28]。本研究基于MATLAB 2018 平台,进行BPNN的结构设计。将建模集的波段组、光谱指数组和全变量组分别作为模型输入因子,土壤盐分作为模型输出因子,建立土壤盐分BPNN 反演模型。经过反复训练,最终确定了最适于本实验数据的BPNN 模型参数,训练函数选用poslin,隐含层传递函数选用purelin,输出层函数选用trainlm,模型最大迭代次数1000次,训练目标最小误差0.00001,波段组的神经网络结构为4-9-1,光谱指数组的结构为7-9-1,全变量组为11-9-1。
1.6 模型评价指标
为量化模型的拟合能力,评价指标采用决定系数(Coefficient of determination,R2)和均方根误差(Root mean square error, RMSE)[29]对模型的建模和验证效果进行综合评价。R2越接近1,表示模型拟合程度越好;RMSE越小,表示实测值和预测值误差越小。因此,R2越大,RMSE 越小,说明模型精度越高,反演效果越好。
2 结果与分析
2.1 土壤盐分特征
根据新疆土壤盐碱化程度等级分类标准[30],将土壤分为非盐化土(0~3 g·kg-1)、轻度盐化土(3~6 g·kg-1)和中度盐化土(6~10 g·kg-1)3 个等级。土壤含盐量的分析结果如表2 所示,总样本统计结果显示,非盐化土、轻度盐化土、中度盐化土所占比例分别为64.94%、27.27%、7.79%,变异系数为0.67,表明棉田土壤含盐量呈中等变异性。

表2 土壤盐分的描述性统计分析Tab.2 Descriptive statistical analysis on soil salinity
2.2 实测高光谱特征
如图2 所示,土壤高光谱波长范围为310~1130 nm。地表土壤含盐量不同导致土壤反射率存在差异,但不同盐渍化等级土壤的光谱曲线相对平行,形态相似,变化趋势基本一致,随着波长的增加,土壤高光谱反射率先减小后增大。波长在310~373 nm 之间,光谱反射率随波长的增加而迅速减小;波长在373~1130 nm 之间,反射率随波长的增加而增大,其中在373~1050 nm 之间,曲线增长较缓,当大于1050 nm时,反射率迅速增大。整体来看,土壤盐渍化越重,光谱反射率越高。
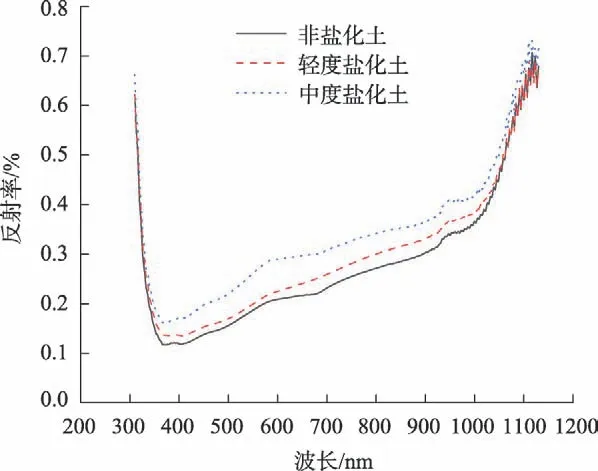
图2 不同盐渍化等级土壤光谱反射率曲线Fig.2 Spectral reflectance curves of soil with different salinization grades
2.3 特征光谱参量优选
根据皮尔逊相关系数界值表[14],样本数(n)等于50 时,当相关系数(r)的绝对值大于0.354 时,表示在0.01 水平上显著,光谱参量与土壤含盐量的Pearson 相关系数如表3 所示,筛选出敏感波段(P<0.01)和敏感光谱指数(P<0.01)。b1、b2、b3、b4波段显著性检验P<0.01,且r均达到0.5 以上,与土壤含盐量的相关性大小依次为b1>b2>b3>b4。SI1、SI2、SI3、SI4、S3、S4、S5盐分指数与土壤含盐量均呈显著相关(P<0.01),相关性大小依次为S4>S5>SI1>SI3>S3>SI2>SI4,且r均达到0.4 以上,说明SI1、SI2、SI3、SI4、S3、S4、S5在一定程度上可以表征土壤含盐量。

表3 光谱参量与土壤盐分的相关性Tab.3 Correlation between spectral parameters and soil salinity
2.4 土壤盐分反演模型构建
选择与土壤盐分显著相关(P<0.01)的b1、b2、b3、b4 波段作为波段组,选择与土壤盐分显著相关(P<0.01)的SI1、SI2、SI3、SI4、S3、S4、S5 盐分指数作为光谱指数组。为了避免模型中遗漏重要的光谱参量,且考虑不同类别光谱参量对模型的影响,将上述4个敏感波段和7个敏感光谱指数共同作为全变量组参与建模。
2.4.1 土壤盐分回归模型由表4 可知,同一变量组作为模型输入变量下,MSR模型建模集R2均高于PLSR,且数值均大于0.340,RMSE 均低于PLSR,且数值均小于1.680,说明MSR 建模效果较好。对模型进行精度验证时,发现波段组的MSR 模型和PLSR 模 型R2相 近,均 大 于0.472,RMSE 均 小 于1.415,验证效果较好。在光谱指数组和全变量组中,PLSR 模型验证集R2均高于MSR,其数值均大于0.448,RMSE均低于MSR,其数值均小于1.448,说明PLSR 验证效果较好。综合对比两种回归方法的不同变量组建模和验证效果,发现基于波段组建立的MSR 模型是表4 所有模型中最优的土壤盐分反演模型。

表4 基于不同变量组的回归模型Tab.4 Regression models based on different groups of variables
2.4.2 土壤盐分机器学习算法反演模型如表5所示,波段组和光谱指数组作为模型输入变量下,建模集的各类机器学习模型R2均大于0.616,其中SVM模型的建模集R2均达到0.768以上,RMSE均小于0.998,建模精度最高,BPNN 模型次之,ELM 模型精度最低。对模型进行精度验证时,发现波段组和光谱指数组的ELM、SVM 模型RMSE 较大。在全变量组中,BPNN模型的建模集和验证集R2均为3个模型中的最高值,分别达到了0.705和0.556,RMSE 分别为1.133 和1.409,模型精度最高,ELM 模型次之,SVM模型精度最低。因此,在3种机器学习算法中,BPNN 模型最适于本实验数据。综合对比3 种算法的不同变量组建模和验证效果,发现基于全变量组建立的BPNN 模型是表5所有模型中最优的土壤盐分反演模型。对比表4 和表5 可知,机器学习模型精度均高于线性回归模型,因此,本文最终使用基于全变量组建立的BPNN 模型来反演31 团春季土壤表层含盐量。

表5 基于不同变量组的机器学习模型Tab.5 Machine learning models based on different variable groups
2.5 土壤盐分空间分布反演
对比图3 和图4 可知,土壤含盐量为6 g·kg-1以上的土壤均分布于灌区中部的盐碱地带上,含盐量为0~3 g·kg-1的土壤均分布于灌区内部远离荒地的区域,越靠近荒地,土壤含盐量越高。由此可知,土壤盐分反演结果与Kriging插值结果基本一致,与调查情况相符,表明耕地盐分反演结果的准确率较高。
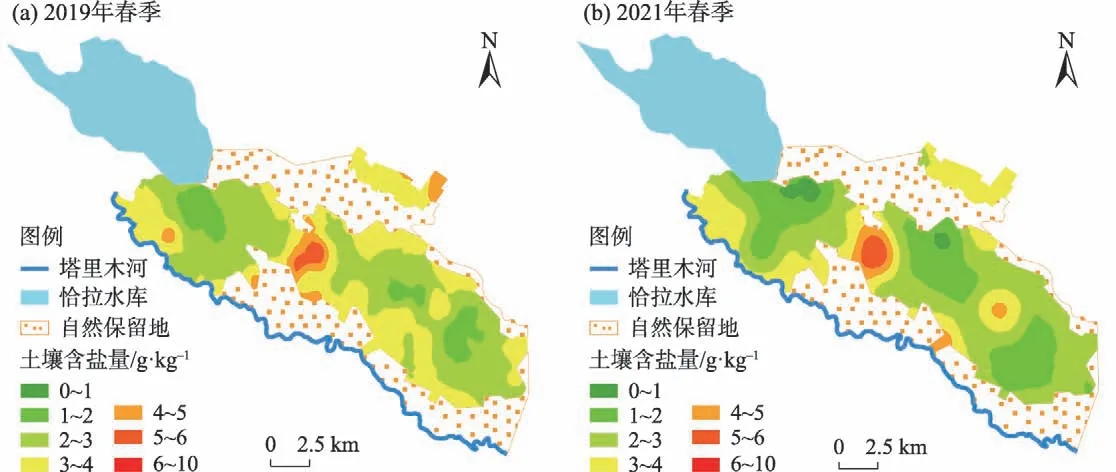
图3 耕作区土壤含盐量Kriging插值分布Fig.3 Kriging interpolation distributions of soil salinity in tillage area

图4 耕作区土壤含盐量反演等级分布Fig.4 Inversion grade distributions of soil salinity in tillage area
如表6所示,2019、2021年春季耕作区土壤主要为非盐化土,分别占耕作区总面积的55.55%和64.62%,其中含盐量为2~3 g·kg-1的土壤分布面积最大,1~2 g·kg-1的土壤分布面积次之,0~1 g·kg-1的土壤分布面积最小。轻度盐化土面积分别占44.31%和35.17%,其中含盐量为3~4 g·kg-1的土壤分布面积最大,4~5 g·kg-1的土壤分布面积次之,5~6 g·kg-1的土壤分布面积最小。对比2 a土壤盐渍化程度,发现2021 年春季非盐化土面积相比2019 年增加了9.07%,轻度盐化土面积缩小了9.14%,中度盐化土面积变化较小。
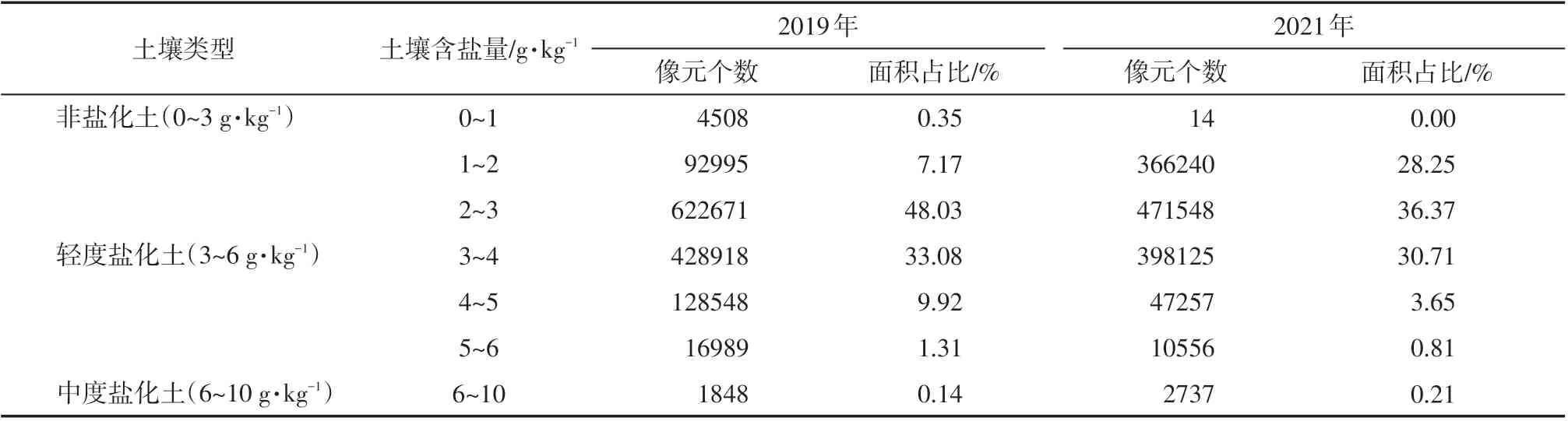
表6 不同盐分层次的像元个数及比例Tab.6 Number and proportion of pixels at different salinity levels
由图4可知,含盐量小于2 g·kg-1的土壤主要分布于恰拉水库附近、耕作区中部和东南部。越接近南北两侧荒地的耕地土壤含盐量越高,东北部的小块耕地盐分偏高,土壤盐渍化程度主要为轻度盐化土。中度盐化土主要分布于灌区中部的盐渍化地带上,与实际影像位置相重合,取得了较为准确的反演效果。此外,东北部的小块耕地部分区域和灌区内的零散地块上也有少量分布。2021 年反演图中绿色更深,即含盐量小于2 g·kg-1的土壤分布面积更大,在整个灌区都有体现。2021 年含盐量大于4 g·kg-1的土壤分布面积相比于2019 年有所减小,图上表现为橙红色区域缩小。综上可知,2021年土壤盐渍化程度较2019年有所减轻。
3 讨论
3.1 盐渍土特征分析及光谱参量优选
棉田土壤含盐量呈中等变异性,说明其易受气候、地形、水文、地质等自然因素和灌溉、翻耕、施肥等人为因素的影响[31-33]。采样时间为2019年和2021年春季,2 a自然环境差异较大,不可控因素较多,因而本文将2 a春季数据混合,以中和不同年份的样本数据变异性,再进行建模集和验证集划分,更具有合理性。本文对建模集OLI 多光谱波段、光谱指数与实测土壤盐分进行相关性分析,发现多光谱敏感波段为蓝、绿、红波段,这与孙亚楠等[2]研究结果一致,说明波段为430~760 nm的土壤盐分光谱信息量较多,而通过波段组进行特征光谱指数的构建可以挖掘光谱与盐分之间的隐含信息,推动土壤盐分遥感定量反演研究的发展。王雪梅等[34]、边玲玲等[35]发现光谱指数与土壤盐分之间存在一定的相关性,在估算应用方面具有很大贡献。本研究也显示,当敏感波段与敏感光谱指数共同作为模型输入变量时,土壤盐分反演模型的建模和验证效果最优。
3.2 土壤盐分反演模型建立
本文基于3 个变量组,使用5 种方法建立了15个土壤盐分反演模型,发现选择不同的输入变量和建模方法,模型效果存在差异。研究发现,基于机器学习模型的精度和稳定性均优于传统线性回归,这是由于土壤盐渍化发生机理的复杂性,土壤光谱特征与表层土壤含盐量之间存在复杂的非线性关系,而机器学习算法具有极强的非线性拟合能力和推广能力,适合模拟变量内部机制的复杂关系。许多学者研究发现机器学习算法的反演效果优于传统回归模型[14,23],与本文的研究结果一致。冯雪力等[15]在进行PCR、MSR和PLSR建模时,发现MSR模型模拟全盐量效果最优,本研究也发现基于波段组建立的MSR模型是6个线性回归模型中最优的土壤盐分反演模型。传统线性回归建模效果虽次于机器学习算法,但其简便易懂,回归方程清楚可见,具有一定的运用价值;机器学习模型可以极大的提升模型反演精度,也具有一定的研究价值。
3.3 土壤盐分时空变化特征
土壤盐分Kriging 插值图基于各采样点处土壤盐分的实测值生成,数据源为点状数据,数据量较小,成果图较为粗略,仅能大致反应土壤盐分的分布状况。而遥感技术能根据土壤盐分反演模型将影像上所有栅格点处的光谱反射率转化为土壤含盐量,由此达到量化效果,再对栅格点数值进行范围划分,可以得出不同盐分层次的栅格点个数及所占比例。对比2 a 土壤盐渍化程度,发现2021 年土壤盐渍化程度较2019 年有所减弱,这可能与气温、蒸发量、灌水量有关。气温越高,蒸发作用越强,土壤中的盐分向表层运移;灌水量越大,对土体淋洗作用越强,土壤表层含盐量越低。而且当地非常重视盐渍土的治理,制定了合理的农业灌溉排水制度和措施,随着时间的推移,取得了一定成效。
已有研究多是针对某一年份的盐渍土进行反演[36-37],但由于每年环境气候多变,且栅格点内地物类型复杂,使得不同年份的遥感影像数据存在较大差异。本研究考虑了不同年份自然环境的差异性,选用2 a春季数据参与建模和验证,通过不断调整模型参数,建立最优反演模型,对春季土壤盐分进行反演,取得了良好的效果,但本次研究对象为非植被覆盖土,未能反演作物生长期的土壤盐分,所以下一步可以尝试研究作物光谱与土壤含盐量之间的关系。另外,试验区自然因素复杂多变,限制了土壤盐分的实时监测,因此反演方法在其他地区和其他季节的适用性还有待进一步研究。
4 结论
(1)棉田土壤主要为非盐化土和轻度盐化土,总样本变异系数为0.67,呈中等变异性。光谱反射率与土壤盐渍化程度的关系表现为土壤盐渍化越重,光谱反射率越高。
(2)通过土壤盐分与OLI 多光谱影像的波段、光谱指数进行相关性分析,发现b1、b2、b3、b4 波段和SI1、SI2、SI3、SI4、S3、S4、S5盐分指数均通过显著性检验P<0.01,相关系数均达到0.4以上。
(3)所有模型中,基于全变量组建立的BPNN模型反演精度最高,建模集R2为0.705,RMSE 为1.133;验证集R2为0.556,RMSE为1.409。综合分析建模和验证效果,选用基于全变量组的BPNN 模型来反演春季棉田表层土壤含盐量。
(4)由反演结果可知,2019、2021年春季耕作区土壤主要为非盐化土,分别占耕作区总面积的55.55%和64.62%,其次为轻度盐化土,分别占44.31%和35.17%。越接近南北两侧荒地的耕作区土壤含盐量越高,东北部的小块耕地盐分偏高。2021年土壤盐渍化程度较2019年有所减轻。
