基于集成学习的铁路隧道空洞敲击检查声音识别
2022-08-05刘振奎张昊宇魏晓悦
高 磊, 刘振奎, 张昊宇, 魏晓悦, 张 奎
(兰州交通大学 土木工程学院,兰州 730070)
隧道衬砌背后空洞是运营铁路隧道中最常见的病害之一,其存在会使衬砌结构在局部产生内力的变化,降低衬砌结构的承载能力,造成衬砌结构的损伤或者破坏,产生巨大安全隐患[1]。因此,如何对铁路隧道衬砌背后空洞进行智能的识别,为铁路隧道的安全服役与长期运营提供重要的理论与技术支撑,已经成为一个重要的研究方向。Lü等[2]将逆时偏移(reverse-time migration,RTM)算法应用于隧道衬砌空洞的高精度成像,提高隧道衬砌空洞检测的精度和成功率,为准确划定隧道衬砌空洞的范围提供了一种科学有效的方法;覃晖等[3]通过对雷达图像进行预处理、特征提取获取机器学习样本,用支持向量机作为分类模型,建立了一种雷达图像智能识别模型,准确识别隧道衬砌和围岩内的空洞;Kurahashi等[4]通过一种高强激光收发设备,分析强激光照射衬砌表面产生的震动,根据震动特征的不同,判断衬砌内部是否存在空洞等内在病害。除此之外,红外成像、图像识别等技术也被用于隧道病害检测。但是先进的检测技术及装备在检测效率、准确度等方面存在不足,与铁路基础设施“精准修、状态修”的理念存在一定差距,导致其普及性差,无法广泛地运用于铁路隧道病害检查维修。人工抵近接触性敲击仍是我国铁路隧道衬砌内部状态检查的主要手段,该方法通过敲击声音人为判断衬砌结构内部是否存在空洞等潜在病害[5]。
声音识别技术被广泛应用于各个领域,通过对声音数据处理及智能分类,实现对病害和故障的诊断以及对危险进行监测。刘思思等[6]用优化的梅尔频率倒谱系数做为训练样本,用人工蜂群算法优化支持向量机(support vector machine, SVM)参数,建立改进的SVM车窗电机异常噪声识别模型,判断电机是否发生异响;王培力等[7]运用支持向量机训练钱塘江潮声的梅尔频率倒谱系数(Mel frequency cepstrum coefficients,MFCC)样本,建立SVM涌潮检测模型,判断钱塘江是否发生涌潮;薛忠军等[8]收集大量标准锤敲击水泥路面的声音信号,以共振峰频率、共振峰振幅、功率谱面积等声音特征参数构建数据集,用Fisher判别分析方法分析,建立判别函数,判断水泥路面是否存在脱空;黎煊等[9]提取猪连续咳嗽声的MFCC特征参数,运用BLSTM(birectional long short-term memory)神经网络训练特征样本,用BPTT(back propagation trough time)训练CTC(connectionist temporal classification)网络,更新模型参数,实现猪连续咳嗽声的识别和疾病的判断;郝洪涛等[10]提出包含时域检测、快速傅里叶变换(fast Fourier transform,FFT)峰值检测、功率谱检测、小波包分解与重构和希尔伯特(Hilbert)包络分析结合、经验模态值分解(empirical mode decomposition,EMD)等方法的声音诊断系统,可实现基于声音信号的托辊故障诊断。但是,尚未有学者用声音识别技术,跟据敲击检查声音对隧道衬砌背后空洞进行智能识别研究。
基于此,本文将采集的铁路隧道空洞敲击检查声音音频文件进行预处理,筛选后得到645个声音样本,用语音识别领域常用的声音处理方法,提取MFCC作为声音特征参数;再将提取得到的声音特征参数的均值作为样本数据,通过梯度提升决策树(gradient boosting decision tree,GBDT)算法进行训练、测试,建立隧道空洞敲击检查声音智能分类模型;最后将该模型应用于实际铁路隧道,对敲击检查声音进行识别分类。该模型相比于优化的支持向量机(cross-validation-support vector machine,CV-SVM)、改进径向基神经网络(particle swarm optimization algorithm-radial basis function neural network,PSO-RBF)等传统的分类模型,具有更高的准确率和更强的稳定性,分类结果更加可靠。为铁路隧道衬砌空洞敲击检查声音智能化识别做出新的探索。
1 声音样本采集
研究数据来源为:兰州铁路局2021年春检期间隧道敲击检查声音。获取声音设备为:采样频率48 kHz的录音笔。音频文件以wav格式储存。为保证录音效果以及得到可靠的声音数据,在检查锤敲击衬砌时开始录音,敲击结束后停止录音。对录音笔采集的声音进行选取,剔除大部分无空洞状态下的敲击检查声音,最终保留98段敲击检查音频文件。
音频文件预处理和特征参数提取基于MATLAB软件中的voicebox工具包实现,对声音数据进行切割处理,得到645个样本数据,其中空洞样本213个,非空洞样本432个。1 s内两种状态下声音信号波形图和短时能量,如图1~图4所示,两种状态下声音信号特征对比,如表1所示。

图1 无空洞状态敲击声Fig.1 Percussive sound in non-voids state
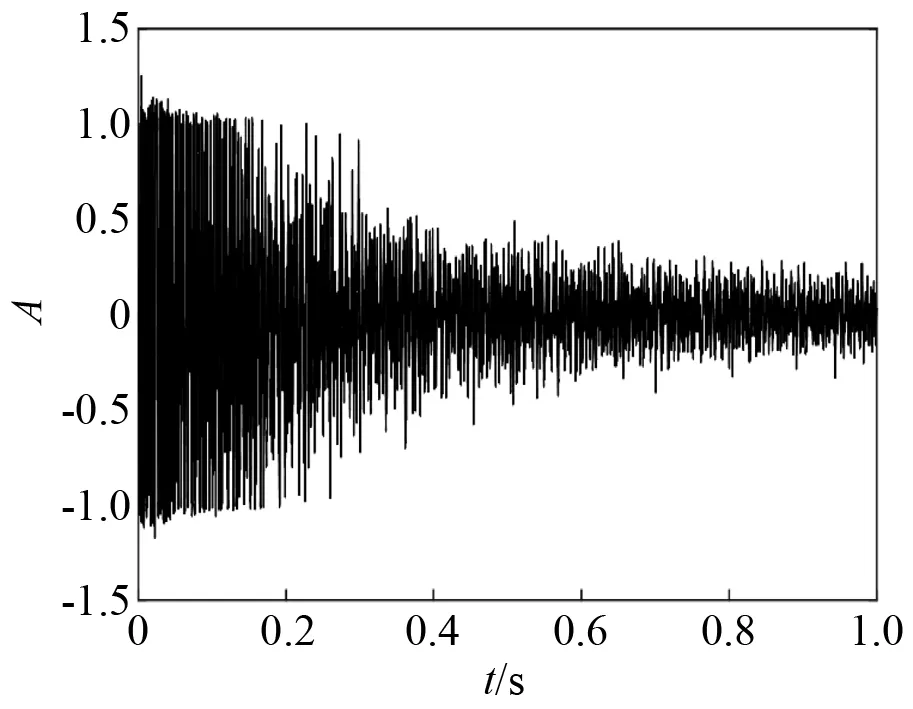
图2 有空洞状态敲击声Fig.2 Percussive sound in voids state
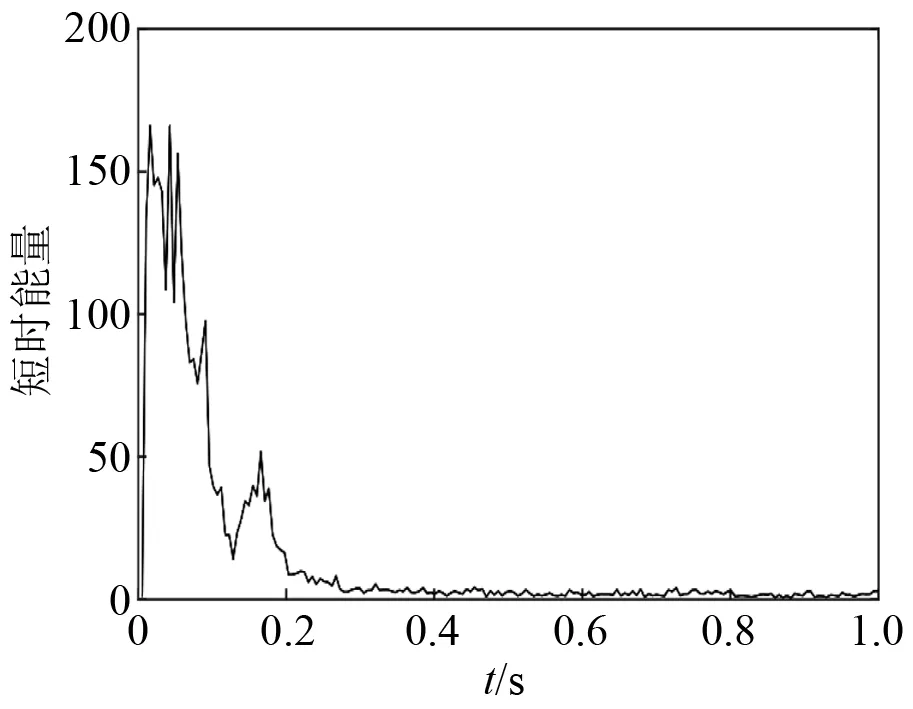
图3 无空洞状态敲击声短时能量Fig.3 Short-time energy of percussive sound in non-voids state
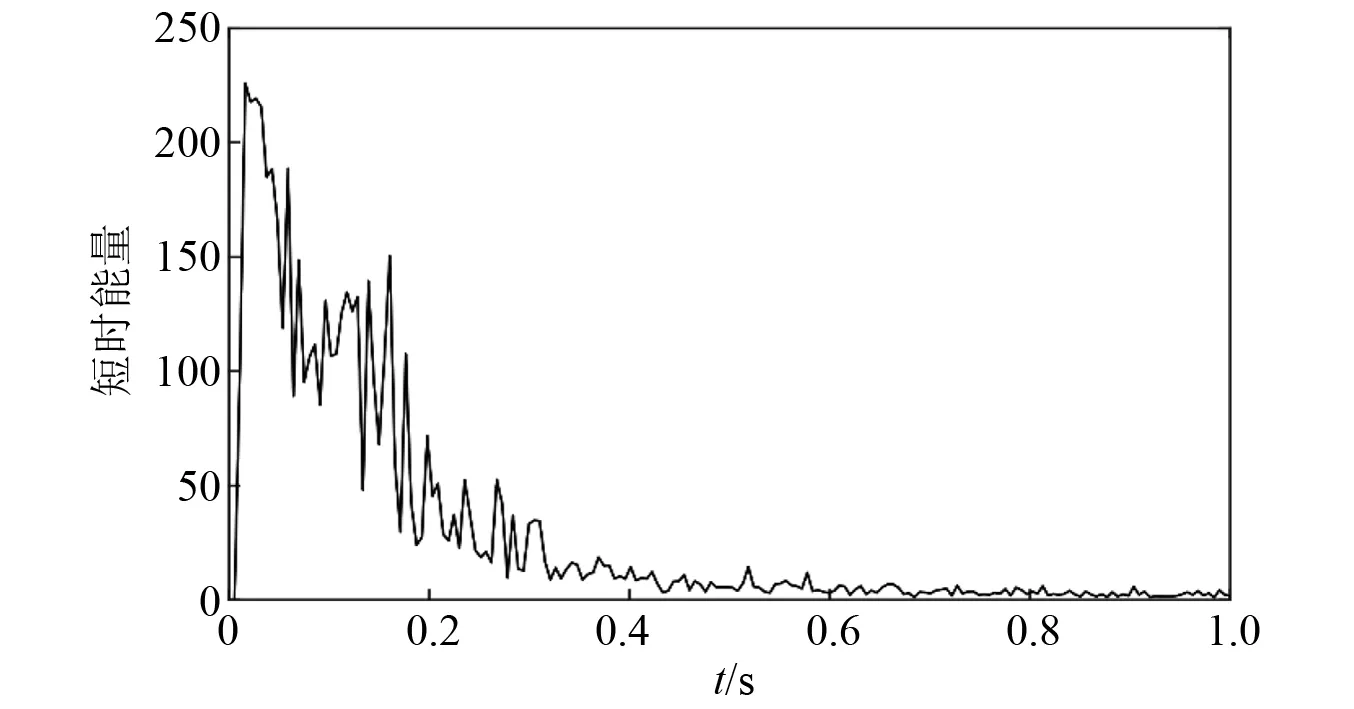
图4 有空洞状态短时能量Fig.4 Short-term energy of percussive sound in voids state
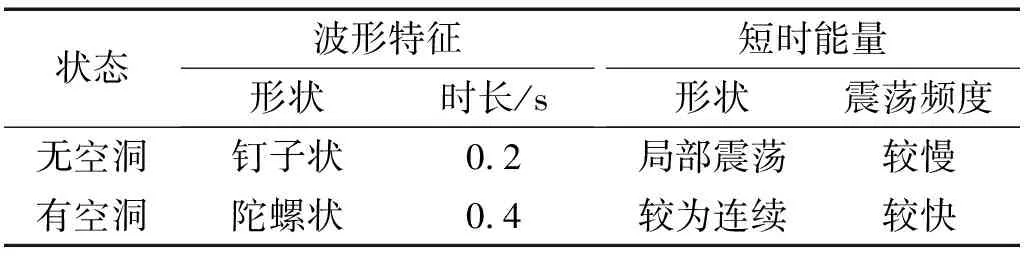
表1 声音信号特征比较Tab.1 Comparison of voice feature
由于检查锤敲击声在隧道内会产生回声,导致无空洞状态下的声音样本在0.2~1.0 s的时间区间和有空洞状态下的声音样本在0.4 s~1.0 s时间区间内,声音幅值和短时能量不为0。
2 声音样本处理
梅尔频率倒谱系数[11]由Davis和Mermelstein在1980年代提出,是基于声音频率的非线性梅尔刻度对数能量频谱的线性变换。由于其更接近与人耳的听觉系统,在语音识别等多个领域有着广泛的应用。MFCC特征参数提取步骤如图5所示。
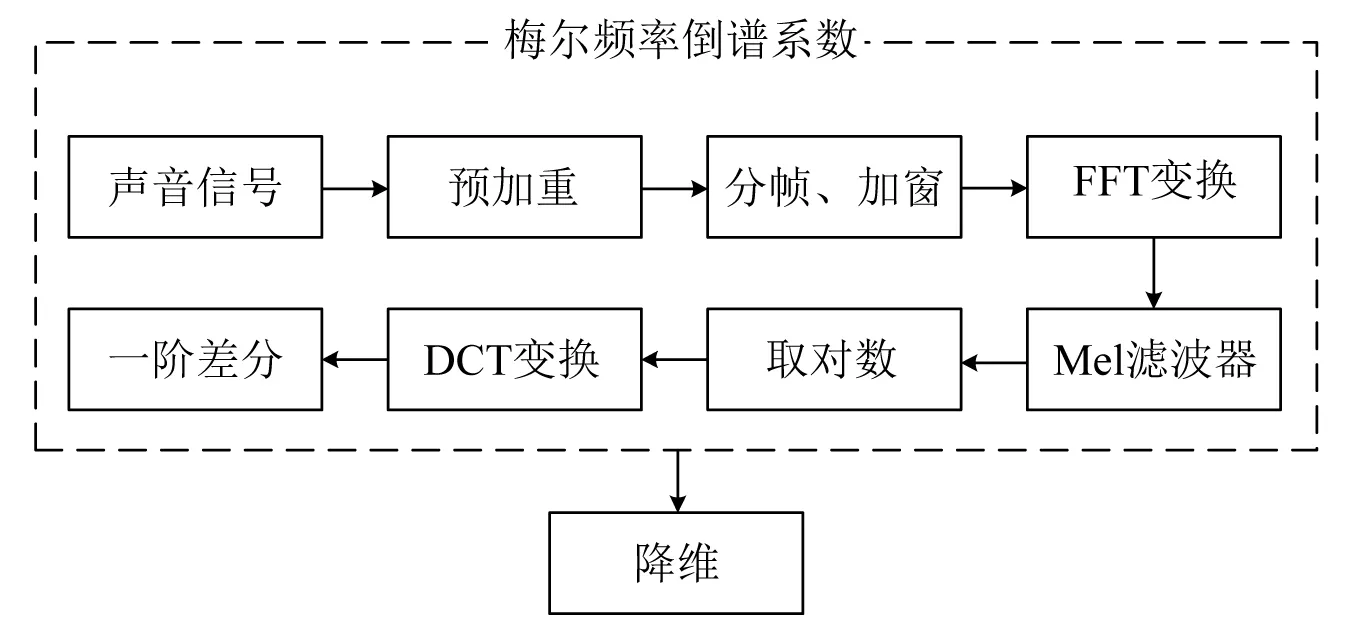
图5 特征参数提取步骤Fig.5 Flow chart of characteristic parameters extraction
2.1 预加重
预加重就是在开始处理声音信号之前,将声音信号通过一个数字滤波器,人为增强高频部分的声音信号。通过预加重补偿检查锤敲击高频部分的声音信号,使信号频谱变得平坦。
高通滤波器传递函数如式(1)所示
H(z)=1-ηz-1
(1)
式中:H(z)为时传输函数;η为预加重系数,通常取0.9~1.0,本文中声音信号预加重系数取0.94。
预处理后结果如式(2)所示
U(n)=u(n)-ηu(n-1)
(2)
式中:U(n)为预加重后的信号;u(n)为n时刻的敲击声音样本值。
2.2 分帧、加窗
声音信号具有短时平稳性,即在短时间内,声音信号的特征处于相对稳定状态。声音信号的分析和处理就是建立在“短时分析”的基础之上,分帧就是将声音信号分为若干个可以进行短时分析的片段。为了使两帧之间保持连续、平滑过渡,需要使前后两帧相互重叠,重叠部分称为移帧。文中帧长K取值为256,相邻两帧之间的重叠区域为80,约为K的1/3。加窗为汉明窗,如式(3)所示。
(3)
Sj(n)=φ(n)Fj(n), 0≤n≤K-1
(4)
式中,φ(n)为分帧后各帧的语音信号。
2.3 提取特征参数
(1) 用快速傅里叶变换对分帧加窗后的的样本数据通过式(5)处理后得到音频频谱,信号的功率谱由对信号频谱的模取平方后得到。
(5)
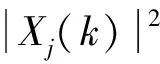
(6)
式中,N为傅里叶变换的点数,取默认值。
(2) 将得到的功率谱通过梅尔三角滤波器式(7),得到梅尔刻度,并提取每个刻度上对数能量。
(7)
(8)
式中,L为三角滤波器的阶数,取值为24。
(3) 最后用离散余弦变换(discrete cosine transform,DCT)最终得到MFCC系数。

(9)
式中,M为MFCC的阶数,通常取值12。
(4) 能量和差分
由以上步骤提取的特征将每一帧单独考虑,是静态的,而实际声音是连续的,帧与帧之间是有联系的,为了表示这种帧与帧间的动态变化,取MFCC特征参数的一阶差分,作为这种动态变化的表示。最终得到MFCC特征参数为24维,包括12维MFCC特征参数和12维一阶差分。
2.4 特征参数降维
对于不同声音样本,组成声音信号的帧数不同,通过MFCC特征提取得到的矩阵大小也不同,且矩阵行数均在500行以上,需要对数据进行降维处理。将各段语音的MFCC特征向量取均值,分别得到1×24维的向量,作为该段语音的特征,同时作为分类模块的输入向量。均值能很好地表示空洞声音和无空洞的敲击声的声音特征,绘制MFCC特征的前12维幅度图(如图6、图7所示)。由于空洞大小不同,敲击发出的声音特征变化明显,而无空洞情况下,敲击声音单一,声音特征变化不大。

图6 无空洞状态12维MFCC均值Fig.6 Average value of 12D MFCC in non-voids state

图7 有空洞状态12维MFCC均值Fig.7 Average value of 12D MFCC in voids state
3 研究方法及模型建立
3.1 集成算法
集成学习[12]是通过组合多个基础学习者的预测来解决不同机器学习问题的一种最先进的方法。集成学习又称为基于委员会的学习或多分类器系统。如图8所示,一个集成由多个个体学习器组成,可以是决策树、神经网络、支持向量机等算法,再通过某种结合策略将各个体学习器结合起来。若集成只包含同种类型的个体学习器,此时生成的集成称为“同质集成”。通常,集成学习一般会获得比单一学习器有更强的泛化能力,可训练出更准确、更稳定的模型。
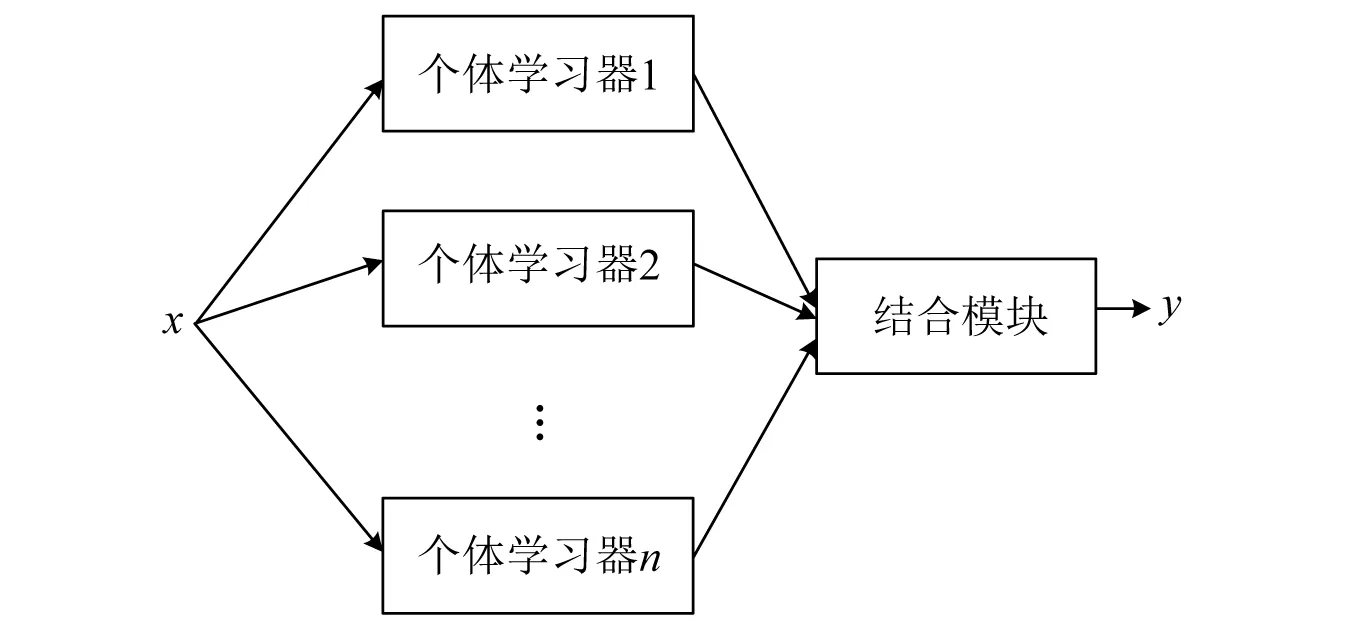
图8 集成学习框架Fig.8 Ensemble methods framework
Bagging、Boosting、Stacking是三类常见的集成算法结合策略 。Bagging是一种并行的集成方法,其原理是从整个训练集中通过有放回的采样得到若干个训练子集,用来训练不同的基学习器,在进行分类时,对基学习器分类的结果进行投票,获胜者作为分类任务的结果。Boosting是一种串行的集成方法,通过纠正弱分类器犯的错误,使弱分类器集成得到一个有着更完美的性能强分类器。Stacking是直接用所有的训练数据对第一层多个模型进行k折交叉验证,这样每个模型在训练集上都有一个预测值,然后将这些预测值做为新特征对第二层的模型进行训练。
3.2 GBDT梯度提升决策树
GBDT适用于多种问题,包括回归,Logistic回归、多项式分类和生存模型,是一种当下流行的机器学习算法。该算法的基础是分类回归树算法。由于普通的分类回归树容易受到训练数据中微小扰动的影响,通过将多棵分类回归树用Boosting结合策略集成,弱化微小变动对CART的影响,将一组弱学习器变为一个强学习器,兼具Boosting算法和CART的优点。用原始指标生成的第一棵决策树,每一次迭代都会使损失函数沿着其梯度方向下降(每次迭代都使CART的损失值最小),多次迭代后残差趋近于0。GBDT建模过程如下:
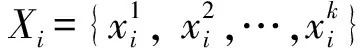
(1) 初始化基学习器
(10)
式中:f0(x)为只有一个根节点的初始决策树;L(yi,c)为损失函数;c为使最小损失函数最小化的常数值,一般取y的均值。
本文中空洞敲击检查声音识别是一个二分类问题,一般采用对数似然损失函数作为损失函数[13]。即
L[y,f(x)]=ln{1+exp[-yf(x)]}
(11)
(2) 确定迭代轮数t=1,2,…,T
①求得训练样本的负梯度
(12)
②利用所有样本及负梯度方向(xi,rti)(i=1,2,…,m)拟合一颗分类回归树中的回归树,得到一颗由J个叶子节点组成的回归树,则第t个叶子节点区域为Rtj(j=1,2,…,J),那么各叶子节点的最佳拟合值为
(13)
③更新学习器
(14)
(3) 经过T次迭代后,得到最终的识别分类模型为
(15)
3.3 空洞检查声音识别模型的建立
本文分类模型程序设计开发环境为Anaconda 3,所用语言为Python 3.8。采用机器学习常用的Scikit-learn模块实现。
(1) 样本分割
将提取到的MFCC特征的均值作为训练和测试的样本。按照机器学习常用划分方法,测试集和训练集按4∶1的比例划分。训练集用于模型训练;测试集用于检验模型的准确率,调整参数,监控模型是否发生过拟合,并在在模型最终训练完成后,评估其泛化能力,测试其真正的预测准确率。
(2) 模型输入输出
在语音识别系统中,通常对MFCC特征进行归一化后作为模型的输入数据。无量纲化的数据不仅可以降低噪声的影响,还可以加快机器学习的收敛速度。样本输出为“0”和“1”,分别表示衬砌背后“无空洞”和“有空洞”。
(3) 模型训练及参数选择
为了充分验证构建的GBDT集成学习模型的有效性,将样本用GBDT模型、交叉验证求最优参数的支持向量机模型[14]和粒子群算法改进的径向基神经网络模型[15]进行训练。经调参后的参数设置如表2所示。

表2 模型参数设置Tab.2 Model parameter setting
(4) 模型性能对比
在机器学习领域,用来评价分类模型常见的分类性能度量指标有准确率A、查准率P、查全率R、综合评价指标F1度量(F1-Score)[16],各个指标计算公式为
(16)
(17)
(18)
(19)
式中:TP为实际为“有空洞”类的样本预测为“有空洞”类的样本数;TN为实际为“无空洞”类的样本预测为“无空洞”类的样本数;FP为实际为“无空洞”类的样本预测为“有空洞”类的样本数;FN为实际为“有空洞”类的样本预测为“无空洞”类的样本数。
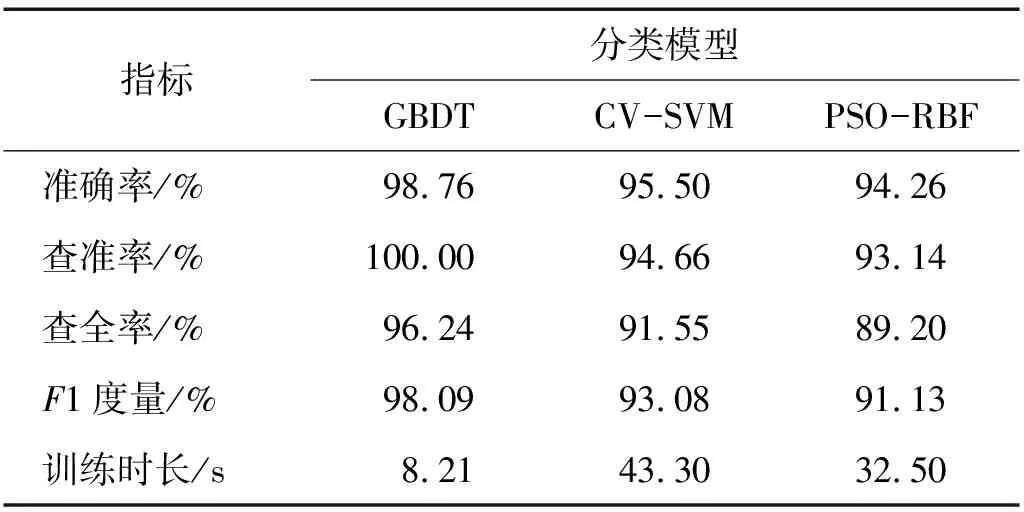
表3 模型性能对比Tab.3 Model performance comparison
通过交叉验证调参后的支持向量机模型可以达到较好的准确率(95.5%),但是耗费大量的时间。PSO-RBF模型的经过10次训练,将训练结果的准确率取均值,得到的平均准确率为94.26%,但同样在粒子寻优过程中耗时较多。对本文中衬砌空洞敲击检查声音特征参数组成的数据集而言,GBDT模型在准确率(98.76%)和训练时长两方面均优于CV-SVM和PSO-RBF模型。
4 工程应用
4.1 工程概况
某隧道为单线隧道,全长4 373 m,隧道中心里程为DK37+391.5。该隧道进口里程为DK35+205、进口端1 475.726 m位于R=1 600 m的左偏曲线上,出口里程DK39+578,其他2 897.274 m位于直线上。隧道最大埋深674 m。其中Ⅱ、Ⅲ级围岩3 015延米,占比69%,Ⅳ、Ⅴ围岩,风积砂段占31%;在隧道施工阶段,进口267 m风积砂段采用施做维护结构及水平旋喷桩预支护后暗挖的方式完成,为该隧道的难点工程。DK35+205-300,DK39+566-578段采用明挖法施工,设置明洞衬砌;其余段落均采用暗挖施工,设置复合式衬砌,暗锚喷构筑法施工,钻爆法开挖。隧道进出口均采用双耳式洞门,洞口永久边仰坡均采用骨架空心砖间值低矮灌木防护。
隧道运营期间,DK37+893-DK38+093衬砌出现裂缝,部分裂缝伴有渗水病害。对比该隧道检测报告,该段隧道空洞情况如表4所示。
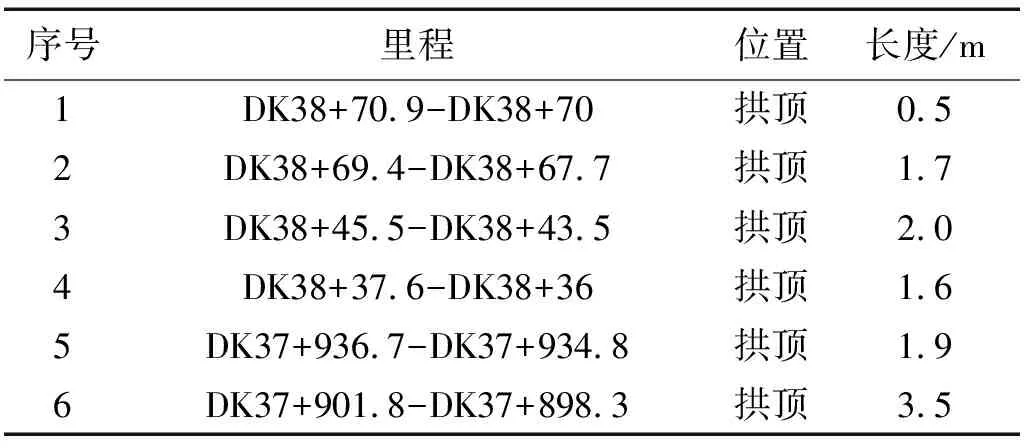
表4 实际空洞情况Tab.4 Actual voids situation
4.2 结果与讨论
对表4中6处隧道空洞所在位置进行敲击检查,并录制6段敲击声音样本(编号为分别为Q-1~Q-6),再取4段无空洞状态下的声音样本(编号为Q-7~Q-10),共同组成验证本文模型的样本集。分别用训练好的GBDT模型,CV-SVM模型和PSO-RBF模型进行分类,得到分类结果如表5所示。
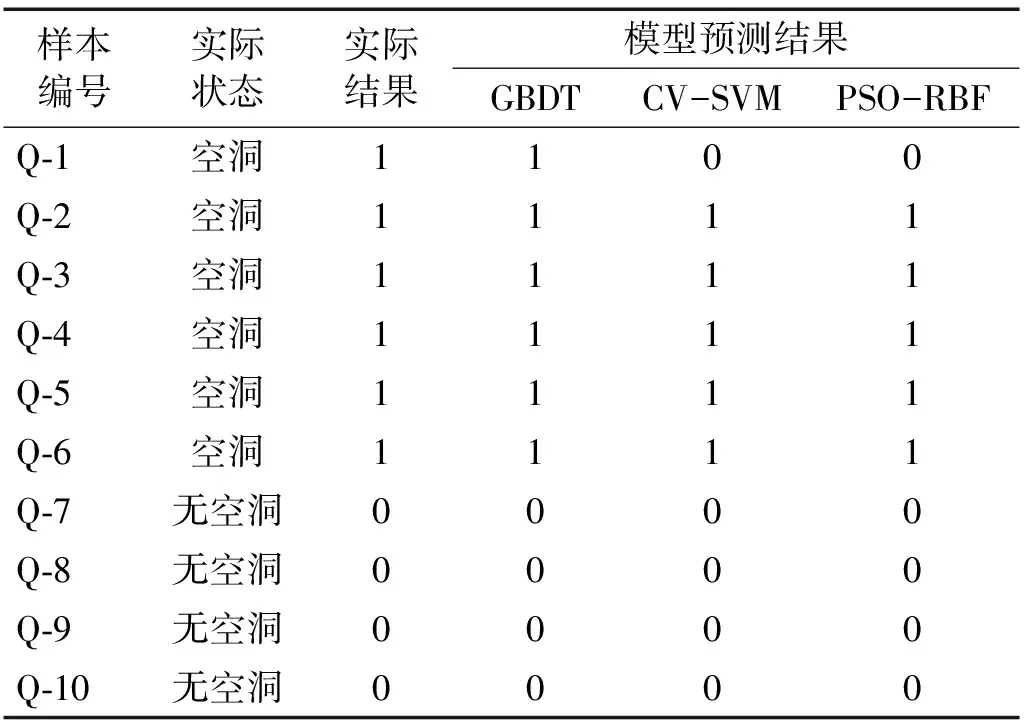
表5 实例验证对比Tab.5 Comparison of example verification
在实际应用中,GBDT集成算法模型能够准确对10个样本进行分类,CV-SVM模型和PSO-RBF模型在对样本Q-1识别时均出现错误,说明三个模型均能识别无空洞状态的衬砌敲击声音和较大空洞的敲击检查声音,但在空洞范围较小时,GBDT模型的分类效果优于其他两种模型。
5 结 论
(1) 通过采集、处理隧道衬砌空洞敲击检查声音,提取声音样本的梅尔频率倒谱系数,作为空洞敲击检查的声音特征。随着空洞的不同,根据敲击声提取到的特征也表现出不同的变化幅度。
(2) 运用GBDT集成算法建立衬砌空洞敲击检查声音智能识别模型,与普通机器学习模型相比,GBDT具有更高的准确率和更少的运算时间,在面对异常数据时具有更强的稳定性,能够根据铁路隧道拱部空洞敲击检查声音准确的识别衬砌是否存在空洞。
(3) 针对铁路运营隧道,我国目前尚缺乏有效的检测数据信息化及管理工具。将声音识别的相关理论与技术应用到隧道衬砌空洞识别,为隧道空洞智能识别提供一种新的思路。目的是通过结合计算机视觉、软件开发等技术达到病害智能识别和检查的数据自动记录,为病害智能诊断、现场无纸化检查、多源数据3D融合等信息化管理手段做出探索。
