基于注意力YOLOv5模型的自动水果识别①
2022-08-04曹秋阳邵叶秦
曹秋阳,邵叶秦,尹 和
1(南通大学 信息科学技术学院,南通 226019)
2(南通大学 交通与土木工程学院,南通 226019)
近年来,随着科学技术的快速发展,人工智能给人们生活带来了便捷和智能化的服务. 水果自动识别在超市、菜市场、果园等很多场景有着重要的应用. 超市以及菜市场可以结合水果称重,自动计算水果的价格,提高顾客购买的效率. 果园可以通过水果的检测与识别,估计水果的收成,并利于机械化自动采摘.
目前,越来越多的国内外研究人员聚焦果蔬识别.彭红星等[1]提出一种改进的single shot multibox detector(SSD)水果检测模型,将SSD 模型主干网络VGG16 替换为ResNet-101 网络,并通过随机梯度下降算法以及迁移学习思想优化SSD 模型,在4 种水果上的检测精度达到88.4%. 王辉等[2]在Darknet-53 网络的基础上使用组归一化代替原先的批量归一化,继而引入YOLOv3[3]算法构建水果检测模型,实现水果的准确识别. Bargoti 等[4]设计了基于Faster-RCNN 的目标检测模型实现自然环境下3 种水果的检测. Liu 等[5]提出了single shot detector 方法,用于对象的检测和识别,在保证准确率的同时提高了效率. 这些方法普遍存在如下问题: (1)数据集中水果种类过少; (2)模型倾向于对象的全局信息,容易忽略某些关键及重要的水果局部信息; (3)目标框与预测框重合时未考虑它们之间的相互关系,容易出现预测结果不精确问题.
因此,本文采用包括不同光照、不同角度等的15 种水果组成的数据集,并使用基于注意力的YOLOv5模型实现水果的准确分类和识别. 具体来说,该模型在主干网络后增加注意力机制squeeze-and-excitation networks (SENet),通过神经网络计算通道注意力权重,以增强水果的重要特征,减弱不重要的特征,使提取的特征更具代表性且保留局部的重要信息,提升水果识别的准确率. 同时,将原先的GIOU损失函数替换为包括边框长宽比信息和中心点位置关系的CIOU损失函数,使预测框更加接近真实框. 实验证明,本文基于注意力的YOLOv5 模型在准确率及速度上都优于目前最新的水果识别算法.
1 YOLOv5 模型
YOLOv5 是由Ultralytics LLC 公司提出的深度神经网络模型. 相比于早期的YOLO 模型[3,6],YOLOv5模型体积小、速度快、精度高,受到工业界的青睐. 具体来说,对比于YOLOv4,YOLOv5 进行了如下改进.首先,对输入图片经过Focus 切片操作,保留了更完整的图片下采样的信息; 其次,采用CSPDarknet-53 主干网络进行特征提取,分别在主干网络以及Neck 部分设计了两种CSP 结构用来调整残差组件的数量以及卷积层数量; 最后,在Neck 部分输出小、中、大3 层特征.虽然YOLOv5 主干网络后的spatial pyramid pooling(SPP)层解决了输入图像特征尺寸不统一的问题,但是没有对特征图进行通道间的加权融合. 为此,本文通过软自注意力的方式融合图像特征,强调有效特征,提高水果识别的准确率.
2 基于注意力YOLOv5 模型的自动水果识别
本文实现基于注意力YOLOv5 模型的自动识别水果,流程如图1 所示. 首先,将数据集进行预处理,接着输入主干网络提取特征,并使用SENet 注意力模块得到一个与通道对应的一维向量作为评价分数; 其次,将评价分数通过乘法操作作用到feature map 的对应通道上,得到用于水果识别的有效特征; 然后,经过feature pyramid networks (FPN)[7]和path aggregation network(PAN)[8]结构将特征融合并获得语义信息更强,定位信息更准的特征图; 最后,经过类别分类与预测框回归计算得到精准检测结果.

图1 本文方法的处理流程图
2.1 预处理
2.1.1 Mosaic 数据增强
Mosaic 数据增强的方式参考了CutMix[9]数据增强思想. CutMix 数据增强将两张图片进行拼接,而Mosaic 采用4 张图片的拼接,增加数据量的同时可以丰富检测物体的背景,如图2 所示.

图2 Mosaic 数据增强
2.1.2 自适应锚框
在YOLO 系列算法中,通常对不同的数据集都会设定初始长宽的锚框. 在YOLOv3、YOLOv4 中,初始锚框都是通过单独算法得到的,常用的是K-means 算法. 本文将这种功能嵌入至代码中,实现了每次训练可以自适应的计算不同训练集中的最佳初始锚框. 本文的初始锚框为[10,13,16,30,33,23]、[30,61,62,45,59,119]、[116,90,156,198,373,326],经过计算本文最佳初始锚框为[111,114,141,121,127,141]、[150,149,159,169,195,212]、[256,173,173,292,326,298].
2.1.3 自适应缩放图片
数据集的大小往往都是大小不一,需要对其尺寸归一化. 然而,实际项目中的很多图片长宽比不一致,缩放并填充后,两端填充部分较多,存在很多冗余信息,影响模型速度及效果. 本文方法对原始图像进行自适应填充最少的灰度值,使得图像高度或宽度两端的灰度值最少,计算量也会随之减少,速度也得到提升. 具体步骤如下.
(1)图像缩放比例. 假设原始图像为1000×800,缩放至416×416. 将416×416 除以原始图像相应宽高,得到系数分别为0.416 和0.52,取其较小值0.416.
(2)缩放后的尺寸. 将原始图片宽高乘以较小的系数0.416,则宽为416,高为332.
(3)灰边的填充值. 先将416−332=84,并采用取余的方式得需要填充的像素值84%32=20 (32 是由于网络经过了5 次下采样,2 的5 次方为32),两端各10 个像素. 在测试过程中采用灰色填充,训练过程依旧使用原始的resize 操作以提高物体的检测、计算速度.
2.2 主干网络
2.2.1 特征提取网络
为了在水果图像上提取丰富的特征,受到YOLOv5 的启发,本文使用CSPDarknet-53 作为主干网络. CSPDarknet-53 可以增强卷积网络的学习能力,降低内存消耗.
CSPDarknet-53 主干网络包括Focus、Mosaic、多次卷积、残差结构等,其中CSP1_X 用来调整残差组件的数量,如图3 所示. Neck 中的CSP2_X 则是用来对卷积层数量的调整,如图4 所示. CSPDarknet-53 提取的特征后续用于得到通道注意力.

图3 CSP1_X 结构

图4 CSP2_X 结构
2.2.2 SELayer
为了得到不同特征通道的权重,强化重要通道,减弱次要通道,本文使用SENet[10]注意力机制学习通道权重. SENet 可以学习通道之间的相关性,生成通道注意力. 虽然计算量有所增加,但是提取的特征更加有效.图5 是SENet 模型示意图. 首先,使用全局平均池化作为Squeeze 操作; 其次,使用两个全连接层得到通道间的相关性,同时减少参数与计算量; 然后,通过Sigmoid归一化权重; 最后,通过Scale 操作将归一化后的权重作用在原始通道的特征上. 本文是将SELayer 嵌入至SPP[11]模块,如图6 所示. SPP 作为一种Inception 结构,嵌入了水果多尺度信息,聚合了不同感受野上的特征,因此使用SELayer 能够对卷积特征通道重新加权,增强重要特征之间的相互依赖,可以学习到不同通道特征的重要程度,从而产生更好的效果并提升识别性能.
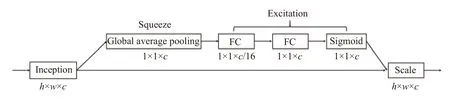
图5 SENet 结构
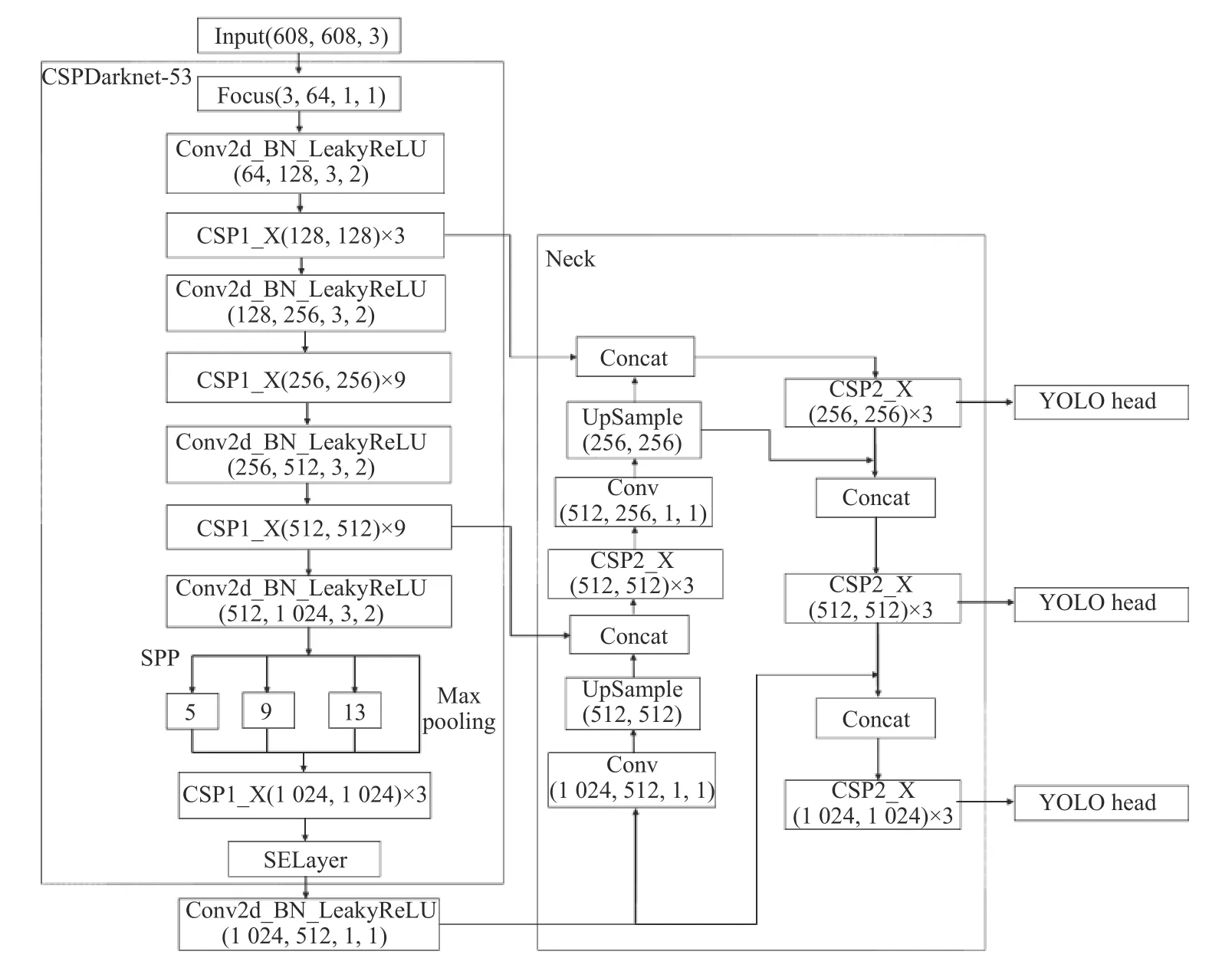
图6 改进YOLOv5 模型结构
针对全局特征差别不大(大小、形状、颜色等),某些局部特征有差异的水果,注意力机制SENet 能够增强水果的重要特征,减弱不重要的特征,使得提取的水果特征更加具有代表性且保留局部重要信息. 如图7特征图所示,本文选取前16 张特征图,青苹果与番石榴的大小、形状、颜色等全局特征相似,而部分区域颜色、表面纹理以及根蒂等有所不同. 如图7(b)、图7(e)所示,在没有进行SENet 操作前,两者特征信息类似,特征像素未体现出特征的重要程度,经过SENet 操作后,如图7(c)、图7(f)所示,根据特征重要程度将特征像素进行重新加权计算,一方面减弱了周边不重要的信息,另一方面突出了两种水果局部纹理、形状等重要特征,有利于准确识别出青苹果与番石榴.
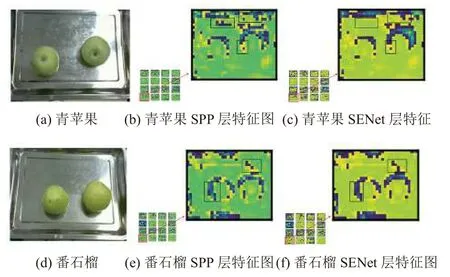
图7 特征图对比图
2.3 FPN+PAN 特征融合
为了获得更强的语义信息以及更为精准的位置信息实现水果准确识别,本文采用特征金字塔FPN+PAN提取多层次的特征,顶层特征包含丰富的语义信息,而底层特征具有精准的位置信息,如图8 所示,其中,(a)区域为FPN 部分,(b)区域为PAN 部分.
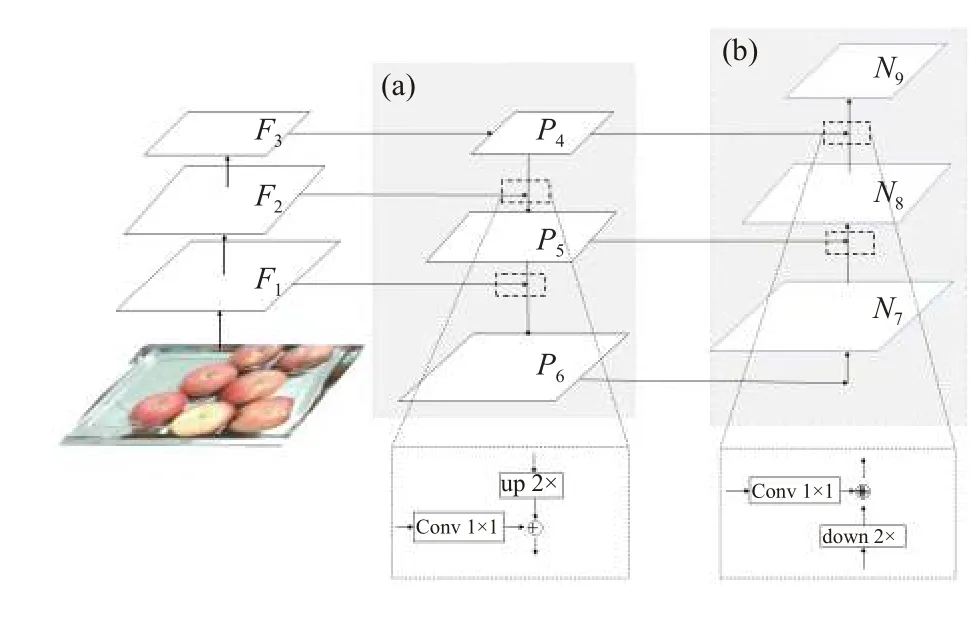
图8 FPN+PAN 结构图
FPN 设计了自顶向下和横向连接的结构,这样的好处是既利用了顶层语义特征(利于分类),又利用了底层的高分辨率信息(利于定位),如图9 所示.

图9 FPN 结构图
本文在FPN 后增加自底向上的特征金字塔PAN,将底层的特征信息通过下采样的方式进行融合,将底层定位信息传送至顶层,这样的操作是对FPN 的补充,将底层的强定位特征传递上去.
通过组合FPN+PAN 两个模块,对不同的检测层进行参数的聚合,增强语义信息的同时,提高目标的定位精度从而全面的提升模型的鲁棒性和准确率.
2.4 损失函数
2.4.1GIOU
YOLOv5 采用GIOU_Loss[12]作为bounding box的损失函数. 具体来说,对于两个bounding boxA、B(如图10),首先,算出A、B的最小外接矩形C; 其次,计算C中没有覆盖A和B的面积(即差集)占C总面积的比值; 最后,用A与B的IOU减去这个比值:
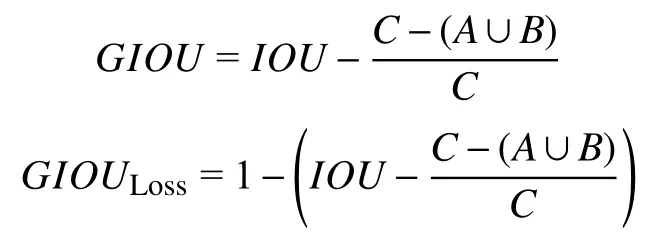

图10 GIOU 示意图
相比于IOU,GIOU一方面解决了当预测框与目标框不相交(IOU=0)时损失函数不可导的问题; 另一方面,当两个预测框大小相同、IOU相同时,IOU损失函数无法区分两个预测框相交的不同之处,GIOU则缓解这种情况的发生.
但是,如图11 所示,当预测框与目标框重叠时,则GIOU的值与IOU值相同,它们的效果一致,因此难以区分两者相对的位置关系.

图11 目标框与预测框重叠,GIOU=IOU=0.85
2.4.2CIOU
针对GIOU_Loss 损失函数所产生的问题,本文采用CIOU_Loss[13]替换了GIOU_Loss. GIOU_Loss 解决了边框不重合的问题,而CIOU_Loss 在其基础上不仅考虑了边框重合问题,而且将边框高宽比和中心的位置关系等信息也考虑进去,使得预测框的回归速度与精度更高.
CIOU是将真实框与预测框之间的距离、重叠率、边框尺度以及惩罚因子均考虑进去,使得目标边框回归更加稳定,有效的解决IOU在训练过程中发散的问题,如图12 所示.

图12 CIOU 示意图
式(1)为CIOU公式:

其中,ρ2(b,bgt)即图10 中预测框与真实框中心点之间的欧式距离d,c表示同时包含真实框与预测框最小闭包矩形框的对角线距离.
式(2)为惩罚项αv中α 的公式:
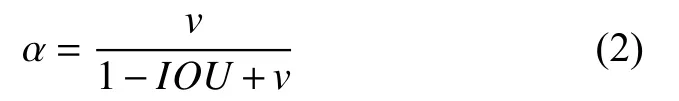
式(3)为惩罚项 αv中v的公式:

其中,wgt和hgt分别表示真实框的宽和高,w和h分别表示预测框的宽和高.
式(4)为CIOU在回归时Loss 的计算公式:

如图13 所示,目标框与预测框重合时,CIOU值也不相同.c值相同时,通过目标框与预测框中心点的欧式距离与对角线的比值d,有效度量两者位置关系,损失函数能够有效收敛.

图13 目标框与预测框重叠,CIOU 值不同
3 实验
3.1 数据采集与预处理
本文的水果数据集部分来自于网上公开数据集,部分来自于手机拍摄的数据,所用数据均为模拟称重时俯拍的水果图片. 水果类别共有15 种,共计13676张,训练集、验证集、测试集的比例为8:1:1 (训练集10940 张,验证集和测试集均为1368 张),具体类别及数量如表1 所示.

表1 数据集表
3.2 实验配置
本文实验是在深度学习开发框架PyTorch 下进行,工作站的配置为Ubuntu 16.04.6、内存64 GB、显存12 GB、GPU 为NVIDIA TITAN Xp、CUDA 10.2 版本以及CUDNN 7.6.4.
3.3 模型训练
模型训练过程中,epoch 共100 次,学习率为0.01,batch_size 为16,权重衰减数为0.000 5. 训练过程中,模型训练集损失函数损失值(box、objectness、classification)、验证集损失值(val box、val objectness、val classification)、查准率(precision)、召回率(recall)以及平均精度(mAP@0.5、mAP@0.5:0.95)如图14. 图15给出15 类水果在验证集上的P-R 曲线图.

图14 各项性能指标
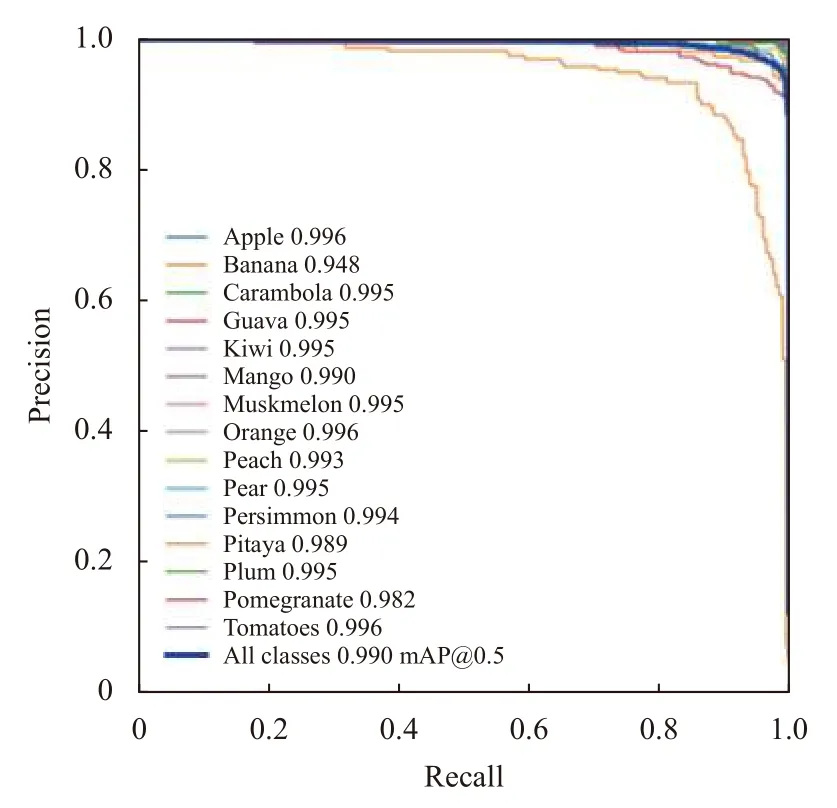
图15 P-R 曲线图
3.4 CIOU 效果验证
为了证明CIOU的有效性,我们进行了对比实验.在YOLOv5 模型的基础上,将GIOU损失函数改为对应的CIOU损失函数. 实验结果如表2 所示.
从表2 中可以看出,利用CIOU作为边框回归损失函数,模型mAP 值为97.72%,提升1.57%,证明了CIOU损失函数的有效性.

表2 CIOU 效果验证性能对比
3.5 SELayer 效果验证
为了证明SELayer 的有效性,我们同样进行了对比实验. 在YOLOv5+CIOU 模型的基础上增加注意力模块SELayer. 实验结果如表3 所示.
从表3 中,可以看出,在YOLOv5+CIOU 的基础上增加SENet 注意力机制模块,即本文基于注意力YOLOv5模型,mAP 值为99.10%,提升了1.38%,精度提升的同时,模型的速度并没有下降,证明了SELayer 的有效性.

表3 SELayer 效果验证性能对比
如图16 所示,在形状、颜色、纹理、大小类似的两种水果中,图16(a)为苹果,图16(b)为番石榴,模型能够准确识别.

图16 SELayer 效果对比
3.6 模型鲁棒性检验
为了验证本文方法的鲁棒性,本文检测了15 种水果,并分别考虑了光照、遮挡等因素. 如图17–图20.
(1)不同光照. 如图17、图18.

图17 光照较强下测试效果对比

图18 光照较弱下测试效果对比
(2)有遮挡. 如图19.

图19 有遮挡测试效果对比
(3)同类别不同品种. 如图20.

图20 同类别不同品种测试效果对比
通过对比发现,本文模型在遮挡、不同光照、多目标等情况下水果的识别效果更好、鲁棒性更好,输出的预测框相比更符合目标水果.
3.7 与最新方法的对比
为了验证方法的有效性,除了对比YOLOv5 模型,本文对比了最新主流的Faster-RCNN、YOLOv4 模型,如表4 所示.
由表4 可见,Faster-RCNN 的mAP 为95.49%,YOLOv4 的mAP 为95.39%,YOLOv5 的mAP 为96.15%,而本文方法的mAP 为99.10%,识别速度到82 帧/s,在准确率及速度上都优于其他主流的对比方法.

表4 模型性能对比
4 结语
本文采用基于注意力YOLOv5 算法模型实现15类水果的自动识别. 实验表明,本文方法是鲁棒的,并且在水果识别准确率和识别速度上都优于主流Faster-RCNN、YOLOv4 和传统YOLOv5 算法. 在后续的研究中,将考虑更多种类的水果,在保证水果种类的多样性时也能够保证模型的泛化能力以及识别准确率与速度.
