基于车牌自动识别数据的车辆OD轨迹还原①
2022-08-04范晓武何逸昕
王 杰,范晓武,何逸昕,陶 峰
(浙江综合交通大数据中心有限公司,杭州 310005)
大规模的车辆轨迹数据可通过GPS、手机信令、视频监控、感应线圈等技术获取[1]. 利用地理信息系统(geographic information system,GIS)将这些轨迹数据投影在电子地图上,能直观地显示交通环境,进行实时的交通智能信息分析. 同时,深入分析车辆轨迹数据还可获取道路起讫点(origin-destination,OD)、出行偏好等信息. 为公路规划、建设养护等工作提供重要决策支撑[2].
在上述的交通信息采集技术中,使用部署在道路上的摄像采集设备,通过自动车牌识别技术能获取车辆的行驶状态,如时间、车牌号、速度、车道和方向.这些行驶状态,结合道路网络拓扑结构,即可得到车辆时序轨迹数据. 与基于GPS[3,4]、手机信令[5]、感应线圈[6]等方法相比,使用摄像采集技术具有覆盖面积广、安装维护便捷、连续性强、样本量大的优势. 同时还可提供可视化图像,以保证数据的精准性[7]. 由此产生了大量基于车牌识别数据的交通特性分析研究,但现有的研究[7–10]主要集中在交通小区交通量、出入站情况、通行效率等宏观特性提取,很少有研究关注到微观的车辆出行轨迹提取与分析. 然而,完整可靠的车辆出行轨迹蕴含丰富的交通运行状态信息,能系统、全面地再现复杂的道路交通运行场景,对交通管控至关重要.
基于车牌识别数据的出行轨迹的研究具有很大挑战,主要原因在于以下2 点: 1)受设备采样频率、信号质量、天气环境等多种因素影响,导致部分轨迹数据错误或者漏检,使得车辆轨迹数据呈现稀疏不完整性. 2)以往的出行路径还原方法没有充分利用视频图像检测器获取的驾驶状态,忽略了出行者路径决策的主观行为.
直观地说,针对稀疏不完整的车牌轨迹数据,充分考虑每2 个监测点之间不同的路线选择方案,以挖掘驾驶员潜在的行驶规律,可有效提升算法的鲁棒性. 为实现此目标,本文提出一种新的OD 轨迹还原算法. 该算法的主要贡献有: 1)设计一种基于K 则最短路径算法(K shortest paths,KSP)的候选路径生成方法,以模拟出行者复杂的路径决策行为. 2)应用变分自编码器(variational auto-encoder,VAE)对多个候选轨迹就行最优化估计,以此重建还原车辆的完整通行轨迹. 该算法在杭州市萧山区实际交通小区进行验证评估. 实验结果表明,该方法在轨迹还原精准度上准达到了95%,远高于用于对比的基准模型. 此外,该方法还被证明能有效适应数据缺失率高的场景,在基于稀疏数据的轨迹重建上显示出巨大的应用前景.
1 OD 轨迹还原算法
本文提出了一种基于稀疏车牌数据的轨迹还原算法. 如图1,该算法框架主要由4 个模块组成: 1)出行链验证分离; 2)候选路径生成; 3)路径校验; 4)路径决策. 本节将对以上模块展开详细描述.
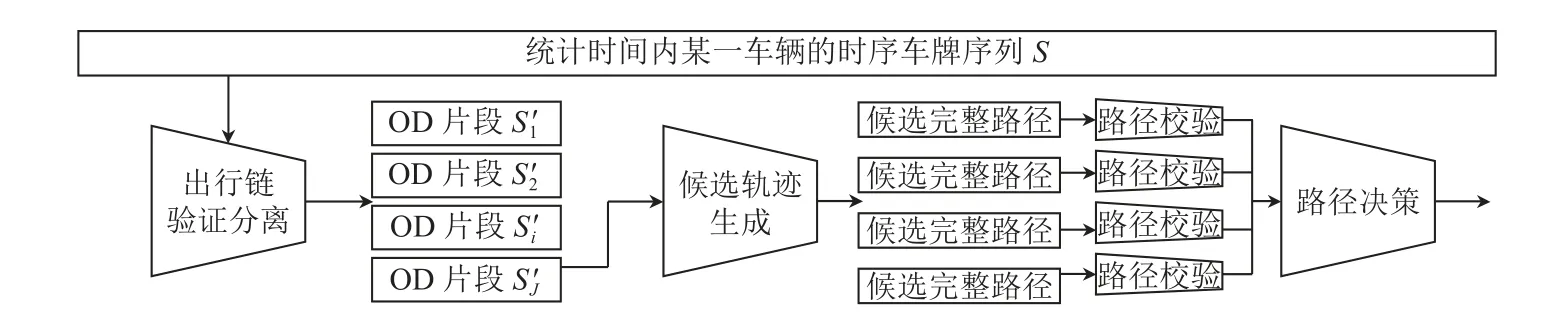
图1 OD 轨迹还原算法框架
为了便于描述,设定G=(V,E)为交通小区的网络拓扑图,V={r1,r2,···,rm}为该小区路口集合,E={
1.1 出行链验证分离
对识别到的所有行驶状态按车牌号进行分组,再以检测时间排序,可得到采样时间段内每辆车的出行链. 如图2 所示,该出行链来自于多个时间段统计聚合,可能包含多个不同目的的OD 出行. 本节首先对整个出行链进行验证,结合相邻样本间空间距离与通行间隔将原始时序数据划分为多个OD 片段,从而保证轨迹推导模型数据的真实可靠.

图2 多OD 出行链示例
具体来说,给予一辆车在统计时间内的出行链,即车牌时序序列S={s1,···,sn},对任意2 个相邻样本点si和si+1,通过样本点中记录的位置信息gi和gi+1可计算得到最短的曼哈顿街区距离d. 同时,相邻样本点通行的时间间隔 ∆t可由检测时间ti+1和ti相减得到. 这样每两个相邻样本点的通行平均速度可以表示为:

然后,判定vi,i+1是否处于预定的最低通行速度阈值vmin和最高通行速度阈值vmax之间. 当vi,i+1偏离预设速度阈值时,将该检测样本点si标记为上一段OD 的终止点,si+1标记为下一段OD 的起始点.
1.2 候选轨迹生成
出行链经过验证分离转化为仅包含一个O 点和D 点的独立轨迹片段. 在实际道路环境中,设备的未覆盖、漏检或者错检,导致这些独立的OD 片段往往呈现出稀疏不完整的性质. 为获取完整的OD 轨迹供后续分析使用,需要对缺失的轨迹数据进行补全还原.
如图3 所示,车辆在两个间断点有多条距离相当的可选通行路径,直接假设车辆以最短路径行驶显然不再适用. 本文设计了一种新的路径还原思路. 对两个间断样本点潜在路径求解,以模拟真实道路交通场景下,出行者复杂的道路选择; 再对候选路径进行校验,择优,以获取最终的通行路径.

图3 OD 缺失拓扑图
具体来说,给予分割后的OD 轨迹序列S′={so,···,sd},o,d≤n,生成潜在候选轨迹的步骤如下:
步骤1: 判断S′中任意2 个相邻样本点所在的路段
步骤2: 如果存在有
步骤3: 汇总并排列组合,得到so至sd中所有可供选择的候选轨迹集合q1,q2,···,qn. 需要注意,为提高复杂路网下轨迹生成效率,本文设定n=10,即仅保留可行轨迹中路径最短的前10 条路径.
1.3 路径校验
生成候选路径的方式将求解完整出行轨迹的问题转化为从多个可行路径中选取一条最符合出行者驾驶风格路径的问题. 为此,本文构建了一系列的决策指标以模拟出行者路径选择决策过程. 从实际出行决策角度,需要考虑的主要因素包括: 路径距离、通行时间、含信号交叉口、转弯次数等[11–13]. 然而,以上因素同属于静态因素,缺乏与出行者固有行驶习惯的关联.
为解决这个问题,本文特别设计了通行时间一致性和轨迹偏好2 个动态指标. 其中,通行时间一致性表示当前候选OD 轨迹先验的平均通行时间与实际的通行时间∆tqi之间的相符程度,其计算过程如式(2)所示:

值越大表示该候选路径与实际通行路径越接近.而轨迹偏好程度用于描述该候选轨迹的实际通行情况占所有轨迹通行情况的比例,求解过程可以描述为:

其中,函数number(·)表示该路径在车牌识别数据集中出现的次数,n=10表示生成的候选路径的数量.
此外,为区分每个指标内部的显著性,本文使用zscore 方法对所有指标进行归一化:

其中,ei属于路径距离、通行时间、含信号交叉口、转弯次数、通行时间一致性和轨迹偏好6 个指标的集合,µ表示当前指标的均值.
1.4 最优路径选择
通过候选OD 轨迹的各项校验指标可计算得到最合适的行驶轨迹,这本质上可视为多属性决策问题. 以往通常使用主成分分析、灰色关联分析等方法进行多属性决策的研究,但这样的方法存在计算复杂度高,特征提取效率低等缺陷. 受Wu 等人[14]的启发,他们在风格迁移任务中首次提出图像的风格可以由实例的均值和方差来表示. 基于此,本文设计了一种基于VAE 模型的多属性路径决策方法. 该方法可以通过VAE 算法的编码器得到输入候选轨迹校验指标的均值和方差,并以此作为出行者固定的风格习惯,从而将最符出行者出行风格的路径中候选路径中挑选出来.
图4 展示了VAE 模型的计算流程. 基于VAE 的路径决策方法以候选轨迹的指标组成的多维向量作为输入,通过模型学习轨迹指标之间的分布关系. 最终,每条候选轨迹计算得到的均值和方差会与代表出行者出行固有习惯的先验值比较,越接近代表越符合最优路径,如图5 所示.

图4 VAE 模型流程图

图5 候选轨迹均值方差(▲)与先验值(X)的空间分布
通过VAE 优化校验指标的目标函数可以表示为:

2 结果与分析
2.1 数据说明
本文所述算法在杭州萧山S103 交通小区进行测试验证. 实施范围如图6 所示,该路网包括34 个路口、50 个路段. 每个路段皆配备1–2 个摄像采集设备,总计117 个. 在2021 年5 月6 日至2021 年8 月6 日时间范围内,通过自动车牌识别技术对该交通小区路网内车辆的交通状态进行提取. 所提取识别数据中包含乱码信息、逻辑关系混乱 、以及车牌不符合规范等异常轨迹信息,剔除后最终得到259219 条可用的稀疏车辆行驶轨迹序列. 每条序列包含了检测设备编码、时间、地点、车牌号等信息,详细数据如表1 所示.

图6 杭州萧山S103 交通小区
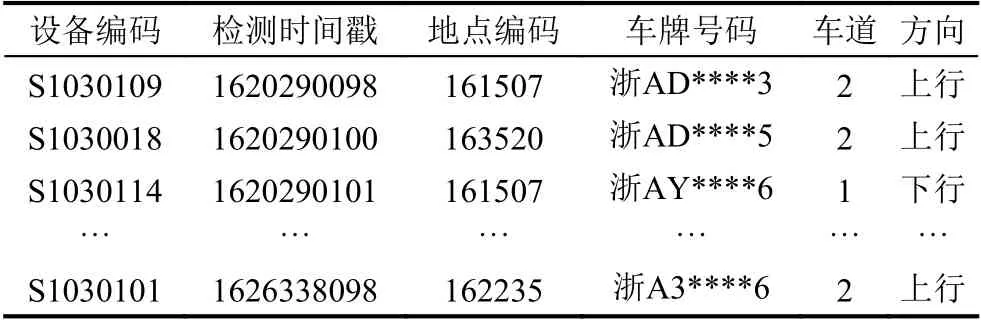
表1 预处理后的车牌识别
2.2 实验结果
本小节将展示一系列的数值化和可视化结果,对本文提出的OD 还原算法进行评估.
2.2.1 轨迹还原对比实验
本文选取了几个比较有竞争力的模型作为基准来验证算法性能. 包括: (1)最短路径法(SP)[15],以间断点最短路径作为补全还原的路径; (2)主成分分析法(PCA)[16],将每个候选轨迹的校验指标映射到2 个维度,并以此作为均值方差的替代; (3)自编码器(AE)[17],同PCA,可自动学习数据映射规律,并映射到2 个维度.
验证使用的数据集是原始车牌识别数据的子集,包括了1208 辆车的总计15812 条不存在间断点的轨迹数据,且每辆车的每个OD 内的轨迹满足检测样本数不小于10. 对于每个完整OD 轨迹Si′={so,···,sd},实验中随机的删除首末样本点间k∈{1,2,3,···,7}个连续的节点以获取不完整的轨迹. 之后,再通过轨迹还原算法进行补全得到完整的重建轨迹S′i′={so∗,···,sd∗}. 那么OD 轨迹还原算法的准确率可以表示为:

其中,函数bool(S′i,S′i′)∈{0,1},当重建轨迹S′i′与原始完整轨迹S′i一致时为1,反之为0.
表2 展示了对比实验的结果,从表中可以发现,SP 算法在轨迹还原的精准度上表现最差,随着节点缺失率的增加,SP 具有最大的降幅(如图7 所示). 主要原因在于,SP 算法假设驾驶车辆以最短的路径行驶,忽略了出行者主观决策等对驾驶路径的影响. 而PCA、AE 和文本提出的算法通过候选轨迹生成模拟出行者的路线选择过程,在指标上明显优于SP 算法. 相较于PCA 和AE,本文使用VAE 对每条候选轨迹计算抽象意义的均值和方差,以此作为出行者的出行风格、固有习惯,这促使本文所提出的算法取得更优越的性能. 此外,从表2 最后一行指标和图7 的可视化视图,还可以发现,与表现最好的对比模型AE 相比,在缺失样本点低(不超过5 个)时,两个算法取得了相当的性能. 但在节点缺失率更高时,本文的算法表现出更强大的适应能力(在缺失节点为7 时,优于表现最好的AE 算法11%).
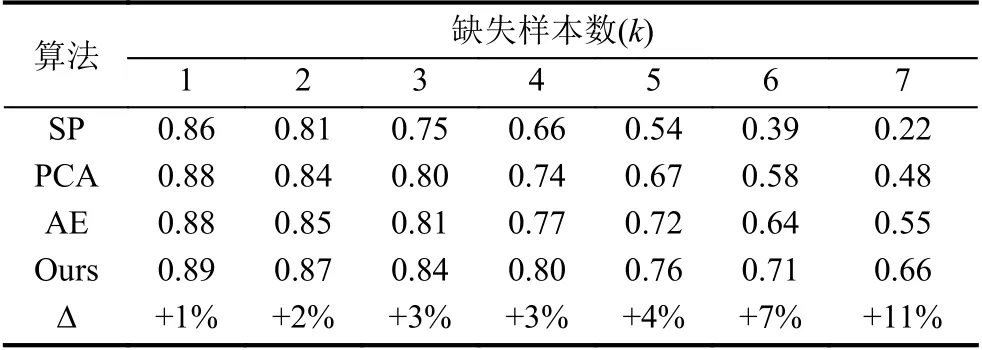
表2 本文提出算法与对比算法的准确率表现

图7 不同算法的准确率表现
表3 展示了各个算法的时空消耗表现. 尽管SP 算法拥有极高的运算效率,但在精度上面很难满足实际需求. 在精度相对比较高的PCA、AE 和本文的算法中,本文算法与AE 算法在运行效率上都明显优于PCA 算法. 尽管本文所提出的算法拥有最高的参数量,但减少一定运算的时空效率给算法带来的是大幅度的精度上的提升.

表3 本文提出算法与对比算法的时空消耗
2.2.2 摄像采集设备覆盖率分析
利用大数据技术、车牌自动识别技术,借助当前高密度、高精度的监测设备,深挖车牌照的自动识别信息,实现OD 数据与交通运行数据的智能化提取,是适应当前复杂的交通发展状况与精确的交通数据需求的思路.但在实际道路交通中,并非每个路口、路段都已部署摄像采集设备. 研究不同覆盖率与轨迹还原准确率的关系,可以在保证达到识别性能和还原效果的情况下,降低设备覆盖率,让轨迹分析系统以更经济、高效的方式运行.
由此,本文进一步测试了不同摄像采集设备覆盖率下车辆OD 轨迹还原的准确率. 从交通小区所有采集设备中随机删除10%、20%、30%、40%、60%、60%和70%的设备以及这些设备对应的识别数据,模拟90%至40%之间以10%为间隔的不同设备覆盖率情况,并通过本文提出算法和对比模型中表现最好的自动编码器(AE)进行轨迹的还原重建. 图8 展示了不同设备覆盖率下本文提出算法与AE 算法轨迹还原的精准度变化情况. 从图中可以发现,随着设备覆盖率的减少,两者轨迹还原的精度都有所下降. 且覆盖率越低,对应的下降幅度越大. 不同的是: (1)本文提出的算法在所有覆盖率下的精度都优与AE 算法; (2)在90%–50%的覆盖率间,本文提出的算法随覆盖率下降带来的准确率的衰退不超过6.6%,而AE 在覆盖率由70%减少60%时,精度就大幅度的衰退了10.3%. (3)在覆盖率50%-30%之间,虽然两者精度都大幅衰退,本文算法始终保值更高的精度以及更小的下降幅度. 以上这些观察证明,在覆盖率高的情况下,本文算法更加准确、有效. 且在覆盖率低的情况下,本文算法依然具有非常良好的适应能力.
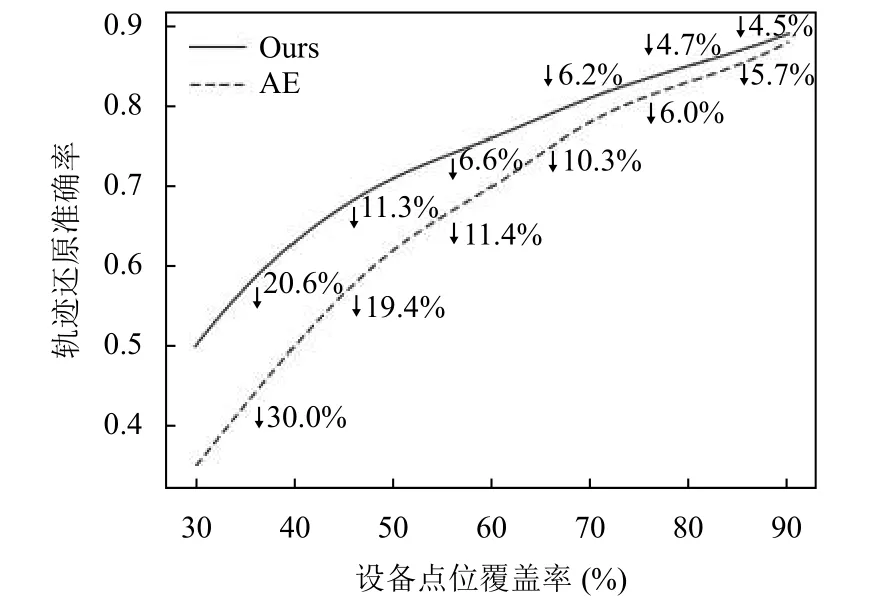
图8 不同摄像点位覆盖率下本文提出算法准确率表现
2.2.3 敏感性分析
第1.3 节介绍了影响最终最优路径决策的6 个关键性指标: 路径距离、通行时间、含信号交叉口、转弯次数、通行时间一致性和轨迹偏好. 计算选择路径与以上指标的相关系数可以得到每个指标对最终决策的影响程度. 图9 展示了各校验指标与决策路径的相关系数矩阵,其中,颜色越深代表相关性越强.
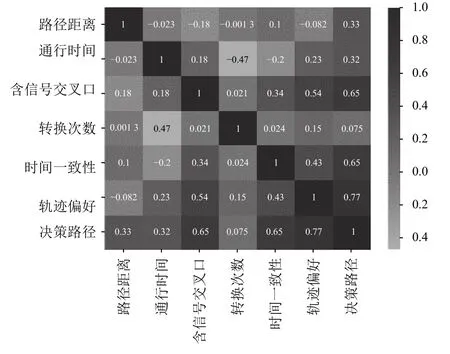
图9 各校验指标与决策路径之间的相关系数矩阵
由图9 可知,本文所提出的时间一致性和轨迹偏好2 个动态性指标最终的决策路径保持着较高的相关稀疏,分别为0.65 和0.77. 在通用的静态决策指标中,含信号灯交叉路口数对最终决策的影响最高,为0.65.总的来说,本文所提出的2 个动态性指标,在最终的轨迹还原中起到了非常积极的促进作用.
3 总结
本文提出一种基于车牌识别数据的城市交通网络车辆轨迹重建算法. 基于车牌识别时序序列,该方法充分考虑到出行者出行过程中复杂道路选择决策过程,从而拟合产生最适合出行者主观行驶风格的通行路径.通过杭州市萧山区实际交通小区对该方法进行校验,综合实验结果表明了算法时鲁棒可靠的,为稀疏车牌数据的轨迹还原提供了一个强有力的基准.
