基于三维注意力机制的车辆重识别算法
2022-08-02方彦策张宏江谢雨成刘培顺
方彦策,张宏江,谢雨成,刘培顺
(1.中国海洋大学 信息科学与工程学部,山东 青岛 266100;2.中国运载火箭技术研究院 研究发展部,北京 100091)
0 引言
车辆重识别技术能给我们的生活带来便利,提供安全保障,例如智慧安防、智慧交通方面:公安涉车侦查、套牌车比对、无牌车管理、违法抓拍、道路拥堵路况检测、交通异常行为分析、停车收费管理等。
近年来,随着机器学习技术的提升,用机器学习算法实现车辆重识别逐渐成为研究热点。2015年,文献[2]通过提取车辆前脸的HOG特征,采用线性判别的分析技术提取车辆梯度方向直方图特征进行车辆识别,但无法处理遮挡问题。文献[3]采用主成分分析PCA算法,通过特征提取,实现对车辆的识别,PCA是非监督的机器学习算法,车辆重识别率较低。文献[4]提出对车辆图像提取的VAR特征图像,统计图像的LBP直方图特征,利用SVM进行分类。文献[5]针对SVM模型识别性能不足且训练时间过长的问题,提出了一种基于Haar类特征和改进的级联分类器的图像分割方法,但该方法未考虑数据不平衡导致的分类精度下降的问题。文献[6]基于Alexnet网络构建了9层的深度卷积神经网络用于识别车辆。该方法与机器学习的车辆识别方法相比,具有更高的准确率。文献[8]等采用自适应算法优化BP神经网络。对车辆识别方面具有较高识别准确率和鲁棒性。文献[9-10]利用卷积神经网络提取的特征实现对车型的识别,显著提高了车辆识别的准确率。文献[11]提出使用PCANet网络对车型进行识别,该网络模型具有较强的抗畸变能力。目前这些车辆重识别的算法大部分是基于车辆的整体特征进行识别,对于某些外观几乎一样的套牌车识别率效果比较差,例如图1所示的套牌车。从图中可以可以看出套牌车最明显的差别位置在车窗,同一车型的车辆在使用一段时间之后,因为使用人的习惯不同,前车窗最容易产生明显的差别,因此本文主要根据前车窗的特征进行车辆重识别,与人脸识别类似,本文称之为车脸识别。

图1 套牌车
“车脸识别”与“人脸识别”类似,不是靠车牌识别车辆,而是识别车辆的前部特征来区分不同车辆。在车脸识别算法研究中,本文用到了注意力机制。注意力机制通过模仿人类对于信息的注意力分配的不均衡,聚焦有用信息,来获得性能提升。近年来,将通道注意力,位置注意力等引入深度神经网络,在提升卷积网络的图像分类、目标检测、语义分割等领域均取得了很大的进展。
大部分注意力机制例如SENet[12],CBAM[13],GCNet[14]等都通过叠加卷积,池化和激活函数等获得通道或位置特征。SENet获得的是1维的通道注意力,首先通过压缩操作使用一个平均池化来嵌入全局信息,再通过激励操作使用一个具有两个全连接层的结构来获得通道之间的关系。CBAM通过两个模块串行的方式获得了同时具有通道和位置特征的矩阵,以串行的方式来获取同时具有通道和位置注意力的图像。是一个2维的注意力机制。GCNet使用了和SE块相似的结构,将Non-local块和SE块结合的方式使GCNet得到了比两者网络都更好的效果。SimAM[15]提出了3维注意力的概念,但实现的方法与其他注意力模块完全不同,引入神经科学的概念,用一种无参的方式获得3维注意力,但效果与SENet类似。可以看出大部分注意力算法都关注于一维的通道注意力和二维的位置注意力,而处理的图像是三维的,因此这些注意力机制往往不能将注意力集中在所有需要关注的区域,造成部分关键信息遗失。
本文介绍一种新的三维注意力机制,通过结合一维的通道注意力和二维的位置注意力机制,得到三维的图像注意力权重矩阵,计算后得到经注意力分配的新图像。相比SENet,在ResNet18[16]和ResNet34上参数量几乎没有增长,在ResNet50和ResNet101上增长了2%左右。在Cifar100[17]数据集上,以ResNet50作为主网络加入注意力后,相比SENet有1.12%的提升。在ImageNet[18]数据集上,比SENet有接近4.5%的提升。
1 车脸识别网络模型
1.1 车脸识别网络模型概述
为了实现车脸识别,本文在ResNet网络基础上添加三维注意力,并对ResNet网络的大量结构进行重新设计,形成TDANet作为主干网络。
在主干网络结构中,通过实验对比分析发现网络中的block对于结果的影响是最重要的,因此将ResNet的(3,4,6,3)的block数量比例改为了Swin-Transformer[19]所使用的(3,3,9,3)的比例,对于更大的模型,使用了(1,1,9,1)的block比例。
为了提高网络的性能,借鉴了ResNeXt[20]中分组卷积的方式,使用了深度卷积的方式,即分组数等同于输入通道数的卷积方式,即将原本的大卷积拆成多个小卷积的并行计算,再将结果结合。
在Transformer[21]所使用的网络中,总共使用了一个激活层,而在ResNet中则可以看到大量的激活层,参考Transformer结构我们将TDANet中的部分激活层去除。
我们在主干网络中使用了反转模块的方式,与原本的从多通道——少通道——多通道的方式不同,我们采用了少通道——多通道——少通道的方式来减少计算量,同时尽可能地避免了从多通道到少通道的转换带来的信息损失。
网络结构如图2所示,车脸图像输入到TDANet网络中,得到尺寸为C×H×W的特征图X,其中C表示通道数量,H表示高度,W表示宽度。特征图X输入到主干网络中的三维注意力模块,然后将得到的注意力特征和原特征图X融合在一起,得到新的注意力分配后的特征图。网络的最后一层是分类层,由1 000个神经元的全连接层组成,和ResNet相同,将前面经过多次卷积后高度抽象化的特征进行整合,归一化,对每一种类别都输出一个概率,代表图片属于该类别的可能性。
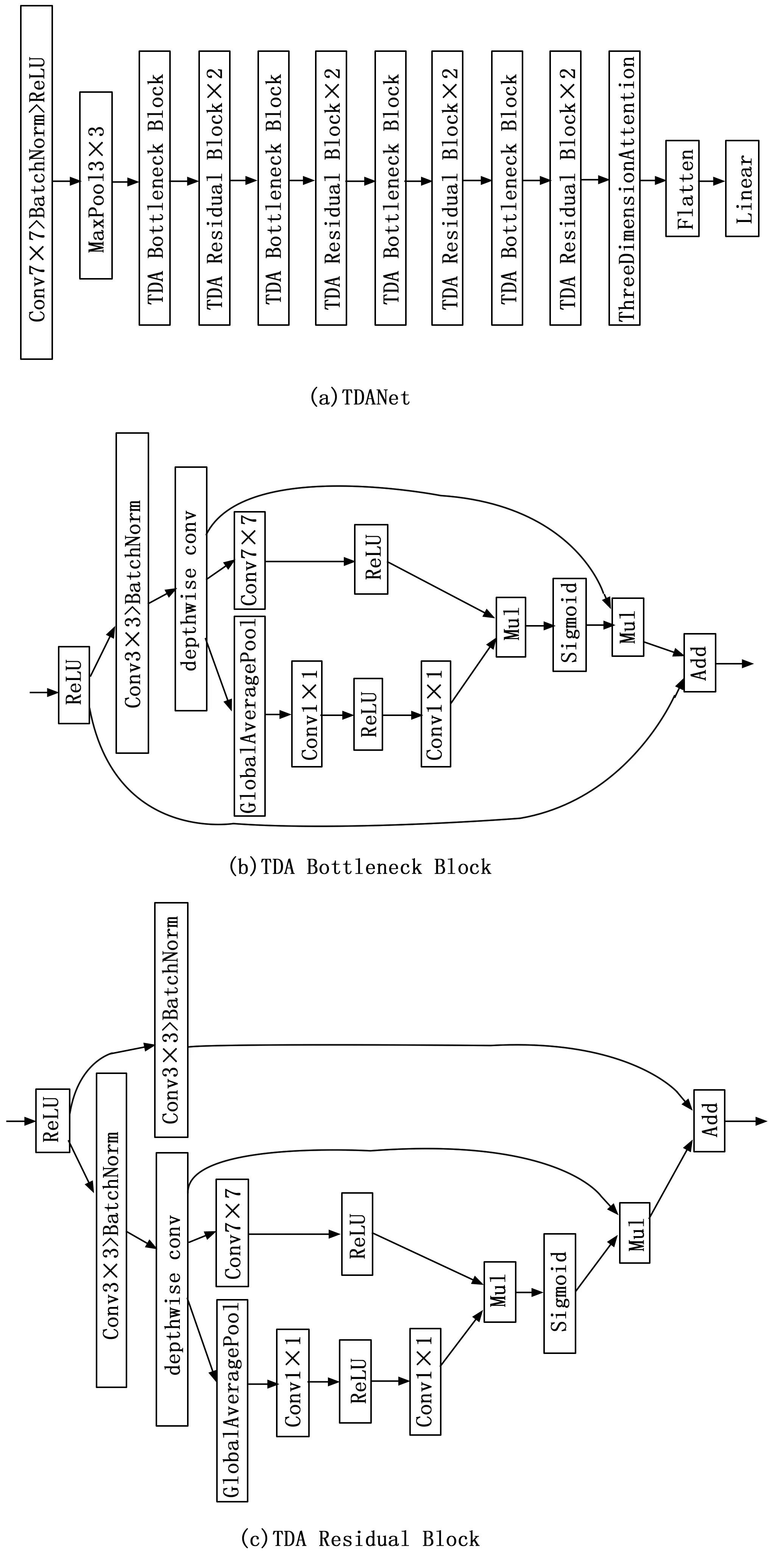
图2 网络总体结构
1.2 三维注意力机制
1.2.1 通道注意力
图像的每一个通道都具有不同样的特征。因此,通道注意力是关注什么样的特征是有意义的。通道注意力是一个一维的注意力,它对不同通道区别对待,对所有位置同等对待。如图2所示。
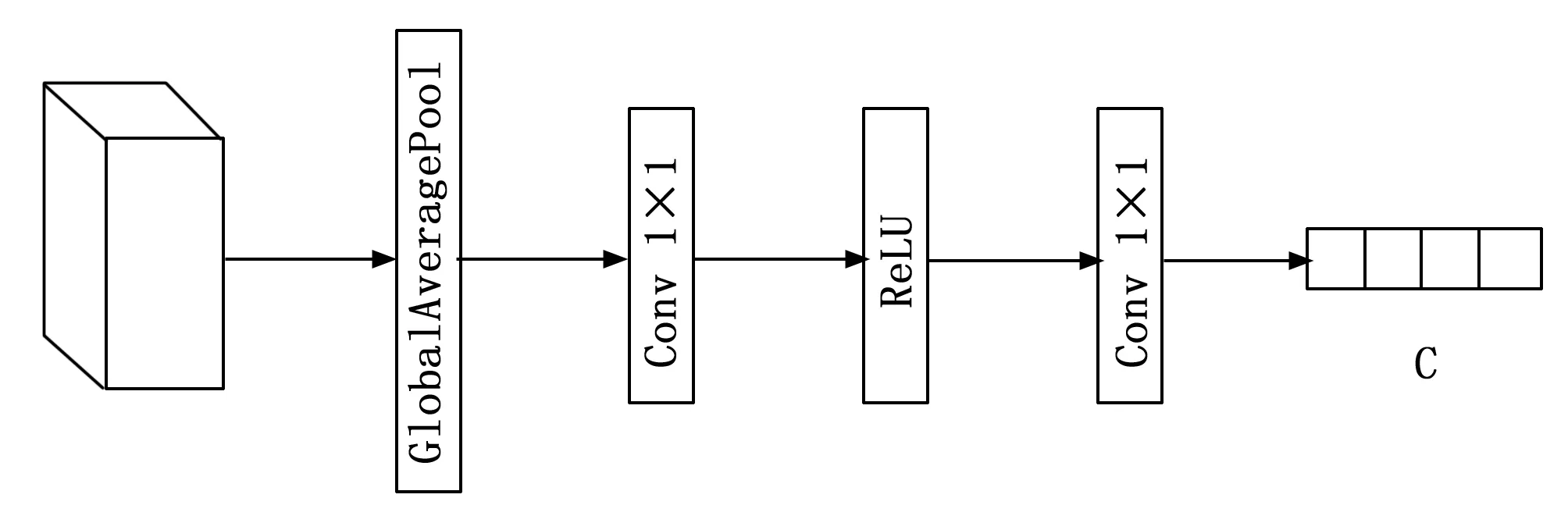
图3 通道注意力
通道注意力的计算包括3个步骤:
1)对于输入特征图X,本文首先使用均值池化从每个通道的H×W图像中提取特征,相比于最大值池化,均值池化在计算量接近的情况下,能表示更多信息,同时实验证明均值池化注意力比使用最大值池化效果好。均值池化的公式为:
(1)
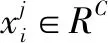
2)上述操作之后可以得到尺寸为C×1×1的特征向量,它们具有所有通道的全局感受野。因为在注意力模块上,全连接层相比卷积层进行了很多额外且效果不明显的计算,全连接层的降维也给通道注意力的预测带来了一定的副作用。借鉴了ECANet的结构,本文用卷积层代替了全连接层。这里本文设计了两个连续的输入和输出通道相差16倍的卷积层,增强网络的非线性,实践证明这种方式可以更合理地描述图像的特征。其计算公式为:
(2)
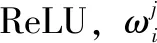
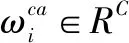
(3)
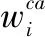
1.2.2 位置注意力
在通道注意力模块之后,我们再引入空间注意力模块来关注哪里的特征是有意义的。和通道注意力不同,位置注意力机制通过一层卷积将所有通道的信息提取成一个通道,得到一个1×H×W的特征图,代表图像中每个像素所拥有的注意力权重。在ReLU层的激活函数操作之后,可以得到代表每个通道内的图像中每个像素的权重的矩阵。位置注意力的公式:
(4)
X∈RC代表输入的图像,σ代表了激活函数ReLU,代表了卷积核大小为7的卷积操作。
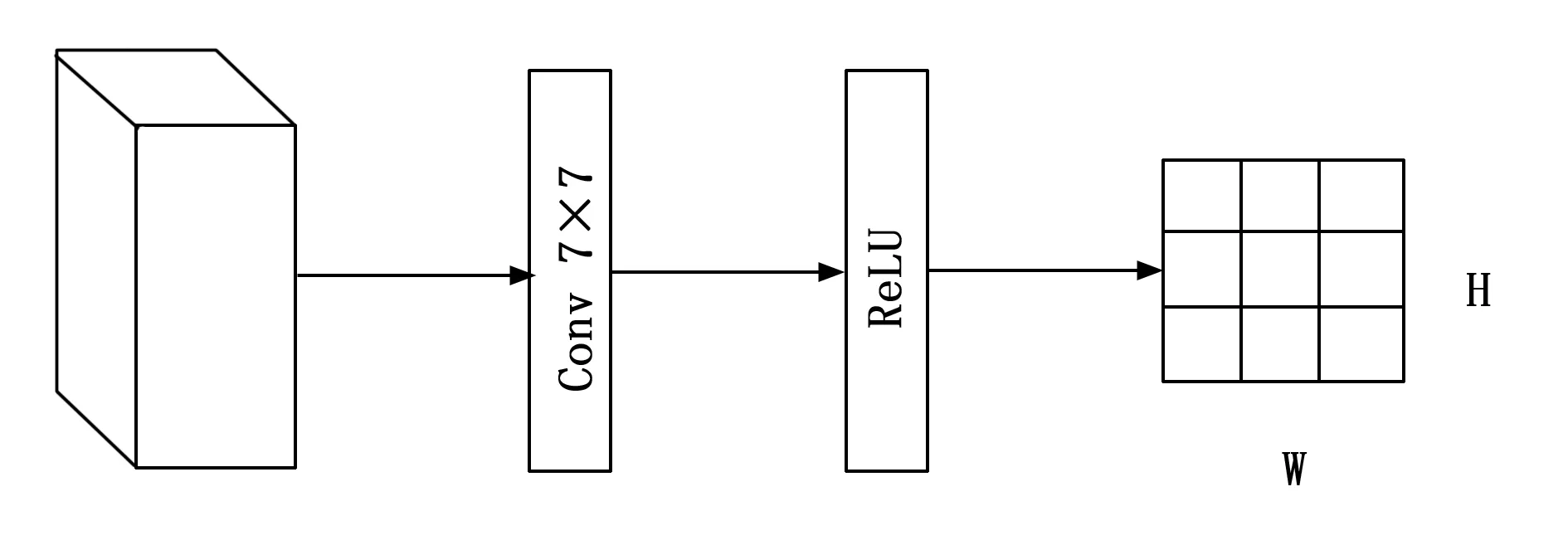
图4 位置注意力
1.2.3 三维注意力模型
CBAM发现在获得的特征图相加的情况下,通道注意力和位置注意力并行的结合方式不如串行的结合方式,并且由实验发现先通道后位置的方式拥有更好的效果[13]。在DANet中采用位置注意力和通道注意力两种注意力得到两种特征图,然后分别和原图相乘后利用相加的方式进行结合[22]这样的结合方式均只是考虑了简单的加法,位置和通道的联系并不紧密。在多注意力结合的领域,几乎所有的多注意力结合方式都使用了最原始的加法来对特征进行融合。对于C×H×W的特征图,每一个点的像素,在通道注意力和位置注意力中,并没有独立的权重,而是由有通道权重而无位置权重的特征图X1,和有位置权重而无位置权重的特征图X2相加而得,这样相当于假设通道权重和位置权重对每个点具有相同的影响。如果点a,b在位置的中的权重分别接近于0,a,而a,b所在通道的权重接近于2a,a,在相加的情况下,这两个点所得到的权重是相似的,而事实上点a所受到的关注应该远小于b。实验中我们发现通道权重和位置权重对于每个点的影响是独立的并且很难做到相同。
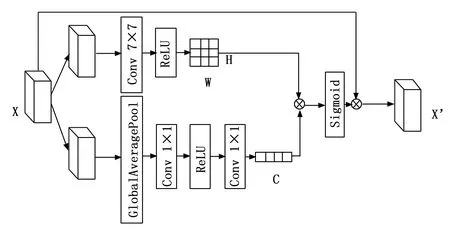
图5 三维注意力
因此我们提出了一种全新的,更加符合图像本质的融合方式,这种结合方式的公式如下:
由通道注意力得到的尺寸为C×1×1的张量代表了每个通道的权重,由位置注意力得到的尺寸为1×H×W的张量代表了位置中每个像素的权重,将两个张量相乘可以得到C×H×W的张量,每个点所具有的权重等于该点所在通道的权重和该点在位置中的权重之积。在此种结合方式中,注意力能够更加集中,权重高的像素点意味着它在通道和位置上都受到重视。这种结合方式更符合点的实际权重。
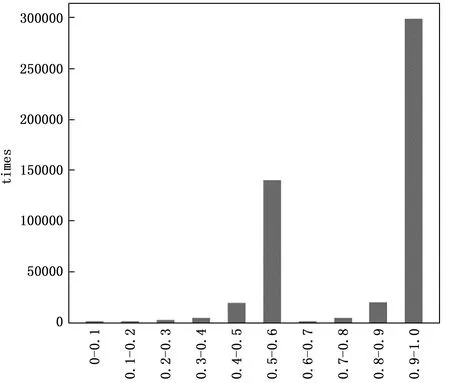
图6 W值分布统计
1.2.4 损失函数
本文设计的模型的损失函数采用了Arcface loss[23]损失函数,它由Softmax loss改进而来。
(6)
Softmax loss函数中,xi∈Rd代表了第i个样本的深度特征,属于第yi类。Wj∈Rd代表了权重W的第j列,bj∈RN代表偏置项。
(7)
(8)
ArcFace loss在基于中心和特征归一化的基础上,将所有样本看作一个个分布在超球面上的点,在角度空间上进行分割,它的角度间隔,也就是在超球面曲面上的最小距离。
在Arcface loss损失函数中,在xi和Wj之间的θ上加上角度间隔m,以加法的方式惩罚深度特征与其相应权重之间的角度。
(9)
通过减少样本和中心之间的角度,Arcface loss可以提高类内的紧密性,内部的损失函数可以有效压缩类内的变化,但也会带来类间角度较小的缺点。
(10)
通过增加不同中心之间的角度,可以增加类间差异性。
2 实验验证
为了验证三维注意力模块的有效性,选用了汽车之家数据集,PKU VehicleID数据集,CIFAR-100数据集和ImageNet数据集,分别进行了对比实验。我们的算法使用PyTorch实现,实验结果表明,三维注意力模块在以上数据集都达到了最先进的性能。在接下来的章节中,将具体介绍数据集和实验细节,并对结果进行分析。
2.1 汽车之家数据集
车脸识别数据集对于每辆车均只采用前车窗的部分进行识别。测试的方法借鉴于人脸识别,目的是对于给定任意两张车窗图片,都能够判断是否属于同一辆车。

图7 汽车之家数据集
数据来源于汽车之家的公开数据,如上图所示。训练集共有1 757辆车,测试集共有522辆车。每辆车的车窗都有三张照片,分为左前,正前,右前3个视角。测试的共有6 000对,其中5 000对为不同车辆的车窗图片,1 000对为相同车辆的车窗图片。
使用了ResNet-50作为主干网络,初始学习率为0.1,在第80,160,240个epoch的时候学习率分别变成0.01,0.001,0.000 1。batchsize为64,momentum为0.9,weight decay为0.000 5,总共训练200个epoch。进行对比实验得到的准确率结果如下:
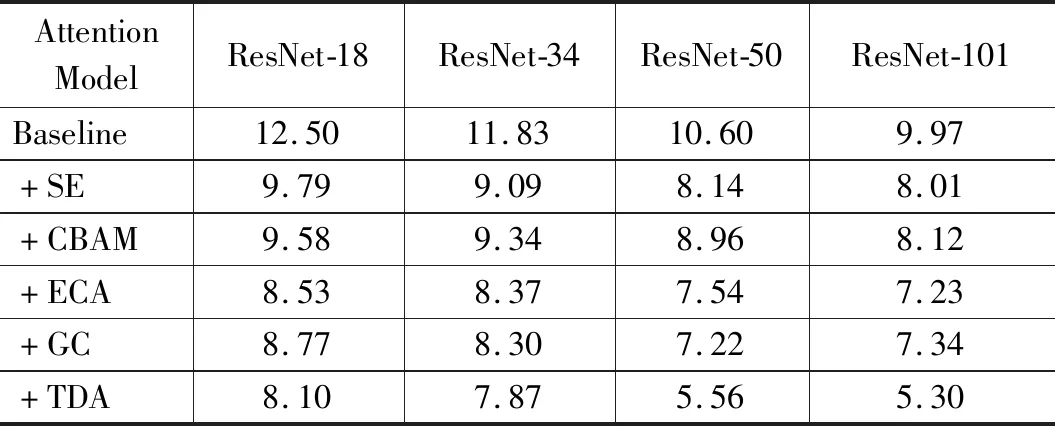
表1 前车窗数据集测试对比分析
从实验数据来看,相比SENet等注意力机制,三维注意力机制拥有相对来说更好的效果。相比SENet,CBAM有约3%的提升,相比ECANet和GCNet有约2%的提升。
2.2 PKU VehicleID数据集
北大VehicleID数据集由北京大学视频技术国家工程实验室(NELVT)在国家基础研究计划和国家自然科学基金委员会的资助下构建。
“VehicleID”数据集包含分布在中国一个小城市的多个现实世界监控摄像头在白天捕获的数据。整个数据集中有26 267辆汽车(共221 763张图像)。每个图像都附有与其在现实世界中的身份相对应的id标签。

图8 PKU VehicleID数据集
对于PKU VehicleID数据集,采用了训练100个epoch, batchsize为64,学习率初始值为1e-5,使用adam优化器,weight decay为0.000 4的设置。
在公开的VehicleID车辆重识别数据集上,表2给出了验证的详细结果。本文设计的三维注意力模块取得了很好的效果,在Small,Medium,Large三种上均获得了最佳效果。
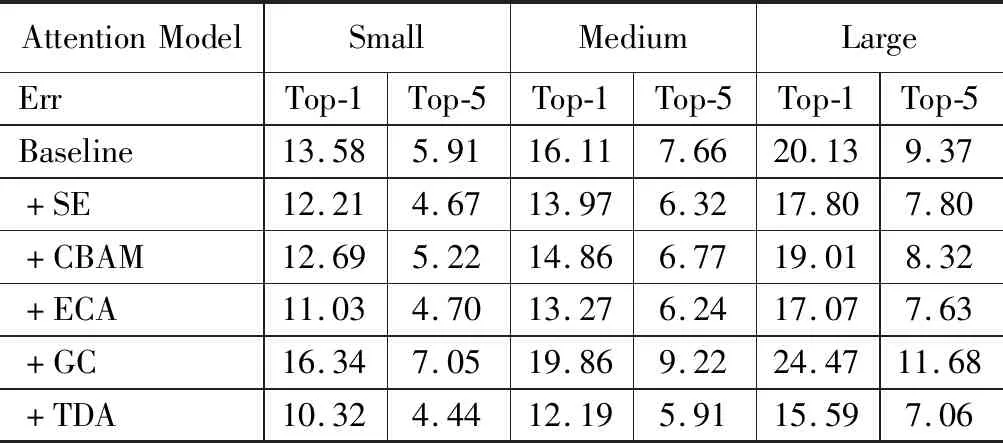
表2 PKU VehicleID数据集测试对比分析
2.3 数据集CIFAR-100分类任务
CIFAR-100 数据集由100个类别的60 000张32×32彩色图像组成,每类有600张图像,其中有500张训练图像和100张测试图像。
对于CIFAR-100测试,用ResNet作为主干网络,验证了ResNet-18,ResNet-34,ResNet-50,ResNet-101四种网络作为基础网络时,三维注意力相比于不添加注意力和添加其他注意力机制都有效果提升。
训练200个epoch,开始的学习率为0.1,在第60,120,160个epoch的时候分别变成0.02,0.004,0.000 8。其中Baseline和添加了SE模块的效果使用了其提供的数据,添加了CBAM,ECA和GC注意力的代码均来自其官方论文所提供的代码。
表3给出了以上这些注意力模块大多数采用了与我们相同的主干网络ResNet。可以看出,本文提出的三维注意力模块在ResNet-50相对于其他注意力模块有比较明显的效果,相比不添加注意力的ResNet-50有2.31%的提升,相比其他的注意力有约1%的提升。值得注意的是,即使是在采用了更加深层的主干网络的时候,三维注意力与基准相比,提升仍然是显著的,这表明了我们的三维注意力模块的有效性。结论表明,三维注意力方法也有较好的鲁棒性。
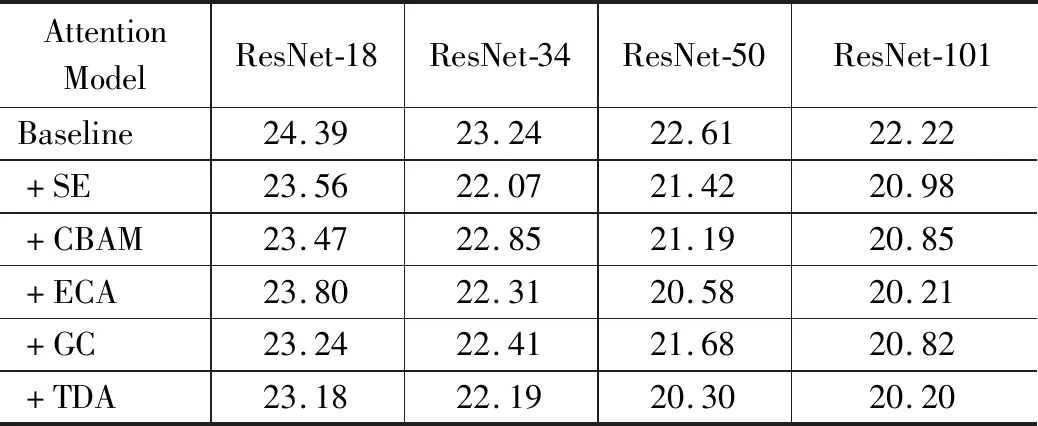
表3 CIFAR-100数据集测试对比分析
2.4 大规模分类数据集ImageNet
ImageNet是一个用于大规模图像分类的基准数据集,包含来自1 000个类的128万张训练图像和5万张验证图像。我们基于带有注意力机制的ResNet50,对三维注意力模块进行了测试。在ILSVRC2012_train数据集上进行训练,在ILSVRC2012_val上测试准确率。ImageNet上的所有训练都使用了8×Tesla V100。
为了加快测试的速度,使用了渐进式图像大小调整来进行分类——在训练开始时使用小图像,然后随着训练的进行逐渐增加大小。图像的宽度从160像素开始训练15个epoch,到320像素训练12个epoch,到图像本身的宽度训练1个epoch。同时使用了LARS(Layer-wise Adaptive Rate Scaling)[24]的优化方法,通过学习率的动态调整,加快模型收敛速度。Batchsize采用 512,在第13,25个epoch时,分别变成224,128。最终我们得到的结果如表4所示。
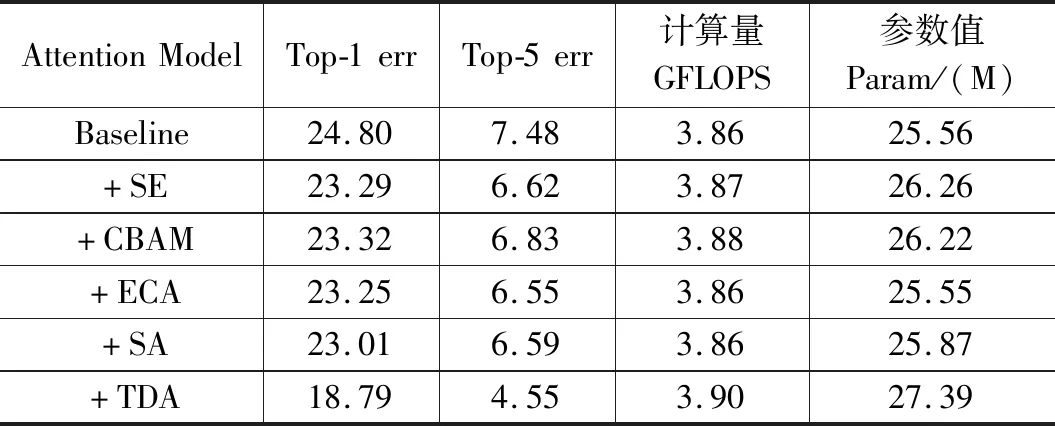
表4 ImageNet数据集测试对比分析
如表4所示,在以ResNet-50为主干网络时,添加了三维注意力模型有6.01%的提升,相比于其他注意力模型有接近5%的提升。
在参数量和计算量没有太大差距的情况下,三维注意力同时达到了轻量化和高效的目标。
2.5 注意力可视化
我们用Grad-CAM[25]对SENet和三维注意力机制进行可视化,并进行对比。

图9 三维注意力的可视化
图中第一列表示未经注意力模块的图像,第二列表示经SE模块得到的图像,第三列表示经本文提出的三维注意力模块得到的图像。
在SENet中,得到的通道注意力处理的图像,并不能非常精确地聚焦图像中的重点信息,而将许多注意力放到了不需要关注的地方。
本文提出的三维注意力在聚焦重点信息上更加具有优势,由于三维注意力所关注的像素同时需要满足在通道和位置上都值得受到注意,所以相比其他注意力更加集中。
同时,在注意力机制上,卷积层比全连接层有更好的表现,所以和SENet的全连接层相比,使用卷积层来获得通道特征的三维注意力能够获得更加贴合物体本身的注意力分布。如图中所示,本文提出的三维注意力所得到的焦点区域相比SENet更加符合人类的注意力特征。
3 结束语
参考已有位置注意力和通道注意力机制,我们提出了一种新的三维注意力模块,能够更全面的反应三维图像中的关键信息,在做到轻量化的同时能有效地提高车辆识别的精确度。把该注意力机制应用到ResNet-50上,大量的实验表明在各类数据集上本文提出三维注意力模块在图像分类的视觉任务上都有很好的效果。
