特征增强和双线性特征向量融合的 移动端工业货箱文本检测
2022-08-01胡海洋厉泽品李忠金
胡海洋,厉泽品,李忠金
(1. 杭州电子科技大学计算机学院,浙江 杭州 310018; 2. 浙江省脑机协同智能重点实验室,浙江 杭州 310018)
0 引言
现实场景中文字承载的高级语义信息能够帮助人们更好地理解周围世界,场景文本检测作为场景文本读取的关键组成部分,一直是计算机视觉领域的热门研究方向,例如工业自动化、自动驾驶和盲人辅助等。
早期的文字检测技术使用传统的模式识别方法,其主要分为两种:一是以连通区域分析为核心技术的文字检测方法[1-3],二是Minetto等[4]提出的以滑动窗口为核心技术的文字检测方法。传统的模式识别方法一般包含4个步骤:字符候选区域生成;候选区域滤除;文本行构造;文本行验证。然而烦琐的检测步骤导致文字检测的实时性差,同时准确率得不到保证。
随着计算机视觉和模式识别领域的发展,卷积神经网络[5]开始崭露头角,逐步成为主流的目标特征提取网络。因此先从训练数据中提取有效的文本特征并建立模型,然后将模型运用于实际环境,并通过文本检测算法完成文本检测任务的深度学习方式逐渐成为主流。
目前,基于深度学习的文本检测方法可以分为两类:一种是基于目标检测方法的回归检测算法,目标检测框架由SSD[6]、FasterRCNN[7]、ResNet[8]等进行针对文字特性的改进得到,这类方法的主要特点是通过回归水平矩形框(anchor)、旋转矩形框以及四边形等形状获得文字检测结果;另一种是基于文本分割方法进行文本检测,此类方法主要借鉴语义分割的思路,将文本像素分到不同的实例中,并通过一些后处理方法获得文本像素级别的定位结果,可以精确定位任意形状的文字,该类方法主要有Liao等[9]提出的可微分二值化(2ifferentiable binarization,DB)后处理算法等。
与传统文字检测方法相比,深度学习的文字检测[10]已经简化了很多步骤,但是网络的加深带来了更大的计算量。ResNet50具有大约25.6 MB大小的参数,以及需要4.1×109FLOPS(floating point operations per secon2,每秒浮点运算次数)的计算量处理一张2242pi× 2242pi 的图像。因此,深度神经网络设计的最新趋势是探索可移植、高效、轻量的网络架构,并为移动设备提供可接受的性能。Han等[11]采用裁剪的方法,对不重要的权值进行裁剪,以此提升网络性能。Howar2等[12]利用深度卷积和逐点卷积相结合构建了MobileNet轻量网络架构,在与VGG16精度相同的情况下,参数量和计算量减少了2个数量级。ShuffleNet[13]改进了通道的shuffle操作,增强了轻量网络的性能。
工厂中的货箱运输环境如图1所示,其中,开发板、显示器、摄像机部署在叉车上,叉车行驶的平均速度为3 m/s左右,摄像机拍摄货箱编号。只有当图片的检测帧率为12 f/s(frames per secon2,每秒传输帧数)以上时,显示器才可以清楚地显示每张图片的检测结果,而处于移动端的文本检测,则需要达到更高的检测帧率才能满足要求,因此需要搭建轻量网络架构,而与轻量网络MobileNet、ShuffleNet文本检测方法相比,工厂环境下的文本检测有其复杂性和特殊性:它所处的运输环境背景混乱、光线变化频繁、文本不规整等。因此在工厂环境下轻量网络文本检测方法无法在保证实时性的同时,达到较高的准确率。

图1 工厂中的货箱运输环境
针对在工厂货箱运输场景中存在的问题,本文提出一种基于轻量级网络的货箱编号检测方法。文本检测模型如图2所示,首先,使用ResNet18作为基础网络架构,用改进的Ghost 模块替换基础残差模块,其中,Ghost 模块嵌入文献[14]中提出的轻量级特征增强技术Squeeze- an2-Excitation,对部分卷积后的特征进行重标定,提高重要特征的权重。其次,采用双分支结构,第一分支使用文献[15]中提出的特征金字塔增强模块(feature pyrami2 enhancement mo2ule,FPEM)提取图像高级和低级信息,第二分支利用本文提出的双线性特征融合向量模块融合不同尺度的特征向量,增强尺度多变的文本特征表达能力。而后特征融合模块(feature fusion mo2ule,FFM)级联所有特征向量。最后,采用DB语义分割算法获得最终结果,其中,修改损失函数为文献[16]中提出的DiceLoss和 MaskLoss。同时在推理阶段采用自适应阈值分割算法替换固定阈值,更能适应工厂环境的光线变化。
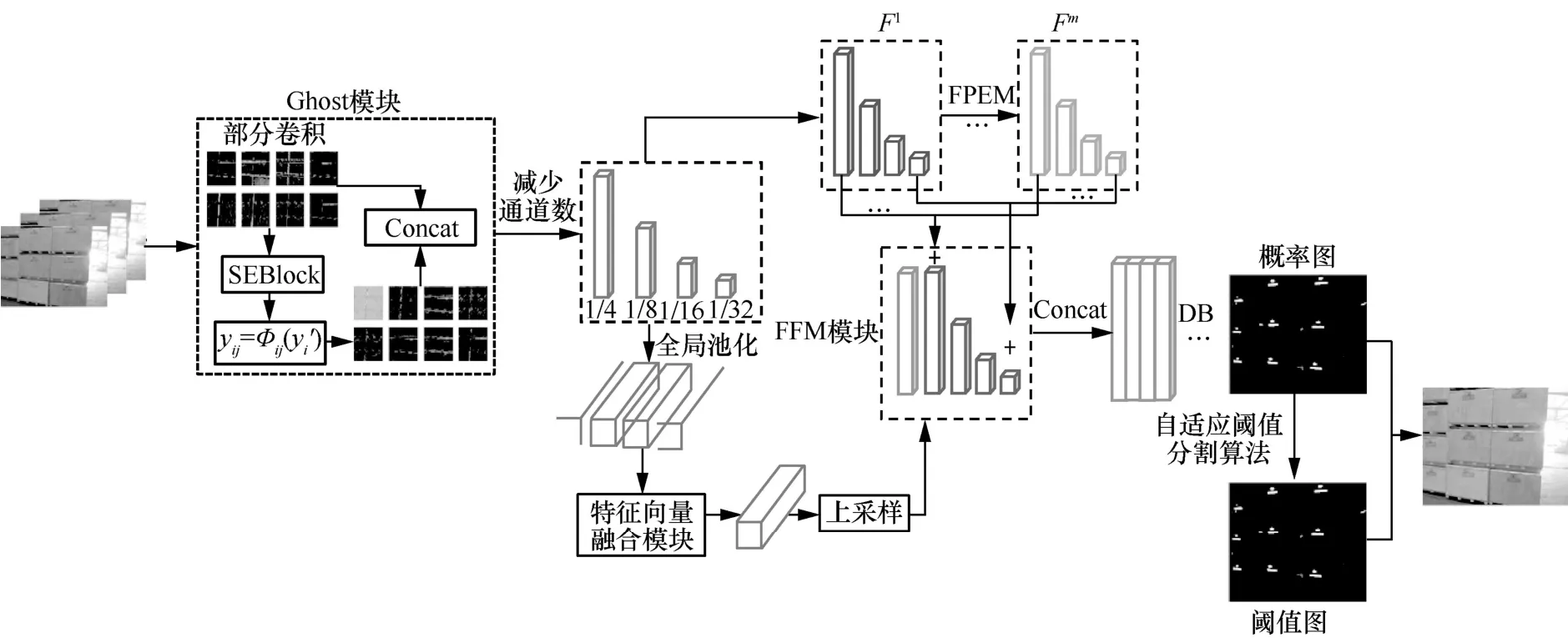
图2 文本检测模型
为了能够训练新型轻量网络框架并评估它的优势,本文创建了一个复杂工厂环境下的货箱文字数据集,数据集中包含了不同种类的货箱,不同视角下、不同形状的文字。实验表明,本文提出的新型轻量级网络框架RGFFD(ResNet18+ GhostMo2ule+特征金字塔增强模块(feature pyrami2 enhancement mo2ule,FPEM)+ 特征融合模块(feature fusion mo2ule,FFM)+可微分二值化(2ifferenttiable binarization,DB ))在实时性和精确度方面都优于其他的网络框架。本文的主要贡献为以下3点。
• 提出了新型的轻量网络架构解决实际工业场景中移动设备的文字检测,并达到了可观的精确度。
• 制作了一个货箱文字数据集对模型进行训练和评估,并最终实现在线部署。
• 在自定义数据集上,本文的模型在识别精度和泛化能力上都超过了主流的文字检测方法。
1 相关工作
近年来,设计轻量高效的神经网络架构一直是热门的研究领域。VGGNets[17]模型表明,增加网络的深度可以显著提高网络的学习特征的能力。同时Batch Normalization操作通过调整输入每一层的分布,提升了深层网络学习过程的稳定性,产生了更平滑的优化曲面。ResNet通过使用残差模型构建更深层次和更强大的网络。而网络的加深带来了更大的计算量,Szege2y等[18]提出采用逐点卷积(1×1)减少参数计算量,并在同一层级利用不同大小的卷积核提取图像不同维度的信息,在保证模型质量的前提下,减少参数量。InceptionV2[19]则通过恰当地分解卷积与积极地正则化尽可能地利用有效的运算。虽然网络的计算成本得到了降低,但是仍无法在一些嵌入式的设备中运行。MobileNet的提出使网络的计算成本出现了大幅度的下降,其主要思想是对每个通道单独利用卷积核进行卷积操作,然后利用逐点卷积融合特征,有效替代传统的卷积层,然而精确度却无法得到保障。MobileNetV2[20]对此进行了扩展,引入线性瓶颈和反向残差结构,主要思想是在深度卷积之前增加逐点卷积操作,使得特征提取能够在高维运行。Howar2等[21]提出MobileNetV3,其添加了轻量级注意力机制,将swish替换为h-swish,以更少的计算量获得更好的性能。ShuffleNet提出逐点组卷积,有效地降低了因为逐点卷积而形成的通道之间的约束,同时采用通道混洗方法提高了通道组之间的信息流通,提高了信息的表示能力。SqueezeNet广泛使用1×1卷积,采用Squeeze-an2-Excitation模块减少参数数量,提升网络的特征提取能力。Lin等[22]提出了特征金字塔网络(feature pyrami2 network,FPN),通过提取并融合上下文信息,使小物体的检测更准确,但由于网络计算复杂,参数量大无法满足实时性要求。Wang等[15]提出了FPEM,采用可分解卷积,降低网络计算量,并通过级联的方式完成高低级特征的提取,同时利用FFM特征融合模块融合不同层次的特征,在保证精度的同时参数量仅为FPN的1/5。
采用轻量网络架构提取图像文本特征,最后利用文本检测算法绘制文本框,文本检测方法大致可以分为两类:基于回归的方法和基于分割的方法。
基于回归的方法是直接回归文本边界框,准确定位文本。Liao等[23]提出的TextBoxes基于SSD修改了anchor和卷积核的尺度,用于文本检测。Liao等[24]提出的TextBoxes++应用四边形回归来检测多方向文本。Tian等[25]首次提出将文字区域分割成一系列小尺度的候选框,同时引入循环神经网络(recurrent neural network,RNN),增加了检测的精度,但只能检测水平方向的文字。Shi等[26]采用角度概念,切割图片为段,使用link检测将属于同一文本的段进行连接,以处理长文本实例。Liao等[27]通过使用旋转不变特征进行分类,使用旋转敏感特征进行回归,将分类和回归解耦,以便在多方向和长文本实例上取得更好的效果。Zhou等[28]提出了全卷积操作,并直接生成预测文本框,利用局部感知非最大抑制(locality- aware non maximum suppression,LNMS)产生最终结果,实现端到端的文本检测。然而这些方法都是为四边形文本检测而设计的,无法识别任意形状的文本。
与基于回归方法不同,基于分割的方法通常结合像素级预测和后处理算法得到边界框,可以检测不规则形状的文本。Deng等[29]提出Pixel-Link概念,对输入图像执行文本和非文本预测以及链接预测,然后通过后处理以获取文本框并过滤噪声,分隔不同的文本实例。Wang等[30]通过分割具有不同规模内核的文本实例,并使用渐进式尺度扩展算法获得最终文本框。然而PSENet因网络计算量大,网络检测文本的实时性大大降低。Wang等[15]引入特征金字塔增强模块,并通过级联的方式提取多级信息,而后采用特征融合模块融合多尺度信息,最后通过像素聚合模块预测相似性向量聚合文本像素,在不降低精度的情况下,减少网络的计算量。DBNet提出了一个可微分二值化模块预测收缩区域,并且收缩区域以恒定的膨胀率扩张,最终获得文本框。Tian等[31]提出了学习形状感知嵌入(learning shape-aware embe22ing,LSAE)方法,将图像像素映射到特征空间中,对属于同一文本实例的像素进行聚类,很好地分割相邻的文本,并且可以检测长文本。
2 本文方法
2.1 特征增强的Ghost模块
深层卷积神经网络中通常由大量的卷积操作组成,这就需要大量的计算量,大多数方法采用逐点卷积处理跨通道的特征,然后采用深度卷积处理空间信息,以此减少网络的计算量。普通的卷积操作会产生大量的冗余信息,特征冗余如图3所示,其中有部分是相似的,因此不需要一个接一个地生成这些冗余的带有大量参数运算的特征映射,而是将相似的特征映射通过某种简单的线性操作进行获取,以此减少计算量。
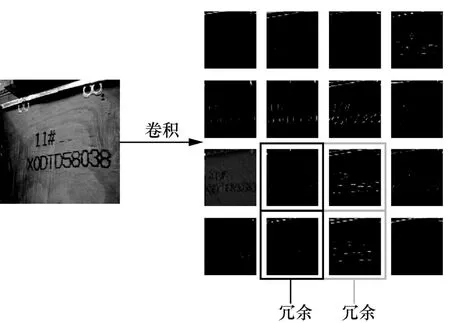
图3 特征冗余
为了解决特征冗余的问题,避免不必要的卷积操作,本文采用改进的Ghost模块替换残差网络的基础残差3×3卷积模块。常规Ghost模块主要由两种关键技术组成,分别是部分卷积和Chollet等[32]提出的DepthWise卷积。相较于常规卷积,部分卷积只有部分特征图是利用卷积核生成的。Depthwise操作的一个卷积核只负责特征映射图的一个通道,一个通道只与一个卷积核进行卷积操作。最后将线性变换的特征图与原先的特征图进行拼接操作,转换为普通卷积操作后通道数相同的特征图。
本文为了使网络能够在训练和测试阶段获得更加完整的文本图像特征,且只提高少许网络的复杂性,因此采用轻量级特征增强技术Squeeze-an2-Excitation,Squeeze-an2-Excitation模块如图4所示,通过显式地建模卷积特征通道之间的相互依赖性提高网络的性能。

图4 Squeeze-an2-Excitation模块
Ghost模块改进方法示意图如图5所示,其中改进方法1将特征增强模块Squeeze-an2-Excitation嵌入Ghost模块中,在部分卷积之后进行特征增强。改进方法2选择在部分卷积和DepthWise卷积后进行特征增强。相较于方法2,方法1在进行特征增强时所需要的网络计算量更少,Ghost模块部分卷积操作只产生通道数为N/2的特征图,因此只需要对一半的特征图进行特征增强。而在工厂环境下,叉车运行速度较快,需要网络检测图片的速率达20 f/s以上,才可以清晰地显示图片。因此本文选择改进方法1,减少网络计算量,提升网络检测速率。
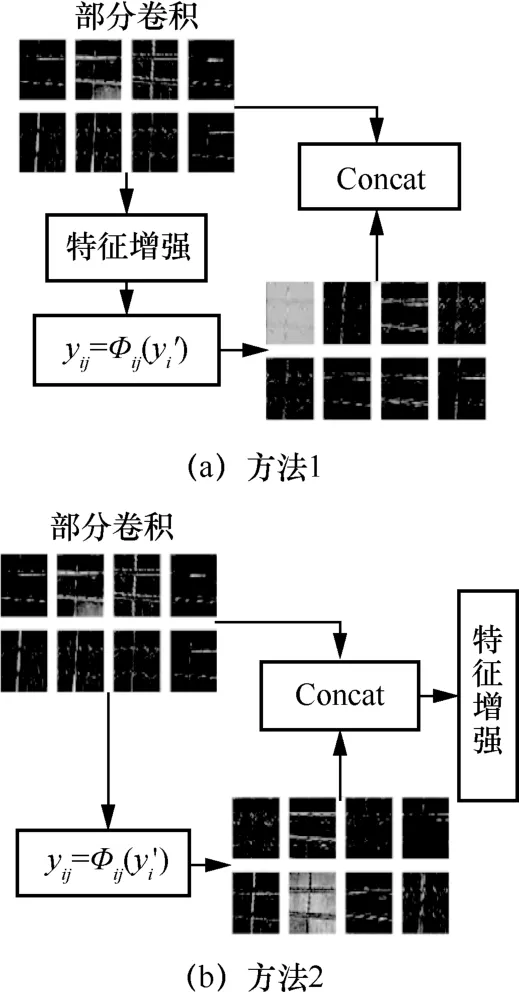
图5 Ghost模块改进方法示意图
2.2 双线性特征向量融合模块
工厂环境复杂,在不同视角存在大量尺度不同的文本,因此为了融合不同尺度的文本特征,增强尺度多变的文本特征表达能力,本文提出了双线性特征向量融合模块。
长短期记忆(long short-term memory,LSTM)[33]是特征向量融合模块的核心成分,LSTM首先被应用在文本识别。特征融合模块细节如图6所示,本文特征向量融合模块仅由4个特征向量组合而成,因此本文舍弃了长期记忆,采用简单的线性操作融合以前的输入信息,将不同层次的特征向量依次输入特征向量融合模块中。其中,tanh网络创建一个可以存储的向量Ct,sigmoi2网络层为此向量中的每个值输出一个0~1的数值it,决定要存储哪些状态值,最后通过简单的线性操作进行融合。通过训练,可以使最后一个特征向量对应的输出存储了所有特征向量重要的信息。因为本文提出的双线性特征向量融合模块只需要经过简单的线性操作,就可以完成不同尺度特征向量的融合,因此在不影响实时性的同时,增加了网络检测的精确率。双线性特征向量融合模块公式化为:
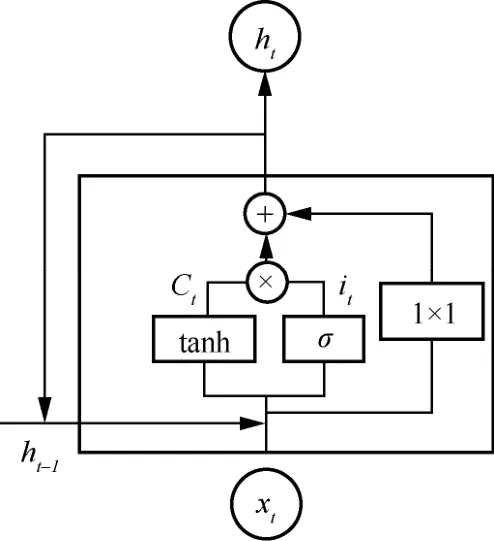
图6 特征融合模块细节
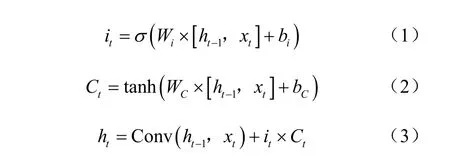
其中 ,it为sigmoi2网络层的输出,Ct为tanh网络层的输出,σ为sigmoi2网络层,ht-1为上一次的输出,xt为第t次的输入。Wi、WC、bi、bC为权重。
2.3 特征金字塔和特征融合
FPN采用特征金字塔模型,对高低层的语义信息进行融合,提高网络检测不同尺度的目标的精度,然而特征融合采用上采样、逐个位相加、向量拼接技术,大大增加了网络计算量,无法保证网络的实时性。FPEM能够通过融合低级和高级信息增强不同尺度的特征。FPEM模块细节如图7所示,FPEM是可级联的模块,随着级联层数的增加,不同尺度的特征图会得到更充分的融合,特征图的感受野也随之增大。此外,因为FPEM是通过可分解卷积构建的,其计算开销非常小,仅为FPN的1/5左右。

图7 FPEM模块细节
FFM模块示意图如图8所示,特征融合模块FFM对FPEM级联产生的不同层次的特征F1,F2,…,Fm进行融合。为增强不同尺度文本的特征表达能力,本文对FFM进行改进,将特征融合后的向量进行上采样并与原模型相级联,获得通道数为5×128,大小为原图1/4的最终特征图。

图8 FFM模块示意图
2.4 自适应阈值后处理DB算法
DBNet采用可微分二值化处理,使阈值在训练期间能随着网络一起优化,同时基于阈值图和概率图获取近似二值图。DBNet提供的可微的二值化计算式为:

其中,Pi,j表示该区域有文字的概率,如果没有文字区域,Pi,j为0;Ti,j是由网络学习到的阈值图;k表示放大系数。
总的损失函数L可以表示为概率图的损失与二值图的损失与阈值图的损失的加权和:
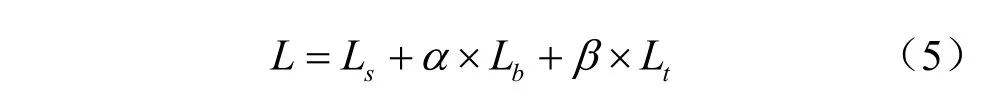
其中,LS是概率图的损失值,Lb是二值图的损失值,Lt是阈值图的损失。其中,α和β分别被设置为5和10。其中LS和Lb分别使用DiceLoss损失函数来进行训练,DiceLoss常用于医学图像分割,其目的就是解决前景比例太小的问题。其计算式为:
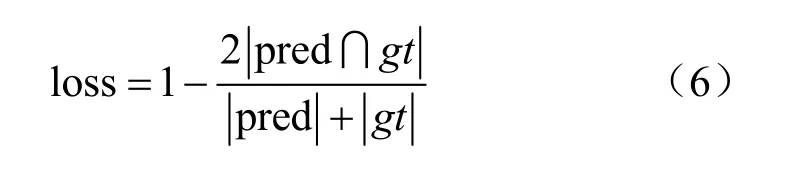
DiceLoss损失函数特点就是收敛速度快,且收敛速度优于交叉熵等分类损失函数。Lt采用Mask L1 Loss损失函数来进行训练,通过掩模进行Lt损失函数的计算。其计算式为:

其中,Lt损失为平均绝对差值,而后增加了mask掩模,对mask指定的区域进行Lt损失函数的计算,n为膨胀后的图像区域在mask掩模下需要进行计算的数量总和。绝对值为预测文本框与标签的距离差值。
DB算法检测不规整文本如图9所示,本文采用自适应阈值替换固定阈值获取阈值图。最终文本框的获取有3个步骤。
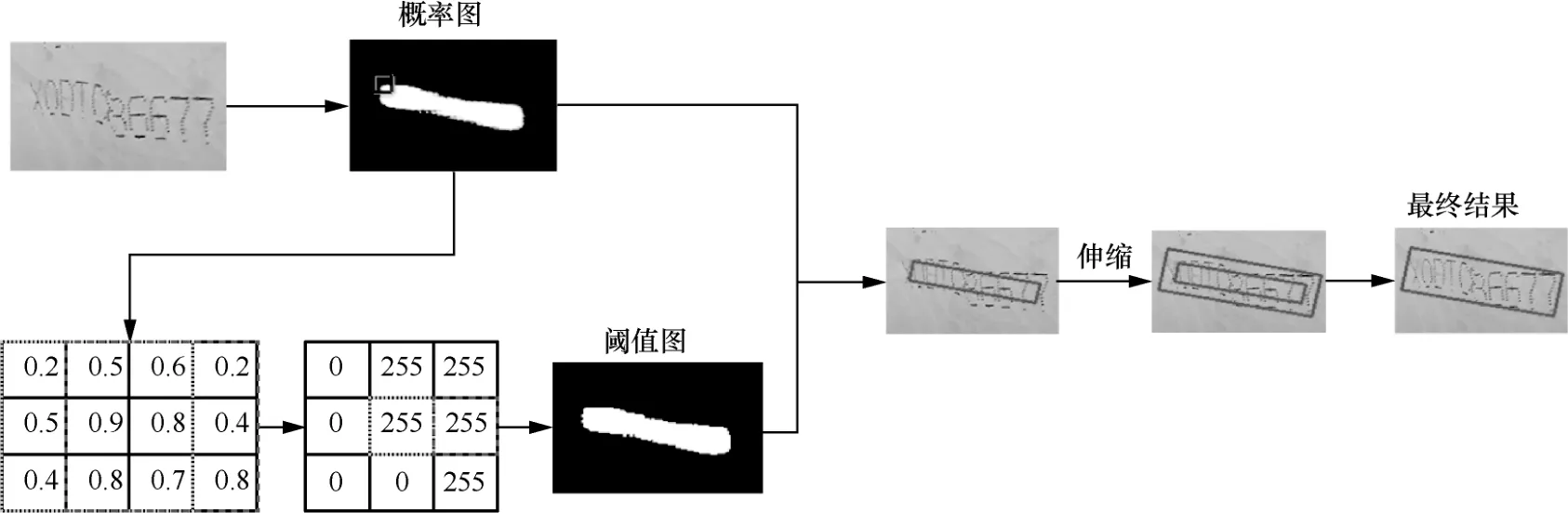
图9 DB算法检测不规整文本
步骤1采用网络输出概率图,其值范围为[0,1],DBNet设定常数阈值(0.2)获取阈值图,本文不设定固定的阈值获取阈值图,而是通过设置九宫格掩模对概率图进行自适应阈值计算获得阈值图,自适应阈值计算式为:

其中,x、y为图像中的坐标,fx,y是坐标为(x,y)的像素值,t为自适应阈值算法求得的阈值,px+i,y+j为原图坐标为(x+i,y+j) 的像素值,fx,y是坐标为(x,y)的阈值。
步骤2从概率图和阈值图中获取连接区域。
步骤3扩大文本区域,进行膨胀,扩大的倍数为D’= (A′×r′) /L′,A′为多边形的面积,L′为多边形的面积,r′被设定为1.8。
3 实验
3.1 数据集
利用本文的网络RGFFD,在ICDAR2015、Total-text以及本文采集并设计的数据集上进行实验和评估,具体如下。
• ICDAR2015数据集:主要面向自然场景的文本检测,有1000张训练图片和500张测试图片,其中图片的像素大小为1280 2pi × 7202pi。
• 自定义数据集:针对复杂工厂环境下货箱编码检测的问题而采集的数据集,包含了在不同形状的木板箱子上从不同角度采集的3000多张的文本图片,其中文本样式各异,并且倾斜角度不同,文字背景信息复杂。文本框区域用矩形的4个坐标点来进行记录。其中图片的像素大小为1280 2pi×7202pi。
• Total-text数据集:包含各种形状文本的数据集,包括水平、多方向和曲线文本实例,由1255张训练图像和300张测试图像组成,文本实例以单词级标注。
3.2 实验环境和模型的训练
在本实验中,实验数据训练在64位的Win2ows系统上,内存为16 GB,CPU是8核,显卡为RTX2060。所有的实验都是通过PyTorch深度学习框架完成的,模型的循环次数(epoch)为500,学习率被设置为0.001,每次训练选取样本数量为8。
实验检测结果在开发板UP2 boar2中运行,开发板具体配置为Win2ows10系统,内存为8 GB,容量大小为64 GB,处理器为N4200。
3.3 网络参数设置
本实验的反向传播选用的是A2am优化算法,A2am优化器是一个寻找全局最优点的优化算法,算法引入了二次梯度校正。
3.4 评价指标
由于常规的视频需要达到12 f/s,显示器才可以清楚地显示每张图片,而处于移动端的文本检测,叉车平均行驶速度为3 m/s,则需要更高的帧率才能满足要求。经实验可知,当帧率达到20 f/s或以上时,图片可以流畅地显示,因此本文算法的性能由精确率、召回率、帧率(检测速度)(f/s)以及检测速度与20的差值这4个指标来衡量。
4 结果比较
4.1 模型对比实验
本文方法与近年出现的其他方法在多个数据集上进行了对比,在公共数据集中算法的实验结果由算法作者提供,自定义数据集中算法的实验结果由本文作者实现。本文方法在ICDAR2015数据集中与不同文本检测方法的比较见表1。由实验结果可知,TextFuseNet在ICDAR2015数据集中的检测精确率和召回率已与SOTA相近,但是网络复杂,计算参数量大,导致网络的检测速度较慢,无法满足20 f/s的要求。PAN(pixel aggregation network)作为PSENet的改进版,将精确率和检测速度做到了很好的平衡,但是本文提出的RGFFD网络同样采用PAN的特征金字塔和特征融合模块并进行改进,在精确率上超过PAN 0.4%,同时在召回率上与PAN接近,且利用改进的Ghost模块替换常规卷积,在速度方面更是超过PAN 2.1 f/s,与其他网络相比本文方法检测速度达到最快。

表1 本文方法在ICDAR2015数据集成中 与不同文本检测方法的比较
本文方法在Total-text数据集中与不同文本检测方法的比较见表2,TextFuseNet在精确率和召回率上已和SOTA相近,但是检测速度不满足 要求,无法达到20 f/s,而PAN在精确率和召回率上与TextFuseNet相近,且速度更是达到39.9 f/s。本文提出的RGFFD网络精确率与PAN相近,且检测速度高于PAN 5.7 f/s。与其他网络相比,本文方法检测速度达到最快。
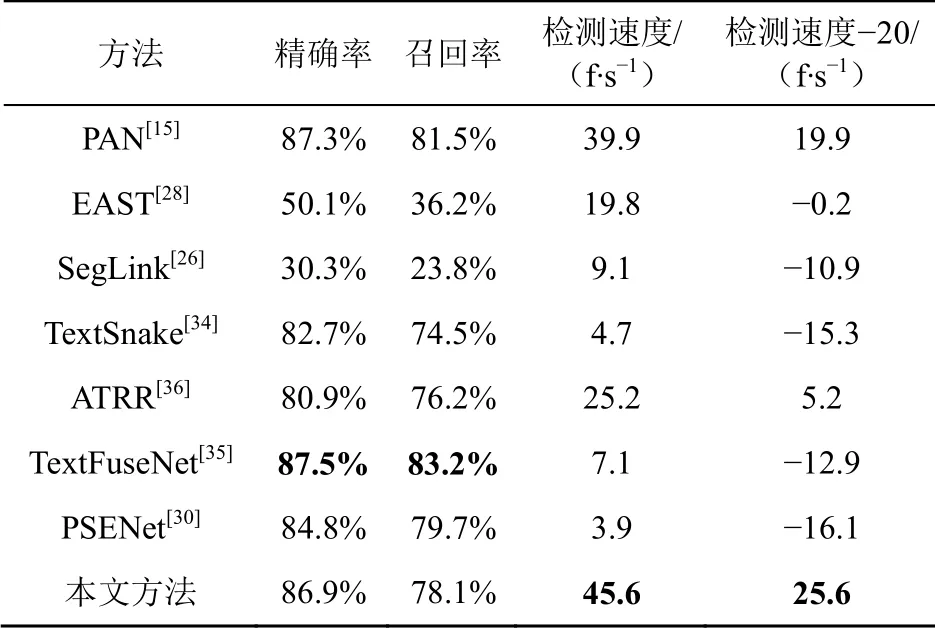
表2 本文方法在Total-text数据集中 与不同文本检测方法的比较
本文方法在自定义数据集中与不同文本检测方法的比较见表3,TextFuseNet的精确率和召回率都显示出自己的优势,但是由于网络复杂、计算量大,网络的检测速度未能达到20 f/s。本文的方法RGFFD,精确率和召回率都与TextFuseNet相近,且检测速度达到20 f/s的要求,并超出TextFuseNet 23.2 f/s。PAN虽然检测速度也达到20 f/s的要求,但是精确率却没有RGFFD高,因此本文的方法RGFFD性能更优异。

表3 本文方法在自定义数据集中与不同文本检测方法的比较
针对复杂工厂环境,将训练好的网络参数移植入开发板UP2 boar2进行检测,开发板中不同方法的效果比较见表4。实验结果表明本文的方法检测速度最快。

表4 开发板中不同方法效果比较
开发板检测的文本效果如图10所示,图10(a)为MobileNetV3+DB网络检测的结果,图10(b)为RGFFD的检测结果。可以看出本文的检测方法能够精确检测远处尺度较小的货箱文本,且针对不同角度,RGFFD也能精确检测。因此,RGFFD能够在工厂环境下高效地完成文本检测任务。

图10 开发板检测的文本效果
4.2 消融研究
为了验证本文不同模块在检测过程中发挥作用,针对不同模块设计了消融实验,所有消融实验均在自定义数据集上进行。
针对Ghost模块,设计了3组实验:第1组实验不对网络嵌入任何模块,第2组实验嵌入的Ghost模块采用改进方法1(如图5所示),第3组实验嵌入的Ghost模块采用改进方法2(如图5所示)。第1组实验、第2组实验与第3组实验形成对比,分别探究删除、不同改进方法对结果的影响,如果第2组实验结果优于第1组实验、第3组实验,则说明本文改进的Ghost模块在文本检测流程中发挥了不可或缺的作用。
本文实验的运行环境以及参数设置均与原实验相同。不同嵌入模块的实验结果对比见表5。由实验结果可知:嵌入Ghost模块之后,网络的检测速度得到了提升,这说明Ghost模块为轻量级。而比较第2组实验、第3组实验,可以发现改进方法1相较于改进方法2,计算的参数量更少,网络的检测速度高出0.8 f/s,且精确率两者相接近,召回率高出0.8%,进一步证明了方法1的有效性。

表5 不同嵌入模块的实验结果对比
此外,本文设计了消融实验验证特征向量融合模块的有效性。特征向量融合模块效果比较见表6。由实验结果可知,嵌入特征向量融合模块虽然降低了检测速度,但是精确率和召回率得到了提升,相较于原来精确率提升了1.1%,召回率提升了0.3%。
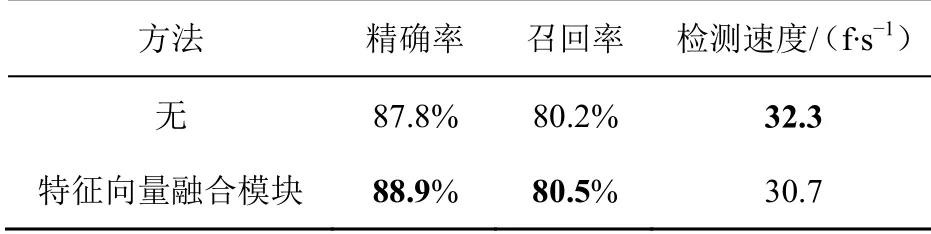
表6 特征向量融合模块效果比较
在推理阶段,本文设计了消融实验验证自适应阈值的DB算法的有效性。在自定义数据集中不同方法的检测结果如图11所示,实验结果表明采用自适应阈值分割算法获得的平均联合交叉(intersection over union,IOU)值要较固定阈值(0.2)高出4%,而文本检测获得的IOU值越高,越能判定文本框的存在,因此真阳率得到了5.2%的提升。因为工厂环境复杂、文本较小、光线变化频繁等因素,直接使用全局阈值分割算法容易引入噪声等不确定因素影响阈值,而自适应阈值分割算法,只获取像素点周围九宫格内的像素进行阈值计算,更好地限制了不利因素,且适应文本较小的情况。

图11 在自定义数据集中不同方法的检测结果
推理阶段检测结果如图12所示,展示了采用自适应阈值分割算法与固定阈值方法检测文本的实验图,图12(a)为固定阈值(0.2)的检测结果,图12(b)为自适应阈值分割算法的检测结果。可以发现在光照频繁变化的情况下,自适应阈值分割算法的判断能力更好,固定阈值算法会发生很多误判,因此自适应阈值分割算法在文本检测流程中发挥着不可或缺的作用。

图12 推理阶段检测结果
5 结束语
本文提出的轻量级文本检测网络RGFFD,采用改进的Ghost模块大幅度降低计算量的同时嵌入特征增强模块(SEBlock)提升Ghost模块提取特征能力,而后连接特征金字塔(FPEM)融合图像高低层语义信息,同时使用双线性特征向量融合模块,增强尺度多变的文本特征表达能力,而后采用特征融合模块(FFM)融合各特征向量。实验结果表明,在工厂环境下,RGFFD网络运行在嵌入式设备UP2 板中,检测速度最快且精度高,因此本文的网络性能更优异。而采用Dice Loss和Mask L1 Loss作为损失函数的DB算法,收敛效果更好。在推理阶段,采用自适应阈值分割算法来获取阈值的方法比直接采用固定阈值的方法,更加能够适应各种环境变化,图片检测文本框的效果也更加精准。
