生物信息综合数据库KEGG的应用
2022-07-30袁炜耿辉王馨笛蒿花王亚军陈新欢马茂
袁炜,耿辉,王馨笛,蒿花,王亚军,陈新欢,马茂
KEGG数据库是日本京都大学生物信息学中心的Kanehisa实验室于1995年建立的生物信息综合数据库[1]。该数据库由4个类别共计17个子数据库,全面集成了生物细胞过程、遗传信息、人类疾病等数据,并通过数据的相关信息开发可视化的网络预测工具,尝试用计算机解释蛋白质交互网络在各种细胞活动中的作用,并提供相应的基因和蛋白质的相关信息、化合物及其反应类别的信息[2]。
基因芯片技术的出现使现代生命科学研究发生了革命性变化,科研人员从掌握个体基因发展到研究基因组及互作网络的功能,运用计算机从宏观角度解决微观世界的作用机制成为现代分子生物学的常规手段,刁兴华等[3]利用KEGG数据库筛选与多囊卵巢综合征(PCOS)相关的关键miRNA和mRNA,发现C型凝集素受体信号传导途径,类固醇生物合成和半乳糖代谢显着富集,该结论可能有助于为PCOS提供新的发病机理及诊断治疗方法。学者Amanda等[4]在一项关于饮食策略改变肠道微生物群帮助肥胖者进行体重管理的研究中,应用KEGG数据库进行代谢组学研究,分析粪便细菌的差异及预测功能分布。彭陈等[5]将筛选后的差异基因在KEGG数据库的信号通路中富集,推测出Sox11和lncRNA Slc6a19os是神经性疼痛的发病及疾病进展过程中的关键基因。李浩文等[6]为研究冠状动脉组织中脂质代谢产物改变如何影响进程中表型变化,利用KEGG数据库对动脉粥样硬化不同阶段脂质代谢产物进行富集分析,获得了特定疾病脂质特征的详细描述。潘晓勇等[7]提出一种基于KEGG数据库的功能及网络嵌入方法来预测蛋白质的亚细胞定位。王兵等[8]为研究非编码RNA(ncRNAs)在重症急性胰腺炎(SAP)发生及细胞过程中的作用,将差异表达的基因通过KEGG数据库的富集分析,寻找SAP的发病机理及新的治疗靶点。辛雯等[9]系统地分析了RNA结合蛋白(RBPs)在胰腺腺癌(PAAD)中的表达,通过KEGG数据库的富集分析,构建了与RBP相关的PAAD预后风险模。
1 KEGG数据库查询流程
KEGG数据库1995年由Kanehisa实验室建立于日本京都大学生物信息学中心,主要目标是通过基因组信息实现包括细胞、生物和生态系统在内的生物系统的信息化重建,将来源于已发表文献中的实验数据以分子相互作用和反应网络用可视化的形式展现出来,尝试将特定生物种群中观察到的实验证据推广到另一生物种群中。KEGG的四个类别分别是“Systems information”KEGG系统信息、“Genomic information”基因组信息、“Chemical information”化学信息、“Health information”健康信息[10],研究者通过这四个类别板块获得完整的基因组序列后,采用网站提供的信息技术重建生物系统并推断其功能,预测目标基因及其产物如何在通路中发挥作用,进而研究其在疾病的发生发展中的影响[11]。
2 KEGG子数据库
KEGG数据库主页(https://www.kegg.jp/kegg/)点击“Current statistics”查询子数据库信息,结果共有17个子数据库包括:“KEGG PATHWAY”医学信号通路、“KEGG BRITE”整合多种类型关系、“KEGG MODULE”功能单元模块、“KEGG ORTHOLOGY”直系同源系统、“KEGG GENOME”基因组数据库、“KEGG GENES”基因数据库、“KEGG SSDB”序列相似性数据库、“KEGG COMPOUND”化合物数据库、“KEGG GLYCAN”多聚糖查询数据库、“KEGG REACTION”生化反应数据库、“KEGG REACTION”生化反应类别数据库、“KEGG ENZYME”酶数据库、“KEGG NETWORK”疾病相关网络数据库、“KEGG VARIANT”基因突变数据库、“KEGG DISEASE”疾病数据库、“KEGG DRUG”药物数据库、“KEGG ENVIRON”与健康相关信息数据库、“KEGG MEDICUS”日本药物查询数据库,如图1所示。KEGG数据库为研究者提供目标基因的信号通路,与其相关的同源系统,所在基因组信息,与其序列相似的基因信息,产生的化学反应,相关的疾病等信息,帮助其一站式全面掌握目标基因的综合信息。
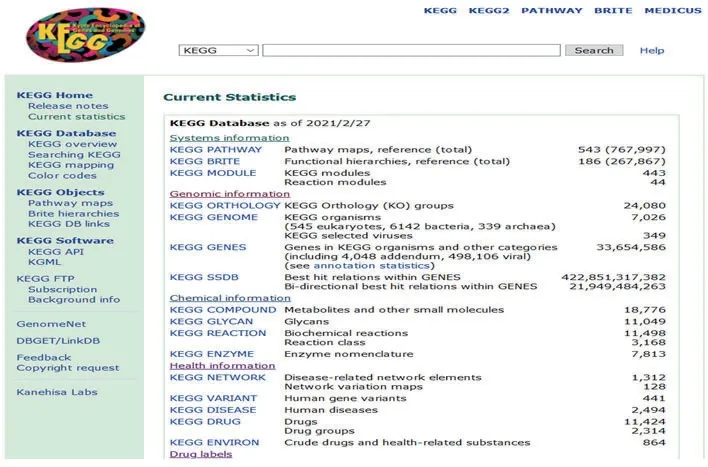
图1 KEGG数据库主页面
2.1 Systems information信息系统板块子数据库应用KEGG数据库的“Systems information”信息系统板块包括“KEGG PATHWAY”医学信号通路、“KEGG BRITE”整合多种类型关系、“KEGG MODULE”功能单元模块三个子数据库。
点击“KEGG PATHWAY”按钮跳转至信号通路子数据库,在“Select prefix”下方填写has(homo sapiens)人类来源,其他物种也可以点击“Organism”按钮进行查询,在“Enter keywords”中输入目标基因,点击“GO”进行检索,检索页面如图2所示。

图2 KEGG PATHWAY子数据库示意图
检索结果包含“Entry”入口信息、“Thumbnail Image”缩略图、“Name”通路名称、“Description”通路描述、“Object”化合物信息、“Legend”通路说明。“Entry”列表下面会显示以“hsa”为前缀加上数字组成的标识符,表示KEGG数据库的特定数据对象,不同的子类有不同的前缀,点击该标识符,会跳转到新页面显示该信号通路的详细信息,包括网络、相关对象、相关药物、相关基因、相关文献、相关通路等信息,如图3所示。

图3 KEGG PATHWAY子页面示意图
“KEGG BRITE”整合多种类型关系,进行目标数据的层次分类,依类别展开生物对象的功能,使用“HTML tables”形式展示层次结构文本文件,层次关系包含五种,分别为:基因和蛋白质、化合物与反应、药品、疾病、生物和细胞。
“KEGG MODULE”功能单元模块以M编号标识的KEGG模块和以RM编号标识的KEGG反应模块组成,KEGG模块进一步分为“pathway modules”通路模块和“signature modules”签名模块,通路模块展示代谢途径中基因集包括分子复合物的功能单元,签名模块展示表型特征的基因组功能单元,反应模块展示代谢途径中连续反应步骤的功能单元。
2.2 Genomic information信息板块子数据库应用KEGG数据库的“Genomic information”信息系统板块包括“KEGG ORTHOLOGY”直系同源系统、“KEGG GENOME”基因组数据库、“KEGG GENES”基因数据库、“KEGG SSDB”序列相似性数据库四个子数据库。
“KEGG ORTHOLOGY”直系同源数据库简写为“KO”,KO数据库的检索方法为:“Search”栏的“for”文本框中输入目标编码,该编码是以K编号为标识的“KO”数据库的专有编码,点击“Go”会转到目标代码的详细信息页面, 包括“Entry”编码信息、“Name”目标蛋白/基因的名称、“Definition”定义、“Pathway”相关通路信息、“Module”功能模块数据库中的信息、“Disease”相关疾病信息等信息,如图4所示。

图4 KEGG ORTHOLOGY子页面示意图
“KO”数据库主页面“Enter K numbers”里输入目标编码,点击“Ortholog table”直系同源表,可查看与该编码同源的详细物种信息。
“KEGG GENOME”基因组数据库,可查询几乎所有物种的具有完整基因组序列的相关信息,信息代码以T0开头后跟四个字母组成,可以搜索和分析的生物组包括:真核生物、软体动物、节肢动物、软体动物、脊椎动物、哺乳动物、两栖动物、单子叶植物、双子叶植物、藻类、细菌等。
“KEGG GENES”基因数据库主要是集成NCBI RefSeq和GenBank两个数据库的所有完整基因组的基因目录的集合,使用网站工具对基因进行重新注释,并给出了对应物种、染色体位置、蛋白质系列等信息。
“KEGG SSDB”序列相似性数据库包含“KEGG GENES”子数据库完整基因组中所有蛋白质编码基因之间氨基酸序列相似性的信息,包括病毒。所有可能相似的基因组均经过Smith-Waterman相似性检验得分为100或更高,将最佳匹配或双向最佳匹配的基因对信息存储到“KEGG SSDB”数据库中,可搜索直系、旁系同源物以及保守的基因组信息。
2.3 Chemical information信息板块应用介绍KEGG数据库的“Chemical information”信息系统板块包括“KEGG COMPOUND”化合物数据库、“KEGG GLYCAN”多聚糖查询数据库、“KEGG REACTION”生化反应数据库、“KEGG ENZYME”酶数据库五个子数据库。
“KEGG COMPOUND”化合物数据库包含小分子,生物聚合物及其他与生物系统有关化学物质的集合,包括有机酸、脂类、碳水化合物、核酸、肽链、维生素和辅助因子、类固醇、激素和递质以及抗生素共9大类别,数据库为每个化合物设置了以“C”开头后跟四个数字的编码,如L-赖氨酸的编码为“C00047”,在化合物数据库页面的“Search”栏输入“C00047”后点击“GO”按钮,跳转至检索结果,选择自己的目标化合物的编码并点击,跳转新的信息页面,包含该化合物的“Name”名称、“Formula”化合式、“Mol weight”分子量、“Structure”化合物结构、“Reaction”反应、“Pathway”通路、“Module”功能模块、“Enzyme”相关酶等详细信息,如图5所示。
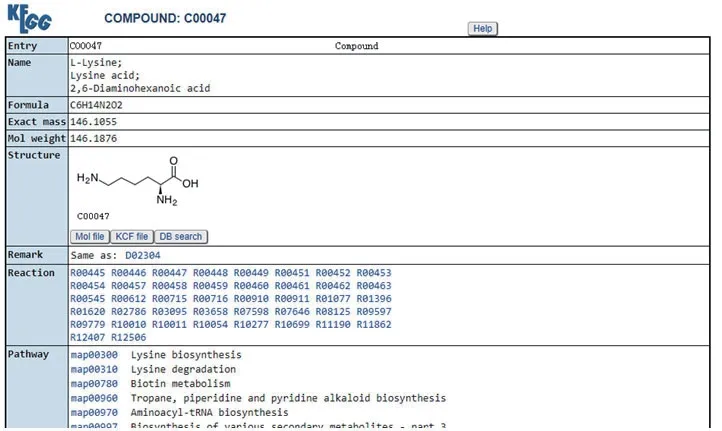
图5 KEGG COMPOUND子页面示意图
“KEGG GLYCAN”多聚糖查询数据库,该数据库集合了实验验证的聚糖结构数据,包括从CarbBank数据库、最新出版物以及“KEGG PATHWAY”中存在的聚糖结构。每个结构都有单独的以“G”开头数字结尾的编码,也可以通过点击“SNFG”按钮转换为聚糖的符号命名法(Symbol Nomenclature for Glycans,SNFG)表示。
“KEGG REACTION”生化反应数据库以及“KEGG ENZYME”酶数据库是同一个数据库,因为KEGG收录的化学反应主要是酶促反应,因此“KEGG REACTION”生化反应数据库将酶促反应设置为一个以“R”开头的单独编码,每条编码的信息页面包含了酶促反应对应的酶、酶促反应的通路、表达式、定义等。
2.4 Health information及Drug labels板块应用简介KEGG数据库的“Health information”、“Drug labels”信息系统板块包括“KEGG NETWORK”疾病相关网络数据库、“KEGG VARIANT”基因突变数据库、“KEGG DISEASE”疾病数据库、“KEGG DRUG”药物数据库、“KEGG ENVIRON”与健康相关信息数据库、“KEGG MEDICUS”日本药物查询数据库六个子数据库。
“KEGG NETWORK”疾病相关网络数据库,通过对通路图分子图标着色,表示该分子易受到突变、病原体、环境因素等的干扰,引起通路的变化,其颜色分别显示为:红色、紫色和蓝色,通路中的符号及其意义为:“→”激活、“┤”抑制、“—”复合物形成等,如图6所示。

图6 KEGG NETWORK子页面示意图
“KEGG VARIANT”基因突变数据库与“KEGG NETWORK”查询方式相同,此处不再赘述。
“KEGG DISEASE”疾病数据库,疾病被视为分子网络系统中非正常状态,疾病的遗传、环境因素以及药物对该系统产生不同的影响,将其展示在“KEGG PATHWAY”数据库的疾病通路图中,疾病基因被标记为红色,每条针对于疾病的通路均有一个特定的编码,以“H”后接数字组成。
“KEGG DRUG”药物数据库包括日本,美国和欧洲已批准药物信的息资源,基于其活性成分的化学结构、化学成分进行了区分和统一,数据库中每个药物均由一个以“D”开头后接数字的编码组成,内容包括其治疗目标,药物代谢、与其他分子相互作用网络信息等。
“KEGG ENVIRON”与健康相关信息数据库,包含以各种天然产物为主要数据来源的数据库,包括“Crude drugs”生药、“Essential oils”精油、“Medicinal herbs”草药三类,该数据库是对“KEGG DRUG”药物数据库的重要补充,每种物质由字母“D”加数字编码组成,内容包括化学成分,功效信息和来源物种信息等。
“KEGG MEDICUS”日本药物查询数据库,通过CAS号、化学名称检索在日本和美国销售的所有药品,及其相关疾病、健康相关物质的综合信息资源数据库。
3 讨论
KEGG全称为Kyoto Encyclopedia of Genes and Genomes(京都基因与基因组百科全书),是日本京都大学生物信息学中心于1995年建立的包括生物细胞过程(Cellular Processes)、环境信息处理(Environmental Information Processing)、遗传信息处理(Genetic Information Processing)、人类疾病(Human Diseases)、新陈代谢(Metabolism)、生物体系统(Organismal Systems)等信息的综合性数据库[12,13],其目标是通过基因组信息实现包括细胞、动物等生物活动过程的计算机重建[14]。
KEGG数据库能从基因组序列及其他分子数据集中预测目标基因在细胞和生物体中的功能[15],开发了基于相同基因序列及功能的直系同源物概念从分子结构单元重建通路系统预测分子状态的方法,通路图代表生物系统的分子互作图,分为代谢、遗传信息处理、环境信息处理、细胞过程、生物系统和人类疾病,涵盖了互作网络、与疾病相关的变异以及药物-靶标关系等功能[16]。基础数据来源于文献中发表的实验数据,从中获取生物学信息,建立以实验数据为基础的分子相互作用和反应网络,形成以代谢通路、基因信息、化合物、酶、药物等为主的子数据库,生物过程以可视化的通路图形式展示在“KEGG PATHWAY”数据库中,网络中的节点与“KEGG ORTHOLOGY”直系同源数据库关联,将特定物种中观察到的实验数据推广到其他物种,进而建立跨物种的联系。因此,一旦实验数据获得某个分子的完整基因组序列,通过整合基因组、化学成分、系统功能、通路富集等信息,基于计算机的高级算法将实验得到的证据形成可视化的系统功能知识库,展示因人类基因变异、药物调控、病毒入侵及其他病原体和环境因素等引起疾病变化的关键分子通路网络状态,使科研人员能够更直观的了解某一分子的变化对疾病通路产生的影响,并通过KEGG数据库重建某一物种的生物系统,推断同源分子在该物种甚至其他物种中的高级功能等信息,对开展下一步研究创造有利条件。
借助计算机全面地分析细胞和生物所包含的生物学信息是后基因组时代的重大挑战,KEGG数据库能够根据基因组中的信息,用计算机计算或者预测出复杂的细胞中的通路或者生物的复杂行为,未来将综合更多大型生物数据库信息,如组织芯片等对实验数据进行补充,扩充更多的基因组信息等,使通路富集数据预测某分子的生物学功能证据更加全面可靠。
