基于BP 神经网络的养老床位供需分配分析
2022-07-29朱辰超刘雅雅
朱辰超,刘雅雅
(上海理工大学 管理学院,上海 200093)
0 引言
中国老龄化问题日益突出,家庭养老的形式难以满足老年人的养老需求。李林潼经过调查研究,发现解决现状的重要方法是采用机构养老的形式,但机构养老在现阶段的实施中存在床位供需失衡的问题。关于养老床位需求的研究,余莹等人运用系统聚类方法分析上海市各个区的养老区域划分。徐佩等人用时间序列模型对上海市的机构养老床位供给量进行预测。除了针对某一个具体省份分析外,曹稀哲等人用多元回归的方法来预测未来六年中国整体的机构床位需求量。王子鑫等人分析了城市和乡村老年人的养老床位需求。大部分关于养老机构床位的研究都只是分析整体的需求量、或者城乡的需求量,很少细化到各个省份来探讨分析。虽然高巍等人基于31 个省份的数据,运用多目标规划来分析养老服务运营模式,但是最终并没有提出各个省份具体的养老服务运营策略。近年来,很多学者采用聚类分析与判别分析结合的方法研究区域化和老年人能力等级的分类问题。但是判别分析有很多种方法,选择不同方法,得到的判别函数也不同,有误判的现象发生。
综上所述,现阶段对于机构养老床位的需求分析并没有细化到各个省份,只是停留在城乡的阶段。基于此,本文主要采用BP 神经网络和灰色预测模型,地区化分析31 个省份养老机构床位的需求量,力图实现省份间的合理分配,解决机构养老床位供需失衡的问题。同时将判别分析与BP 神经网络的精确度进行对比分析,以期减少误判现象,实现地区的准确分类。选用65 岁及以上人口数、城镇单位就业人员数、城镇居民消费水平、城镇人口数、基本养老保险基金支出、老年人口抚养比这6 个指标,考虑到养老床位需求受到历史数据的影响,故收集历年中国31 个省份的指标数据,运用K 均值聚类的方法将历年省份分为3 类,分别为养老床位需求高、中、低的地区,并将分类结果用于BP 神经网络的训练。再采用灰色预测模型和差分整合移动平均自回归模型来预测2022 年各指标值,对2022 年中国各省养老床位的需求进行分类。最后,基于2022 年的分类结果,通过熵权法对各类中各省的养老床位需求程度打分,根据分数的高低提出一种地区化分配养老床位的方案,为养老床位供需失衡问题提供解决方案支持。同时,用判别分析对2022 年31 个省份进行分类,将判别分析的结果与BP 神经网络的结果进行对比,实现误判最小化。
1 预备知识
1.1 BP 神经网络
BP 神经网络(Back Propagation Neural Network)采用误差的反向传播和信号的正向传播来确定权值,误差按照负梯度的方向不断传播,直至误差达到一个极小值时停止,或者在模型的学习次数达到初始设定的最大学习次数时停止,得到最终的完整网络。在BP 神经网络中,最常见的是3 层反馈网络,分别为输入层、隐含层、输出层。在BP 神经网络中,隐含层神经细胞的数量由式(1)来求得:
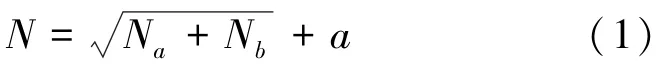
其中,N是输入层中神经元的数量;N是输出层神经元的数量;是调节常数,其范围在[1,10] 之间。
隐含层神经元的数量需要根据过去的数据逐步训练BP 神经网络,直至得到预测误差最小的网络,从而确定隐含层神经元数量。
在计算过程中,本文拟采用函数作为隐含层的激活函数,线性传递函数作为输出层的激活函数。设输入层的输入为分类后的2008~2017 年各省的65 岁及以上人口数、城镇单位就业人员数、城镇居民消费水平、城镇人口数、基本养老保险基金支出、老年人口抚养比,该层使用函数,对此可表示为:
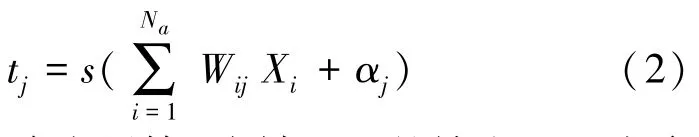
其中,t为隐含层第个神经元的输出;W为隐含层神经元与输入层神经元i 的权值; α为隐含层神经元的阈值;()为隐含层神经元的激活函数。
将高、中、低三个需求类别作为输出层神经元的3 个输出值,神经元运用激活函数将激活后的输入值输出,函数的数学形式可表示为:

其中,W为隐含层神经元到输出层神经元的权值;α为输出层神经元的阈值;()为输出层神经元的激活函数。
1.2 判别分析
判别分析要求每类中至少有一个样本,且解释变量必须是可测量的,才能计算每类的均值和方差,用于判别函数的具体表达式与计算。判别分析的计算步骤如下:
(1)计算各组类别中各判别变量的均值和协方差阵。
(2)计算协方差阵的估计值的逆矩阵。
(3)运用逆矩阵和均值确定判别函数的具体表达式。
(4)运用判别函数对已有样本进行回判,计算精确度。
(5)运用判别函数对待判别样本进行分类。
2 数据预处理
本文从国家统计局中收集2008~2017 年中国31 个省份的6 个指标值作为样本数据。首先,运用数据分析软件SPSS(Statistical Product and Service Solutions)对数据进行归一化处理,去除量纲对于聚类结果的影响;其次,采用K 均值聚类的方法将样本分为3 类,分别为:床位需求最多、床位需求适中和床位需求最少,最终的聚类结果见表1 和表2,最终聚类中心表示各类别中各指标数据的均值。
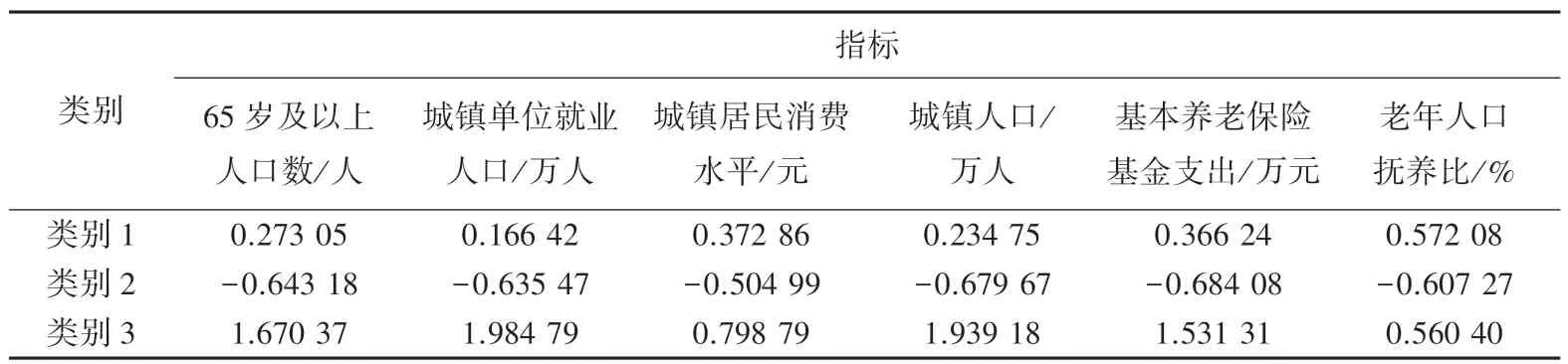
表1 最终聚类中心Tab.1 Final clustering center

表2 各类中的样本数Tab.2 Number of samples in each category
由表1 的数值可知,第一类对应的是床位需求适中的地区,第二类对应的是床位需求最少的地区,第三类对应的是床位需求最多的地区。因每年养老床位的需求都受到过去情况的影响,具有连续性,不是独立于历史存在的离散值,故本文以历史样本数据的分类结果为后续模型预测的基础样本,结果见表2,所有收集的样本均实现分类,并不存在一个样本属于多个类别的情况。
3 模型应用
3.1 最佳BP 神经网络训练
依据K 均值聚类方法的分类结果,将每个类别的70%样本作为训练集,30%样本作为测试集。由于输入变量为6 个,输出变量为3 个,根据公式(1),隐含层个数确定在[4,13]内。在该区间内选取不同的隐含层个数,训练BP 神经网络,对比各个隐含层个数下BP 神经网络的预测精度,选择精度最高的网络对应的隐含层个数,最终确定为10。养老床位需求BP 神经网络结构如图1 所示,分类误差直方图如图2 所示。
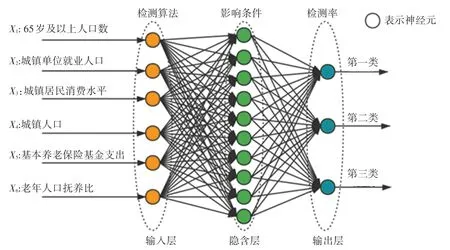
图1 养老床位需求BP 神经网络结构Fig.1 The BP neural network structure of pension service beds demand
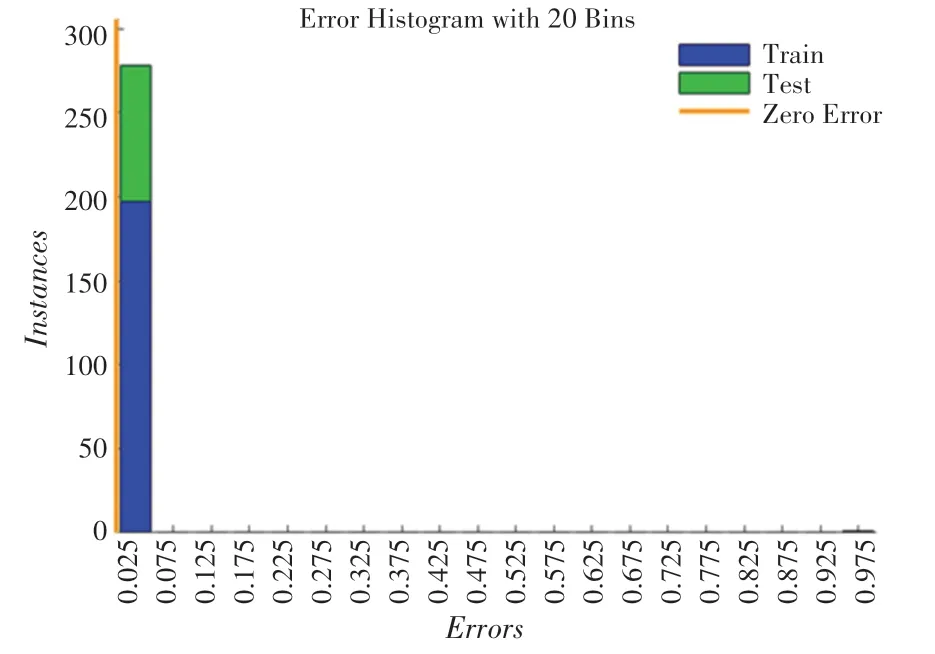
图2 分类误差直方图Fig.2 Histogram of classification error
在神经网络训练的过程中,需要重视过拟合问题。当训练集的精确度极高,而测试集的精确度低时,就会产生过拟合现象。由图2 可以看出,训练集和测试集的误差均在0.025 附近,即训练集和测试集的预测精确度基本均接近于100%,本文的养老床位需求BP 神经网络并不存在过拟合现象。
3.2 BP 神经网络与判别分析精确度的对比
判别分析是对已知样本数据进行计算得到判别函数,选择不同方法得到的判别函数也不相同,常用的判别方法有最大似然法、距离判别法、Fisher 判别法、Bayes 判别法。本文将K 均值聚类方法的分类结果作为基础样本,以Fisher 判别法为例,通过判别函数对基础样本进行回判,从而求得判别分析的精确度。与养老床位需求BP 神经网络的精确度相比,判别分析的精确度较低,故本文选用BP 神经网络的方法来实现养老床位需求的分类。
3.3 各个指标值预测
本文采用灰色预测模型和差分整合移动平均自回归模型,根据2008~2017 年31 个省份的6 个指标值,预测2022 年的指标值。灰色预测模型是运用少量数据进行短期预测,在计算残差的方差和指标数据的方差后,将两者的比值称为后验差比值,进行后验差比检验。当后验差比值大于0.65 时,则表明灰色预测模型的预测结果对于该指标数据而言不合格,需要选用其他方法进行预测。差分整合移动平均自回归模型是对平稳的时间序列数据进行中短期预测,当数据不平稳时,需要对数据进行差分,使其变成平稳序列。在本文的指标预测的过程中,对每个指标都先运用灰色预测模型进行预测和检验,当检验结果显示不合格、即精确度过低时,将采用差分整合移动平均自回归模型进行预测,最终的预测结果见表3。

表3 2022 年6 个指标31 个省份的预测值Tab.3 Predicted values of six indicators in 31 provinces of China in 2022
3.4 中国31 个省份的分类结果预测
根据差分整合移动平均自回归模型和灰色预测模型预测得到的2022 年各个省份的指标值,运用训练好的养老床位需求BP 神经网络,得到最终2022年31 个省份的类别情况,见表4。
由表4 可知,在面对中国整体的机构养老床位需求量增加的情况下,关于床位的增加量应按照第三类、第一类、第二类的先后顺序进行分配。优先增加第三类地区的养老床位,其次增加第一类地区的养老床位,最后增加第二类地区的养老床位。

表4 2022 年31 个省份预测类别Tab.4 China′s 31 provinces forecast categories in 2022
3.5 最终31 个省份得分结果
本文根据2022 年中国31 个省份对应的6 个指标预测值,采用熵权法计算各个指标的权重,最终得出各类中每个地区的评分,评分越高则相应地区对于床位的需求越急切。
由于运用SPSS 软件对该组数据进行标准化时发现有负值,故重新采用另一种标准化方法,保证标准化结果在[0,1]之间,列出公式见如下:
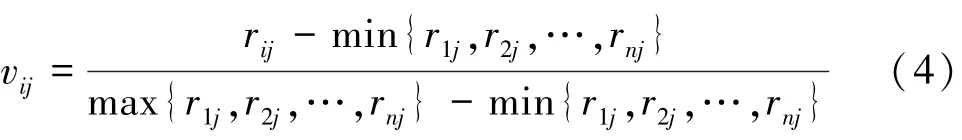
其中,r表示2022 年31 个省份对应的各指标预测值。
熵权法是根据指标的离散程度来分配权重,具有较强的客观性。熵权法需先对标准化矩阵v计算其对应的概率矩阵;其次,根据概率矩阵求各指标的信息熵和信息效用值;最后,将信息效用值归一化,得到各个指标的熵权。熵权与标准化矩阵的元素进行加权求和,即为各个样本的评分结果。评分结果是各个地区养老床位需求程度的评分,评分越高表示该地区对养老床位的需求程度越高,见表5。
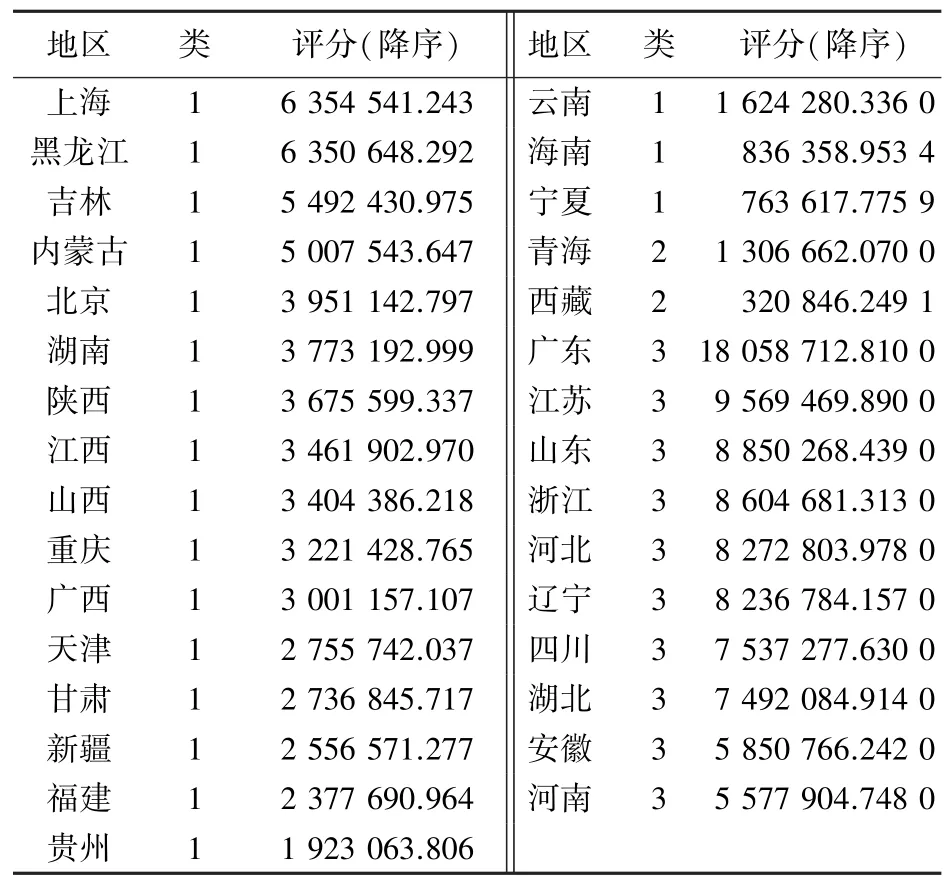
表5 2022 年31 个省份每类的评分(每类中评分按降序)Tab.5 The score of each category of China′s 31 provinces in 2022(descending order)
4 运算结果分析
本文主要采用BP 神经网络和灰色预测模型来预测分析2022 年31 个省份的养老床位需求增加量的情况,并且针对床位供需失衡的问题提出相应的解决方法:
(1)对2022 年的养老床位需求增加量,应按照第三类(需求最多)、第一类(需求适中)、第二类(需求最少)地区的顺序来增加养老床位的供给,先在整体上解决养老床位供需失衡的问题。
(2)在各组类别中,各地区按照熵权法的评分结果,先分配评分高的地区,再分配评分低的地区,即各类中按照各个地区对于养老床位需求程度的高低进行分配。
(3)在2022 年,在第三类地区中,按照广东、江苏、山东、浙江、河北、辽宁、四川、湖北、安徽、河南的顺序依次增加养老床位供给量;对于第一类地区,按照上海、黑龙江、吉林、内蒙古、北京、湖南、陕西、江西、山西、重庆、广西、天津、甘肃、新疆、福建、贵州、云南、海南、宁夏的顺序依次增加床位供给量;针对第二类地区,则是按照青海、西藏的顺序增加床位供给量。
5 结束语
本文针对中国养老床位供需失衡的问题,通过分类、预测、评分这3 个步骤提出一种地区化分配养老床位的方案。首先,运用K 均值聚类方法将2008~2017 年31 个省份分为3 类作为样本数据,分别为养老床位需求最少、适中、最多。运用BP 神经网络对样本数据进行训练,同时运用判别分析对样本数据进行回判,比较2 个方法的精确度,确定BP神经网络更适用于养老床位需求的分类预测。通过灰色预测模型和差分整合移动平均自回归模型求出2022 年各个指标的预测值,输入BP 神经网络进行分类预测。运用熵权法对各类地区按养老床位的需求程度进行评分,提出具体的养老床位地区化分配方案。政府在分配养老床位时,需要先对养老床位需求最多的类别进行分配,在每组类别中,需要对养老床位需求最紧迫的地区进行分类;在养老床位供给量有限的情况下,优先解决养老床位需求最多的地区,力图实现养老床位在各省间的合理分配。
