三种机器学习算法在回归应用中的对比分析
2022-07-29李培德
蔡 明,孙 杰,李培德,鲍 清
(1 湖北省气象信息与技术保障中心,武汉 430074;2 暴雨监测预警湖北重点实验室,武汉 430074)
0 引言
目前,对于中等数据集来说,与人工神经网络(Artificial Neural Network,ANN)相比,boosting 方法则有着较为明显优势。相对来说,boosting 的训练时间会更短,参数调整时也不会耗费太多时间。
Boosting 是一种集成学习策略,致力于从各种弱分类器中生成准确的分类器。通过划分训练数据,并使用每个部分来训练不同的模型或用一个具有不同设置的模型来实现,最后再用多数票将结果组合在一起。AdaBoost 是Freund 等人提出的第一个用于二元分类的有效boosting 方法。当AdaBoost 进行第一次迭代时,所有记录的权重相同,但在下一次迭代中,却会为错误分类的记录赋予更高的权重,模型迭代将继续、直到构造出有效的分类器。AdaBoost 发布后不久,就有研究发现,即使迭代次数增加,模型误差也不会变大。因此,AdaBoost模型十分适用于解决过拟合问题。近些年来,学者们基于梯度提升决策树(Gradient Boosting Decision Tree,GBDT)提出了3 种基于决策树的有效梯度方法,分别是:XGBoost、CatBoost 和LightGBM。这些方法均已成功应用于工业界、学术界和竞争性机器学习的研究中。
1 相关算法介绍
1.1 GBDT
梯度提升树是一种利用加法模型与前向分歩算法实现学习的优化过程。当损失函数为平方误差损失函数和指数损失函数时,每一步的优化较为简单。但对一般损失函数而言,往往每一步优化并不容易。针对这一问题,Freidman 提出了梯度提升(Gradient Boosting)算法。Gradient Boosting 是Boosting 中的一类算法,设计思想参考自梯度下降法,基本原理是根据当前模型损失函数的负梯度信息,来训练新加入的弱分类器,并将训练好的弱分类器以累加的形式结合到现有模型中。采用决策树作为弱分类器的Gradient Boosting 算法被称为GBDT,有时也称为MART(Multiple Additive Regression Tree)。
梯度提升方法以分段方式构造解,并通过优化损失函数来解决过拟合问题。例如:假设有一个定制的基学习器(,)(如决策树)和一个损失函数(,())。若直接估计参数会十分困难,因此在每次迭代时使用迭代模型。每次迭代模型都将被更新、并重选一个新的基学习器(,θ),其中增量可表示为:
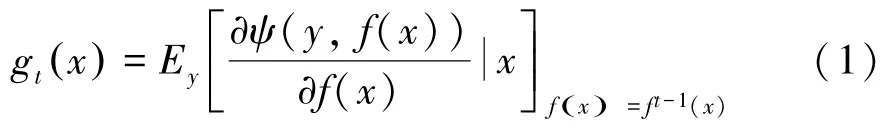
这样就可以将难解的优化问题转化为常用的最小二乘优化问题,即:
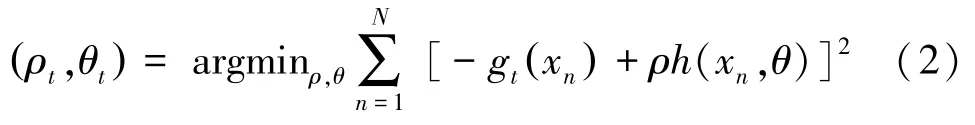
这里,对梯度提升算法的实现步骤可做阐释表述如下。
令为常数;
对于1 到有:
1:利用式(1)计算g();
2:训练函数(,θ) ;
3:利用式(2)寻找最优ρ;
结束。
该算法从一片叶子开始,接着将针对每个节点和每个样本优化学习速率。
1.2 XGBoost
XGBoost(eXtreme Gradient Boosting)是一种高度可扩展、灵活且通用的梯度提升工具,其设计目的在于正确使用资源,并克服以往梯度提升算法的局限性。XGBoost 和其它梯度提升算法的主要区别是,XGBoost 使用了一种新的正则化技术,控制过拟合现象的产生。因此,在模型调整期间,XGBoost会更快、更健壮。正则化技术是通过在损失函数中添加一个新项来实现的,此处的数学公式可写为:
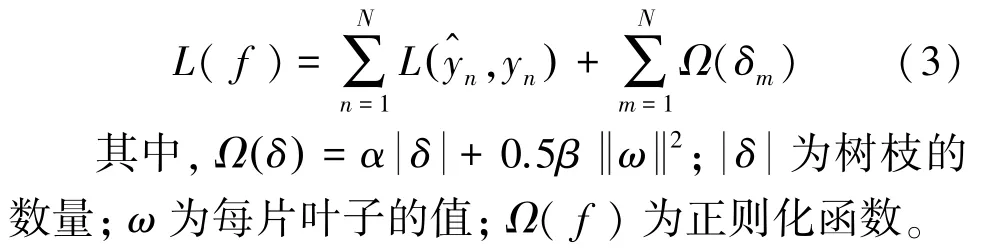
XGBoost 使用了新的增益函数,相应的函数形式具体如下:

文中,对XGBoost 基本核心算法流程拟做阐释如下。
(1)不断地添加树,并不断地进行特征分裂来生长一棵树。每次添加一个树,其实是学习一个新函数(),去拟合上次预测的残差。
(2)当训练完成得到棵树,需要预测一个样本的分数,即根据这个样本特征,在每棵树中会求得对应的一个叶子节点,每个叶子节点就对应一个分数。
(3)基于此,只需将每棵树对应的分数加起来,就得到了该样本的预测值。
1.3 LightGBM
为了提高GBDT 算法效率、避免XGBoost 的缺陷、并且能够在不损害准确率的条件下加快GBDT模型的训练速度,微软研究团队于2017 年4 月开发了LightGBM。LightGBM 在传统GBDT 算法上进行了如下优化:
(1)基于Histogram 的决策树算法。一个叶子的直方图可以由其父亲节点直方图与其兄弟直方图做差得到,在速度上可以提升一倍。
(2)单边梯度采样(Gradient-based One-Side Sampling,GOSS)。使用GOSS 可以减少大量只具有小梯度的数据实例,使其在计算信息增益时只利用余下的具有高梯度的数据即可。相比XGBoost 而言,既遍历所有特征值,也节省了不少时间和空间上的开销。GOSS 算法从减少样本的角度出发,排除大部分小梯度的样本,仅用剩下的样本计算信息增益,这样做的好处是在减少数据量和保证精度上取得平衡。
(3)互斥特征捆绑(Exclusive Feature Bundling EFB)。使用EFB 可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的。
(4)带深度限制的Leaf-wise 叶子生长策略。大多数GBDT 工具使用低效的按层生长(levelwise)的决策树生长策略,且由于不加区分地对待同一层的叶子,带来了很多额外开销。实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。LightGBM 使用了带有深度限制的按叶子生长(leaf-wise)算法,在分裂次数相同的情况下,Leaf-wise可以降低误差,得到更好的精度。并且,还能做到:
①直接支持类别特征(Categorical Feature);
②支持高效并行;
③Cache 命中率优化。
上述优化使得LightGBM 具有更好的准确性、更快的训练速度、以及大规模处理数据能力,同时还能支持GPU 学习的优点。按层生长与按叶子生长的设计示意如图1 所示。
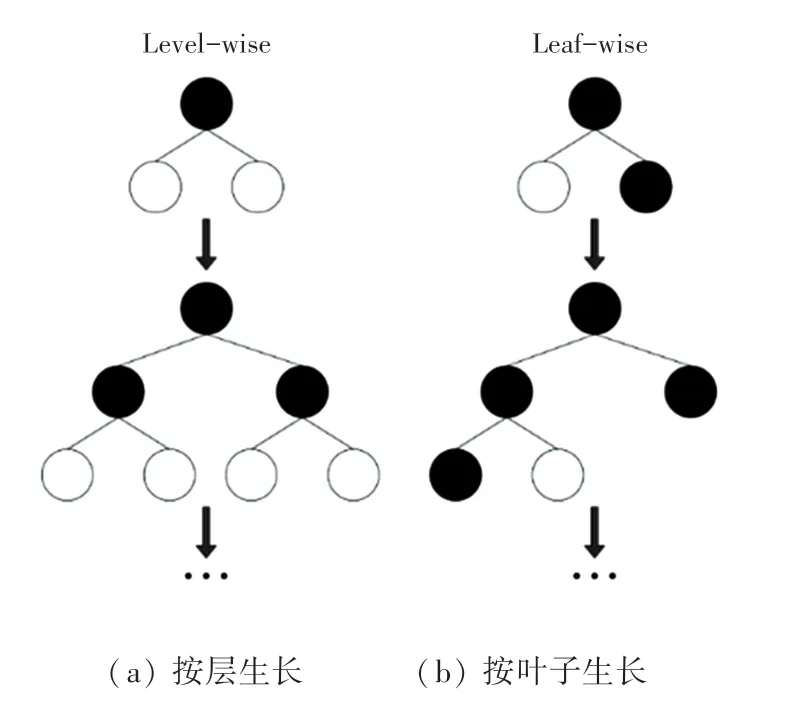
图1 按层生长与按叶子生长示意图Fig.1 Schematic diagram of level-wise growth and leaf-wise growth
1.4 CatBoost
CatBoost 是Yandex 在2017 年提出的开源的机器学习库,同前面介绍的XGBoost 和LightGBM类似,依然是在GBDT 算法框架下的一种改进算法,是一种基于对称决策树(oblivious trees)算法的GBDT 框架,不仅参数少、准确性高,还能支持类别型变量,高效合理地处理类别型特征(Categorical features)也是其主要亮点及优势。由其名称就可以看出,CatBoost 是由categorical 和boost 组成,并改善了梯度偏差(Gradient bias)及预测偏移(Predictionshift)问题,提高了算法准确性和泛化能力。
CatBoost 可以利用各种统计上的分类特征和数值特征的组合,将分类值编码成数字,并通过在当前树的新拆分处,使用贪婪方法解决特征组合的指数增长问题。同均值编码类似,重点是通过以下步骤防止过拟合:
(1)将记录随机划分为子集。
(2)将标签转换为整数的同时,将分类特征转化为数字特征,研究求得的数学公式为:
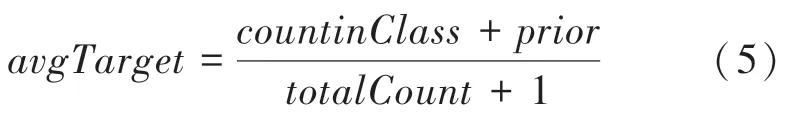
其中,是给定分类特征在目标中的个数;是之前对象的个数;由初始参数指定。
与XGBoost、LightGBM 相比,CatBoost 的创新点体现在如下方面:
(1)嵌入了将类别型特征自动处理为数值型特征的创新算法。先对categorical features 做一些统计,计算某个类别特征(category)出现的频率,此后加上超参数,生成新的数值型特征(numerical features)。
(2)Catboost 使用了组合类别特征,可以用到特征之间的联系,极大地丰富了特征维度。
(3)采用排序提升的方法对抗训练集中的噪声点,这就避免了梯度估计的偏差,进而解决预测偏移的问题。
(4)采用完全对称树作为基模型。
2 前期准备
2.1 数据集
选择Kaggle 比赛中的NYC Taxi fares 数据集作为3 种模型对比实验的数据集,以此来对比3 种算法的性能。数据集共有1 108 477条数据,数据集的前5 行数据样本见表1。特征变量数目为8,目标特征为fare_amount。

表1 初始数据集快照Tab.1 Snapshot of initial dataset
在对特征变量进行处理时,将拆分生成新特征变量年、月、星期、年积日、时;通过、、、和NYC 内机场经纬度坐标,计算乘车距离Distance 和到各个机场的距离作为新的特征变量。同时对数据集进行处理,去除≥5 或记录为空的数据。
最终,将经过预处理和特征工程加工的数据集按照7 ∶3 的比例划分为训练集和测试集。
2.2 实验设计
为了从性能表现、效率等方面对比最具代表性的3 种基于GBDT 的研发算法在回归应用中的情况,文中将按照以下步骤进行实验:
(1)使用相同的初始参数训练 XGBoost、CatBoost、LightGBM 算法的基准模型。
(2)使用超参数自动搜索模块GridSearch CV训练XGBoost、CatBoost 和LightGBM 算法的调整模型。
(3)从训练和预测时间、预测得分两方面比较算法性能的表现情况。
3 实验结果对比分析
3.1 预测精度对比
为了研究不同数据样本量对模型性能的影响,分别按照全部、1/2、1/5 和1/10 的比例,从样本数据集中随机抽取样本形成新的样本集。对新的样本集,按照7 ∶3 的比例划分训练集和测试集,从模型预测精度和训练、预测用时等方面,对比3 种算法的回归预测性能。
本文使用均方根误差对模型的预测精度进行评价。均方根误差的数学定义的公式表述可写为:
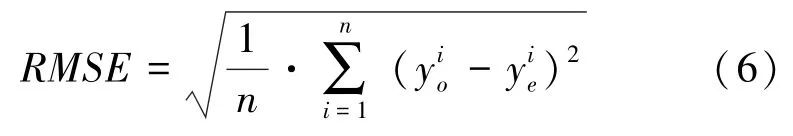
3 种模型回归预测的见表2。表2 中,XGBoost、LightGBM、CatBoost 代表建立的基准模型,XGBoost_CV、LightGBM_CV、CatBoost_CV 代表在基准模型基础上,经过网格搜索和交叉验证后的优化模型。观察表2 可以看出,3 种算法经过参数调优后的,相比各自基准模型的都有所降低,说明参数优化提高了模型的预测精度。随着样本规模的降低,3 种算法的皆有不同程度的增长,说明样本规模的减小,降低了模型的预测精度。但是,CatBoost 算法在样本规模由总样本数目的1/5 降至1/10 时,模型预测结果的并没有出现增长。说明样本规模降低至总样本数目的1/5后,CatBoost 对样本规模的降低已不再敏感,样本规模与模型预测精度的具体联系有待进一步研究。
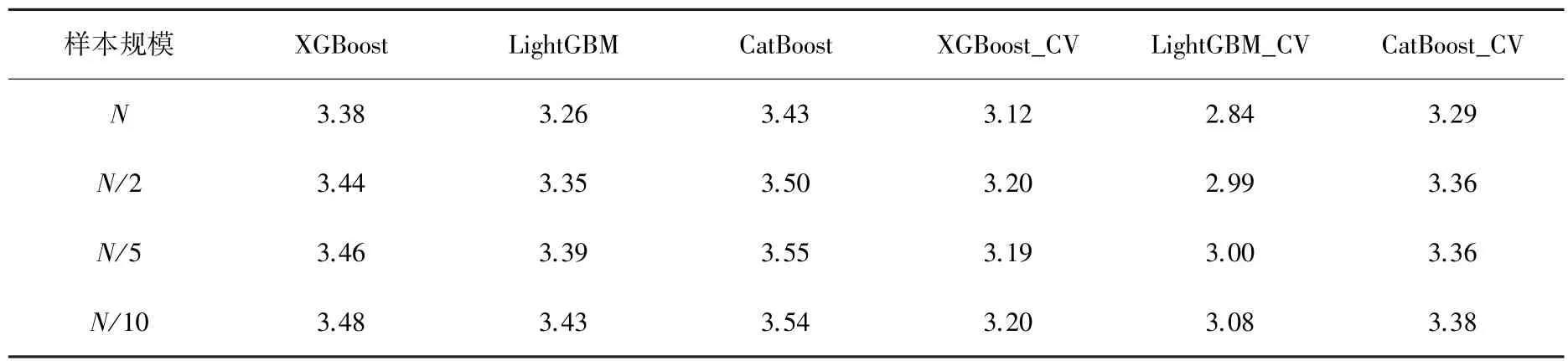
表2 模型预测精度RMSETab.2 Prediction accuracy of the models RMSE
由此可见,LightGBM 在基准模型和优化模型上都比其它2 种算法的要小,说明LightGBM 算法在实验数据集上的预测效果优于其它2 种算法。
3.2 运行时间对比
通过记录3 种模型训练和预测用时,进行3 种模型的运行用时对比,对比结果见表3。从表3 中也可以看出,对于同一模型,使用网格搜索交叉检验模型的运行用时远高于其基准模型,这是由于网格搜索和交叉检验操作用时较多。同时,从表3 中也可以看出,样本规模和模型运行时间成正比,模型样本规模越大,训练和预测用时越多。不同模型间进行对比时,LightGBM 无论是基准模型、还是经过网格搜索交叉检验后的优化模型,在运行用时上都是最少,CatBoost 模型的运行时间次之,XGBoost 模型运行耗时最多,这与前文论述中对3 种模型的特性介绍相符。
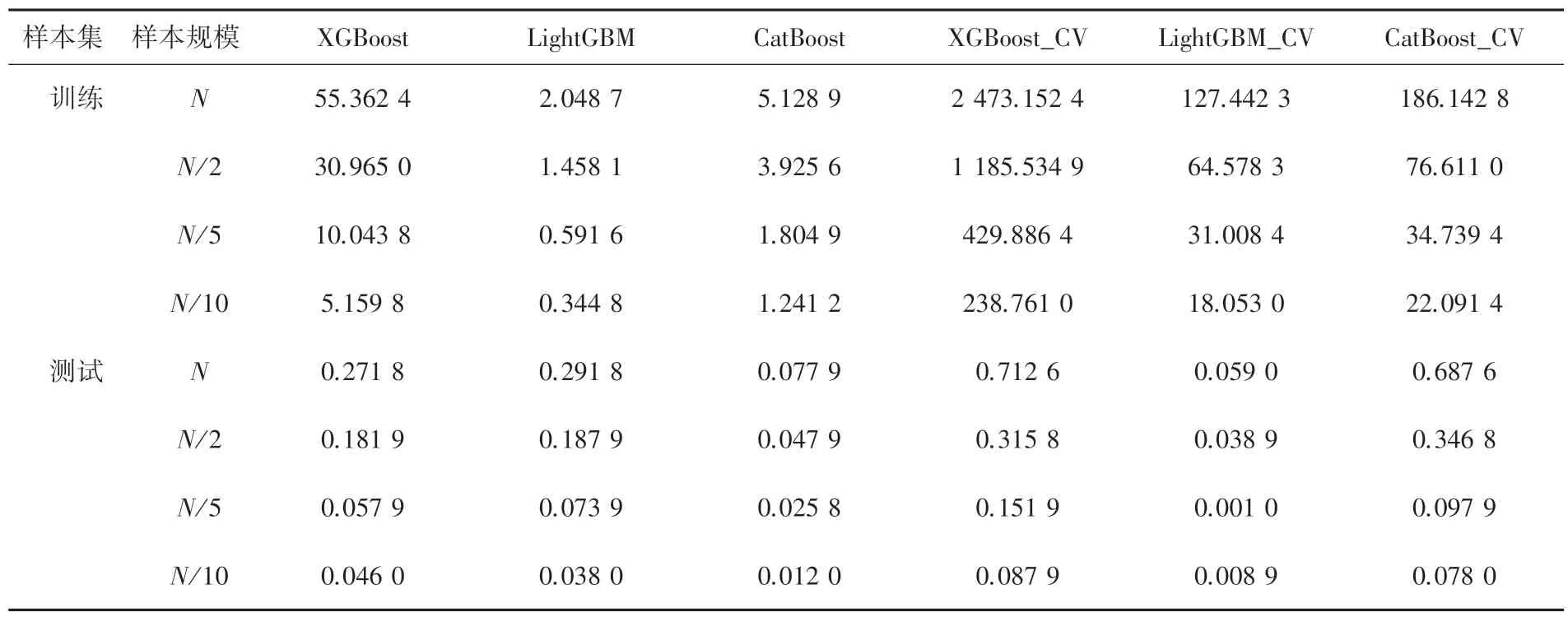
表3 模型运行时间Tab.3 Running time of the models s
3.3 参数重要性评价
通过比较3 种模型的feature_importances_属性,研究这些属性中哪些对模型的预测影响最大,对比结果如图2~图4 所示。由图2~图4 分析可知,虽然3 种模型中的各个变量重要性排序不尽相同,但订单距离、机场订单距离_、订单年份和乘客下车时的经度_的变量重要性均排名前4,说明无论是采用哪种模型,这4 个变量均是决定模型预测效果的关键变量。4 个变量中,订单距离、机场订单距离_和订单年份均是通过特征工程从原始数据集中生成的变量,这也说明对原始数据集进行特征工程加工是提升模型训练效果的一种有效手段。
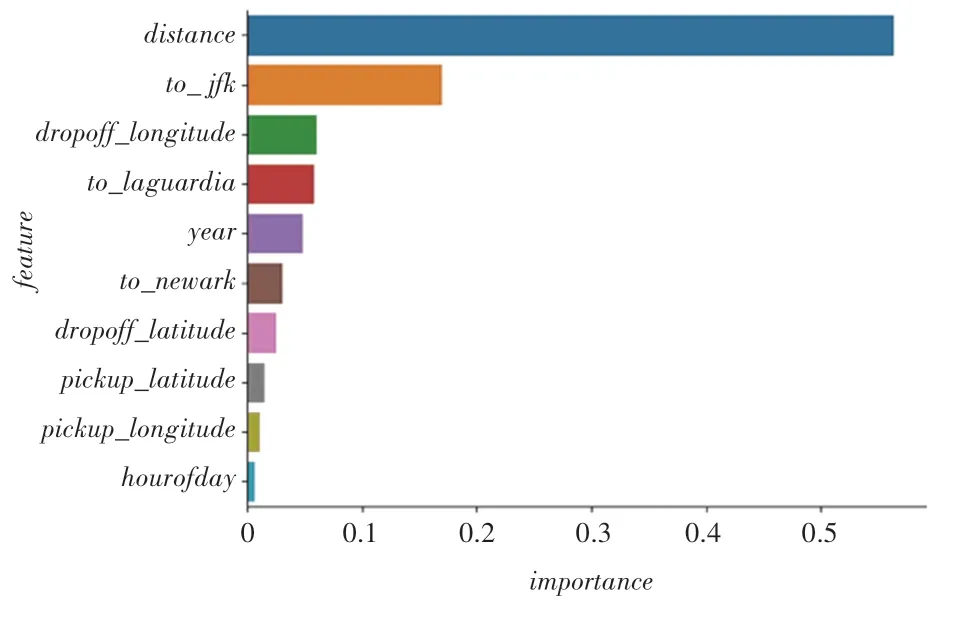
图2 使用XGBoost 模型的特征重要性排序图Fig.2 Ranking diagram of feature importance using XGBoost model
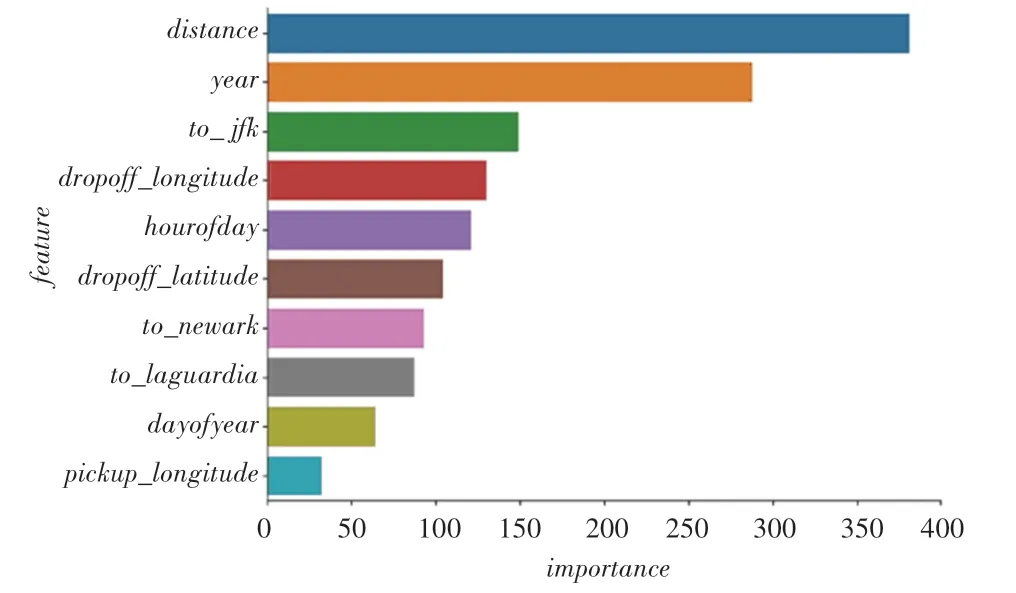
图3 使用LightGBM 模型的特征重要性排序图Fig.3 Ranking diagram of feature importance using LightGBM model
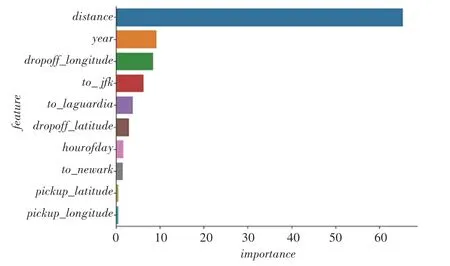
图4 使用CatBoost 模型的特征重要性排序图Fig.4 Ranking diagram of feature importance using CatBoost model
4 结束语
本文比较了3 种最先进的梯度增强方法(XGBoost、LightGBM 和CatBoost)的回归预测精度和运行时间。LightGBM 在实验数据集上的表现较其他梯度增强方法要快得多,而且在同样经过超参数优化后,可以取得更好的回归预测结果;可以通过对原始数据集进行新特征生成和最佳特征选择等特征工程操作,提升模型预测性能。综合前文论述可知,由于LightGBM 模型在预测精度和运行速度上的优势,可以作为回归应用的首选模型。
