基于U-net 变体和分类器的动漫线稿风格迁移
2022-07-29冯煜颋李志伟
冯煜颋,李志伟
(上海工程技术大学 电子电气工程学院,上海 201620)
0 引言
素描或线稿艺术上色是一个有着巨大市场需求的研究领域。与强烈依赖纹理信息的普通照片上色不同,草图上色更具挑战性,因为草图可能没有纹理。在动漫、游戏这些产业中,大部分的作品都是通过素描或线稿来进行创作的,这就会耗费大量的时间和精力,因为需要人工去给这些线稿上色来达到人们想要的状态。如果尝试将某种绘画风格应用到半成品的动漫线稿上,那么就可以省去不少多余的工作,比如用一个动漫的特定人物的某张图片作为风格参考图像,并将这种颜色风格应用到人物的素描上。而图像上色一般分为2 种:有引导上色和无引导上色。其中,无引导指的是全交由算法进行自动化上色,而有引导是在上色过程中有人为(其它参照)干预,比如给出一幅风格参考图像或指定某一区域为特定颜色。本文提出的上色方法属于一种有引导上色。
神经风格算法可以结合线稿图和风格图生成优秀的图像,但是却缺乏处理素描线稿的能力,生成的图像远未达到人工上色的预期效果。事实上,U-net和生成对抗网络已获证明在图像上色方面有着很好的效果。Zhang 等人提出了一种二阶段的线稿上色方法:第一阶段是草稿阶段,根据人工输入颜色提示或是提供参考图生成模拟合成草图;第二阶段是精修阶段,通过Inception V1 网络提取草图的颜色特征和预先提示的颜色特征,来控制最终生成图像的颜色风格。Zhang 等人开发了线稿风格迁移工具Style2paints,实现了线稿到彩色图像的风格迁移上色,根据自带一些颜色风格特征或是参考图像可以进行快速的线稿上色。于是改进了一种残差增强的U-net 来增加生成网络学习特征图的能力,结合辅助分类器对抗生成网络(ACGAN)作为解决方案。这种前馈网络能够快速地合成绘画,节省时间。另外,U-net 和条件GAN(CGAN)在没有成对输入和输出信息的均衡量时性能会相对下降。因此,本文在原有的生成网络基础上附加了2 个指引解码器来实现额外的损失。网络的整体结构如图1所示。
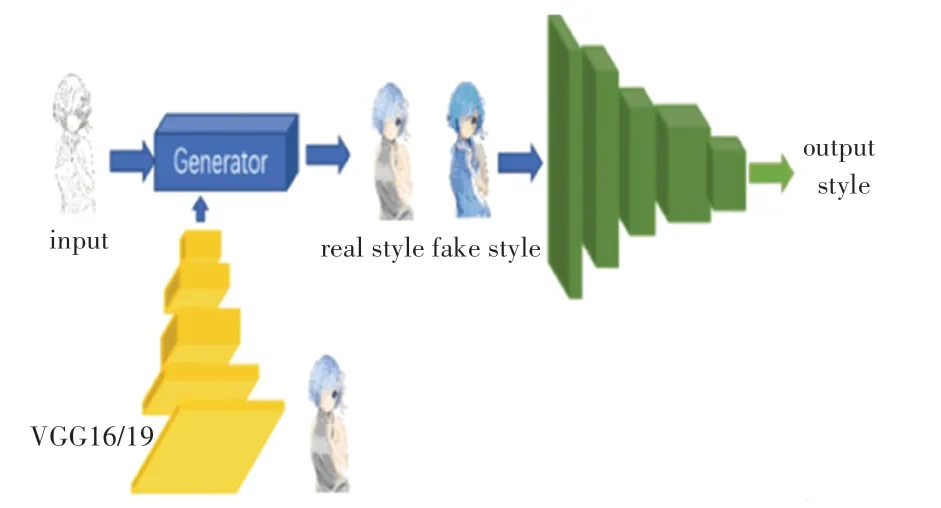
图1 生成对抗网络的整体结构Fig.1 The overall structure of the generative adversarial network
生成网络由残差增强的U-net、分类器和指引解码器组成;判别网络由AC-GAN 进行改进,经判别器处理后会输出一个2 048 或4 096 维的特征向量对应VGG 的特征向量(颜色风格),而不再是原始GAN 的二分类值。全局的颜色风格提示可以被看作是一个具有2 048 或4 096 个类的低级分类结果。
1 相关工作
生成对抗网络(GANS)的出现,在深度学习领域中日益受到广大学者的关注。生成对抗模型通常是由一个生成器和一个判别器组成,其中生成器捕捉真实样本的潜在分布,并且生成新的数据样本;判别器往往是一个二值分类器,通过训练可以尽可能正确地从生成样本中区分出真实样本。利用判别器来引导生成器的训练,通过2 个模型之间的交替训练不断进行对抗,最终使得生成模型能够更好地完成生成任务。而随着越来越多GANS 变体的出现,GANS 在图像的各个领域都取得了不错的成果。在图像上色领域中,GANS 同样在主流算法中占据着至关重要的地位。目前,基于深度学习的自动着色模型大多采用GANS 体系结构。
Lee 等人提出的动漫线稿自动上色算法是基于二次规划图匹配,但是这种基于参考图的自动上色方法难度较大,原因在于线稿中人物姿态的变化,使得参考图和线稿的一些区域无法对应起来,给图匹配算法带来了极大挑战。这种上色方法生成的彩色图像因参考图和线稿有些区域并不匹配,一些区域只能随机上色,导致图像的质量很差。GAN 的出现使线稿基于参考图上色逐渐变得可靠,在生成器和判别器的对抗式训练中,模型不断学习并将线稿到对应彩色图像间的映射关系做了进一步优化。
神经风格迁移,是通过基于最小化深度卷积层的格拉姆矩阵的差异的算法,可以将一张普通的照片赋予另外一种艺术作品风格。然而,本文的目标是将风格图像和草图相结合。事实上,从风格图像到草图的神经风格迁移得到的最终图像远不是一幅正常的图像,往往和风格图像有很大差异。
Pix2pix 是基于条件生成对抗网络CGAN 的风格迁移模型之一,在成对数据集的情况下,可以完成很多任务。如:将素描画轮廓转换成图片,将黑夜场景转换成白天场景,自动上色等等。但在实验中发现,网络的输出的质量最终取决于输入信息和输出信息的差距程度。实际上,条件判别器很容易导致生成器过于关注草图和绘画之间的关系,因此,在某种程度上,忽略了绘画的组成,导致不可避免的过拟合。
2 本文方法
2.1 增强型的残差连接
本文提出的残差连接 Enhanced residual connection,是对ResNet 中残差模块的一种改进。这种连接方式是SwishMod 集成残差模块的连接方式,SwishMod 包含了卷积层和激活函数。其残差连接结构如图2 所示。
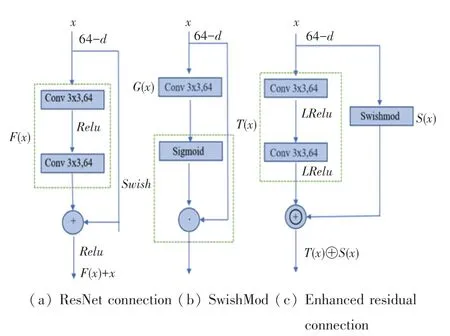
图2 增强残差连接方式Fig.2 Enhanced residual connection mode
本文图2 中,表示输入数据,()表示残差,()是残差连接后的输出,“”表示像素点对应相加;()表示SwishMod 中卷积层的输出,“·”表示像素点对应相乘;()表示卷积层经过非线性函数后的输出,()是SwishMod 的输出,“⊕”表示特征图之间进行拼接,“()⊕()”是的最终输出。
在残差连接中,输入数据没有经过处理就直接和残差相加;而在SwishMod 中,对进行了处理,使用了函数,该种设计优势就在于能够控制数值的幅度,在深层网络中可以保持数据幅度不会出现大的变化。此外,对Enhanced residual connection 中的卷积层使用了非线性,对于生成类的任务比有着更好的效果。
采用SwishMod 滤波输入数据,控制了输入数据从底层到高层之间通过一个捷径的特征图传输,得到更精细和准确的颜色特征。
SwishMod 定义为:
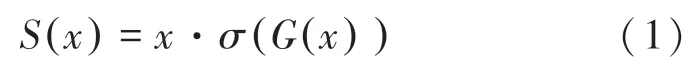
SwishGatedBlock 的输出为:
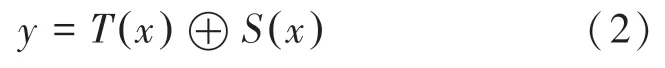
其中,()是模块中的残差部分,()是SwishMod 滤波后的信息,两者拼接在一起输出得到更精细的颜色特征。
2.2 生成网络结构和损失函数
U-net 虽然在图像合成领域有着出色的表现,能够提取每个层次的特征图像,一旦U-net 具备了能够在低级层中处理问题的能力后,那么高级层就不会再去学习任何东西。如果训练一个U-net 来做一项简单的工作、即复制图像(如图3 所示),当输入和输出相同时,损失值将立即降至0。因为第一层编码器发现,可以简单地经由跳过连接,将所有特征图直接传输到解码器的最后一层,来最小化损失。在这种情况下,无论训练多少次,中间层都不会得到任何梯度。对于U-net 的解码层来说,每一层的特征图都是由更高层或是跳接层中获得。在训练过程的每次迭代中,这些层选择了经过非线性激活其它层的输出来最小化损失。当U-net 用高斯随机数初始化网络时,编码器中第一层的输出具有足够的信息来表达完整的输入映射,而解码器中第二到最后一层的输出似乎存在噪声。因此,“懒惰的”U-net放弃了相对来说有噪声的特征图。
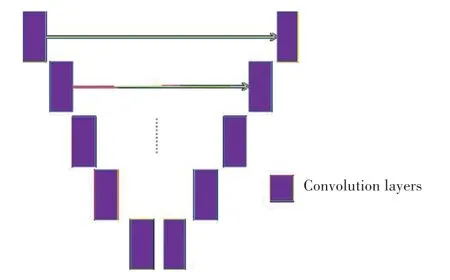
图3 U-net 的跳接方式Fig.3 Skipped connection between U-net layers
网络生成器网络整体结构是基于残差增强U-net的变体(如图4 所示),每个蓝色模块都是一个Enhanced residual connection,在下一个分辨率提取特征时,通过残差增强可以得到更精细的特征。随着等级的提高,分辨率也逐渐降低。该网络也可以看做是左、右两个分支,但是把同一个分辨率等级的左、右分支之间嵌入一个SwishMod,来滤波编码路径传递到解码路径的信息,而不再是原来的跳接。因此,SwishMod 在提高网络收敛速度的同时,还能提高网络的性能。在左侧分支中,每个Enhanced residual connection 的输出由残差部分输出的特征图和经过SwishMod 滤波的特征图组成;而在右侧分支中,每个Enhanced residual connection 的输出是由残差部分输出的特征图、经过SwishMod 滤波的特征图、以及对应左侧分支通过SwishMod 滤波的特征图三部分组成。由此可见,经过残差增强的U-net,完全解决了U-net 在训练时中间层不会得到任何梯度的问题。
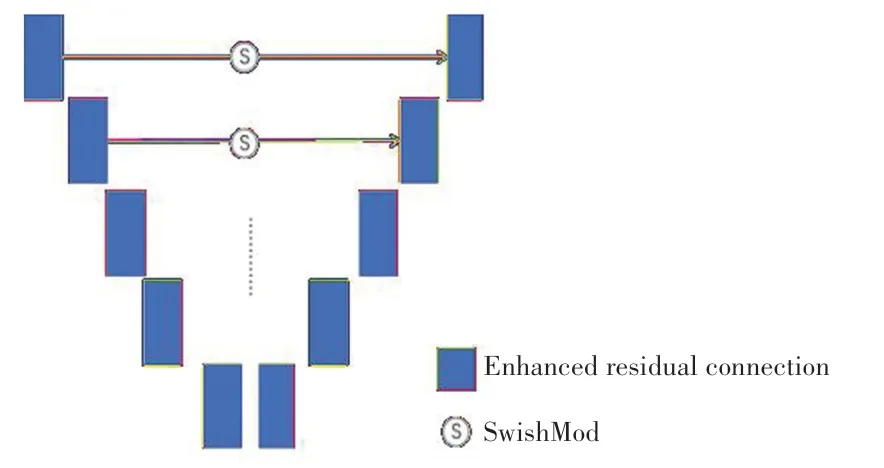
图4 残差增强U-net 层与层之间的连接Fig.4 The connections between residual enhanced U-net layers
此外,本文在生成器的结构中增加了一个分类器,如图5 所示。相对来说,1×1×256 的风格提示不能够满足动漫线稿的颜色风格,所以在VGG19 全连接层的输出中不再使用激活函数,则会得到更多的1×1×4 096 的颜色风格提示。然而,对于一个新初始化的U-net,如果将4 096 维的特征向量直接添加到该层中,中间层的输出噪声可能会非常大。由于有噪声的中间层会被U-net 放弃,因此这些层不能接收到任何梯度。
为了解决上述问题,本文在原有的生成网络中附加了2 个解码器(见图5)。如果给每一层附加额外的损失,无论中间一层的输出有多嘈杂,该层将永远不会被U-Net 放弃,不会出现梯度消失的情况,从而会得到稳定的梯度。通过向中间层添加一个有信息量和有具体内容的噪声提示,解决了原本网络传递特征信息跳过中间层而导致训练时中间层梯度消失的问题。通过在“指引解码器1”和“指引解码器2”中实现了2 个额外的损失,因此就避免了中间层的梯度消失。
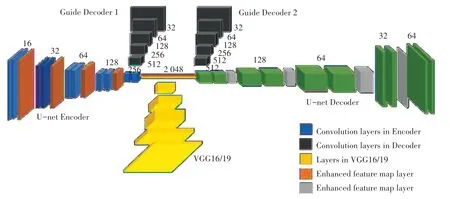
图5 生成器的网络结构Fig.5 The network structure of the generator
损失函数定义为:
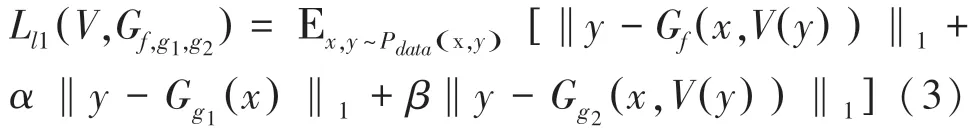
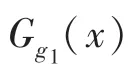
此外,通过用灰度图输入位于中间层入口的指引解码器,可以改善颜色的分布,让颜色分布不会特别单一,因此最终的损失如下:
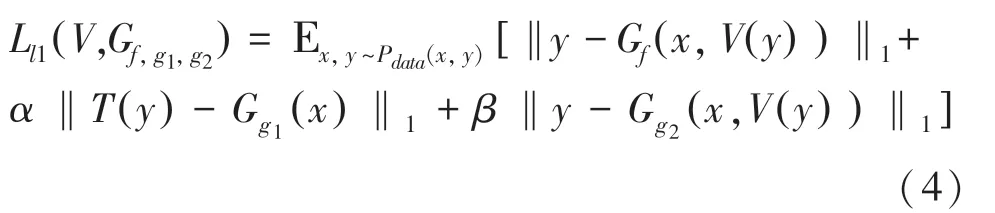
其中,()可以将转换为灰度图像。
2.3 判别网络结构和损失函数
绘画是一项复杂的过程,需要人类考虑到色彩的选择、构图和微调,所有这些都需要一个艺术家专注于绘画的整体方式。然而,条件鉴别器总是更倾向于关注素描线和颜色之间的关系,而不是全局信息。比如在Pixtopix 中使用的是条件鉴别器,生成器会产生强烈的抵抗,这就导致了最终的彩色图像会出现颜色溢出和颜色混淆的结果。
在进行风格迁移时,需要判别器具有判断图像的颜色风格、并在风格转移时相应地提供梯度的能力,因此选用了集成AC-GAN 的判别器。与ACGAN 判别器相比,本文判别器输出不含二分类,只包含生成图像的类标签。具体而言,判别器的输出为一个4 096 维的特征向量,与VGG 输出特征向量的意义基本相同,可视为色彩风格类别的分类结果。当判别器的输入图像为时,输出向量接近于全为0;当判别器的输入图像为时,输出向量接近于VGG19 的全连接层输出的特征向量。
最终的损失函数定义为:
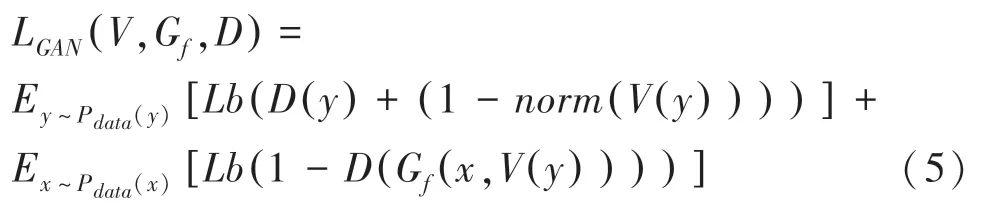
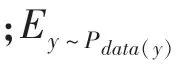
本文使用的归一化函数如下:
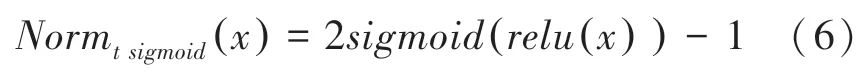
最终目标函数为:
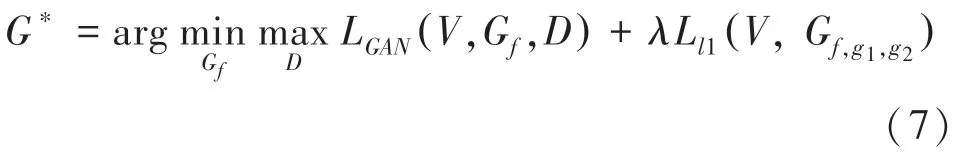
3 实验分析
3.1 数据集
研究指出,由于目前还没有一个动漫线稿和参考图配对的数据集,本文使用的是训练好的VGG 网络-ImageNet 图片分类数据集。由于本文的生成网络使用的是U-Net 网络,可以对任意形状大小的图片进行卷积操作,特别是任意大的图片。因此,在图像上色任务中,就可以对任意分辨率的灰度图像进行上色。实验数据随机截取了ImageNet 图片分类数据集中的5 000 幅匹配图像进行训练,并将所有图像分辨率都调整为256×256。
3.2 实验结果
为了证明本文采用的2 个指引解码器能够解决训练时中间层梯度消失的问题,实验对象分别采用2 个指引解码器和无指引解码器的上色模型;目标函数分别采用指引解码器的额外损失和原GAN 的生成对抗损失。Style2color-Guide 使用了2 个指引解码器的生成模型,生成模型的目标函数选择了2个指引解码器的额外损失作为目标函数;Style2color-GAN不使用指引解码器的生成模式,生成模型的目标函数采用原始GAN 的生成对抗损失。实验结果如图6 所示。由图6 可见,Style2color-Guide 上色模型生成的彩色图像有着更多的颜色层次,彩色图像质量优于Style2color-GAN。此外,Style2color-Guide 生成的彩色图像颜色风格在细节上更接近于风格图像,而Style2color-GAN 在细节上的表现依然欠佳(如图6 中眼睛的颜色部分)。

图6 2 种方法结果图对比Fig.6 Results of two coloring methods
为了验证本文方法中判别器和生成器都能学习到深层次的颜色特征、同时训练时不会有中间梯度消失,将本文方法与Style2paints 方法进行了对比,对比结果如图 7 所示。由图 7 可以看出,Style2paints 过于追求风格迁移,在很多区域的颜色都出现了溢出现象,而本文方法生成的图像在视觉上更符合审美观念,同时也能生成更精细的颜色特征,颜色分布不会混淆,算法生成的图像有着更高的视觉质量和更加自然的色彩梯度。

图7 本文方法和Style2paints 生成图像对比Fig.7 Results of the proposed method and Style2paints
3.3 定量分析
从上色结果可以直观地看出,Style2color-Guide的上色效果相比Style2color-GAN 的上色效果更加细腻连贯。因为2 个上色模型结构几乎一致,进一步采用(Frechet Inception Distance)指标来评价最终生成的彩色图像的质量。指标的实验结果见表1。由此可见,Style2color-Guide 生成的彩色图像质量略优于Style2color-GAN 生成的彩色图像。对于动漫线稿颜色迁移来说,2 种指引解码器额外实现的损失函数效果不仅比传统GAN 生成的对抗损失效果更好,还能避免网络训练时梯度消失的问题。
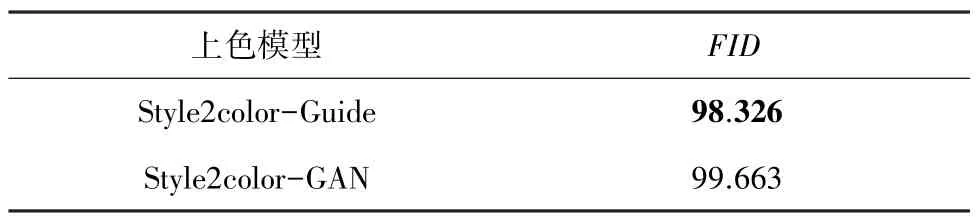
表1 Style2color-Guide 和Style2color-GAN 的实验结果Tab.1 Results of Style2color-Guide and Style2color-GAN
此外,为了进一步证明本文方法的优越性,采用峰值信噪比()、相似结构性()、特征相似度()三种常规评价图像质量的方法,评价本文算法和现在流行的Style2paints 算法生成的彩色图像质量(清晰度)和色彩多样性,结果见表2。由表2 可见,本文方法在所有指标上都获得了较好的表现,说明这种残差增强型的生成网络能够解决U-net训练时中间层梯度消失的问题。
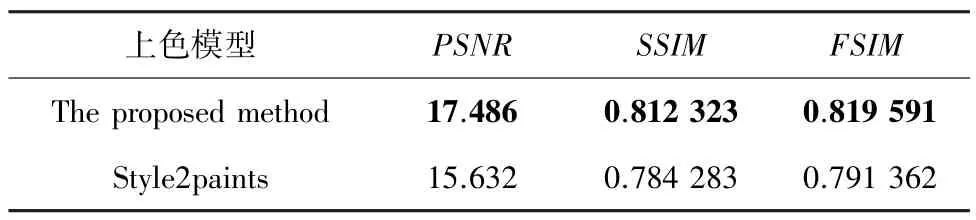
表2 本文方法和Style2paints 的实验结果Tab.2 Results of the proposed method and Style2paints
4 结束语
本文提出了一种集成U-net 变体和分类器的线稿风格迁移模型。通过残差增强的U-net 变体能够更好地传递颜色特征图信息,避免了U-net 训练时中间层梯度容易消失的问题,生成的彩色图像不会出现颜色混淆和颜色溢出的问题。同时引入2 个指引解码器来附加2 个损失,通过这2 个损失来训练生成网络,取代了原来的生成对抗的训练方式,使得网络模型能够更多地聚焦于全局信息、而不再关注颜色和线条的关系。经过实验证明,本文算法比Style2paints 在输出的结果上有着更高的颜色质量和更加平滑的颜色梯度,满足了人们的艺术审美需求。
本文的不足在于VGG 的分类是ImageNet 分类,只能使用训练好的VGG,如果可以找到或者制作一个庞大的线稿匹配数据自行训练,则网络的训练效果会更趋完善,甚至于生成的彩色图像会完全接近人工上色的效果。
