基于点云与图像融合的可行驶区域检测
2022-07-29邵哲钦黄影平郭志阳
邵哲钦,黄影平,郭志阳
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
交通场景感知是智能汽车环境感知的基本任务,汽车只有自主感知交通道路场景环境后,才能进行车的移动控制决策。无人驾驶汽车主要通过激光雷达、相机、毫米波雷达、GPS 全球定位系统等探测车辆周围的环境信息。其中,相机和激光雷达是智能汽车中运用最广泛的2 类传感器,能准确地感知物体的三维信息,相机则能够获取环境丰富的纹理信息。现有的研究表明,将相机与激光雷达两种传感器数据进行融合,可以提高道路检测精度。因此,相机与激光雷达融合是目前无人驾驶领域的热点和难点问题之一。
Shinzato 等人提出了一种基于传感器融合的鲁棒方法。该方法基于单目相机和3D 雷达的空间关系将雷达点云投影至相机图像之上,使用一种障碍物分类方法,将雷达点云分为障碍物点和非障碍物点,进而处理图像得到可行驶区域。Ren 等人于2003 年首次提出了超像素的概念,超像素是指具有相似纹理、颜色、亮度等特征的相邻像素构成的有一定视觉意义的不规则像素块。Achanta 等人于2010 年提出了SLIC 超像素算法、即简单的线性迭代聚类,首先将彩色图像转化为CIELAB 颜色空间和XY 坐标下的5 维特征向量,对5 维特征向量构造距离度量标准,对图像像素进行局部聚类。SLIC 算法能生成紧凑、近似均匀的超像素,在运算速度、物体轮廓保持、超像素形状方面的综合性能上都获得较高评价。
本文先将雷达点云投影至图像中,对点云进行德洛内三角剖分;其次,用两点之间的角度阈值区分障碍物与地面点;最后,使用超像素聚类,对点云分类结果在图像中进行补全,完成图像中可行驶区域检测。
1 方法
本文基于稀疏非结构化的三维激光雷达点云与相机图像融合,首先利用相机坐标与激光雷达的空间关系,进行雷达到图像的投影;其次,对投影至图像中离散无序的点云构建局部空间关系,并结合点云的三维度量来判断该点是否为障碍物;最后,在图像中以点云为核心,对图像所有像素点进行聚类,完成可行驶区域的划分。该方法包括5 个处理步骤:
(1)传感器融合。将三维空间中的雷达点云数据投影至相机坐标系中。
(2)构造离散点云的局部空间关系。通过德洛内三角剖分,构建德洛内三角网络,找出点云中最接近的点,并以直线连接,构成三角网络。
(3)点云分类。通过三角网络中点的空间关系,将点云分类为障碍物与非障碍物。
(4)聚类。借鉴SLIC 超像素算法中的聚类算法,在图像中以分类后的点云为中心进行聚类,将图像中所有像素点分为障碍物点与非障碍物点,对图像的分割结果进行补全。
(5)可行驶区域的提取。以视觉中心点、即图像最底部的中点为基准点,对可行驶区域做进一步分割。
1.1 坐标系融合
不同传感器有着不同的独立坐标系,必须把不同坐标系的数据变换到同一坐标系,找到同一时刻点云数据和图像中对应的像素点,才能实现融合。坐标变换主要分为2 个步骤,拟做分述如下。
(1)根据相机的内参和外参,将雷达坐标系下的点云P= (X,Y,Z,1)通过坐标变换到相机坐标系,得到P= (X,Y,Z,1),对此可表示为:
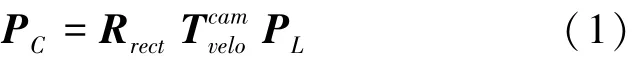
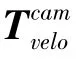


(2)为了得到像素坐标(,),将所有P代入公式(3):
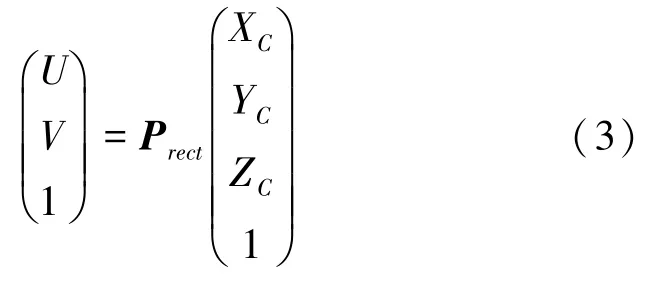
其中,P为矫正后的相机坐标系至像素坐标系的投影矩阵。
由于激光雷达的探测视野较大,有些点云会投影至图像外,直接剔除这部分图像外的点云,投影结果如图1 所示。图1 中,颜色越红,表示离激光雷达越近,越蓝则表示越远,将像素坐标(,)与(X,Y,Z)组成新的集合(X,Y,Z,,)。

图1 激光雷达点云投影至图像上的结果Fig.1 Results of LIDAR point cloud projection on images
1.2 构造离散点云的局部空间关系
利用得到的点的(,)坐标构造一个德洛内三角网,这是一系列相连但不重叠的三角形集合,以最近3 个点形成一个三角形。这种网络拥有以下特性:
(1)最接近性。以最近的3 个点形成一个三角形,且各三角形的边皆不相交。
(2)唯一性。无论从区域何处开始构建,最终都将得到一致的网络结果。利用这两点特性,可以保证所有点云都被包含在网络中,并能找出两两之间距离最接近的点云,将其作为三角形的顶点。利用德洛内三角网络将原本非结构化的离散点云数据结构化,其网络结构良好,数据冗余度小,大大减少障碍物分类的运行时间,其中所有小三角形顶点是上一步中投影得来的所有点,如图2 所示。

图2 德洛内三角网络Fig.2 Delaunay triangle network
1.3 障碍物点分类
本文采用基于点云三维坐标的障碍物分类方法,该方法简单高效,仅利用点的(X,Y,Z) 数据,即可完成分类,达到可行驶区域的初步分割。利用德洛内三角网,取所有三角形的每条边所连接的2 个点和为一对,使用公式(4)即可将障碍物与非障碍物节点区分开。此方法不用设定任何高度阈值,便可将点分类为障碍物与非障碍物点。函数() 在公式(4)中定义,如果函数() 返回正值1,则将节点分类为障碍物;如果函数返回0,则将其分类为非障碍物。这里用到的数学公式可写为:
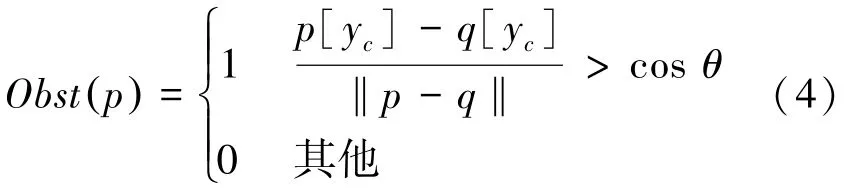
其中,[y][y] 为这两点之间的高度差;是一个阈值,Shinzato 等人使用该方法得到77°、为最优分类角度阈值,故直接取77°;‖‖ 是向量()长度,即,两点的距离。
分类结果如图3 所示,该方法将铁轨、汽车、树木上的点云都分类为障碍物点,而道路、2 条铁轨之间、以及草坪等比较平坦的地方分类为非障碍物点。

图3 障碍物点分类结果Fig.3 Obstacle points classification results
1.4 基于超像素算法的聚类
超像素是由一系列位置相邻,且颜色、亮度纹理等特征相似的像素点组成的小区域,可将一个小区域内具有相似特性的像素聚集起来,形成一个大元素、即一个超像素。使用超像素算法总能将原有物体的边界分割出来,利用该算法,对可行驶区域的检测结果进行补全,进一步细化障碍物的边界。常规超像素算法初始时,通过人为设置需要将图像分割成的超像素个数,并将聚类中心均匀置于图像中。若设置太小,则分割结果不一定能够覆盖物体所有的边界;若设置过大,虽然能更好地将物体轮廓覆盖,但会加深过分割的程度,一个物体会被分成许多区域,故而就要在后期合并相似区域来消除过分割的影响。
本文借鉴了SLIC 算法中用到的聚类方法,在其基础上进行改动,取消了迭代过程。本文的方法无需设定超像素的个数,而是直接将图像中所有分类后的点云作为聚类中心,以点云的数量作为值。此外,由于只将图像分为障碍物与非障碍物两类,故只要将同一类区域合并,即可很好地消除过分割的负面影响,同时又能够将障碍物边界精准地分割出来,简单又高效。具体步骤如下:
(1)初始化聚类中心(种子点)。将分类后的点云对应的图像位置的点设为聚类中心点(种子点)。
(2)计算距离度量。在每个种子点的22范围内搜索所有像素点,对于每个搜索到的像素点,分别计算这个像素点和该种子点的颜色距离与空间距离,推导得到的数学公式分别如下:
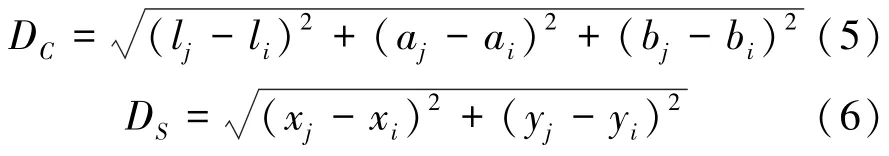
结合颜色距离与空间距离,得到距离度量,计算方法见式(7):
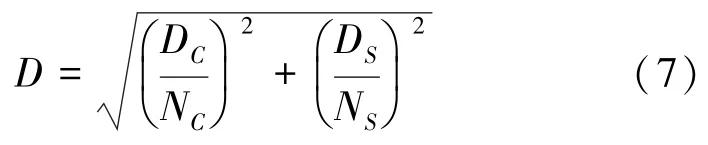
式(5)~式(7)中,D表示颜色距离;D表示空间距离;N是类内最大空间距离。
进一步,研究给出的数学定义表示式为:
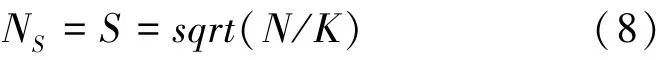
其中,为图片被点云覆盖区域的面积,如图4所示。为图像上点云个数,也是超像素的个数。最大颜色距离N随图片不同而不同,也随聚类不同而不同,取一个固定常数,取值范围[1,40],一般取10。

图4 点云覆盖区域Fig.4 Point cloud coverage area
由于每个像素点都会被多个种子点搜索到,所以每个像素点都会有一个与附近不同种子点的距离,取距离度量最小值对应的种子点作为该像素点的聚类中心。
(3)分配类标签。在每个种子点周围的22邻域内为每个像素点分配类标签。
(4)后处理。使用中值滤波以及平滑滤波对聚类结果进行处理,将障碍物边界提取出来,覆盖于原图中,得到图5。图5(a)中绿色区域代表非障碍物区域,红色代表了障碍物区域,图5(b)中蓝线为障碍物边界。

图5 障碍区域及其边界Fig.5 Obstacle area and boundary
1.5 可行驶区域提取
以视觉中心位置,即图片底部的中间位置的像素点为起始点,向两边延伸,若遇到障碍物边界,则停止延伸,并将沿途经过的像素点标记为0;此后,再以底部所有标记为0 的像素点为起始点,向上延伸遇到障碍物边界,则停止;最终得到可行驶区域边界,如图6 所示。

图6 可行驶区域边界Fig.6 Boundary of drivable region
2 实验结果与分析
2.1 Kitti 数据集
Kitti 数据集是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(stereo)、光流(optical flow)、视觉测距(visual odometry)、道路(road)、3D 物体检测(object detection)和3D 跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI 包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15 辆车和30 个行人,还有各种程度的遮挡与截断。KITTI 数据集中道路又分为urban marked(um)城市有标线、urban unmarked(uu)城市无标线和urban multiple marked(umm)城市多标线场景,共包含289 张训练图片和290 张测试图片,图像分辨率为1 240×375。定量评价时,需要将道路分割结果以二值形式的800×400 像素鸟瞰图(bev)上传至官网,进行评估。
2.2 评价指标
主要评价指标由KITTI 数据集官方指定,即加权调和平均作为最终的评价指标,计算方式见式(8):
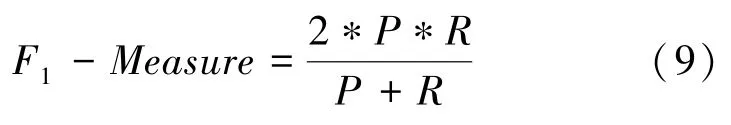
其中,为准确度(),即正确预测为正的像素点,占所有预测为正的像素点的比例;为召回率(),即正确预测为正的像素点占所有正样本的比例。
此外该数据集也提供平均准确率()、假阳性率()、假阴性率()指标的评估。
2.3 性能评估及比较
2.3.1 典型场景的可视化结果
从Kitti 公共数据集road 中选择uu 场景作为实验数据,得到可行驶区域的边界结果如图7 所示,绿线为可行驶区域边界。将实验结果上传至Kitti 官网评估,得到的部分评估结果如图8 所示。图8 中,绿色区域为正确分割像素,蓝色为假阳性像素,红色为假阴性像素。不难看出,本文的方法可以将可行驶区域与明显高出地面的障碍物,如草坪、汽车、路沿石等很好地分割出来。本文的算法不会因为道路中阴影部分与正常道路之间的纹理区别,而造成误分割。对于一些高度不明显的路缘石,以及禁止行驶的标记区域,本文不能很好地将其识别出来。

图7 实验结果Fig.7 Experimental results

图8 评估结果Fig.8 Evaluation results
2.3.2 与其他方法的比较
本文选取了Shinzato等人的方法以及基于条件随机场CRF 的方法进行检测结果对比,对比结果见表1。本文的达到了84.96,平均准确率达到了74.43%,分别超过了Shinzato 的方法将近3%和4%;本文与一些CRF 的方法对比,在指标上相差不大,但是在运行速度上,本文的速度比FusedCRF 和MixedCRF 这2 个方法提升了许多。
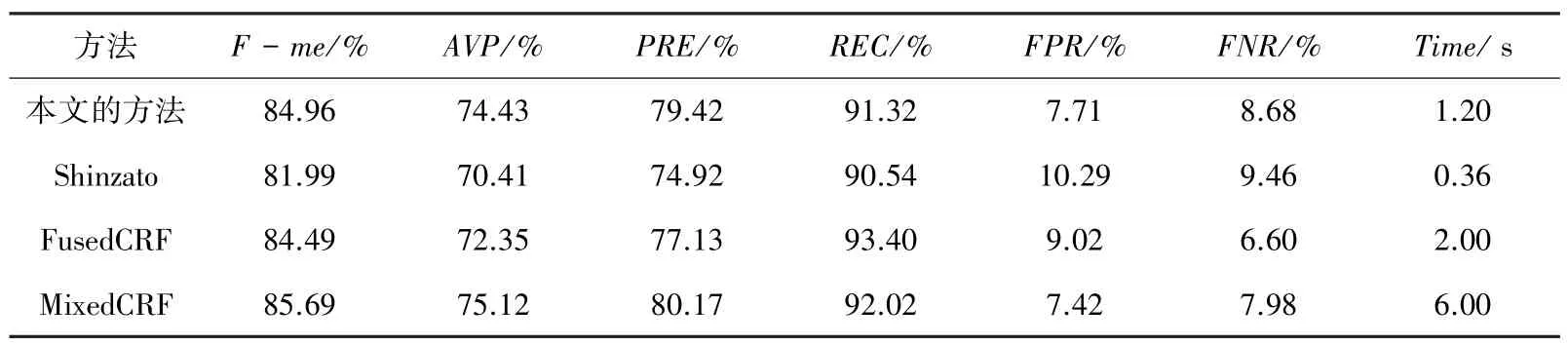
表1 Kitti 数据集评估与比较Tab.1 Kitti dataset evaluation and comparison
总的来说,本文提出的方法在检测精度和速度方面,展现出了更加全面的优势。但本文采用的思想对于高出地面的障碍物检测效果很好,对于一些地势平坦、但禁止行驶的区域不能很好地识别出来。
3 结束语
本文融合了单目相机图像的颜色信息和激光雷达的三维空间关系,结合了两者的优势,同时借鉴了超像素的思想,提出了一种新颖简单的可行驶区域检测方法,并取得了较好的检测效果。采用Kitti 数据集进行验证,结果表明,该方法可以有效地检测出可行驶区域,具有运行速度和精度的综合优势。
