一种基于灰色关联分析的缺失数据填补优化算法
2022-07-28陈小杰
陈小杰
一种基于灰色关联分析的缺失数据填补优化算法
陈小杰
(重庆师范大学 数学科学学院,重庆 401131)
针对传统KNN(k-NearestNeighbor)算法表示变量相关性不够精确的问题,提出了改进算法,即用灰色关联度去替代算法中的传统距离公式,得到近邻数值,然后将KNN算法思想与DBSCAN算法思想进行结合,排除异常值(噪声点的干扰)。多次实验结果显示,改进算法的均方误差和均方根误差值比传统方法小,证实了该改进算法的有效性。
KNN;DBSCAN聚类;数据缺失;灰色关联分析
1 改进后的填补算法
1.1 数据标准化及缺失构造
首先,将完整数据整理为矩阵模式,其中包含条数据实例,表示数据实例的维数,得到完整数据矩阵,记为:
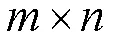
1.2 缺失数据预填补
在R统计软件中首先对以上训练集样本数据进行预填补,即将训练集样本数据按照列分成i个样本向量,算出每个属性向量中数值的均值进行初期填补,从而得到了一个完整无缺失的数据集记为1、2、3(对于三种缺失比例)。那么前述的数据矩阵就有:1→1、2→2、3→3。然后对缺失数据进行预填补得到完整数据集。在完整数据集上进一步工作,数据会更加有效反映出整个数据集的信息[4],使得结果可靠精确。
1.3 灰色关联度计算
基于传统的KNN思想,对于上述缺失数据集可进行缺失填补,它的算法流程大致如下[5]:

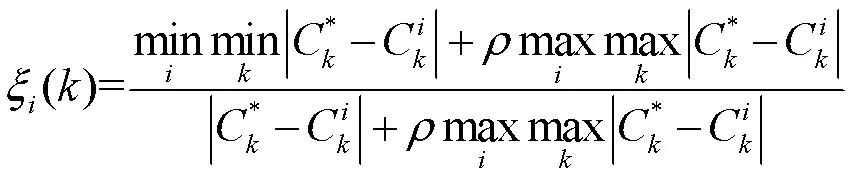
土木工程作为国民经济的重要组成部分,其对国民经济增长与发展有重要作用。随着当前土木工程管理信息化发展速度的加快,提高管理的信息化水平,实现网络信息技术的有效应用对土木工程可持续发展发挥着积极作用。通过计算机技术可以实现信息资源的共享,同时为土木工程建设提供更加可靠的依据。时代的发展对土木工程提出了更高的要求,土木工程技术也在不断创新与增加,这些都给管理提出来新的挑战。实现土木工程信息化管理势在必行。
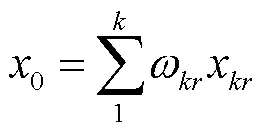
1.4 KNN与DBSCAN聚类结合
KNN填补算法是用填补数据的全部个近邻数据作为参考数据进行计算然后得到填补值,在数据填补中不能排除异常值的影响[7],所以笔者将DBSCAN聚类算法思想与KNN算法思想进行结合,在聚类的同时发现异常点。DBSCAN聚类算法中有两个重要参数,Eps是定义密度时的邻域半径,MinPts为定义核心点时的阈值,就是形成簇类所需要最小的样本数据点[8]。
对于DBSCAN聚类算法可分为以下几步:
第一步,首先确定Eps和MinPts,找到每一个样本数据点的Eps领域内的样本个数,如果个数大于等于MinPts,那么该样本就是核心点;
第二步,找出每一个核心样本密度直达和密度可达的样本,且该样本亦为核心样本,忽略所有的非核心样本;
第三步,如果Eps邻域内包含非核心样本,则该非核心样本就是边界样本,反之为噪声[5]。
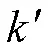
2 实例分析
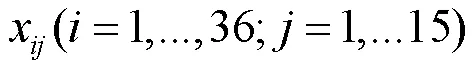
2.1 实验设置
首先进行构造缺失比例,数据的三种缺失模式直观分布情况如图1所示。
图1将数据可视化后可以观察到数据集每行数据是否缺失,横轴表示数据矩阵列向量,纵轴表示数据矩阵的行向量,缺失值默认表示为红色,红色部分代表该位置的数据是缺失的,浅色板块代表该数值比较小,深色板块代表该数值比较大。
然后,求参数Eps和MinPts。以距离矩阵中第一个样本数据(第一列数据)为例,数据分布如图2所示。
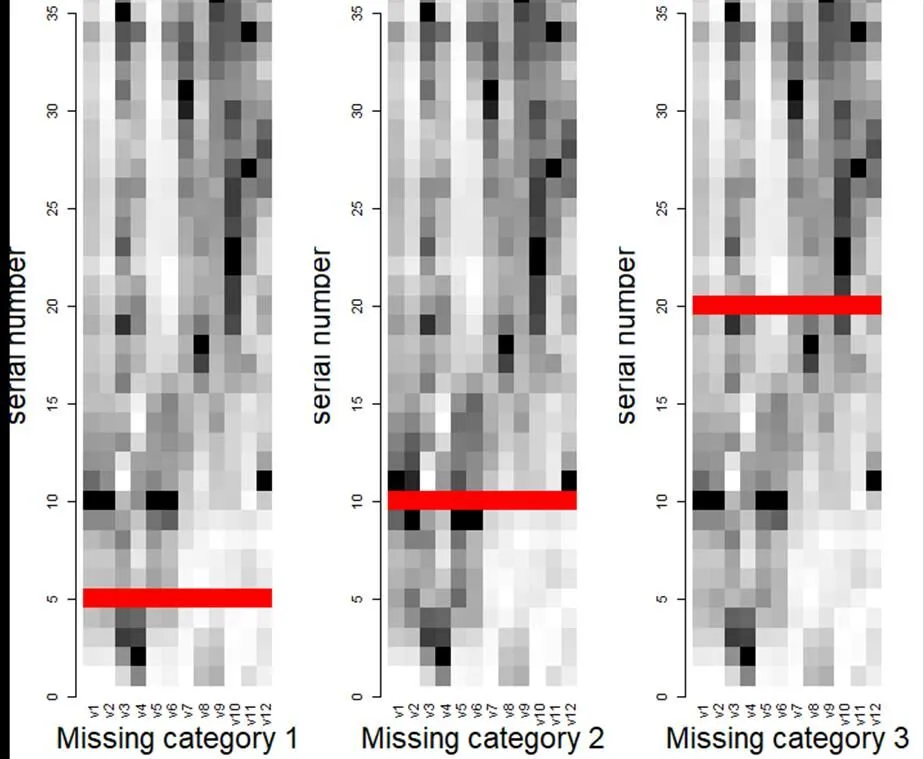
图1 数据缺失分布情况
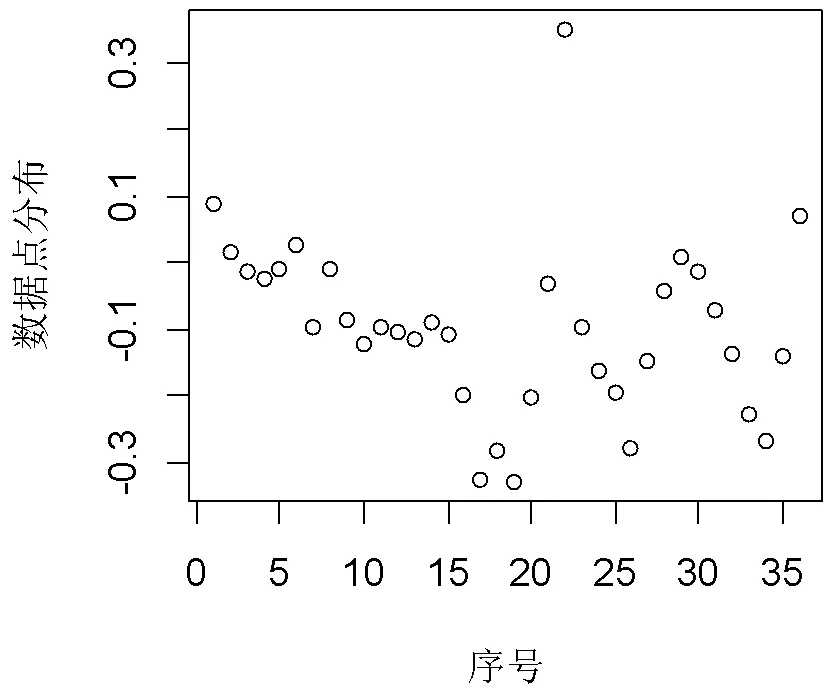
图2 样本数据散点图
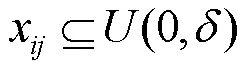
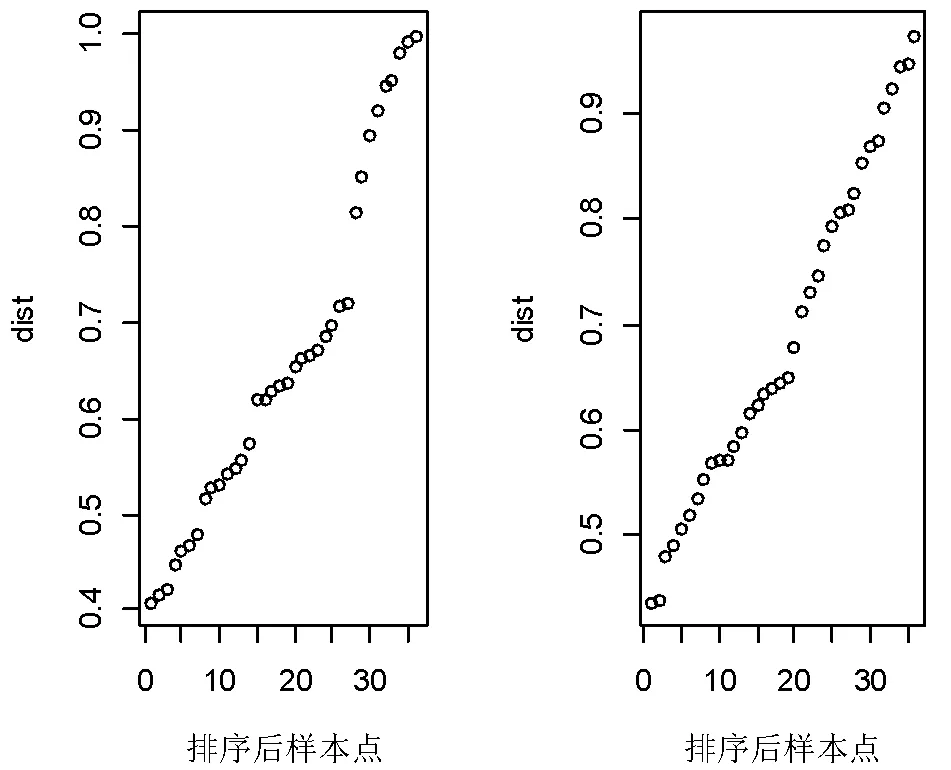
图3 排序后数据距离升序图
图3是距离矩阵排序后的距离走势图。由图可知在dist=0.60时出现了拐点,所以取Eps=0.60,最小邻居数的取值范围应为2≤MinPts≤。在本文运用中,我们选择样本量平方根[6]作为确定的值,结合本文运用的数据量,选取值为9。由于我们的数据量较小且数据变化比较小,所以更适合DBSCAN聚类算法,且密度阈值应满足2≤MinPts <9,综合考虑,设置密度阈值MinPts=7。
2.2 实验结果
均方误差(MSE)均方根误差(RMSE)是衡量真实值与填补值之间的差距的一个指标并以此作为评价缺失数据填补效果的指标,其值越小说明填补数据效果越好,其计算公式为[8]:
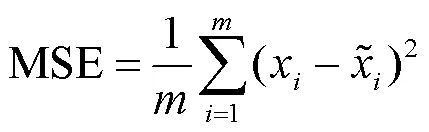
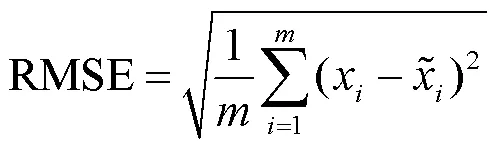
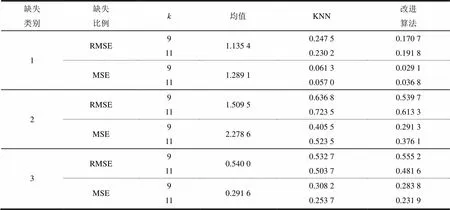
表1 数据缺失实验结果
表1中,最好的填补效果值用黑体进行标注。从表中可以清晰地观察到,在多种情况下,基于KNN改进的算法的均方根误差值(或者均方误差值)都比改进前的KNN算法较小,说明经过改进的KNN算法比传统KNN的算法要更有效[9],填补缺失值能力更高[10]。
3 结论
在传统的KNN算法在基础上,提出了优化改进,引入灰色关联度替换传统的欧氏距离。实验结果证实,在填补缺失值时,改进算法明显提高了填补效果。
[1] 晔沙.数据缺失及其处理方法综述[J].电子测试,2017, 24(18):65-67.
[2] H. Toutenburg. Little, R. J. A. and D. B. Rubin: Statistical analysis with missing data[J]. Statistical Papers, 1991, 32(1): 70-75.
[3] 毛冬焰.在“灰”色的世界里探索──邓聚龙教授访谈[J].统计与决策,1995,11(2):6-9.
[4] 张赤.基于聚类分析的缺失数据填补算法研究[D].武汉:武汉轻工大学,2013:7-12.
[5] 谢霖铨,赵楠,徐浩,等.基于属性相关性的KNN近邻填补算法改进[J].江西理工大学学报,2019,40(1):95-101.
[6] 刘莎,杨有龙.基于灰色关联分析的类中心缺失值填补方法[J].四川大学学报(自然科学版),2020,57(5):871- 878.
[7] 张晓斌.基于出行特征的纯电驱动客车储能系统设计与能效优化[D].北京:清华大学,2017:9-16.
[8] 解小东,陈治华.基于KNN-DBSCAN的缺失数据填补优化算法[J].工业控制计算机,2020,33(4):58-63.
[9] Yonghua Wang, Jingyi Lu, Kaidi Zhao. A locally weighted KNN algorithm based on eigenvector of SVM[J]. Inter- national Journal of Wireless and Mobile Computing, 2020, 19(3): 256-266.
[10] 王治和,曹旭琰,杜辉.一种优化初始点与自适应半径的密度聚类算法[J].计算机工程,2022,48(1):51-59.
A Missing Data Filling Improved Algorithm Based on Grey Relational Analysis
CHEN Xiao-jie
(School of Mathematical Sciences, Chongqing Normal University, Chongqing 401131, China)
Aiming at the problem that the traditional KNN algorithm is not accurate enough in expressing variable correlation, an improved algorithm is proposed. The grey correlation degree is used to replace the traditional distance formula in the algorithm to obtain the nearest neighbor value, and the idea of KNN algorithm is combined with the idea of DBSCAN algorithm to exclude outliers (interference from noise points). The experimental results show that the MSE and RMSE of the improved algorithm are smaller than those of the traditional method, which proves the effectiveness of the improved algorithm.
KNN; DBSCAN; missing data; grey relational analysis
TP301.6
A
1009-9115(2022)03-0014-03
10.3969/j.issn.1009-9115.2022.03.005
2021-07-12
2022-04-19
陈小杰(1996-),女,重庆开州人,硕士研究生,研究方向为应用数理统计。
(责任编辑、校对:赵光峰)
