基于Doc2Vec和随机森林的外卖评价预测方法
2022-07-26梁家富李家华
梁家富, 李家华
(广州科技职业技术大学 信息工程学院, 广东, 广州 510550)
0 引言
随着互联网的快速发展,社交媒体飞速成长,大量的外卖评论产生。外卖评论留言与商家的销量存在巨大的利益关系,诱发个别商家通过违规手段构建虚假评论。虚假评价迷惑性大,消费者难以识别,会误导消费者进行网上点餐。当前,外卖餐饮一般都是采用人工统计的方式收集,无法适应大规模评论的精确统计要求。为了构建公平的外卖环境,迫切需要一种自动化的手段收集外卖评论信息并判断信息虚假性质,压制外卖购买的虚假评论,维持公平稳定的外卖环境。
很多学者对本文评价数据进行了大量虚假测评和研究分析。岳文应[1]提出了基于Doc2Vec与SVM整合的文本聚类模型,对象是聊天信息的检测,判别信息虚假性和判断该信息是否被阻挡。黄欣欣[2]利用Ott黄金数据集,基于word2vec和CNN结合,构建CNN模型结构,生成CNN模型。王晨超[3]提出采用Doc2vec和DNN结合模型对语料文本进行聚类分析。
本文在随机森林模型的基础上,融合在探究词义相关上有优越性的Doc2vec句向量,提出一种新的基于RF模型和句向量的文本表示方式——随机森林句向量模型(Doc-RF)。这模型保留了RF模型的优势,同时增加了文本词义信息。Doc2ve在通过训练文本的短语,结合上下文的段落向量,可以准确解析不同语境中的词语义,再与随机森林模型对文本整体性集合,全面地提高文本模型在语义环境研究中的精度[4]。
1 相关技术
1.1 Doc2Vec模型
2014年Mikolov团队在Word2vec算法的理论基础上提出改进的Doc2Vec模型,Word2vec模型的基本理论是:依据上下文的词语进行预测下一个词语出现的几率。Word2vec模型如果给定上下文的训练集,通过训练得到词向量,将词向量级联或者求和作为特征值,可以预测下一个词语出现概率[5]。公式如下:
(1)
如果计算的是多分类问题,预测需要分类器最后一层使用层次(softmax),目标公式如下:
(2)
这里eywi是对数函数,把每个单词当作一个类别,任务输出层的每个词的计算公式如下:
y=a+bf(wn-k,…,wn+k;W)
(3)
其中,a和b都是softmax参数,函数f则是wn-k,…,wn+k从词向量矩阵W中的级联或者求平均。
Doc2Vec与Word2vec应用近似,Doc2Vec训练对象是句向量,Word2vec训练对象是词向量[6]。Doc2Vec模型增加一个段落向量paragraph id,它的长度与词向量相等,具有固定长度,具有对新鲜样本更好的适应能力。Doc2Vec有两种模型:Distributed Memory (DM)和Distributed Bag Of Words(DBOW)。DBOW是基于目标单词预测上下文出现的概率,而PV-DM是从已知的上下文预测目标单词[7]。本文采用PV-DM进行研究,如图1所示。
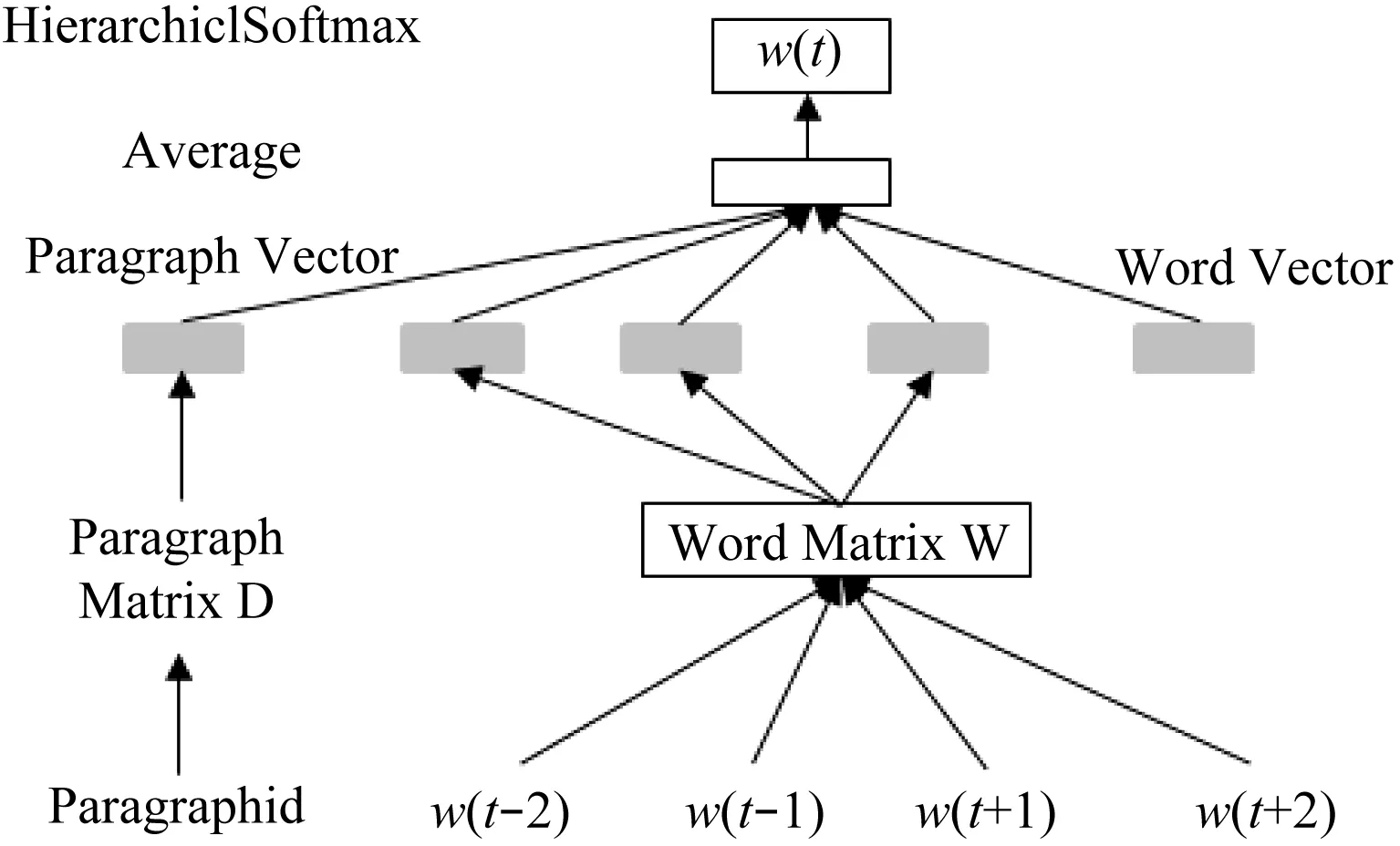
图1 PV-DM向量模型
1.2 RF(随机森林)模型
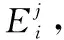
(4)
式中,X随着参数j变动,导致袋外误差增加越快,精度减小得越大,则表示该参数越重要。研究现有成果得到,随机森林算法可以防止删除重要的参数。
本质上RF模型就是一种决策树,通过对分类树的边和节点进行甄辨,得到预测目标。随机森林算法流程如图2所示。

图2 随机森林算法流程
1.3 Doc-RF模型
随机森林模型在数据噪声大时会出现拟合情况,选用的属性过多会影响RF的结果。Doc2Vec算法具有较好的泛化能力,能以局部特征预测下一个词语,生成精准的段落向量数据集[9]。因此,将Doc2Vec的局部泛化信息与随机森林模型高效的集成信息融合进行训练向量学习,使Doc2Vec_RF既充分使用全部语料库的内容,又保留段落与文档上下文的相关语义,新的词向量拥有更精确的自然语言处理甄别能力和预测能力。
Doc-RF模型如图3所示。它是由文本预处理、文本向量构建和随机森林预测评分三个阶段构成。

图3 Doc-RF模型总体框架
文本预处理阶段,主要是对外卖评价预料库通过AliWS(Alibaba Word Segmenter)词法分析系统、停用词过滤和增加序列号等方式进行数据预处理。文本向量构建阶段,Doc-RF模型是文档、段落主题、单词组成的高维语义空间,外卖评价语料库是一系列独立的评价语句组成,把每句评价句子采用Doc2Vec模型进行训练得到文本向量。RF预测评分阶段,就是充分利用本文向量拆分、RF训练和预测功能完成预测评分。最后,使用混淆矩阵进行模型的评估。

Doc-RF模型的总体框架的训练过程其步骤可总结如下。
(1) 对外卖评价数据集进行数据预处理,采用AliWS词法分析系统,对数据集的评价内容列进行分词。
(2) 基于停用词数据集使用停用词过滤组件对外卖评价内容预处理,得到语料库DOC文档。
(3) 在语料库中添加段落号append_id,满足Doc2Vec算法的基本要求。
(4) 利用Doc2Vec算法进行短文本分析,得到语料库的短文本向量表,通过join内连接,把短文本向量表和评价内容列合并,组成新的短文本向量表。
(5) 使用拆分组件采用“按比例拆分”0.7比例进行切分短文本向量表,得到两份文本向量表。大比例的向量表是提供给随机森林模型进行训练学习的,小比例的向量表是用了预测验证使用。
(6) 采用随机森林算法对大比例向量表进行模型生成,得到由各100个子树组成的森林模型。
(7) 利用预测组件对RF训练结果开展预测评分,得到预测向量表。
(8) 最后使用混淆矩阵组件对向量表进行统计分析,得到预测结果数据和评估报告。
2 实验设计及分析
2.1 数据集
本实验的开发环境采用阿里云机器学习PAI实验室,模型开发与训练使用Studio-PAI可视化建模平台,大数据计算机服务使用MaxCompute平台。使用的数据集来自阿里云天池实验室对外开放的公共数据,数据集的内容是外卖评论数据库。本项目的数据集由两部分构成,一是语料库共11 987条,二是停用词库共746条。外卖评论数据库如图4所示。
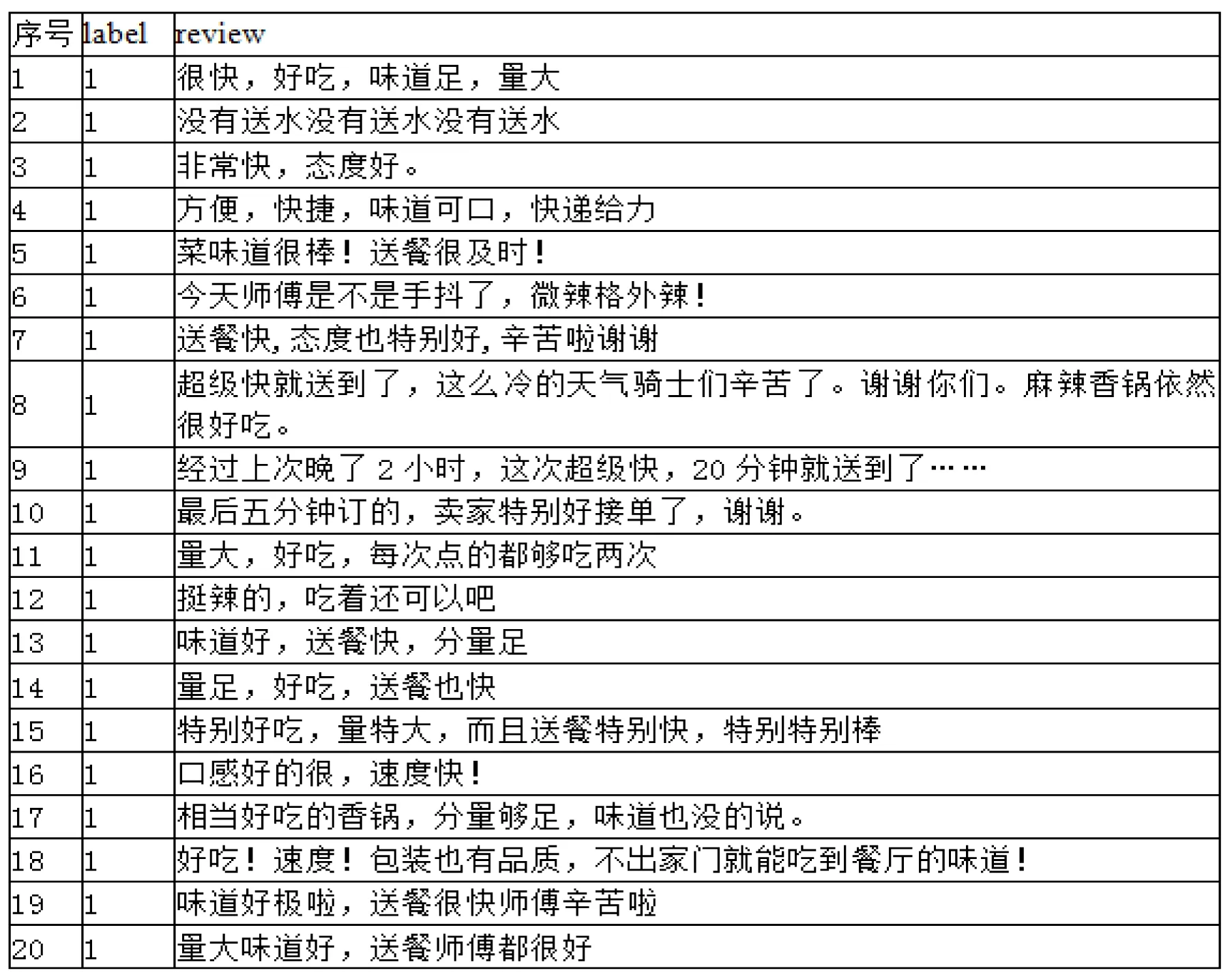
图4 外卖评论数据库
2.2 Doc-RF模型训练过程分析
训练集经过停用词过滤和增加序列号等处理后,语料库采用Doc2Vec算法训练词向量,向量模型的参数设定如:单词的特征纬度一般是[0,1 000],本文采用100;语言模型本文采用cbow模型;单词窗口大小为5;截断的最小词频为5;采用Hierarchincal Softmax;Negative Sampling设定为5;向下采样值一般是1e-3或者1e-5,本文取值为1e-3;开始学习速率0.025;训练的迭代次数为1;windows是否随机,本文采用“不随机,其值有Windows参数指定”。训练集经过Doc2Vec运行之后,输出的文本向量表。
随机森林模型的参数设置如:森林中树的个数(0,1 000],本文采用100;单棵树在森林中的位置,采用id3、cart、c4.5算法在森林中均分;单棵数随机特征数范围[1,N],采用log2N;叶结点数据的最小个数为2;叶结点数据个数占父节点的最小比例[0,1],设为0;单棵树的最大深度[1,∞),设为默认无穷大;单棵树输入的随机数据个数(1 000,1 000 000),设为100 000。经过Doc-RF模型训练后生产f0-f99棵子树,其中f0子树结构如图5所示。

图5 Doc-RF模型下f0子树结构
2.3 Doc-RF模型训练结果分析
本项目模型使用F-measure(F1)对外卖评价预测效果进行综合评价,F1就是一个综合衡量准确率(Precision,P)和召回率(Recall,R)的metric[10]。采用正确率、召回率和F1等评价指标来衡量模型的效果,对应公式如式(5)~式(7):
(5)
(6)
(7)
本文为了进一步验证Doc-RF模型对外卖评价方面的预测作用,本文选取几种经典的算法与Doc-RF算法进行横向比较。经过筛选,本文选用逻辑回归二分类、GBDT二分类、SVM以及朴素贝叶斯作为比较算法。性能评价指标主要是正确数、错误数、总计、准确率、精确率、召回率和F1指标。在保证其他操作一致的条件下,进行了5种算法的实验。实验结果见表2。

表2 五种预测方式的实验结果
分析表2可知,使用逻辑回归二分类、GBDT二分类、RF、SVM和朴素贝叶斯算法进行外卖评价时,在准确率和召回率上差异不是特别大。
(1) 在正确数指标中,SVM算法以2 326正确数排行第一,与此同时SVM算法在错误数指标中也是排行第一,这是因为SVM算法的召回率高达97.00%,参与运算的数据总计3 240也是第一的。
(2) 在精确率上,GBDT二分类算法以78.99%占据第一名。
(3) 在准确率上,随机森林算法以78.60%的准确率排在榜首。在F1综合指标中,随机森林算法F1指标值为85.42%以微弱的优势排在第一位。
综上所述,随机森林算法在外卖评价预测系统中比逻辑回归二分类、GBDT二分类、SVM和朴素贝叶斯算法更优,符合外卖评价预测系统的设计要求。
3 总结
本文提出了一种基于随机森林和Doc2Vec算法的外卖评价预测模型,使得该模型既能结合数据集的全局信息,又利用段落向量在上下文的相关性,通过随机森林算法较精确地预测外卖评价的语义信息。Doc2Vec模型依据段落特征从外卖评价数据集中提取出词语义信息,建立段落向量和词向量之间的相关性,采用随机森林算法分类树的预测优势,得到预测的混淆矩阵评估报告。实验说明,基于随机森林模型的预测效果优于逻辑回归二分类、GBDT二分类、SVM和朴素贝叶斯等模型,应用性更强,能够解决外卖评价的虚假质量问题。
