基于改进的YOLOv3口罩佩戴检测算法研究
2022-07-25黄日辰陈晓龙
王 静,黄日辰,陈晓龙
(金华职业技术学院,浙江金华 321007)
2020 年暴发的新型冠状病毒的主要传播途径是呼吸道飞沫传播,佩戴口罩是防止病毒传播最重要的一个手段,也能保障人们最基本的健康。疫情防控常态化要求在公共场合布置口罩检测系统,通过系统检测人们是否正确配套口罩,而且还要求检测系统有较高的工作效率,因为高检测效率在一定程度上能降低病毒传播速度。疫情期间,学校、超市、车站等人群密集场所都需要工作人员检测过往人们是否正确佩戴口罩,这样不仅增加了工作人员的工作量,而且工作效率较低。因此研制一个高效并准确检测口罩佩戴的算法是非常有必要的。
传统的口罩识别技术一般基于深度学习的有两种通用检测算法框架。第一种是二阶段的检测算法,第一步利用候选区域生成网络(RPN)获取多个候选区域,第二步通过卷积神经网络对候选区域中的目标进行分类以及对目标位置进行微调。常见的二阶段的检测算法有以RCNN[2]、Fast RCNN[3]、Faster RCNN[1]为代表的RCNN 系列算法。第二种是一阶段的检测算法,该类算法可以直接回归得到目标的位置预测框。常见的一阶段检测算法有YOLO[4]、SSD[5]等算法。一阶段算法比二阶段检测算法检测速度更快。本文拟以一阶段的检测算法YOLOv3[6]为基础,针对检测速度、精度以及适应不同场合下的情况,进行如下改进:第一,针对检测速度重新设计了YOLOv3的主网络,引入快速降采样模块,YOLOv3原主干网络Darknet53需要53层达到32倍降采样,而该模块只需要4 层;第二,针对检测精度本文在YOLOv3后面加入一个分类网络。
1 YOLOv3算法介绍
1.1 网络结构
YOLOv3在视频、实时目标检测、图像等的应用中经常使用。YOLOv3 是YOLOv2[7]的改进版,检测精度和检测速度要比v2 高和快。YOLOv3 算法以Darknet53 网络结构为基础,使用Darknet53 网络作为特征提取,如图1所示。
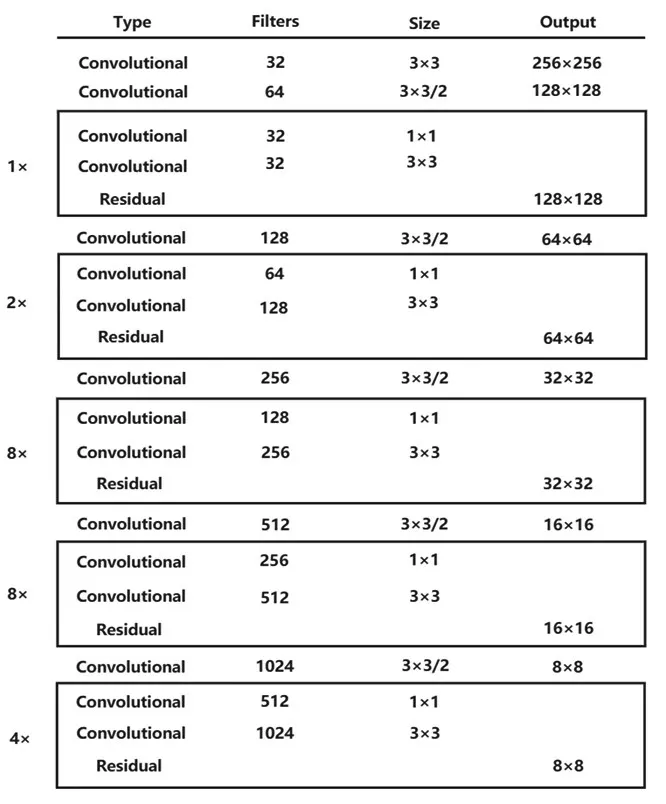
图1 DarkNet53网络结构
Darknet53网络是包含了53个卷积层的全卷积结构,在每个卷积层后跟有一个归一化层和一个激活层;同时为了防止信息丢失过多,采用了步长为2的卷积操作实现采样。Darknet53 还引入了残差块结构,不仅能使深层网络的难度训练有效降低,还能更好地收敛网络。
YOLOv3 引入了特征金字塔网络思想(FPN)[8],通过提取不同尺度的特征图,提高对小目标检测的精度。为了提高检测精度,YOLOv3 将经过采样的深层特征与浅层特征进行融合,生成特征图有三种不同尺度,分别用于检测小、中、大三种尺寸的目标。三种尺度的特征图用来检测不同比例的目标,每种尺度的特征图上生成不同比例的3 个锚点框。在预测和训练过程中,锚点框的比例通过对数据集中的目标进行聚类得到。如图2 所示,YOLOv3 在检测的过程中,将输入图片划分为S×S个网络,每个网格的宽、高为Cx、Cy网络输出相对于锚点框的偏移量分别是tx、ty、tw、th,预测框目标计算公式为:

图2 预测框示意图
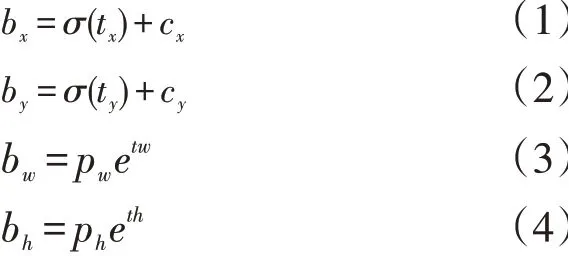
其中预测框的中心坐标为(bx,by),宽高分别为bw、bh,锚点框的宽高分别为pw、ph。Sigma 为激活函数,将预测值tx、ty映射到[0,1]区间内,计算每个预测框的置信度。设置置信度的阈值,对小于阈值的预测框进行过滤,最后利用非极大值抑制算法删除多余的预测框。
1.2 分类预测
在实际应用中,一个目标分属于多个类,为了解决该问题,YOLOv3 采用了多个Logistics 分类器代替原有的Softmax 分类器,对每个类别进行二分类。输入值用Sigmoid函数归一化到[0,1]之间,Sigmoid函数为

其中,z为分类边界函数,假设边界函数为线性的,该函数公式为
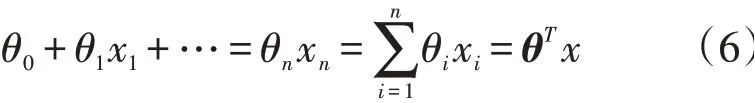
将其代入到Sigmoid函数中,得到预测函数公式
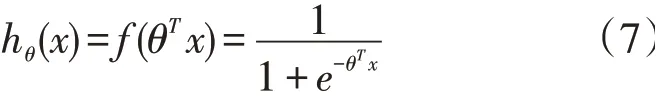
当Sigmoid 值超过0.5 时,判定目标属于该类,否则则不是。
2 算法改进
2.1 网络结构改进
Darknet53网络是一个非常耗时的网络,对硬件的要求较高,在资源较少的设备上无法保证实时性。为了确保口罩佩戴检测算法可以部署在CPU或者边缘设备上,本文参考了FaceBoxes[9]中的主干网络设计原则,设计了一种轻量化的主干网络来替换YOLOv3中的Darknet53网络,设计规则为主干网络分为快速降采样网络模块和Inception[10]网络模块。在快速降采样网络模块中采用一系列大步长的卷积层来快速降低输入,如图3 所示。其中Conv1 步长为4,Conv2、Conv3、Conv4 步长均为2。相比于DarkNet53 需要通过53 层卷积层才达到32倍降采样,本文设计的轻量化网络只需要通过前4层网络就能完成32 倍降采样,该轻量化网络适合CPU 下实时运行。另外为了避免快速下降所导致的精度下降,Conv1 和Conv2 采用7×7 的卷积核,Conv3 和Conv4 采用5×5 的卷积核。为了进一步降低计算量,本文采用CReLU[11]。有文献指出CReLU浅层网络的滤波器具有对称性,因此可以在网络输出经过CReLU 函数之前通过拼接的方式对网络的输出通道数进行加倍,以达到更好的效果。Conv1、Conv2 的通道数为24,Conv3、Conv4 通道数为64。

图3 快速降采样网络模块
口罩佩戴检测场景下,人脸的尺度范围大,单一尺度下卷积网络特征提取导致检测效果较差。因此,为了更好地提取到不同尺度下的人脸特征,提高检测精度,在快速降采样网络模块后加入Inception网络模块,如图4所示,同时对Inception模块进行重新设计,如图5所示。

图4 Inception网络模块
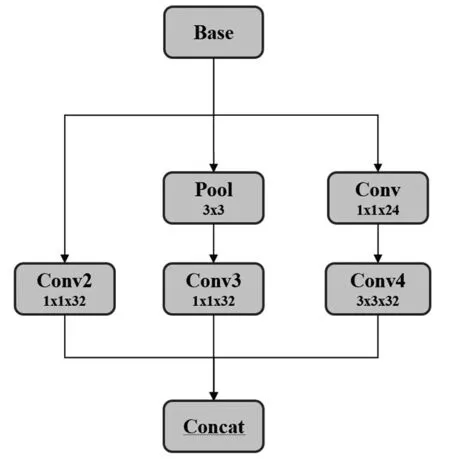
图5 Inception网络模块
2.2 加入分类网络
在传统的深度学习检测算法中分类任务和编辑框回归共享一个检测头,有学者[12]提出fc-head更加适用于分类任务,conv-head 更加适合于边界框回归任务。基于该发现,本文在YOLOv3 的检测头后面添加一个用于判别是否佩戴口罩的分类网络,如图6所示。
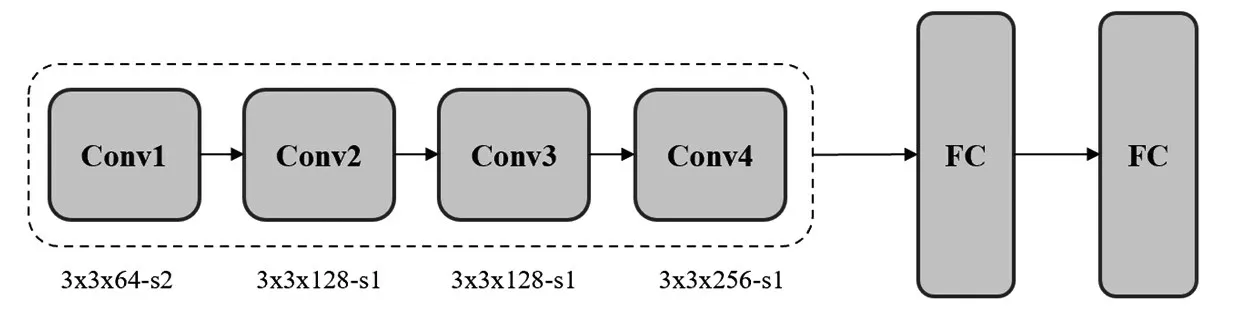
图6 分类网络
2.3 锚点设置
考虑到人脸目标都是1∶1 的比例,本文将YOLOv3 中不同比例的锚点框比例设置为1∶1。为了尽快提高小目标的召回率,引入了Faceboxes中的锚点定义策略。
3 训练
3.1 训练数据集
本文的检测模型和分类模型都使用了WIDER FACE[13]、RMFD[14]和CMFD[15]数据集。其中在分类模型训练过程中会根据检测模型的结果对WIDER FACE和RMFD中的数据进行人脸裁剪。
检测模型训练数据集:检测模型采用了WIDER FACE 和RMFD 数据集。随机抽取WIDER FACE数据集中,按人脸从大到小排序,取前70%的人脸数据进行口罩覆盖数据增强。
分类模型训练数据集:分类模型数据集采用了经过检测模型检测后并裁剪后的WIDER FACE 数据集和RMFD 数据集,分类数据集的图片大小统一缩放到416×416。
口罩覆盖数据增强方式:为了更加有效地检测人们口罩佩戴情况,数据集CMFD 将不正确佩戴口罩分为未覆盖下巴、未覆盖鼻子和未覆盖鼻子及嘴巴三类,利用关键点检测算法生成了相关样本,但是CMFD只考虑了外科口罩的情况并没有考虑其他类型的口罩。本文为了提高模型的泛化性,在WIDER FACE 和CMFD 数据集进行口罩覆盖数据增强时添加了多种防护口罩类型。
3.2 数据增强
除口罩覆盖数据增强外,训练检测模型和分类模型都遵循色彩失真、随机裁剪、尺度缩放、水平翻转等数据增强策略。
3.3 实现细节
检测模型和分类模型的参数都采用“Xavier”方法[16]进行初始化,采用动量为0.9的随机梯度下降法(SGD),权重衰减系数设置为0.0001 和BatchSize 设置为32。检测模型总共进行15 万次训练迭代,前10万次学习率设置为0.001,后5万次学习率分别对半设置为0.0001和0.00001。分类模型进行10万次迭代训练,前8 万次学习率设置为0.001,后2 万次学习率设置为0.0001,BatchSize设置为64。
3.4 损失函数
本文中口罩识别采用的损失函数有两类,一类是检测模型的损失函数,另一类是分类模型的损失函数。其中检测模型采用YOLOv3 中的损失函数,分类模型采用Softmax 损失函数。口罩识别分类有两大类:正确佩戴口罩和不正确佩戴口罩,其中不正确佩戴口罩又分为未覆盖鼻子、未覆盖鼻子和嘴巴、未覆盖下巴三小类。针对不同类别,文中分类损失函数采用了不同的类别权重系数,其中正确佩戴口罩类别系数为0.1,未覆盖鼻子的不正确佩戴口罩类别系数为0.5,未覆盖鼻子和嘴巴与未覆盖下巴的不正确佩戴口罩类别系数设置为0.2。
4 实验验证
4.1 运行效率
卷积神经网络算法的最大缺点就是运行效率不够高、实用性不够强。尽管现在的卷积神经网络算法可以通过GPU进行加速达到实时性,但这也限制了算法的应用场景,尤其是在CPU 设备上的使用。本文提出的算法就是为了更好满足CPU 设备场景下的应用。表1 展示了CPU(i7-4770k@3.50)下的本文的算法和YOLOv3在速度上的对比。
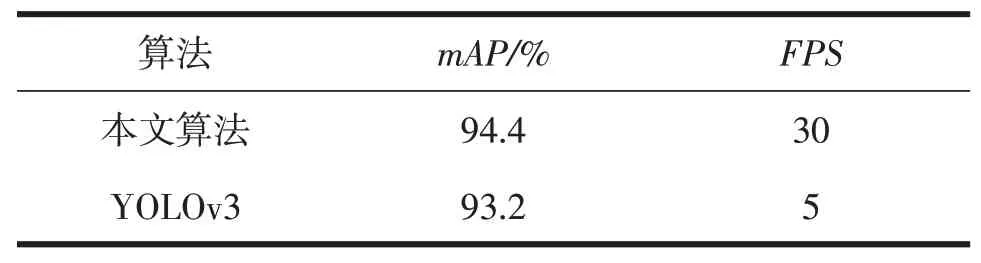
表1 与YOLOv3算法运行速度上的对比
4.2 分类模型
为了证明在检测模型后面增加一个分类模型的有效性,本文进行了对比试验。基于相同的参数分别训练了一个带分类模型和不带分类模型的检测算法,结果如表2所示。

表2 带分类模型和不带分类模型的检测算法对比
通过可视化分析发现,在CMFD 数据集中的不正确佩戴口罩的数据集,在加入分类模型后的效果优于不带分类模型的算法。
4.3 快速降采样模块
池化层在一定程度上会损失信息往下传递,本文对FaceBoxes 中的快速降采样模块进行了改进,对比试验结果如表3所示。

表3 与FaceBoxes中的快速降采样模块对比
4.4 Inception模块
本文算法对FaceBoxes 中的Inception 模块进行进一步简化,提高模型的运行效率。对比试验结果,简化后的模块虽然在精度上下降了0.2%,但是运行速度却提高了21%,如表4所示。

表4 与FaceBoxes中的Inception模块对比
图7展示了测试结果,图7中第1排和第2排图片表示检测出未佩戴口罩,第3 排图片表示正确佩戴口罩,第4排图片表示未正确佩戴口罩。

图7 检测结果
5 结论
当前的疫情环境下,口罩佩戴识别系统是一个应用非常广泛的系统,为了尽可能减少对硬件资源的依赖,本文提出了基于YOLOv3 的不受限于硬件资源的口罩佩戴检测算法。该算法与YOLOv3算法相比,精度只损失了0.8%,但是在CPU 上的运行速度是YOLOv3的6倍。
