基于沙漏结构的实时语义分割算法
2022-07-25禹素萍许武军
张 政,禹素萍,许武军,范 红
(东华大学信息科学与技术学院,上海 201600)
0 引言
近年来,随着深度学习技术的快速发展和GPU 计算能力的不断提高,深度学习相关的技术已经应用到了很多领域,如图像分类、目标检测和跟踪、语义分割等。如今,图像的语义分割已是计算机视觉领域不可或缺的一部分,并且已经在诸多方面体现出其应用价值,如自动驾驶、医疗诊断、娱乐应用等。
图像的语义分割被定义为对图像进行逐像素的分类,具有图形分类和目标检测两者的特性。随着将深度学习在图像语义分割领域的应用,越来越多的算法在近几年不断涌现,不断刷新这个领域的最高精度。这一切的起点便是2015 年Long 等发布的全卷积神经网络(FCN),将最后的全连接层替换成卷积层,并且在编码器和解码器结构中引入了跳跃连接,为此后的研究标定了新的起点。
在语义分割的领域需要考虑两个问题:分割精度和分割时间。因此划分出了两种不同风格的语义分割网络,第一种是以分割精度为目标的Deeplab 系列语义分割网络,其中最新的Deeplab v3+网络在沿用了之前版本中的空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)结构的基础上进行改进,添加了解码器模块,并且改进了Xception 模型,使Deeplab v3+ 在cityscapes 数据集上的平均交并比(MIoU)达到了82.1%。但是算法模型大,推理时间长的缺点让Deeplab v3+在考虑实时性的领域难以应用。第二种是以牺牲部分精度换取分割时间的,以提高分割实时性的网络,如ENet,ERFNet,ESPNet等。大多数实时语义分割网络使用了Resnet,Mobilenet v2等轻量级的骨干网络,采用高效的特征融合方式,做到了语义分割领域中分割实时性的突破。
为了解决上述分割精度和分割实时性不可兼得的问题,本文构建了基于沙漏结构的实时语义分割网络,使用沙漏结构搭建骨干网络,相比倒置残差结构,在仅仅增加少量计算量的情况下,达到更高的精度。借鉴了Deeplab v3+中空洞空间金字塔池化模块并加以改进,使用深度可分离卷积替换原有的普通卷积,在降低计算量的同时保证语义特征的提取,加快推理时间,提高实时性。并且将经过不同空洞卷积所得到的特征图进行逐层特征叠加,进一步抑制空洞卷积产生的网格现象,针对不同维度的特征,使用注意力机制进行引导,设计了特征融合模块,提高语义分割的精准度。
1 模型设计
1.1 融合空洞卷积的沙漏模块
近年来,为了构建轻量的骨干网络,出现了瓶颈结构、倒置残差结构和本文中的沙漏结构。如图1(a)所示,瓶颈结构先使用1 × 1 的卷积降维,以减小通道数,再使用普通卷积进行特征提取,最后使用1 × 1 的卷积升维。瓶颈结构不仅降低了计算量,而且加深了网络层数,便于训练。如图1(b)所示,倒置残差结构是MoblieNet V2提出的,它提高了移动网络在多类型任务分类中的性能。倒置残差结构中首先使用1 × 1 的卷积进行通道数的上升,用来获得更多的图像特征,之后使用大小为3 × 3 的卷积核提取特征,最后再使用1 × 1 的卷积核进行降维处理。由于特征维数的缩小,容易导致传播中的梯度混淆,从而削减梯度跨层传播的能力,进而影响训练过程中的收敛和模型的性能。因此,沙漏结构应运而生。如图1(c)所示,与倒置残差结构相比,沙漏结构在线性高维之间创建跳跃连接,能够传输网络结构中的更多信息,并且将深度卷积应用在高维空间中,以学习更具表现力的特征。
基于对上述模块的研究,本文构建了融合空洞卷积的沙漏模块,作为骨干网络提取特征。如图1(d)所示,将原始沙漏结构中的深度卷积,修改为空洞深度卷积(DDwise)用来拓展感受野,进而获取更多的上下文信息。
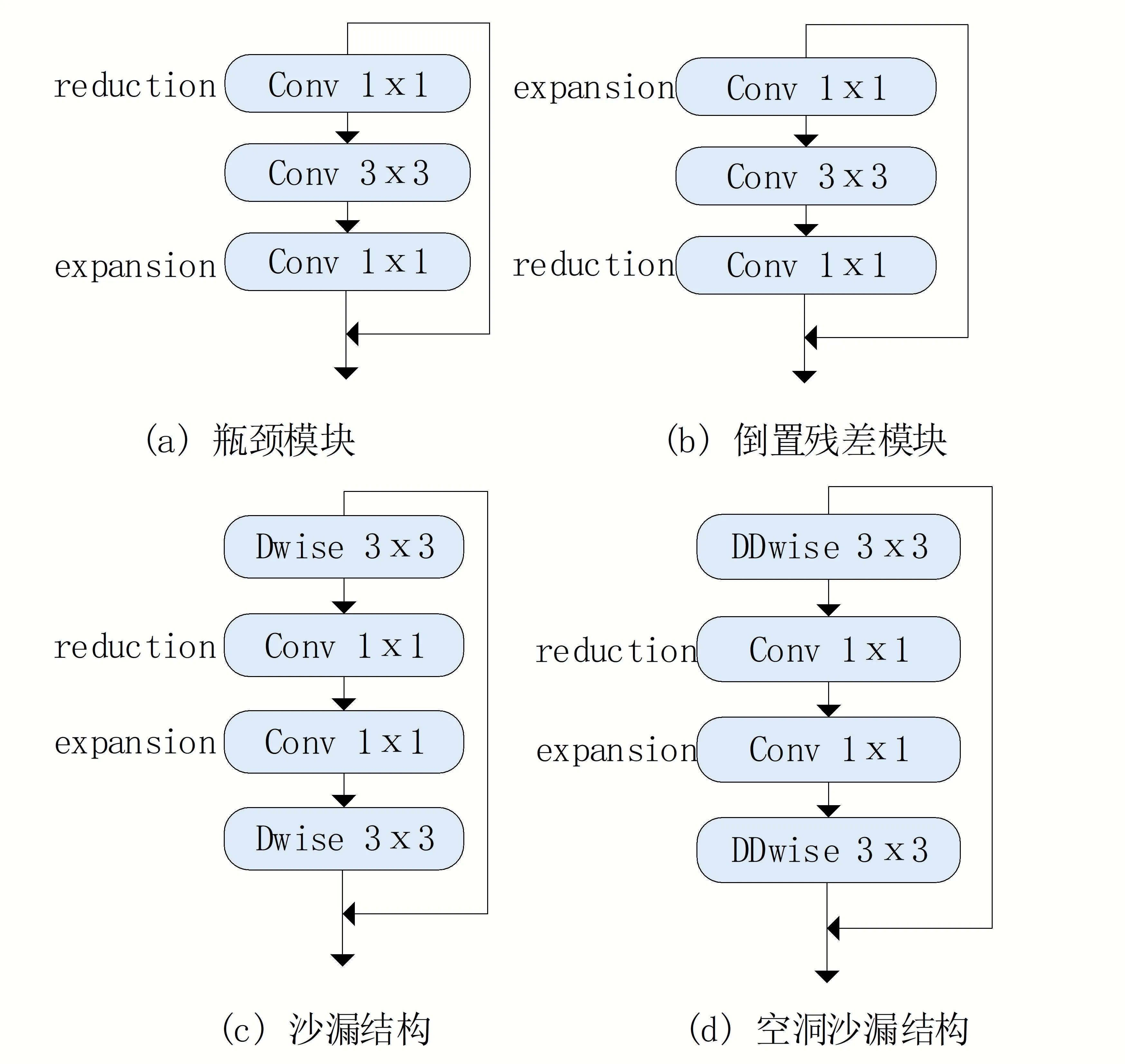
图1 轻量级网络结构
1.2 改进的空洞空间金字塔池化模块
空洞空间金字塔池化模块利用不同空洞率的空洞卷积对骨干网络输出的特征图进行并行的多尺度特征提取,并将提取出的特征图使用堆叠的方式进行融合。
为了减少算法网络的参数,提高网络的实时性,并且保证模型精度。本文在ASPP 模块中引入了深度可分离卷积,用来替换原有的普通卷积。如图2所示,深度可分离卷积可以分为两部分:逐通道卷积、逐点卷积。如图2(a)所示,首先逐通道卷积在二维平面上进行,卷积核的数量为输入的特征的通道数。如图2(b)所示,逐点卷积核的大小是1 × 1 ×,表示输入的通道数,逐点卷积通过将输入的特征图在通道方向上进行加权组合,得到输出的特征图。

图2 深度可分离卷积
虽然ASPP 模块为特征提取网络提供了较大的感受野,但同时叠加了由不同空洞率而得到的特征图,导致出现网格现象。为解决这一问题,本文借鉴了ESPNet 中分层特征融合的思想,在所有特征图进行融合之前,将使用不同空洞率所得到的特征图进行逐元素相加。这个方法不仅简单有效,而且不会增加模型的复杂度。
改进后的ASPP 模块如图3 所示,将ASPP模块中卷积后的特征图相加有利于在同一维度下增加其中的信息量,提高最终的分割精度。

图3 改进的ASPP模块
1.3 特征融合模块
在实时语义分割算法中,通常使用以下方法来提高模型的前向传播速度:①通过裁剪输入图像的尺寸,降低计算量;②缩短网络的通道数来缩短前向推理时间,同时也会丢失部分特征信息。这些方法有效,可以显著提升网络模型的实时性,但同时也会丢失部分空间细节,物体边界分割不连贯,甚至产生误分割现象。
为了解决上述问题,研究人员通常使用跳跃连接,融合骨干网络中不同层次的特征图,来补充下采样过程中空间细节的损失。但是这种方法也存在一定的缺陷,通过骨干网络提取出来的高维度特征图丢失的空间细节信息,并不能够直接通过融合低维度特征的方式直接恢复。因此本文使用了特征融合模块对低维度层特征和高维度特征进行融合,进一步补充因为多次下采样导致的空间信息损失。本文中特征融合模块的设计借鉴了CBAM注意力模型中的通道注意力机制,如图4所示。

图4 通道注意力模块
首先对输入的特征F(××)进行全局最大池化和全局平均池化,得到两个1 × 1 ×的特征图。接着对得到的两个特征图分别使用两个卷积层提取特征和一层激活函数,第一层使用1 × 1 的卷积特征提取,同时进行降维,紧接着的激活函数是Relu,第二个卷积层使用1 ×1的卷积进行升维。最后将输出的两个特征图进行相加,经过Sigmoid 激活函数后,生成最终的通道注意力特征,即每个通道对应特征值的权重。
特征融合模块如图5 所示,其中Attention module 为上一节中的通道注意力模块。首先将低维度特征图和高维度特征图进行叠加,再使1 × 1 的卷积进行降维,接着将输出的特征图传入通道注意力机制模块,将得到的通道权重和第一步得到的特征图进行相乘,最后将相乘后的特征图和降维后的特征图相加,至此特征融合结束。

图5 特征融合模块
1.4 网络结构
本文的网络结构是非对称的编解码器结构,即编码器模型远大于解码器模型。编码器由下采样模块、普通沙漏模块、空洞沙漏模块、改进的ASPP 模块组成,解码器由上采样模块和普通的沙漏模块组成。在分割任务中,输入的图像一般比较大,其中包含了丰富的信息。此时优先使用下采样模块可以有效缩小图片的尺寸,缩短后续的处理时间。之后使用沙漏模块提取语义特征,并在更深的维度使用空洞沙漏模块,增大感受野,获取更多的上下文信息。由于在下采样过程中特征图变小,我们需要图像恢复到输入图像的尺寸用来计算最终的精确度,进而引入了上采样模块。通常的上采样方式有以下几种:双线性插值,反卷积,反池化,本文采用反卷积构建上采样模块进行上采样。
本文的网络结构如图6 所示,其中downsampler 表示的下采样模块,借鉴的是ENet 中的下采样模块,采用双路分支,主分支使用卷积提取特征,拓展分支使用最大池化提取特征,最后在拼接后使用批归一化和Relu 激活函数,输出的特征图是输入原图尺寸的1/2。sgblock 即上文所述的沙漏模块,dsgblock 即融合了空洞卷积的沙漏模块,ASPP 模块采用的是改进后的ASPP 模块,上采样模块使用的是反卷积,批归一化和Relu 激活函数的组合,upsampler1 采用了四倍上采样后使用沙漏模块细化特征,再和低维度的特征图进行特征融合,FFM 模块即上文所述的特征融合模块,upsampler2使用的是双倍上采样,恢复到输入原图的大小。
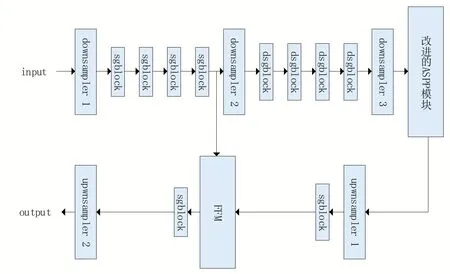
图6 整体网络结构
2 实验及分析
2.1 语义分割数据集介绍
本文使用的是CamVid(cambridge-driving labeled video database)数据集,是由剑桥大学发布的像素级别标注的公开数据集,总共有11 个语义类别,主要应用于语义分割领域,尤其是道路交通的分割。在CamVid 中总共有701 张城市的街景图像,训练集中的图片有367张,验证集中的图片有101 张,剩下的233 张图片作为测试集使用,部分标注图片如图7所示。

图7 CamVid数据集
2.2 评价标准
本文使用的准确度评估指标是语义分割中的平均交并比(mean Intersection over Union,MIoU),推理速度评估指标是帧速率(frames per second,FPS)。
平均交并比():计算的是真实值和预测值两个集合之间交集和并集的比值,是图像语义分割中评价准确度的常用指标。计算公式表示为:

其中+1表示的是类别的总数,p表示的是实际类别是,并且正确预测是类别的像素的数目,p表示的是实际类别是,被判断为类别的像素数目。
帧速率():是指每秒钟刷新图片的次数。计算公式表示为:

指标越高,则表示算法的实时性越好,主观感受越流畅。
2.3 实验环境和参数设置
本文的模型使用的硬件平台是Intel i7-11700,内存为64 G,使用的显卡为RTX 2080Ti,软件环境是Ubuntu 18.04 操作系统,使用的深度学习框架是Pytorch。
训练时使用的批量大小为10,使用Adam优化方法,初始的学习率是0.0005,L2 正则化系数是0.0002,学习率衰减策略为固定步长衰减,步长为90,衰减率为0.1。
2.4 实验结果与分析
本文对改进的ASPP模块和FFM 模块进行了消融实验,来验证两个模块对最终结果的影响,在CamVid数据集上的结果如表1所示。

表1 消融实验结果
分割结果如图8所示,与其他语义分割算法对比见表2。
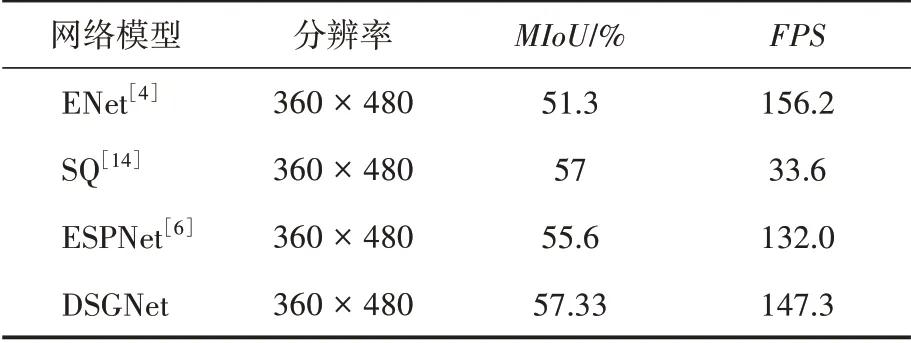
表2 本文算法与其他语义分割算法在CamVid数据集的对比结果
将本文中使用dsgblock构建的骨干网络定义为baseline,将添加改进ASPP 模块和特征融合模块后的网络定义为DSGNet。由表1 所知,本文基于沙漏结构创建的语义分割网络在CamVid数据集上以159.7FPS 的速度达到了54.58%MIoU的精确度。在只加入改进的ASPP 模块后平均交并比提升了2.33 个百分点,同时FPS 下降到153.1。在只使用特征融合模块FFM 的情况下,比原始网络的MioU 提升了0.73 个百分点,同时FPS下降了3.9。最终,将改进的ASPP模块和特征融合模块都加入原始网络后,MIoU 有显著提升,达到了57.33%,同时FPS也达到了147.3。
图8 展示了CamVid 数据集中原始的输入图像和标签图,baseline 对于原图的分割存在以下几个问题:①对于建筑物和树相连的部分存在误分割现象;②对于小物体的分割效果不够理想;③对于物体的边缘分割效果不够精细。在加入改进的ASPP 模块后,提升了模型整体的感受野,能够更多地获取上下文信息,特征融合模块也可以更好地将高低维度的特征信息进行融合。因此DSGNet 相对于baseline,建筑物和树木之间的误分割现象明显减少,路面和建筑物的边缘能够较好地还原,细小物体的分割效果明显增强,如广告牌,电线杆等。

图8 分割效果可视化对比
由表2可知,本文提出的基于沙漏结构的语义分割网络与其他语义分割网络相比各有优劣。与表中实时性较高的ENet 相比,本文网络的FPS 指标略低,但是平均交并比显著高于ENet。和SQ 相比,在平均交并比相似的情况下,实时性显著高于SQ。本文网络在CamVid数据集上的表现,均略高于ESPNet。
3 结语
为解决语义分割中实时性和精确度不能兼顾的问题,本文提出了基于沙漏结构的实时语义分割网络。将深度可分离卷积和ASPP 模块结合可降低参数量,同时提高了推理速度。针对ASPP 模块中空洞卷积产生网格现象的问题,将不同空洞率提取出的特征图进行有效堆叠,从而抑制网格现象。为了将不同维度的特征图进行有效的融合,基于注意力机制提出特征融合模块。实验结果表明,改进的ASPP 模块和特征融合模块在基于沙漏结构的语义分割网络中有效地减少了误分割的现象。
由最终分割结果可知,本文提出的算法仍然存在部分场景中边缘分割不够精细的问题。针对上述问题,如何设计更加高效的骨干网络,如何精确提取边缘语义信息将是今后研究的重点。
