基于YOLO 的手机外观缺陷视觉检测算法*
2022-07-21刘思瀚
杨 戈 ,刘思瀚
(1.北京师范大学珠海分校 智能多媒体技术重点实验室,广东 珠海 519087;2.北京师范大学 自然科学高等研究院,广东 珠海 519087)
0 引言
手机是当前人们生活中的必需品,如何高效并且尽可能低成本地制造手机成为了热点之一。而手机的屏幕缺陷检测则是属于手机制造过程中重要的一个环节,如何在这个环节上化繁为简并且提高效率至关重要。传统的人工检测不仅效率低下,并且会增加手机制造成本。还有一些传统的视觉处理方法,通过提取图像特征再通过提取的特征去选择、识别。这种传统的办法虽然降低了人工成本,但是受限于特征提取时的环境以及方式,使得特征提取环节变得复杂,所以效率也不会太高。因此,寻求一种高效、可靠的基于深度学习的智能化的手机屏幕缺陷检测算法是很有必要的。
1 机器视觉缺陷检测方法
1.1 传统的机器视觉缺陷检测方法
传统的机器视觉缺陷检测方法主要是研究图像的特征选取、特征的选择以及特征的识别这三个方面。在图像特征选取方面,文献[1]的主要研究内容是图像特征的提取、特征的选择和图像的识别。在特征提取时有根据统计量来提取的,也有根据信号域来提取的。文献[2]的方法是由获取图像、图像处理和图像反馈三部分组成的,先用特殊的专业相机去获取清晰度高的图像,再将获取的图像进行降噪的处理,目的是降低图像的环境噪声,尽可能地降低环境干扰,使得图像的信息得到增强。文献[3]提出基于图像处理技术的手机划痕检测算法,该方法需要将图片进行预处理,降低图像的噪声,剔除环境噪声,增强图像的有用信息,将灰度进行变换从而提高图片的质量。
文献[4]设计了一套包含光学成像模块、图像采集模块以及软件算法的整体方案。为了提高图像增强的效果,改进了引导滤波,把改进的中值滤波后的图像作为引导图像,将引导滤波的高效边缘保持效果和改进的中值滤波的平滑作用相结合,去除低照度图像的噪声。文献[5]进行二值化和边缘检测确定手机屏幕区域的位置,其次采用几何校正使目标区域保持水平,利于进行目标提取操作,最后进行颜色空间转换提高屏幕缺陷与周围的对比度,以便于之后进行缺陷检测。
传统的机器视觉缺陷检测方法虽然可以对一些具有重复性的缺陷进行高效率的检测,但由于这种方法的检测效率对图像的特征选取和特征的选择这两方面有较高的依赖性,并且在实现中有很多的缺陷特征和类型都不同,使得该方法的检测效率并不高,无法作为生产中实时缺陷检测的技术[6]。
1.2 基于深度学习的缺陷检测方法
基于深度学习的缺陷检测方法通过卷积计算,将图片的特征参数化,提高了算法的实用性和有效性,可以再通过优化参数从而来提高算法的精准度。文献[7]将现有的FCN(Fully Convolutional Network)进行改进,构建了一套适合裂纹检测的全卷积神经网络Crack FCN,该网络保留FCN 网络的优点,输入的图片没有限制,任意尺寸的图片都可以作为网络的输入,该网络通过反卷积操作来还原最后一层卷积层的图片特征尺寸,提高了预测的精度。文献[8]构建了一种能够模拟视觉感知的深度学习网络结构,结合了神经网络非线性映射的能力,提出了一种网络结构自我生长的和参数自我学习的方法。通过模拟人类大脑深度学习的过程,可以使得可疑区域直接通过深度学习网络结构,再进行卷积网络的逐层学习提取可疑区域的特征,最后利用径向基网络实现图像的识别功能[8]。但是该算法也存在相应的缺点,即在背景噪声太大和有效区域太过模糊的情况下会导致算法结果不稳定。
文献[9]提出CNN(Convolutional Neural Network)算法,CNN 属于前馈神经网络,是一种包含了卷积计算的深度学习网络。CNN 网络一般包括了卷积层、池化层和全连接层。卷积神经网络的主要模型包括LeNet 模型、AlexNet模型、VGGNet模型和ResNet模型等[10-12]。
文献[13]提出YOLO(You Only Look Once)系列算法,该系列算法属于端到端的深度学习神经网络,它将网络结构应用在整个图像上,将图像分成若干个网格,对网格的边界进行预测并预测网格中内容的所属类别,它最终将目标检测问题转化为了回归问题。不同于R-CNN系列算法,它直接采用预测目标对象的边界框的方法,将区域识别和对象识别这两个阶段融合成一个阶段,可以在预测边界坐标的同时对目标进行分类。这就使得YOLO 系列算法网络结构更加简洁,速度更快,准确率更高。YOLO 算法的网络结构图包含了24 个卷积层和2个全连接层,用卷积层网络来提取特征,用全连接层来得到预测值[14-15]。
2 YOLO-q-v3 算法
YOLO-q-v3 算法采用53 层卷积层,其中卷积层由filters 过滤器和激活函数构成,通过设定filter 的数值,按照设置的步长不断地提取图片的特征,从局部特征再到总体的特征,从而完成图像的识别。卷积层的参数包括了卷积核的大小、步长和填充。卷积层里面有多个卷积核,卷积核的大小影响了选择区域的大小即感受野的大小,卷积核越大提取的图片特征越复杂。全连接层的作用是将经过卷积层和池化池处理后的数据串联起来,再对串联出的结果进行识别和分类。全连接层接受卷积层或者池化层的输入,并输出一个多维向量,这个多维向量代表了每一个类别的概率,即输出各个结果的预测值,然后取最大的概率作为全连接层识别分类的结果。
2.1 YOLO-q-v3 算法设计
本文提出YOLO-q-v3 算法中用于提取特征的主要网络是卷积神经网络DarkNet-53。DarkNet-53 提取了ResNet 网络的优点,它在某些卷积层之间添加了一条快捷路径,这条路径和卷积层形成了残差组件。残差组件可以使得网络层数相应减少,参数减少,从而减少计算量,使得DarkNet-53 的性能得到了较大提升。但是在本文运用的数据集中,图片缺陷数量不多,不需要检测多个对象,因此本文提出将原DarkNet-53 网络在保持原本的检测精度的情况下进行删减网络层数,通过减少参数来提高算法的检测效率,算法相关参数如表1 所示。

表1 算法参数对比
YOLO-q-v3 算法还采用了FPN(Feature Pyramid Networks)的结构改善对较小物体的检测结果,每一个特征图被拿来做了边界框回归,其中尺寸最小的顶层特征用来检测较大的物体,而尺寸较大的特征图则用来检测较小的物体。如果是单一尺度检测器,尺度太大而数据集上特征过小就会导致生成的锚框对小特征检测效果不好。采用多尺度检测器就能避免这个缺点,不论在检测特征过小还是特征过大的图片时,都有适当尺寸的检测器去进行检测。该网络结构没有池化层和全连接层,是由卷积层构成了全卷积神经网络,这样使得算法减少了卷积层的运算量,从而提升了DarkNet-53 网络的计算效率。并且在预测对象类别时不再使用softmax,而是改用logistic 来进行预测,能够支持多标签的对象。
如图1 所示,改进的DarkNet-53 网络的主体卷积层与原网络相同,一共有53 层卷积层,除去最后一个1×1的卷积层共有52 个卷积作为DarkNet-53 网络的网络卷积主体。DarkNet-53 网络提取了ResNet 网络的优点,它在某些卷积层之间添加了一条快捷路径,这条路径和卷积层形成了残差组件,使得DarkNet-53 网络结构层次变得更深。而本文提出的改进算法将原网络的残差组件数量从1、2、8、8、4 个分别删减到1、2、2、6、4 个。

图1 改进DarkNet-53 网络结构
2.2 算法实现
YOLO-q-v3 算法实现步骤如图2 所示,首先通过特征提取网络DarkNet-53 对输入的图像进行特征提取,得到不同尺度大小的特征图。然后对图像的特征图进行网格划分,划分出来的网格可以负责来预测落在该网格中的真实边界框中的目标。每个目标有固定数量的边界框,在YOLO-q-v3 中有3 个边界框,最后使用逻辑回归来确定预测的回归框。

图2 YOLO-q-v3 框架
2.2.1 检测框预测
如图3 改进算法直接预测相对位置,预测出b-box中心点相对于网格单元左上角的相对坐标。

图3 检测框预测

根据anchor 的预测值来预测宽和高的公式如下:其中,bx、by、bw、bh分别为预测框的中心坐标x、y、宽度、高度,tx、ty、tw、th分别为网络输出的预测框的中心坐标x、y、宽度、高度,cx、cy分别是网格左上角的坐标x、y,pw、ph分别是锚框的宽和高。
2.2.2 损失函数
本文算法在计算损失函数时,根据IOU(Intersection over Union)对预测框结果进行分类,IOU 的计算公式为[13]:
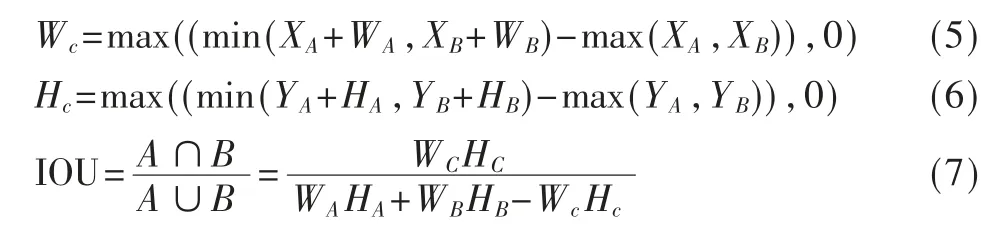
其中,(XA,YA)为边框A 的左上角坐标,WA为A 的宽,HA为A 的高;(XB,YB)为边框B 的左上角坐标,WB为B 的宽,HB为B 的高;C 为边框A 与B 相交的矩形区域,WC为C 的宽,HC为C 的高[13]。
YOLO v3 算法的损失函数与每个特征图的相关损失有关,其中每个特征图的损失lossN1与预测框大小和位置相关lossbox、预测结果置信度相关losscon、预测分类结果相关lossclass有关,公式如下:

3 实验与结果
3.1 数据集
手机屏幕缺陷包括裂痕、油脂、破裂等,本文主要采用裂痕数据集,数据集中标注裂痕缺陷目标,采用LabelImg 软件对数据集进行标记,包括标注出数据集中的目标位置和缺陷的种类,保存为xml 格式。本文用于实验的数据集来源于学生自己拍摄的手机屏幕缺陷图集,一共有2 071 张裂痕缺陷图片,分辨率为1 432×1 432,由于数据集量偏少,因此将图片通过旋转和翻折等操作对进行数据集进行扩充,可以降低模型过拟合的机率,提高实验的检测效果。将数据集以8:2 的比例分为训练集和测试集,其中随机选取1 657 张图片作为训练集样本,选取414 张图片作为测试集样本。
3.2 实验环境
本文将以检测手机屏幕裂痕缺陷为目的,通过改进原YOLO v3 算法提出YOLO-q-v3 算法,并将两个算法在同一实验环境下进行实验,再通过对比指标进行比较,实验环境如表2 所示。

表2 实验环境
3.3 评估指标
本文模型性能评估指标为精度(Precision)、召回率(Recall)、平均精度均值(mean Average Precision,mAP)和F1 值。精度P 代表预测正确的正例数据占预测为正例数据的比例,计算公式为:

其中,TP 为标签正样本输出正样本实例的数量,FP 为标签负样本输出正样本实例的数量。
召回率R 表示预测正确的正例数据占实际正例数据的比例,计算公式为:

其中,FN 为标签正样本输出负样本实例的数量。精度P与召回率R 越大说明检测效果越好,然而两者为负相关关系,需要量化指标mAP 在两者间进行权衡。mAP 值为两类目标AP 值的平均值,而F1 值与mAP 值作用相似,也需要同时考虑P 和R 两者的量化指标。F1 值计算公式为:

3.4 实验结果
3.4.1 训练模型
图4 给出了YOLO-q-v3 模型在训练过程的loss 曲线,可以看出该模型的各项损失值在训练轮数达到一定次数时都处于逐渐收敛的状态,说明YOLO-q-v3 网络模型训练的各个阶段已经达到了一个稳定的状态,也说明YOLO-q-v3 模型完成训练。
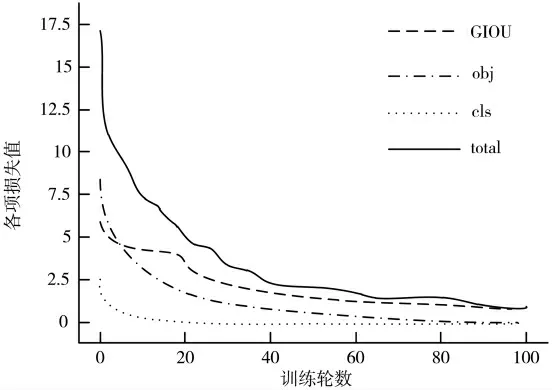
图4 loss 曲线
3.4.2 实验结果对比及分析
本文改进的YOLO-q-v3 算法首先能够准确地将数据集中的裂痕缺陷识别出来,并与原算法在同一实验环境下对同一数据集进行比较试验。
从表3 的各项评估指标可以看出,本文YOLO-q-v3算法的精度P 比原YOLO v3 算法的精度减少了0.4%,两个算法的召回率R 相同,YOLO-q-v3 算法的F1 值比原YOLO v3 算法下降0.1%。

表3 不同算法指标对比
实验结果表明,本文YOLO-q-v3 算法能够准确地识别数据集中的缺陷,虽然在检测精度上对比原算法有所下降,但是下降幅度不大,并且在识别效率上比原算法有所提高,比原算法检测速率提高了24%。
4 结论
本文对YOLO v3 算法的DarkNet-53 网络结构进行了相应的删减改进,使用FPN,提出了YOLO-q-v3 算法进行手机屏幕缺陷检测,减少了计算量,使得算法更适合需要实时检测的要求,如手机生产线对缺陷检测速度有着严格要求。本文YOLO-q-v3 能够正确识别出手机屏幕裂痕,该算法能够满足手机裂痕的非人工检测,检测效率比YOLO v3 算法有所提高。
