基于局部感知的车辆重识别算法
2022-07-21陈冬艳彭锦佳蒋广琪付先平米泽田
陈冬艳,彭锦佳,蒋广琪,付先平,2,米泽田+
(1.大连海事大学 信息科学技术学院,辽宁 大连 116026; 2.鹏城实验室 机器人中心部,广东 深圳 518033)
0 引 言
由于不同车辆可能具有相同品牌、型号和颜色,因此很难通过全局外观辨别不同车辆之间的差异,如图1所示,每一列的两辆车具有不同的ID,图中用圆圈突出它们的局部差异性。为克服这一困难,早期的车辆重识别[1-3]采用人工标注的方式,但监视视频的质量通常受拍摄角度、光照、背景等诸多因素的影响,由图2可知,不同摄像头下的车辆图片差异较大,因此,在监视场景中人工提取的判别特征具有不稳定性。随着深卷积神经网络(convolutional neural networks,CNN)[4,5]在计算机视觉领域的发展,一些研究者采用CNN技术获取车辆全局特征,如Liu等[6]提出一种相对距离学习的耦合簇损失对全局特征进行学习该方法从一定程度上提高了重识别的准确性,但对高度相似车辆的识别率并不高。为解决这一问题,Liu等[7]提出一种区域感知深度模型,直接将较高层全局特征进行划分, 以获得粗略的局部特征。Pirazh等[8]提出利用关键点特征作为车辆结构特征,但未考虑背景信息的影响。Wang 等[9]将车辆方向关键点分为4组,使得每个方向的关键点均具有可见性,但不是所有关键点均具有判别信息。为解决以上问题,本文提出基于局部感知的车辆重识别算法LVR采用三分支网络结构,不仅可获取较为精细的判别特征,还解决背景信息的干扰问题。实验结果表明,该算法具有较好的重识别结果。

图1 相似外观的不同车辆示例
1 基于局部感知的车辆重识别算法
LVR算法模型结构如图3所示,该网络模型主要包含3个网络分支:即图3(a)全局特征分支(第1.1节)、图3(b)分块局部特征分支(第1.2节)和图3(c)关键点选择分支(第1.3节)。首先,将车辆图像输入全局特征提取分支,该分支将极大限度的提取车辆的宏观特征并保留图像上下文信息,但该网络分支可能无法判别相似车辆之间的细微差异,其中最困难的是相同品牌、颜色、型号的车辆;为解决这一问题,本文引入另一网络分支:基于图像分块的局部特征分支,该分支在去除图像背景信息干扰后,将车辆图像均分为上、中、下3块,经卷积得到的车辆局部特征;其次,将去除背景信息后的车辆图像输入两阶段关键点检测分支,该分支首先预测出20个车辆关键点,然后采用由粗到细的方式筛选关键点并去除不可见关键点的影响,得到更为精细的车辆关键点特征;最后将3个网络分支的车辆特征相连,利用L2-Softmax损失[10]对车辆图像进行分类。网络结构和模型训练的详细信息将在以下部分描述。

图3 基于局部感知的车辆重识别算法(LVR)网络模型
1.1 全局特征分支
如图3(a)所示,为提取全局外观特征,本文采用了ResNet-50作为Backbone网络,并将该网络作为LVR网络结构的Baseline模型。该模型由5个下采样和一个全局平均池组成。首先,利用ImageNet预训练模型的权重作为该模型的初始化权重;然后,将ResNet-50最后一个卷积层的2048维特征向量输入浅层感知器。为了将相同车辆ID特征聚集,不同车辆ID特征分开,本文采用L2-Softmax损失函数训练该网络,将网络提取到的特征向量约束在半径为α的区域内。该操作的具体的表达式为
(1)
其中,y表示车辆类别,x表示车辆特征向量,Wm表示权重,bm表示与类别m对应的偏差,α是可训练的正标量参数,N表示车辆类别的数量。
1.2 分块局部特征分支
为提取判别度较高的局部特征并解决背景信息对重识别的影响,本文采用空间变换网络(spatial transformer networks,STN)[11]对齐模块对输入的车辆图像进行定位对齐,然后将图像分为均等的上、中、下3部分,分块后的图像输入到ResNet-50的Block3~Block5层,得到相对全局特征更为精细的局部判别特征。
空间变换网络对齐模块。该模块主要由3部分组成:本地网络(localisation network)、网格生成器(grid gene-rator)以及采样器(sampler)。如图4所示,首先,使用ResNet-50提取车辆图像的全局特征。Block4特征通过由两个卷积层组成的网格生成器进行特征映射,输出转换参数θ。之后,网格生成器依据预测的变换参数θ构建采样网格T(θ), 最后采样器利用双线性内插法根据T(θ) 对车辆图像定位,输出目标特征图。本文对STN对齐模块中特征图的具体转换过程进行分析,其转换过程如下
(2)
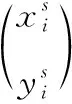
L2(ω)=λ1l1+λ2l2+λ3l3
(3)
其中,l1,l2,l3分别表示上、中、下3个分支的损失,λ1,λ2,λ3表示对应的权重,ω表示深度模型网络参数。

图4 空间变换网络(STN)
局部分块特征训练过程中,添加了全连接层来识别只有局部特征作为输入的车辆图像。该过程强制网络在每个部分提取判别细节,提高网络对局部特征的学习能力。
1.3 关键点选择分支
为获得更精细的局部特征,本文对上节利用空间变换网络去除背景信息后的车辆图像采用两阶段的关键点检测模型:第一阶段,将去除背景信息的车辆图像输入到VGG-16[12]的全卷积神经网络,进行关键点预测,并输出大小为112×112×64的20个关键点的响应图。尽管第一阶段已预测出可见关键点的位置,但预测出的结果中可能存在不可见关键点的影响。受堆叠式沙漏网络[13]的启发,本文采用去除全连接层的两层沙漏网络提取关键点特征,该网络在保证输出关键点响应图质量的同时,对第一阶段粗糙关键点进行精细化选择。图5展示了两阶段的关键点响应图,左侧为第一阶段预测的20个粗略关键点响应图,右侧为第二阶段关键点精细化选择后的响应图,图中可以观察到关键点由粗糙到精细的变化。

图5 车辆关键点响应
车辆关键点方向设定。为得到预测出的20个关键点对应的车辆方向,受OIFE[6]的启发,本文将20个关键点分为4类,分别代表车辆的前、后、左、右4个方向,但相邻两个方向之间没有绝对的界限。然后通过关键点选择器自适应选择关键点最多的方向。为保证预测方向的准确性,每个方向至少有6个可见关键点,并根据关键点预测的多个方向,选择关键点最多的方向,并以此作为车辆的方向。对于每个图,利用σ=2的高斯核确定关键点位置,以解决不可见关键点问题。为得到第一阶段粗略关键点估计,本文采用交叉熵损失训练网络
(4)
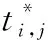
(5)
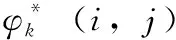
(6)
其中,O={上、 下、 左、 右} 表示关键点方向,o*表示关键点的真实方向。第二阶段精细关键点分支总损失为
L3=LMSE+βLCEE
(7)
其中,β表示平衡优化模型损失的权重,经实验验证当β=12时取得的效果最好。
最后,我们将3个分支特征连接,并在全连接层后利用L2-Softmax作为分类损失对车辆图像进行分类。
2 实验与结果分析
在本节中,首先介绍用于车辆重识别任务的两个大型数据集及评估标准,然后通过对比实验和消融实验验证本文所述算法的有效性。
2.1 数据集及评估标准
本文实验采用两个公开的大规模车辆重识别数据集:VeRi-776数据集和Vehicle-ID数据集,测试LVR算法的有效性。
VeRi-776数据集包含由20个监控摄像头捕获的776种车辆ID的50 000张图像。所有图像均标有车辆ID、类型和颜色。其中车辆类型有9种,例如轿车、公共汽车和卡车等;车辆颜色有10种,例如红色、黑色和橙色等。在这些图像中,训练集和测试集分别包含按37 778张图片(576种ID)和11 579张图片(200种ID)。并从测试集中选择1678张图像作为查询集。
VehicleID数据集包含26 267种车辆ID的221 763张图像。所有图像均标有车辆的ID信息,一部分标有车辆类型和颜色信息。选取13 164车辆的图片作为训练集,而另一半用于评估。从测试集中分别提取800、1600、2400种车辆ID的图片分为3个子集。在每个子集中,随机选择每个车辆ID图像,分别得到800、1600、2400种图像组成的测试集,本文测试实验中使用了800和1600种图像组成的测试集。
车辆重识别中广泛采用两个评判指标对重识别结果进行评估——累积匹配曲线(cumulative match characteristic,CMC)和平均精确度均值(mean average precision,mAP)。CMC反映总体分类器的性能,其中CMC@1表示首位匹配准确率。mAP代表所有查询的平均精度的平均值,它反映整体识别结果的平均精度,其中平均精度(ave-rage precision,AP)是识别结果中某一类别的加权平均值,mAP则为所有类别AP值的平均。
2.2 实验细节
实验过程中,将输入网络的图像大小调整为224×224,Batch size的大小设定为64。训练期间,首先对基础网络进行微调(参照1.1),然后使用Adam(β1=0.5、β2=0.999)优化器优化网络,另外,本文针对不同数据集在训练过程中设置的学习率变化方式也不同。在VeRi-776上全局特征分支和分块局部分支前40个Epoch初始学习率为0.1,后40个Epoch学习率设置为0.01;在VehicleID上全局特征分支和分块局部分支前40个Epoch初始学习率为0.1,后50个Epoch学习率设置为0.01;特别的,对于关键点网络分支,在VeRi-776和VehicleID数据集上该分支网络第一、二阶段均训练40个Epoch,学习率均为le-4。此外本文所有实验均通过Pytorch[13]工具完成。
2.3 评估结果及评估
为测试LVR算法每个分支的有效性,首先对两阶段关键点选择分支进行评估,然后在VeRi-776和Vehicle-ID数据集上设定消融实验和对比实验对该算法进行评估并给出相应的实验结果。
关键点选择分支评估。为评估两阶段关键点选择分支的性能,首先,我们使用均方误差在VeRi-776数据集上对检测到的关键点位置进行准确性测试。表1显示了该分支在第一阶段和第二阶段的MSE数值,由表1可知,第二阶段关键点定位误差比第一阶段降低了18.3个百分点。这也进一步表明,本文采用两阶段由粗到细的关键点检测方法的有效性。然后,采用与OIFE算法相同的评价标准,利用交叉熵损失对该分支的所有可见关键点位置与真实位置之间的平均距离进行评估。如果该距离小于阈值r0则认为该关键点预测正确,否则认为该关键点预测错误。比较结果见表2,当阈值r0为5时预测的准确性提高了1.93个百分点,不难发现本文提出的两阶段关键点选择分支优于OIFE算法。

表1 关键点特征图定位均方误差

表2 关键点预测结果
STN去除背景有效性评估。为进一步说明背景信息对车辆重识别的噪声干扰,本文删除了局部分块分支中的STN定位模型并将车辆图像直接划分为3个重叠区域(按照1.2节所述方式),该网络命名为“背景分块局部分支”并在VeRi-776和VehicleID数据集上对“全局特征分支+背景分块局部分支”网络模型和“全局特征分支+分块局部分支”网络模型的准确性进行对比验证。实验结果见表3和表4。与未去除背景信息的分块局部分支相比,包含STN去除背景信息定位模块的“全局特征分支+分块局部分支”网络模型在VehicleID 800和1600测试集上的mAP值分别提升了1.82个百分点和2.10个百分点,CMC@1分别提升了1.85个百分点和1.64个百分点;在VeRi-776数据集上“全局特征分支+分块局部分支”网络模型的mAP提升了3.41个百分点,CMC@1提升了2.45个百分点。实验结果表明,本文采用STN的定位模型能有效去除背景信息提升车辆重识别的准确性。

表3 VeRi-776上STN去除背景性能实验评估结果/%

表4 VehicleID上STN去除背景性能实验评估结果/%
各分支性能评估。为了评估各分支的性能,本文分别在两个数据集上设定了7个步骤的消融实验对各分支进行评价并给出相应的实验结果。第一是全局特征分支。命名为“全局特征分支”;第二是分块局部分支的上、中、下3个分支,命名为“上局部分块分支”、“中间局部分块分支”、“下局部分块分支”;第三是整个将分块局部分支的上、中、下3个分支连接起来,命名为“局部分块分支”;第四是“全局特征分支+局部分块分支”;第五是在“全局特征分支”的基础上加入两阶段关键点检测分支,命名为“全局特征分块+关键点选择分支”;第六是在“局部分块分支”的基础上加入“关键点选择分支”命名为“局部分块分支+关键点选择分支”;第七是在“局部分块分支+关键点选择分支”基础上加入“全局特征分支”分支,也就是本文提出的“LVR”。
在VehicleID数据集上的实验结果见表5。由表可知,“上局部分块分支”、“中间局部分块分支”、“下局部分块分支”的mAP、CMC@1、CMC@5的结果均低于“全局特征分支”,这是由于分块之后3个分块局部分支不包含整张图片上下文信息导致的;“全局特征分支+局部分块分支”的mAP比“全局特征分支”在800和1600测试集上分别提升了3.28个百分点和3.47个百分点;“全局特征分支+关键点选择分支”在800和1600测试集上的mAP、值比“全局特征分支”分别提升了3.16个百分点和3.35个百分点,这说明了局部分块分支和关键点分支的有效性;在“局部分块分支+关键点选择分支”后加入“全局特征分支”构成LVR算法,在800和1600测试集上,与“全局特征分支+局部分块分支”相比LVR算法的mAP值分别提升了2.87个百分点和4.69个百分点,CMC@1分别提升了2.42个百分点和5.29个百分点;同样可知LVR算法比“全局特征分支+关键点选择分支”识别效果也得到进一步提升,其中mAP值分别提升了2.99个百分点和4.81个百分点,CMC@5分别提升了1.42个百分点和0.94个百分点。
在VeRi-776数据集的实验结果见表6,不难发现与在VehicleID数据集上的实验结果类似,“上局部分块分支”、“中间局部分块分支”、“下局部分块分支”的各个评价标准均低于“全局特征分支”,这是由局部特征不能包含整个车辆的判别特征导致的,与LVR相比“全局特征分支+局部分块分支”的mAP值降低了3.22个百分点,“全局特征分支+关键点选择分支”的CMC@1值降低了2.45个百分点,进一步验证了各个分支的有效性。
LVR算法的车辆重识别效果评估。为验证本文提出的LVR算法的有效性,我们在VehicleID和VeRi-776两个数据集上设定了对比实验。一方面,在VehicleID上与LOMO[14]、VGG+T[15]、VGG+CCL[15]、Mixed DC[15]、FACT[16]、VAMI[17]进行比较。实验结果见表7,不难发现LVR的CMC@1和CMC@5值均优于其它算法。其中,LVR比传统人工特征选择方法LOMO的CMC@1提升了53.31个百分点,这也充分验证基于CNN的车辆重识别方法远远优于早期人工特征选择方法;LVR和这些比较方法中结果最高的VAMI相比,VAMI比LVR算法的CMC@1降低了9.95个百分点,这充分显示出本文提出的LVR算法的有效性。另一方面,在VeRi-776与LOMO[14]、FACT[16]、OIFE[9]、FACT+Plate-SNN+STR[18]、OIFE+ST[9]及RAM[7]、Siamese-Visual[19]进行比较。实验结果见表8,由表8可知,LVR算法比OIFE和RAM的mAP值分别提升了17.53个百分点、4.03个百分点,LVRC比RAM的CMC@1值提升了1.37个百分点,比OIFE的CMC@5值提升了7.12个百分点,这也表明LVR去除背景信息和考虑不可见关键点信息的有效性。
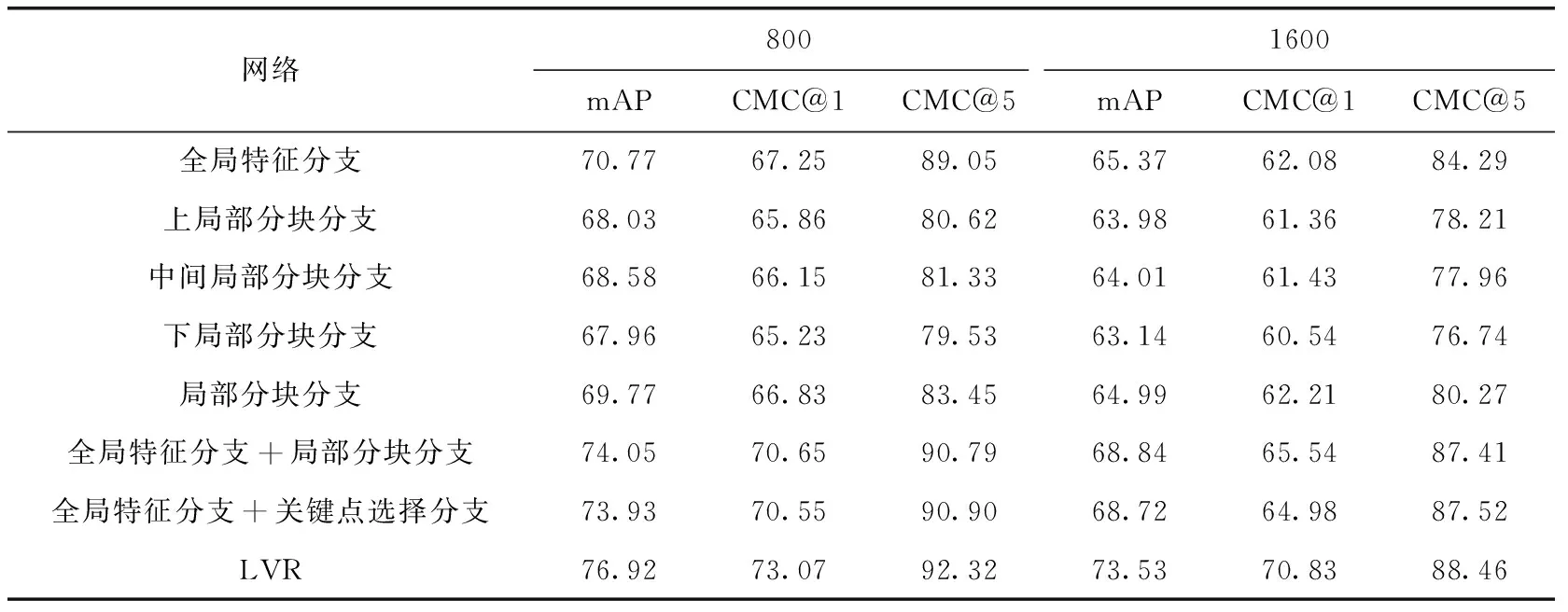
表5 在VehicleID上特征融合性能实验评估结果/%

表6 VeRi-776上特征融合性能实验评估结果/%

表7 VehicleID上与已有部分方法对比实验评估结果/%

表8 VeRi-776上与已有部分方法对比实验评估结果/%
3 结束语
为解决相似度较高车辆尤其是相同品牌、颜色、型号的车辆识别率低的问题,本文从全局和局部多个角度提取车辆的判别特征,提高车辆重识别对相似车辆识别效果。与已有的全局和局部特征识别算法相比,本文方法融合局部分块和关键点及全局特征,可以获取更加精细的车辆判别特征,最终提升重识别的准确性。由消融实验和对比实验可以得出本文方法不仅有效解决背景信息干扰,还可以获取更加精细的局部判别特征,增强了识别性能。尽管本文方法获得了较好的重识别效果,但仍然存在以下不足:本文方法采用的提取关键点选择分支虽然可以获取精细的判别特征,增强重识别对相似度较高车辆的识别性能,但如果采集到的车辆图像遮挡物较多不能获取6个以上关键点,本文方法则不能达到最优的效果。
