多尺度选择金字塔网络的小样本目标检测算法
2022-07-21李晓明
彭 豪 ,李晓明,2+
1.太原科技大学 计算机科学与技术学院,太原030024
2.太原科技大学 计算机科学与技术学院 计算机重点实验室,太原030024
在近几年里,深度学习为目标检测带来了前所未有的进步,基于深度学习的各种目标检测方法,例如R-CNN(regions with convolutional neural network features)、Fast R-CNN、Meta R-CNN、YOLO(you only look once)等效果提升到了一个较高的水平,在很多方面取代了人工。这些检测器的检测效果取决于网络在详尽标注的大规模标注数据集上经过训练得到的模型。通常,这些数据来源需要大量人力资源手工标注,而手工标注的成本又非常高昂。当某些特殊场景缺少样本时,模型往往会产生过拟合或是欠拟合等问题,容易导致检测器泛化性能差无法识别新类别。
近些年来出现很多小样本目标检测方法。LSTD(low-shot transfer detector)结合了Faster R-CNN和SSD(single shot multi-box detector)在分类任务和边框回归任务上的特性,提出了知识迁移正则化和背景抑制正则化两种方法,分别利用源域和目标域的知识增强模型对小样本数据的泛化能力。RepMet(representative-based metric)引入了原型聚类,构造原型空间提取图像的嵌入特征,使用欧式距离计算嵌入特征与支持集类别表示之间的距离。Feature Reweight使用元加权模型将支持集特征以通道相乘融合到查询集特征,这种方法需要额外的掩膜分支,增加了计算复杂度。Attention-RPN将基于注意力的区域生成网络(region proposal network,RPN)与比较训练的策略相结合,利用Matching Networks的思想计算查询实例和支持实例的相似性。LSCN(low-shot object detection via classification refinement)中提出了统一识别、全局接收场、类间分离和置信度校正四个组件,解决因为类指定参数过多导致分类置信度和定位精度存在严重误差的问题。Wu等人和Han 等人研究了在小样本目标检测中的多尺度问题,设计了一个特征金字塔模块生成多尺度特征,并在不同尺度上进行细化,但其网络构造复杂,引入过多的参数增加了计算复杂度。
对于小样本目标检测来说,建立特征的相关性和增强新类参数的敏感性是提升小样本目标检测性能的关键。当有目标相互交错在一起时,检测器会因为只看到了不完整的anchor而发生漏检。Context-Transformer认为从小样本目标检测的任务性质出发,边框回归任务在经过数据的充分训练后再在新类上经过微调就可以取得不错的效果,但分类却很困难。造成这一困难首先是模型对于新类参数不敏感,其次在经过新类样本二次训练后也在一定程度上扰乱了基类已学习到的参数。而现有方法中大多考虑的是整体的检测性能或是采用了简单的融合策略,没有专门针对新类与基类的参数融合问题进行探索。
如图1所示,Meta R-CNN 中设计了一个PRN模块提取支持集类向量,以通道乘法对查询集的实例级感兴趣区域(region of interest,RoI)进行元加权。首先,查询集图片经过特征提取网络和RPN 网络得到感兴趣区域的特征图,然后支持集图像和对应的真实标签图经过预测器重建模网络(predictorhead remodeling network,PRN)得到每个类别对应的类别注意力向量,CNN 的特征提取网络结构相同且权重共享,得到对应特征图后,通过逐元素Sigmoid函数得到对应的注意力向量,最后将RPN 网络输出的感兴趣区域特征图和PRN网络输出的注意力向量通过逐通道相乘的方式进行融合,再利用Faster/Mask R-CNN中预测头得到对应的检测图或分割图。这种方法结构简单,但是没有考虑特征的相关性,在含有大量无效背景的特征中,检测器很容易产生混淆。同时,对于少量样本,模型对新类参数不敏感,检测精度不高。

图1 Meta R-CNN结构图Fig. 1 Meta R-CNN structure diagram
因此在本文中,建立特征的相关性和增强新类参数的敏感性是提升小样本目标检测性能的关键。本文的主要贡献总结如下:
(1)设计了一个用于小样本目标检测的尺度选择金字塔网络,它由三个组件组成:上下文层注意力(contextual layer of attention,CLA)模块;特征尺度增强(feature scale enhancement,FSE),专注于特定尺度的物体;特征尺度选择模块(feature scale selection module,FSS),实现深层和浅层之间适当的特征共享。
(2)在RPN网络产生的RoI特征后采用平均池化和最大池化来提升特征之间的相关性,在后面进行特征融合,并且采用特征减法(feature subtraction,FS)滤除特征图像中的杂波,突出特征中的区分类信息,提升模型对新类参数的敏感度,保持模型对基类参数的稳定性。
(3)引入正交损失(orthogonal loss,OL),就是在隐藏层的特征空间施加正交性,保持不同类特征间的分离性,同一类特征的聚合性。从而保证模型在少量样本情况下也能够很好地衡量特征间的相似性。
1 基于多尺度选择金字塔网络的小样本目标检测
提出的基于多尺度选择金字塔网络的小样本目标检测算法的体系结构如图2所示。首先,设计了一个用于小样本目标检测的尺度选择金字塔网络,它由三个组件组成:上下文层注意力模块、特征尺度增强模块、特征尺度选择模块。然后在RPN 网络产生的RoI 特征后采用最大池化和平均池化来提升特征之间的相关性,之后进行特征融合,并且采用特征减法来突出特征中的类别信息;最后采用正交映射损失函数使模型在分类层前就约束特征。
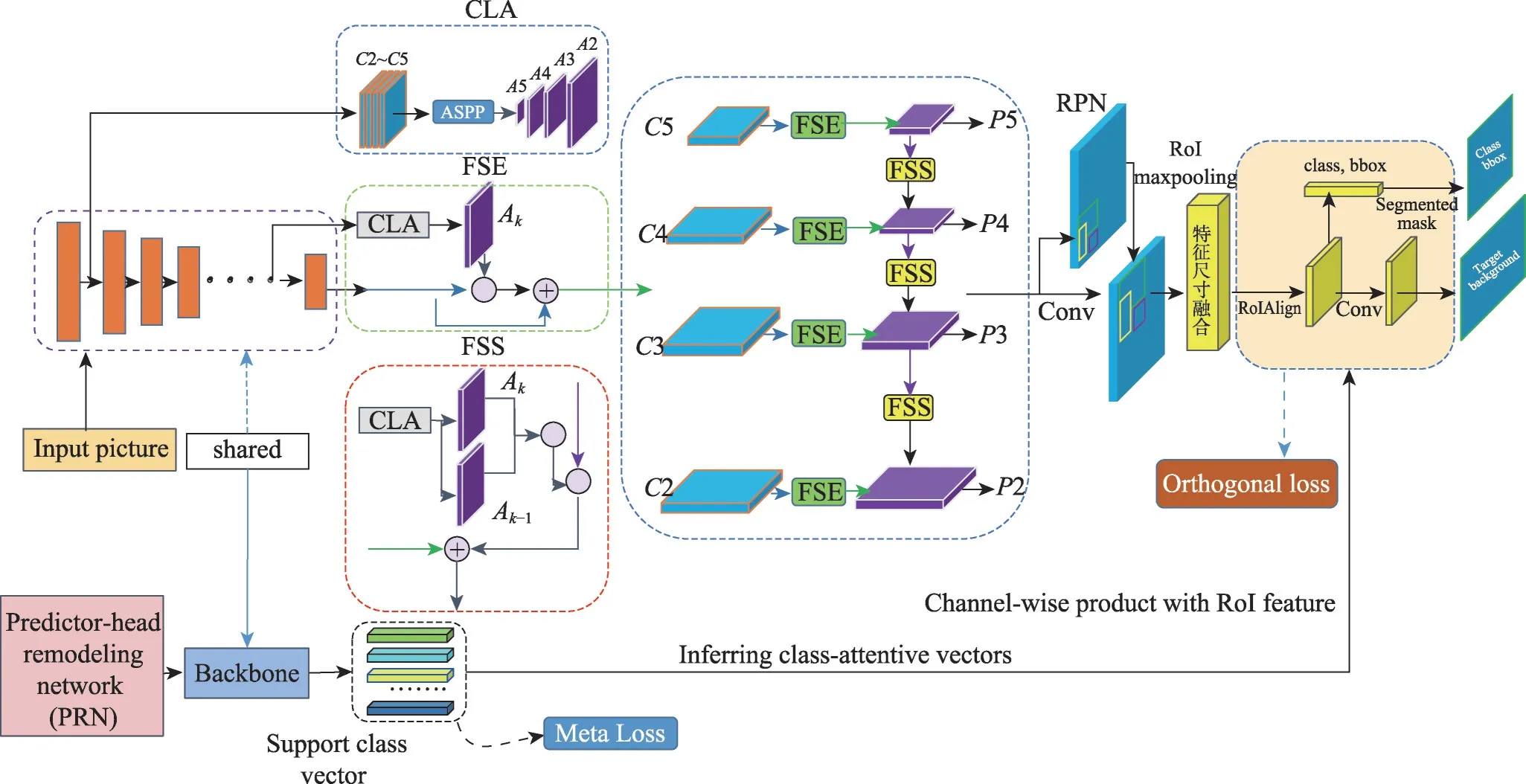
图2 提出的小样本目标检测算法的体系结构Fig. 2 Architecture of proposed small sample target detection algorithm
1.1 上下文层注意力(CLA)
为了生成分层的attention heatmap,本文设计了CLA来生成不同层次的attention heatmap。因为上下文信息可以提高检测小目标的性能,所以,本文首先将backbone 在不同stage 产生的特征进行上采样,使其与底部的特征具有相同的形状,并将它们连接起来。然后采用多尺度空间金字塔池算法(atrous spatial pyramid pooling,ASPP)提取的多尺度特征来寻找目标线索。ASPP 生成的上下文感知特征被传递到一个由多个3×3 卷积和sigmoid 激活函数组成的激活门。该激活门由多个不同stride的卷积和sigmoid激活函数组成,生成层次attention heatmap A:



图3 不同层注意力热力图和不同模块互补作用分析Fig. 3 Heat map of attention on different layers and analysis of complementary effects of different modules
1.2 特征尺度增强(FSE)
采用FSE 增强目标物体的线索。目标信息在低层特征上信息少,因此作用于中高层中,使得FSE能够产生尺度感知特征。

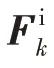
1.3 特征尺度选择(FSS)
FSS引导浅层向深层提供合适的特征,如果相邻层的目标都能被检测到,那么深层将提供更多的语义特征,同时与下一层进行优化。FSS可以设计如下:

其中,A与A的交点为⊙,f为最近的上采样操作,P′为第层的合并映射,C为第(-1)个残块的输出。FSS 起着比例选择的作用。对于下一层尺度范围内的目标对应的特征将被视为合适的特征流入下一层,而其他特征将被弱化以抑制梯度计算中的不一致性。
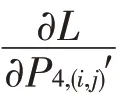



在特征提取过程中,高层特征丢失了大量位置信息,在目标定位,特别是小目标的定位上影响较大,因此考虑将ASPP生成的上下文感知特征叠加到高层特征中减少背景信息对小目标的影响,增加分类准确性。对于小的目标而言,目标特征经过多次卷积池化的操作后,特征信息容易丢失。但是在高层特征的分类中有用信息又主要集中在高层,FSE作用于高层的最后2~3层特征上,跟单纯的特征叠加不同,小目标有相对较小的尺度,合适的A将会把感觉兴趣的区域放在目标特征上。FSS 在特征从浅层往深层的流动中,起到一个筛选作用。图3右侧直观展示了增加不同模块后的特征热力图的效果。
1.4 多元特征融合(MFF)
Meta R-CNN 保留了Faster R-CNN 的两段式结构,由RPN生成图像中目标的候选边界框anchors,然后经过RoI Pooling层和RoI Align层后网络从候选边界框中提取感兴趣区域的目标特征,由分类器和回归器分别对目标特征进行分类和边框回归。网络对特征的提取以及处理模式是固定的,当数据量比较少时,这样的处理往往会遗漏图像的重要特征。通常来讲,网络的高层语义特征对于分类任务都是有所帮助的,因此本文使用RoI mean-pooling 来获得网络中的CLA 整体信息,计算特征基于通道的相关性。最大池化作用于FSE,可以滤除无关信息,两者的结合形成多元特征,对于少量样本信息,提取保留更多纹理等细节特征,以此来提升模型对新类参数的敏感度,具体如图4所示。
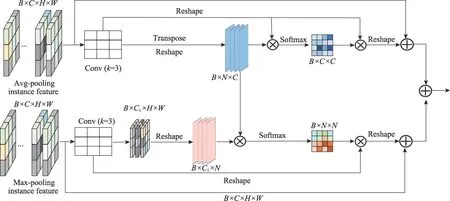
图4 多元特征融合示意图Fig. 4 Schematic diagram of multiple feature fusion


关系矩阵经过softmax 后得到跨通道关系注意力特征图Ψ:

式中,Ψ表示第个通道对于第个通道的关系分数,矩阵的每一行都表示了特征上通道间的互相关程度。注意力特征图Ψ通过矩阵乘法映射到特征″上得到特征向量。最后,经过维度变换后以元素相加的方式叠加到原始特征′上增强跨通道的特征表示,得到基于通道的互相关特征。
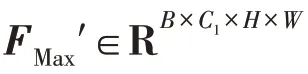

之后,通过softmax函数得关系注意力特征图Θ:
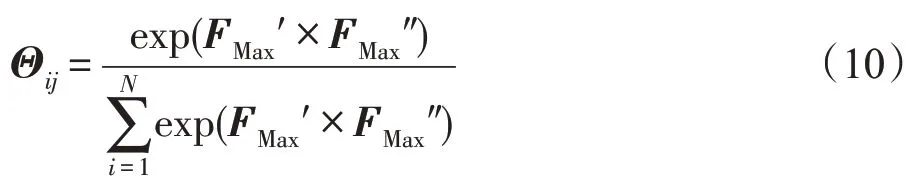
为了突出特征显著性,将Θ通过矩阵乘法映射到″上得到特征向量,最后把经过维度变换后以元素相加的方式叠加到原始特征′上增强跨像素空间的特征表示,得到基于像素空间的互相关特征。
最后,基于像素空间的互相关特征和基于通道的互相关特征拼接起来,最终输出为:

特征减法(FS)可以滤除图像中的杂波,能够突出特征中的区分类信息,结构如图5所示。
图5中,是每个批中包含的样本实例数,是特征通道数,是卷积核的大小,和分别表示生成的得分向量和新类加权系数。使用卷积得到一个可学习的参数,将特征取绝对值,通过激活函数后将维度还原,这里采用Sigmoid 函数只是充当一个门控作用,缓解查询集图像中存在的过多背景和无用特征对分类器的影响,还可以滤除一些杂波,然后加权增加新类参数的敏感性。避免通道上的局部交互特征受维度的影响。输出可以表示为:

图5 特征减法示意图Fig. 5 Schematic diagram of feature subtraction

这种做法能尽量避免产生高维特征,有助于模型泛化,保持稳定性。
1.5 损失函数构建
在小样本目标检测任务中,由于新类中可学习样本数量较少,神经网络往往难以在几个实例上就学到可靠的特征表示,不够明确的特征参数给分类器带来了很大的困难。除此之外,如果直接将隐藏层特征输入到分类层,分类器很容易会产生现有类与新增加类的混淆。为减轻这种混淆给检测模型带来的影响,采用了一种正交损失,在隐藏层的特征空间施加正交性,保持不同类特征间的分离性,同一类特征的聚合性。

式中,为一个控制权重的超参数,|·|表示绝对值操作,余弦相似度的具体计算如下:

其中,||·||表示向量的2 范数。在等式中通过约束逼近1 来保持同类样本间聚类,逼近0 让不同类样本间保持距离,以减轻特征混淆对分类器的影响。这种方法没有多余的参数需要学习,简单高效,带来的性能提升将在后面的消融实验中进行分析。
网络架构基于类似于Meta R-CNN,采用两阶段训练方法,训练过程中的损失函数可以表示如下:

其中,为应用于RPN 网络区分前景背景和微调anchors 的损失;为R-CNN 中用于分类的交叉熵损失;为R-CNN 中用于边框回归的Smooth损失;为Meta R-CNN中用于生成支持集类向量的交叉熵损失。特征相关性构建模块和特征融合模块添加约束,整个网络中应用的损失函数可以表示如下:

在实验中,通过权重可以增加前景与背景作用提高不同类特征间的分离性,起到分类作用,因的作用有限,在中增加损失,增强相同特征的聚合性和不同特征之间的分离性,通过改变和使得模型达到最好的效果。
2 实验结果与分析
2.1 数据集介绍
VOC07 常用来衡量图像分类检测能力,其中训练集(5 011 幅),测试集(4 952 幅),共计9 963 幅图,共包含20 个种类。COCO2014有91 个分类,其中82个分类每个都超过5 000个实例对象,为了能更好地学习每个对象的位置信息,在每个类别的对象数目上也是远远超过VOC07 数据集。为了公平比较,本文的实验设置与文献[3]一致,所有实验结果都通过随机数据采样运行10次计算平均值得到。
2.2 训练参数设置
本文中使用Meta R-CNN 作为网络基本架构,ResNet101作为主干网,在初始化时使用ImageNet上预先训练的权值。本文的训练策略与文献[3]相同,使用随机梯度下降作为网络的优化器,整个训练过程分为两个阶段:第一阶段只训练数据丰富标注完备的基类,设置初始学习率为10,batchsize 为4,一共训练20 个epochs,每个epoch 迭代3 000 次,每5个epochs 后学习率衰减为原来的1/10。第二阶段在同时包含基类和新类的小样本数据集上训练,设置初始学习率为10,batchsize 大小为4,一共训练9 个epochs,在训练5 个epochs 后学习率衰减为10,继续训练剩余4 个epochs。此外,设置中参数=2,=1.3,=1.8。所有实验使用GTX 3090 在Pytorch上实现。
2.3 VOC实验
实验分为两阶段:
第一阶段,使用一种low-shot 实验设置,在VOC07上考虑了三种不同的数据集拆分设置(如表1第2行),这一阶段,只考虑基类对象。在每一个训练基类中都有3 000个带标注的bbox,其中∈{1,2,3,5,10}。为了公平评估,正确的预测应该与Ground Truth的交并比(intersection over union,IoU)大于0.5,并以平均准确率(mean average precision,mAP)作为评价指标。第一阶段结果如表1所示。
从表1 可以看出,本文模型的检测性能优于Meta R-CNN。在VOC split 3 实验中,本文模型都达到了最佳性能。当极标注类别比较少(=1,2,3)时,Meta R-CNN 很难提高检测性能,本文模型可以有更好的性能,并且随着的增加,优势更加明显。在=10 与baseline相差分别为12.0个百分点、7.9个百分点和9.5个百分点。相比其他先进方法,本文方法也有明显优势。

表1 VOC07测试集上的low-shot检测mAPTable 1 Low-shot detection mAP on VOC07 test suite %
第二阶段,数据被随机分为15 个基本类别和5种新类别。模型在包含15个类别的基类数据集上进行训练,每个基类中的对象有3 000个标注的边界框用于训练,在5 个新类数据集上测试。表2 记录了VOC 在拆分数据上每个新类别的评估结果。首先,与基准相比,Meta R-CNN 在VOC 的3 个分割上的“sofa”检测性能较差,特别是当=1 时。在本文方法中,VOC spilt 1 中“sofa”的单次检测性能增加了20.77个百分点,而双次检测性能增加了29.40个百分点。在其他方法中,VOC split 2 中“bottle”的检测性能并不理想,本文方法得到的mAP 高于其他方法。将值对应的3 次平均精度展示在图6 中。总体而言,该方法在所有类别的测试结果中都更具竞争力。VOC 中的“bottle”往往过于密集,所占比例相对较小,实验结果证明该模型也可以聚焦于此类对象。

表2 VOC07测试集上的AP 和mAPTable 2 AP and mAP on VOC07 test suite %
如图6 所示,分别是表2 中不同的平均精度,最后一图是各方法的平均精度。本文方法在各类值上均有优势,换句话说,模型能够在适当关注图像中的每个对象的同时学习对象的鉴别特征。
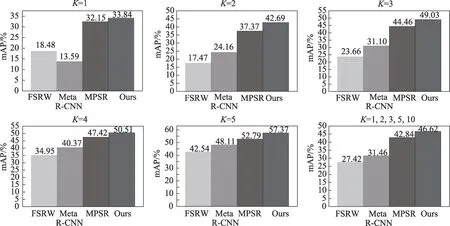
图6 在不同K 下的平均精度Fig. 6 Average accuracy under different K
2.4 COCO实验
COCO2014 包含80 个类别,其中20 个类别与VOC07中的类别相同。与VOC实验类似,使用60个与VOC 不相交的类别作为训练的基类,20 个作为新类。每个类都有个带标签的对象实例,分别取10 和50。评价指标包括、、和、、。其中是指IoU 的平均精度,学习率保持为0.05,指的是的平均精度,指的是的平均精度。指的是图像中小于32×32的物体的平均检测精度,指的是图像中大于32×32,小于96×96 的物体的平均检测精度,是指图像中大于96×96 的物体的平均检测精度。结果记录于表3中。
从表3 中可以看出,在10-shot 中本文方法在和上达到最优15.9%和28.4%,在其他评估指标下该方法也能达到较好水平。在30-shot 中,能达到32.9%。

表3 COCO2014测试集上的AP 和mAPTable 3 AP and mAP on COCO2014 test suite %
2.5 混合实验
最后,进行COCO 到VOC 的跨数据集验证。使用COCO 中与VOC 不相交的60 个类别作为源域数据训练,在VOC07 测试集上进行测试。本文实验的训练参数设置与之前的相同,在评估实验中设置了每个类包含10 个实例,即=10。结果绘制在图7中。如图7 所示,在=10 时本文模型比Meta R-CNN 平均精度高7.36 个百分点,证明所提方法确实可以提高小样本的检测精度。

图7 混合平均精度对比Fig. 7 Comparison of mixed average accuracy
2.6 消融实验
针对VOC07 数据集,分析了各个组件对模型性能的贡献,并分析了这些组件产生效果的具体原因。在本节中,通过逐步应用这些模块来分析提出方法中每个模块的效果。在VOC07 split 1数据集上评估各个模块的贡献,并在表4中记录。

表4 不同模块在VOC07测试集上的low-shot检测mAPTable 4 Low-shot detection mAP of different modules on VOC07 test suite %
从表4 中可以看出,特征尺度增强模块(FSE)使网络能够聚焦于特定尺度的物体,而不是广阔的背景,有效提高了检测性能。特征尺度选择模块(FSS)可以将那些合适的特征从深层传递到浅层用以帮助检测。多元特征融合模块的加入对检测性能影响较大,最大池化和平均池化的特征来挖掘特征相关性,同时保留特征细节和纹理以增强显著特征,可以在视觉信息缺乏的情况下尽可能多地保留住重要特征。随着可学习信息数量的增加(增大),简单的网络构造模块不足以对每个样本进行深度挖掘和特征引导,因此获得的性能增益不高。特征减法滤除一些特征中的杂波,增加新类参数的敏感性,对性能有较小的提升。正交映射损失减轻了类间和类内特征的混淆,对性能有较好的增益,特别是当增大,信息混淆的减少帮助会更大。图8 对比了部分图片的测试结果。

图8 部分测试结果对比Fig. 8 Comparison of partial test results
2.7 参数分析
在实验中具体评估了正交损失对模型性能影响。从表4中第6、7行可知,在使用正交损失后对应={1,2,3,5,10} 的模型性能分别提升了1.4 个百分点、3.5 个百分点、3.8 个百分点、3.3 个百分点、6.5 个百分点。多元特征融合在整体性能提升中发挥了很大的作用,但是随着标签样本的增加(的增大),特征相关性构建模块带来的性能增益降低。主要因为特征的类间和类内混淆导致了标签样本增加而性能增益并不明显,这也是一个固有的问题,而该损失函数可以缓解这种情况。此外,针对正交损失中使用的两个超参数进行了参数分析,具体将分别取0.1、0.5、0.9,分别取0.1、0.4、0.9、1.8,组成参数组=(,),在VOC split 1上的分析结果如图9 所示。可以看出当=(0.5,0.9)时mAP最大。

图9 正交损失不同参数的mAP对比图Fig. 9 mAP of different parameters of orthogonal loss
3 结束语
为进一步提高小样本的检测效果,提出了一种多尺度选择金字塔网络的小样本目标检测方法。跟以往通过简单的特征提取从几个样本中学习特征的方法不同,在特征提取的过程中,使用尺度选择金字塔网络对特征进行有效筛选,其次采用最大最小池化分别进行特征处理,再对特征进行融合,最大限度地保留小样本信息。另外,考虑无效特征和参数敏感性对检测效果的影响,采用特征减法,使用Sigmoid函数作为滤波器的融合方法。除此之外,结合了正交损失对特征进一步约束避免分类器产生混淆,提高新类的检测性能。在实验中,通过对两个基准数据集的综合评估,所提出的方法与基准方法相比有更好的性能。经过消融实验,可以发现多元特征融合在少量标注信息时对检测性能提升最大。样本数增多,基准方法稳定在一个较低的水平,特征减法和正交损失的加入,新类的检测性能提升明显。
